 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning Spatiotemporal Frequency-Transformer for Compressed Video Super-Resolution
Aug 05, 2022

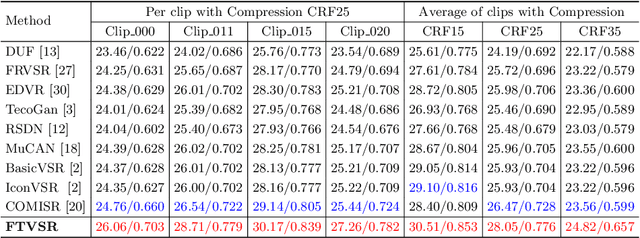
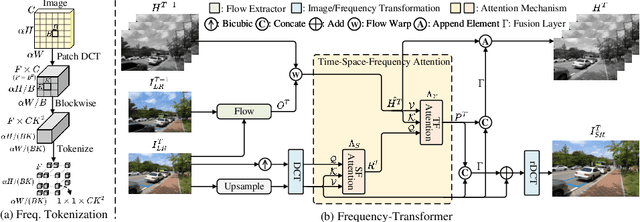
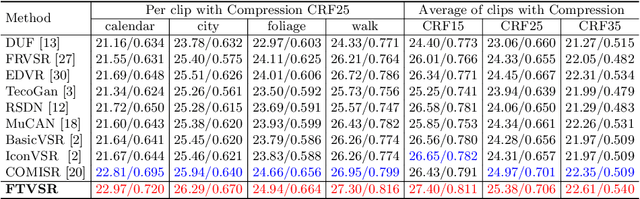
Compressed video super-resolution (VSR) aims to restore high-resolution frames from compressed low-resolution counterparts. Most recent VSR approaches often enhance an input frame by borrowing relevant textures from neighboring video frames. Although some progress has been made, there are grand challenges to effectively extract and transfer high-quality textures from compressed videos where most frames are usually highly degraded. In this paper, we propose a novel Frequency-Transformer for compressed video super-resolution (FTVSR) that conducts self-attention over a joint space-time-frequency domain. First, we divide a video frame into patches, and transform each patch into DCT spectral maps in which each channel represents a frequency band. Such a design enables a fine-grained level self-attention on each frequency band, so that real visual texture can be distinguished from artifacts, and further utilized for video frame restoration. Second, we study different self-attention schemes, and discover that a divided attention which conducts a joint space-frequency attention before applying temporal attention on each frequency band, leads to the best video enhancement quality. Experimental results on two widely-used video super-resolution benchmarks show that FTVSR outperforms state-of-the-art approaches on both uncompressed and compressed videos with clear visual margins. Code is available at https://github.com/researchmm/FTVSR.
Sharing pattern submodels for prediction with missing values
Jun 22, 2022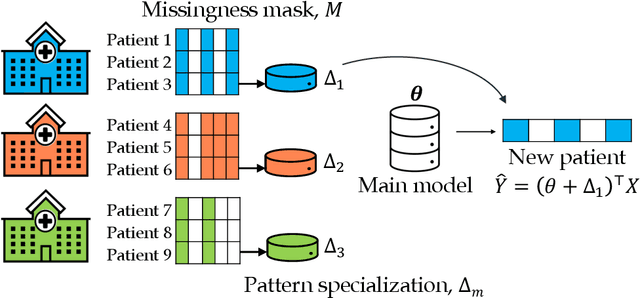
