 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Neural Integro-Differential Equations
Jun 28, 2022
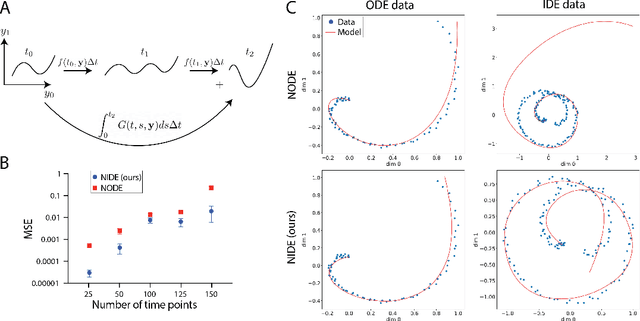


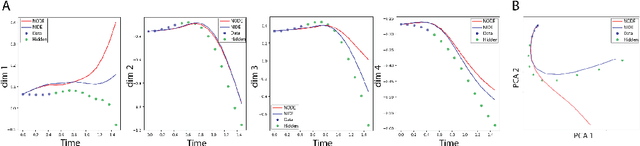
Modeling continuous dynamical systems from discretely sampled observations is a fundamental problem in data science. Often, such dynamics are the result of non-local processes that present an integral over time. As such, these systems are modeled with Integro-Differential Equations (IDEs); generalizations of differential equations that comprise both an integral and a differential component. For example, brain dynamics are not accurately modeled by differential equations since their behavior is non-Markovian, i.e. dynamics are in part dictated by history. Here, we introduce the Neural IDE (NIDE), a framework that models ordinary and integral components of IDEs using neural networks. We test NIDE on several toy and brain activity datasets and demonstrate that NIDE outperforms other models, including Neural ODE. These tasks include time extrapolation as well as predicting dynamics from unseen initial conditions, which we test on whole-cortex activity recordings in freely behaving mice. Further, we show that NIDE can decompose dynamics into its Markovian and non-Markovian constituents, via the learned integral operator, which we test on fMRI brain activity recordings of people on ketamine. Finally, the integrand of the integral operator provides a latent space that gives insight into the underlying dynamics, which we demonstrate on wide-field brain imaging recordings. Altogether, NIDE is a novel approach that enables modeling of complex non-local dynamics with neural networks.
Ad2Attack: Adaptive Adversarial Attack on Real-Time UAV Tracking
Mar 03, 2022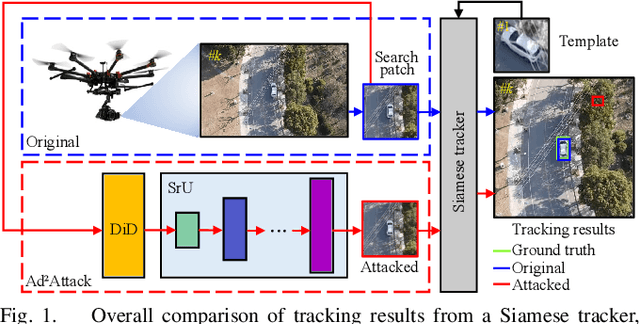
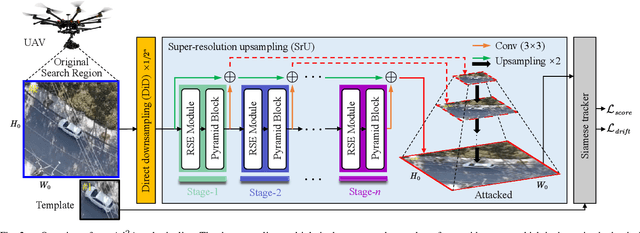
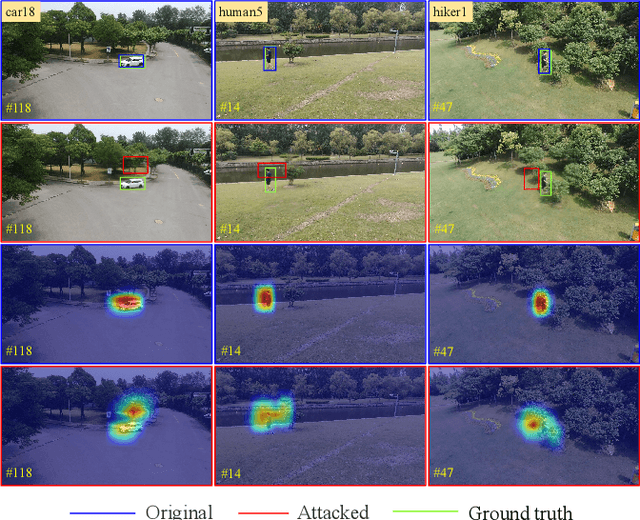
