 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Low Complexity First: Duration-Centric ISI Mitigation in Molecular Communication via Diffusion
Jul 19, 2022
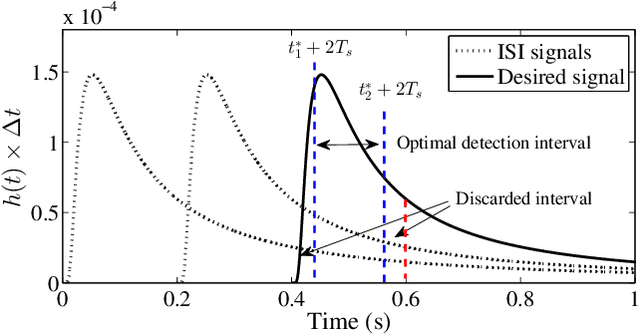
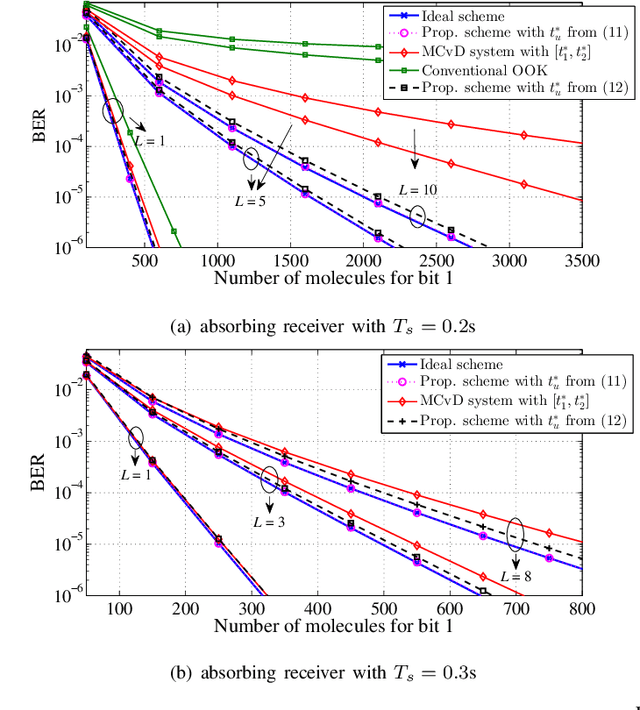
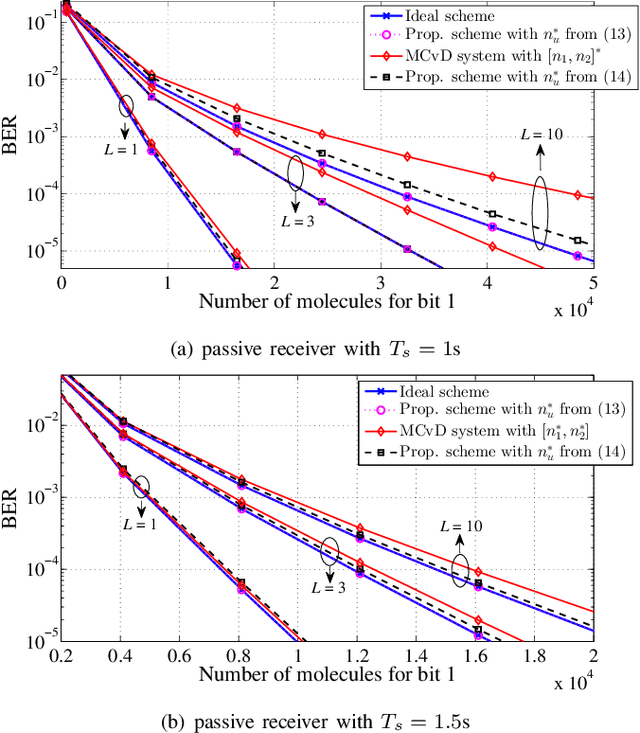
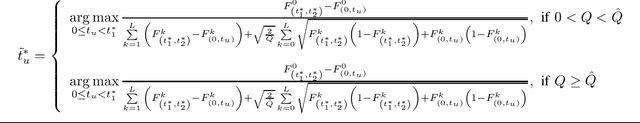
In this paper, we propose a novel inter-symbol interference (ISI) mitigation scheme for molecular communication via diffusion (MCvD) systems with the optimal detection interval. Its rationale is to exploit the discarded duration (i.e., the symbol duration outside this optimal interval) to relieve ISI in the target system. Following this idea, we formulate an objective function to quantify the impact of the discarded time on bit error rate (BER) performance. Besides, an optimally reusable interval within the discarded duration is derived in closed form, which applies to both the absorbing and passive receivers. Finally, numerical results validate our analysis and show that for the considered MCvD system, significant BER improvements can be achieved by using the derived reusable duration.
