 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
covEcho Resource constrained lung ultrasound image analysis tool for faster triaging and active learning
Jun 21, 2022
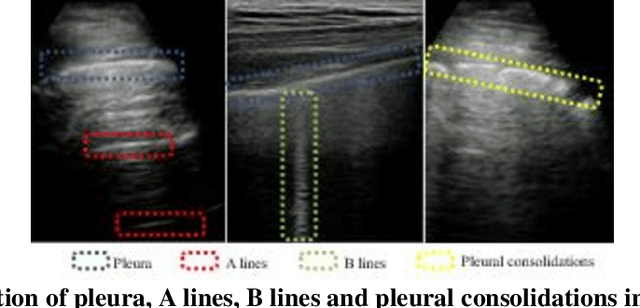
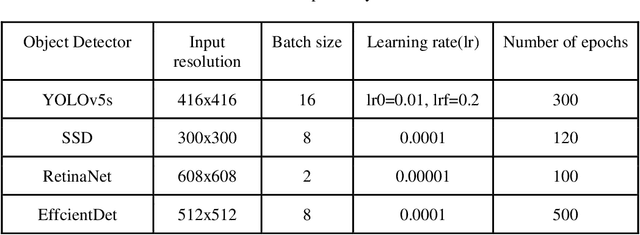
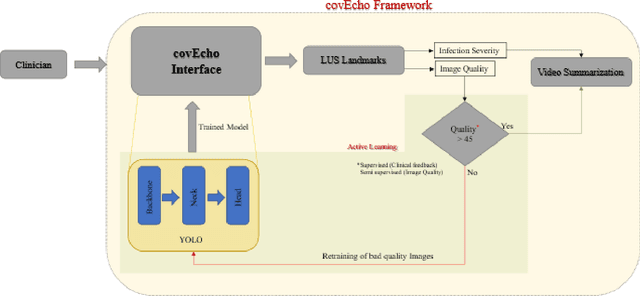
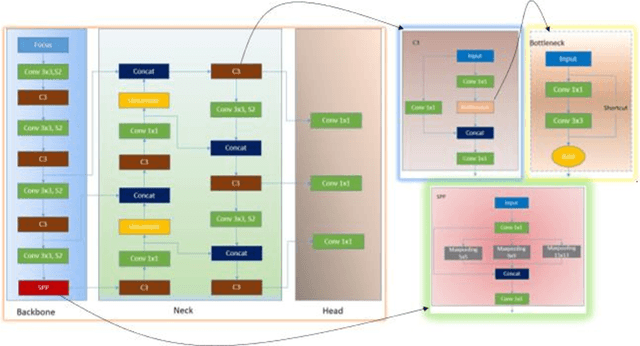
Lung ultrasound (LUS) is possibly the only medical imaging modality which could be used for continuous and periodic monitoring of the lung. This is extremely useful in tracking the lung manifestations either during the onset of lung infection or to track the effect of vaccination on lung as in pandemics such as COVID-19. There have been many attempts in automating the classification of severity of lung into various classes or automatic segmentation of various LUS landmarks and manifestations. However, all these approaches are based on training static machine learning models which require a significantly clinically annotated large dataset and are computationally heavy and most of the time non-real time. In this work, a real-time light weight active learning-based approach is presented for faster triaging in COVID-19 subjects in resource constrained settings. The tool, based on the you look only once (YOLO) network, has the capability of providing the quality of images based on the identification of various LUS landmarks, artefacts and manifestations, prediction of severity of lung infection, possibility of active learning based on the feedback from clinicians or on the image quality and a summarization of the significant frames which are having high severity of infection and high image quality for further analysis. The results show that the proposed tool has a mean average precision (mAP) of 66% at an Intersection over Union (IoU) threshold of 0.5 for the prediction of LUS landmarks. The 14MB lightweight YOLOv5s network achieves 123 FPS while running in a Quadro P4000 GPU. The tool is available for usage and analysis upon request from the authors.
