 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Long Range Probabilistic Forecasting in Time-Series using High Order Statistics
Nov 05, 2021
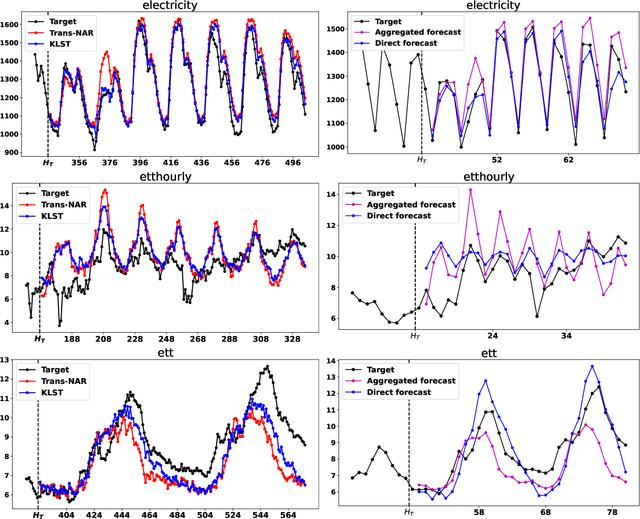
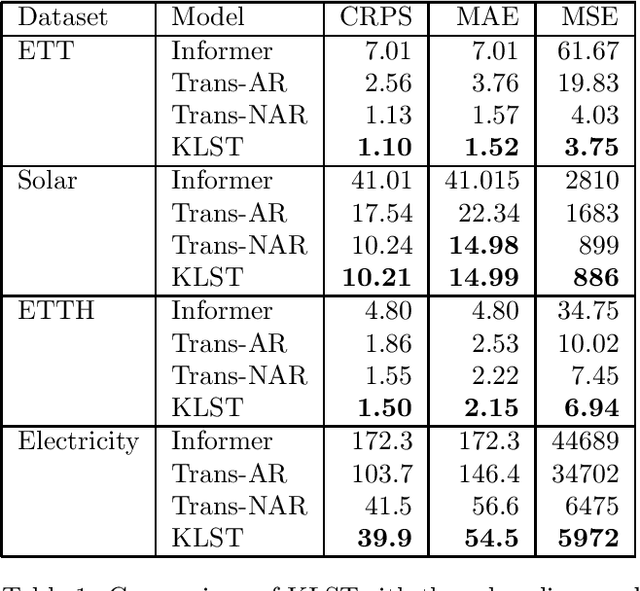
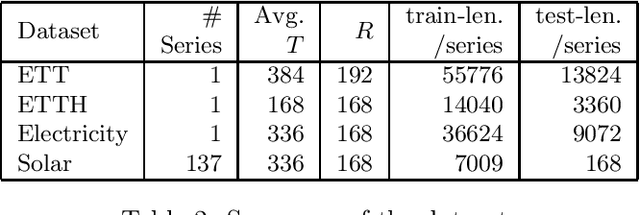
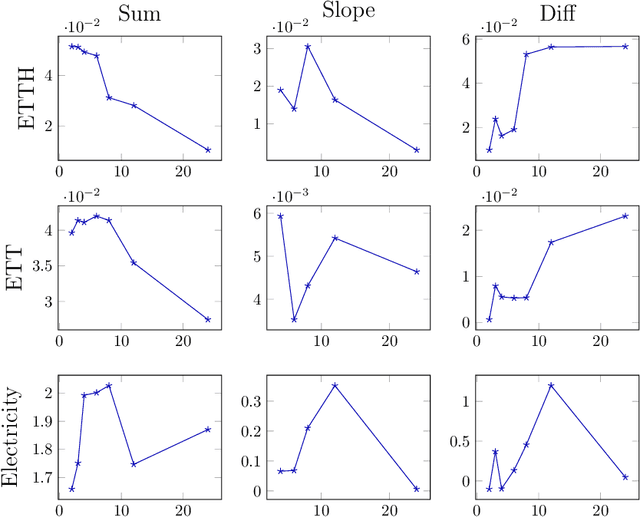
Long range forecasts are the starting point of many decision support systems that need to draw inference from high-level aggregate patterns on forecasted values. State of the art time-series forecasting methods are either subject to concept drift on long-horizon forecasts, or fail to accurately predict coherent and accurate high-level aggregates. In this work, we present a novel probabilistic forecasting method that produces forecasts that are coherent in terms of base level and predicted aggregate statistics. We achieve the coherency between predicted base-level and aggregate statistics using a novel inference method. Our inference method is based on KL-divergence and can be solved efficiently in closed form. We show that our method improves forecast performance across both base level and unseen aggregates post inference on real datasets ranging three diverse domains.