Folding Knots Using a Team of Aerial Robots
Aug 02, 2022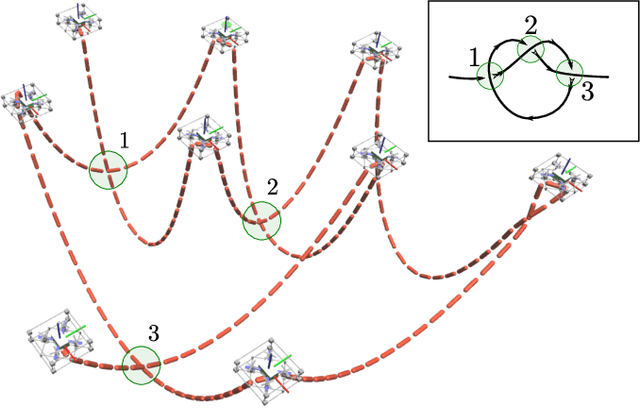
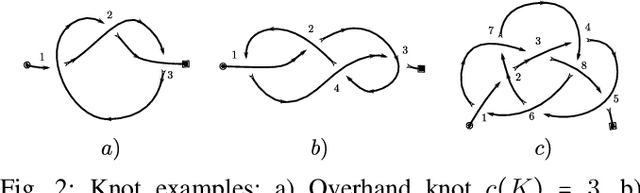
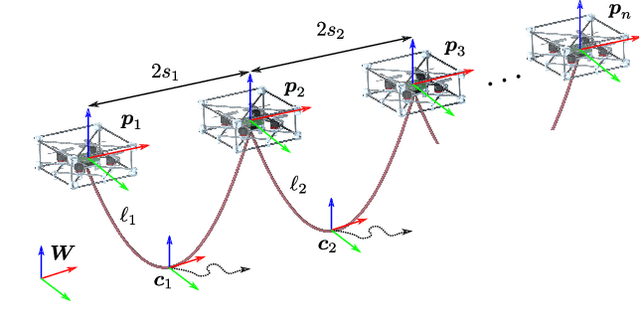

From ancient times, humans have been using cables and ropes to tie, carry, and manipulate objects by folding knots. However, automating knot folding is challenging because it requires dexterity to move a cable over and under itself. In this paper, we propose a method to fold knots in midair using a team of aerial vehicles. We take advantage of the fact that vehicles are able to fly in between cable segments without any re-grasping. So the team grasps the cable from the floor, and releases it once the knot is folded. Based on a composition of catenary curves, we simplify the complexity of dealing with an infinite-dimensional configuration space of the cable, and formally propose a new knot representation. Such representation allows us to design a trajectory that can be used to fold knots using a leader-follower approach. We show that our method works for different types of knots in simulations. Additionally, we show that our solution is also computationally efficient and can be executed in real-time.