Examining the Robustness of Spiking Neural Networks on Non-ideal Memristive Crossbars
Jun 20, 2022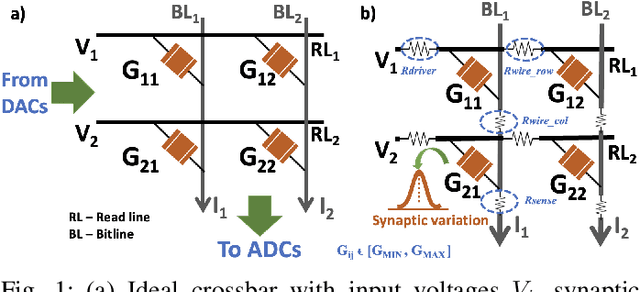
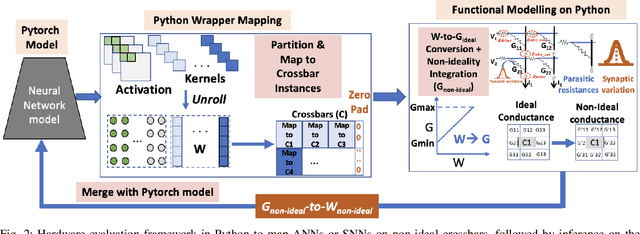
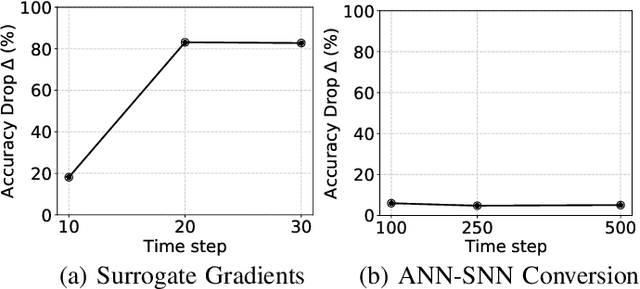
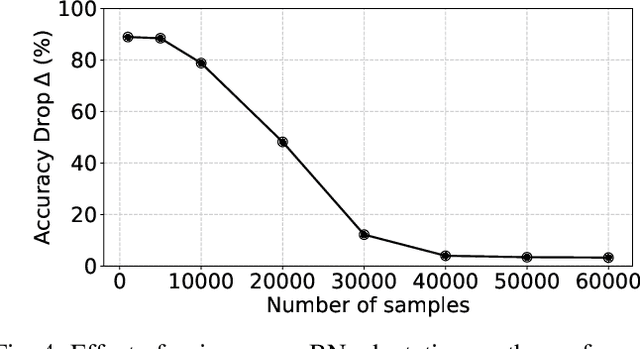
Spiking Neural Networks (SNNs) have recently emerged as the low-power alternative to Artificial Neural Networks (ANNs) owing to their asynchronous, sparse, and binary information processing. To improve the energy-efficiency and throughput, SNNs can be implemented on memristive crossbars where Multiply-and-Accumulate (MAC) operations are realized in the analog domain using emerging Non-Volatile-Memory (NVM) devices. Despite the compatibility of SNNs with memristive crossbars, there is little attention to study on the effect of intrinsic crossbar non-idealities and stochasticity on the performance of SNNs. In this paper, we conduct a comprehensive analysis of the robustness of SNNs on non-ideal crossbars. We examine SNNs trained via learning algorithms such as, surrogate gradient and ANN-SNN conversion. Our results show that repetitive crossbar computations across multiple time-steps induce error accumulation, resulting in a huge performance drop during SNN inference. We further show that SNNs trained with a smaller number of time-steps achieve better accuracy when deployed on memristive crossbars.