Cooperative Actor-Critic via TD Error Aggregation
Jul 25, 2022
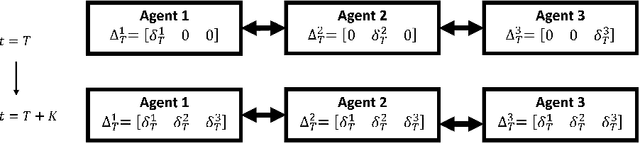
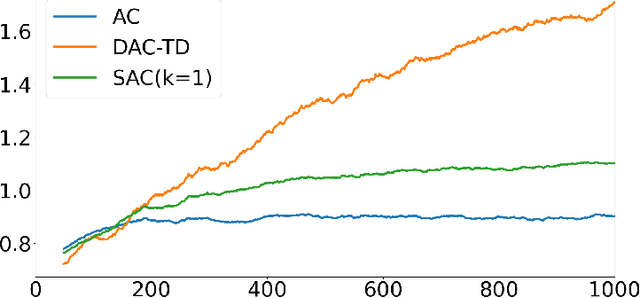
In decentralized cooperative multi-agent reinforcement learning, agents can aggregate information from one another to learn policies that maximize a team-average objective function. Despite the willingness to cooperate with others, the individual agents may find direct sharing of information about their local state, reward, and value function undesirable due to privacy issues. In this work, we introduce a decentralized actor-critic algorithm with TD error aggregation that does not violate privacy issues and assumes that communication channels are subject to time delays and packet dropouts. The cost we pay for making such weak assumptions is an increased communication burden for every agent as measured by the dimension of the transmitted data. Interestingly, the communication burden is only quadratic in the graph size, which renders the algorithm applicable in large networks. We provide a convergence analysis under diminishing step size to verify that the agents maximize the team-average objective function.
Pixel-level Correspondence for Self-Supervised Learning from Video
Jul 08, 2022
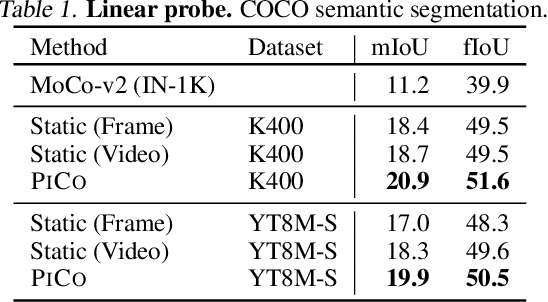


While self-supervised learning has enabled effective representation learning in the absence of labels, for vision, video remains a relatively untapped source of supervision. To address this, we propose Pixel-level Correspondence (PiCo), a method for dense contrastive learning from video. By tracking points with optical flow, we obtain a correspondence map which can be used to match local features at different points in time. We validate PiCo on standard benchmarks, outperforming self-supervised baselines on multiple dense prediction tasks, without compromising performance on image classification.