Visual tracking is adopted to extensive unmanned aerial vehicle (UAV)-related applications, which leads to a highly demanding requirement on the robustness of UAV trackers. However, adding imperceptible perturbations can easily fool the tracker and cause tracking failures. This risk is often overlooked and rarely researched at present. Therefore, to help increase awareness of the potential risk and the robustness of UAV tracking, this work proposes a novel adaptive adversarial attack approach, i.e., Ad$^2$Attack, against UAV object tracking. Specifically, adversarial examples are generated online during the resampling of the search patch image, which leads trackers to lose the target in the following frames. Ad$^2$Attack is composed of a direct downsampling module and a super-resolution upsampling module with adaptive stages. A novel optimization function is proposed for balancing the imperceptibility and efficiency of the attack. Comprehensive experiments on several well-known benchmarks and real-world conditions show the effectiveness of our attack method, which dramatically reduces the performance of the most advanced Siamese trackers.
Building for Tomorrow: Assessing the Temporal Persistence of Text Classifiers
May 11, 2022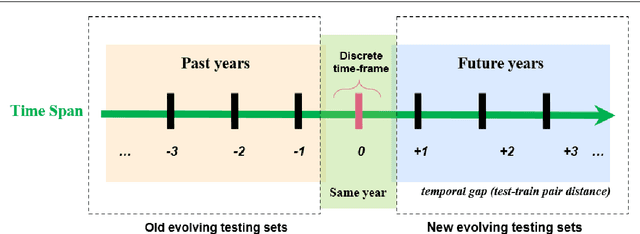
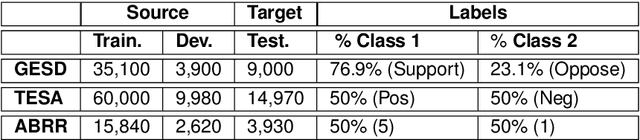
Performance of text classification models can drop over time when new data to be classified is more distant in time from the data used for training, due to naturally occurring changes in the data, such as vocabulary change. A solution to this is to continually label new data to retrain the model, which is, however, often unaffordable to be performed regularly due to its associated cost. This raises important research questions on the design of text classification models that are intended to persist over time: do all embedding models and classification algorithms exhibit similar performance drops over time and is the performance drop more prominent in some tasks or datasets than others? With the aim of answering these research questions, we perform longitudinal classification experiments on three datasets spanning between 6 and 19 years. Findings from these experiments inform the design of text classification models with the aim of preserving performance over time, discussing the extent to which one can rely on classification models trained from temporally distant training data, as well as how the characteristics of the dataset impact this.
