 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
FastATDC: Fast Anomalous Trajectory Detection and Classification
Jul 23, 2022
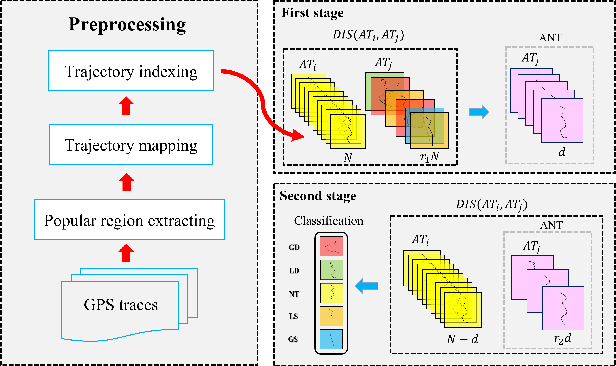
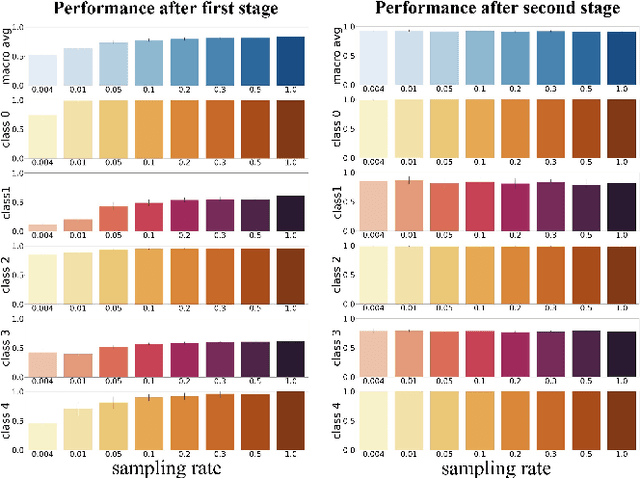
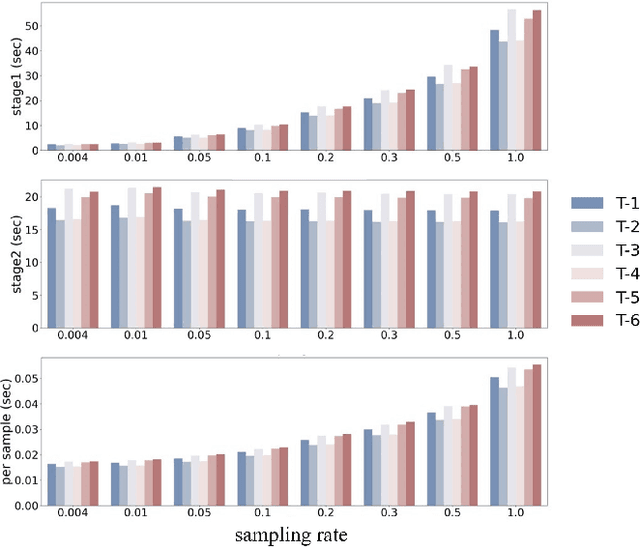
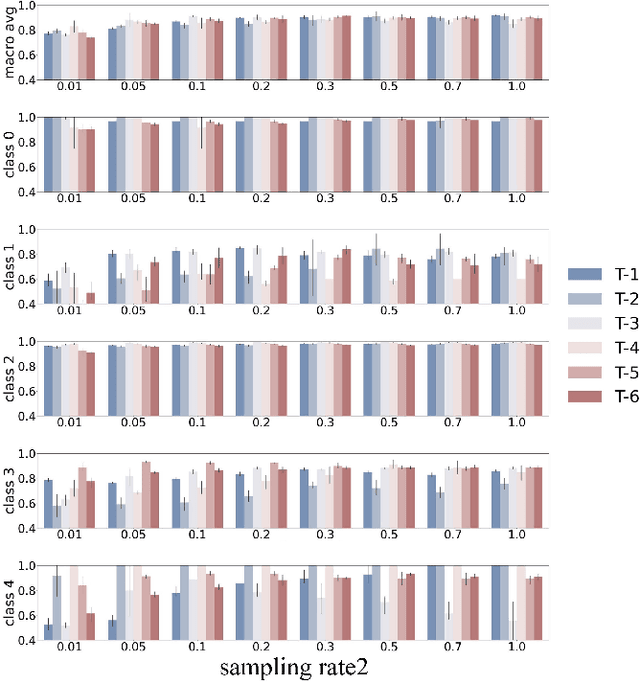
Automated detection of anomalous trajectories is an important problem with considerable applications in intelligent transportation systems. Many existing studies have focused on distinguishing anomalous trajectories from normal trajectories, ignoring the large differences between anomalous trajectories. A recent study has made great progress in identifying abnormal trajectory patterns and proposed a two-stage algorithm for anomalous trajectory detection and classification (ATDC). This algorithm has excellent performance but suffers from a few limitations, such as high time complexity and poor interpretation. Here, we present a careful theoretical and empirical analysis of the ATDC algorithm, showing that the calculation of anomaly scores in both stages can be simplified, and that the second stage of the algorithm is much more important than the first stage. Hence, we develop a FastATDC algorithm that introduces a random sampling strategy in both stages. Experimental results show that FastATDC is 10 to 20 times faster than ATDC on real datasets. Moreover, FastATDC outperforms the baseline algorithms and is comparable to the ATDC algorithm.
