 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Augmented Driver Behavior Models for High-Fidelity Simulation Study of Crash Detection Algorithms
Aug 10, 2022
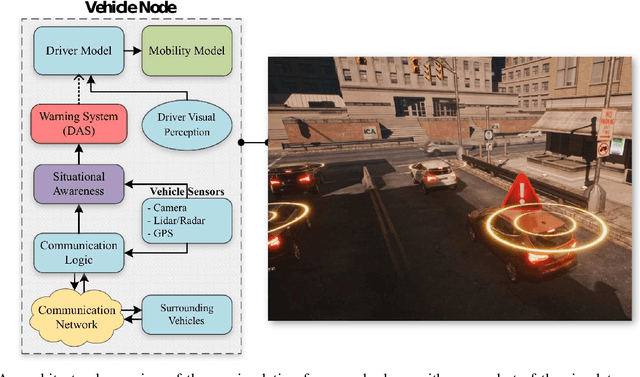
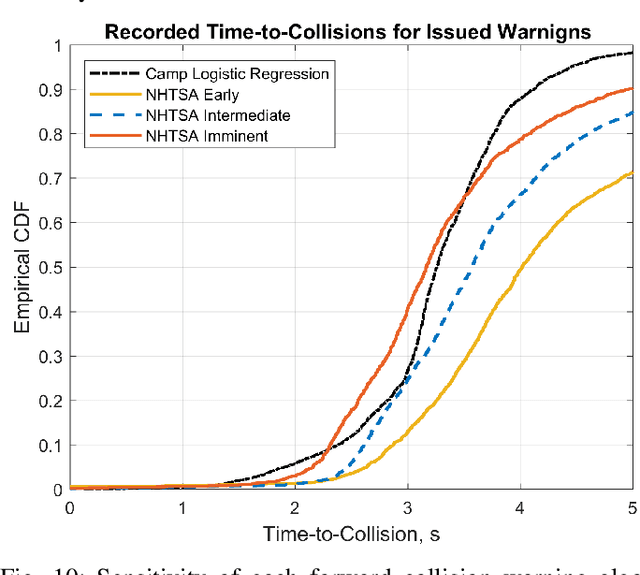
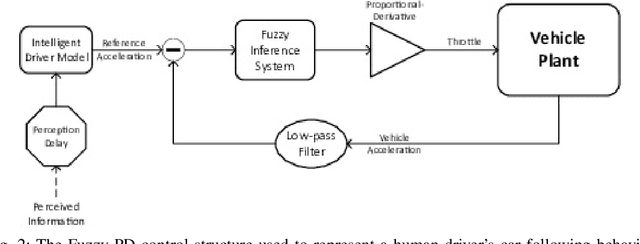
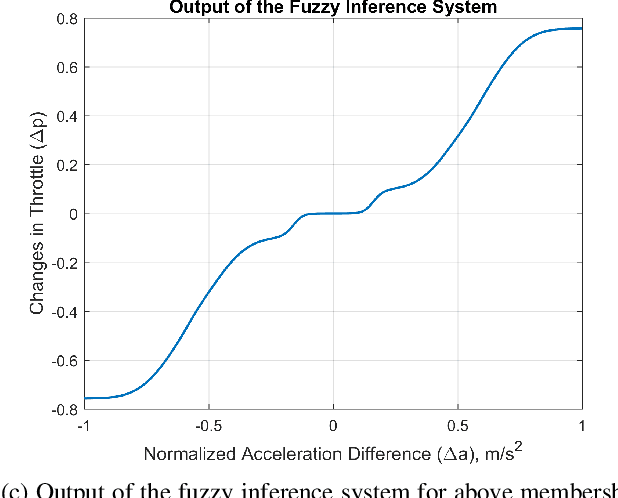
Developing safety and efficiency applications for Connected and Automated Vehicles (CAVs) require a great deal of testing and evaluation. The need for the operation of these systems in critical and dangerous situations makes the burden of their evaluation very costly, possibly dangerous, and time-consuming. As an alternative, researchers attempt to study and evaluate their algorithms and designs using simulation platforms. Modeling the behavior of drivers or human operators in CAVs or other vehicles interacting with them is one of the main challenges of such simulations. While developing a perfect model for human behavior is a challenging task and an open problem, we present a significant augmentation of the current models used in simulators for driver behavior. In this paper, we present a simulation platform for a hybrid transportation system that includes both human-driven and automated vehicles. In addition, we decompose the human driving task and offer a modular approach to simulating a large-scale traffic scenario, allowing for a thorough investigation of automated and active safety systems. Such representation through Interconnected modules offers a human-interpretable system that can be tuned to represent different classes of drivers. Additionally, we analyze a large driving dataset to extract expressive parameters that would best describe different driving characteristics. Finally, we recreate a similarly dense traffic scenario within our simulator and conduct a thorough analysis of various human-specific and system-specific factors, studying their effect on traffic network performance and safety.
