 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Feature-space Multimodal Data Augmentation Technique for Text-video Retrieval
Aug 03, 2022
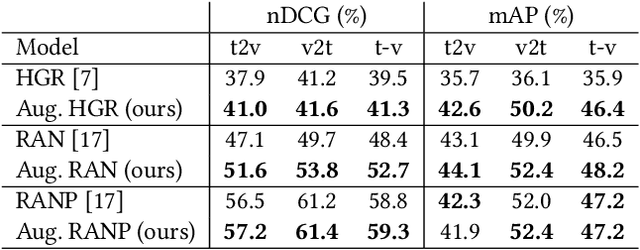

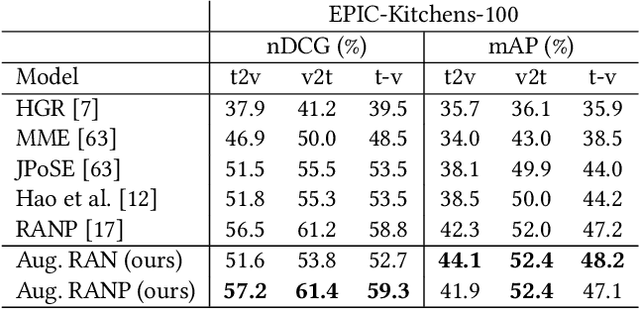
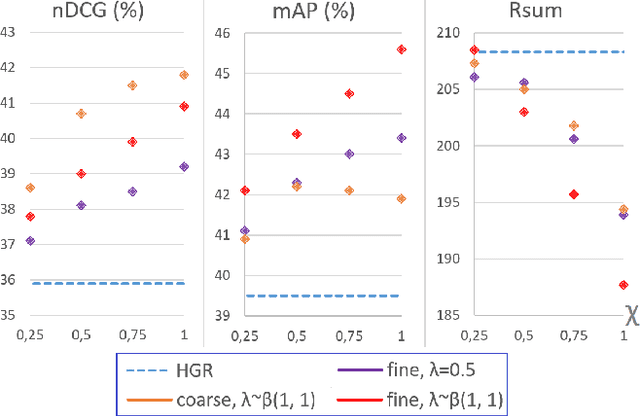
Every hour, huge amounts of visual contents are posted on social media and user-generated content platforms. To find relevant videos by means of a natural language query, text-video retrieval methods have received increased attention over the past few years. Data augmentation techniques were introduced to increase the performance on unseen test examples by creating new training samples with the application of semantics-preserving techniques, such as color space or geometric transformations on images. Yet, these techniques are usually applied on raw data, leading to more resource-demanding solutions and also requiring the shareability of the raw data, which may not always be true, e.g. copyright issues with clips from movies or TV series. To address this shortcoming, we propose a multimodal data augmentation technique which works in the feature space and creates new videos and captions by mixing semantically similar samples. We experiment our solution on a large scale public dataset, EPIC-Kitchens-100, and achieve considerable improvements over a baseline method, improved state-of-the-art performance, while at the same time performing multiple ablation studies. We release code and pretrained models on Github at https://github.com/aranciokov/FSMMDA_VideoRetrieval.
