 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Interactive Physically-Based Simulation of Roadheader Robot
Jun 29, 2022
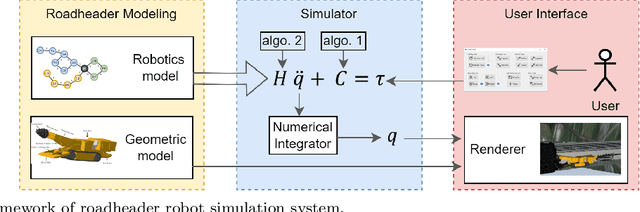
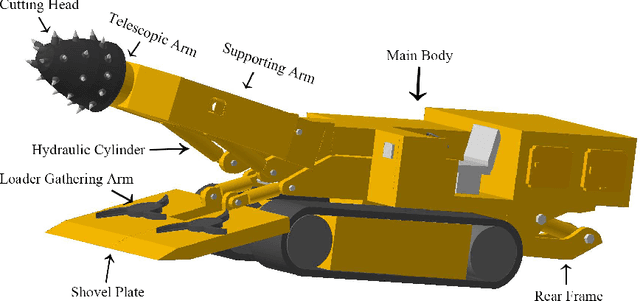

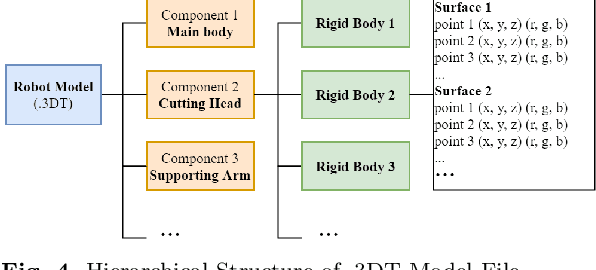
Roadheader is an engineering robot widely used in underground engineering and mining industry. Interactive dynamics simulation of roadheader is a fundamental problem in unmanned excavation and virtual reality training. However, current research is only based on traditional animation techniques or commercial game engines. There are few studies that apply real-time physical simulation of computer graphics to the field of roadheader robot. This paper aims to present an interactive physically-based simulation system of roadheader robot. To this end, an improved multibody simulation method based on generalized coordinates is proposed. First, our simulation method describes robot dynamics based on generalized coordinates. Compared to state-of-the-art methods, our method is more stable and accurate. Numerical simulation results showed that our method has significantly less error than the game engine in the same number of iterations. Second, we adopt the symplectic Euler integrator instead of the conventional fourth-order Runge-Kutta (RK4) method for dynamics iteration. Compared with other integrators, our method is more stable in energy drift during long-term simulation. The test results showed that our system achieved real-time interaction performance of 60 frames per second (fps). Furthermore, we propose a model format for geometric and robotics modeling of roadheaders to implement the system. Our interactive simulation system of roadheader meets the requirements of interactivity, accuracy and stability.
BiometryNet: Landmark-based Fetal Biometry Estimation from Standard Ultrasound Planes
Jun 29, 2022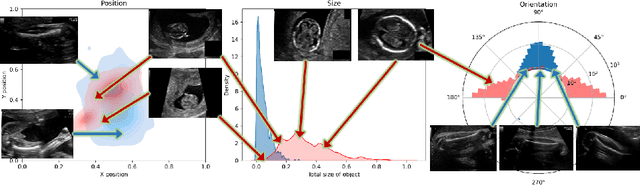
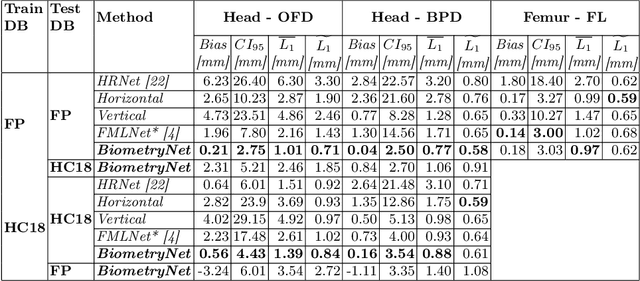
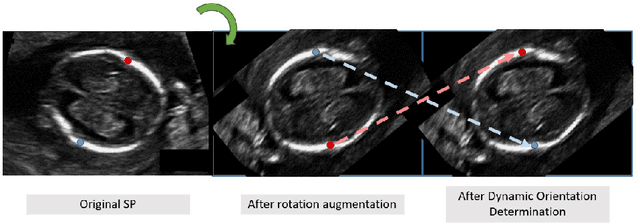
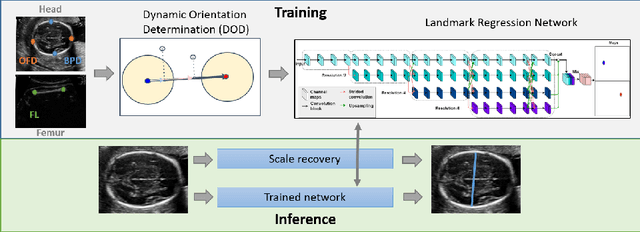
Fetal growth assessment from ultrasound is based on a few biometric measurements that are performed manually and assessed relative to the expected gestational age. Reliable biometry estimation depends on the precise detection of landmarks in standard ultrasound planes. Manual annotation can be time-consuming and operator dependent task, and may results in high measurements variability. Existing methods for automatic fetal biometry rely on initial automatic fetal structure segmentation followed by geometric landmark detection. However, segmentation annotations are time-consuming and may be