SOMTimeS: Self Organizing Maps for Time Series Clustering and its Application to Serious Illness Conversations
Aug 26, 2021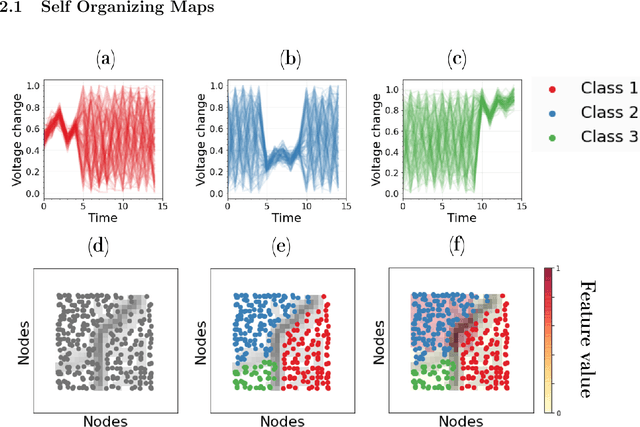
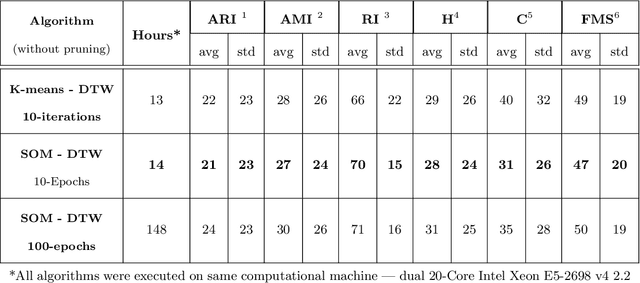
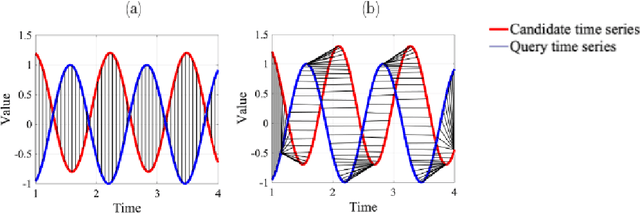
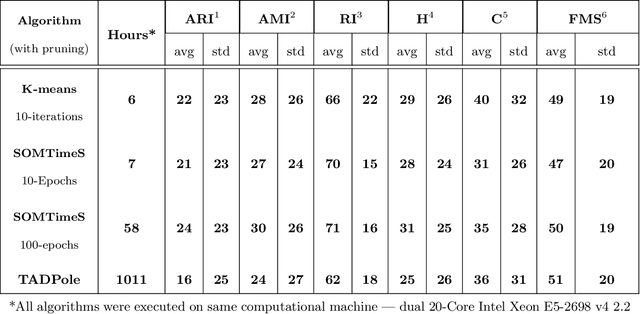
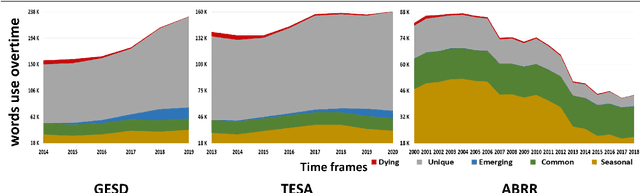
There is an increasing demand for scalable algorithms capable of clustering and analyzing large time series datasets. The Kohonen self-organizing map (SOM) is a type of unsupervised artificial neural network for visualizing and clustering complex data, reducing the dimensionality of data, and selecting influential features. Like all clustering methods, the SOM requires a measure of similarity between input data (in this work time series). Dynamic time warping (DTW) is one such measure, and a top performer given that it accommodates the distortions when aligning time series. Despite its use in clustering, DTW is limited in practice because it is quadratic in runtime complexity with the length of the time series data. To address this, we present a new DTW-based clustering method, called SOMTimeS (a Self-Organizing Map for TIME Series), that scales better and runs faster than other DTW-based clustering algorithms, and has similar performance accuracy. The computational performance of SOMTimeS stems from its ability to prune unnecessary DTW computations during the SOM's training phase. We also implemented a similar pruning strategy for K-means for comparison with one of the top performing clustering algorithms. We evaluated the pruning effectiveness, accuracy, execution time and scalability on 112 benchmark time series datasets from the University of California, Riverside classification archive. We showed that for similar accuracy, the speed-up achieved for SOMTimeS and K-means was 1.8x on average; however, rates varied between 1x and 18x depending on the dataset. SOMTimeS and K-means pruned 43% and 50% of the total DTW computations, respectively. We applied SOMtimeS to natural language conversation data collected as part of a large healthcare cohort study of patient-clinician serious illness conversations to demonstrate the algorithm's utility with complex, temporally sequenced phenomena.