A novel approach to increase scalability while training machine learning algorithms using Bfloat 16 in credit card fraud detection
Jun 24, 2022
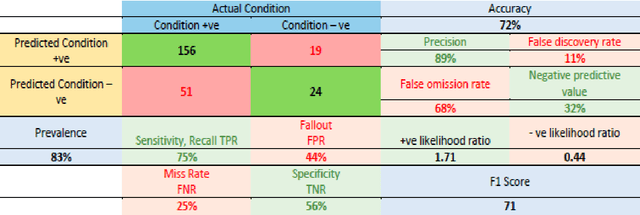
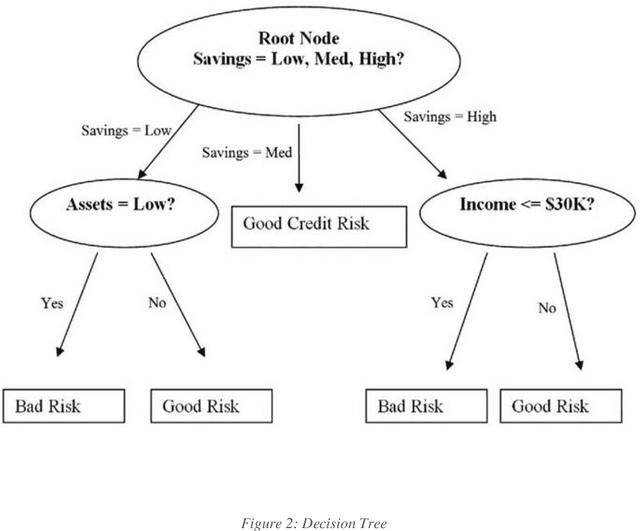
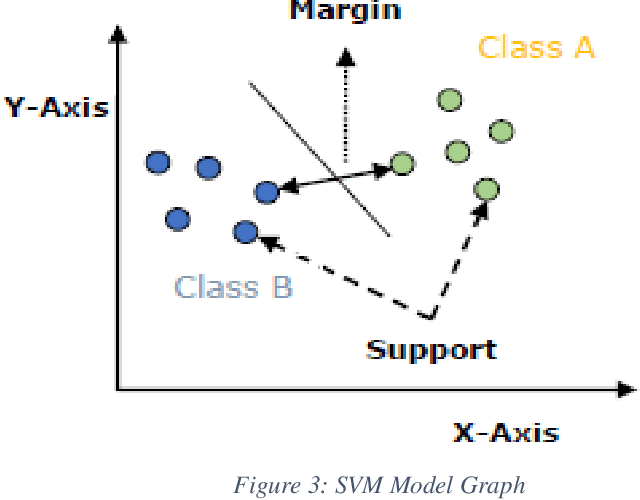
The use of credit cards has become quite common these days as digital banking has become the norm. With this increase, fraud in credit cards also has a huge problem and loss to the banks and customers alike. Normal fraud detection systems, are not able to detect the fraud since fraudsters emerge with new techniques to commit fraud. This creates the need to use machine learning-based software to detect frauds. Currently, the machine learning softwares that are available focuses only on the accuracy of detecting frauds but does not focus on the cost or time factors to detect. This research focuses on machine learning scalability for banks' credit card fraud detection systems. We have compared the existing machine learning algorithms and methods that are available with the newly proposed technique. The goal is to prove that using fewer bits for training a machine learning algorithm will result in a more scalable system, that will reduce the time and will also be less costly to implement.
AMLB: an AutoML Benchmark
Jul 25, 2022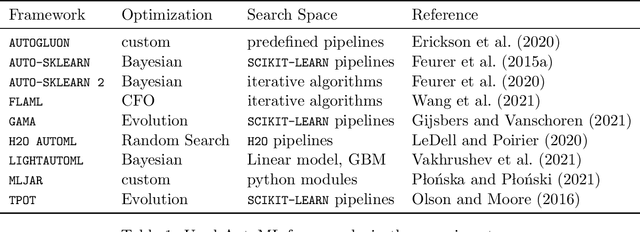
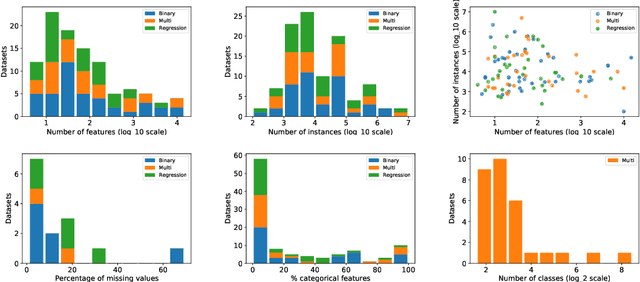
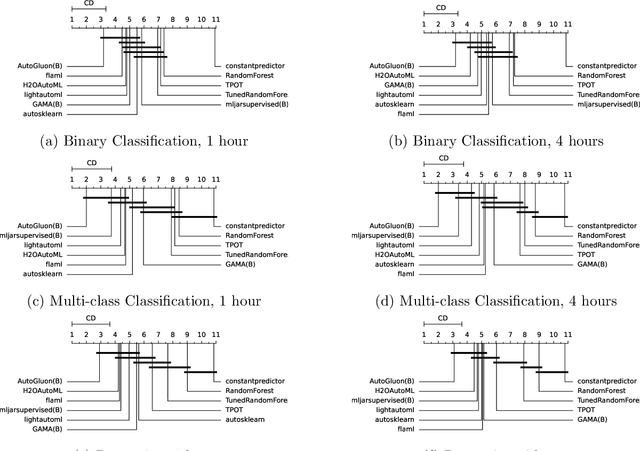
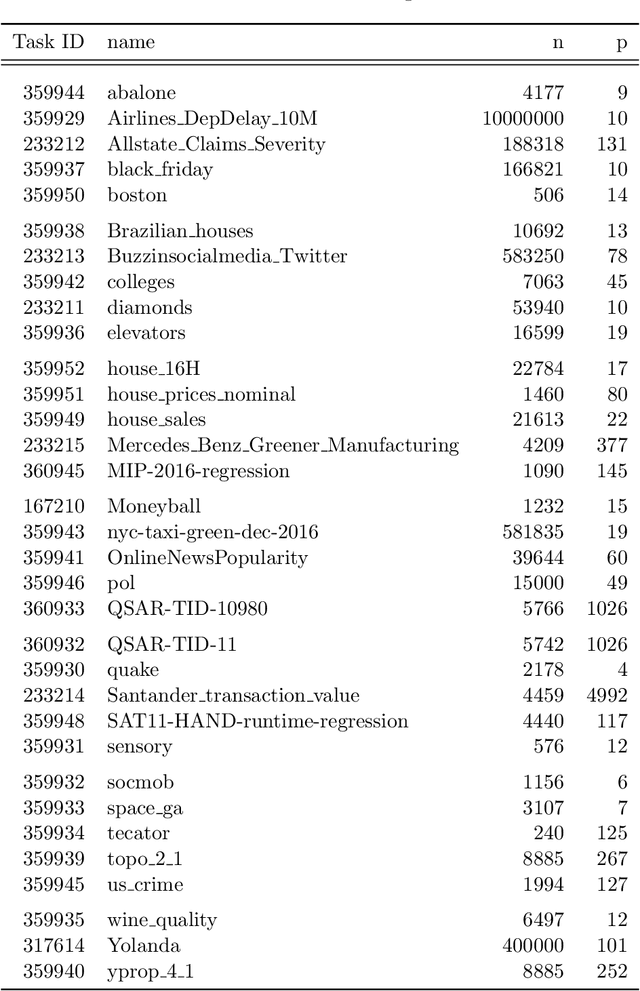
