 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Continuous Beam Alignment for Mobile MIMO
Aug 05, 2022
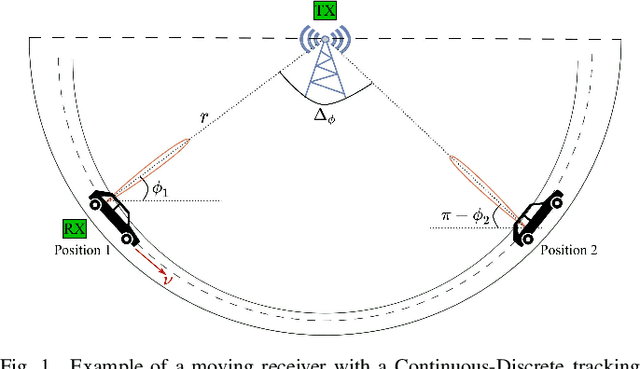
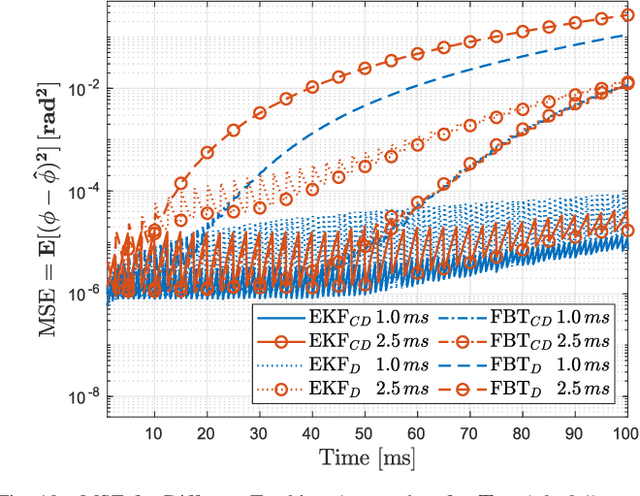
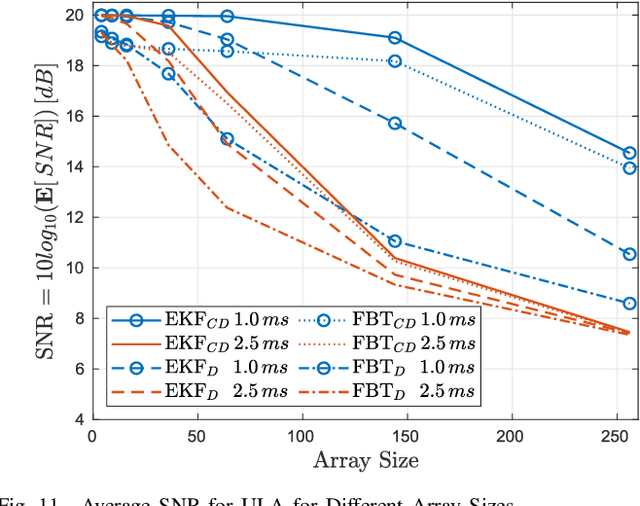
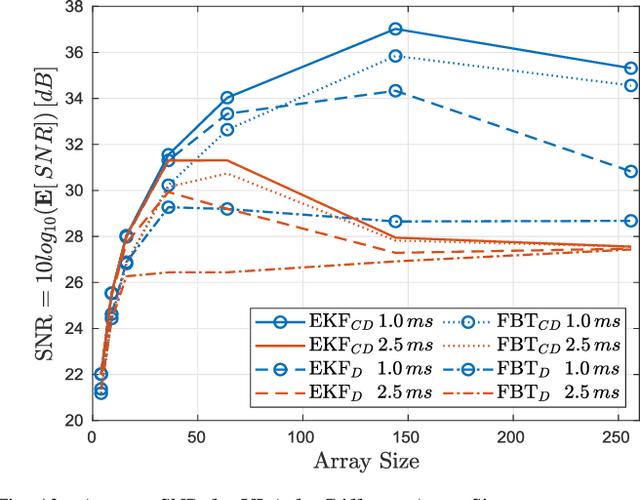
Millimeter-wave transceivers use large antenna arrays to form narrow high-directional beams and overcome severe attenuation. Narrow beams require large signaling overhead to be aligned if no prior information about beam directions is available. Moreover, beams drift with time due to user mobility and may need to be realigned. Beam tracking is commonly used to keep the beams tightly coupled and eliminate the overhead associated with realignment. Hence, with periodic measurements, beams are adjusted before they lose alignment. We propose a model where the receiver adjusts beam direction "continuously" over each physical-layer sample according to a carefully calculated estimate of the continuous variation of the beams. In our approach, the change of direction is updated using the estimate of the variation rate of beam angles via two different methods, a Continuous-Discrete Kalman filter and an MMSE of a first-order approximation of the variation. Our approach incurs no additional overhead in pilots, yet, the performance of beam tracking is improved significantly. Numerical results reveal an SNR enhancement associated with reducing the MSE of the beam directions. In addition, our approach reduces the pilot overhead by 60% and up to 87% while achieving a similar total tracking duration as the state-of-the-art.