Predictor-corrector algorithms for stochastic optimization under gradual distribution shift
May 26, 2022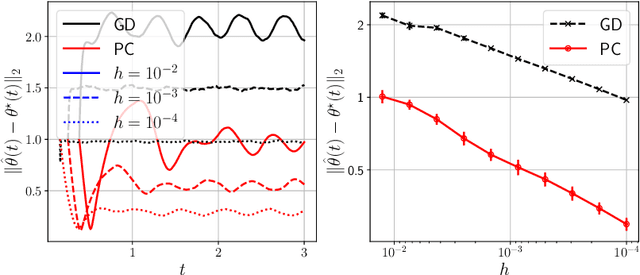
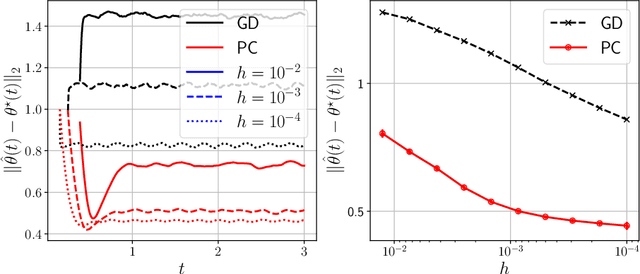
Time-varying stochastic optimization problems frequently arise in machine learning practice (e.g. gradual domain shift, object tracking, strategic classification). Although most problems are solved in discrete time, the underlying process is often continuous in nature. We exploit this underlying continuity by developing predictor-corrector algorithms for time-varying stochastic optimizations. We provide error bounds for the iterates, both in presence of pure and noisy access to the queries from the relevant derivatives of the loss function. Furthermore, we show (theoretically and empirically in several examples) that our method outperforms non-predictor corrector methods that do not exploit the underlying continuous process.
Dynamic Time Warping Clustering to Discover Socio-Economic Characteristics in Smart Water Meter Data
Dec 28, 2021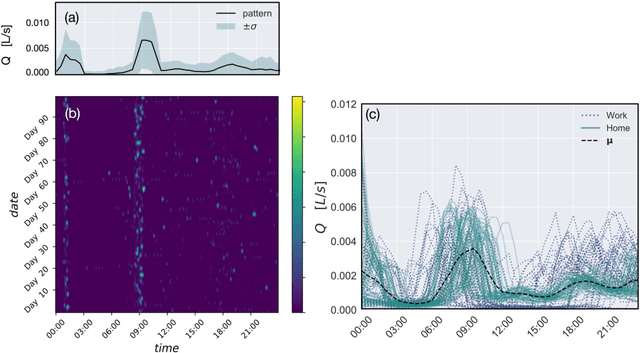
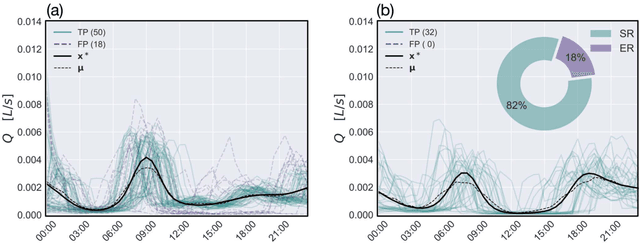
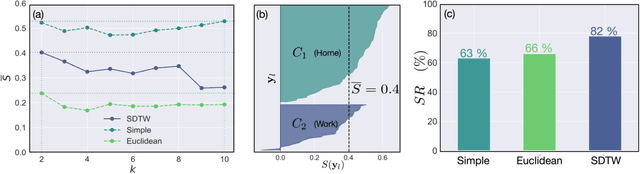
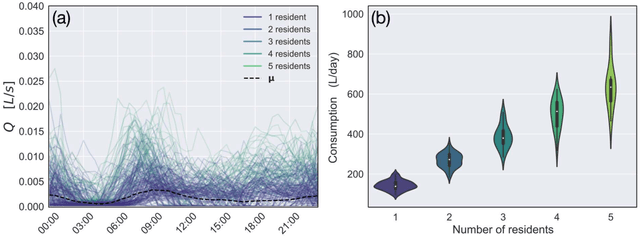
Socio-economic characteristics are influencing the temporal and spatial variability of water demand - the biggest source of uncertainties within water distribution system modeling. Improving our knowledge on these influences can be utilized to decrease demand uncertainties. This paper aims to link smart water meter data to socio-economic user characteristics by applying a novel clustering algorithm that uses dynamic time warping on daily demand patterns. The approach is tested on simulated and measured single family home datasets. We show that the novel algorithm performs better compared to commonly used clustering methods, both, in finding the right number of clusters as well as assigning patterns correctly. Additionally, the methodology can be used to identify outliers within clusters of demand patterns. Furthermore, this study investigates which socio-economic characteristics (e.g. employment status, number of residents) are prevalent within single clusters and, consequently, can be linked to the shape of the cluster's barycenters. In future, the proposed methods in combination with stochastic demand models can be used to fill data-gaps in hydraulic models.