Model-based graph reinforcement learning for inductive traffic signal control
Aug 01, 2022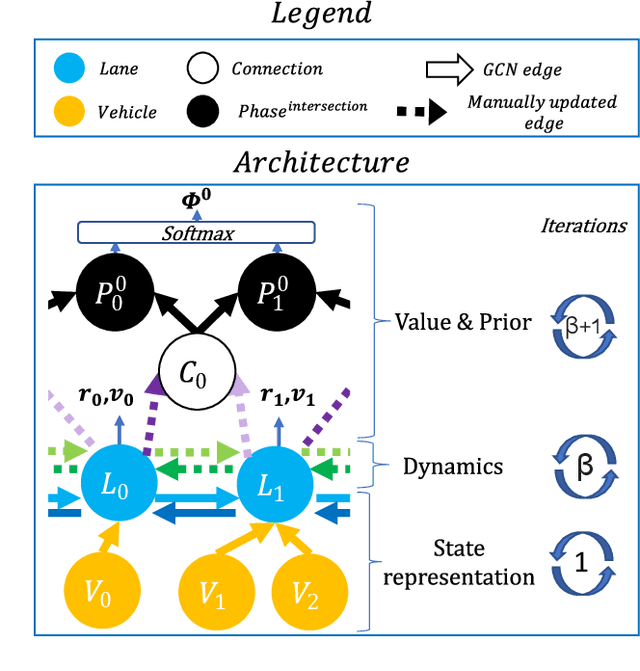
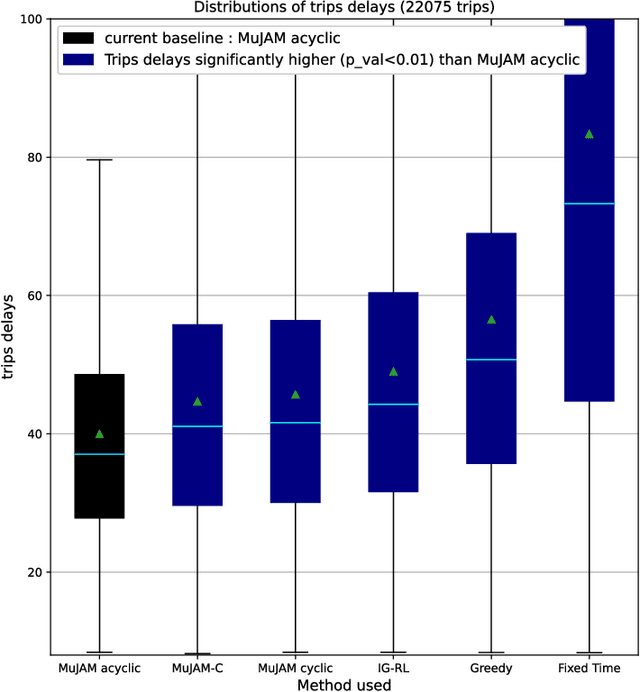
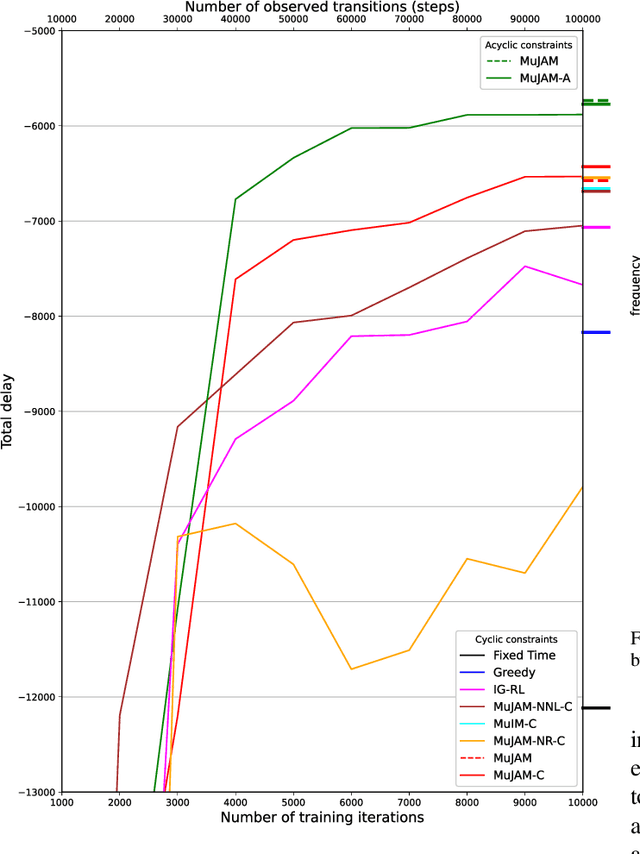
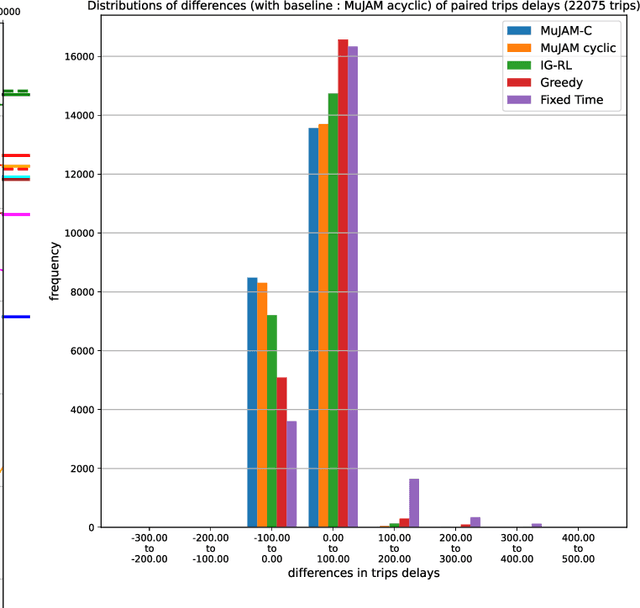
Most reinforcement learning methods for adaptive-traffic-signal-control require training from scratch to be applied on any new intersection or after any modification to the road network, traffic distribution, or behavioral constraints experienced during training. Considering 1) the massive amount of experience required to train such methods, and 2) that experience must be gathered by interacting in an exploratory fashion with real road-network-users, such a lack of transferability limits experimentation and applicability. Recent approaches enable learning policies that generalize for unseen road-network topologies and traffic distributions, partially tackling this challenge. However, the literature remains divided between the learning of cyclic (the evolution of connectivity at an intersection must respect a cycle) and acyclic (less constrained) policies, and these transferable methods 1) are only compatible with cyclic constraints and 2) do not enable coordination. We introduce a new model-based method, MuJAM, which, on top of enabling explicit coordination at scale for the first time, pushes generalization further by allowing a generalization to the controllers' constraints. In a zero-shot transfer setting involving both road networks and traffic settings never experienced during training, and in a larger transfer experiment involving the control of 3,971 traffic signal controllers in Manhattan, we show that MuJAM, using both cyclic and acyclic constraints, outperforms domain-specific baselines as well as another transferable approach.