Time-Frequency Localization Using Deep Convolutional Maxout Neural Network in Persian Speech Recognition
Aug 09, 2021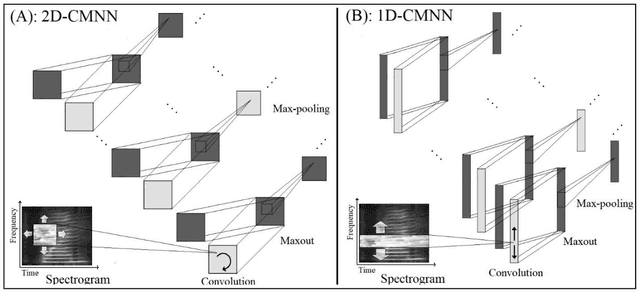
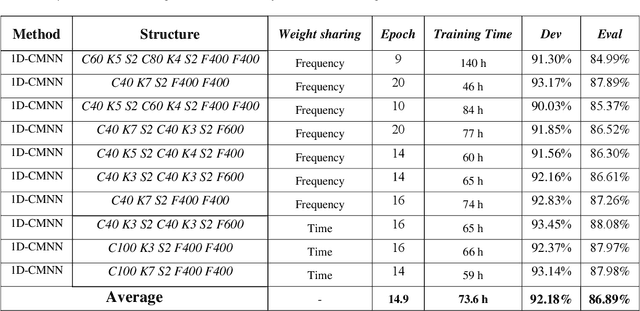
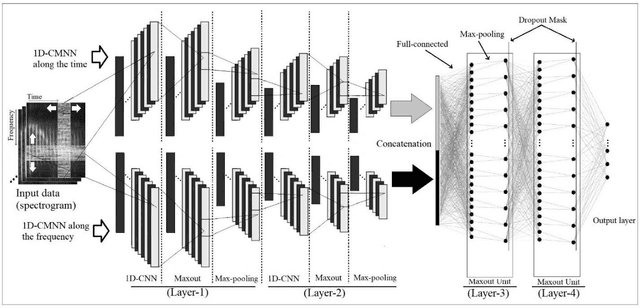
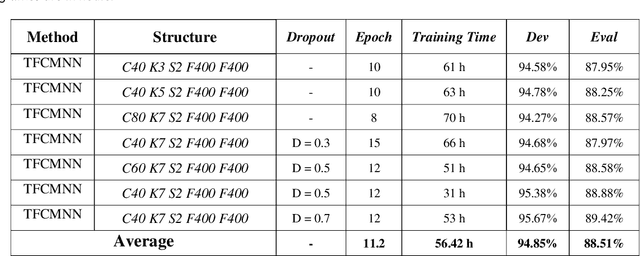
In this paper, a CNN-based structure for time-frequency localization of audio signal information in the ASR acoustic model is proposed for Persian speech recognition. Research has shown that the receptive fields' time-frequency flexibility in some mammals' auditory neurons system improves recognition performance. Biosystems have inspired many artificial systems because of their high efficiency and performance, so time-frequency localization has been used extensively to improve system performance. In the last few years, much work has been done to localize time-frequency information in ASR systems, which has used the spatial immutability properties of methods such as TDNN, CNN and LSTM-RNN. However, most of these models have large parameter volumes and are challenging to train. In the structure we have designed, called Time-Frequency Convolutional Maxout Neural Network (TFCMNN), two parallel blocks consisting of 1D-CMNN each have weight sharing in one dimension, are applied simultaneously but independently to the feature vectors. Then their output is concatenated and applied to a fully connected Maxout network for classification. To improve the performance of this structure, we have used newly developed methods and models such as the maxout, Dropout, and weight normalization. Two experimental sets were designed and implemented on the Persian FARSDAT speech data set to evaluate the performance of this model compared to conventional 1D-CMNN models. According to the experimental results, the average recognition score of TFCMNN models is about 1.6% higher than the average of conventional models. In addition, the average training time of the TFCMNN models is about 17 hours lower than the average training time of traditional models. As a result, as mentioned in other references, time-frequency localization in ASR systems increases system accuracy and speeds up the model training process.