* 16 pages, 8 figures
Active Learning for Non-Parametric Choice Models
Aug 05, 2022


We study the problem of actively learning a non-parametric choice model based on consumers' decisions. We present a negative result showing that such choice models may not be identifiable. To overcome the identifiability problem, we introduce a directed acyclic graph (DAG) representation of the choice model, which in a sense captures as much information about the choice model as could information-theoretically be identified. We then consider the problem of learning an approximation to this DAG representation in an active-learning setting. We design an efficient active-learning algorithm to estimate the DAG representation of the non-parametric choice model, which runs in polynomial time when the set of frequent rankings is drawn uniformly at random. Our algorithm learns the distribution over the most popular items of frequent preferences by actively and repeatedly offering assortments of items and observing the item chosen. We show that our algorithm can better recover a set of frequent preferences on both a synthetic and publicly available dataset on consumers' preferences, compared to the corresponding non-active learning estimation algorithms. This demonstrates the value of our algorithm and active-learning approaches more generally.
Nonparametric Extrema Analysis in Time Series for Envelope Extraction, Peak Detection and Clustering
Sep 05, 2021In this paper, we propose a nonparametric approach that can be used in envelope extraction, peak-burst detection and clustering in time series. Our problem formalization results in a naturally defined splitting/forking of the time series. With a possibly hierarchical implementation, it can be used for various applications in machine learning, signal processing and mathematical finance. From an incoming input signal, our iterative procedure sequentially creates two signals (one upper bounding and one lower bounding signal) by minimizing the cumulative $L_1$ drift. We show that a solution can be efficiently calculated by use of a Viterbi-like path tracking algorithm together with an optimal elimination rule. We consider many interesting settings, where our algorithm has near-linear time complexities.
Minimax Mixing Time of the Metropolis-Adjusted Langevin Algorithm for Log-Concave Sampling
Sep 27, 2021
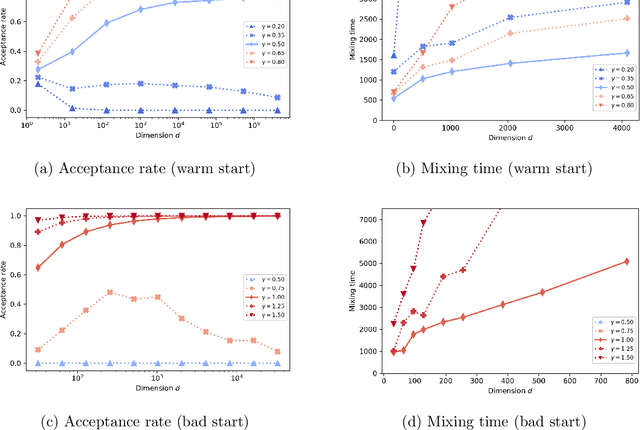
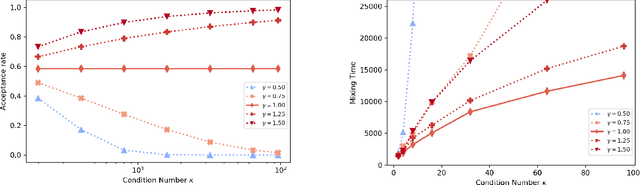
We study the mixing time of the Metropolis-adjusted Langevin algorithm (MALA) for sampling from a log-smooth and strongly log-concave distribution. We establish its optimal minimax mixing time under a warm start. Our main contribution is two-fold. First, for a $d$-dimensional log-concave density with condition number $\kappa$, we show that MALA with a warm start mixes in $\tilde O(\kappa \sqrt{d})$ iterations up to logarithmic factors. This improves upon the previous work on the dependency of either the condition number $\kappa$ or the dimension $d$. Our proof relies on comparing the leapfrog integrator with the continuous Hamiltonian dynamics, where we establish a new concentration bound for the acceptance rate. Second, we prove a spectral gap based mixing time lower bound for reversible MCMC algorithms on general state spaces. We apply this lower bound result to construct a hard distribution for which MALA requires at least $\tilde \Omega (\kappa \sqrt{d})$ steps to mix. The lower bound for MALA matches our upper bound in terms of condition number and dimension. Finally, numerical experiments are included to validate our theoretical results.