Polyphonic Sound Event Detection Using Capsule Neural Network on Multi-Type-Multi-Scale Time-Frequency Representation
Nov 25, 2021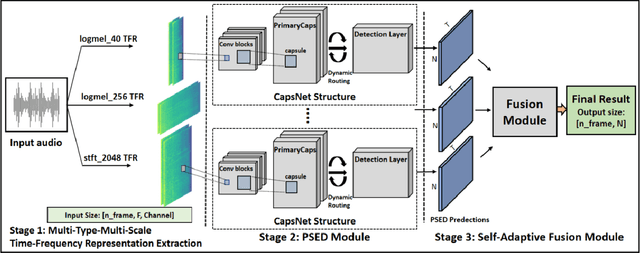
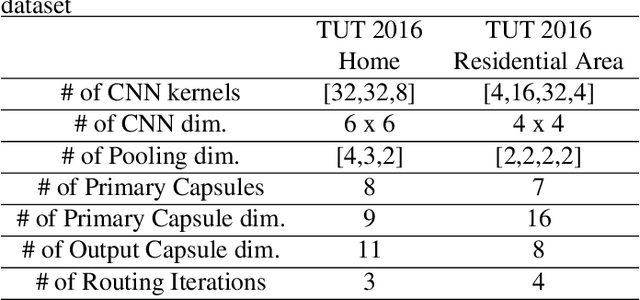
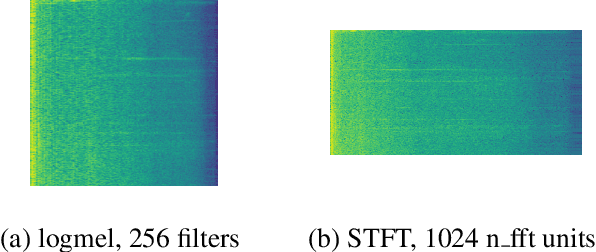
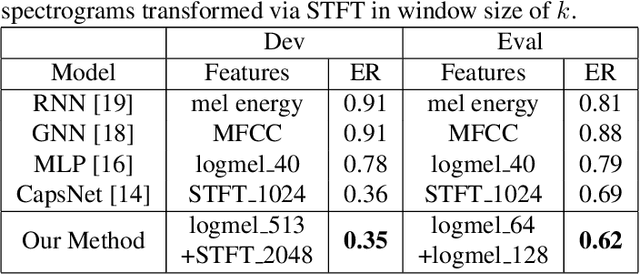
The challenges of polyphonic sound event detection (PSED) stem from the detection of multiple overlapping events in a time series. Recent efforts exploit Deep Neural Networks (DNNs) on Time-Frequency Representations (TFRs) of audio clips as model inputs to mitigate such issues. However, existing solutions often rely on a single type of TFR, which causes under-utilization of input features. To this end, we propose a novel PSED framework, which incorporates Multi-Type-Multi-Scale TFRs. Our key insight is that: TFRs, which are of different types or in different scales, can reveal acoustics patterns in a complementary manner, so that the overlapped events can be best extracted by combining different TFRs. Moreover, our framework design applies a novel approach, to adaptively fuse different models and TFRs symbiotically. Hence, the overall performance can be significantly improved. We quantitatively examine the benefits of our framework by using Capsule Neural Networks, a state-of-the-art approach for PSED. The experimental results show that our method achieves a reduction of 7\% in error rate compared with the state-of-the-art solutions on the TUT-SED 2016 dataset.