Analysis and Design of Quadratic Neural Networks for Regression, Classification, and Lyapunov Control of Dynamical Systems
Jul 26, 2022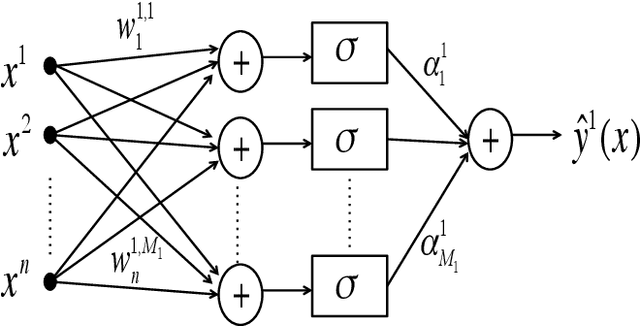
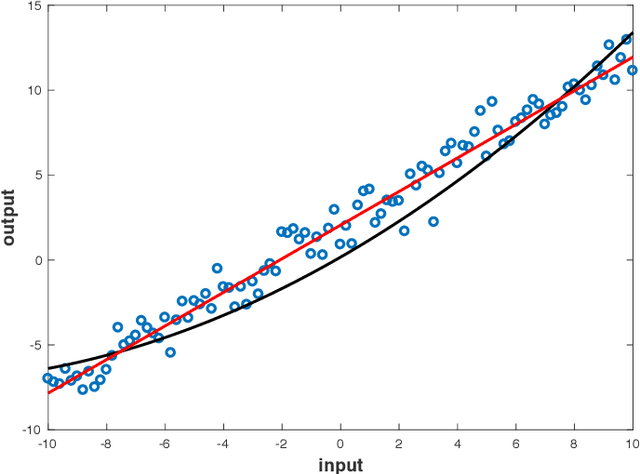
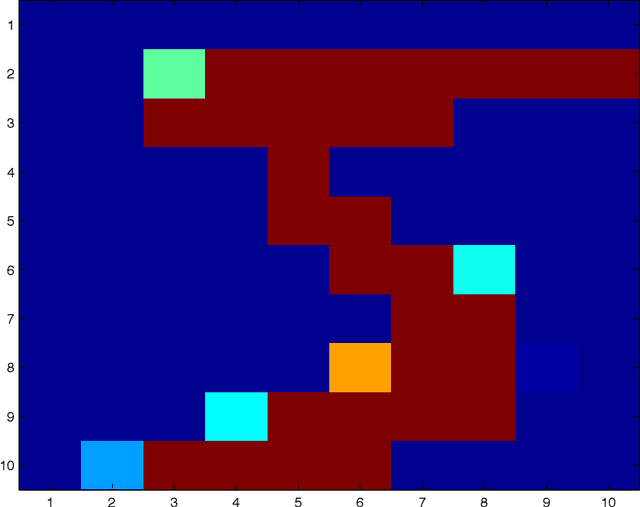
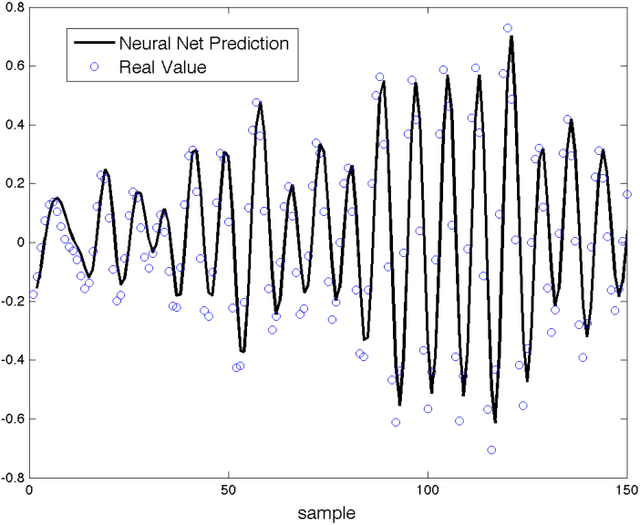
This paper addresses the analysis and design of quadratic neural networks, which have been recently introduced in the literature, and their applications to regression, classification, system identification and control of dynamical systems. These networks offer several advantages, the most important of which are the fact that the architecture is a by-product of the design and is not determined a-priori, their training can be done by solving a convex optimization problem so that the global optimum of the weights is achieved, and the input-output mapping can be expressed analytically by a quadratic form. It also appears from several examples that these networks work extremely well using only a small fraction of the training data. The results in the paper cast regression, classification, system identification, stability and control design as convex optimization problems, which can be solved efficiently with polynomial-time algorithms to a global optimum. Several examples will show the effectiveness of quadratic neural networks in applications.
On the Limitations of Continual Learning for Malware Classification
Aug 13, 2022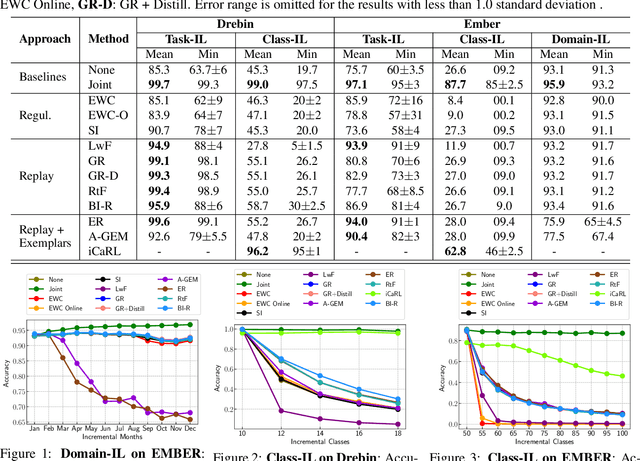
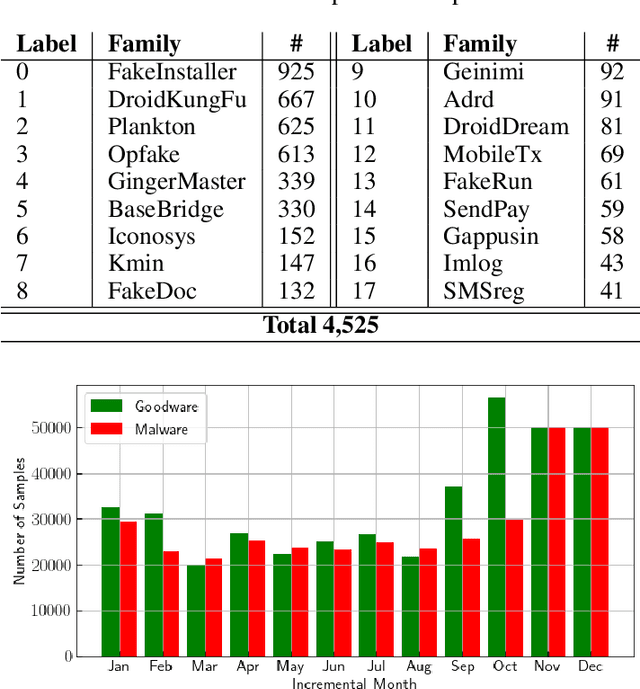
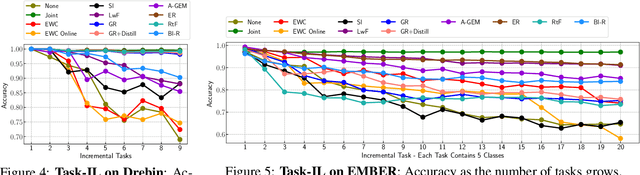
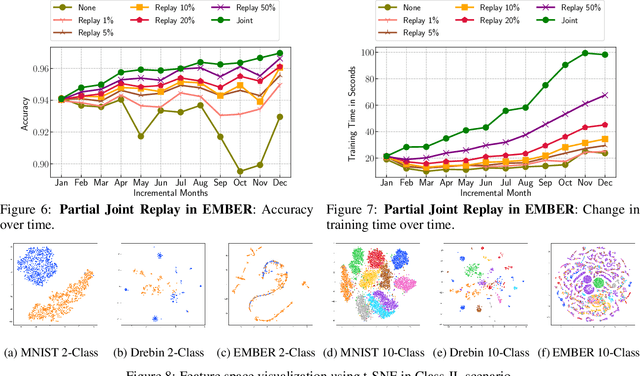
Malicious software (malware) classification offers a unique challenge for continual learning (CL) regimes due to the volume of new samples received on a daily basis and the evolution of malware to exploit new vulnerabilities. On a typical day, antivirus vendors receive hundreds of thousands of unique pieces of software, both malicious and benign, and over the course of the lifetime of a malware classifier, more than a billion samples can easily accumulate. Given the scale of the problem, sequential training using continual learning techniques could provide substantial benefits in reducing training and storage overhead. To date, however, there has been no exploration of CL applied to malware classification tasks. In this paper, we study 11 CL techniques applied to three malware tasks covering common incremental