 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Reconfigurable Intelligent Surface Enabled Over-the-Air Uplink Non-orthogonal Multiple Access
Aug 06, 2022
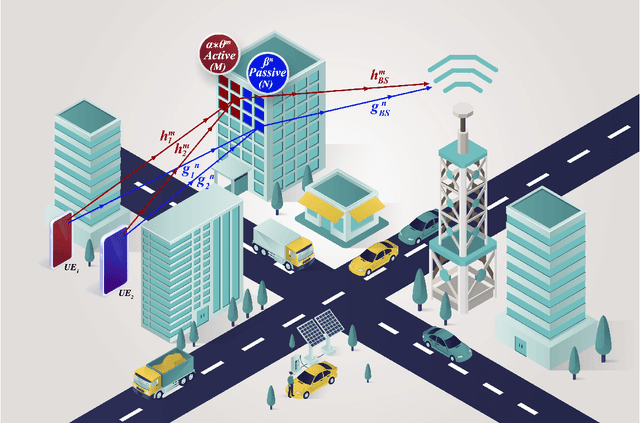
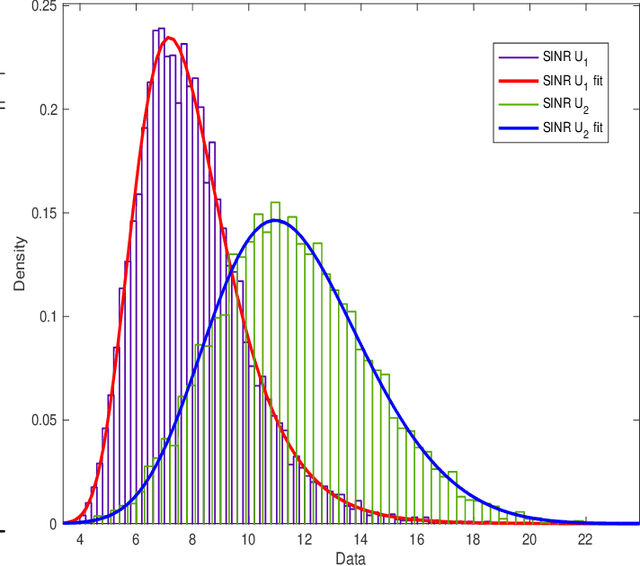
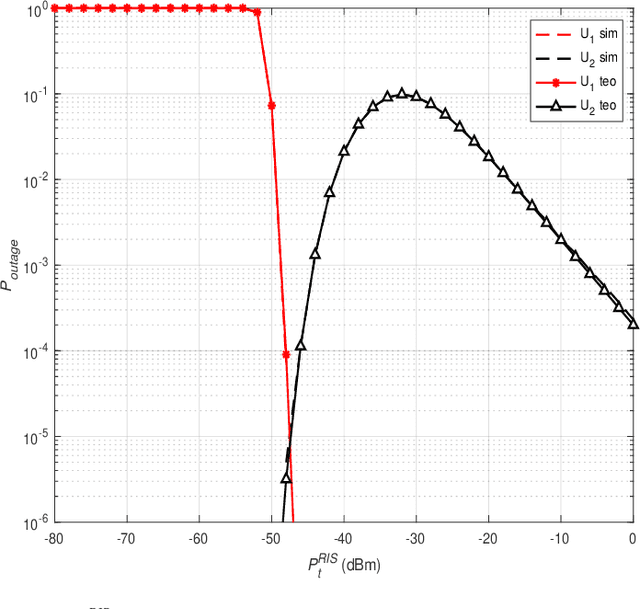
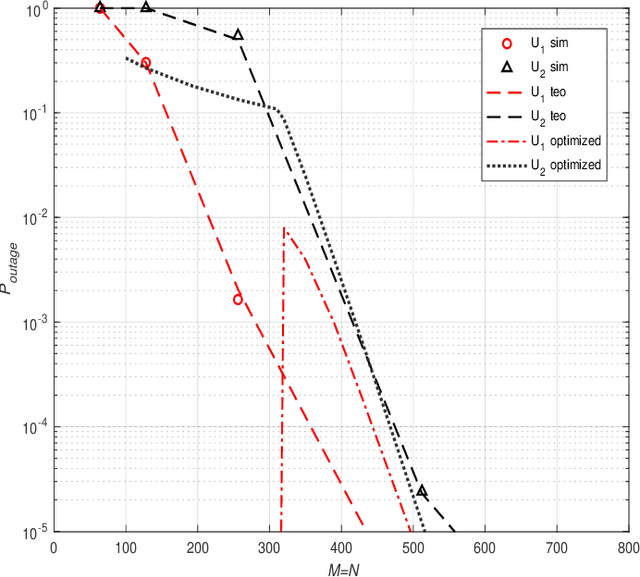
Innovative reconfigurable intelligent surface (RIS) technologies are rising and recognized as promising candidates to enhance 6G and beyond wireless communication systems. RISs acquire the ability to manipulate electromagnetic signals, thus, offering a degree of control over the wireless channel and the potential for many more benefits. Furthermore, active RIS designs have recently been introduced to combat the critical double fading problem and other impairments passive RIS designs may possess. In this paper, the potential and flexibility of active RIS technology are exploited for uplink systems to achieve virtual non-orthogonal multiple access (NOMA) through power disparity over-the-air rather than controlling transmit powers at the user side. Specifically, users with identical transmit power, path loss, and distance can communicate with a base station sharing time and frequency resources in a NOMA fashion with the aid of the proposed hybrid RIS system. Here, the RIS is partitioned into active and passive parts and the distinctive partitions serve different users aligning their phases accordingly while introducing a power difference to the users' signals to enable NOMA. First, the end-to-end system model is presented considering two users. Furthermore, outage probability calculations and theoretical error probability analysis are discussed and reinforced with computer simulation results.