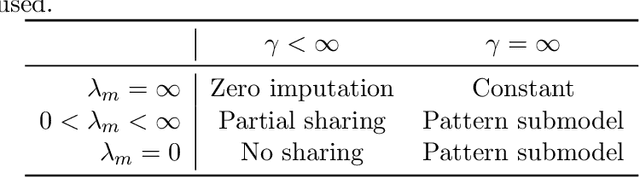
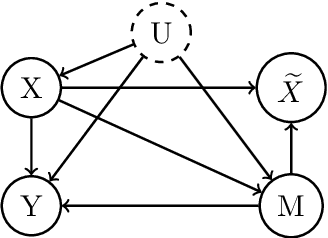
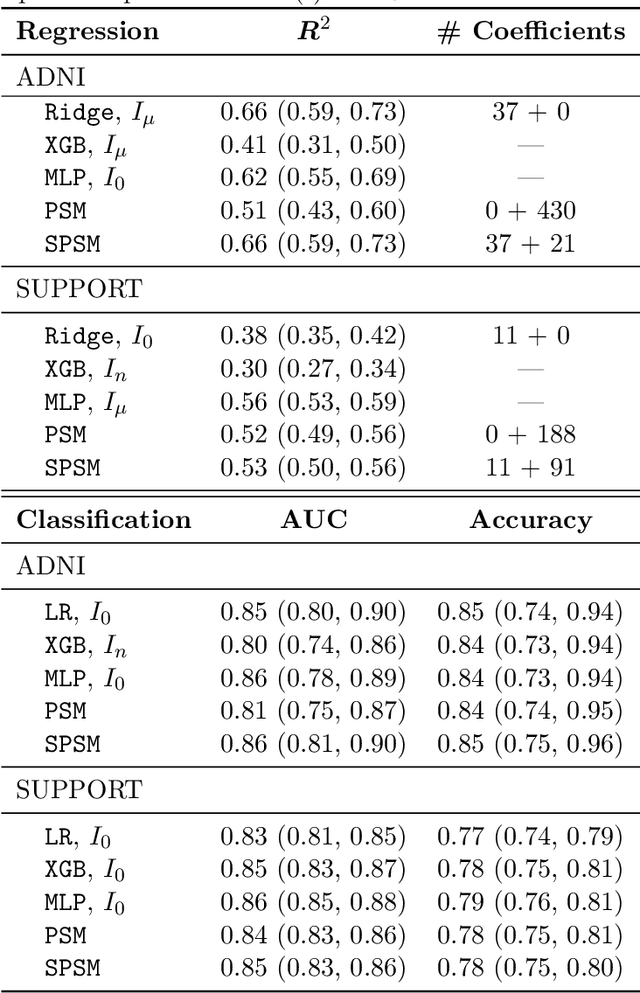
Missing values are unavoidable in many applications of machine learning and present a challenge both during training and at test time. When variables are missing in recurring patterns, fitting separate pattern submodels have been proposed as a solution. However, independent models do not make efficient use of all available data. Conversely, fitting a shared model to the full data set typically relies on imputation which may be suboptimal when missingness depends on unobserved factors. We propose an alternative approach, called sharing pattern submodels, which make predictions that are a) robust to missing values at test time, b) maintains or improves the predictive power of pattern submodels, and c) has a short description enabling improved interpretability. We identify cases where sharing is provably optimal, even when missingness itself is predictive and when the prediction target depends on unobserved variables. Classification and regression experiments on synthetic data and two healthcare data sets demonstrate that our models achieve a favorable trade-off between pattern specialization and information sharing.
The Problem of Semantic Shift in Longitudinal Monitoring of Social Media: A Case Study on Mental Health During the COVID-19 Pandemic
Jun 22, 2022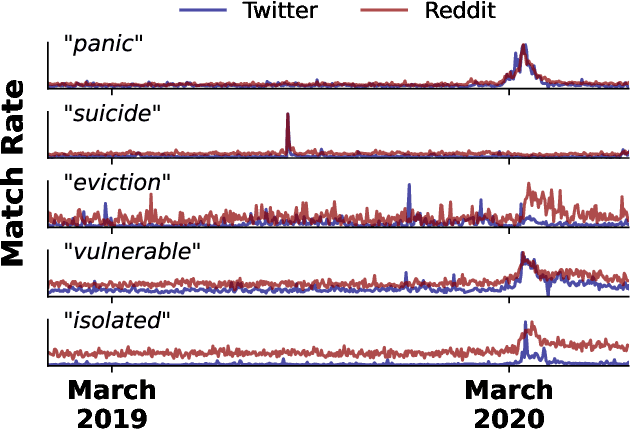
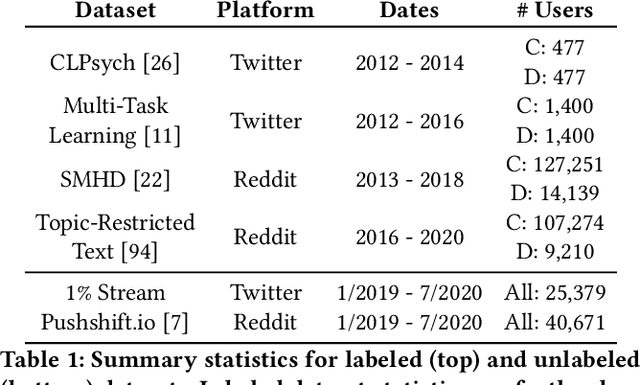
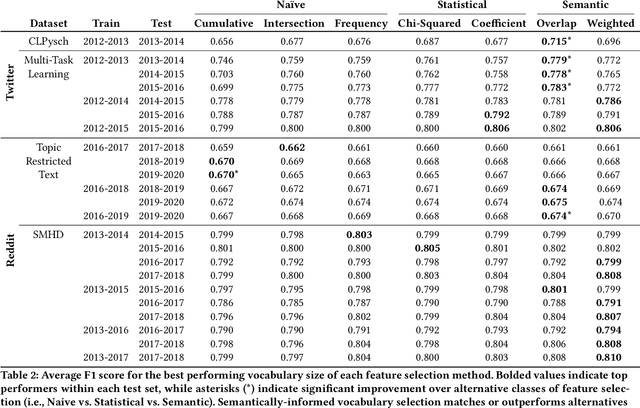
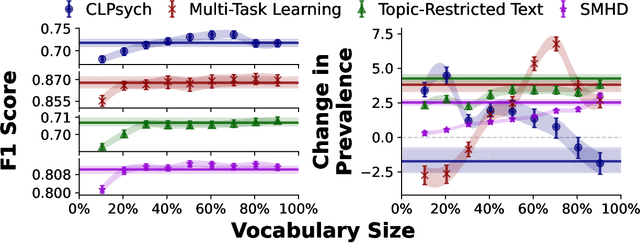
Social media allows researchers to track societal and cultural changes over time based on language analysis tools. Many of these tools rely on statistical algorithms which need to be tuned to specific types of language. Recent studies have shown the absence of appropriate tuning, specifically