 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
An Auto-Regressive Formulation for Smoothing and Moving Mean with Exponentially Tapered Windows
Jun 29, 2022
We investigate an auto-regressive formulation for the problem of smoothing time-series by manipulating the inherent objective function of the traditional moving mean smoothers. Not only the auto-regressive smoothers enforce a higher degree of smoothing, they are just as efficient as the traditional moving means and can be optimized accordingly with respect to the input dataset. Interestingly, the auto-regressive models result in moving means with exponentially tapered windows.
General Optimization Framework for Recurrent Reachability Objectives
May 27, 2022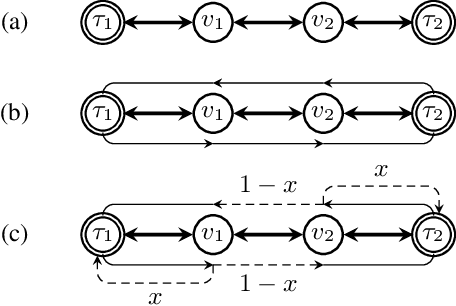
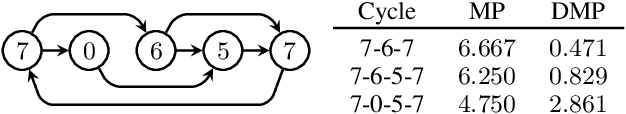
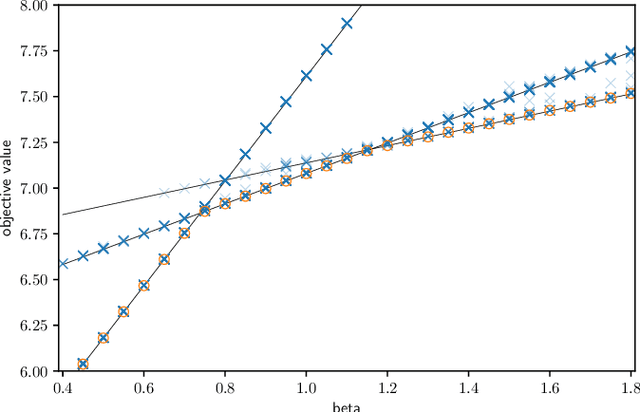
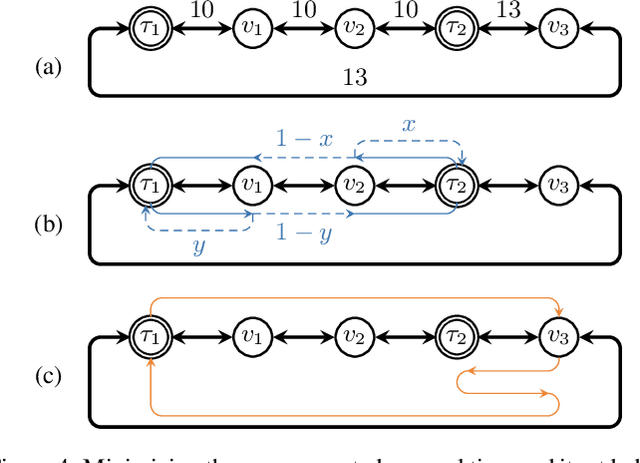
We consider the mobile robot path planning problem for a class of recurrent reachability objectives. These objectives are parameterized by the expected time needed to visit one position from another, the expected square of this time, and also the frequency of moves between two neighboring locations. We design an efficient strategy synthesis algorithm for recurrent reachability objectives and demonstrate its functionality on non-trivial instances.