IterMiUnet: A lightweight architecture for automatic blood vessel segmentation
Aug 02, 2022
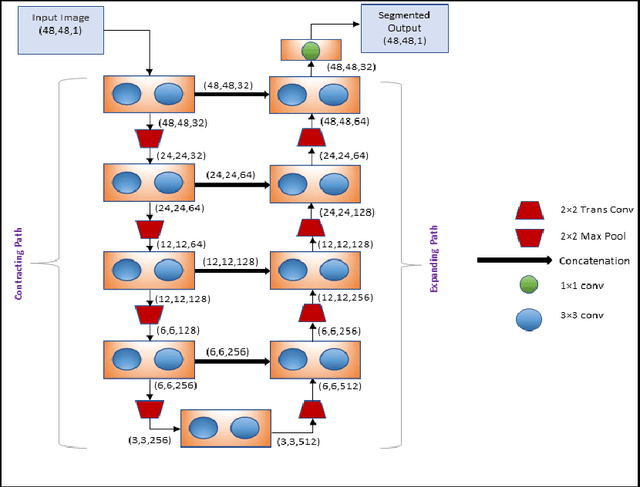
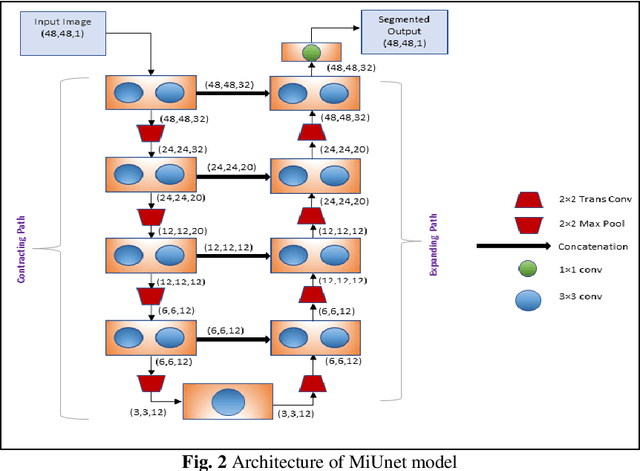
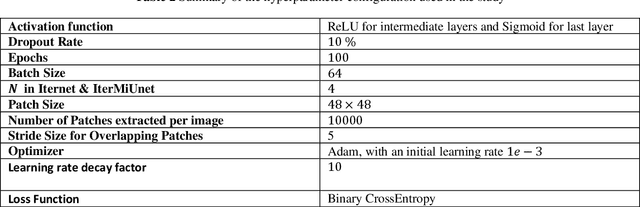
The automatic segmentation of blood vessels in fundus images can help analyze the condition of retinal vasculature, which is crucial for identifying various systemic diseases like hypertension, diabetes, etc. Despite the success of Deep Learning-based models in this segmentation task, most of them are heavily parametrized and thus have limited use in practical applications. This paper proposes IterMiUnet, a new lightweight convolution-based segmentation model that requires significantly fewer parameters and yet delivers performance similar to existing models. The model makes use of the excellent segmentation capabilities of Iternet architecture but overcomes its heavily parametrized nature by incorporating the encoder-decoder structure of MiUnet model within it. Thus, the new model reduces parameters without any compromise with the network's depth, which is necessary to learn abstract hierarchical concepts in deep models. This lightweight segmentation model speeds up training and inference time and is potentially helpful in the medical domain where data is scarce and, therefore, heavily parametrized models tend to overfit. The proposed model was evaluated on three publicly available datasets: DRIVE, STARE, and CHASE-DB1. Further cross-training and inter-rater variability evaluations have also been performed. The proposed model has a lot of potential to be utilized as a tool for the early diagnosis of many diseases.