in the presence of semantic shift, can hinder robustness of the underlying methods. However, little is known about the practical effect this sensitivity may have on downstream longitudinal analyses. We explore this gap in the literature through a timely case study: understanding shifts in depression during the course of the COVID-19 pandemic. We find that inclusion of only a small number of semantically-unstable features can promote significant changes in longitudinal estimates of our target outcome. At the same time, we demonstrate that a recently-introduced method for measuring semantic shift may be used to proactively identify failure points of language-based models and, in turn, improve predictive generalization.
MusicNet: Compact Convolutional Neural Network for Real-time Background Music Detection
Oct 08, 2021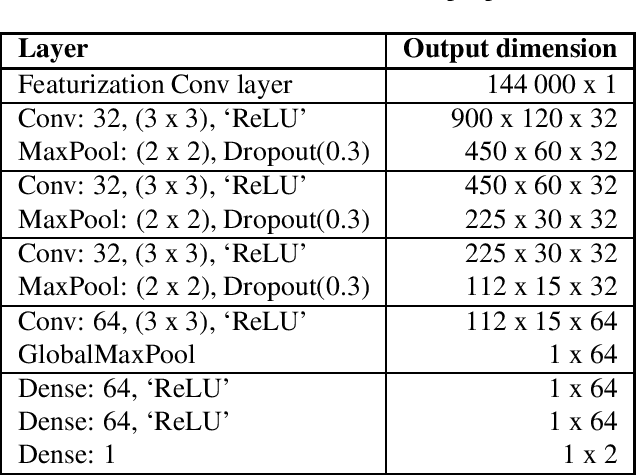
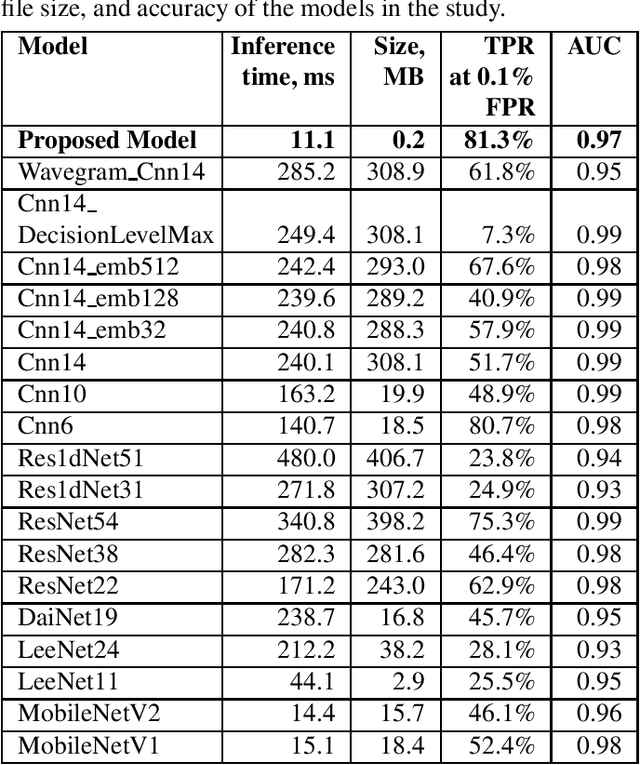
With the recent growth of remote and hybrid work, online meetings often encounter challenging audio contexts such as background noise, music, and echo. Accurate real-time detection of music events can help to improve the user experience in such scenarios, e.g., by switching to high-fidelity music-specific codec or selecting the optimal noise suppression model. In this paper, we present MusicNet -- a compact high-performance model for detecting background music in the real-time communications pipeline. In online video meetings, which is our main use case, music almost always co-occurs with speech and background noises, making the accurate classification quite challenging. The proposed model is a binary classifier that consists of a compact convolutional neural network core preceded by an in-model featurization layer. It takes 9 seconds of raw audio as input and does not require any model-specific featurization on the