 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
What Does a One-Bit Quanta Image Sensor Offer?
Aug 19, 2022


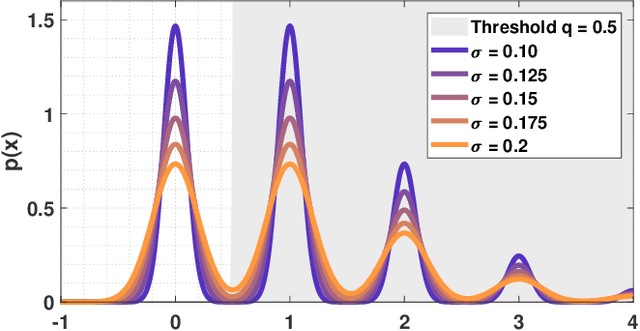
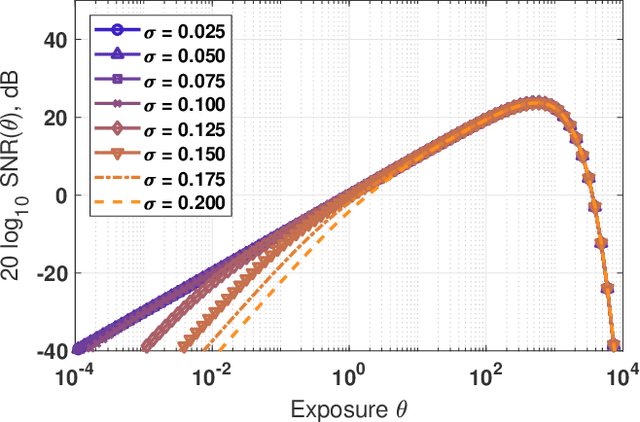
The one-bit quanta image sensor (QIS) is a photon-counting device that captures image intensities using binary bits. Assuming that the analog voltage generated at the floating diffusion of the photodiode follows a Poisson-Gaussian distribution, the sensor produces either a ``1'' if the voltage is above a certain threshold or ``0'' if it is below the threshold. The concept of this binary sensor has been proposed for more than a decade, and physical devices have been built to realize the concept. However, what benefits does a one-bit QIS offer compared to a conventional multi-bit CMOS image sensor? Besides the known empirical results, are there theoretical proofs to support these findings? The goal of this paper is to provide new theoretical support from a signal processing perspective. In particular, it is theoretically found that the sensor can offer three benefits: (1) Low-light: One-bit QIS performs better at low-light because it has a low read noise, and its one-bit quantization can produce an error-free measurement. However, this requires the exposure time to be appropriately configured. (2) Frame rate: One-bit sensors can operate at a much higher speed because a response is generated as soon as a photon is detected. However, in the presence of read noise, there exists an optimal frame rate beyond which the performance will degrade. A Closed-form expression of the optimal frame rate is derived. (3) Dynamic range: One-bit QIS offers a higher dynamic range. The benefit is brought by two complementary characteristics of the sensor: nonlinearity and exposure bracketing. The decoupling of the two factors is theoretically proved, and closed-form expressions are derived.