inaccurate, and landmark detection requires developing measurement-specific geometric methods. This paper describes BiometryNet, an end-to-end landmark regression framework for fetal biometry estimation that overcomes these limitations. It includes a novel Dynamic Orientation Determination (DOD) method for enforcing measurement-specific orientation consistency during network training. DOD reduces variabilities in network training, increases landmark localization accuracy, thus yields accurate and robust biometric measurements. To validate our method, we assembled a dataset of 3,398 ultrasound images from 1,829 subjects acquired in three clinical sites with seven different ultrasound devices. Comparison and cross-validation of three different biometric measurements on two independent datasets shows that BiometryNet is robust and yields accurate measurements whose errors are lower than the clinically permissible errors, outperforming other existing automated biometry estimation methods. Code is available at https://github.com/netanellavisdris/fetalbiometry.
Towards Green ASR: Lossless 4-bit Quantization of a Hybrid TDNN System on the 300-hr Switchboard Corpus
Jun 23, 2022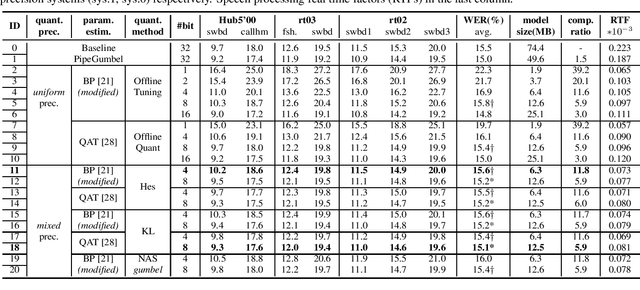
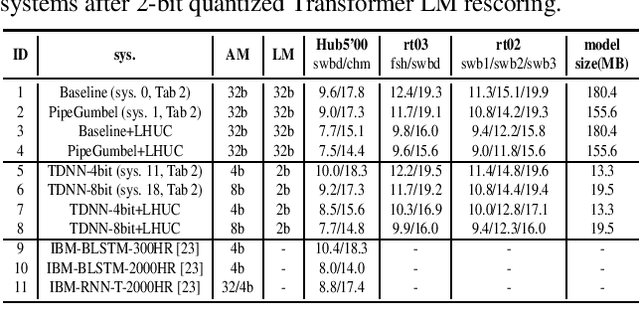
State of the art time automatic speech recognition (ASR) systems are becoming increasingly complex and expensive for practical applications. This paper presents the development of a high performance and low-footprint 4-bit quantized LF-MMI trained factored time delay neural networks (TDNNs) based ASR system on the 300-hr Switchboard corpus. A key feature of the overall system design is to account for the fine-grained, varying performance sensitivity at different model components to quantization errors. To this end, a set of neural architectural compression and mixed precision quantization approaches were used to facilitate hidden layer level auto-configuration of optimal factored TDNN weight matrix subspace dimensionality and quantization bit-widths. The proposed techniques were also used to produce 2-bit mixed precision quantized Transformer language models. Experiments conducted on the Switchboard data suggest that the proposed neural architectural compression and mixed precision quantization techniques consistently outperform the uniform precision quantised baseline systems of comparable bit-widths in terms of word error rate (WER). An overall "lossless" compression ratio of 13.6 was obtained over the baseline full precision system including both the TDNN and Transformer components while incurring no statistically significant WER increase.