client. We train our model on a balanced subset of the AudioSet data and use 1000 crowd-sourced real test clips to validate the model. Finally, we compare MusicNet performance to 20 other state-of-the-art models. Our classifier gives a true positive rate of 81.3% at a 0.1% false positive rate, which is significantly better than any other model in the study. Our model is also 10x smaller and has 4x faster inference than the comparable baseline.
Two Heads are Better than One: Robust Learning Meets Multi-branch Models
Aug 17, 2022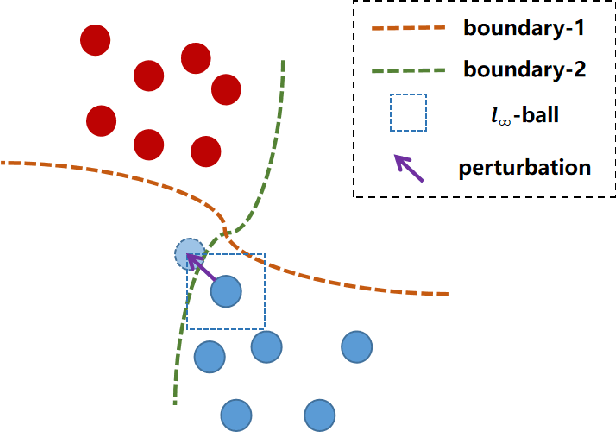
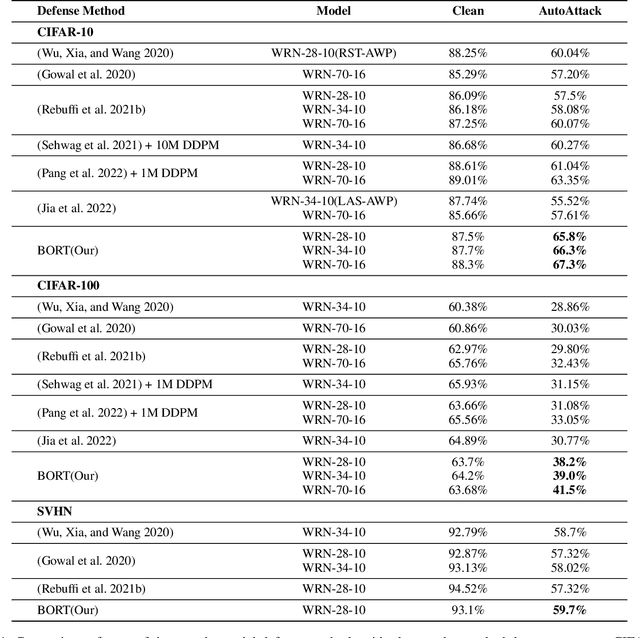
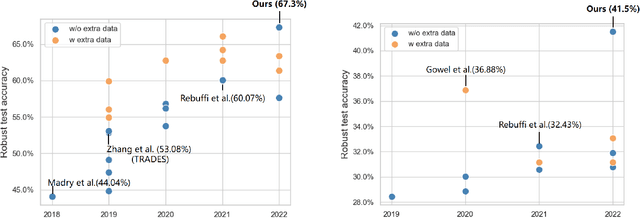
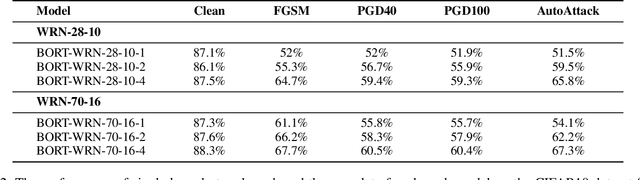
Deep neural networks (DNNs) are vulnerable to adversarial examples, in which DNNs are misled to false outputs due to inputs containing imperceptible perturbations. Adversarial training, a reliable and effective method of defense, may significantly reduce the vulnerability of neural networks and becomes the de facto standard for robust learning. While many recent works practice the data-centric philosophy, such as how to generate better adversarial examples or use generative models to produce additional training data, we look back to the models themselves and revisit the adversarial robustness from the perspective of deep feature distribution as an insightful complementarity. In this paper, we propose Branch Orthogonality adveRsarial Training (BORT) to obtain state-of-the-art performance with solely the original dataset for adversarial training. To practice our design idea of integrating multiple orthogonal solution spaces, we leverage a simple and straightforward multi-branch neural network that eclipses adversarial attacks with no increase in inference time. We heuristically propose a corresponding loss function, branch-orthogonal