Graphical Join: A New Physical Join Algorithm for RDBMSs
Jun 22, 2022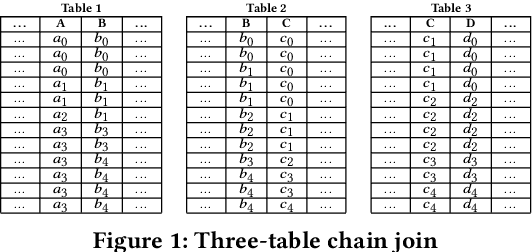

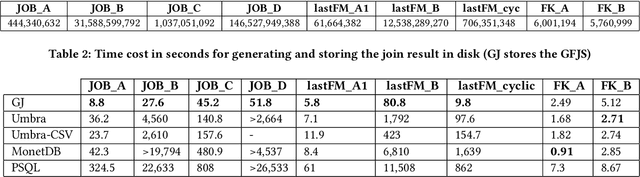
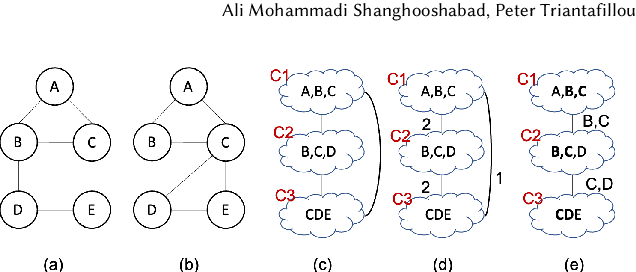
Join operations (especially n-way, many-to-many joins) are known to be time- and resource-consuming. At large scales, with respect to table and join-result sizes, current state of the art approaches (including both binary-join plans which use Nested-loop/Hash/Sort-merge Join algorithms or, alternatively, worst-case optimal join algorithms (WOJAs)), may even fail to produce any answer given reasonable resource and time constraints. In this work, we introduce a new approach for n-way equi-join processing, the Graphical Join (GJ). The key idea is two-fold: First, to map the physical join computation problem to PGMs and introduce tweaked inference algorithms which can compute a Run-Length Encoding (RLE) based join-result summary, entailing all statistics necessary to materialize the join result. Second, and most importantly, to show that a join algorithm, like GJ, which produces the above join-result summary and then desummarizes it, can introduce large performance benefits in time and space. Comprehensive experimentation is undertaken with join queries from the JOB, TPCDS, and lastFM datasets, comparing GJ against PostgresQL and MonetDB and a state of the art WOJA implemented within the Umbra system. The results for in-memory join computation show performance improvements up to 64X, 388X, and 6X faster than PostgreSQL, MonetDB and Umbra, respectively. For on-disk join computation, GJ is faster than PostgreSQL, MonetDB and Umbra by up to 820X, 717X and 165X, respectively. Furthermore, GJ space needs are up to 21,488X, 38,333X, and 78,750X smaller than PostgresQL, MonetDB, and Umbra, respectively.
Hierarchical Agglomerative Graph Clustering in Nearly-Linear Time
Jun 10, 2021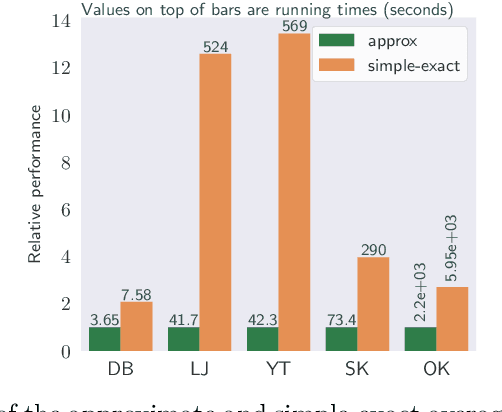

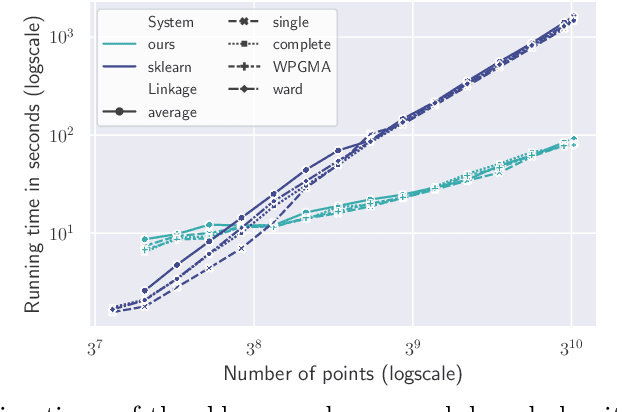
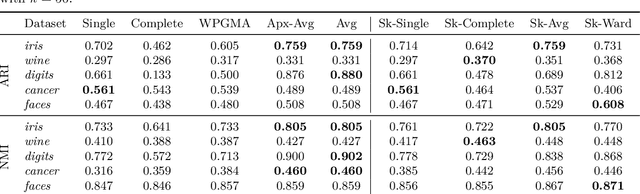
We study the widely used hierarchical agglomerative clustering (HAC) algorithm on edge-weighted graphs. We define an algorithmic framework for hierarchical agglomerative graph clustering that provides the first efficient $\tilde{O}(m)$ time exact algorithms for classic linkage measures, such as complete- and WPGMA-linkage, as well as other measures. Furthermore, for average-linkage, arguably the most popular variant of HAC, we provide an algorithm that runs in $\tilde{O}(n\sqrt{m})$ time. For this variant, this is the first exact algorithm that runs in subquadratic time, as long as $m=n^{2-\epsilon}$ for some constant $\epsilon > 0$. We complement this result with a simple $\epsilon$-close approximation algorithm for average-linkage in our framework that runs in $\tilde{O}(m)$ time. As an application of our algorithms, we consider clustering points in a metric space by first using $k$-NN to generate a graph from the point set, and then running our algorithms on the resulting weighted graph. We validate the performance of our algorithms on publicly available datasets, and show that our approach can speed up clustering of point datasets by a factor of 20.7--76.5x.