Decentralized Bandits with Feedback for Cognitive Radar Networks
Jul 20, 2022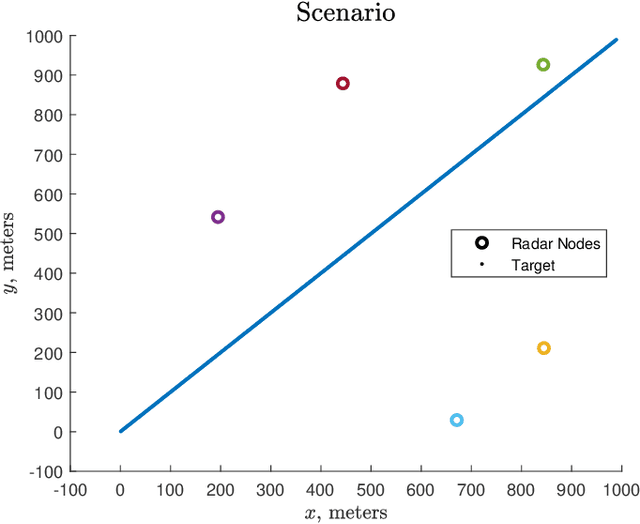
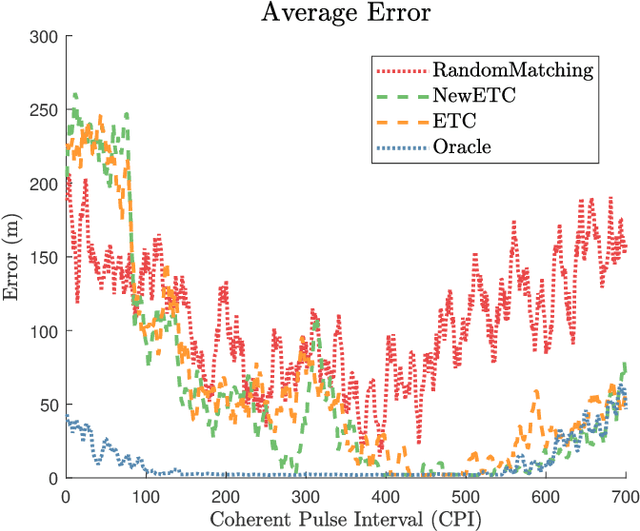
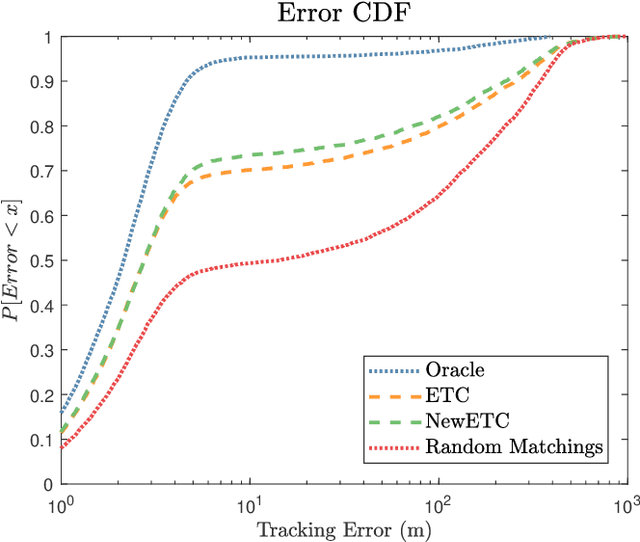
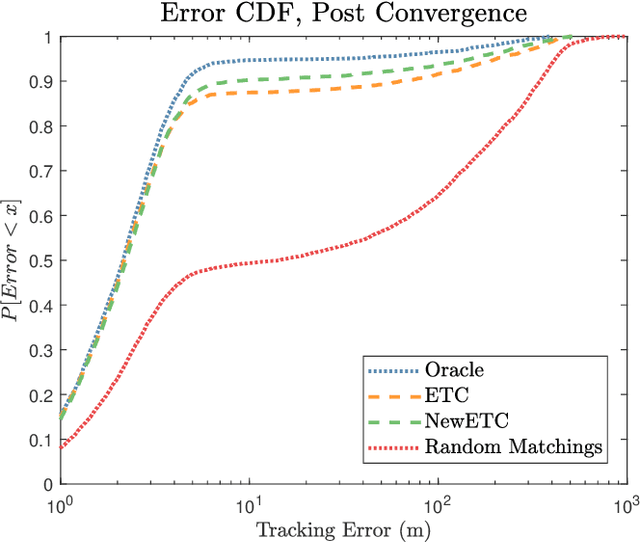
Completely decentralized Multi-Player Bandit models have demonstrated high localization accuracy at the cost of long convergence times in cognitive radar networks. Rather than model each radar node as an independent learner, entirely unable to swap information with other nodes in a network, in this work we construct a "central coordinator" to facilitate the exchange of information between radar nodes. We show that in interference-limited spectrum, where the signal to interference plus noise (SINR) ratio for the available bands may vary by location, a cognitive radar network (CRN) is able to use information from a central coordinator to reduce the number of time steps required to attain a given localization error. Importantly, each node is still able to learn separately. We provide a