Multi-stage warm started optimal motion planning for over-actuated mobile platforms
Jul 29, 2022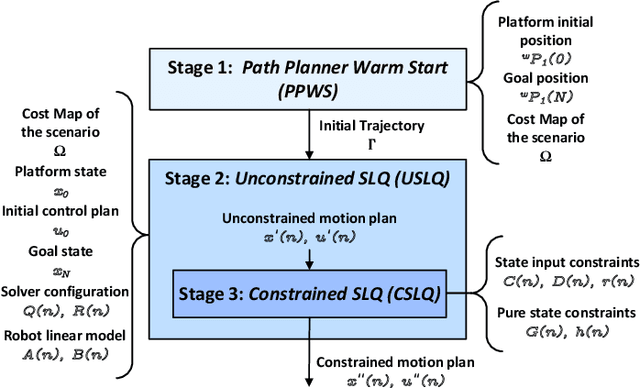
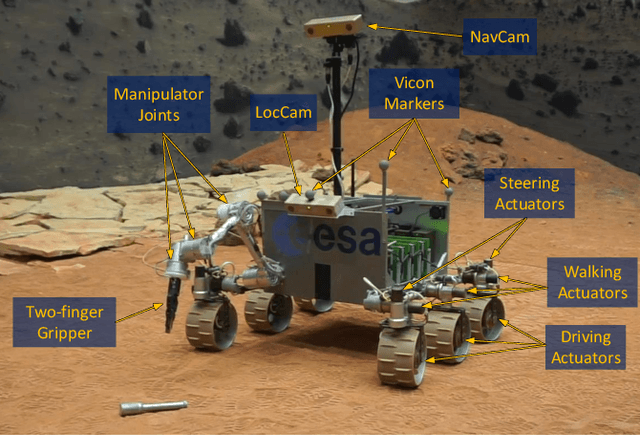
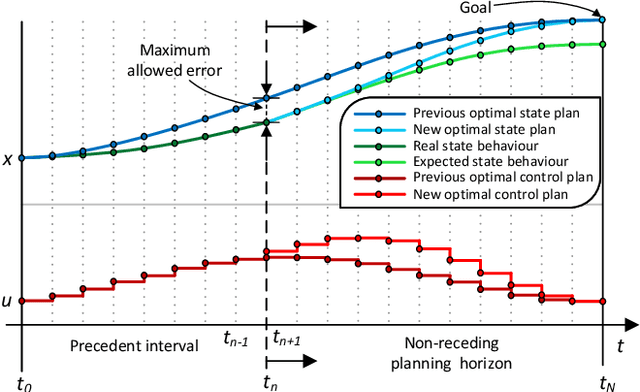
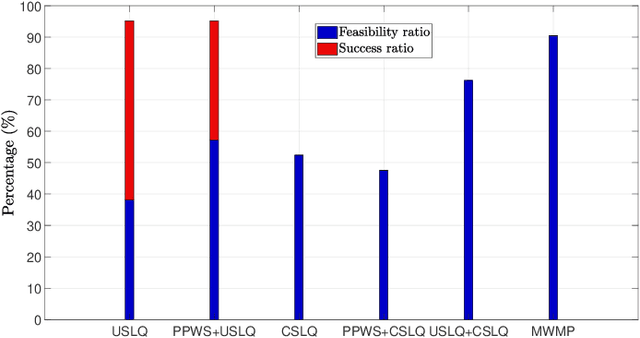
This work presents a computationally lightweight motion planner for over-actuated platforms. For this purpose, a general state-space model for mobile platforms with several kinematic chains is defined, which considers non-linearities and constraints. The proposed motion planner is based on a sequential multi-stage approach that takes advantage of the warm start on each step. Firstly, a globally optimal and smooth 2D/3D trajectory is generated using the Fast Marching Method. This trajectory is fed as a warm start to a sequential linear quadratic regulator that is able to generate an optimal motion plan without constraints for all the platform actuators. Finally, a feasible motion plan is generated considering the constraints defined in the model. In this respect, the sequential linear quadratic regulator is employed again, taking the previously generated unconstrained motion plan as a warm start. This novel approach has been deployed into the Exomars Testing Rover of the European Space Agency. This rover is an Ackermann-capable planetary exploration testbed that is equipped with a robotic