"Double vaccinated, 5G boosted!": Learning Attitudes towards COVID-19 Vaccination from Social Media
Jun 27, 2022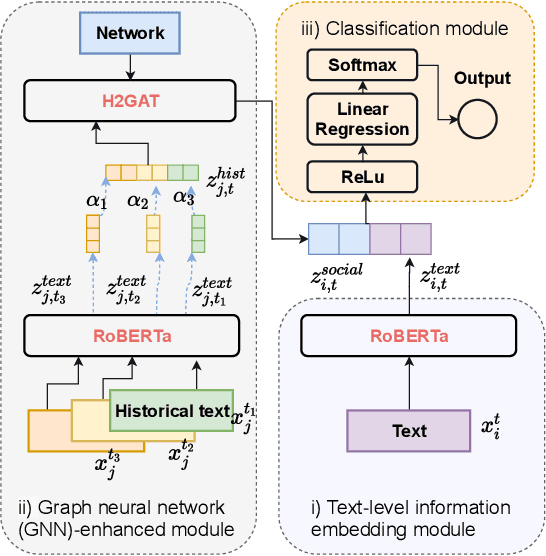
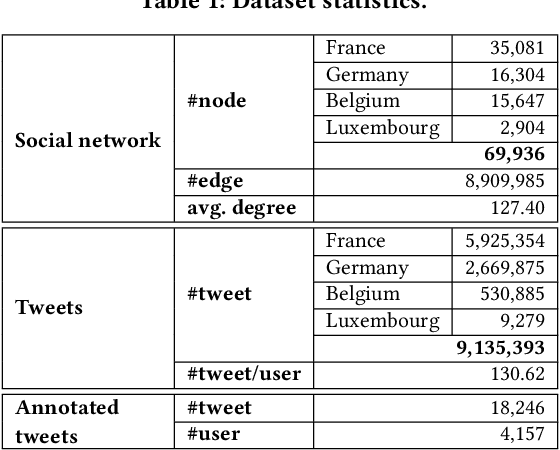

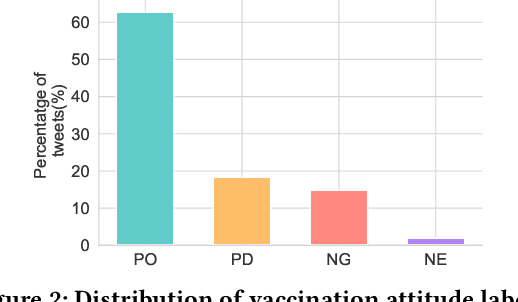
To address the vaccine hesitancy which impairs the efforts of the COVID-19 vaccination campaign, it is imperative to understand public vaccination attitudes and timely grasp their changes. In spite of reliability and trustworthiness, conventional attitude collection based on surveys is time-consuming and expensive, and cannot follow the fast evolution of vaccination attitudes. We leverage the textual posts on social media to extract and track users' vaccination stances in near real time by proposing a deep learning framework. To address the impact of linguistic features such as sarcasm and irony commonly used in vaccine-related discourses, we integrate into the framework the recent posts of a user's social network neighbours to help detect the user's genuine attitude. Based on our annotated dataset from Twitter, the models instantiated from our framework can increase the performance of attitude extraction by up to 23% compared to state-of-the-art text-only models. Using this framework, we successfully validate the feasibility of using social media to track the evolution of vaccination attitudes in real life. We further show one practical use of our framework by validating the possibility to forecast a user's vaccine hesitancy changes with information perceived from social media.
Deep Learning Driven Natural Languages Text to SQL Query Conversion: A Survey
Aug 08, 2022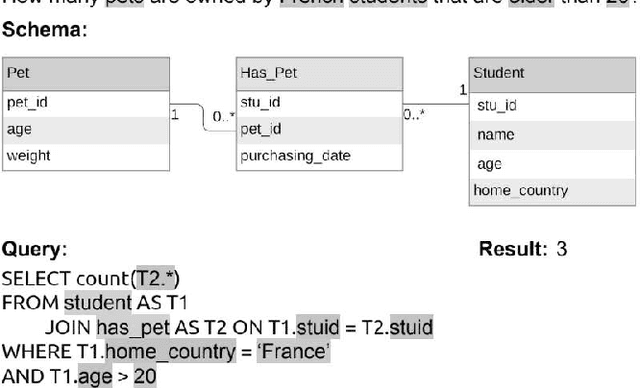
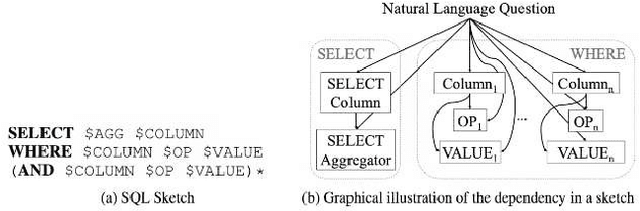
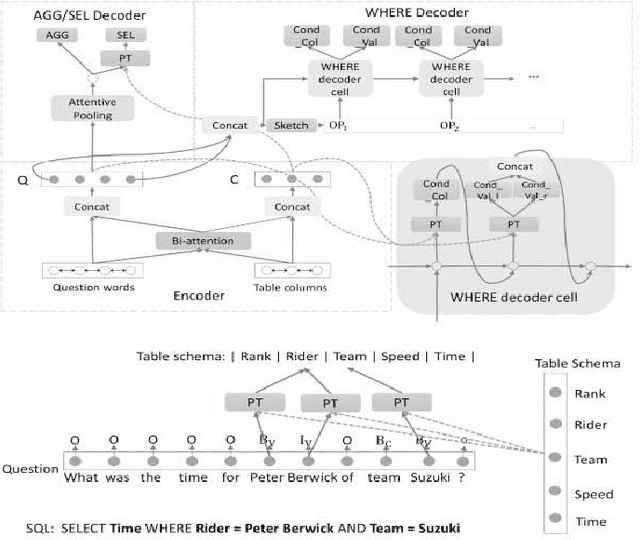
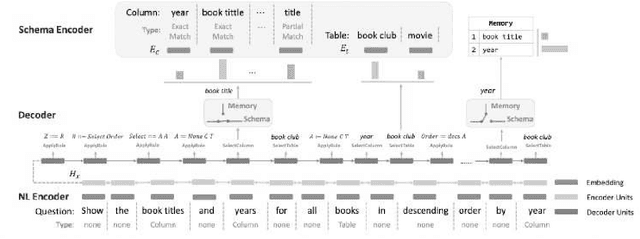
With the future striving toward data-centric decision-making, seamless access to databases is of utmost importance. There is extensive research on creating an efficient text-to-sql (TEXT2SQL) model to access data from the database. Using a Natural language is one of the best interfaces that can bridge the gap between the data and results by accessing the database efficiently, especially for non-technical users. It will open the doors and create tremendous interest among users who are