Deep Bayesian Estimation for Dynamic Treatment Regimes with a Long Follow-up Time
Sep 20, 2021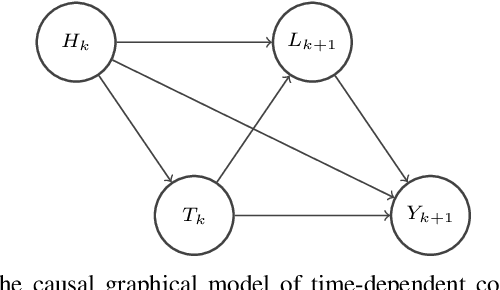
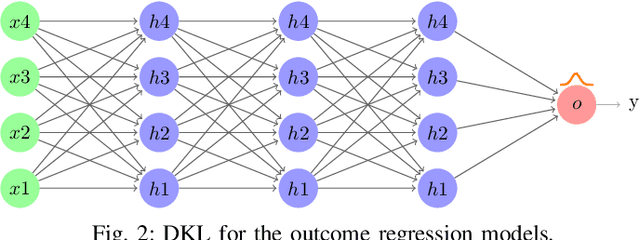
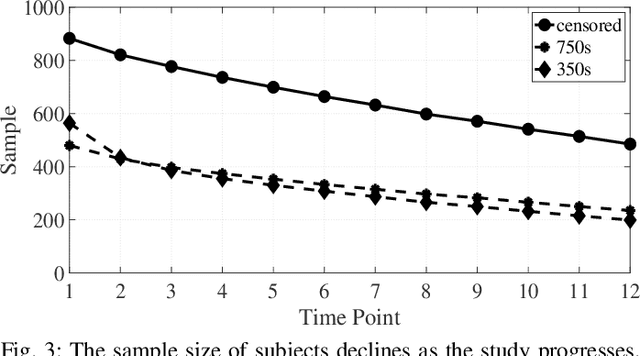
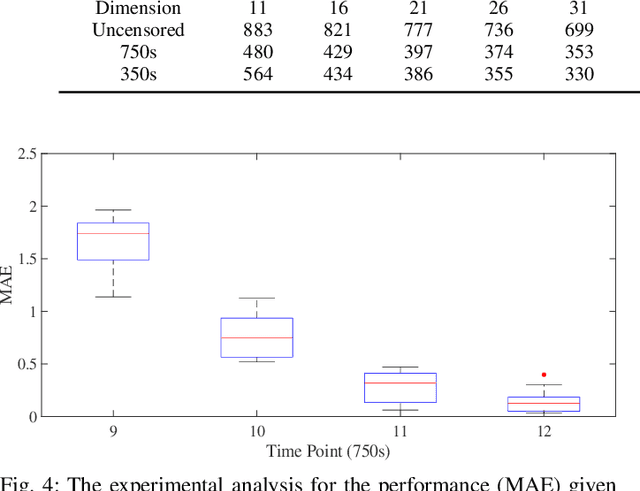
Causal effect estimation for dynamic treatment regimes (DTRs) contributes to sequential decision making. However, censoring and time-dependent confounding under DTRs are challenging as the amount of observational data declines over time due to a reducing sample size but the feature dimension increases over time. Long-term follow-up compounds these challenges. Another challenge is the highly complex relationships between confounders, treatments, and outcomes, which causes the traditional and commonly used linear methods to fail. We combine outcome regression models with treatment models for high dimensional features using uncensored subjects that are small in sample size and we fit deep Bayesian models for outcome regression models to reveal the complex relationships between confounders, treatments, and outcomes. Also, the developed deep Bayesian models can model uncertainty and output the prediction variance which is essential for the safety-aware applications, such as self-driving cars and medical treatment design. The experimental results on medical simulations of HIV treatment show the ability of the proposed method to obtain stable and accurate dynamic causal effect estimation from observational data, especially with long-term follow-up. Our technique provides practical guidance for sequential decision making, and policy-making.