Backpropagation on Dynamical Networks
Jul 07, 2022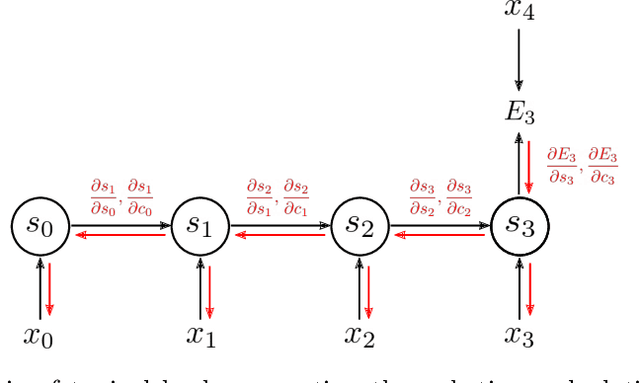
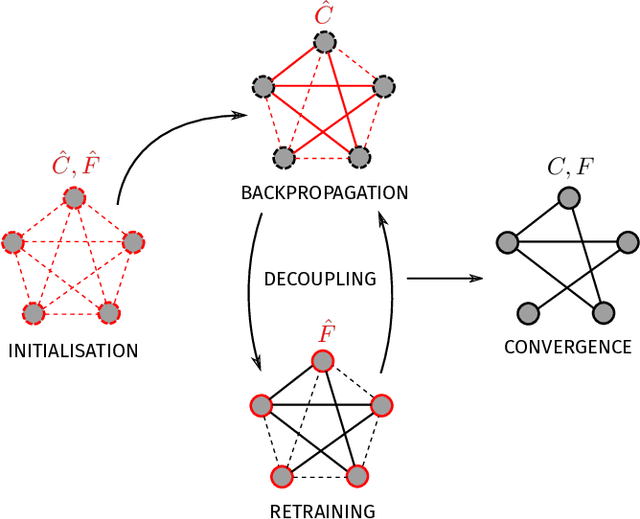
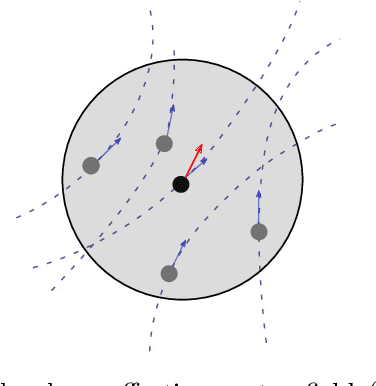
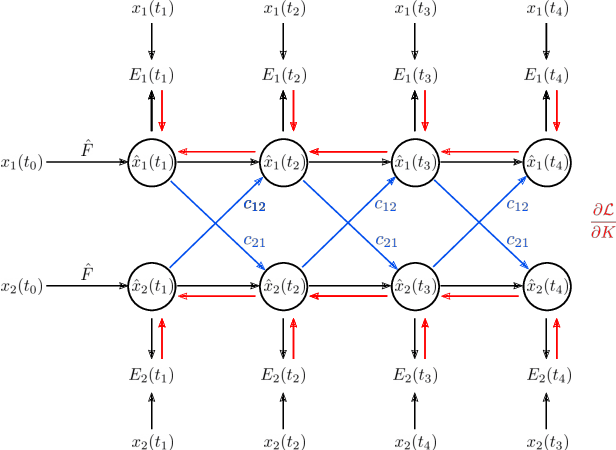
Dynamical networks are versatile models that can describe a variety of behaviours such as synchronisation and feedback. However, applying these models in real world contexts is difficult as prior information pertaining to the connectivity structure or local dynamics is often unknown and must be inferred from time series observations of network states. Additionally, the influence of coupling interactions between nodes further complicates the isolation of local node dynamics. Given the architectural similarities between dynamical networks and recurrent neural networks (RNN), we propose a network inference method based on the backpropagation through time (BPTT) algorithm commonly used to train recurrent neural networks. This method aims to simultaneously infer both the connectivity structure and local node dynamics purely from observation of node states. An approximation of local node dynamics is first constructed using a neural network. This is alternated with an adapted BPTT algorithm to regress corresponding network weights by minimising prediction errors of the dynamical network based on the previously constructed local models until convergence is achieved. This method was found to be succesful in identifying the connectivity structure for coupled networks of Lorenz, Chua and FitzHugh-Nagumo oscillators. Freerun prediction performance with the resulting local models and weights was found to be comparable to the true system with noisy initial conditions. The method is also extended to non-conventional network couplings such as asymmetric negative coupling.