loss, to make each solution space of the multi-branch model orthogonal. We evaluate our approach on CIFAR-10, CIFAR-100, and SVHN against \ell_{\infty} norm-bounded perturbations of size \epsilon = 8/255, respectively. Exhaustive experiments are conducted to show that our method goes beyond all state-of-the-art methods without any tricks. Compared to all methods that do not use additional data for training, our models achieve 67.3% and 41.5% robust accuracy on CIFAR-10 and CIFAR-100 (improving upon the state-of-the-art by +7.23% and +9.07%). We also outperform methods using a training set with a far larger scale than ours. All our models and codes are available online at https://github.com/huangd1999/BORT.
Towards Smart City Security: Violence and Weaponized Violence Detection using DCNN
Jul 26, 2022
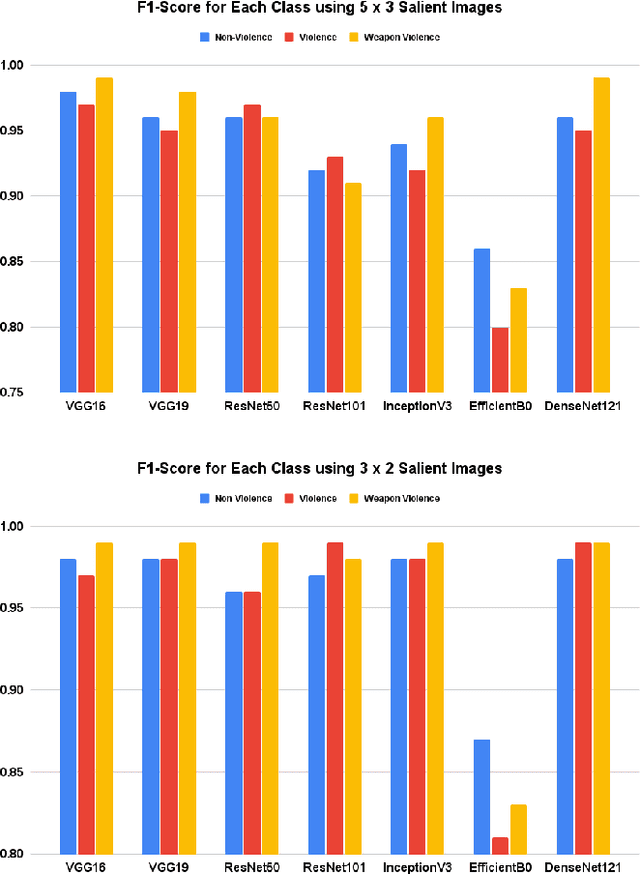


In this ever connected society, CCTVs have had a pivotal role in enforcing safety and security of the citizens by recording unlawful activities for the authorities to take actions. In a smart city context, using Deep Convolutional Neural Networks (DCNN) to detection violence and weaponized violence from CCTV videos will provide an additional layer of security by ensuring real-time detection around the clock. In this work, we introduced a new specialised dataset by gathering real CCTV footage of both weaponized and non-weaponized violence as well as non-violence videos from YouTube. We also proposed a novel approach in merging consecutive video frames into a single salient image which will then be the input to the DCNN. Results from multiple DCNN architectures have proven the effectiveness of our method by having the highest accuracy of 99\%. We also take into consideration the efficiency of our methods through several parameter trade-offs to ensure smart city sustainability.