MoRPI: Mobile Robot Pure Inertial Navigation
Jul 06, 2022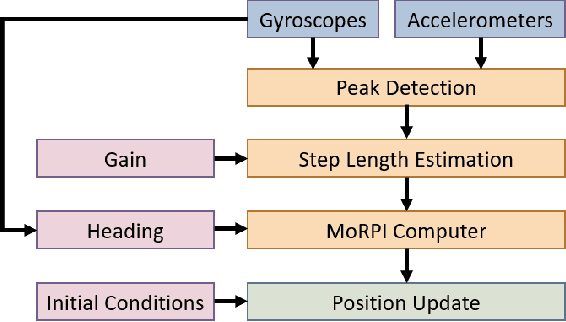
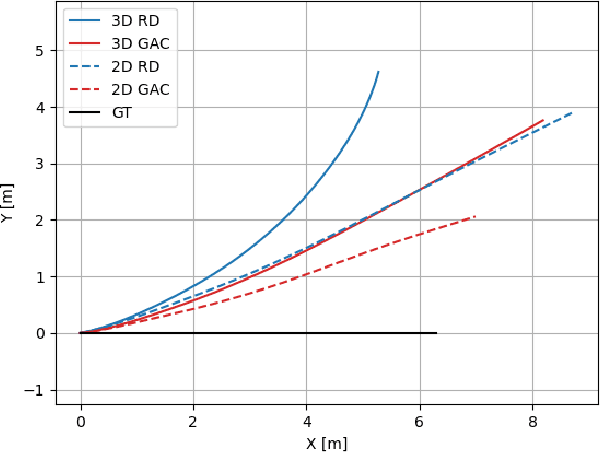
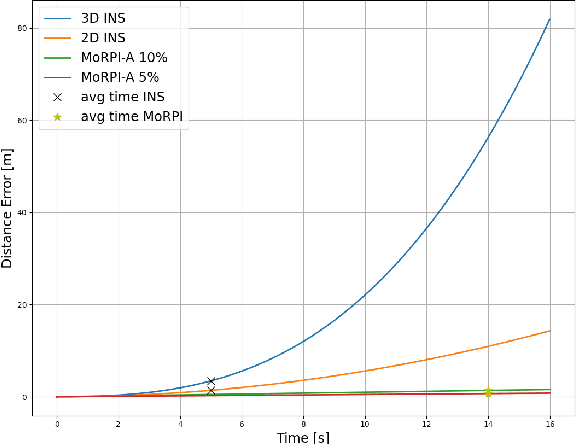

Mobile robots are used in industrial, leisure, and military applications. In some situations, a robot navigation solution relies only on inertial sensors and as a consequence, the navigation solution drifts in time. In this paper, we propose the MoRPI framework, a mobile robot pure inertial approach. Instead of travelling in a straight line trajectory, the robot moves in a periodic motion trajectory to enable peak-to-peak estimation. In this manner, instead of performing three integrations to calculate the robot position in a classical inertial solution, an empirical formula is used to estimate the travelled distance. Two types of MoRPI approaches are suggested, where one is based on both accelerometer and gyroscope readings while the other is only on gyroscopes. Closed form analytical solutions are derived to show that MoRPI produces lower position error compared to the classical pure inertial solution. In addition, to evaluate the proposed approach, field experiments were made with a mobile robot equipped with two types of inertial sensors. In total, 143 trajectories with a time duration of 75 minutes were collected and evaluated. The results show the benefits of using our approach. To facilitate further development of the proposed approach, both dataset and code are publicly available at https://github.com/ansfl/MoRPI.
Geometric deep learning for computational mechanics Part II: Graph embedding for interpretable multiscale plasticity
Jul 30, 2022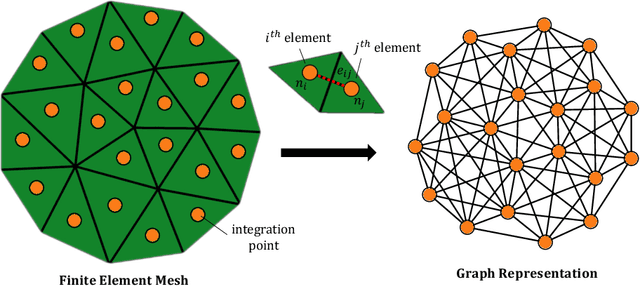
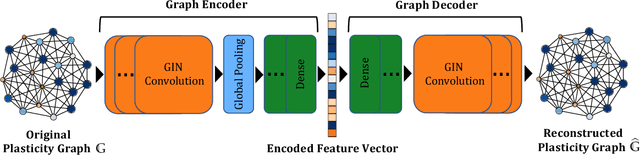

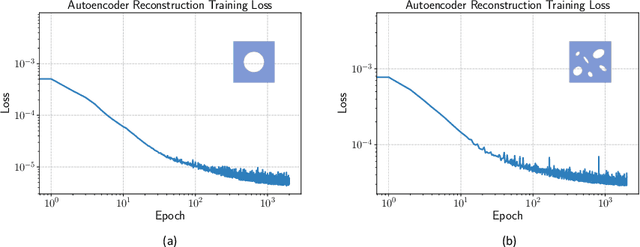
The history-dependent behaviors of classical plasticity models are often driven by internal variables evolved according to phenomenological laws. The difficulty to interpret how these internal variables represent a history of deformation, the lack of direct measurement of these internal variables for calibration and validation, and the weak physical underpinning of those phenomenological laws have long been criticized as barriers to creating realistic models. In this work, geometric machine learning on graph data (e.g. finite element solutions) is used as a means to establish a connection between nonlinear dimensional reduction techniques and plasticity models. Geometric learning-based encoding on graphs allows the embedding of rich time-history data onto a low-dimensional Euclidean space such that the evolution of plastic deformation can be predicted in the embedded feature space. A corresponding decoder can then convert these low-dimensional internal variables back into a weighted graph such that the dominating topological features of plastic deformation can be observed and analyzed.