Calibrating Agent-based Models to Microdata with Graph Neural Networks
Jun 15, 2022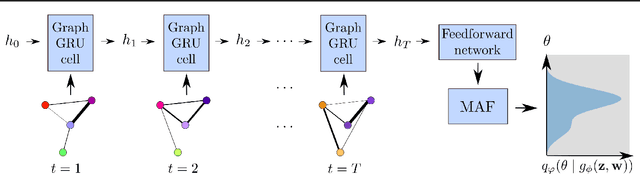
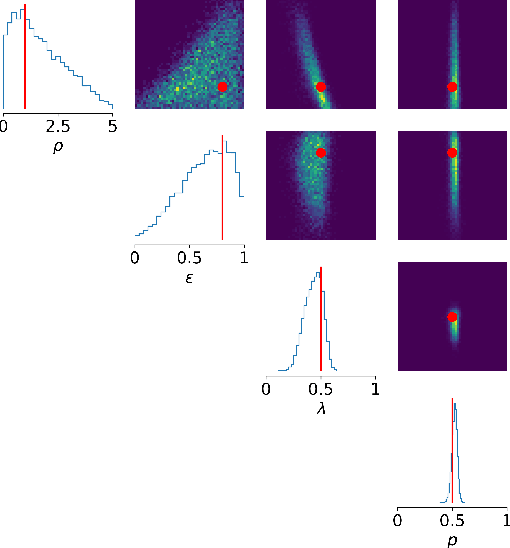
Calibrating agent-based models (ABMs) to data is among the most fundamental requirements to ensure the model fulfils its desired purpose. In recent years, simulation-based inference methods have emerged as powerful tools for performing this task when the model likelihood function is intractable, as is often the case for ABMs. In some real-world use cases of ABMs, both the observed data and the ABM output consist of the agents' states and their interactions over time. In such cases, there is a tension between the desire to make full use of the rich information content of such granular data on the one hand, and the need to reduce the dimensionality of the data to prevent difficulties associated with high-dimensional learning tasks on the other. A possible resolution is to construct lower-dimensional time-series through the use of summary statistics describing the macrostate of the system at each time point. However, a poor choice of summary statistics can result in an unacceptable loss of information from the original dataset, dramatically reducing the quality of the resulting calibration. In this work, we instead propose to learn parameter posteriors associated with granular microdata directly using temporal graph neural networks. We will demonstrate that such an approach offers highly compelling inductive biases for Bayesian inference using the raw ABM microstates as output.
Ithaca365: Dataset and Driving Perception under Repeated and Challenging Weather Conditions
Aug 01, 2022
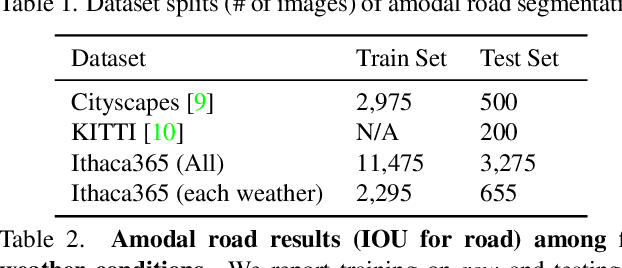
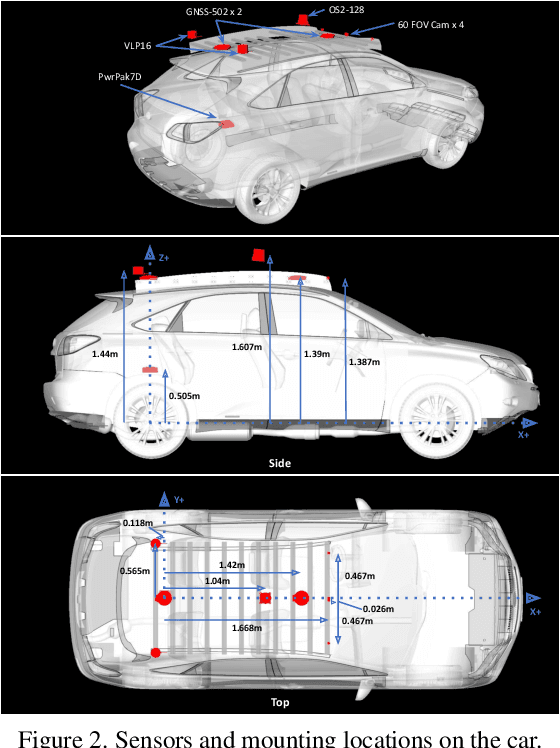
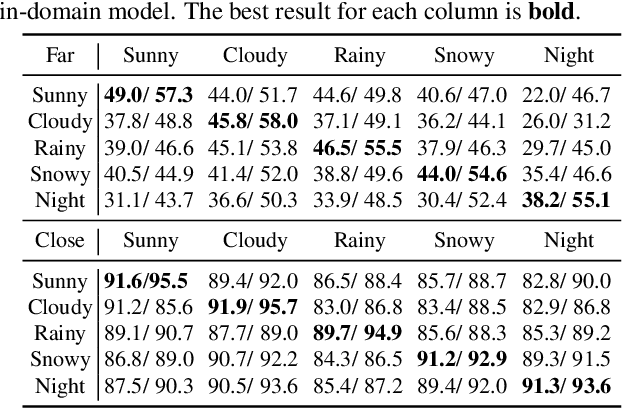