An Open Source Interactive Visual Analytics Tool for Comparative Programming Comprehension
Jul 29, 2022



This paper proposes an open source visual analytics tool consisting of several views and perspectives on eye movement data collected during code reading tasks when writing computer programs. Hence the focus of this work is on code and program comprehension. The source code is shown as a visual stimulus. It can be inspected in combination with overlaid scanpaths in which the saccades can be visually encoded in several forms, including straight, curved, and orthogonal lines, modifiable by interaction techniques. The tool supports interaction techniques like filter functions, aggregations, data sampling, and many more. We illustrate the usefulness of our tool by applying it to the eye movements of 216 programmers of multiple expertise levels that were collected during two code comprehension tasks. Our tool helped to analyze the difference between the strategic program comprehension of programmers based on their demographic background, time taken to complete the task, choice of programming task, and expertise.
Signal Detection and Inference Based on the Beta Binomial Autoregressive Moving Average Model
Jul 29, 2022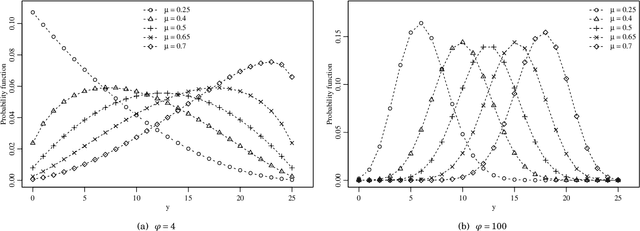
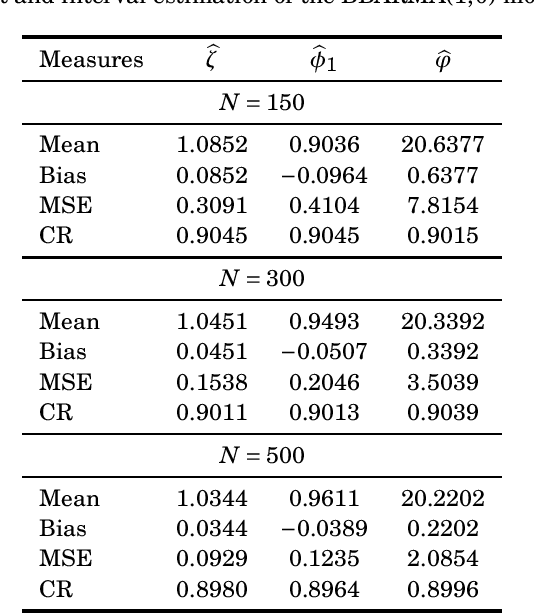
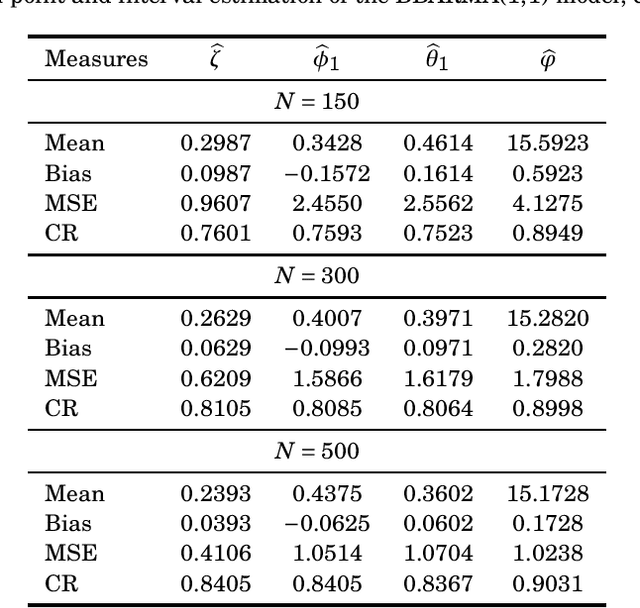