Comparing different AutoML frameworks is notoriously challenging and often done incorrectly. We introduce an open and extensible benchmark that follows best practices and avoids common mistakes when comparing AutoML frameworks. We conduct a thorough comparison of 9 well-known AutoML frameworks across 71 classification and 33 regression tasks. The differences between the AutoML frameworks are explored with a multi-faceted analysis, evaluating model accuracy, its trade-offs with inference time, and framework failures. We also use Bradley-Terry trees to discover subsets of tasks where the relative AutoML framework rankings differ. The benchmark comes with an open-source tool that integrates with many AutoML frameworks and automates the empirical evaluation process end-to-end: from framework installation and resource allocation to in-depth evaluation. The benchmark uses public data sets, can be easily extended with other AutoML frameworks and tasks, and has a website with up-to-date results.
MGNet: Monocular Geometric Scene Understanding for Autonomous Driving
Jun 27, 2022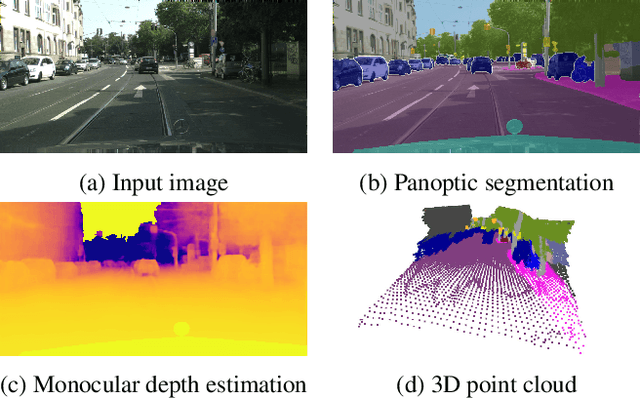
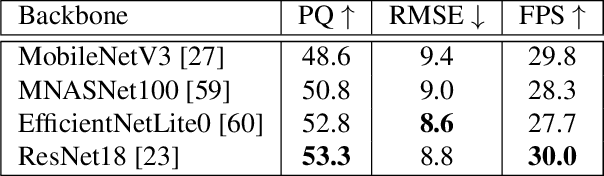
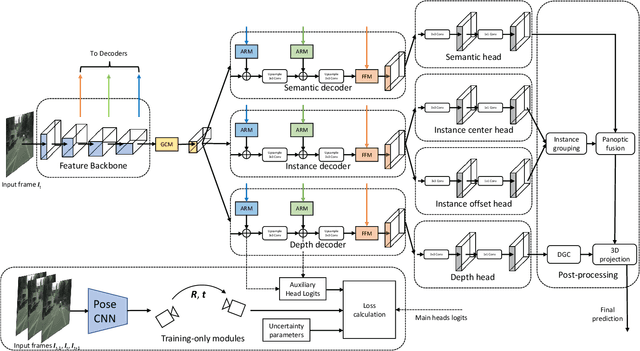
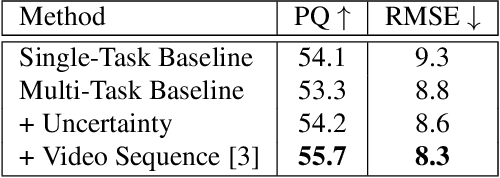
We introduce MGNet, a multi-task framework for monocular geometric scene understanding. We define monocular geometric scene understanding as the combination of two known tasks: Panoptic segmentation and self-supervised monocular depth estimation. Panoptic segmentation captures the full scene not only semantically, but also on an instance basis. Self-supervised monocular depth estimation uses geometric constraints derived from the camera measurement model in order to measure depth from monocular video sequences only. To the best of our knowledge, we are the first to propose the combination of these two tasks in one