 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Advances of Artificial Intelligence in Classical and Novel Spectroscopy-Based Approaches for Cancer Diagnostics. A Review
Aug 08, 2022
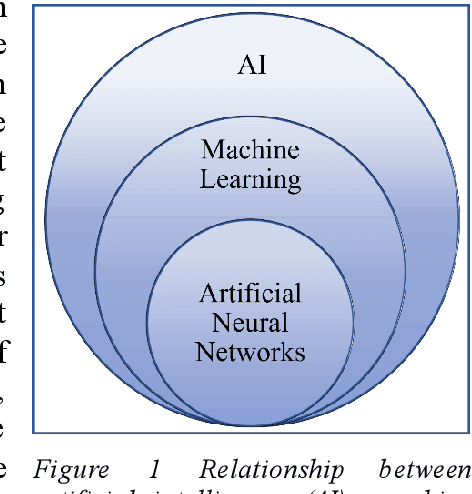

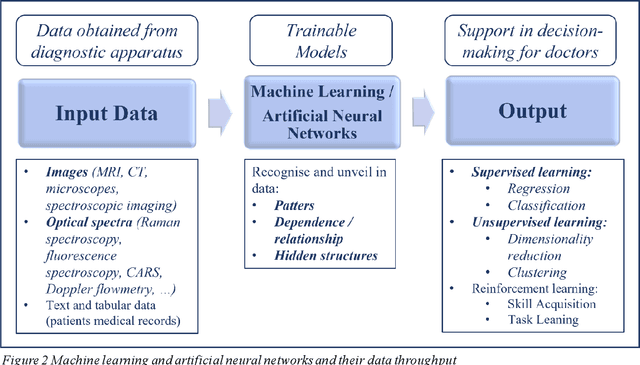
Cancer is one of the leading causes of death worldwide. Fast and safe early-stage, pre- and intra-operative diagnostics can significantly contribute to successful cancer identification and treatment. Artificial intelligence has played an increasing role in the enhancement of cancer diagnostics techniques in the last 15 years. This review covers the advances of artificial intelligence applications in well-established techniques such as MRI and CT. Also, it shows its high potential in combination with optical spectroscopy-based approaches that are under development for mobile, ultra-fast, and low-invasive diagnostics. I will show how spectroscopy-based approaches can reduce the time of tissue preparation for pathological analysis by making thin-slicing or haematoxylin-and-eosin staining obsolete. I will present examples of spectroscopic tools for fast and low-invasive ex- and in-vivo tissue classification for the determination of a tumour and its boundaries. Also, I will discuss that, contrary to MRI and CT, spectroscopic measurements do not require the administration of chemical agents to enhance the quality of cancer imaging which contributes to the development of more secure diagnostic methods. Overall, we will see that the combination of spectroscopy and artificial intelligence constitutes a highly promising and fast-developing field of medical technology that will soon augment available cancer diagnostic methods.