learning scenarios, including task, class, and domain incremental learning (IL). Specifically, using two realistic, large-scale malware datasets, we evaluate the performance of the CL methods on both binary malware classification (Domain-IL) and multi-class malware family classification (Task-IL and Class-IL) tasks. To our surprise, continual learning methods significantly underperformed naive Joint replay of the training data in nearly all settings -- in some cases reducing accuracy by more than 70 percentage points. A simple approach of selectively replaying 20% of the stored data achieves better performance, with 50% of the training time compared to Joint replay. Finally, we discuss potential reasons for the unexpectedly poor performance of the CL techniques, with the hope that it spurs further research on developing techniques that are more effective in the malware classification domain.
MusicNet: Compact Convolutional Neural Network for Real-time Background Music Detection
Oct 08, 2021
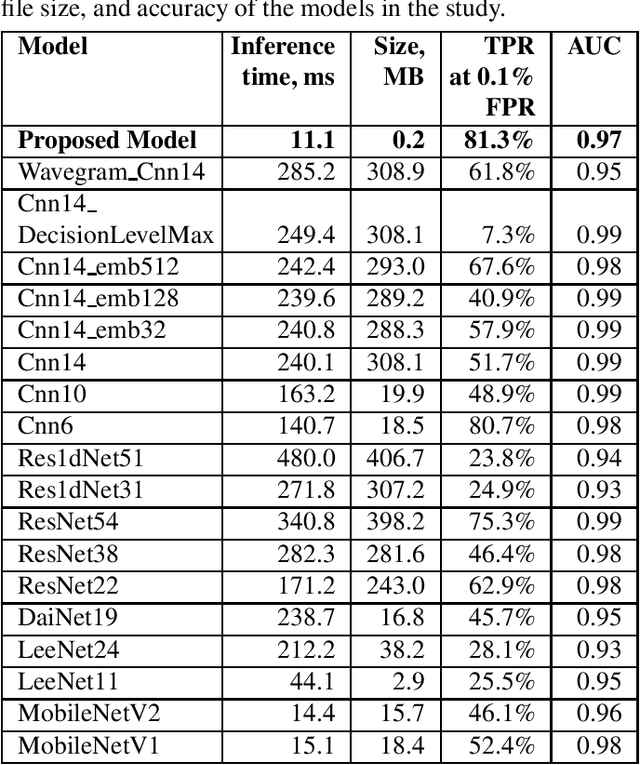
With the recent growth of remote and hybrid work, online meetings often encounter challenging audio contexts such as background noise, music, and echo. Accurate real-time detection of music events can help to improve the user experience in such scenarios, e.g., by switching to high-fidelity music-specific codec or selecting the optimal noise suppression model. In this paper, we present MusicNet -- a compact high-performance model for detecting background music in the real-time communications pipeline. In online video meetings, which is our main use case, music almost always co-occurs with speech and background noises, making the accurate classification quite challenging. The proposed model is a binary classifier that consists of a compact convolutional neural network core preceded by an in-model featurization layer. It takes 9 seconds of raw audio as input and does not require any model-specific featurization on the client. We train our model on a balanced subset of the AudioSet data and use 1000 crowd-sourced real test clips to validate the model. Finally, we compare MusicNet performance to 20 other state-of-the-art models. Our classifier gives a true positive rate of 81.3% at a 0.1% false positive rate, which is significantly better than any other model in the study. Our model is also 10x smaller and has 4x faster inference than the comparable baseline.