single model. Our model is designed with focus on low latency to provide fast inference in real-time on a single consumer-grade GPU. During deployment, our model produces dense 3D point clouds with instance aware semantic labels from single high-resolution camera images. We evaluate our model on two popular autonomous driving benchmarks, i.e., Cityscapes and KITTI, and show competitive performance among other real-time capable methods. Source code is available at https://github.com/markusschoen/MGNet.
Cooperative Actor-Critic via TD Error Aggregation
Jul 25, 2022
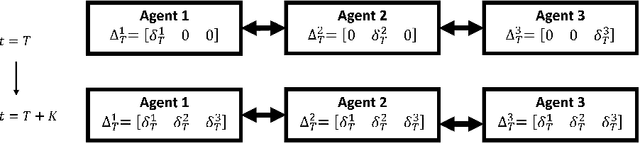
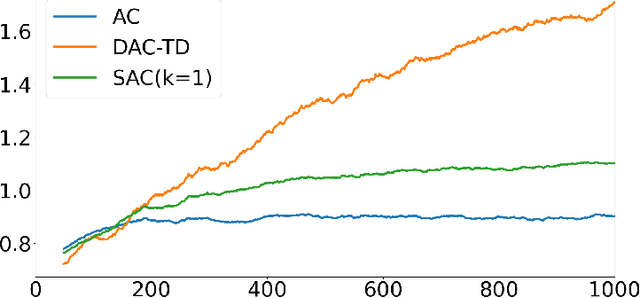
In decentralized cooperative multi-agent reinforcement learning, agents can aggregate information from one another to learn policies that maximize a team-average objective function. Despite the willingness to cooperate with others, the individual agents may find direct sharing of information about their local state, reward, and value function undesirable due to privacy issues. In this work, we introduce a decentralized actor-critic algorithm with TD error aggregation that does not violate privacy issues and assumes that communication channels are subject to time delays and packet dropouts. The cost we pay for making such weak assumptions is an increased communication burden for every agent as measured by the dimension of the transmitted data. Interestingly, the communication burden is only quadratic in the graph size, which renders the algorithm applicable in large networks. We provide a convergence analysis under diminishing step size to verify that the agents maximize the team-average objective function.