Asymptotic Tracking Control of Uncertain MIMO Nonlinear Systems with Less Conservative Controllability Conditions
Aug 03, 2022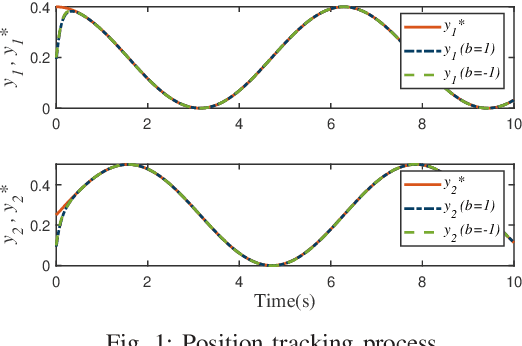
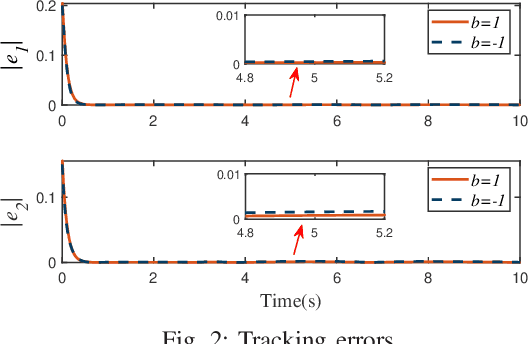
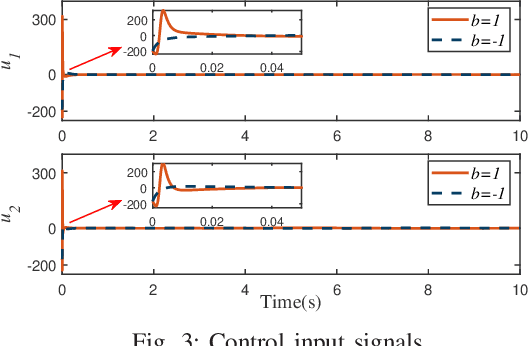
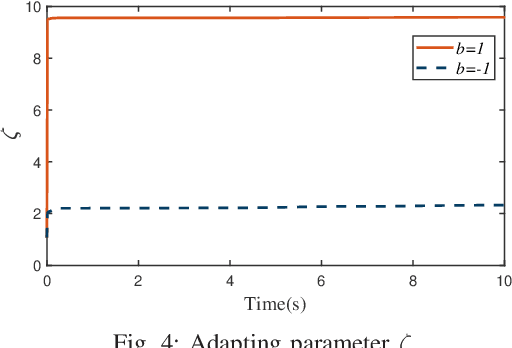
For uncertain multiple inputs multi-outputs (MIMO) nonlinear systems, it is nontrivial to achieve asymptotic tracking, and most existing methods normally demand certain controllability conditions that are rather restrictive or even impractical if unexpected actuator faults are involved. In this note, we present a method capable of achieving zero-error steady-state tracking with less conservative (more practical) controllability condition. By incorporating a novel Nussbaum gain technique and some positive integrable function into the control design, we develop a robust adaptive asymptotic tracking control scheme for the system with time-varying control gain being unknown its magnitude and direction. By resorting to the existence of some feasible auxiliary matrix, the current state-of-art controllability condition is further relaxed, which enlarges the class of systems that can be considered in the proposed control scheme. All the closed-loop signals are ensured to be globally ultimately uniformly bounded. Moreover, such control methodology is further extended to the case involving intermittent actuator faults, with application to robotic systems. Finally, simulation studies are carried out to demonstrate the effectiveness and flexibility of this method.