Time-Frequency Localization Using Deep Convolutional Maxout Neural Network in Persian Speech Recognition
Aug 09, 2021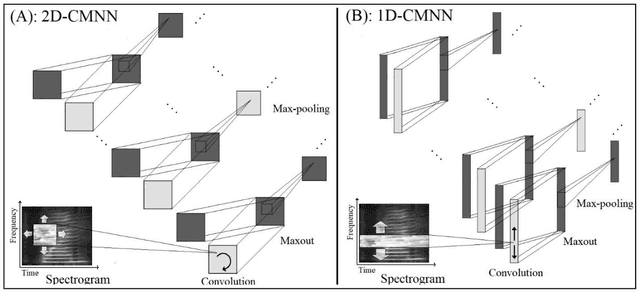
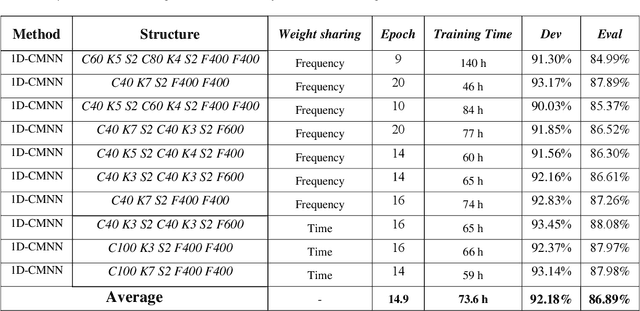
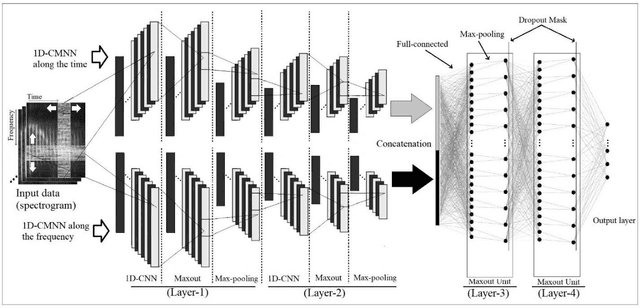
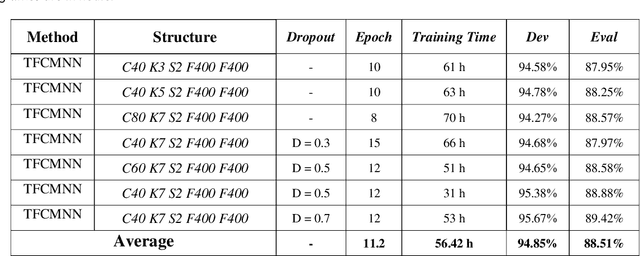
In this paper, a CNN-based structure for time-frequency localization of audio signal information in the ASR acoustic model is proposed for Persian speech recognition. Research has shown that the receptive fields' time-frequency flexibility in some mammals' auditory neurons system improves recognition performance. Biosystems have inspired many artificial systems because of their high efficiency and performance, so time-frequency localization has been used extensively to improve system performance. In the last few years, much work has been done to localize time-frequency information in ASR systems, which has used the spatial immutability properties of methods such as TDNN, CNN and LSTM-RNN. However, most of these models have large parameter volumes and are challenging to train. In the structure we have designed, called Time-Frequency Convolutional Maxout Neural Network (TFCMNN), two parallel blocks consisting of 1D-CMNN each have weight sharing in one dimension, are applied simultaneously but independently to the feature vectors. Then their output is concatenated and applied to a fully connected Maxout network for classification. To improve the performance of this structure, we have used newly developed methods and models such as the maxout, Dropout, and weight normalization. Two experimental sets were designed and implemented on the Persian FARSDAT speech data set to evaluate the performance of this model compared to conventional 1D-CMNN models. According to the experimental results, the average recognition score of TFCMNN models is about 1.6% higher than the average of conventional models. In addition, the average training time of the TFCMNN models is about 17 hours lower than the average training time of traditional models. As a result, as mentioned in other references, time-frequency localization in ASR systems increases system accuracy and speeds up the model training process.