Advances in perception for self-driving cars have accelerated in recent years due to the availability of large-scale datasets, typically collected at specific locations and under nice weather conditions. Yet, to achieve the high safety requirement, these perceptual systems must operate robustly under a wide variety of weather conditions including snow and rain. In this paper, we present a new dataset to enable robust autonomous driving via a novel data collection process - data is repeatedly recorded along a 15 km route under diverse scene (urban, highway, rural, campus), weather (snow, rain, sun), time (day/night), and traffic conditions (pedestrians, cyclists and cars). The dataset includes images and point clouds from cameras and LiDAR sensors, along with high-precision GPS/INS to establish correspondence across routes. The dataset includes road and object annotations using amodal masks to capture partial occlusions and 3D bounding boxes. We demonstrate the uniqueness of this dataset by analyzing the performance of baselines in amodal segmentation of road and objects, depth estimation, and 3D object detection. The repeated routes opens new research directions in object discovery, continual learning, and anomaly detection. Link to Ithaca365: https://ithaca365.mae.cornell.edu/
Unsupervised Tissue Segmentation via Deep Constrained Gaussian Network
Aug 04, 2022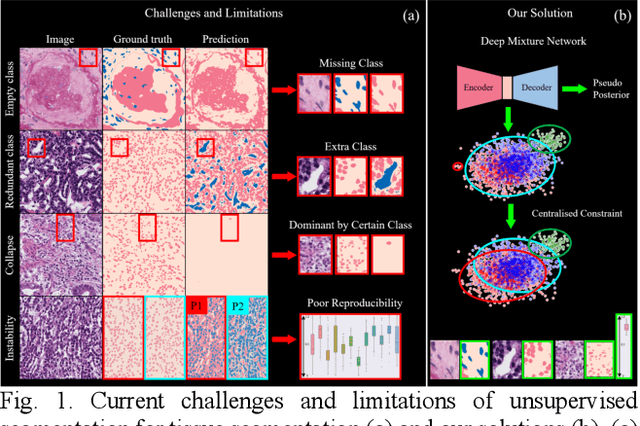
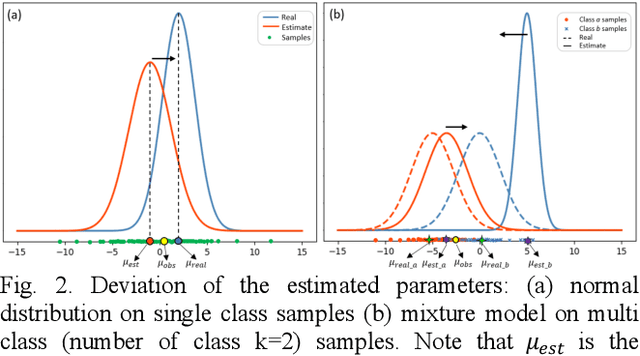
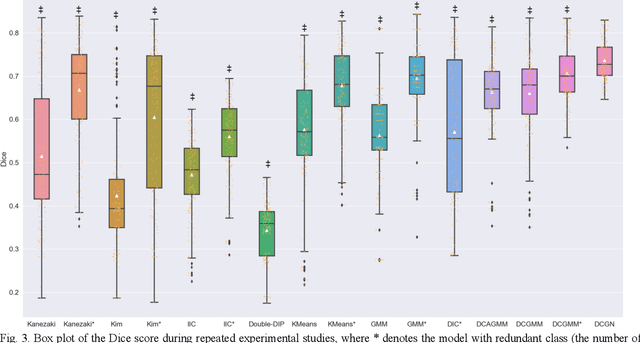
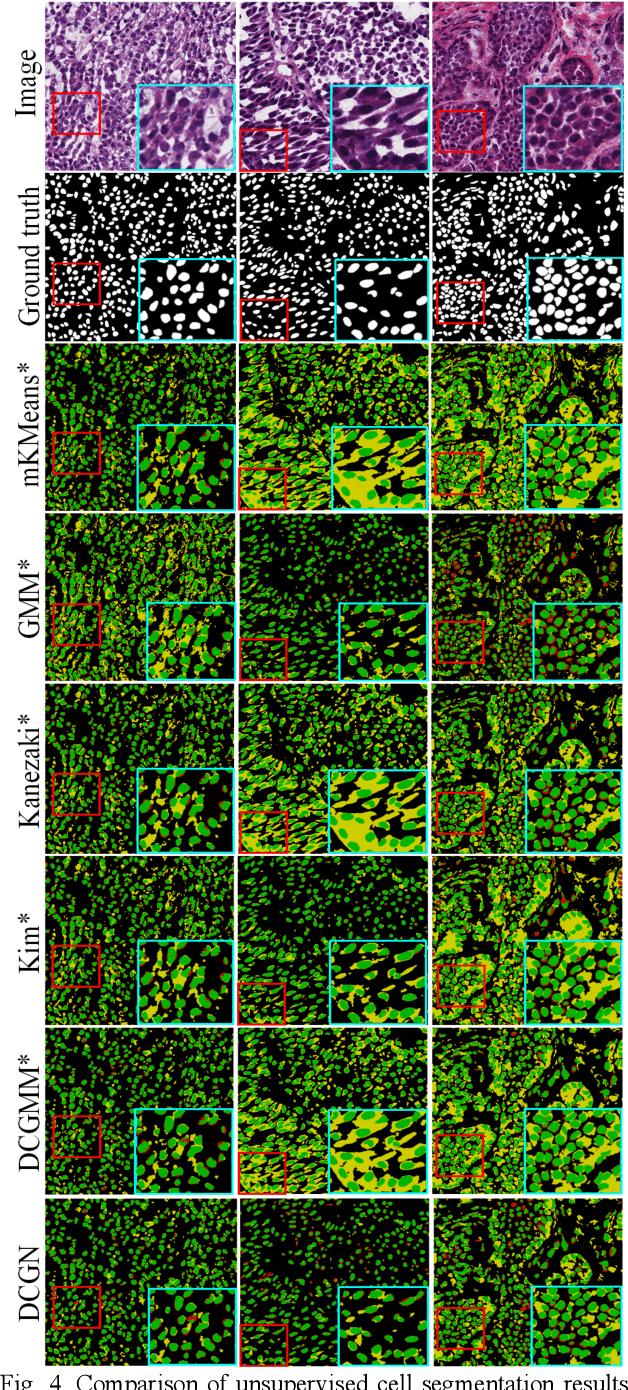
Tissue segmentation is the mainstay of pathological examination, whereas the manual delineation is unduly burdensome. To assist this time-consuming and subjective manual step, researchers have devised methods to automatically segment structures in pathological images. Recently, automated machine and deep learning based methods dominate tissue segmentation research studies. However, most machine and deep learning based approaches are supervised and developed using a large number of training samples, in which the pixelwise annotations are expensive and sometimes can be impossible to obtain. This paper introduces a novel unsupervised learning paradigm by integrating an end-to-end deep mixture model with a constrained indicator to acquire accurate semantic tissue segmentation. This constraint aims to centralise the components of deep