Explain My Surprise: Learning Efficient Long-Term Memory by Predicting Uncertain Outcomes
Jul 27, 2022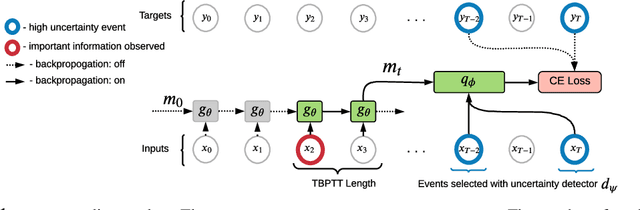
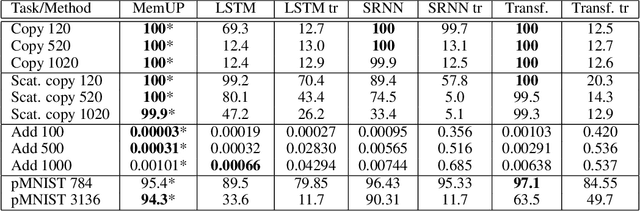
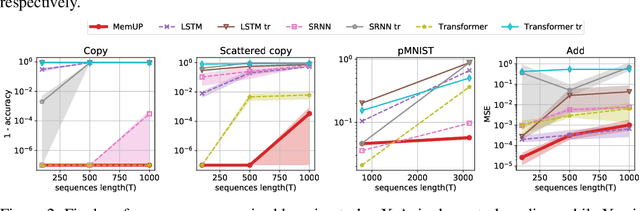
In many sequential tasks, a model needs to remember relevant events from the distant past to make correct predictions. Unfortunately, a straightforward application of gradient based training requires intermediate computations to be stored for every element of a sequence. This requires prohibitively large computing memory if a sequence consists of thousands or even millions elements, and as a result, makes learning of very long-term dependencies infeasible. However, the majority of sequence elements can usually be predicted by taking into account only temporally local information. On the other hand, predictions affected by long-term dependencies are sparse and characterized by high uncertainty given only local information. We propose MemUP, a new training method that allows to learn long-term dependencies without backpropagating gradients through the whole sequence at a time. This method can be potentially applied to any gradient based sequence learning. MemUP implementation for recurrent architectures shows performances better or comparable to baselines while requiring significantly less computing memory.