well versed in technical skills or not very skilled in query languages. Even if numerous deep learning-based algorithms are proposed or studied, there still is very challenging to have a generic model to solve the data query issues using natural language in a real-work scenario. The reason is the use of different datasets in different studies, which comes with its limitations and assumptions. At the same time, we do lack a thorough understanding of these proposed models and their limitations with the specific dataset it is trained on. In this paper, we try to present a holistic overview of 24 recent neural network models studied in the last couple of years, including their architectures involving convolutional neural networks, recurrent neural networks, pointer networks, reinforcement learning, generative models, etc. We also give an overview of the 11 datasets that are widely used to train the models for TEXT2SQL technologies. We also discuss the future application possibilities of TEXT2SQL technologies for seamless data queries.
Direct Localization in Underwater Acoustics via Convolutional Neural Networks: A Data-Driven Approach
Jul 20, 2022
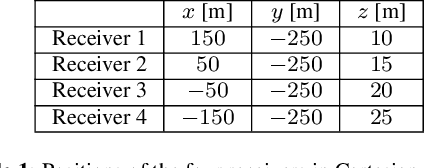
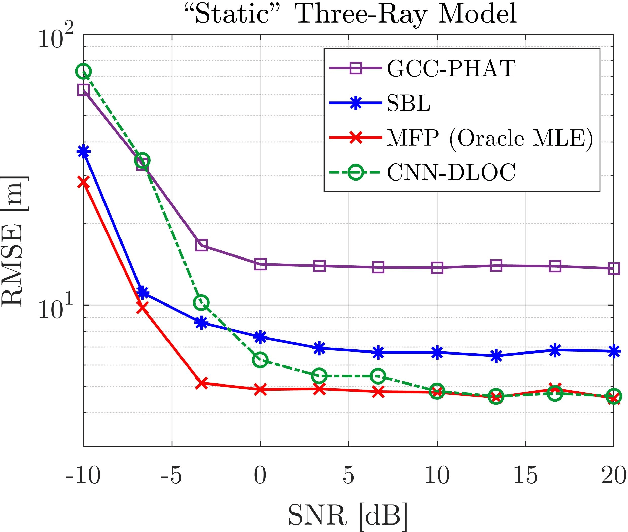
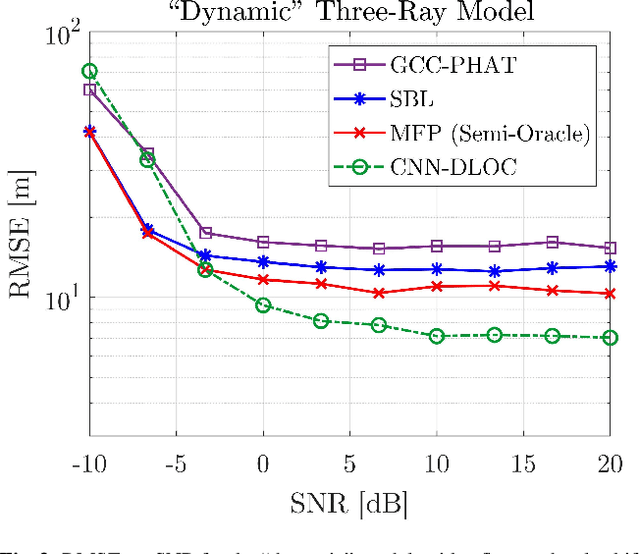
Direct localization (DLOC) methods, which use the observed data to localize a source at an unknown position in a one-step procedure, generally outperform their indirect two-step counterparts (e.g., using time-difference of arrivals). However, underwater acoustic DLOC methods require prior knowledge of the environment, and are computationally costly, hence slow. We propose, what is to the best of our knowledge, the first data-driven DLOC method. Inspired by classical and contemporary optimal model-based DLOC solutions, and leveraging the capabilities of convolutional neural networks (CNNs), we devise a holistic CNN-based solution. Our method includes a specifically-tailored input structure, architecture, loss function, and a progressive training procedure, which are of independent interest in the broader context of machine learning. We demonstrate that our method outperforms attractive alternatives, and asymptotically matches the performance of an oracle optimal model-based solution.