Dynamic Time Warping Clustering to Discover Socio-Economic Characteristics in Smart Water Meter Data
Dec 28, 2021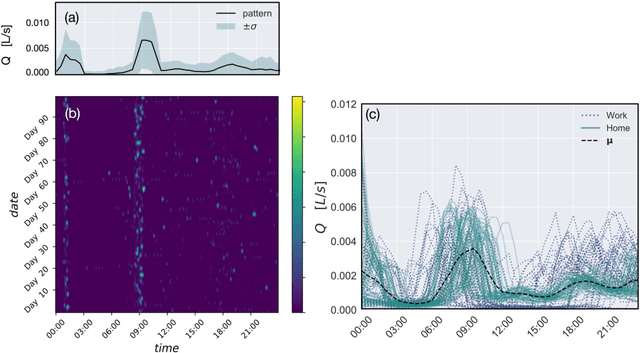
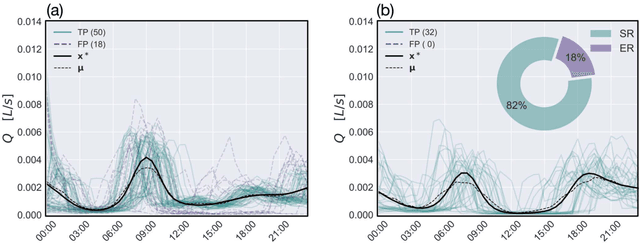
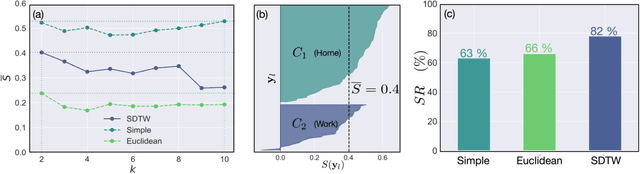
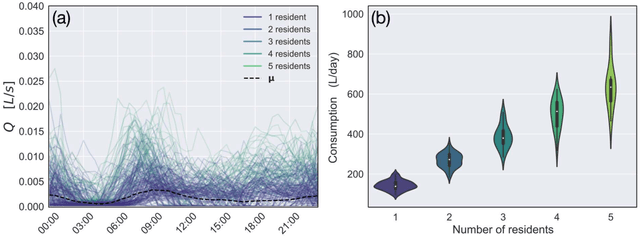
Socio-economic characteristics are influencing the temporal and spatial variability of water demand - the biggest source of uncertainties within water distribution system modeling. Improving our knowledge on these influences can be utilized to decrease demand uncertainties. This paper aims to link smart water meter data to socio-economic user characteristics by applying a novel clustering algorithm that uses dynamic time warping on daily demand patterns. The approach is tested on simulated and measured single family home datasets. We show that the novel algorithm performs better compared to commonly used clustering methods, both, in finding the right number of clusters as well as assigning patterns correctly. Additionally, the methodology can be used to identify outliers within clusters of demand patterns. Furthermore, this study investigates which socio-economic characteristics (e.g. employment status, number of residents) are prevalent within single clusters and, consequently, can be linked to the shape of the cluster's barycenters. In future, the proposed methods in combination with stochastic demand models can be used to fill data-gaps in hydraulic models.
* 16 pages, 8 figures
What Can be Seen is What You Get: Structure Aware Point Cloud Augmentation
Jun 20, 2022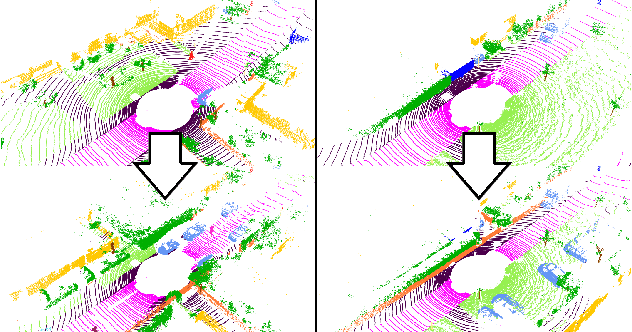
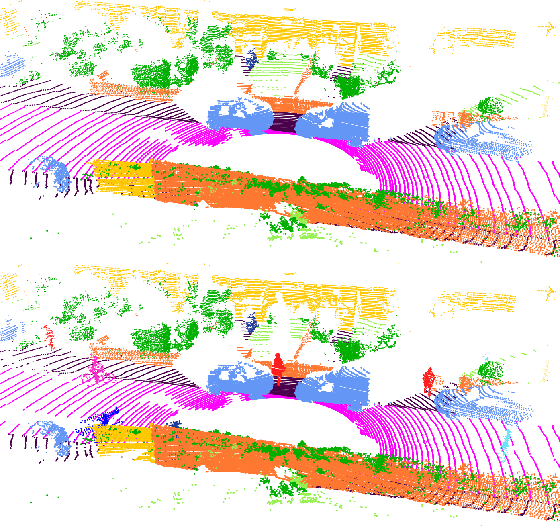
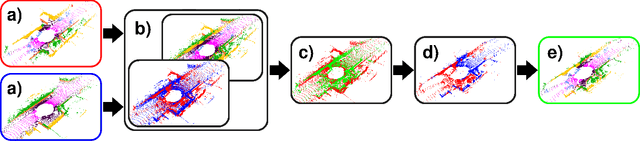
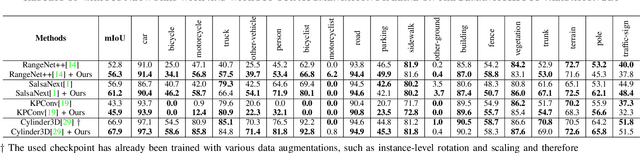
To train a well performing neural network for semantic segmentation, it is crucial to have a large dataset with available ground truth for the network to generalize on unseen data. In this paper we present novel point cloud augmentation methods to artificially diversify a dataset. Our sensor-centric methods keep the data structure consistent with the lidar sensor capabilities. Due to these new methods, we are able to enrich low-value