description of a network which has hybrid cognition in both a central coordinator and in each of the cognitive radar nodes, and examine the online machine learning algorithms which can be implemented in this structure.
Sepsis Prediction with Temporal Convolutional Networks
May 31, 2022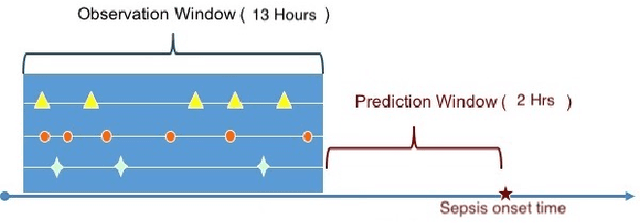

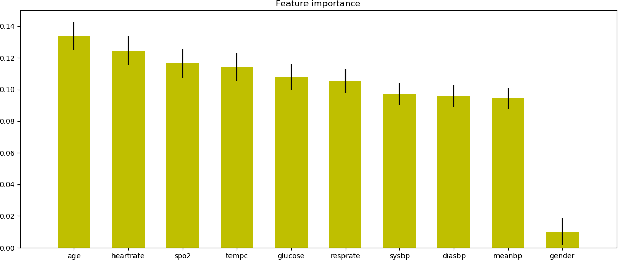
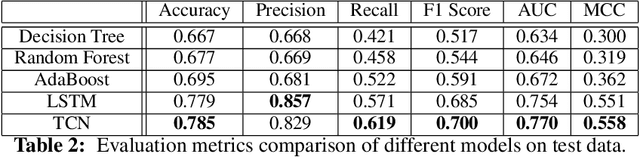
We design and implement a temporal convolutional network model to predict sepsis onset. Our model is trained on data extracted from MIMIC III database, based on a retrospective analysis of patients admitted to intensive care unit who did not fall under the definition of sepsis at the time of admission. Benchmarked with several machine learning models, our model is superior on this binary classification task, demonstrates the prediction power of convolutional networks for temporal patterns, also shows the significant impact of having longer look back time on sepsis prediction.
RealTime QA: What's the Answer Right Now?