arm. Several experiments were carried out demonstrating that the proposed approach speeds up the computation time, increasing the success ratio for a martian sample retrieval mission, which can be considered as a representative use case of an over-actuated mobile platform.
Quantum Quantile Mechanics: Solving Stochastic Differential Equations for Generating Time-Series
Aug 06, 2021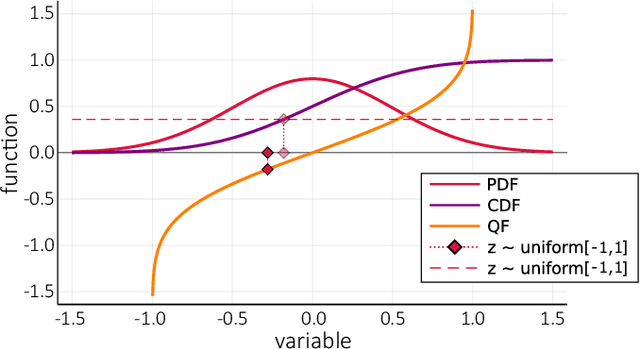
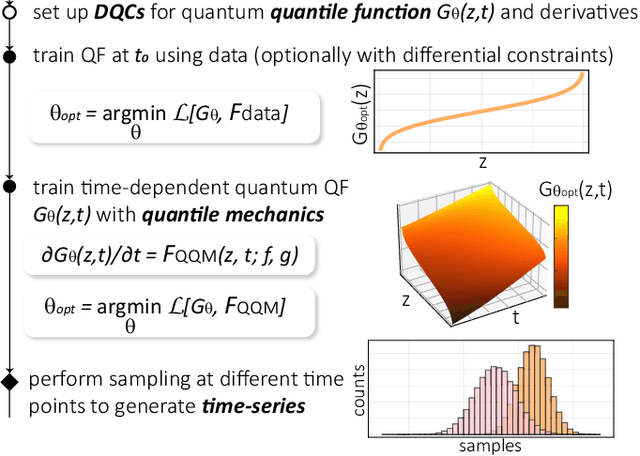

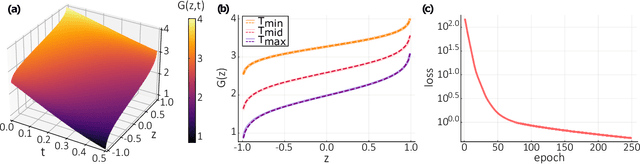
We propose a quantum algorithm for sampling from a solution of stochastic differential equations (SDEs). Using differentiable quantum circuits (DQCs) with a feature map encoding of latent variables, we represent the quantile function for an underlying probability distribution and extract samples as DQC expectation values. Using quantile mechanics we propagate the system in time, thereby allowing for time-series generation. We test the method by simulating the Ornstein-Uhlenbeck process and sampling at times different from the initial point, as required in financial analysis and dataset augmentation. Additionally, we analyse continuous quantum generative adversarial networks (qGANs), and show that they represent quantile functions with a modified (reordered) shape that impedes their efficient time-propagation. Our results shed light on the connection between quantum quantile mechanics (QQM) and qGANs for SDE-based distributions, and point the importance of differential constraints for model training, analogously with the recent success of physics informed neural networks.