Efficient spike encoding algorithms for neuromorphic speech recognition
Jul 14, 2022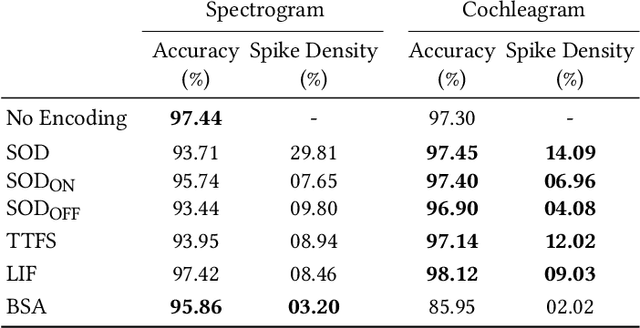
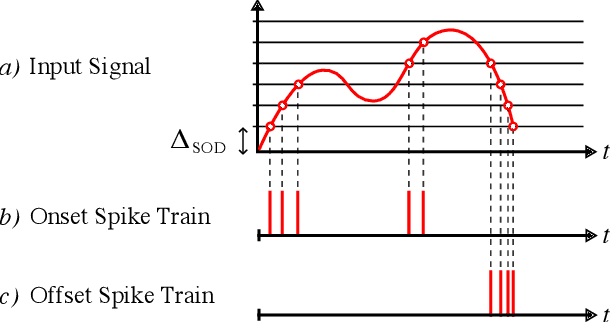

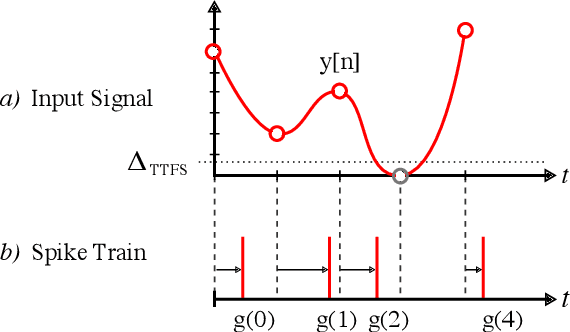
Spiking Neural Networks (SNN) are known to be very effective for neuromorphic processor implementations, achieving orders of magnitude improvements in energy efficiency and computational latency over traditional deep learning approaches. Comparable algorithmic performance was recently made possible as well with the adaptation of supervised training algorithms to the context of SNN. However, information including audio, video, and other sensor-derived data are typically encoded as real-valued signals that are not well-suited to SNN, preventing the network from leveraging spike timing information. Efficient encoding from real-valued signals to spikes is therefore critical and significantly impacts the performance of the overall system. To efficiently encode signals into spikes, both the preservation of information relevant to the task at hand as well as the density of the encoded spikes must be considered. In this paper, we study four spike encoding methods in the context of a speaker independent digit classification system: Send on Delta, Time to First Spike, Leaky Integrate and Fire Neuron and Bens Spiker Algorithm. We first show that all encoding methods yield higher classification accuracy using significantly fewer spikes when encoding a bio-inspired cochleagram as opposed to a traditional short-time Fourier transform. We then show that two Send On Delta variants result in classification results comparable with a state of the art deep convolutional neural network baseline, while simultaneously reducing the encoded bit rate. Finally, we show that several encoding methods result in improved performance over the conventional deep learning baseline in certain cases, further demonstrating the power of spike encoding algorithms in the encoding of real-valued signals and that neuromorphic implementation has the potential to outperform state of the art techniques.