Jul 27, 2022
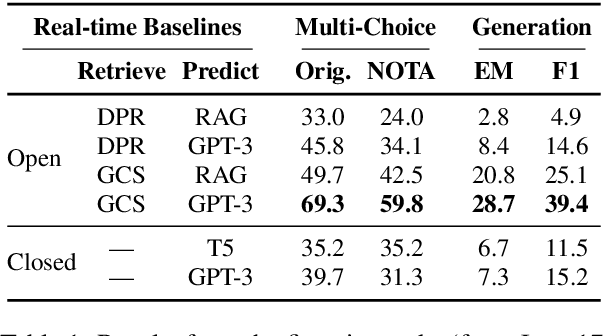
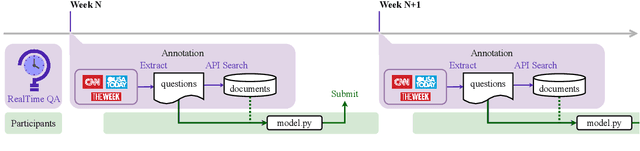
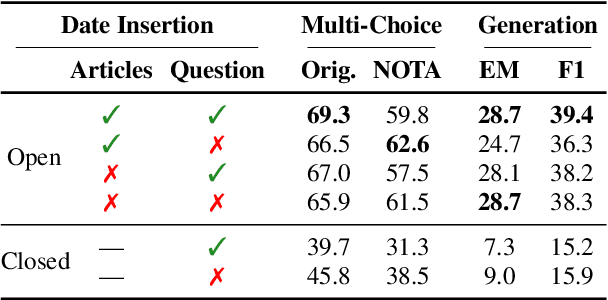
We introduce RealTime QA, a dynamic question answering (QA) platform that announces questions and evaluates systems on a regular basis (weekly in this version). RealTime QA inquires about the current world, and QA systems need to answer questions about novel events or information. It therefore challenges static, conventional assumptions in open domain QA datasets and pursues, instantaneous applications. We build strong baseline models upon large pretrained language models, including GPT-3 and T5. Our benchmark is an ongoing effort, and this preliminary report presents real-time evaluation results over the past month. Our experimental results show that GPT-3 can often properly update its generation results, based on newly-retrieved documents, highlighting the importance of up-to-date information retrieval. Nonetheless, we find that GPT-3 tends to return outdated answers when retrieved documents do not provide sufficient information to find an answer. This suggests an important avenue for future research: can an open domain QA system identify such unanswerable cases and communicate with the user or even the retrieval module to modify the retrieval results? We hope that RealTime QA will spur progress in instantaneous applications of question answering and beyond.
An Embedded Monocular Vision Approach for Ground-Aware Objects Detection and Position Estimation
Jul 20, 2022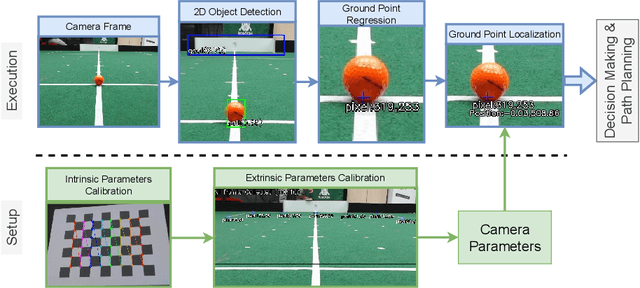



In the RoboCup Small Size League (SSL), teams are encouraged to propose solutions for executing basic soccer tasks inside the SSL field using only embedded sensing information. Thus, this work proposes an embedded monocular vision approach for detecting objects and estimating relative positions inside the soccer field. Prior knowledge from the environment is exploited by assuming objects lay on the ground, and the onboard camera has its position fixed on the robot. We implemented the proposed method on an NVIDIA Jetson Nano and employed SSD MobileNet v2 for 2D Object Detection with TensorRT optimization, detecting balls, robots, and goals with distances up to 3.5 meters. Ball localization evaluation shows that the proposed solution overcomes the currently used SSL vision system for positions closer than 1 meter to the onboard camera with a Root Mean Square Error of 14.37 millimeters. In addition, the proposed method achieves real-time performance with an average processing speed of 30 frames per second.