A comprehensive survey on computer-aided diagnostic systems in diabetic retinopathy screening
Aug 03, 2022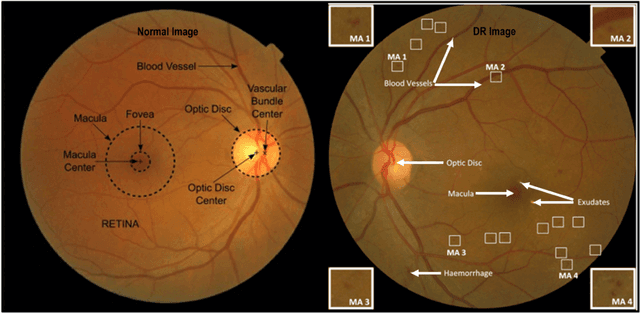

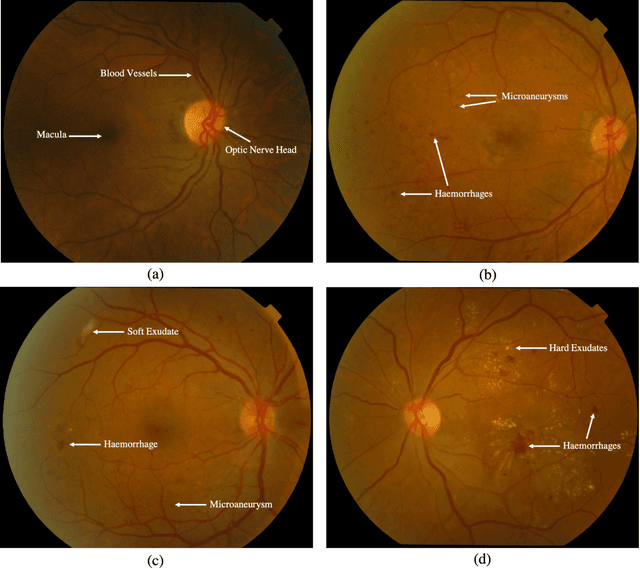
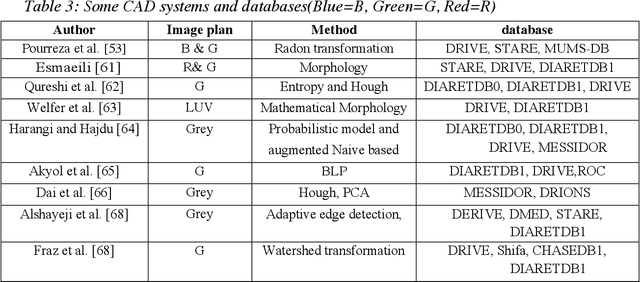
Diabetes Mellitus (DM) can lead to significant microvasculature disruptions that eventually causes diabetic retinopathy (DR), or complications in the eye due to diabetes. If left unchecked, this disease can increase over time and eventually cause complete vision loss. The general method to detect such optical developments is through examining the vessels, optic nerve head, microaneurysms, haemorrhage, exudates, etc. from retinal images. Ultimately this is limited by the number of experienced ophthalmologists and the vastly growing number of DM cases. To enable earlier and efficient DR diagnosis, the field of ophthalmology requires robust computer aided diagnosis (CAD) systems. Our review is intended for anyone, from student to established researcher, who wants to understand what can be accomplished with CAD systems and their algorithms to modeling and where the field of retinal image processing in computer vision and pattern recognition is headed. For someone just getting started, we place a special emphasis on the logic, strengths and shortcomings of different databases and algorithms frameworks with a focus on very recent approaches.