OTPose: Occlusion-Aware Transformer for Pose Estimation in Sparsely-Labeled Videos
Jul 28, 2022
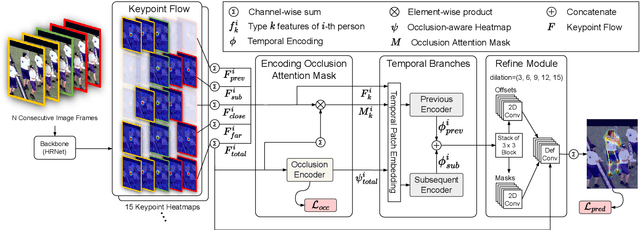

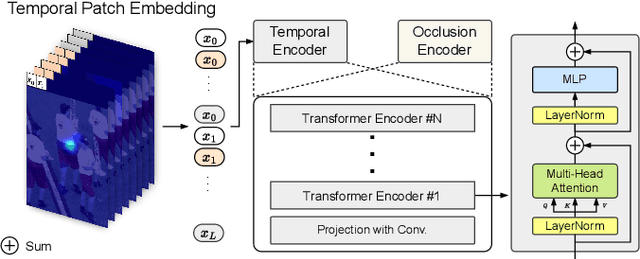
Although many approaches for multi-human pose estimation in videos have shown profound results, they require densely annotated data which entails excessive man labor. Furthermore, there exists occlusion and motion blur that inevitably lead to poor estimation performance. To address these problems, we propose a method that leverages an attention mask for occluded joints and encodes temporal dependency between frames using transformers. First, our framework composes different combinations of sparsely annotated frames that denote the track of the overall joint movement. We propose an occlusion attention mask from these combinations that enable encoding occlusion-aware heatmaps as a semi-supervised task. Second, the proposed temporal encoder employs transformer architecture to effectively aggregate the temporal relationship and keypoint-wise attention from each time step and accurately refines the target frame's final pose estimation. We achieve state-of-the-art pose estimation results for PoseTrack2017 and PoseTrack2018 datasets and demonstrate the robustness of our approach to occlusion and motion blur in sparsely annotated video data.