Quantifying the Effect of Feedback Frequency in Interactive Reinforcement Learning for Robotic Tasks
Jul 20, 2022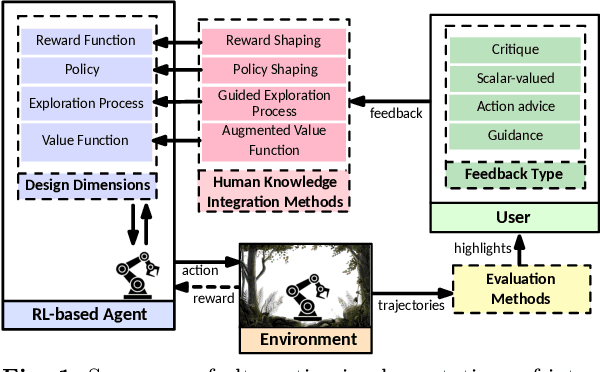
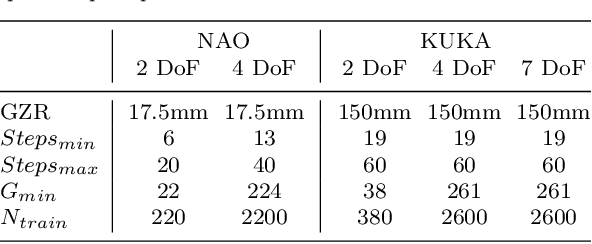
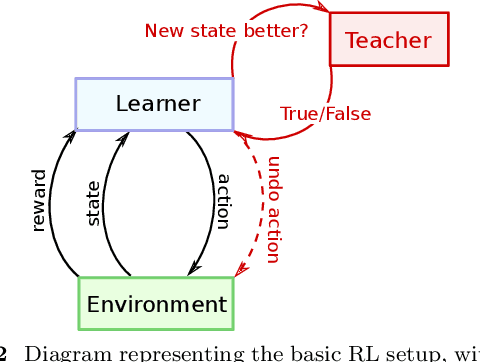
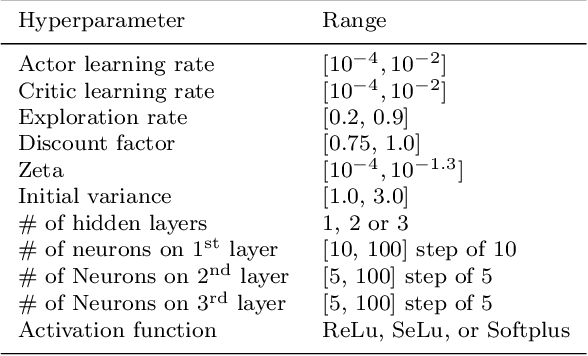
Reinforcement learning (RL) has become widely adopted in robot control. Despite many successes, one major persisting problem can be very low data efficiency. One solution is interactive feedback, which has been shown to speed up RL considerably. As a result, there is an abundance of different strategies, which are, however, primarily tested on discrete grid-world and small scale optimal control scenarios. In the literature, there is no consensus about which feedback frequency is optimal or at which time the feedback is most beneficial. To resolve these discrepancies we isolate and quantify the effect of feedback frequency in robotic tasks with continuous state and action spaces. The experiments encompass inverse kinematics learning for robotic manipulator arms of different complexity. We show that seemingly contradictory reported phenomena occur at different complexity levels. Furthermore, our results suggest that no single ideal feedback frequency exists. Rather that feedback frequency should be changed as the agent's proficiency in the task increases.
JDRec: Practical Actor-Critic Framework for Online Combinatorial Recommender System
Jul 27, 2022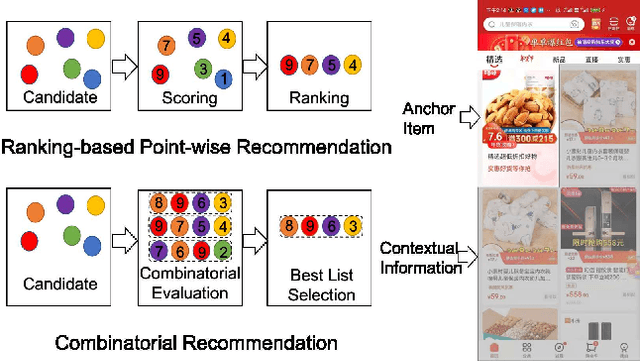

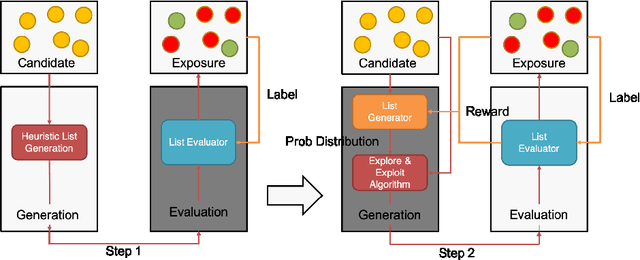

A combinatorial recommender (CR) system feeds a list of items to a user at a time in the result page, in which the user behavior is affected by both contextual information and items. The CR is formulated as a combinatorial optimization problem with the objective of maximizing the recommendation reward of the whole list. Despite its importance, it is still a challenge to build a practical CR system, due to the efficiency, dynamics, personalization requirement in online environment. In particular, we tear the problem into two sub-problems, list generation and list evaluation. Novel and practical model architectures are designed for these sub-problems aiming at jointly optimizing effectiveness and efficiency. In order to adapt to online case, a bootstrap algorithm forming an actor-critic reinforcement framework is given to explore better recommendation mode in long-term user interaction. Offline and online experiment results demonstrate the efficacy of proposed JDRec framework. JDRec has been applied in online JD recommendation, improving click through rate by 2.6% and synthetical value for the platform by 5.03%. We will publish the large-scale dataset used in this study to contribute to the research community.