mixture models during the calculation of the optimisation function. In so doing, the redundant or empty class issues, which are common in current unsupervised learning methods, can be greatly reduced. By validation on both public and in-house datasets, the proposed deep constrained Gaussian network achieves significantly (Wilcoxon signed-rank test) better performance (with the average Dice scores of 0.737 and 0.735, respectively) on tissue segmentation with improved stability and robustness, compared to other existing unsupervised segmentation approaches. Furthermore, the proposed method presents a similar performance (p-value > 0.05) compared to the fully supervised U-Net.
Syntax Controlled Knowledge Graph-to-Text Generation with Order and Semantic Consistency
Jul 02, 2022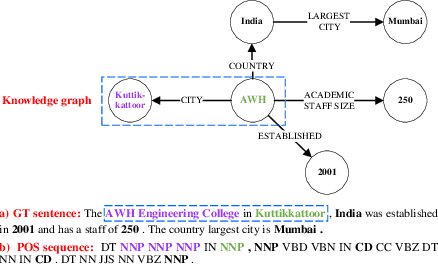
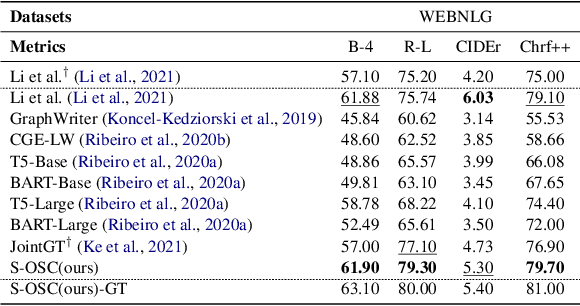
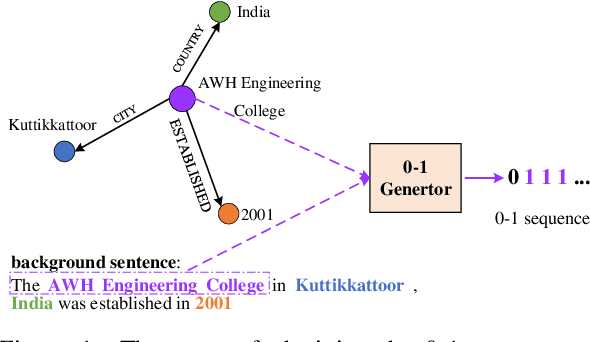
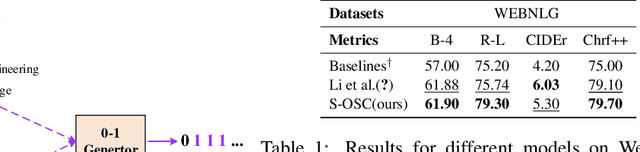
The knowledge graph (KG) stores a large amount of structural knowledge, while it is not easy for direct human understanding. Knowledge graph-to-text (KG-to-text) generation aims to generate easy-to-understand sentences from the KG, and at the same time, maintains semantic consistency between generated sentences and the KG. Existing KG-to-text generation methods phrase this task as a sequence-to-sequence generation task with linearized KG as input and consider the consistency issue of the generated texts and KG through a simple selection between decoded sentence word and KG node word at each time step. However, the linearized KG order is commonly obtained through a heuristic search without data-driven optimization. In this paper, we optimize the knowledge description order prediction under the order supervision extracted from the caption and further enhance the consistency of the generated sentences and KG through syntactic and semantic regularization. We incorporate the Part-of-Speech (POS) syntactic tags to constrain the positions to copy words from the KG and employ a semantic context scoring function to evaluate the semantic fitness for each word in its local context when decoding each word in the generated sentence. Extensive experiments are conducted on two datasets, WebNLG and DART, and achieve state-of-the-art performances.