Efficient High-Resolution Deep Learning: A Survey
Jul 26, 2022
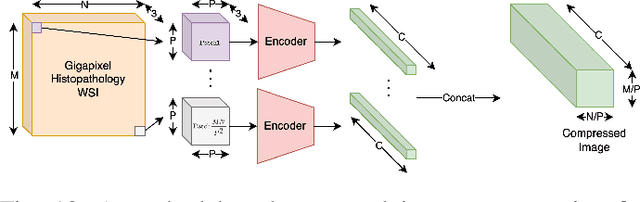
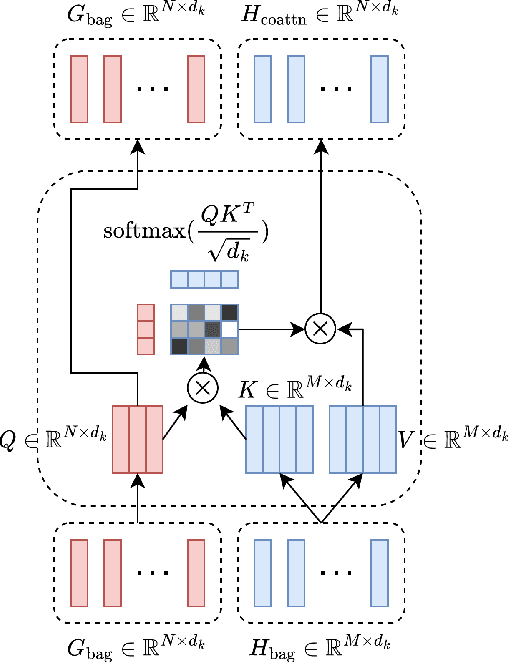

Cameras in modern devices such as smartphones, satellites and medical equipment are capable of capturing very high resolution images and videos. Such high-resolution data often need to be processed by deep learning models for cancer detection, automated road navigation, weather prediction, surveillance, optimizing agricultural processes and many other applications. Using high-resolution images and videos as direct inputs for deep learning models creates many challenges due to their high number of parameters, computation cost, inference latency and GPU memory consumption. Simple approaches such as resizing the images to a lower resolution are common in the literature, however, they typically significantly decrease accuracy. Several works in the literature propose better alternatives in order to deal with the challenges of high-resolution data and improve accuracy and speed while complying with hardware limitations and time restrictions. This survey describes such efficient high-resolution deep learning methods, summarizes real-world applications of high-resolution deep learning, and provides comprehensive information about available high-resolution datasets.