FRIB: Low-poisoning Rate Invisible Backdoor Attack based on Feature Repair
Jul 26, 2022

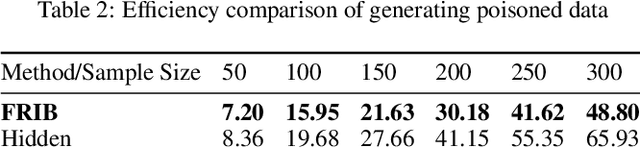
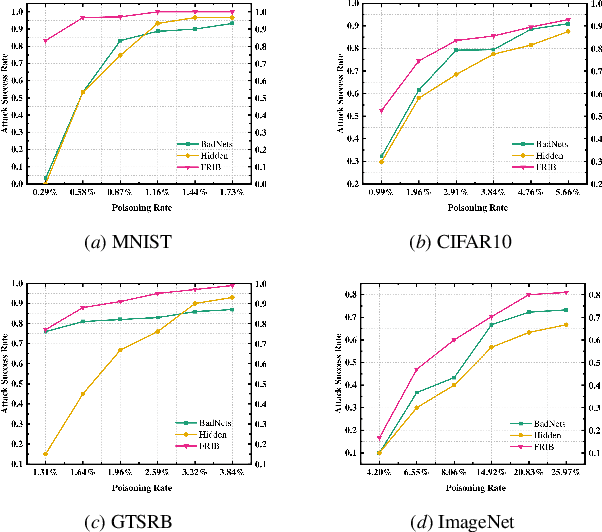
During the generation of invisible backdoor attack poisoned data, the feature space transformation operation tends to cause the loss of some poisoned features and weakens the mapping relationship between source images with triggers and target labels, resulting in the need for a higher poisoning rate to achieve the corresponding backdoor attack success rate. To solve the above problems, we propose the idea of feature repair for the first time and introduce the blind watermark technique to repair the poisoned features lost during the generation of poisoned data. Under the premise of ensuring consistent labeling, we propose a low-poisoning rate invisible backdoor attack based on feature repair, named FRIB. Benefiting from the above design concept, the new method enhances the mapping relationship between the source images with triggers and the target labels, and increases the degree of misleading DNNs, thus achieving a high backdoor attack success rate with a very low poisoning rate. Ultimately, the detailed experimental results show that the goal of achieving a high success rate of backdoor attacks with a very low poisoning rate is achieved on all MNIST, CIFAR10, GTSRB, and ImageNet datasets.
A Spoken Drug Prescription Dataset in French for Spoken Language Understanding
Jul 17, 2022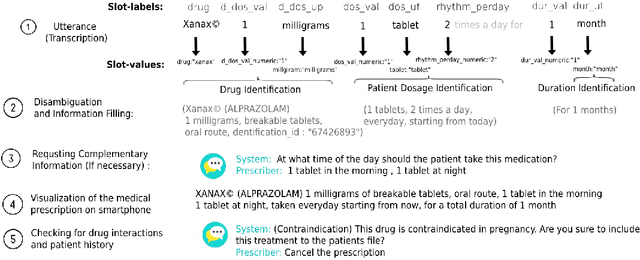
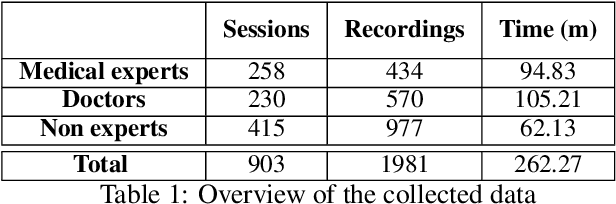


Spoken medical dialogue systems are increasingly attracting interest to enhance access to healthcare services and improve quality and traceability of patient care. In this paper, we focus on medical drug prescriptions acquired on smartphones through spoken dialogue. Such systems would facilitate the traceability of care and would free clinicians' time. However, there is a lack of speech corpora to develop such systems since most of the related corpora are in text form and in English. To facilitate the research and development of spoken medical dialogue systems, we present, to the best of our knowledge, the first spoken medical drug prescriptions corpus, named PxSLU. It contains 4 hours of transcribed and annotated dialogues of drug prescriptions in French acquired through an experiment with 55 participants experts and non-experts in prescriptions. We also present some experiments that demonstrate the interest of this corpus for the evaluation and development of medical dialogue systems.