InfiniteNature-Zero: Learning Perpetual View Generation of Natural Scenes from Single Images
Jul 22, 2022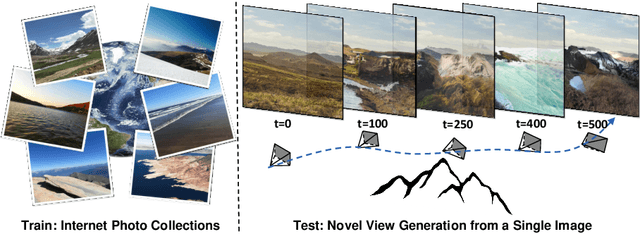
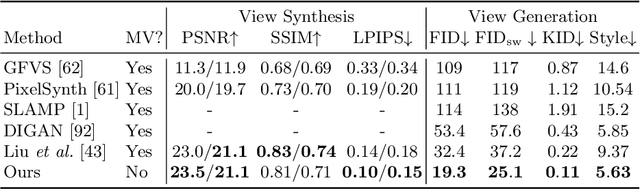
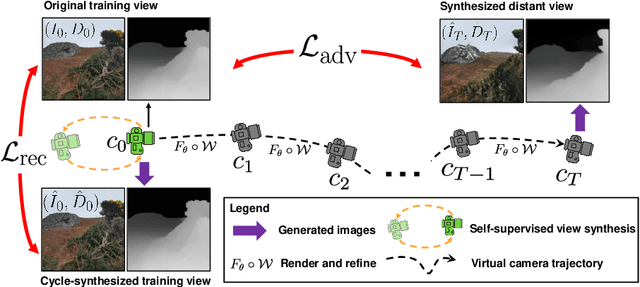
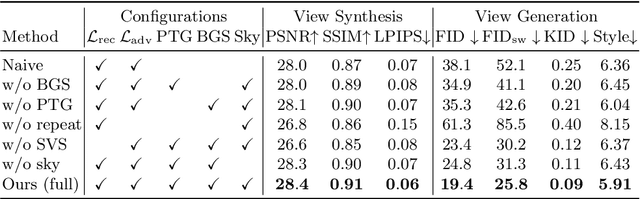
We present a method for learning to generate unbounded flythrough videos of natural scenes starting from a single view, where this capability is learned from a collection of single photographs, without requiring camera poses or even multiple views of each scene. To achieve this, we propose a novel self-supervised view generation training paradigm, where we sample and rendering virtual camera trajectories, including cyclic ones, allowing our model to learn stable view generation from a collection of single views. At test time, despite never seeing a video during training, our approach can take a single image and generate long camera trajectories comprised of hundreds of new views with realistic and diverse content. We compare our approach with recent state-of-the-art supervised view generation methods that require posed multi-view videos and demonstrate superior performance and synthesis quality.
Answer Fast: Accelerating BERT on the Tensor Streaming Processor
Jun 22, 2022
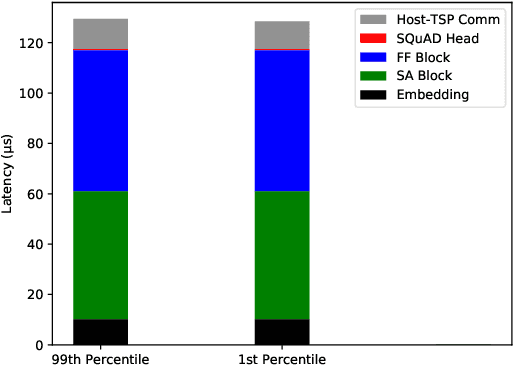
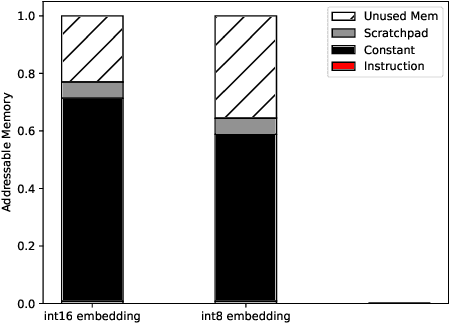

Transformers have become a predominant machine learning workload, they are not only the de-facto standard for natural language processing tasks, but they are also being deployed in other domains such as vision and speech recognition. Many of the transformer-based applications are real-time systems such as machine translation and web search. These real time systems often come with strict end-to-end inference latency requirements. Unfortunately, while the majority of the transformer computation comes from matrix multiplications, transformers also include several non-linear components that tend to become the bottleneck during an inference. In this work, we accelerate the inference of BERT models on the tensor streaming processor. By carefully fusing all the nonlinear components with the matrix multiplication components, we are able to efficiently utilize the on-chip matrix multiplication units resulting in a deterministic tail latency of 130 $\mu$s for a batch-1 inference through BERT-base, which is 6X faster than the current state-of-the-art.