* 65 pages, 7 figures, 9 tables
Nextformer: A ConvNeXt Augmented Conformer For End-To-End Speech Recognition
Jun 30, 2022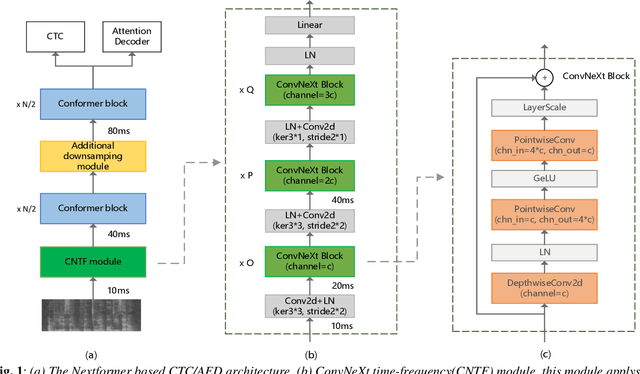
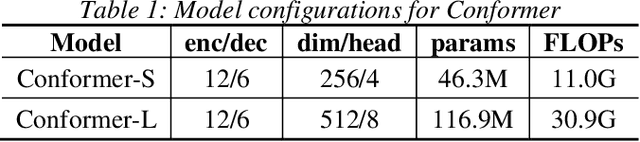
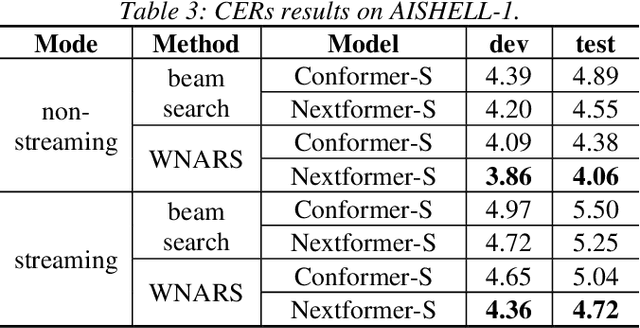
Conformer models have achieved state-of-the-art(SOTA) results in end-to-end speech recognition. However Conformer mainly focuses on temporal modeling while pays less attention on time-frequency property of speech feature. In this paper we augment Conformer with ConvNeXt and propose Nextformer structure. We use stacks of ConvNeXt block to replace the commonly used subsampling module in Conformer for utilizing the information contained in time-frequency speech feature. Besides, we insert an additional downsampling module in middle of Conformer layers to make our model more efficient and accurate. We conduct experiments on two opening datasets, AISHELL-1 and WenetSpeech. On AISHELL-1, compared to Conformer baselines, Nextformer obtains 7.3% and 6.3% relative CER reduction in non-streaming and streaming mode respectively, and on a much larger WenetSpeech dataset, Nextformer gives 5.0%~6.5% and 7.5%~14.6% relative CER reduction in non-streaming and streaming mode, while keep the computational cost FLOPs comparable to Conformer. To the best of our knowledge, the proposed Nextformer model achieves SOTA results on AISHELL-1(CER 4.06%) and WenetSpeech(CER 7.56%/11.29%).
Time series analysis with dynamic law exploration
Apr 22, 2021
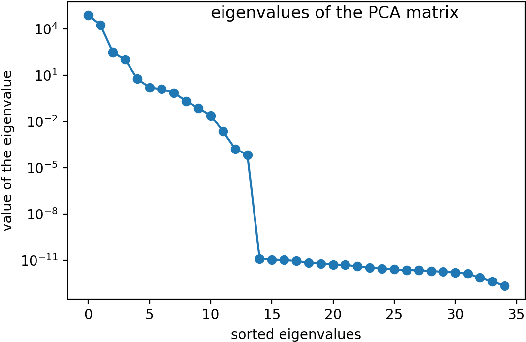
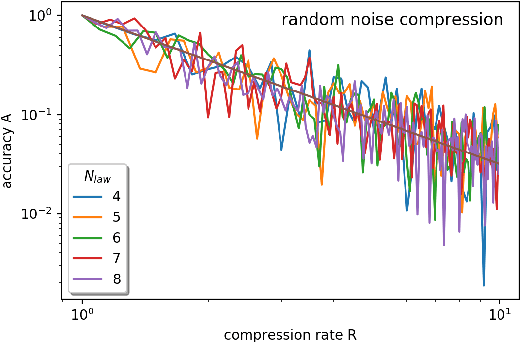
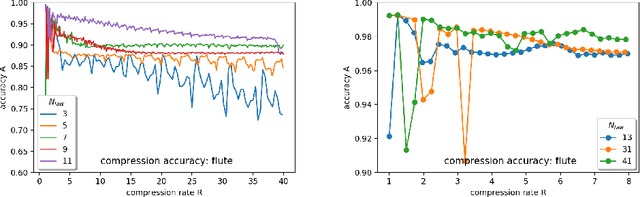
In this paper we examine, how the dynamic laws governing the time evolution of a time series can be identified. We give a finite difference equation as well as a differential equation representation for that. We also study, how the required symmetries, like time reversal can be imposed on the laws. We study the compression performance of linear laws on sound data.