Deeptime: a Python library for machine learning dynamical models from time series data
Oct 28, 2021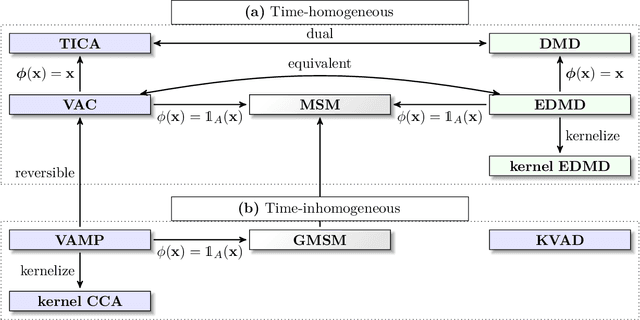

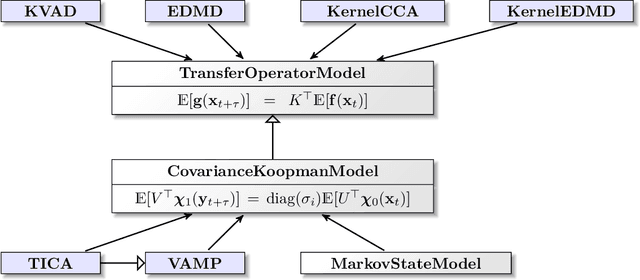
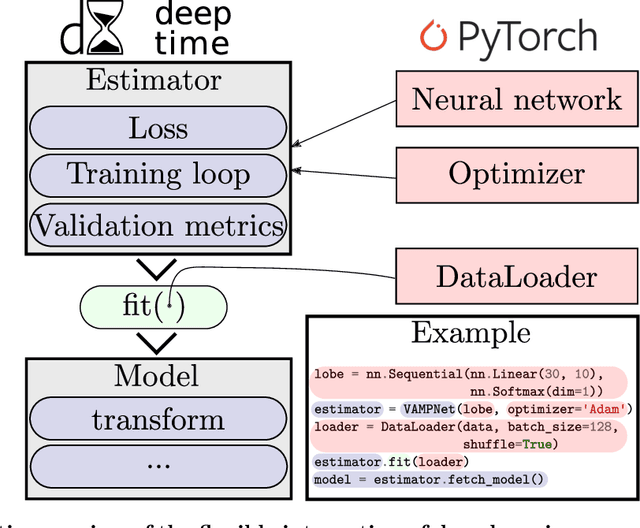
Generation and analysis of time-series data is relevant to many quantitative fields ranging from economics to fluid mechanics. In the physical sciences, structures such as metastable and coherent sets, slow relaxation processes, collective variables dominant transition pathways or manifolds and channels of probability flow can be of great importance for understanding and characterizing the kinetic, thermodynamic and mechanistic properties of the system. Deeptime is a general purpose Python library offering various tools to estimate dynamical models based on time-series data including conventional linear learning methods, such as Markov state models (MSMs), Hidden Markov Models and Koopman models, as well as kernel and deep learning approaches such as VAMPnets and deep MSMs. The library is largely compatible with scikit-learn, having a range of Estimator classes for these different models, but in contrast to scikit-learn also provides deep Model classes, e.g. in the case of an MSM, which provide a multitude of analysis methods to compute interesting thermodynamic, kinetic and dynamical quantities, such as free energies, relaxation times and transition paths. The library is designed for ease of use but also easily maintainable and extensible code. In this paper we introduce the main features and structure of the deeptime software.