First Glance Diagnosis: Brain Disease Classification with Single fMRI Volume
Aug 10, 2022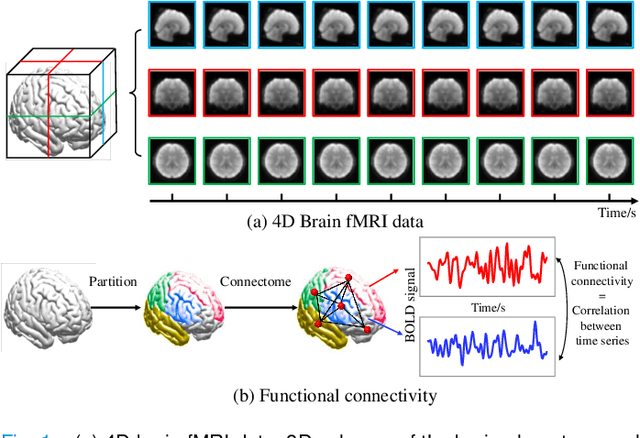
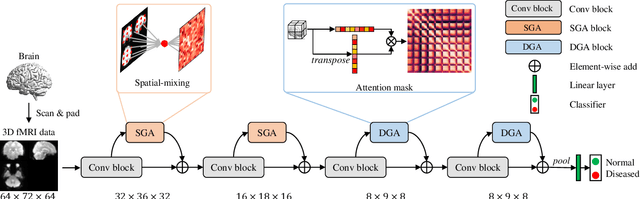
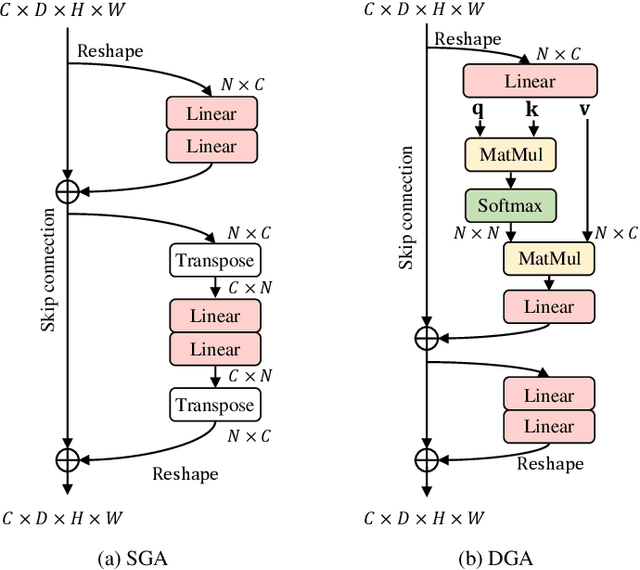

In neuroimaging analysis, functional magnetic resonance imaging (fMRI) can well assess brain function changes for brain diseases with no obvious structural lesions. So far, most deep-learning-based fMRI studies take functional connectivity as the basic feature in disease classification. However, functional connectivity is often calculated based on time series of predefined regions of interest and neglects detailed information contained in each voxel, which may accordingly deteriorate the performance of diagnostic models. Another methodological drawback is the limited sample size for the training of deep models. In this study, we propose BrainFormer, a general hybrid Transformer architecture for brain disease classification with single fMRI volume to fully exploit the voxel-wise details with sufficient data dimensions and sizes. BrainFormer is constructed by modeling the local cues within each voxel with 3D convolutions and capturing the global relations among distant regions with two global attention blocks. The local and global cues are aggregated in BrainFormer by a single-stream model. To handle multisite data, we propose a normalization layer to normalize the data into identical distribution. Finally, a Gradient-based Localization-map Visualization method is utilized for locating the possible disease-related biomarker. We evaluate BrainFormer on five independently acquired datasets including ABIDE, ADNI, MPILMBB, ADHD-200 and ECHO, with diseases of autism, Alzheimer's disease, depression, attention deficit hyperactivity disorder, and headache disorders. The results demonstrate the effectiveness and generalizability of BrainFormer for multiple brain diseases diagnosis. BrainFormer may promote neuroimaging-based precision diagnosis in clinical practice and motivate future study in fMRI analysis. Code is available at: https://github.com/ZiyaoZhangforPCL/BrainFormer.
Real-time Identification and Simultaneous Avoidance of Static and Dynamic Obstacles on Point Cloud for UAVs Navigation
Oct 20, 2021
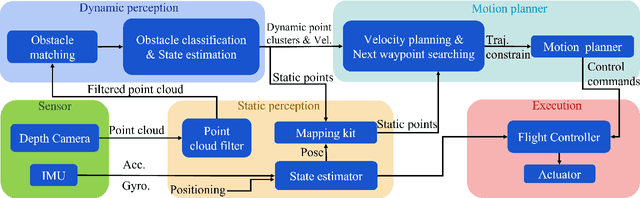
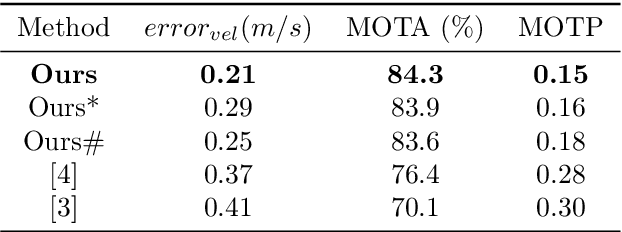
Avoiding hybrid obstacles in unknown scenarios with an efficient flight strategy is a key challenge for unmanned aerial vehicle applications. In this paper, we introduce a more robust technique to distinguish and track dynamic obstacles from static ones with only point cloud input. Then, to achieve dynamic avoidance, we propose the forbidden pyramids method to solve the desired vehicle velocity with an efficient sampling-based method in iteration. The motion primitives are generated by solving a nonlinear optimization problem with the constraint of desired velocity and the waypoint. Furthermore, we present several techniques to deal with the position estimation error for close objects, the error for deformable objects, and the time gap between different submodules. The proposed approach is implemented to run onboard in real-time and validated extensively in simulation and hardware tests, demonstrating our superiority in tracking robustness, energy cost, and calculating time.