Learning Time Series from Scale Information
Mar 18, 2021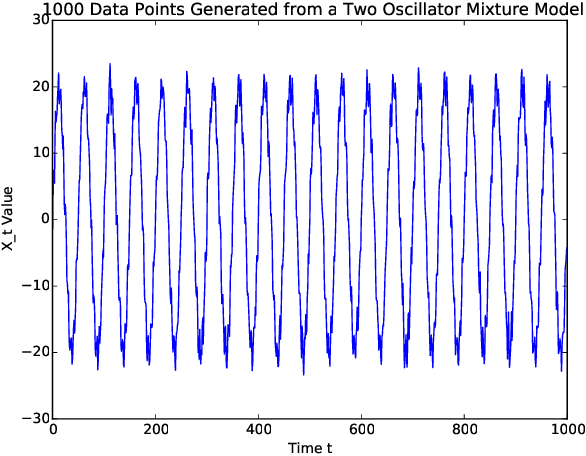
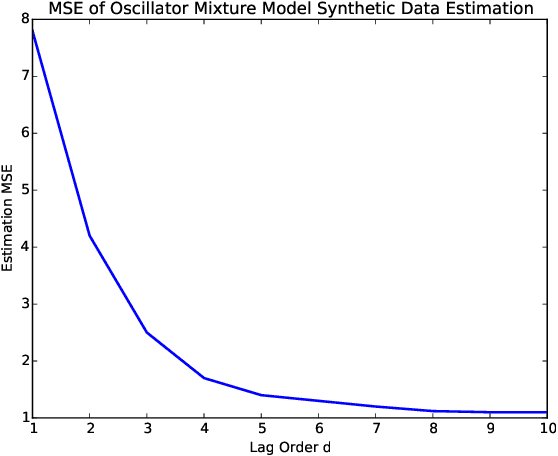
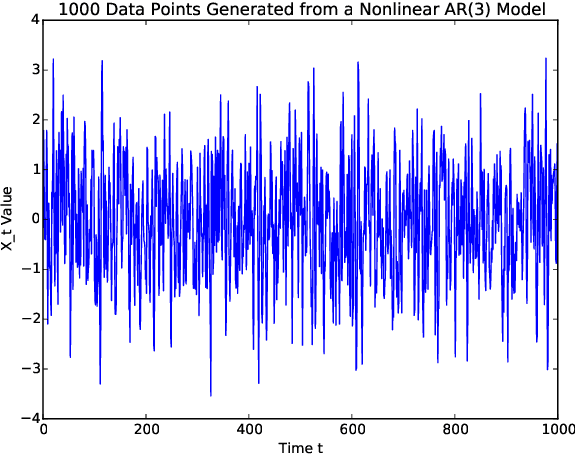
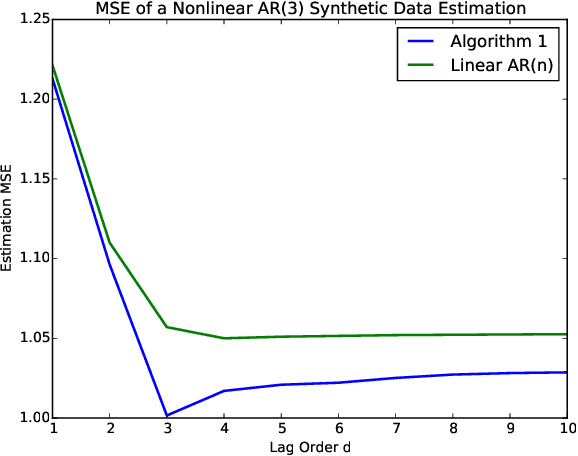
Sequentially obtained dataset usually exhibits different behavior at different data resolutions/scales. Instead of inferring from data at each scale individually, it is often more informative to interpret the data as an ensemble of time series from different scales. This naturally motivated us to propose a new concept referred to as the scale-based inference. The basic idea is that more accurate prediction can be made by exploiting scale information of a time series. We first propose a nonparametric predictor based on $k$-nearest neighbors with an optimally chosen $k$ for a single time series. Based on that, we focus on a specific but important type of scale information, the resolution/sampling rate of time series data. We then propose an algorithm to sequentially predict time series using past data at various resolutions. We prove that asymptotically the algorithm produces the mean prediction error that is no larger than the best possible algorithm at any single resolution, under some optimally chosen parameters. Finally, we establish the general formulations for scale inference, and provide further motivating examples. Experiments on both synthetic and real data illustrate the potential applicability of our approaches to a wide range of time series models.
Evaluation of 3D GANs for Lung Tissue Modelling in Pulmonary CT
Aug 17, 2022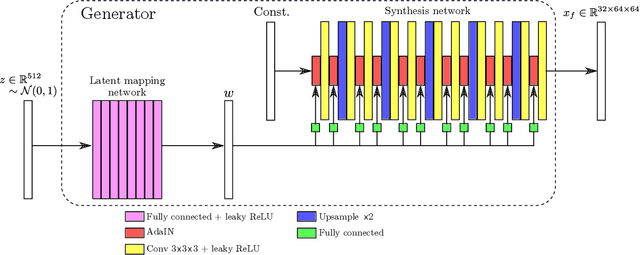
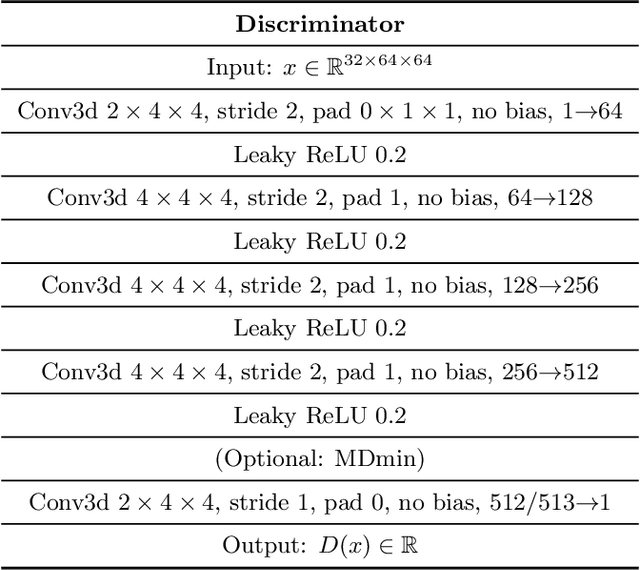
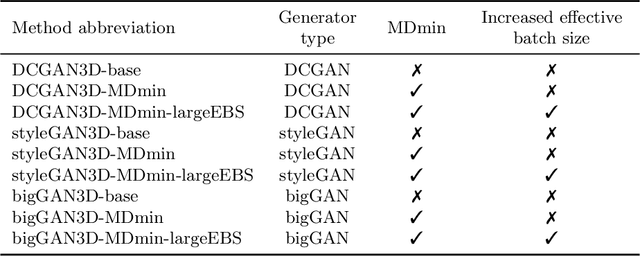

GANs are able to model accurately the distribution of complex, high-dimensional datasets, e.g. images. This makes high-quality GANs useful for unsupervised anomaly detection in medical imaging. However, differences in training datasets such as output image dimensionality and appearance of semantically meaningful features mean that GAN models from the natural image domain may not work `out-of-the-box' for medical imaging, necessitating re-implementation and re-evaluation. In this work we adapt and evaluate three GAN models to the task of modelling 3D healthy image patches for pulmonary CT. To the best of our knowledge, this is the first time that such an evaluation has been performed. The DCGAN, styleGAN and the bigGAN architectures were investigated due to their ubiquity and high performance in natural image processing. We train different variants of these methods and assess their performance using the FID score. In addition, the quality of the generated images was evaluated by a human observer study, the ability of the networks to model 3D domain-specific features was investigated, and the structure of the GAN latent spaces was analysed. Results