Automated, real-time hospital ICU emergency signaling: A field-level implementation
Nov 03, 2021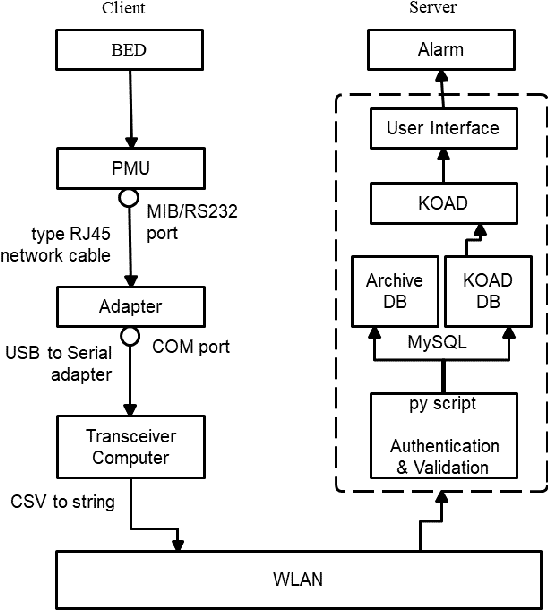
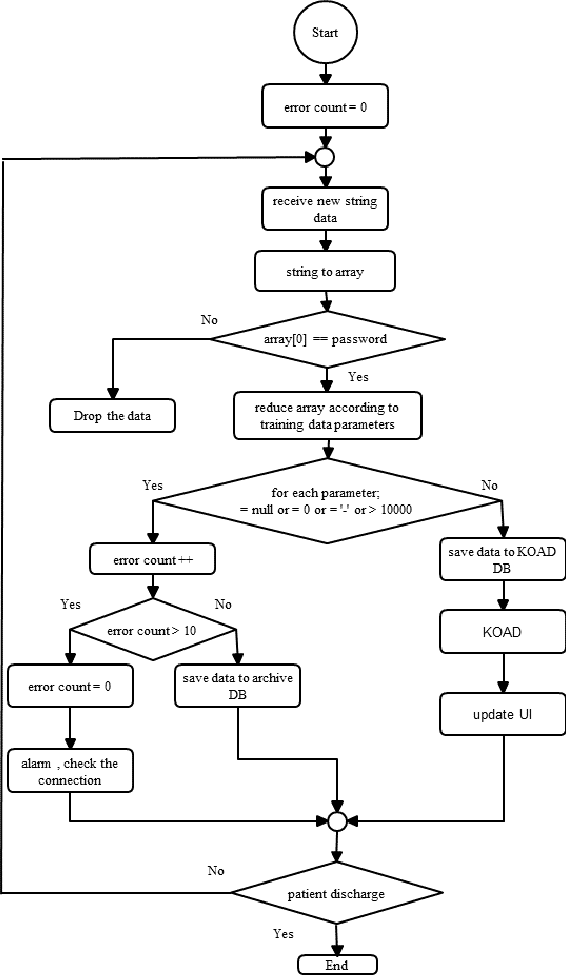
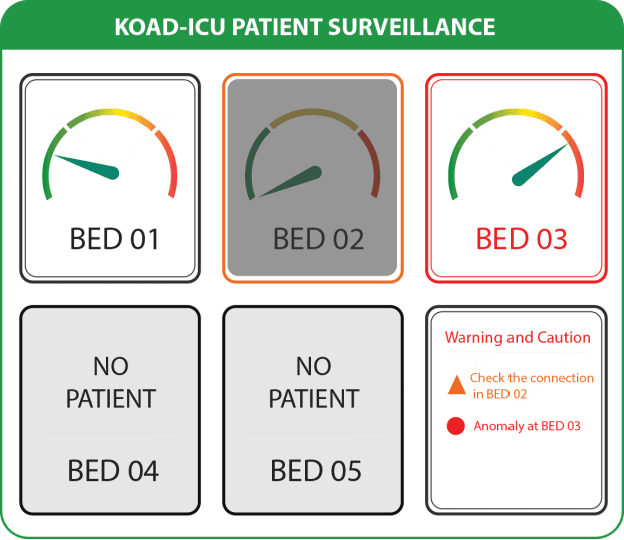
Contemporary patient surveillance systems have streamlined central surveillance into the electronic health record interface. They are able to process the sheer volume of patient data by adopting machine learning approaches. However, these systems are not suitable for implementation in many hospitals, mostly in developing countries, with limited human, financial, and technological resources. Through conducting thorough research on intensive care facilities, we designed a novel central patient monitoring system and in this paper, we describe the working prototype of our system. The proposed prototype comprises of inexpensive peripherals and simplistic user interface. Our central patient monitoring system implements Kernel-based On-line Anomaly Detection (KOAD) algorithm for emergency event signaling. By evaluating continuous patient data, we show that the system is able to detect critical events in real-time reliably and has low false alarm rate.