Rearrangement-Based Manipulation via Kinodynamic Planning and Dynamic Planning Horizons
Aug 03, 2022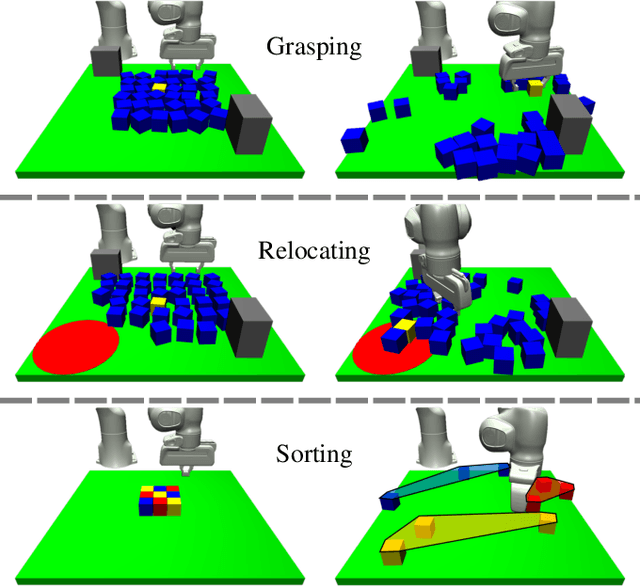

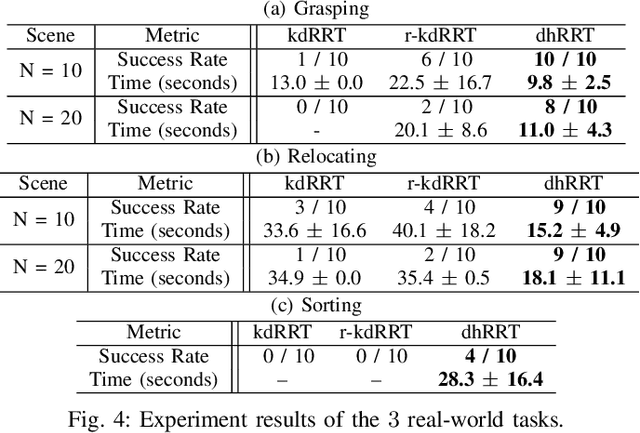
Robot manipulation in cluttered environments often requires complex and sequential rearrangement of multiple objects in order to achieve the desired reconfiguration of the target objects. Due to the sophisticated physical interactions involved in such scenarios, rearrangement-based manipulation is still limited to a small range of tasks and is especially vulnerable to physical uncertainties and perception noise. This paper presents a planning framework that leverages the efficiency of sampling-based planning approaches, and closes the manipulation loop by dynamically controlling the planning horizon. Our approach interleaves planning and execution to progressively approach the manipulation goal while correcting any errors or path deviations along the process. Meanwhile, our framework allows the definition of manipulation goals without requiring explicit goal configurations, enabling the robot to flexibly interact with all objects to facilitate the manipulation of the target ones. With extensive experiments both in simulation and on a real robot, we evaluate our framework on three manipulation tasks in cluttered environments: grasping, relocating, and sorting. In comparison with two baseline approaches, we show that our framework can significantly improve planning efficiency, robustness against physical uncertainties, and task success rate under limited time budgets.
Copulaboost: additive modeling with copula-based model components
Aug 09, 2022
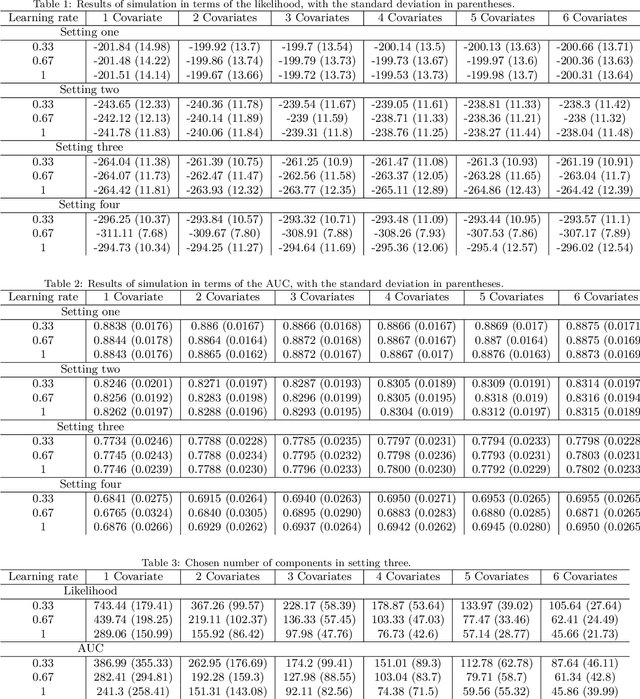
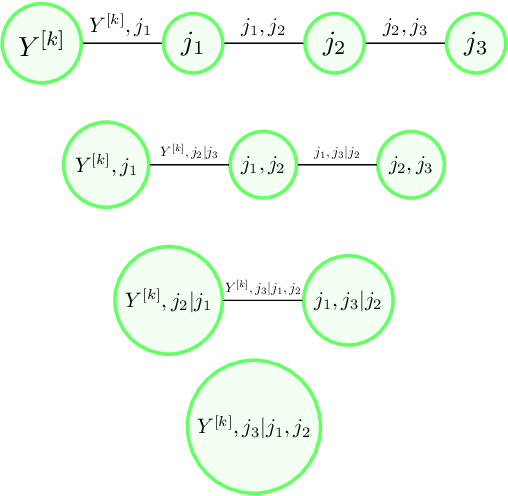
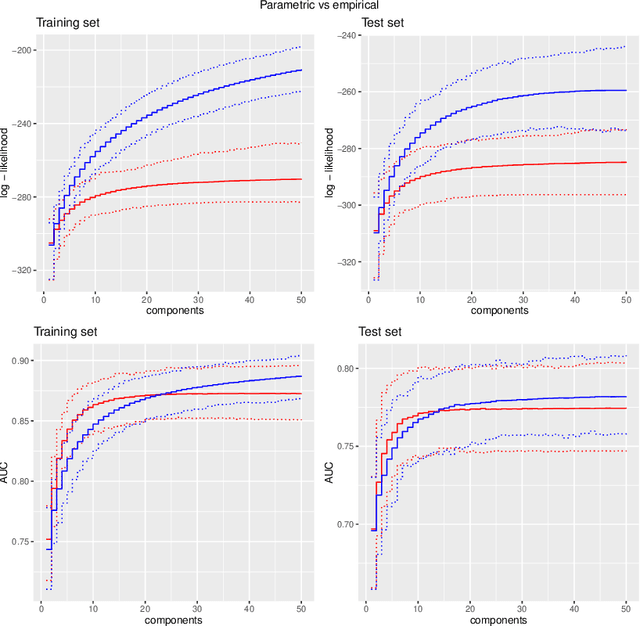
We propose a type of generalised additive models with of model components based on pair-copula constructions, with prediction as a main aim. The model components are designed such that our model may capture potentially complex interaction effects in the relationship between the response covariates. In addition, our model does not require discretisation of continuous covariates, and is therefore suitable for problems with many such covariates. Further, we have designed a fitting algorithm inspired by gradient boosting, as well as