Towards Grand Unification of Object Tracking
Jul 18, 2022
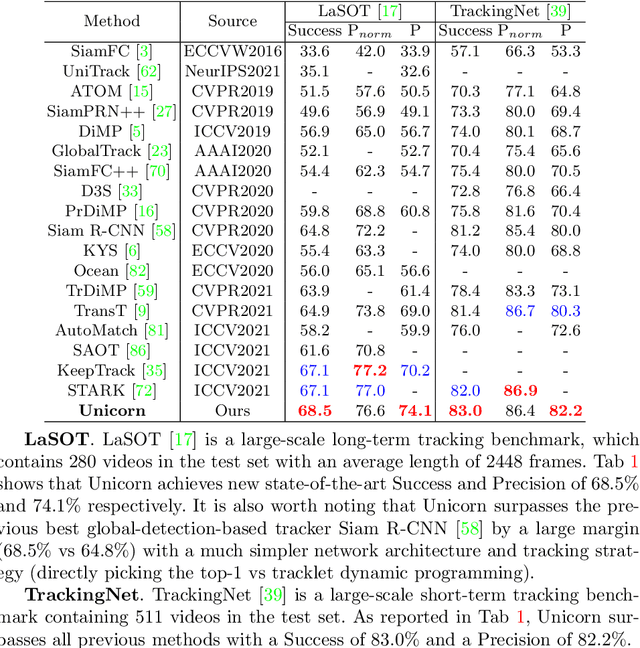
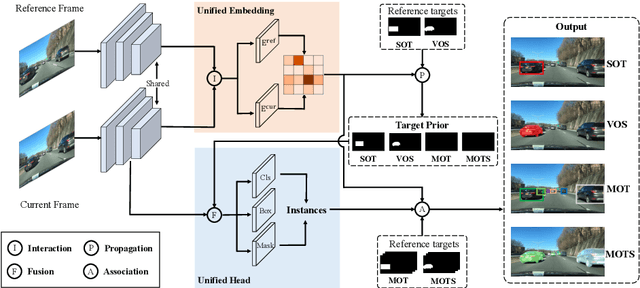
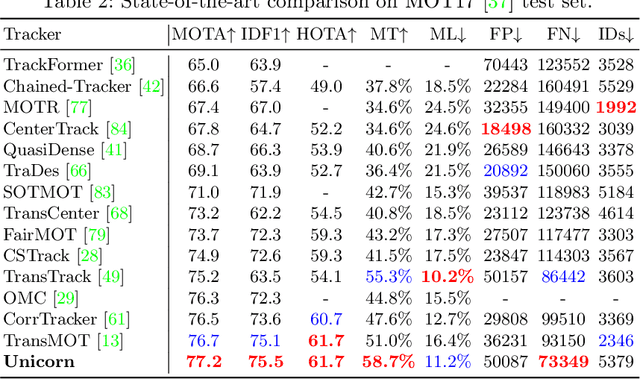
We present a unified method, termed Unicorn, that can simultaneously solve four tracking problems (SOT, MOT, VOS, MOTS) with a single network using the same model parameters. Due to the fragmented definitions of the object tracking problem itself, most existing trackers are developed to address a single or part of tasks and overspecialize on the characteristics of specific tasks. By contrast, Unicorn provides a unified solution, adopting the same input, backbone, embedding, and head across all tracking tasks. For the first time, we accomplish the great unification of the tracking network architecture and learning paradigm. Unicorn performs on-par or better than its task-specific counterparts in 8 tracking datasets, including LaSOT, TrackingNet, MOT17, BDD100K, DAVIS16-17, MOTS20, and BDD100K MOTS. We believe that Unicorn will serve as a solid step towards the general vision model. Code is available at https://github.com/MasterBin-IIAU/Unicorn.