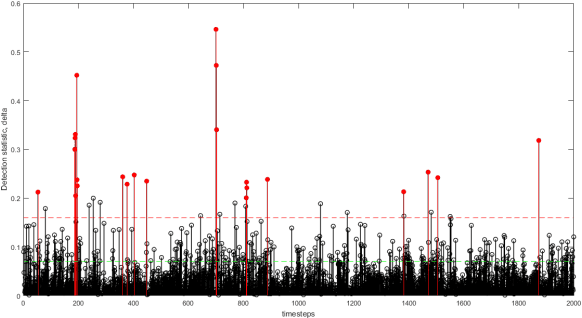
Innovations Autoencoder and its Application in Real-Time Anomaly Detection
Jun 23, 2021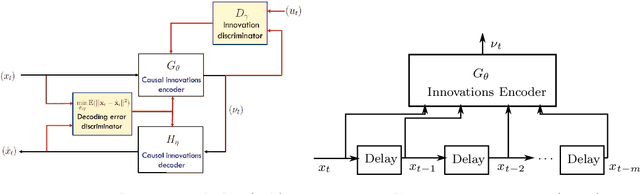


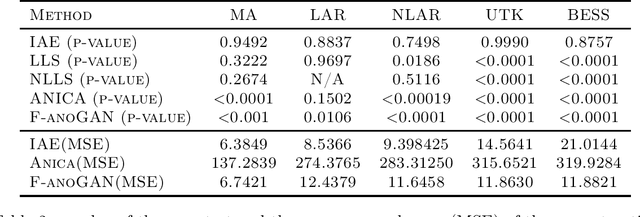
An innovations sequence of a time series is a sequence of independent and identically distributed random variables with which the original time series has a causal representation. The innovation at a time is statistically independent of the prior history of the time series. As such, it represents the new information contained at present but not in the past. Because of its simple probability structure, an innovations sequence is the most efficient signature of the original. Unlike the principle or independent analysis (PCA/ICA) representations, an innovations sequence preserves not only the complete statistical properties but also the temporal order of the original time series. An long-standing open problem is to find a computationally tractable way to extract an innovations sequence of non-Gaussian processes. This paper presents a deep learning approach, referred to as Innovations Autoencoder (IAE), that extracts innovations sequences using a causal convolutional neural network. An application of IAE to nonparametric anomaly detection with unknown anomaly and anomaly-free models is also presented.