Memory-augmented Adversarial Autoencoders for Multivariate Time-series Anomaly Detection with Deep Reconstruction and Prediction
Oct 15, 2021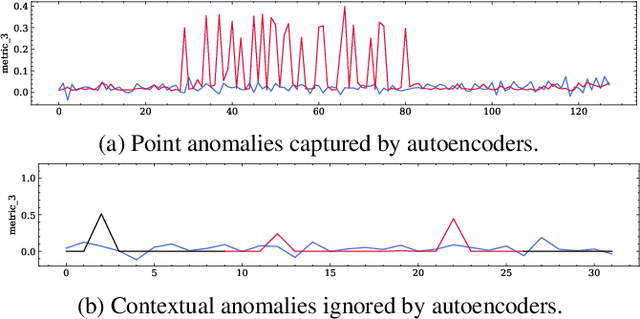
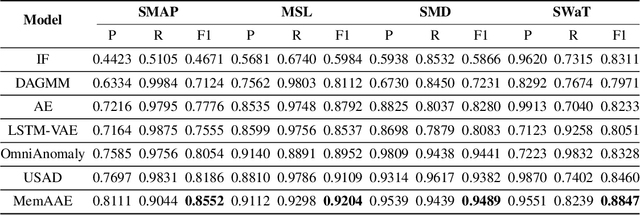
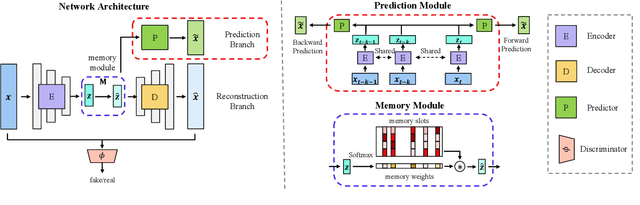
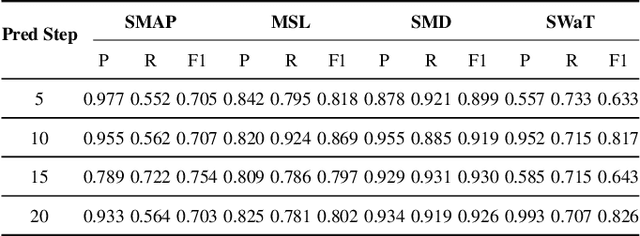
Detecting anomalies for multivariate time-series without manual supervision continues a challenging problem due to the increased scale of dimensions and complexity of today's IT monitoring systems. Recent progress of unsupervised time-series anomaly detection mainly use deep autoencoders to solve this problem, i.e. training on normal samples and producing significant reconstruction error on abnormal inputs. However, in practice, autoencoders can reconstruct anomalies so well, due to powerful capabilites of neural networks. Besides, these approaches can be ineffective for identifying non-point anomalies, e.g. contextual anomalies and collective anomalies, since they solely utilze a point-wise reconstruction objective. To tackle the above issues, we propose MemAAE (\textit{Memory-augmented Adversarial Autoencoders with Deep Reconstruction and Prediction}), a novel unsupervised anomaly detection method for time-series. By jointly training two complementary proxy tasks, reconstruction and prediction, with a shared network architecture, we show that detecting anomalies via multiple tasks obtains superior performance rather than single-task training. Additionally, a compressive memory module is introduced to preserve normal patterns, avoiding unexpected generalization on abnormal inputs. Through extensive experiments, MemAAE achieves an overall F1 score of 0.90 on four public datasets, significantly outperforming the best baseline by 0.02.
Federated Learning under Distributed Concept Drift
Jun 01, 2022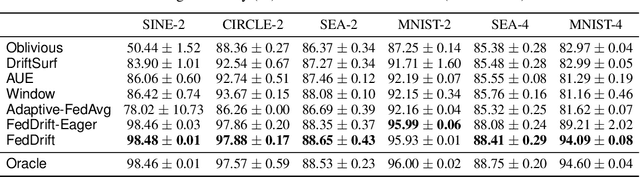


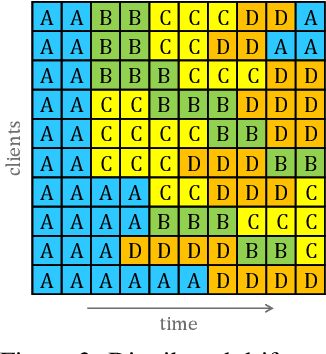
Federated Learning (FL) under distributed concept drift is a largely unexplored area. Although concept drift is itself a well-studied phenomenon, it poses particular challenges for FL, because drifts arise staggered in time and space (across clients). Our work is the first to explicitly study data heterogeneity in both dimensions. We first demonstrate that prior solutions to drift adaptation, with their single global model, are ill-suited to staggered drifts, necessitating multi-model solutions. We identify the problem of drift adaptation as a time-varying clustering problem, and we propose two new clustering algorithms for reacting to drifts based on local drift detection and hierarchical clustering. Empirical evaluation shows that our solutions achieve significantly higher accuracy than existing baselines, and are comparable to an idealized algorithm with oracle knowledge of the ground-truth clustering of clients to concepts at each time step.