Quantization enabled Privacy Protection in Decentralized Stochastic Optimization
Aug 07, 2022
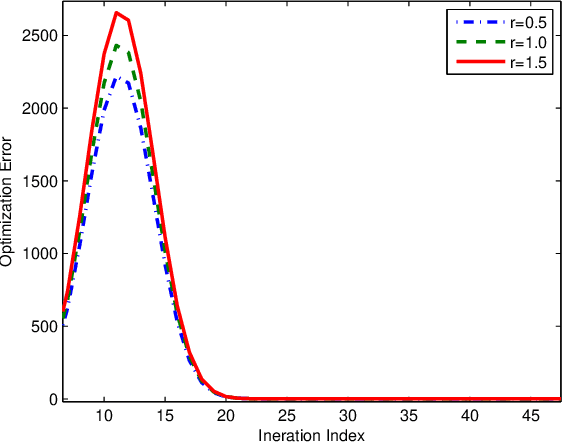
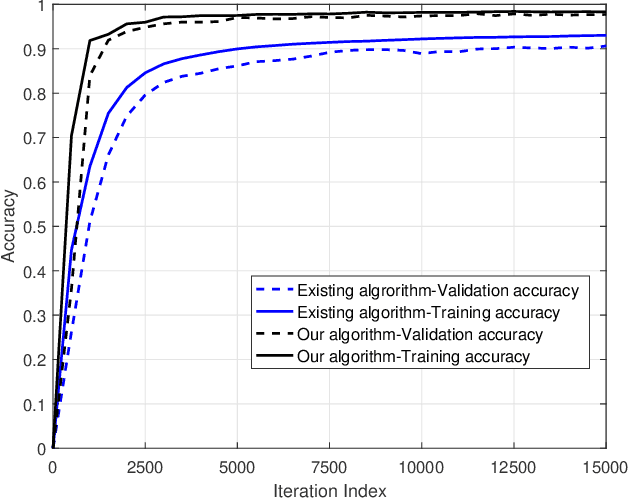
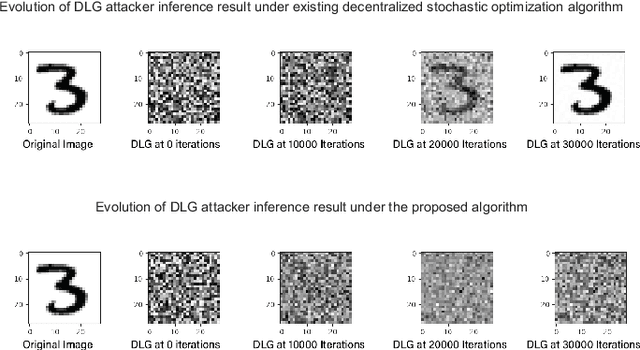
By enabling multiple agents to cooperatively solve a global optimization problem in the absence of a central coordinator, decentralized stochastic optimization is gaining increasing attention in areas as diverse as machine learning, control, and sensor networks. Since the associated data usually contain sensitive information, such as user locations and personal identities, privacy protection has emerged as a crucial need in the implementation of decentralized stochastic optimization. In this paper, we propose a decentralized stochastic optimization algorithm that is able to guarantee provable convergence accuracy even in the presence of aggressive quantization errors that are proportional to the amplitude of quantization inputs. The result applies to both convex and non-convex objective functions, and enables us to exploit aggressive quantization schemes to obfuscate shared information, and hence enables privacy protection without losing provable optimization accuracy. In fact, by using a {stochastic} ternary quantization scheme, which quantizes any value to three numerical levels, we achieve quantization-based rigorous differential privacy in decentralized stochastic optimization, which has not been reported before. In combination with the presented quantization scheme, the proposed algorithm ensures, for the first time, rigorous differential privacy in decentralized stochastic optimization without losing provable convergence accuracy. Simulation results for a distributed estimation problem as well as numerical experiments for decentralized learning on a benchmark machine learning dataset confirm the effectiveness of the proposed approach.