Label-Guided Auxiliary Training Improves 3D Object Detector
Jul 24, 2022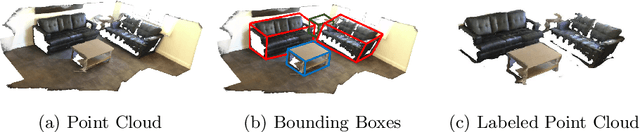
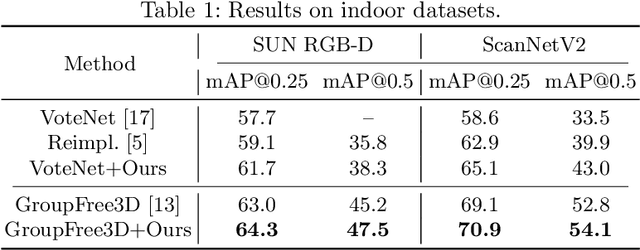
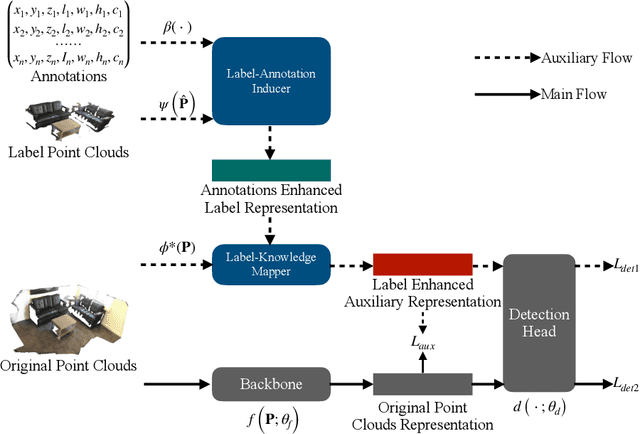
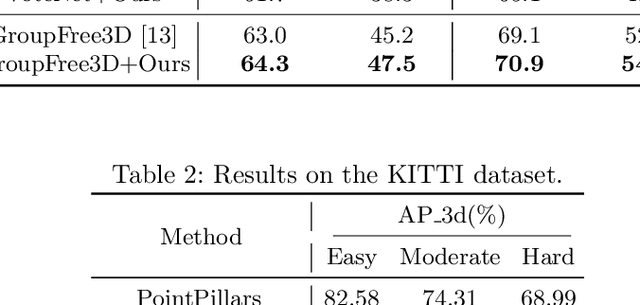
Detecting 3D objects from point clouds is a practical yet challenging task that has attracted increasing attention recently. In this paper, we propose a Label-Guided auxiliary training method for 3D object detection (LG3D), which serves as an auxiliary network to enhance the feature learning of existing 3D object detectors. Specifically, we propose two novel modules: a Label-Annotation-Inducer that maps annotations and point clouds in bounding boxes to task-specific representations and a Label-Knowledge-Mapper that assists the original features to obtain detection-critical representations. The proposed auxiliary network is discarded in inference and thus has no extra computational cost at test time. We conduct extensive experiments on both indoor and outdoor datasets to verify the effectiveness of our approach. For example, our proposed LG3D improves VoteNet by 2.5% and 3.1% mAP on the SUN RGB-D and ScanNetV2 datasets, respectively.