data with high-value instances, as well as create entirely new scenes. We validate our methods on multiple neural networks with the public SemanticKITTI dataset and demonstrate that all networks improve compared to their respective baseline. In addition, we show that our methods enable the use of very small datasets, saving annotation time, training time and the associated costs.
* Published in IEEE IV 2022
Entropy Induced Pruning Framework for Convolutional Neural Networks
Aug 13, 2022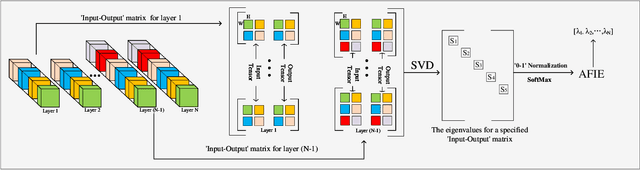
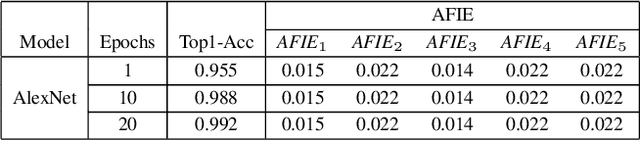
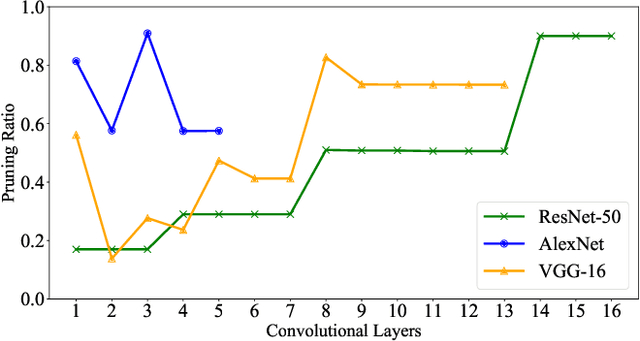

Structured pruning techniques have achieved great compression performance on convolutional neural networks for image classification task. However, the majority of existing methods are weight-oriented, and their pruning results may be unsatisfactory when the original model is trained poorly. That is, a fully-trained model is required to provide useful weight information. This may be time-consuming, and the pruning results are sensitive to the updating process of model parameters. In this paper, we propose a metric named Average Filter Information Entropy (AFIE) to measure the importance of each filter. It is calculated by three major steps, i.e., low-rank decomposition of the "input-output" matrix of each convolutional layer, normalization of the obtained eigenvalues, and calculation of filter importance based on information entropy. By leveraging the proposed AFIE, the proposed framework is able to yield a stable importance evaluation of each filter no matter whether the original model is trained fully. We implement our AFIE based on AlexNet, VGG-16, and ResNet-50, and test them on MNIST, CIFAR-10, and ImageNet, respectively. The experimental results are encouraging. We surprisingly observe that for our methods, even when the original model is only trained with one epoch, the importance evaluation of each filter keeps identical to the results when the model is fully-trained. This indicates that the proposed pruning strategy can perform effectively at the beginning stage of the training process for the original model.