Sample Condensation in Online Continual Learning
Jun 23, 2022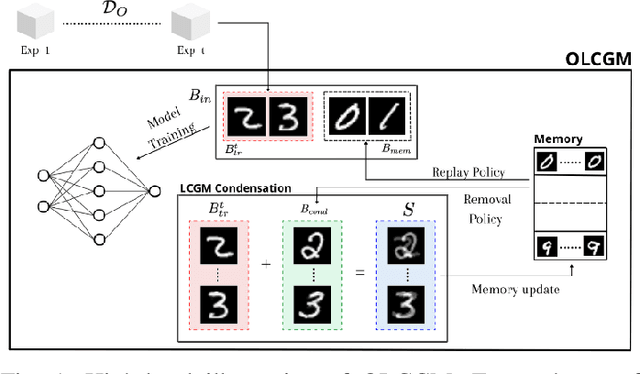


Online Continual learning is a challenging learning scenario where the model must learn from a non-stationary stream of data where each sample is seen only once. The main challenge is to incrementally learn while avoiding catastrophic forgetting, namely the problem of forgetting previously acquired knowledge while learning from new data. A popular solution in these scenario is to use a small memory to retain old data and rehearse them over time. Unfortunately, due to the limited memory size, the quality of the memory will deteriorate over time. In this paper we propose OLCGM, a novel replay-based continual learning strategy that uses knowledge condensation techniques to continuously compress the memory and achieve a better use of its limited size. The sample condensation step compresses old samples, instead of removing them like other replay strategies. As a result, the experiments show that, whenever the memory budget is limited compared to the complexity of the data, OLCGM improves the final accuracy compared to state-of-the-art replay strategies.
Gradient-based Neuromorphic Learning on Dynamical RRAM Arrays
Jun 26, 2022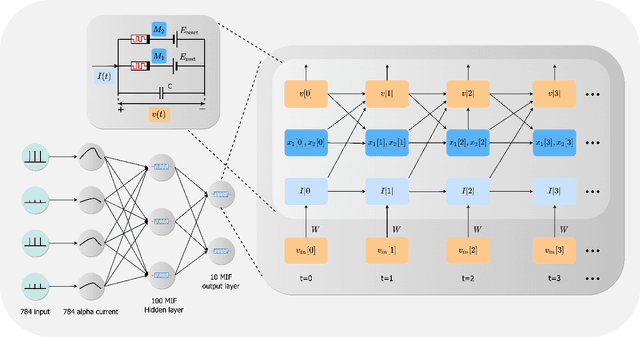
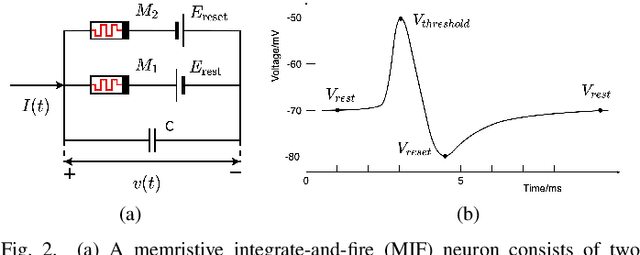
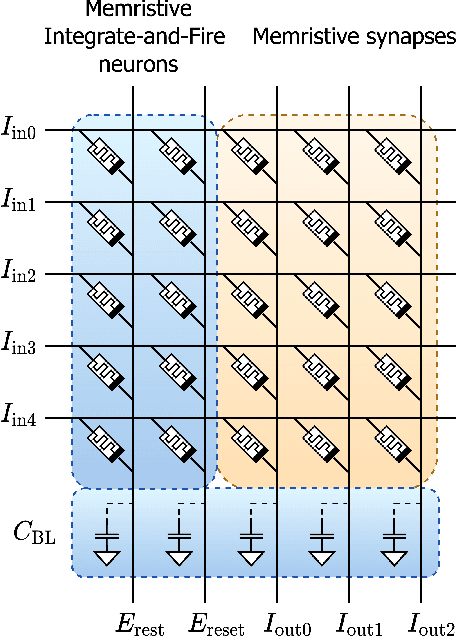
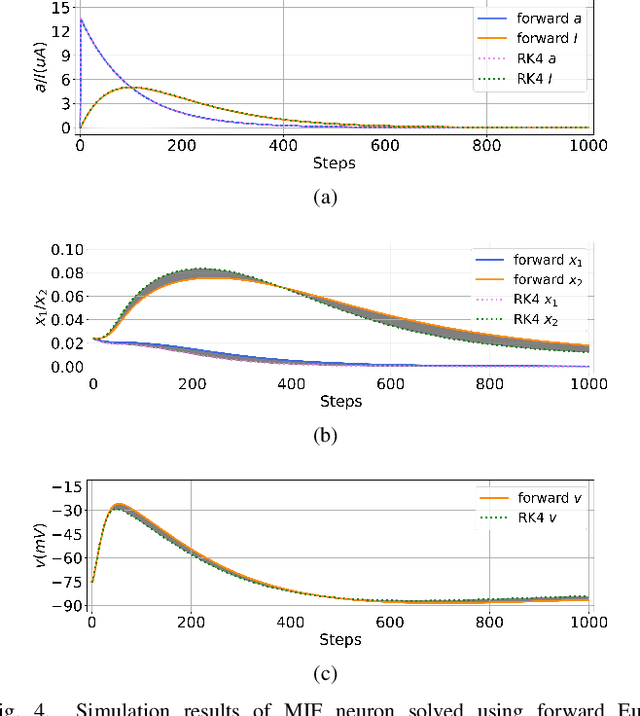
We present MEMprop, the adoption of gradient-based learning to train fully memristive spiking neural networks (MSNNs). Our approach harnesses intrinsic device dynamics to trigger naturally arising voltage spikes. These spikes emitted by memristive dynamics are analog in nature, and thus fully differentiable, which eliminates the need for surrogate gradient methods that are prevalent in the spiking neural network (SNN) literature. Memristive neural networks typically either integrate memristors as synapses that map offline-trained networks, or otherwise rely on associative learning mechanisms to train networks of memristive neurons. We instead apply the backpropagation through time (BPTT) training algorithm directly on analog SPICE models of memristive neurons and synapses. Our implementation is fully memristive, in that synaptic weights and spiking neurons are both integrated on resistive RAM (RRAM) arrays without the need for additional circuits to implement spiking dynamics, e.g., analog-to-digital converters (ADCs) or thresholded comparators. As a result, higher-order electrophysical effects are fully exploited to use the state-driven dynamics of memristive neurons at run time. By moving towards non-approximate gradient-based learning, we obtain highly competitive accuracy amongst previously reported lightweight dense fully MSNNs on several benchmarks.