show that the 3D styleGAN produces realistic-looking images with meaningful 3D structure, but suffer from mode collapse which must be addressed during training to obtain samples diversity. Conversely, the 3D DCGAN models show a greater capacity for image variability, but at the cost of poor-quality images. The 3D bigGAN models provide an intermediate level of image quality, but most accurately model the distribution of selected semantically meaningful features. The results suggest that future development is required to realise a 3D GAN with sufficient capacity for patch-based lung CT anomaly detection and we offer recommendations for future areas of research, such as experimenting with other architectures and incorporation of position-encoding.
Rapid Exploration of a 32.5M Compound Chemical Space with Active Learning to Discover Density Functional Approximation Insensitive and Synthetically Accessible Transitional Metal Chromophores
Aug 10, 2022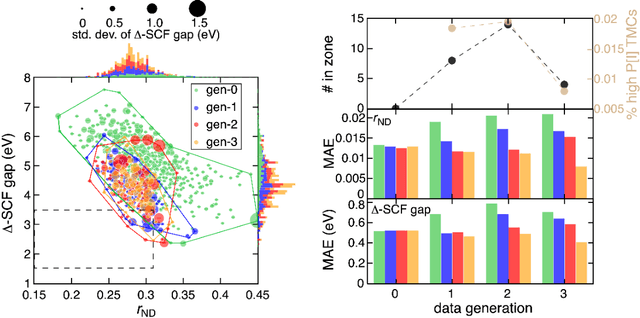
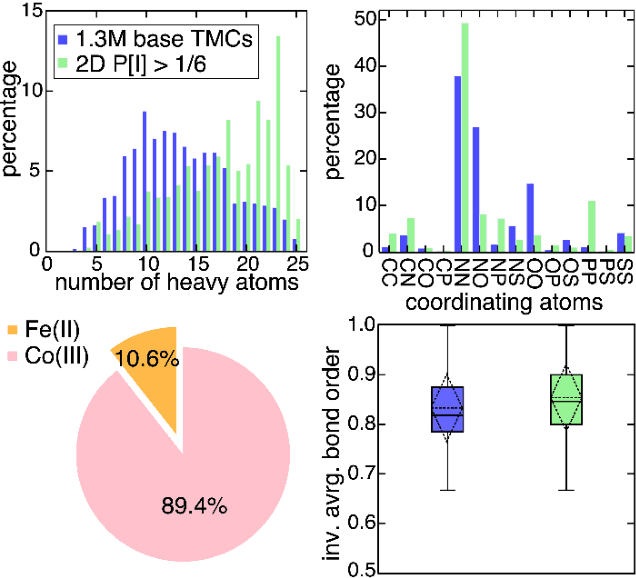
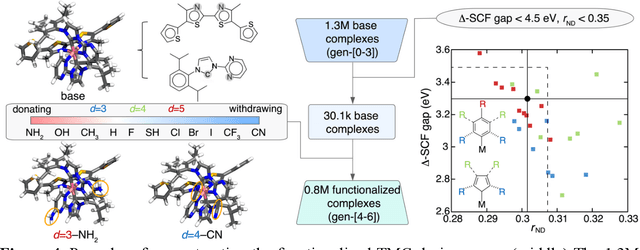
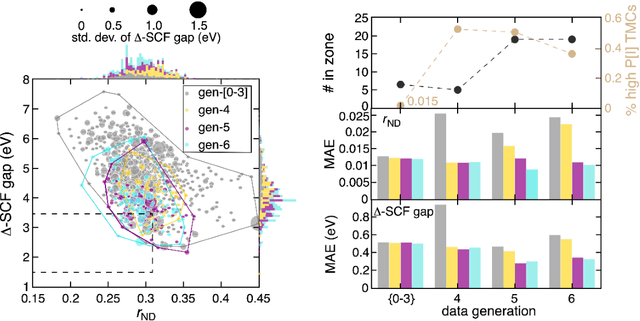
Two outstanding challenges for machine learning (ML) accelerated chemical discovery are the synthesizability of candidate molecules or materials and the fidelity of the data used in ML model training. To address the first challenge, we construct a hypothetical design space of 32.5M transition metal complexes (TMCs), in which all of the constituent fragments (i.e., metals and ligands) and ligand symmetries are synthetically accessible. To address the second challenge, we search for consensus in predictions among 23 density functional approximations across multiple rungs of Jacob's ladder. To accelerate the screening of these 32.5M TMCs, we use efficient global optimization to sample candidate low-spin chromophores that simultaneously have low absorption energies and low static correlation. Despite the scarcity (i.e., $<$ 0.01\%) of potential chromophores in this large chemical space, we identify transition metal chromophores with high likelihood (i.e., $>$ 10\%) as the ML models improve during active learning. This represents a 1,000 fold acceleration in discovery corresponding to discoveries in days instead of years. Analyses of candidate chromophores reveal a preference for Co(III) and large, strong-field ligands with more bond saturation. We compute the absorption spectra of promising chromophores on the Pareto front by time-dependent density functional theory calculations and verify that two thirds of them have desired excited state properties. Although these complexes have never been experimentally explored, their constituent ligands demonstrated interesting optical properties in literature, exemplifying the effectiveness of our construction of realistic TMC design space and active learning approach.