Automaton-Guided Control Synthesis for Signal Temporal Logic Specifications
Jul 17, 2022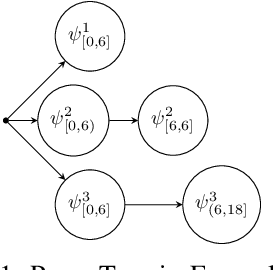
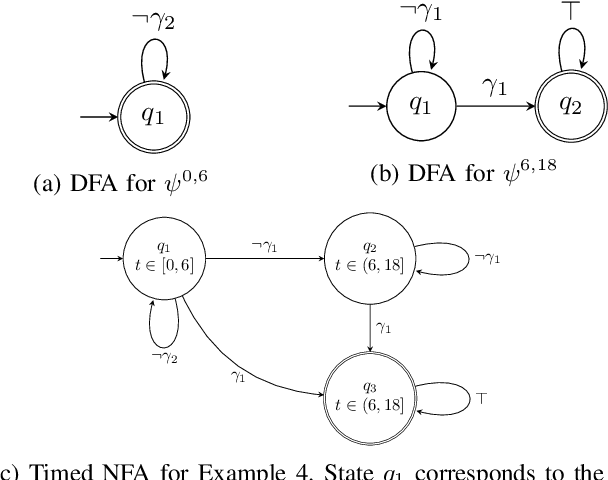
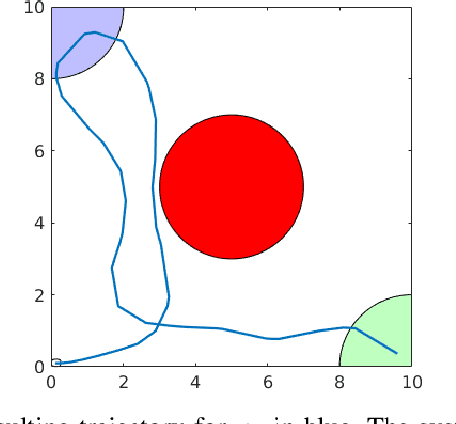
This paper presents an algorithmic framework for control synthesis of continuous dynamical systems subject to signal temporal logic (STL) specifications. We propose a novel algorithm to obtain a time-partitioned finite automaton from an STL specification, and introduce a multi-layered framework that utilizes this automaton to guide a sampling-based search tree both spatially and temporally. Our approach is able to synthesize a controller for nonlinear dynamics and polynomial predicate functions. We prove the correctness and probabilistic completeness of our algorithm, and illustrate the efficiency and efficacy of our framework on several case studies. Our results show an order of magnitude speedup over the state of the art.