Location Sensing and Beamforming Design for IRS-Enabled Multi-User ISAC Systems
Aug 10, 2022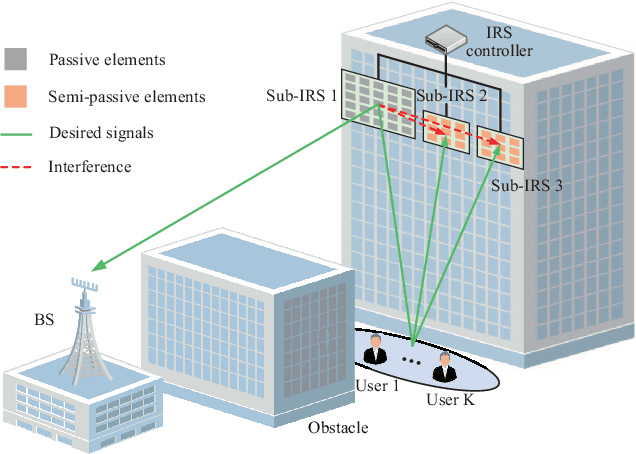
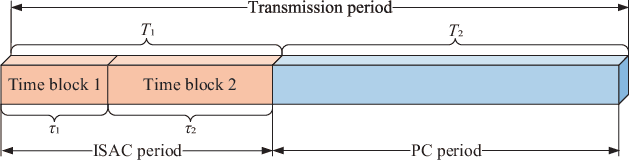
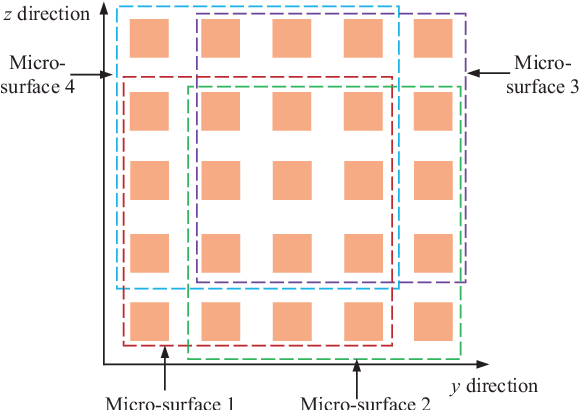
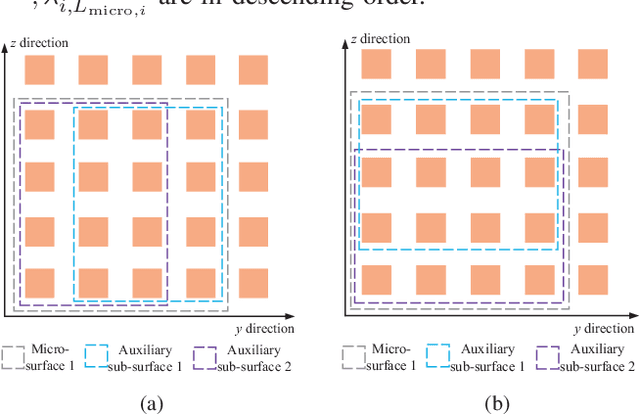
This paper explores the potential of the intelligent reflecting surface (IRS) in realizing multi-user concurrent communication and localization, using the same time-frequency resources. Specifically, we propose an IRS-enabled multi-user integrated sensing and communication (ISAC) framework, where a distributed semi-passive IRS assists the uplink data transmission from multiple users to the base station (BS) and conducts multi-user localization, simultaneously. We first design an ISAC transmission protocol, where the whole transmission period consists of two periods, i.e., the ISAC period for simultaneous uplink communication and multi-user localization, and the pure communication (PC) period for only uplink data transmission. For the ISAC period, we propose a multi-user location sensing algorithm, which utilizes the uplink communication signals unknown to the IRS, thus removing the requirement of dedicated positioning reference signals in conventional location sensing methods. Based on the sensed users' locations, we propose two novel beamforming algorithms for the ISAC period and PC period, respectively, which can work with discrete phase shifts and require no channel state information (CSI) acquisition. Numerical results show that the proposed multi-user location sensing algorithm can achieve up to millimeter-level positioning accuracy, indicating the advantage of the IRS-enabled ISAC framework. Moreover, the proposed beamforming algorithms with sensed location information and discrete phase shifts can achieve comparable performance to the benchmark considering perfect CSI acquisition and continuous phase shifts, demonstrating how the location information can ensure the communication performance.