Machine Learning Approaches to Predict Breast Cancer: Bangladesh Perspective
Jun 30, 2022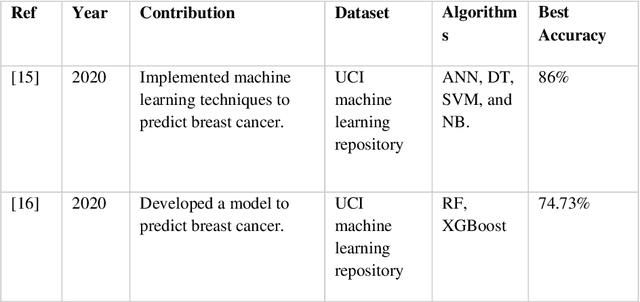
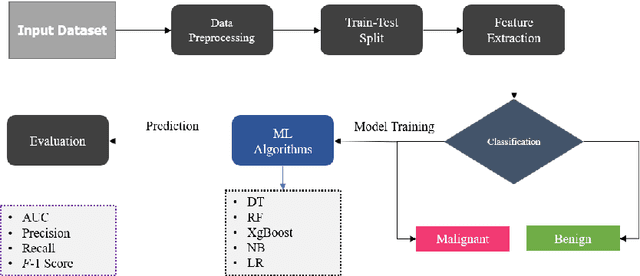
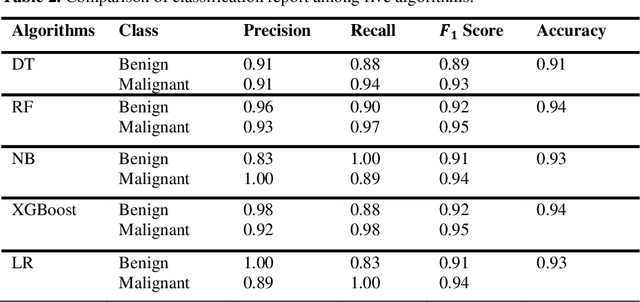
Nowadays, Breast cancer has risen to become one of the most prominent causes of death in recent years. Among all malignancies, this is the most frequent and the major cause of death for women globally. Manually diagnosing this disease requires a good amount of time and expertise. Breast cancer detection is time-consuming, and the spread of the disease can be reduced by developing machine-based breast cancer predictions. In Machine learning, the system can learn from prior instances and find hard-to-detect patterns from noisy or complicated data sets using various statistical, probabilistic, and optimization approaches. This work compares several machine learning algorithm's classification accuracy, precision, sensitivity, and specificity on a newly collected dataset. In this work Decision tree, Random Forest, Logistic Regression, Naive Bayes, and XGBoost, these five machine learning approaches have been implemented to get the best performance on our dataset. This study focuses on finding the best algorithm that can forecast breast cancer with maximum accuracy in terms of its classes. This work evaluated the quality of each algorithm's data classification in terms of efficiency and effectiveness. And also compared with other published work on this domain. After implementing the model, this study achieved the best model accuracy, 94% on Random Forest and XGBoost.
Interplay between Distributed AI Workflow and URLLC
Aug 02, 2022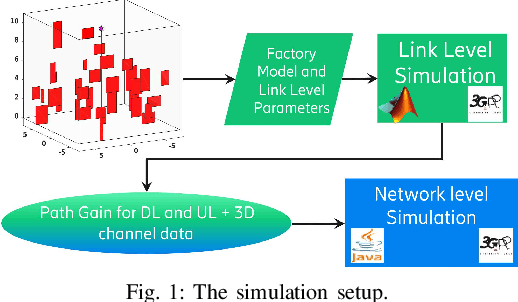
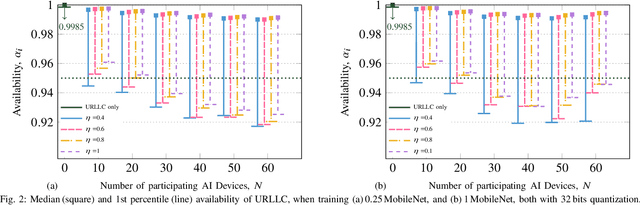
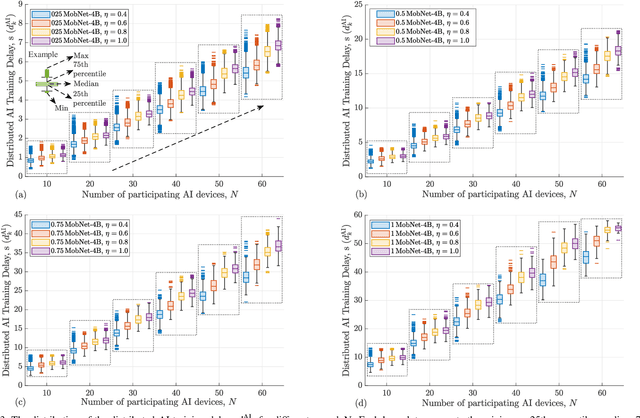

Distributed artificial intelligence (AI) has recently accomplished tremendous breakthroughs in various communication services, ranging from fault-tolerant factory automation to smart cities. When distributed learning is run over a set of wireless connected devices, random channel fluctuations, and the incumbent services simultaneously running on the same network affect the performance of distributed learning. In this paper, we investigate the interplay between distributed AI workflow and ultra-reliable low latency communication (URLLC) services running concurrently over a network. Using 3GPP compliant simulations in a factory automation use case, we show the impact of various distributed AI settings (e.g., model size and the number of participating devices) on the convergence time of distributed AI and the application layer performance of URLLC. Unless we leverage the existing 5G-NR quality of service handling mechanisms to separate the traffic from the two services, our simulation results show that the impact of distributed AI on the availability of the URLLC devices is significant. Moreover, with proper setting of distributed AI (e.g., proper user selection), we can substantially reduce network resource utilization, leading to lower latency for distributed AI and higher availability for the URLLC users. Our results provide important insights for future 6G and AI standardization.