Longitudinal detection of new MS lesions using Deep Learning
Jun 16, 2022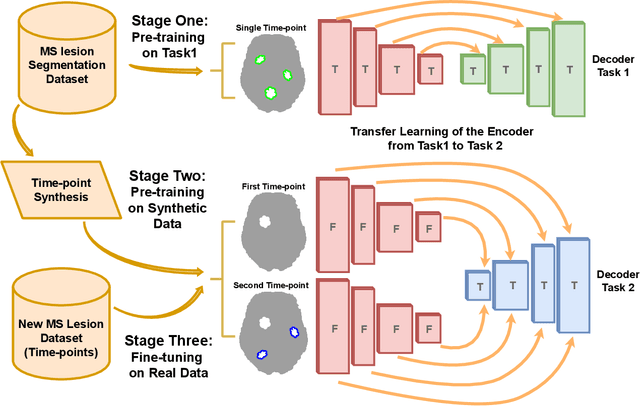

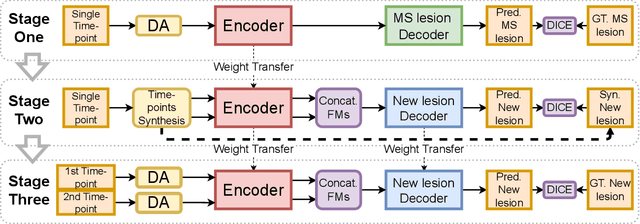
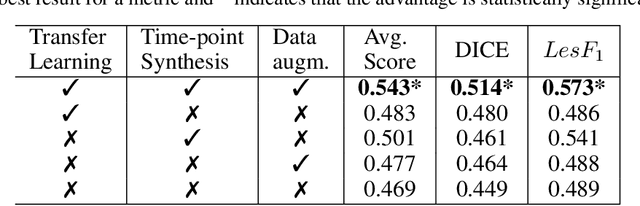
The detection of new multiple sclerosis (MS) lesions is an important marker of the evolution of the disease. The applicability of learning-based methods could automate this task efficiently. However, the lack of annotated longitudinal data with new-appearing lesions is a limiting factor for the training of robust and generalizing models. In this work, we describe a deep-learning-based pipeline addressing the challenging task of detecting and segmenting new MS lesions. First, we propose to use transfer-learning from a model trained on a segmentation task using single time-points. Therefore, we exploit knowledge from an easier task and for which more annotated datasets are available. Second, we propose a data synthesis strategy to generate realistic longitudinal time-points with new lesions using single time-point scans. In this way, we pretrain our detection model on large synthetic annotated datasets. Finally, we use a data-augmentation technique designed to simulate data diversity in MRI. By doing that, we increase the size of the available small annotated longitudinal datasets. Our ablation study showed that each contribution lead to an enhancement of the segmentation accuracy. Using the proposed pipeline, we obtained the best score for the segmentation and the detection of new MS lesions in the MSSEG2 MICCAI challenge.
Minimax Mixing Time of the Metropolis-Adjusted Langevin Algorithm for Log-Concave Sampling
Sep 27, 2021
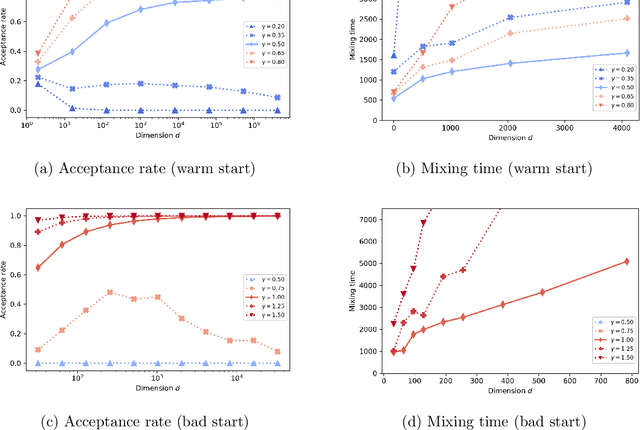
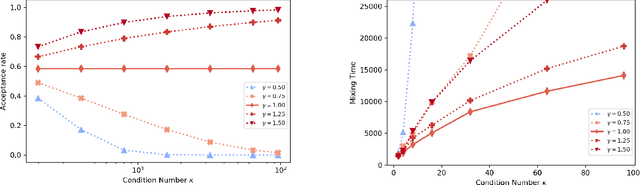
We study the mixing time of the Metropolis-adjusted Langevin algorithm (MALA) for sampling from a log-smooth and strongly log-concave distribution. We establish its optimal minimax mixing time under a warm start. Our main contribution is two-fold. First, for a $d$-dimensional log-concave density with condition number $\kappa$, we show that MALA with a warm start mixes in $\tilde O(\kappa \sqrt{d})$ iterations up to logarithmic factors. This improves upon the previous work on the dependency of either the condition number $\kappa$ or the dimension $d$. Our proof relies on comparing the leapfrog integrator with the continuous Hamiltonian dynamics, where we establish a new concentration bound for the acceptance rate. Second, we prove a spectral gap based mixing time lower bound for reversible MCMC algorithms on general state spaces. We apply this lower bound result to construct a hard distribution for which MALA requires at least $\tilde \Omega (\kappa \sqrt{d})$ steps to mix. The lower bound for MALA matches our upper bound in terms of condition number and dimension. Finally, numerical experiments are included to validate our theoretical results.