Global Pointer: Novel Efficient Span-based Approach for Named Entity Recognition
Aug 05, 2022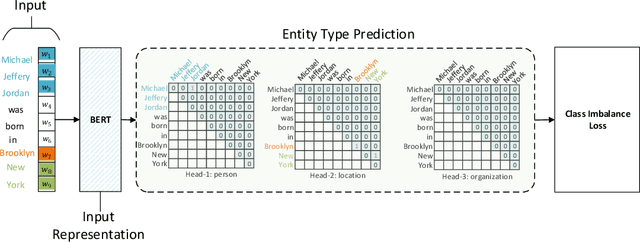
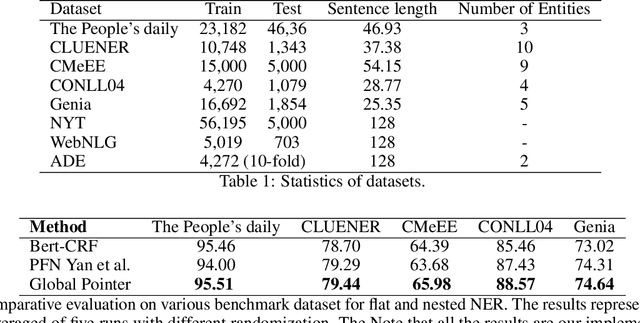
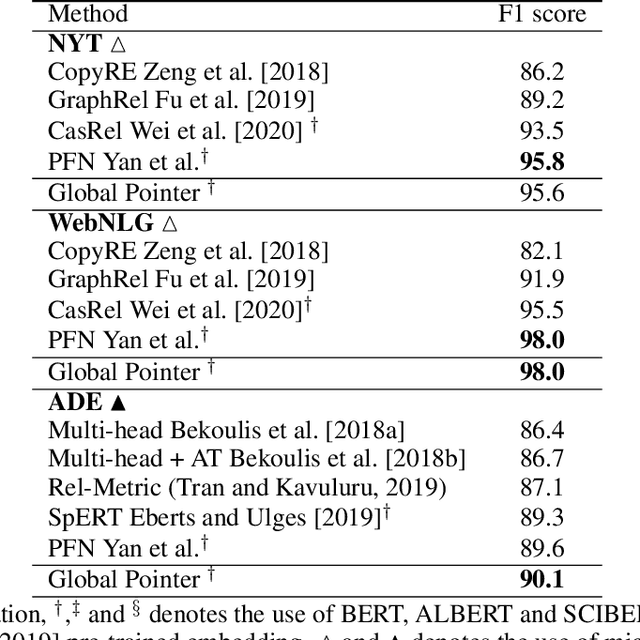

Named entity recognition (NER) task aims at identifying entities from a piece of text that belong to predefined semantic types such as person, location, organization, etc. The state-of-the-art solutions for flat entities NER commonly suffer from capturing the fine-grained semantic information in underlying texts. The existing span-based approaches overcome this limitation, but the computation time is still a concern. In this work, we propose a novel span-based NER framework, namely Global Pointer (GP), that leverages the relative positions through a multiplicative attention mechanism. The ultimate goal is to enable a global view that considers the beginning and the end positions to predict the entity. To this end, we design two modules to identify the head and the tail of a given entity to enable the inconsistency between the training and inference processes. Moreover, we introduce a novel classification loss function to address the imbalance label problem. In terms of parameters, we introduce a simple but effective approximate method to reduce the training parameters. We extensively evaluate GP on various benchmark datasets. Our extensive experiments demonstrate that GP can outperform the existing solution. Moreover, the experimental results show the efficacy of the introduced loss function compared to softmax and entropy alternatives.