A Fast, Autonomous, Bipedal Walking Behavior over Rapid Regions
Jul 17, 2022
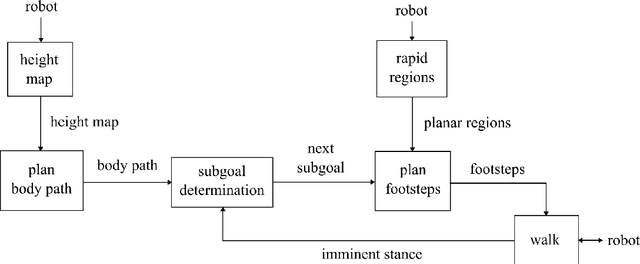
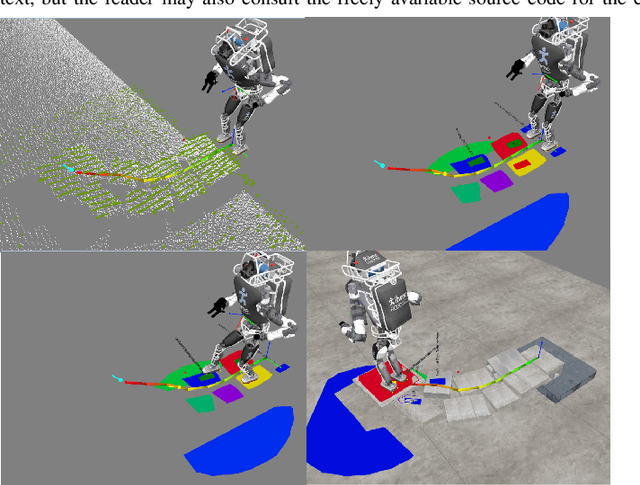
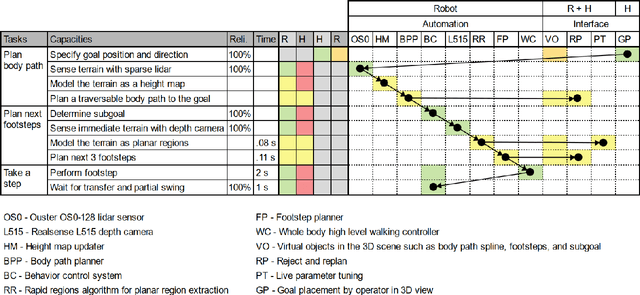
In trying to build humanoid robots that perform useful tasks in a world built for humans, we address the problem of autonomous locomotion. Humanoid robot planning and control algorithms for walking over rough terrain are becoming increasingly capable. At the same time, commercially available depth cameras have been getting more accurate and GPU computing has become a primary tool in AI research. In this paper, we present a newly constructed behavior control system for achieving fast, autonomous, bipedal walking, without pauses or deliberation. We achieve this using a recently published rapid planar regions perception algorithm, a height map based body path planner, an A* footstep planner, and a momentum-based walking controller. We put these elements together to form a behavior control system supported by modern software development practices and simulation tools.