SSDPT: Self-Supervised Dual-Path Transformer for Anomalous Sound Detection in Machine Condition Monitoring
Aug 06, 2022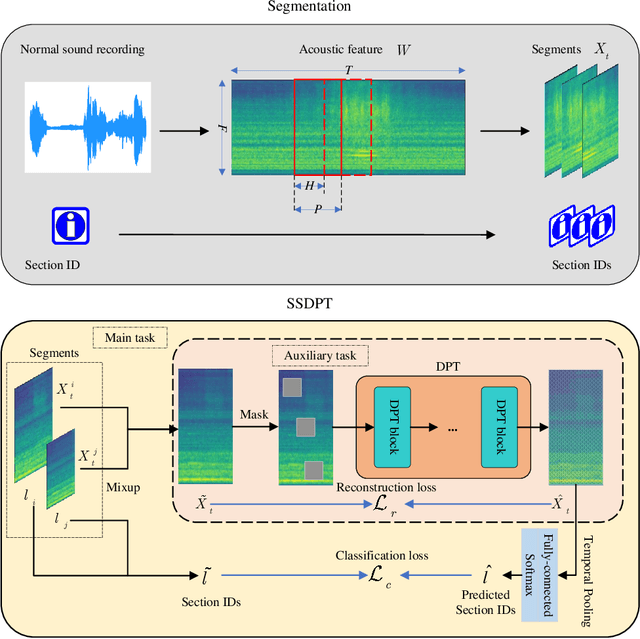
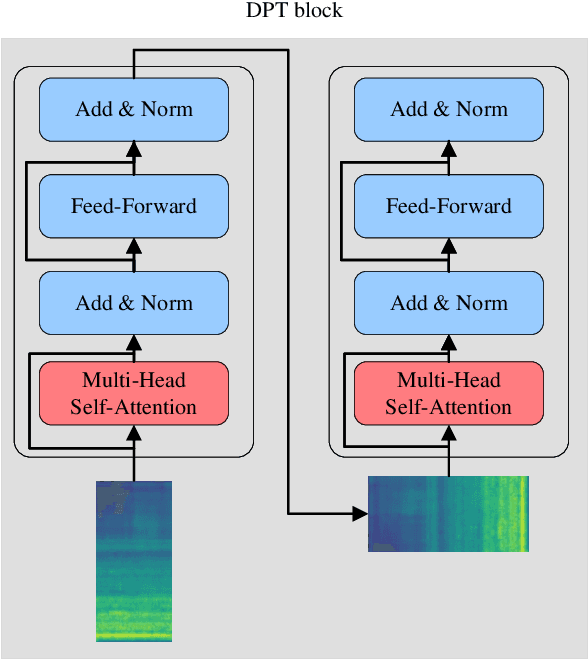

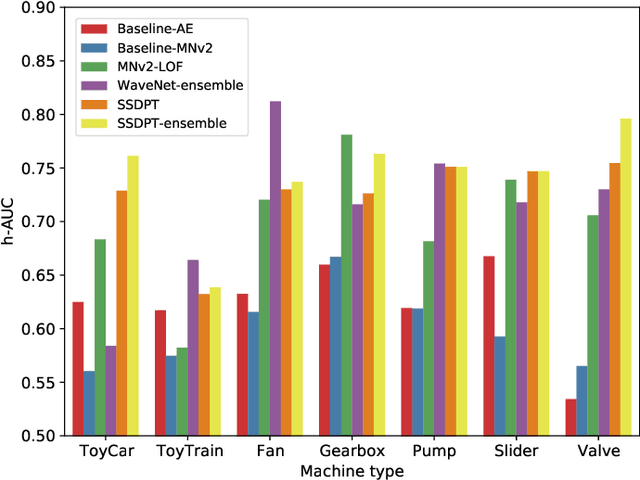
Anomalous sound detection for machine condition monitoring has great potential in the development of Industry 4.0. However, these anomalous sounds of machines are usually unavailable in normal conditions. Therefore, the models employed have to learn acoustic representations with normal sounds for training, and detect anomalous sounds while testing. In this article, we propose a self-supervised dual-path Transformer (SSDPT) network to detect anomalous sounds in machine monitoring. The SSDPT network splits the acoustic features into segments and employs several DPT blocks for time and frequency modeling. DPT blocks use attention modules to alternately model the interactive information about the frequency and temporal components of the segmented acoustic features. To address the problem of lack of anomalous sound, we adopt a self-supervised learning approach to train the network with normal sound. Specifically, this approach randomly masks and reconstructs the acoustic features, and jointly classifies machine identity information to improve the performance of anomalous sound detection. We evaluated our method on the DCASE2021 task2 dataset. The experimental results show that the SSDPT network achieves a significant increase in the harmonic mean AUC score, in comparison to present state-of-the-art methods of anomalous sound detection.