Bayesian Inference of Stochastic Dynamical Networks
Jun 02, 2022
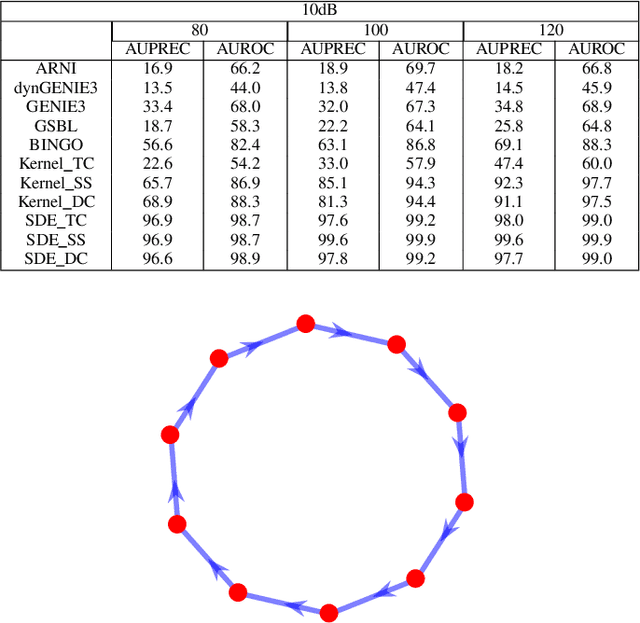
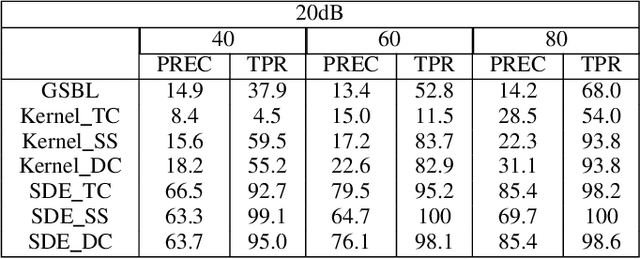
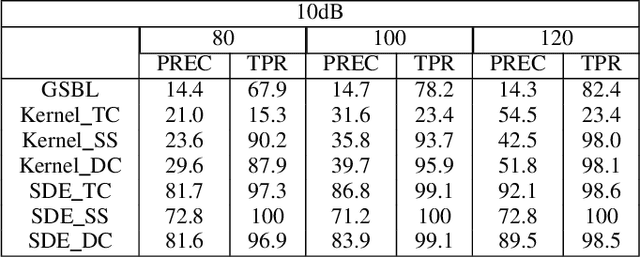
Network inference has been extensively studied in several fields, such as systems biology and social sciences. Learning network topology and internal dynamics is essential to understand mechanisms of complex systems. In particular, sparse topologies and stable dynamics are fundamental features of many real-world continuous-time networks. Given that usually only a partial set of nodes are able to observe, in this paper, we consider linear continuous-time systems to depict networks since they can model unmeasured nodes via transfer functions. Additionally, measurements tend to be noisy and with low and varying sampling frequencies. For this reason, we consider continuous-time models (CT) since discrete-time approximations often require fine-grained measurements and uniform sampling steps. The developed method applies dynamical structure functions (DSFs) derived from linear stochastic differential equations (SDEs) to describe networks of measured nodes. Further, a numerical sampling method, preconditioned Crank-Nicolson (pCN), is used to refine coarse-grained trajectories to improve inference accuracy. The simulation conducted on random and ring networks, and a synthetic biological network illustrate that our method achieves state-of-the-art performance compared with group sparse Bayesian learning (GSBL), BINGO, kernel-based methods, dynGENIE3, GENIE3 and ARNI. In particular, these are challenging networks, suggesting that the developed method can be applied under a wide range of contexts.