This paper proposes the beta binomial autoregressive moving average model (BBARMA) for modeling quantized amplitude data and bounded count data. The BBARMA model estimates the conditional mean of a beta binomial distributed variable observed over the time by a dynamic structure including: (i) autoregressive and moving average terms; (ii) a set of regressors; and (iii) a link function. Besides introducing the new model, we develop parameter estimation, detection tools, an out-of-signal forecasting scheme, and diagnostic measures. In particular, we provide closed-form expressions for the conditional score vector and the conditional information matrix. The proposed model was submitted to extensive Monte Carlo simulations in order to evaluate the performance of the conditional maximum likelihood estimators and of the proposed detector. The derived detector outperforms the usual ARMA- and Gaussian-based detectors for sinusoidal signal detection. We also presented an experiment for modeling and forecasting the monthly number of rainy days in Recife, Brazil.
* 17 pages, 4 tables, 5 figures
Coil2Coil: Self-supervised MR image denoising using phased-array coil images
Aug 16, 2022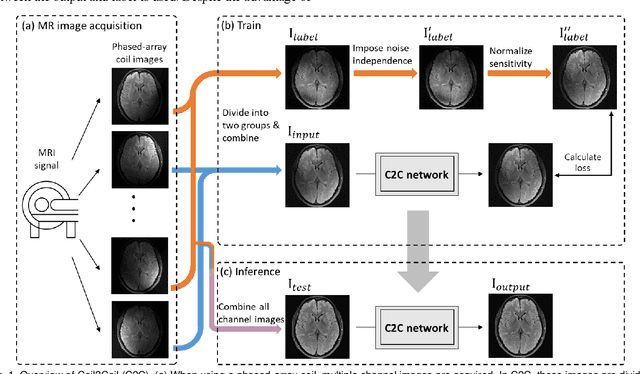
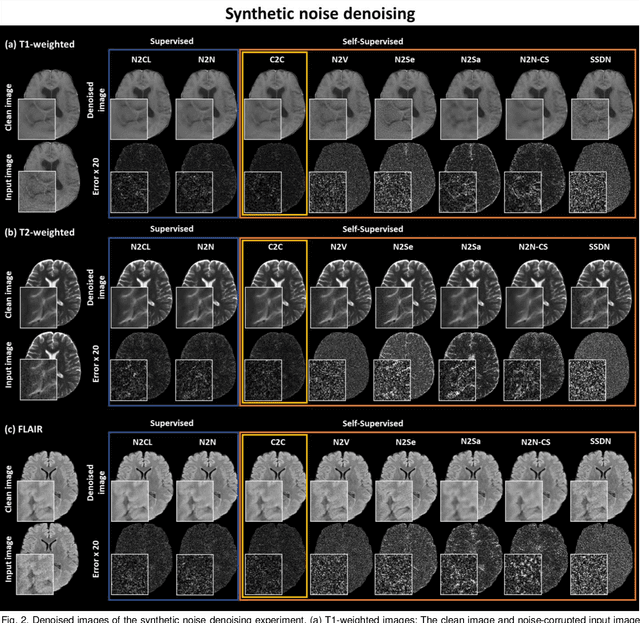
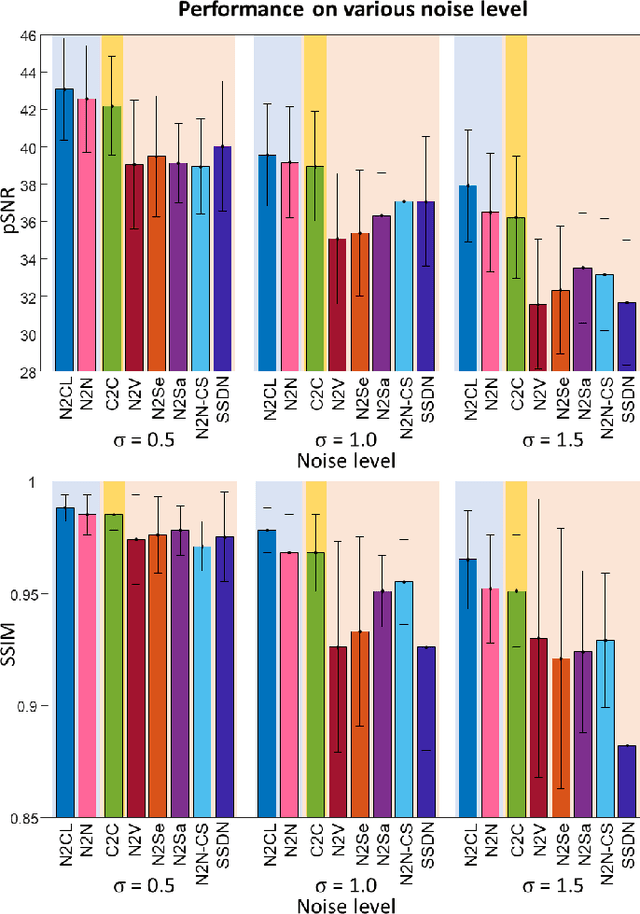
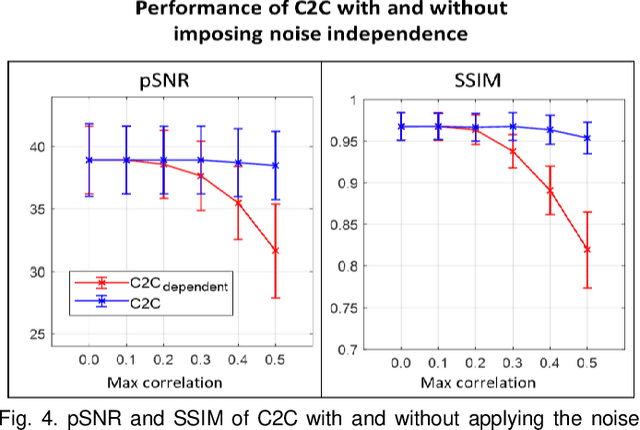
Denoising of magnetic resonance images is beneficial in improving the quality of low signal-to-noise ratio images. Recently, denoising using deep neural networks has demonstrated promising results. Most of these networks, however, utilize supervised learning, which requires large training images of noise-corrupted and clean image pairs. Obtaining training images, particularly clean images, is expensive and time-consuming. Hence, methods such as Noise2Noise (N2N) that require only pairs of noise-corrupted images have been developed to reduce the burden of obtaining training datasets. In this study, we propose a new self-supervised denoising method, Coil2Coil (C2C), that does not require the acquisition of clean images or paired noise-corrupted images for training. Instead, the method utilizes multichannel data from phased-array coils to generate training images. First, it divides and combines multichannel coil images into two images, one for input and the other for label. Then, they are processed to impose noise independence and sensitivity normalization such that they can be used for the training images of N2N. For inference, the method inputs a coil-combined image (e.g., DICOM image), enabling a wide application of the method. When evaluated using synthetic noise-added images, C2C shows the best performance against several self-supervised methods, reporting comparable outcomes to supervised methods. When testing the DICOM images, C2C successfully denoised real noise without showing structure-dependent residuals in the error maps. Because of the significant advantage of not requiring additional scans for clean or paired images, the method can be easily utilized for various clinical applications.