Training Latent Variable Models with Auto-encoding Variational Bayes: A Tutorial
Aug 16, 2022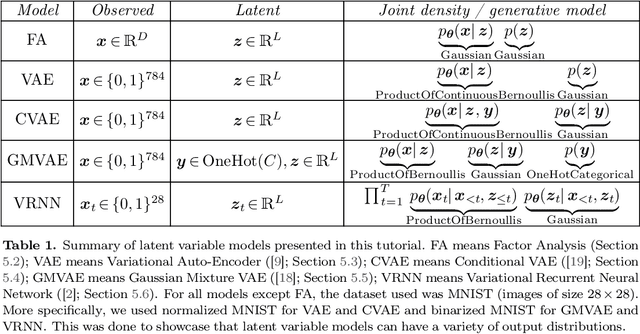
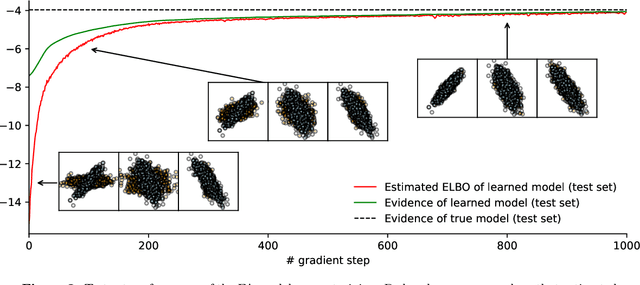
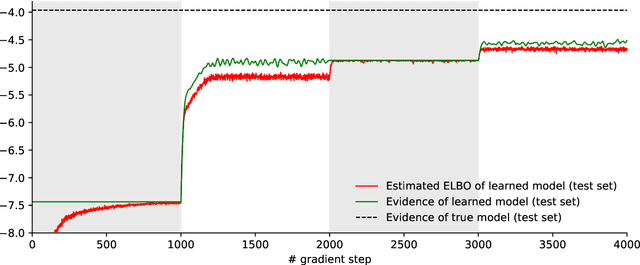
Auto-encoding Variational Bayes (AEVB) is a powerful and general algorithm for fitting latent variable models (a promising direction for unsupervised learning), and is well-known for training the Variational Auto-Encoder (VAE). In this tutorial, we focus on motivating AEVB from the classic Expectation Maximization (EM) algorithm, as opposed to from deterministic auto-encoders. Though natural and somewhat self-evident, the connection between EM and AEVB is not emphasized in the recent deep learning literature, and we believe that emphasizing this connection can improve the community's understanding of AEVB. In particular, we find it especially helpful to view (1) optimizing the evidence lower bound (ELBO) with respect to inference parameters as approximate E-step and (2) optimizing ELBO with respect to generative parameters as approximate M-step; doing both simultaneously as in AEVB is then simply tightening and pushing up ELBO at the same time. We discuss how approximate E-step can be interpreted as performing variational inference. Important concepts such as amortization and the reparametrization trick are discussed in great detail. Finally, we derive from scratch the AEVB training procedures of a non-deep and several deep latent variable models, including VAE, Conditional VAE, Gaussian Mixture VAE and Variational RNN. It is our hope that readers would recognize AEVB as a general algorithm that can be used to fit a wide range of latent variable models (not just VAE), and apply AEVB to such models that arise in their own fields of research. PyTorch code for all included models are publicly available.