Explain My Surprise: Learning Efficient Long-Term Memory by Predicting Uncertain Outcomes
Jul 27, 2022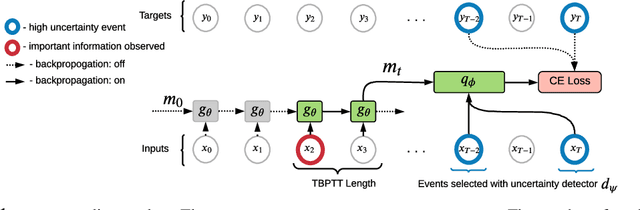
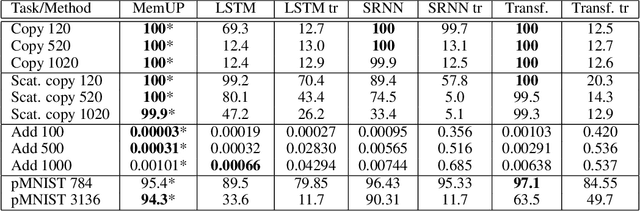
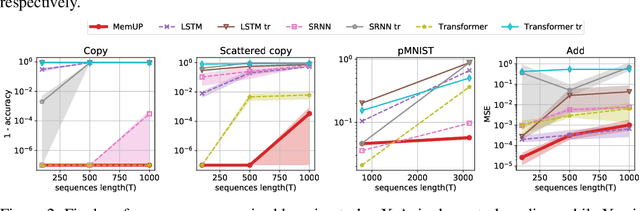
In many sequential tasks, a model needs to remember relevant events from the distant past to make correct predictions. Unfortunately, a straightforward application of gradient based training requires intermediate computations to be stored for every element of a sequence. This requires prohibitively large computing memory if a sequence consists of thousands or even millions elements, and as a result, makes learning of very long-term dependencies infeasible. However, the majority of sequence elements can usually be predicted by taking into account only temporally local information. On the other hand, predictions affected by long-term dependencies are sparse and characterized by high uncertainty given only local information. We propose MemUP, a new training method that allows to learn long-term dependencies without backpropagating gradients through the whole sequence at a time. This method can be potentially applied to any gradient based sequence learning. MemUP implementation for recurrent architectures shows performances better or comparable to baselines while requiring significantly less computing memory.
Pixel-level Correspondence for Self-Supervised Learning from Video
Jul 08, 2022
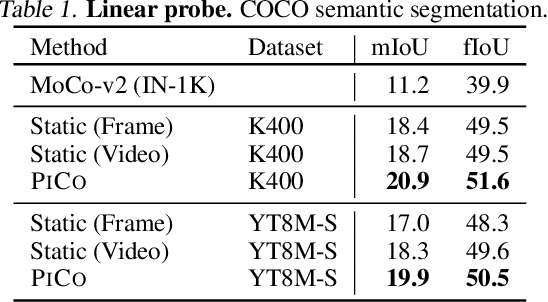


While self-supervised learning has enabled effective representation learning in the absence of labels, for vision, video remains a relatively untapped source of supervision. To address this, we propose Pixel-level Correspondence (PiCo), a method for dense contrastive learning from video. By tracking points with optical flow, we obtain a correspondence map which can be used to match local features at different points in time. We validate PiCo on standard benchmarks, outperforming self-supervised baselines on multiple dense prediction tasks, without compromising performance on image classification.
Efficient spike encoding algorithms for neuromorphic speech recognition
Jul 14, 2022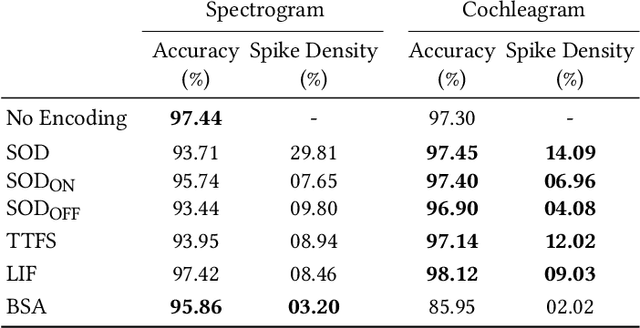
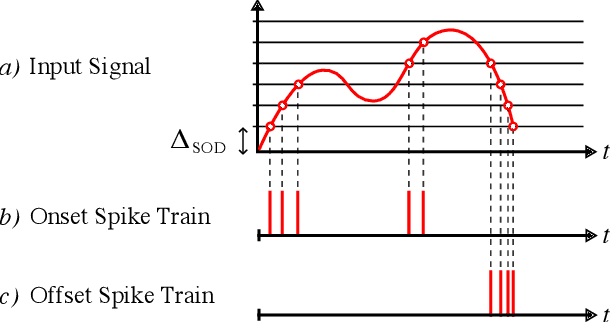

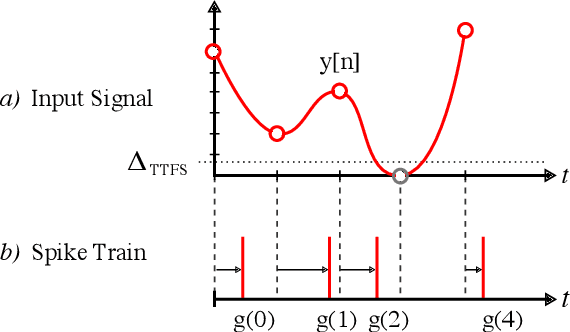
Spiking Neural Networks (SNN) are known to be very effective for neuromorphic processor implementations, achieving orders of magnitude improvements in energy efficiency and computational latency over traditional deep learning approaches. Comparable algorithmic performance was recently made possible as well with the adaptation of supervised training algorithms to the context of SNN. However, information including audio, video, and other sensor-derived data are typically encoded as real-valued signals that are not well-suited to SNN, preventing the network from leveraging spike timing information. Efficient encoding from real-valued signals to spikes is therefore critical and significantly impacts the