efficient procedures for model selection and evaluation of the model components, through constraints on the model space and approximations, that speed up time-costly computations. In addition to being absolutely necessary for our model to be a realistic alternative in higher dimensions, these techniques may also be useful as a basis for designing efficient models selection algorithms for other types of copula regression models. We have explored the characteristics of our method in a simulation study, in particular comparing it to natural alternatives, such as logic regression, classic boosting models and penalised logistic regression. We have also illustrated our approach on the Wisconsin breast cancer dataset and on the Boston housing dataset. The results show that our method has a prediction performance that is either better than or comparable to the other methods, even when the proportion of discrete covariates is high.
Sequence Model Imitation Learning with Unobserved Contexts
Aug 03, 2022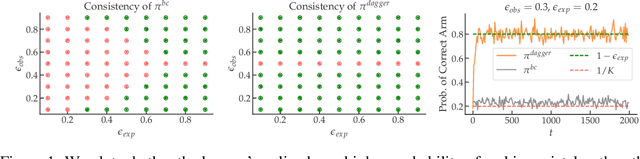
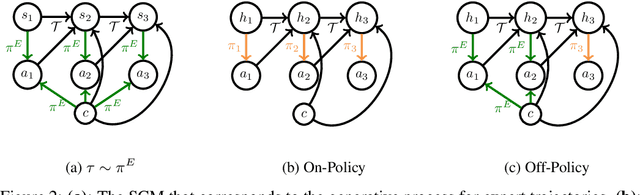
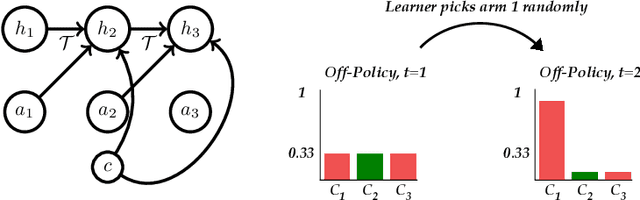

We consider imitation learning problems where the expert has access to a per-episode context that is hidden from the learner, both in the demonstrations and at test-time. While the learner might not be able to accurately reproduce expert behavior early on in an episode, by considering the entire history of states and actions, they might be able to eventually identify the context and act as the expert would. We prove that on-policy imitation learning algorithms (with or without access to a queryable expert) are better equipped to handle these sorts of asymptotically realizable problems than off-policy methods and are able to avoid the latching behavior (naive repetition of past actions) that plagues the latter. We conduct experiments in a toy bandit domain that show that there exist sharp phase transitions of whether off-policy approaches are able to match expert performance asymptotically, in contrast to the uniformly good performance of on-policy approaches. We demonstrate that on several continuous control tasks, on-policy approaches are able to use history to identify the context while off-policy approaches actually perform worse when given access to history.