Nonparametric Extrema Analysis in Time Series for Envelope Extraction, Peak Detection and Clustering
Sep 05, 2021In this paper, we propose a nonparametric approach that can be used in envelope extraction, peak-burst detection and clustering in time series. Our problem formalization results in a naturally defined splitting/forking of the time series. With a possibly hierarchical implementation, it can be used for various applications in machine learning, signal processing and mathematical finance. From an incoming input signal, our iterative procedure sequentially creates two signals (one upper bounding and one lower bounding signal) by minimizing the cumulative $L_1$ drift. We show that a solution can be efficiently calculated by use of a Viterbi-like path tracking algorithm together with an optimal elimination rule. We consider many interesting settings, where our algorithm has near-linear time complexities.
COBRA: Cpu-Only aBdominal oRgan segmentAtion
Jul 21, 2022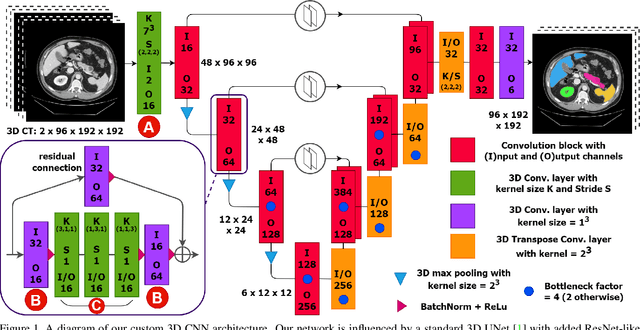

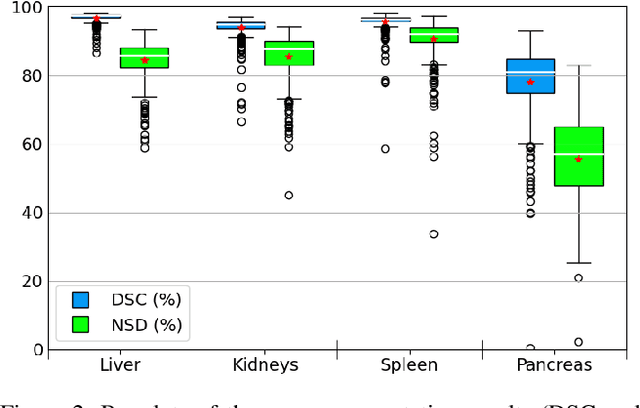
Abdominal organ segmentation is a difficult and time-consuming task. To reduce the burden on clinical experts, fully-automated methods are highly desirable. Current approaches are dominated by Convolutional Neural Networks (CNNs) however the computational requirements and the need for large data sets limit their application in practice. By implementing a small and efficient custom 3D CNN, compiling the trained model and optimizing the computational graph: our approach produces high accuracy segmentations (Dice Similarity Coefficient (%): Liver: 97.3$\pm$1.3, Kidneys: 94.8$\pm$3.6, Spleen: 96.4$\pm$3.0, Pancreas: 80.9$\pm$10.1) at a rate of 1.6 seconds per image. Crucially, we are able to perform segmentation inference solely on CPU (no GPU required), thereby facilitating easy and widespread deployment of the model without specialist hardware.