performance of the overall system. To efficiently encode signals into spikes, both the preservation of information relevant to the task at hand as well as the density of the encoded spikes must be considered. In this paper, we study four spike encoding methods in the context of a speaker independent digit classification system: Send on Delta, Time to First Spike, Leaky Integrate and Fire Neuron and Bens Spiker Algorithm. We first show that all encoding methods yield higher classification accuracy using significantly fewer spikes when encoding a bio-inspired cochleagram as opposed to a traditional short-time Fourier transform. We then show that two Send On Delta variants result in classification results comparable with a state of the art deep convolutional neural network baseline, while simultaneously reducing the encoded bit rate. Finally, we show that several encoding methods result in improved performance over the conventional deep learning baseline in certain cases, further demonstrating the power of spike encoding algorithms in the encoding of real-valued signals and that neuromorphic implementation has the potential to outperform state of the art techniques.
Graphical Join: A New Physical Join Algorithm for RDBMSs
Jun 22, 2022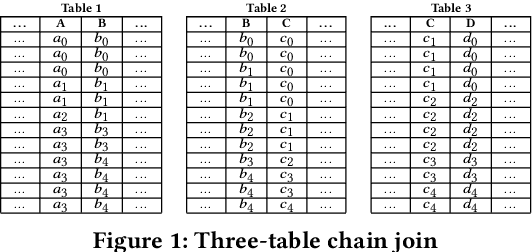

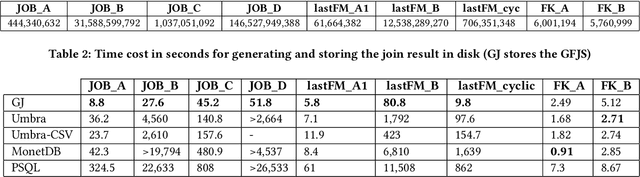
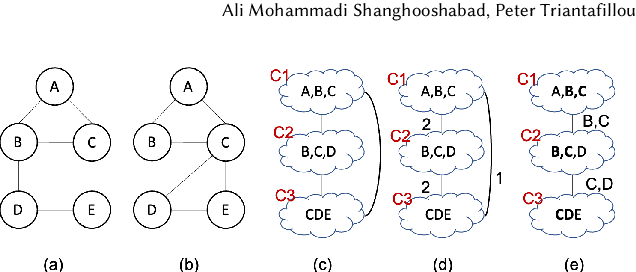
Join operations (especially n-way, many-to-many joins) are known to be time- and resource-consuming. At large scales, with respect to table and join-result sizes, current state of the art approaches (including both binary-join plans which use Nested-loop/Hash/Sort-merge Join algorithms or, alternatively, worst-case optimal join algorithms (WOJAs)), may even fail to produce any answer given reasonable resource and time constraints. In this work, we introduce a new approach for n-way equi-join processing, the Graphical Join (GJ). The key idea is two-fold: First, to map the physical join computation problem to PGMs and introduce tweaked inference algorithms which can compute a Run-Length Encoding (RLE) based join-result summary, entailing all statistics necessary to materialize the join result. Second, and most importantly, to show that a join algorithm, like GJ, which produces the above join-result summary and then desummarizes it, can introduce large performance benefits in time and space. Comprehensive experimentation is undertaken with join queries from the JOB, TPCDS, and lastFM datasets, comparing GJ against PostgresQL and MonetDB and a state of the art WOJA implemented within the Umbra system. The results for in-memory join computation show performance improvements up to 64X, 388X, and 6X faster than PostgreSQL, MonetDB and Umbra, respectively. For on-disk join computation, GJ is faster than PostgreSQL, MonetDB and Umbra by up to 820X, 717X and 165X, respectively. Furthermore, GJ space needs are up to 21,488X, 38,333X, and 78,750X smaller than PostgresQL, MonetDB, and Umbra, respectively.