Deep inference of latent dynamics with spatio-temporal super-resolution using selective backpropagation through time
Oct 29, 2021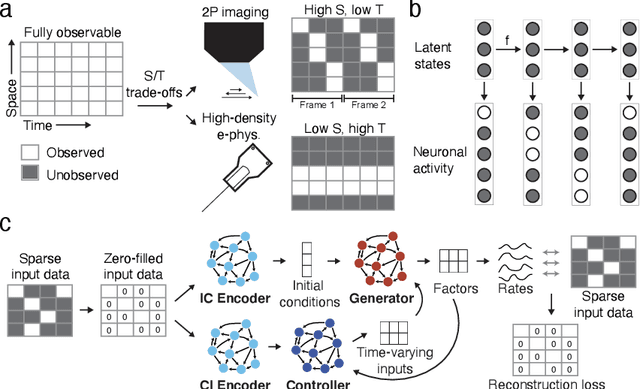
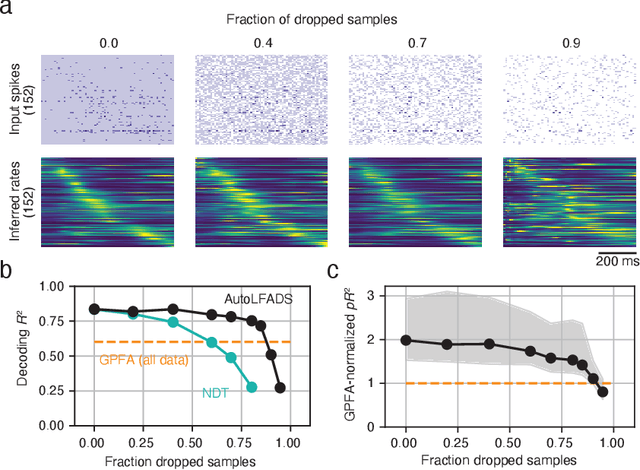
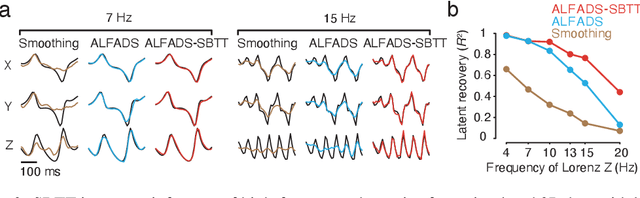
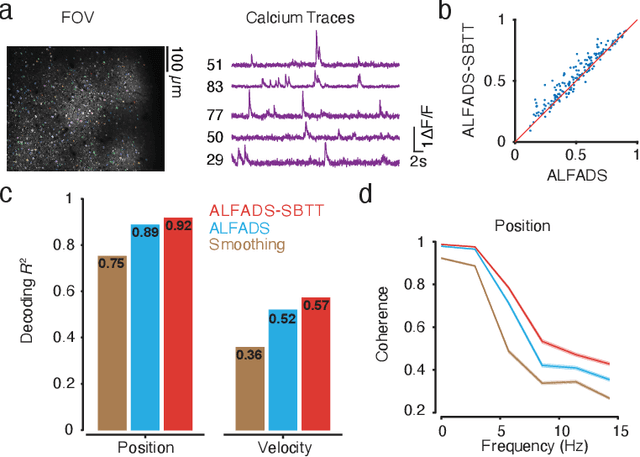
Modern neural interfaces allow access to the activity of up to a million neurons within brain circuits. However, bandwidth limits often create a trade-off between greater spatial sampling (more channels or pixels) and the temporal frequency of sampling. Here we demonstrate that it is possible to obtain spatio-temporal super-resolution in neuronal time series by exploiting relationships among neurons, embedded in latent low-dimensional population dynamics. Our novel neural network training strategy, selective backpropagation through time (SBTT), enables learning of deep generative models of latent dynamics from data in which the set of observed variables changes at each time step. The resulting models are able to infer activity for missing samples by combining observations with learned latent dynamics. We test SBTT applied to sequential autoencoders and demonstrate more efficient and higher-fidelity characterization of neural population dynamics in electrophysiological and calcium imaging data. In electrophysiology, SBTT enables accurate inference of neuronal population dynamics with lower interface bandwidths, providing an avenue to significant power savings for implanted neuroelectronic interfaces. In applications to two-photon calcium imaging, SBTT accurately uncovers high-frequency temporal structure underlying neural population activity, substantially outperforming the current state-of-the-art. Finally, we demonstrate that performance could be further improved by using limited, high-bandwidth sampling to pretrain dynamics models, and then using SBTT to adapt these models for sparsely-sampled data.