Joint Beam Placement and Load Balancing Optimization for Non-Geostationary Satellite Systems
Jul 29, 2022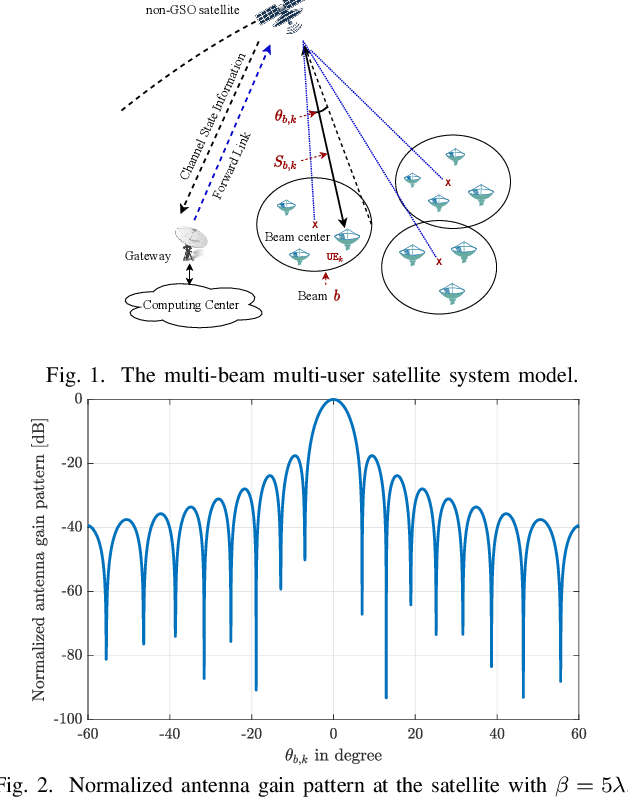
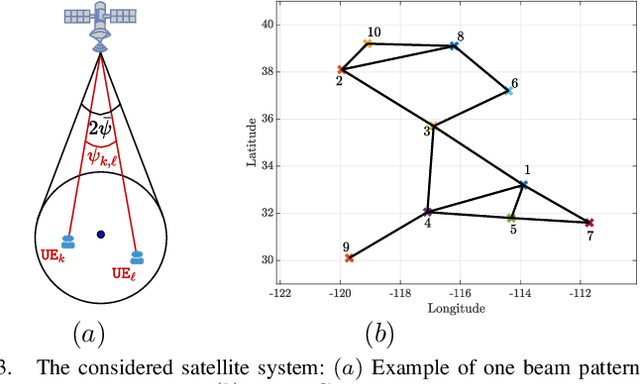
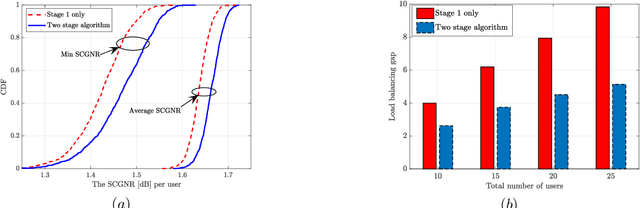
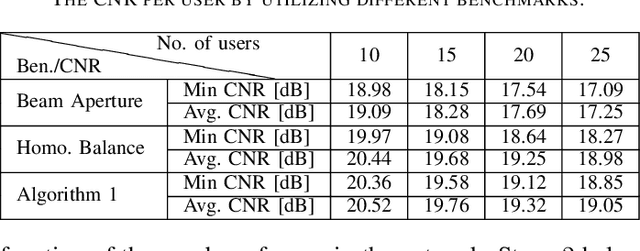
Non-geostationary (Non-GSO) satellite constellations have emerged as a promising solution to enable ubiquitous high-speed low-latency broadband services by generating multiple spot-beams placed on the ground according to the user locations. However, there is an inherent trade-off between the number of active beams and the complexity of generating a large number of beams. This paper formulates and solves a joint beam placement and load balancing problem to carefully optimize the satellite beam and enhance the link budgets with a minimal number of active beams. We propose a two-stage algorithm design to overcome the combinatorial structure of the considered optimization problem providing a solution in polynomial time. The first stage minimizes the number of active beams, while the second stage performs a load balancing to distribute users in the coverage area of the active beams. Numerical results confirm the benefits of the proposed methodology both in carrier-to-noise ratio and multiplexed users per beam over other benchmarks.