Choose qualified instructor for university based on rule-based weighted expert system
Aug 09, 2022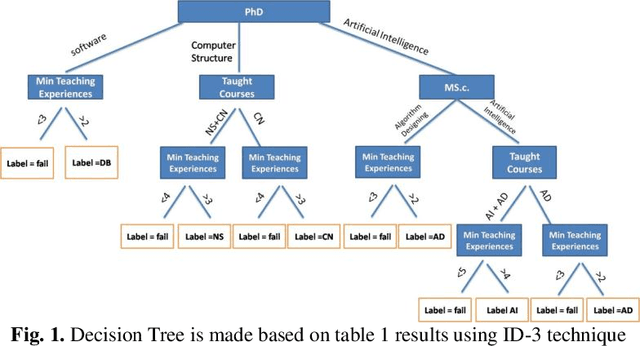
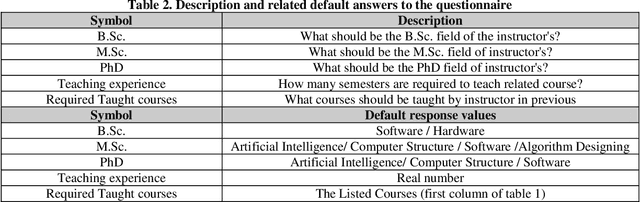
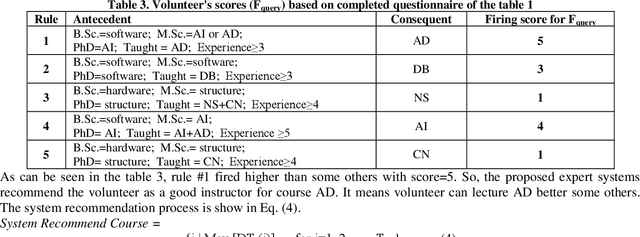
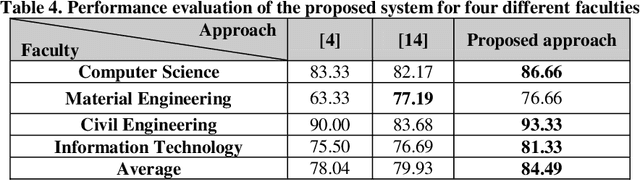
Near the entire university faculty directors must select some qualified professors for respected courses in each academic semester. In this sense, factors such as teaching experience, academic training, competition, etc. are considered. This work is usually done by experts, such as faculty directors, which is time consuming. Up to now, several semi-automatic systems have been proposed to assist heads. In this article, a fully automatic rule-based expert system is developed. The proposed expert system consists of three main stages. First, the knowledge of human experts is entered and designed as a decision tree. In the second step, an expert system is designed based on the provided rules of the generated decision tree. In the third step, an algorithm is proposed to weight the results of the tree based on the quality of the experts. To improve the performance of the expert system, a majority voting algorithm is developed as a post-process step to select the qualified trainer who satisfies the most expert decision tree for each course. The quality of the proposed expert system is evaluated using real data from Iranian universities. The calculated accuracy rate is 85.55, demonstrating the robustness and accuracy of the proposed system. The proposed system has little computational complexity compared to related efficient works. Also, simple implementation and transparent box are other features of the proposed system.
A novel approach to increase scalability while training machine learning algorithms using Bfloat 16 in credit card fraud detection
Jun 24, 2022
The use of credit cards has become quite common these days as digital banking has become the norm. With this increase, fraud in credit cards also has a huge problem and loss to the banks and customers alike. Normal fraud detection systems, are not able to detect the fraud since fraudsters emerge with new techniques to commit fraud. This creates the need to use machine learning-based software to detect frauds. Currently, the machine learning softwares that are available focuses only on the accuracy of detecting frauds but does not focus on the cost or time factors to detect. This research focuses on machine learning scalability for banks' credit card fraud detection systems. We have compared the existing machine learning algorithms and methods that are available with the newly proposed technique. The goal is to prove that using fewer bits for training a machine learning algorithm will result in a more scalable system, that will reduce the time and will also be less costly to implement.