Fairness Based Energy-Efficient 3D Path Planning of a Portable Access Point: A Deep Reinforcement Learning Approach
Aug 10, 2022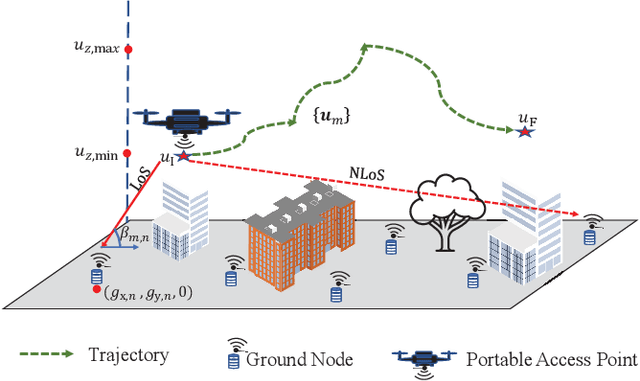
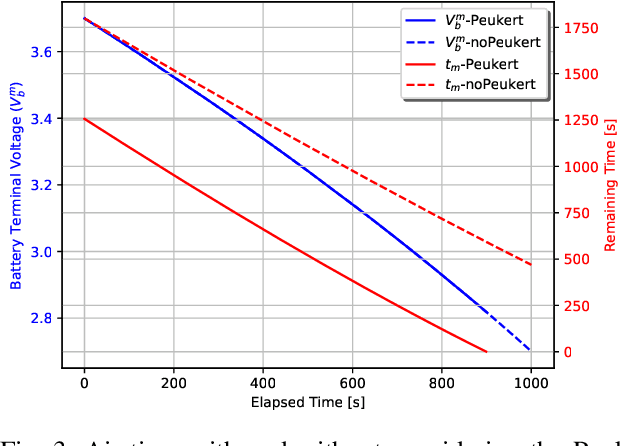
In this work, we optimize the 3D trajectory of an unmanned aerial vehicle (UAV)-based portable access point (PAP) that provides wireless services to a set of ground nodes (GNs). Moreover, as per the Peukert effect, we consider pragmatic non-linear battery discharge for the battery of the UAV. Thus, we formulate the problem in a novel manner that represents the maximization of a fairness-based energy efficiency metric and is named fair energy efficiency (FEE). The FEE metric defines a system that lays importance on both the per-user service fairness and the energy efficiency of the PAP. The formulated problem takes the form of a non-convex problem with non-tractable constraints. To obtain a solution, we represent the problem as a Markov Decision Process (MDP) with continuous state and action spaces. Considering the complexity of the solution space, we use the twin delayed deep deterministic policy gradient (TD3) actor-critic deep reinforcement learning (DRL) framework to learn a policy that maximizes the FEE of the system. We perform two types of RL training to exhibit the effectiveness of our approach: the first (offline) approach keeps the positions of the GNs the same throughout the training phase; the second approach generalizes the learned policy to any arrangement of GNs by changing the positions of GNs after each training episode. Numerical evaluations show that neglecting the Peukert effect overestimates the air-time of the PAP and can be addressed by optimally selecting the PAP's flying speed. Moreover, the user fairness, energy efficiency, and hence the FEE value of the system can be improved by efficiently moving the PAP above the GNs. As such, we notice massive FEE improvements over baseline scenarios of up to 88.31%, 272.34%, and 318.13% for suburban, urban, and dense urban environments, respectively.