Video Activity Localisation with Uncertainties in Temporal Boundary
Jun 26, 2022

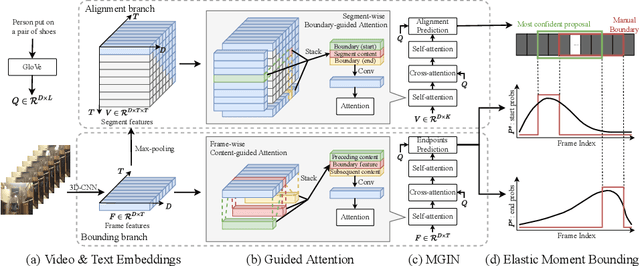
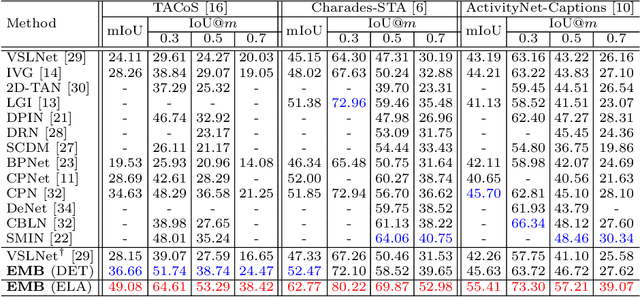
Current methods for video activity localisation over time assume implicitly that activity temporal boundaries labelled for model training are determined and precise. However, in unscripted natural videos, different activities mostly transit smoothly, so that it is intrinsically ambiguous to determine in labelling precisely when an activity starts and ends over time. Such uncertainties in temporal labelling are currently ignored in model training, resulting in learning mis-matched video-text correlation with poor generalisation in test. In this work, we solve this problem by introducing Elastic Moment Bounding (EMB) to accommodate flexible and adaptive activity temporal boundaries towards modelling universally interpretable video-text correlation with tolerance to underlying temporal uncertainties in pre-fixed annotations. Specifically, we construct elastic boundaries adaptively by mining and discovering frame-wise temporal endpoints that can maximise the alignment between video segments and query sentences. To enable both more robust matching (segment content attention) and more accurate localisation (segment elastic boundaries), we optimise the selection of frame-wise endpoints subject to segment-wise contents by a novel Guided Attention mechanism. Extensive experiments on three video activity localisation benchmarks demonstrate compellingly the EMB's advantages over existing methods without modelling uncertainty.
AA3DNet: Attention Augmented Real Time 3D Object Detection
Jul 26, 2021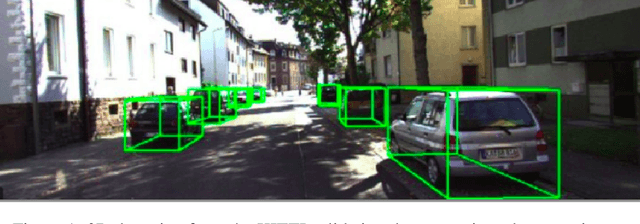
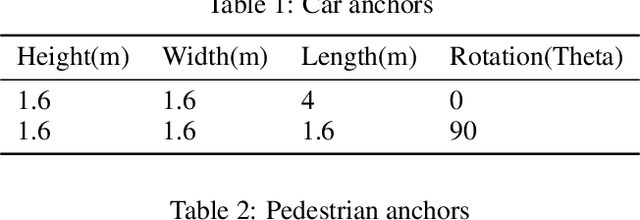
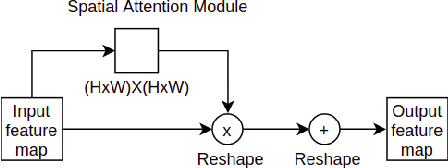
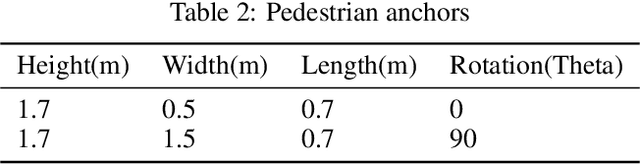
In this work, we address the problem of 3D object detection from point cloud data in real time. For autonomous vehicles to work, it is very important for the perception component to detect the real world objects with both high accuracy and fast inference. We propose a novel neural network architecture along with the training and optimization details for detecting 3D objects using point cloud data. We present anchor design along with custom loss functions used in this work. A combination of spatial and channel wise attention module is used in this work. We use the Kitti 3D Birds Eye View dataset for benchmarking and validating our results. Our method surpasses previous state of the art in this domain both in terms of average precision and speed running at > 30 FPS. Finally, we present the ablation study to demonstrate that the performance of our network is generalizable. This makes it a feasible option to be deployed in real time applications like self driving cars.