CSDI: Conditional Score-based Diffusion Models for Probabilistic Time Series Imputation
Jul 07, 2021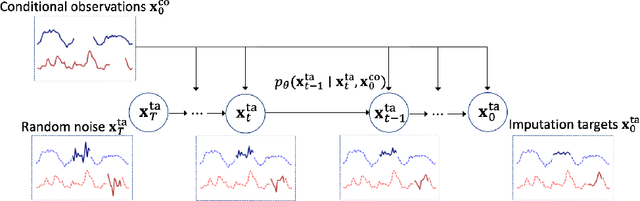

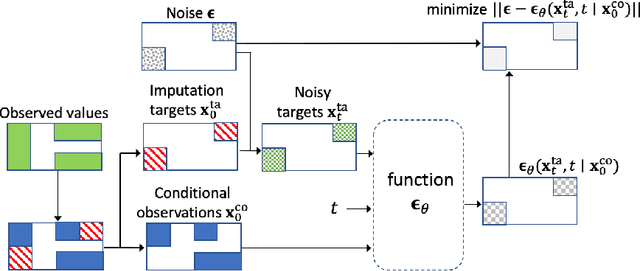
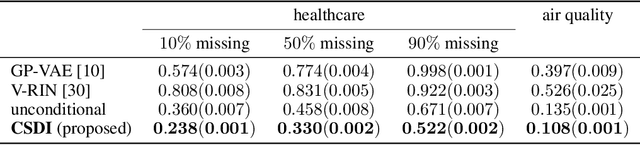
The imputation of missing values in time series has many applications in healthcare and finance. While autoregressive models are natural candidates for time series imputation, score-based diffusion models have recently outperformed existing counterparts including autoregressive models in many tasks such as image generation and audio synthesis, and would be promising for time series imputation. In this paper, we propose Conditional Score-based Diffusion models for Imputation (CSDI), a novel time series imputation method that utilizes score-based diffusion models conditioned on observed data. Unlike existing score-based approaches, the conditional diffusion model is explicitly trained for imputation and can exploit correlations between observed values. On healthcare and environmental data, CSDI improves by 40-70% over existing probabilistic imputation methods on popular performance metrics. In addition, deterministic imputation by CSDI reduces the error by 5-20% compared to the state-of-the-art deterministic imputation methods. Furthermore, CSDI can also be applied to time series interpolation and probabilistic forecasting, and is competitive with existing baselines.
Mathematical Foundations of Graph-Based Bayesian Semi-Supervised Learning
Jul 03, 2022
In recent decades, science and engineering have been revolutionized by a momentous growth in the amount of available data. However, despite the unprecedented ease with which data are now collected and stored, labeling data by supplementing each feature with an informative tag remains to be challenging. Illustrative tasks where the labeling process requires expert knowledge or is tedious and time-consuming include labeling X-rays with a diagnosis, protein sequences with a protein type, texts by their topic, tweets by their sentiment, or videos by their genre. In these and numerous other examples, only a few features may be manually labeled due to cost and time constraints. How can we best propagate label information from a small number of expensive labeled features to a vast number of unlabeled ones? This is the question addressed by semi-supervised learning (SSL). This article overviews recent foundational developments on graph-based Bayesian SSL, a probabilistic framework for label propagation using similarities between features. SSL is an active research area and a thorough review of the extant literature is beyond the scope of this article. Our focus will be on topics drawn from our own research that illustrate the wide range of mathematical tools and ideas that underlie the rigorous study of the statistical accuracy and computational efficiency of graph-based Bayesian SSL.