Yformer: U-Net Inspired Transformer Architecture for Far Horizon Time Series Forecasting
Oct 13, 2021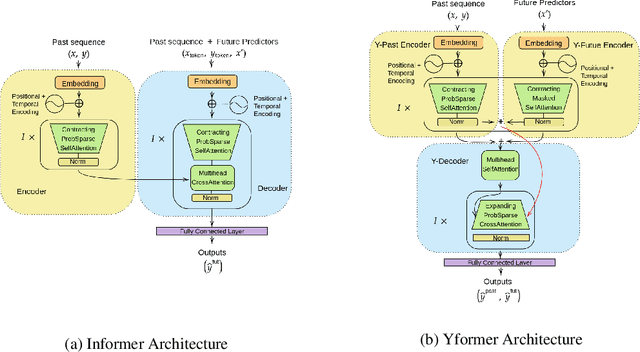
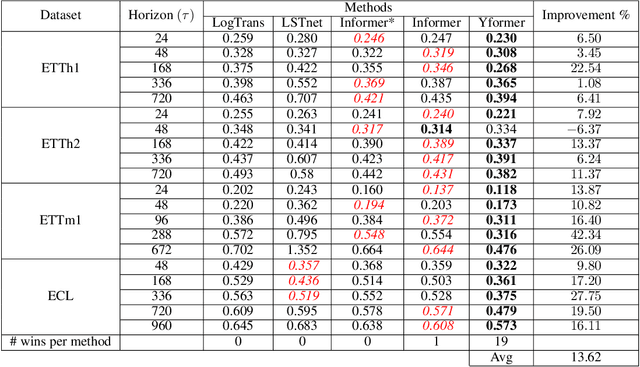
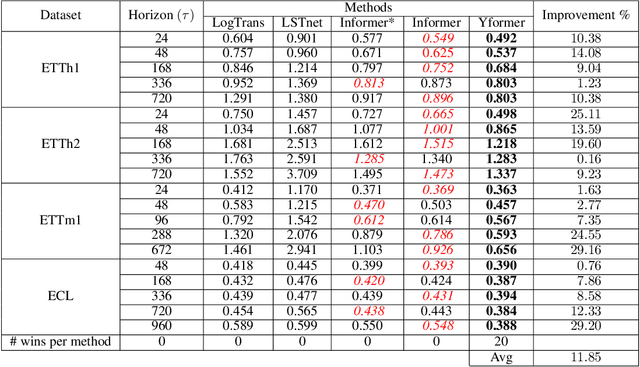
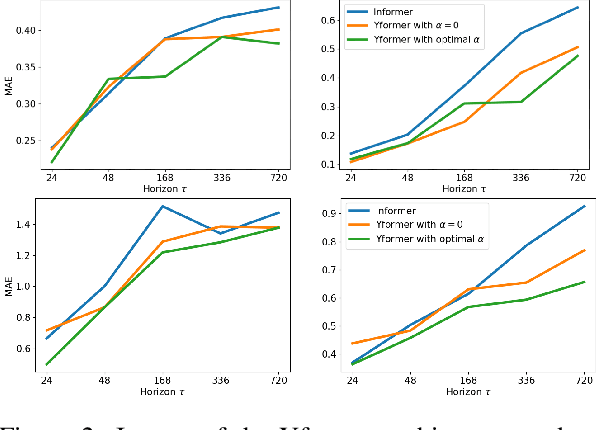
Time series data is ubiquitous in research as well as in a wide variety of industrial applications. Effectively analyzing the available historical data and providing insights into the far future allows us to make effective decisions. Recent research has witnessed the superior performance of transformer-based architectures, especially in the regime of far horizon time series forecasting. However, the current state of the art sparse Transformer architectures fail to couple down- and upsampling procedures to produce outputs in a similar resolution as the input. We propose the Yformer model, based on a novel Y-shaped encoder-decoder architecture that (1) uses direct connection from the downscaled encoder layer to the corresponding upsampled decoder layer in a U-Net inspired architecture, (2) Combines the downscaling/upsampling with sparse attention to capture long-range effects, and (3) stabilizes the encoder-decoder stacks with the addition of an auxiliary reconstruction loss. Extensive experiments have been conducted with relevant baselines on four benchmark datasets, demonstrating an average improvement of 19.82, 18.41 percentage MSE and 13.62, 11.85 percentage MAE in comparison to the current state of the art for the univariate and the multivariate settings respectively.