Surrey System for DCASE 2022 Task 5: Few-shot Bioacoustic Event Detection with Segment-level Metric Learning
Jul 21, 2022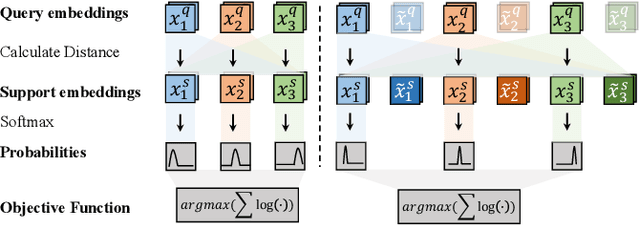

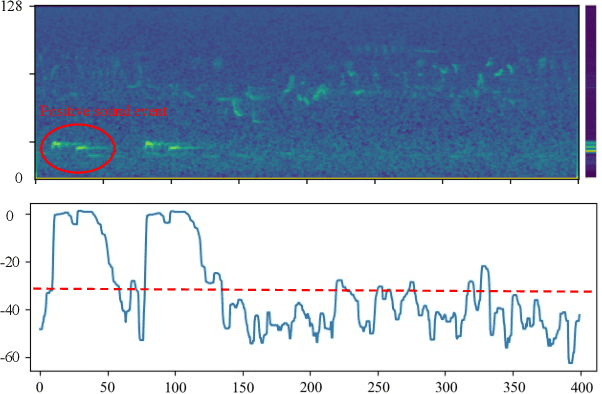

Few-shot audio event detection is a task that detects the occurrence time of a novel sound class given a few examples. In this work, we propose a system based on segment-level metric learning for the DCASE 2022 challenge of few-shot bioacoustic event detection (task 5). We make better utilization of the negative data within each sound class to build the loss function, and use transductive inference to gain better adaptation on the evaluation set. For the input feature, we find the per-channel energy normalization concatenated with delta mel-frequency cepstral coefficients to be the most effective combination. We also introduce new data augmentation and post-processing procedures for this task. Our final system achieves an f-measure of 68.74 on the DCASE task 5 validation set, outperforming the baseline performance of 29.5 by a large margin. Our system is fully open-sourced at https://github.com/haoheliu/DCASE_2022_Task_5.
Real-time Identification and Simultaneous Avoidance of Static and Dynamic Obstacles on Point Cloud for UAVs Navigation
Oct 20, 2021
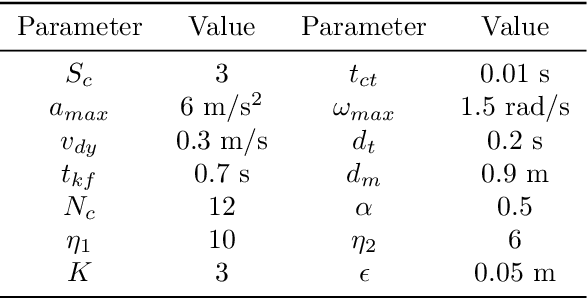
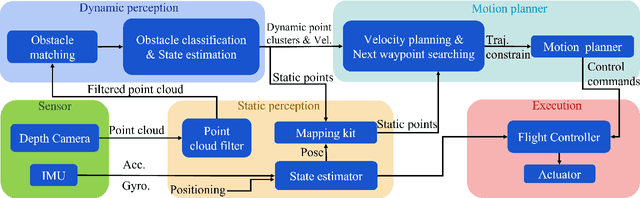
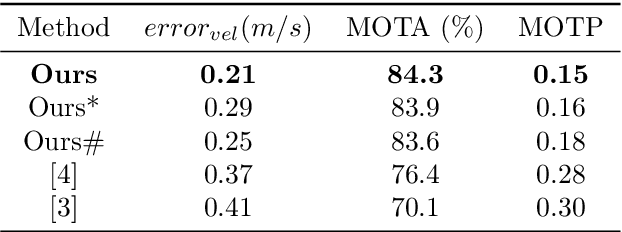
Avoiding hybrid obstacles in unknown scenarios with an efficient flight strategy is a key challenge for unmanned aerial vehicle applications. In this paper, we introduce a more robust technique to distinguish and track dynamic obstacles from static ones with only point cloud input. Then, to achieve dynamic avoidance, we propose the forbidden pyramids method to solve the desired vehicle velocity with an efficient sampling-based method in iteration. The motion primitives are generated by solving a nonlinear optimization problem with the constraint of desired velocity and the waypoint. Furthermore, we present several techniques to deal with the position estimation error for close objects, the error for deformable objects, and the time gap between different submodules. The proposed approach is implemented to run onboard in real-time and validated extensively in simulation and hardware tests, demonstrating our superiority in tracking robustness, energy cost, and calculating time.