The use of deep learning enables high diagnostic accuracy in detecting syndesmotic instability on weight-bearing CT scanning
Jul 07, 2022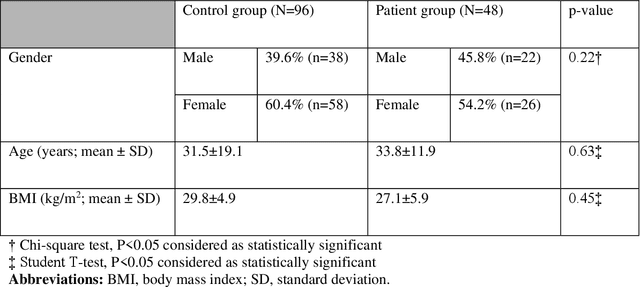

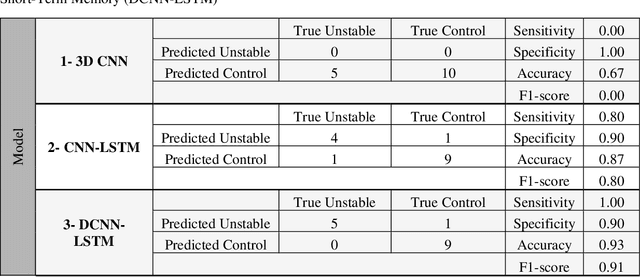

Delayed diagnosis of syndesmosis instability can lead to significant morbidity and accelerated arthritic change in the ankle joint. Weight-bearing computed tomography (WBCT) has shown promising potential for early and reliable detection of isolated syndesmotic instability using 3D volumetric measurements. While these measurements have been reported to be highly accurate, they are also experience-dependent, time-consuming, and need a particular 3D measurement software tool that leads the clinicians to still show more interest in the conventional diagnostic methods for syndesmotic instability. The purpose of this study was to increase accuracy, accelerate analysis time, and reduce inter-observer bias by automating 3D volume assessment of syndesmosis anatomy using WBCT scans. We conducted a retrospective study using previously collected WBCT scans of patients with unilateral syndesmotic instability. 144 bilateral ankle WBCT scans were evaluated (48 unstable, 96 control). We developed three deep learning (DL) models for analyzing WBCT scans to recognize syndesmosis instability. These three models included two state-of-the-art models (Model 1 - 3D convolutional neural network [CNN], and Model 2 - CNN with long short-term memory [LSTM]), and a new model (Model 3 - differential CNN LSTM) that we introduced in this study. Model 1 failed to analyze the WBCT scans (F1-score = 0). Model 2 only misclassified two cases (F1-score = 0.80). Model 3 outperformed Model 2 and achieved a nearly perfect performance, misclassifying only one case (F1-score = 0.91) in the control group as unstable while being faster than Model 2.