Augmented Reality-Empowered Network Planning Services for Private Networks
Jun 24, 2022
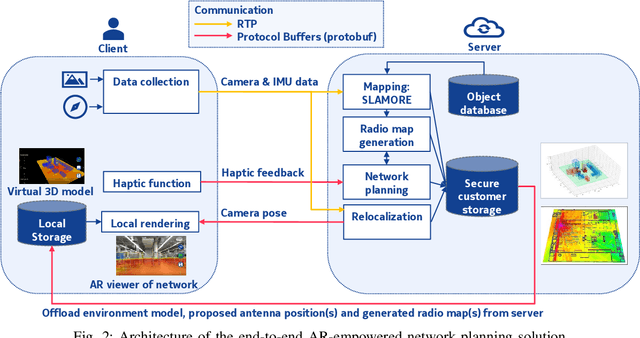
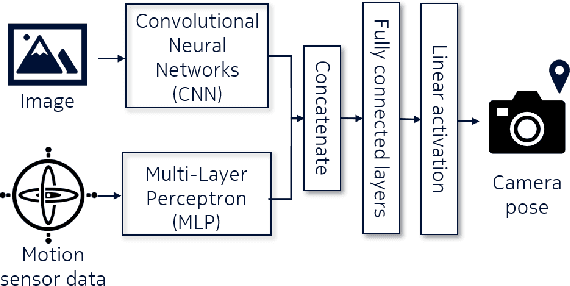
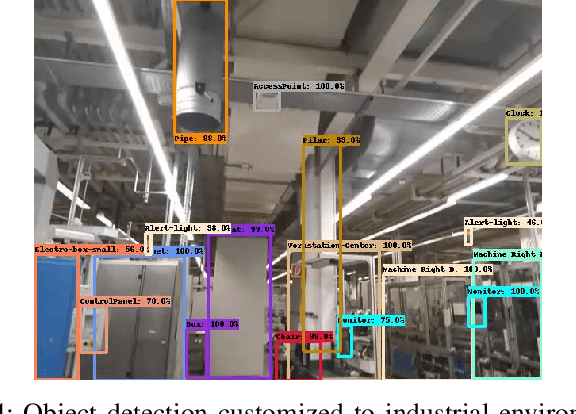
To support Industry 4.0 applications with haptics and human-machine interaction, the sixth generation (6G) requires a new framework that is fully autonomous, visual, and interactive. In this paper, we propose a novel framework for private network planning services, providing an end-to-end solution that receives visual and sensory data from the user device, reconstructs the 3D network environment and performs network planning on the server, and visualizes the network performance with augmented reality (AR) on the display of the user devices. The solution is empowered by three key technical components: 1) vision- and sensor fusion-based 3D environment reconstruction, 2) ray tracing-based radio map generation and network planning, and 3) AR-empowered network visualization enabled by real-time camera relocalization. We conducted the proof-of-concept in a Bosch plant in Germany and showed good network coverage of the optimized antenna location, as well as high accuracy in both environment reconstruction and camera relocalization. We also achieved real-time AR-supported network monitoring with an end-to-end latency of about 32 ms per frame.