Adaptive Sampling of Latent Phenomena using Heterogeneous Robot Teams (ASLaP-HR)
Aug 11, 2022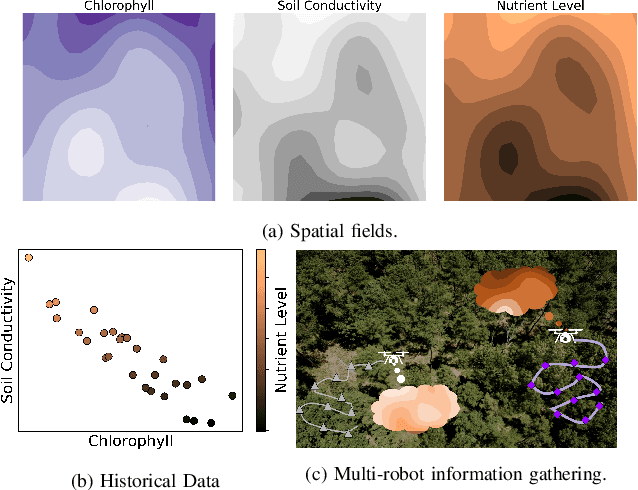
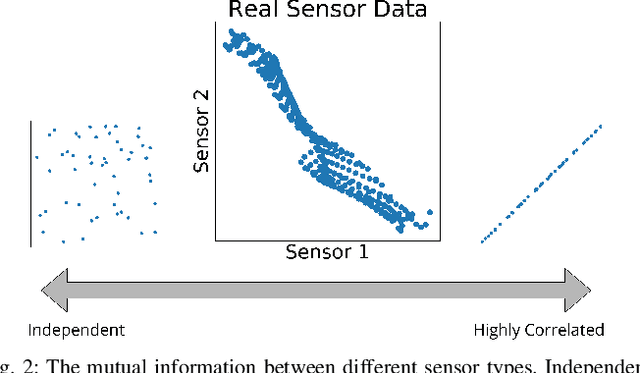
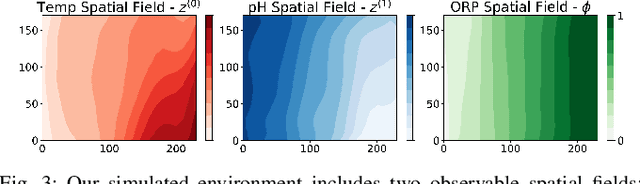
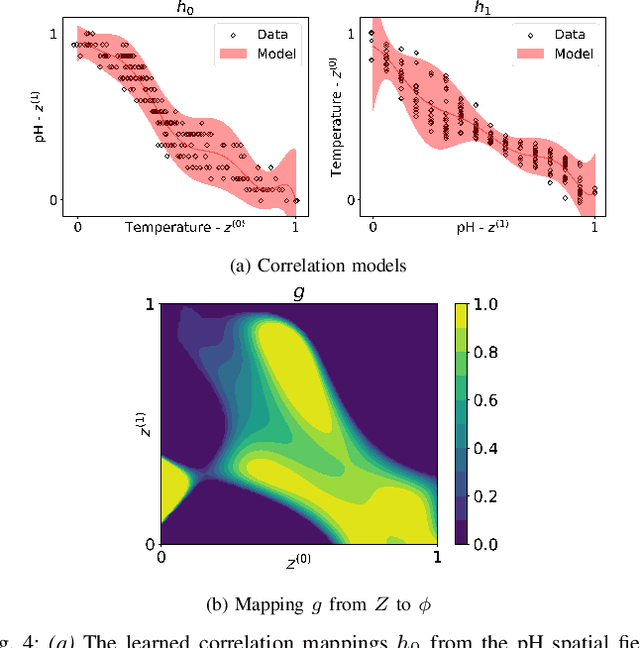
In this paper, we present an online adaptive planning strategy for a team of robots with heterogeneous sensors to sample from a latent spatial field using a learned model for decision making. Current robotic sampling methods seek to gather information about an observable spatial field. However, many applications, such as environmental monitoring and precision agriculture, involve phenomena that are not directly observable or are costly to measure, called latent phenomena. In our approach, we seek to reason about the latent phenomenon in real-time by effectively sampling the observable spatial fields using a team of robots with heterogeneous sensors, where each robot has a distinct sensor to measure a different observable field. The information gain is estimated using a learned model that maps from the observable spatial fields to the latent phenomenon. This model captures aleatoric uncertainty in the relationship to allow for information theoretic measures. Additionally, we explicitly consider the correlations among the observable spatial fields, capturing the relationship between sensor types whose observations are not independent. We show it is possible to learn these correlations, and investigate the impact of the learned correlation models on the performance of our sampling approach. Through our qualitative and quantitative results, we illustrate that empirically learned correlations improve the overall sampling efficiency of the team. We simulate our approach using a data set of sensor measurements collected on Lac Hertel, in Quebec, which we make publicly available.