Memetic algorithms for Spatial Partitioning problems
Aug 04, 2022

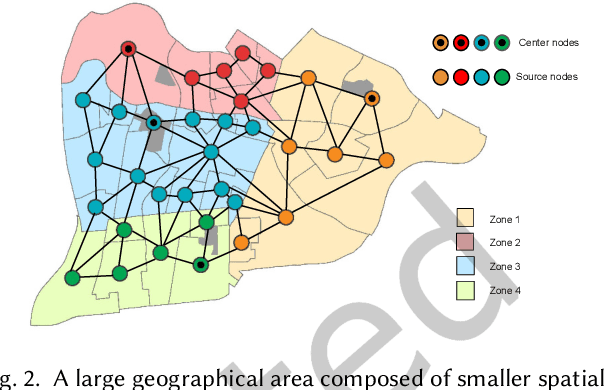
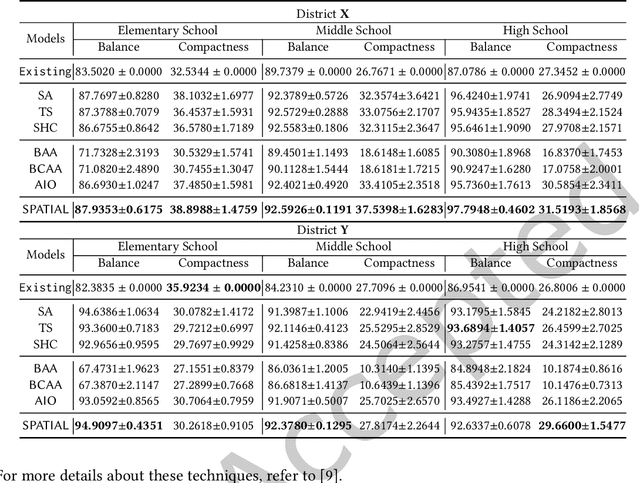
Spatial optimization problems (SOPs) are characterized by spatial relationships governing the decision variables, objectives, and/or constraint functions. In this article, we focus on a specific type of SOP called spatial partitioning, which is a combinatorial problem due to the presence of discrete spatial units. Exact optimization methods do not scale with the size of the problem, especially within practicable time limits. This motivated us to develop population-based metaheuristics for solving such SOPs. However, the search operators employed by these population-based methods are mostly designed for real-parameter continuous optimization problems. For adapting these methods to SOPs, we apply domain knowledge in designing spatially-aware search operators for efficiently searching through the discrete search space while preserving the spatial constraints. To this end, we put forward a simple yet effective algorithm called swarm-based spatial memetic algorithm (SPATIAL) and test it on the school (re)districting problem. Detailed experimental investigations are performed on real-world datasets to evaluate the performance of SPATIAL. Besides, ablation studies are performed to understand the role of the individual components of SPATIAL. Additionally, we discuss how SPATIAL~is helpful in the real-life planning process and its applicability to different scenarios and motivate future research directions.
Improved Multiple-Image-Based Reflection Removal Algorithm Using Deep Neural Networks
Aug 10, 2022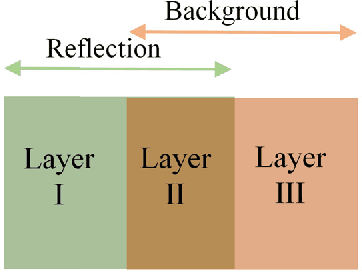

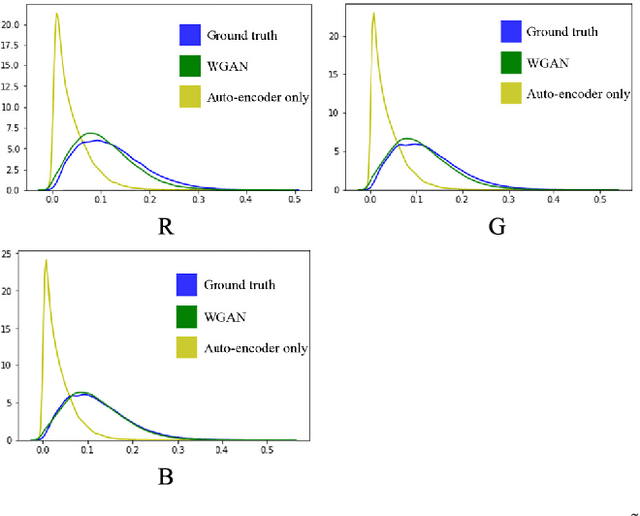

When imaging through a semi-reflective medium such as glass, the reflection of another scene can often be found in the captured images. It degrades the quality of the images and affects their subsequent analyses. In this paper, a novel deep neural network approach for solving the reflection problem in imaging is presented. Traditional reflection removal methods not only require long computation time for solving different optimization functions, their performance is also not guaranteed. As array cameras are readily available in nowadays imaging devices, we first suggest in this paper a multiple-image based depth estimation method using a convolutional neural network (CNN). The proposed network avoids the depth ambiguity problem due to the reflection in the image, and directly estimates the depths along the image edges. They are then used to classify the edges as belonging to the background or reflection. Since edges having similar depth values are error prone in the classification, they are removed from the reflection removal process. We suggest a generative adversarial network (GAN) to regenerate the removed background edges. Finally, the estimated background edge map is fed to another auto-encoder network to assist the extraction of the background from the original image. Experimental results show that the proposed reflection removal algorithm achieves superior performance both quantitatively and qualitatively as compared to the state-of-the-art methods. The proposed algorithm also shows much faster speed compared to the existing approaches using the traditional optimization methods.