Continuous Temporal Graph Networks for Event-Based Graph Data
May 31, 2022
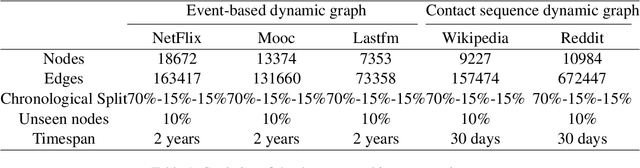
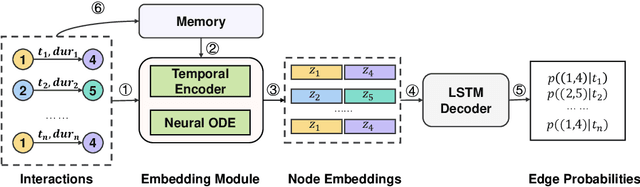
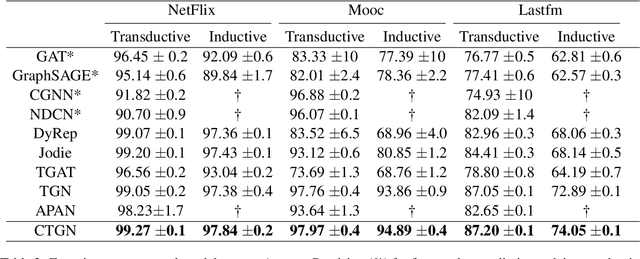
There has been an increasing interest in modeling continuous-time dynamics of temporal graph data. Previous methods encode time-evolving relational information into a low-dimensional representation by specifying discrete layers of neural networks, while real-world dynamic graphs often vary continuously over time. Hence, we propose Continuous Temporal Graph Networks (CTGNs) to capture the continuous dynamics of temporal graph data. We use both the link starting timestamps and link duration as evolving information to model the continuous dynamics of nodes. The key idea is to use neural ordinary differential equations (ODE) to characterize the continuous dynamics of node representations over dynamic graphs. We parameterize ordinary differential equations using a novel graph neural network. The existing dynamic graph networks can be considered as a specific discretization of CTGNs. Experiment results on both transductive and inductive tasks demonstrate the effectiveness of our proposed approach over competitive baselines.
Real-time Optimal Landing Control of the MIT Mini Cheetah
Oct 06, 2021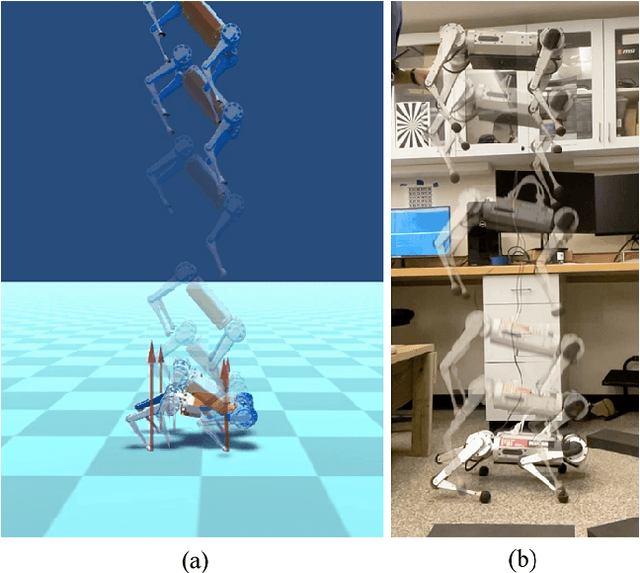
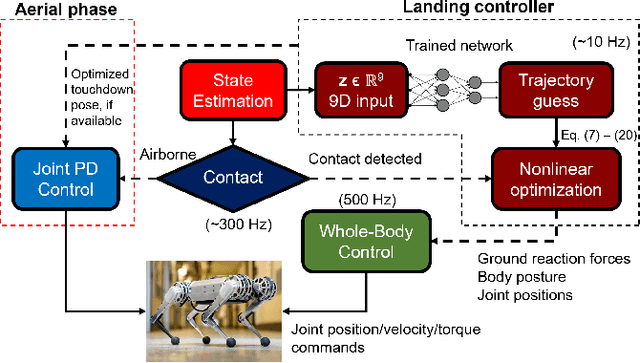

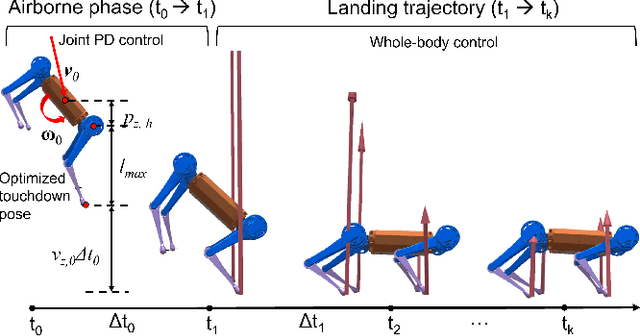
Quadrupedal landing is a complex process involving large impacts, elaborate contact transitions, and is a crucial recovery behavior observed in many biological animals. This work presents a real-time, optimal landing controller that is free of pre-specified contact schedules. The controller determines optimal touchdown postures and reaction force profiles and is able to recover from a variety of falling configurations. The quadrupedal platform used, the MIT Mini Cheetah, recovered safely from drops of up to 8 m in simulation, as well as from a range of orientations and planar velocities. The controller is also tested on hardware, successfully recovering from drops of up to 2 m.