Deep COVID-19 Recognition using Chest X-ray Images: A Comparative Analysis
Jul 26, 2022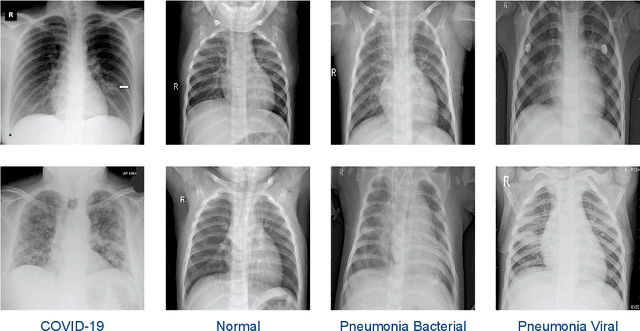
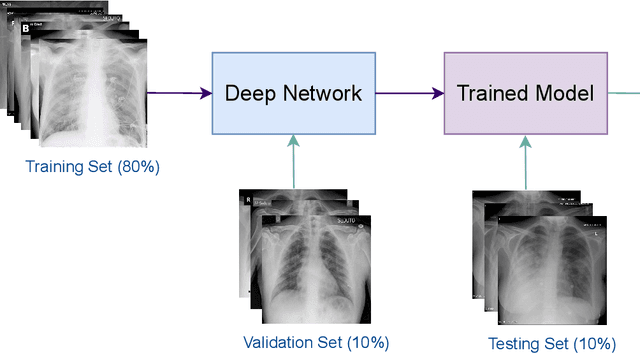
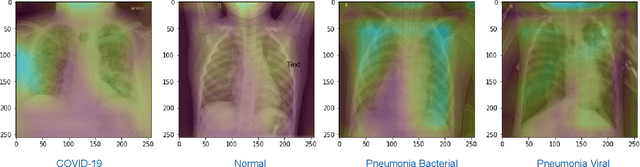
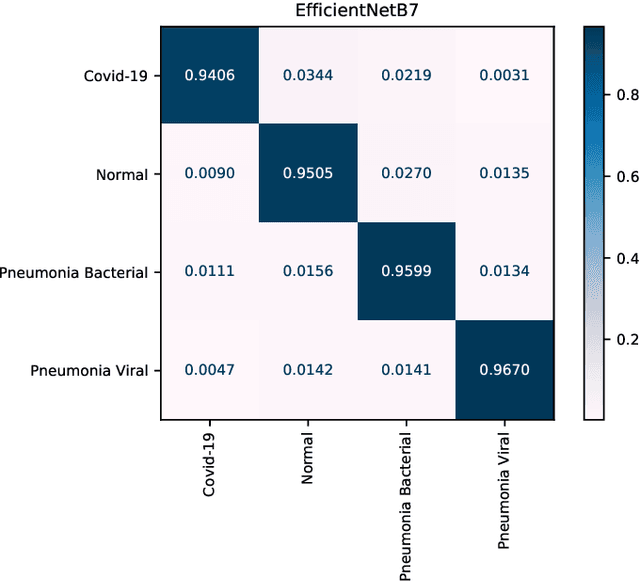
The novel coronavirus variant, which is also widely known as COVID-19, is currently a common threat to all humans across the world. Effective recognition of COVID-19 using advanced machine learning methods is a timely need. Although many sophisticated approaches have been proposed in the recent past, they still struggle to achieve expected performances in recognizing COVID-19 using chest X-ray images. In addition, the majority of them are involved with the complex pre-processing task, which is often challenging and time-consuming. Meanwhile, deep networks are end-to-end and have shown promising results in image-based recognition tasks during the last decade. Hence, in this work, some widely used state-of-the-art deep networks are evaluated for COVID-19 recognition with chest X-ray images. All the deep networks are evaluated on a publicly available chest X-ray image dataset. The evaluation results show that the deep networks can effectively recognize COVID-19 from chest X-ray images. Further, the comparison results reveal that the EfficientNetB7 network outperformed other existing state-of-the-art techniques.
* 5 pages