 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
State Supervised Steering Function for Sampling-based Kinodynamic Planning
Jun 15, 2022
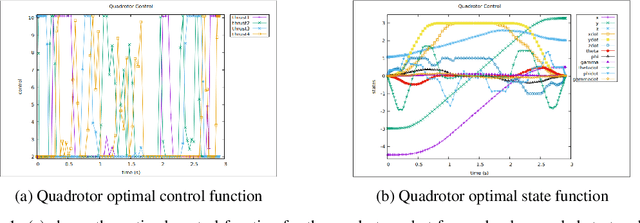

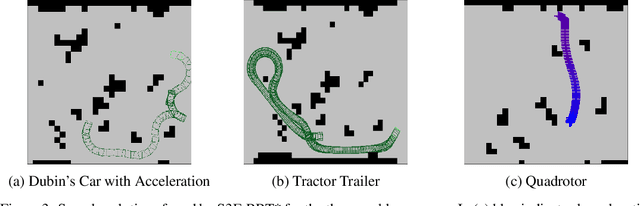
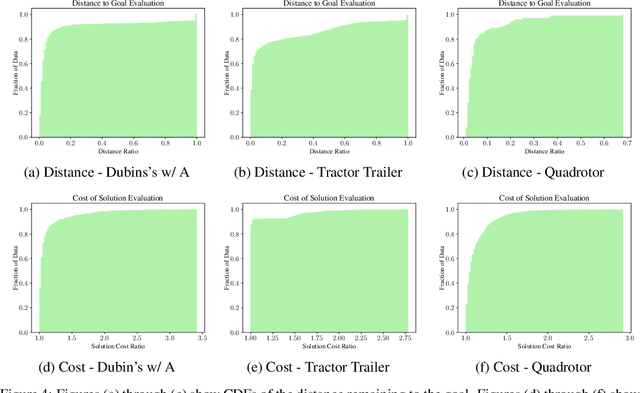
Sampling-based motion planners such as RRT* and BIT*, when applied to kinodynamic motion planning, rely on steering functions to generate time-optimal solutions connecting sampled states. Implementing exact steering functions requires either analytical solutions to the time-optimal control problem, or nonlinear programming (NLP) solvers to solve the boundary value problem given the system's kinodynamic equations. Unfortunately, analytical solutions are unavailable for many real-world domains, and NLP solvers are prohibitively computationally expensive, hence fast and optimal kinodynamic motion planning remains an open problem. We provide a solution to this problem by introducing State Supervised Steering Function (S3F), a novel approach to learn time-optimal steering functions. S3F is able to produce near-optimal solutions to the steering function orders of magnitude faster than its NLP counterpart. Experiments conducted on three challenging robot domains show that RRT* using S3F significantly outperforms state-of-the-art planning approaches on both solution cost and runtime. We further provide a proof of probabilistic completeness of RRT* modified to use S3F.
FEANet: Feature-Enhanced Attention Network for RGB-Thermal Real-time Semantic Segmentation
Oct 18, 2021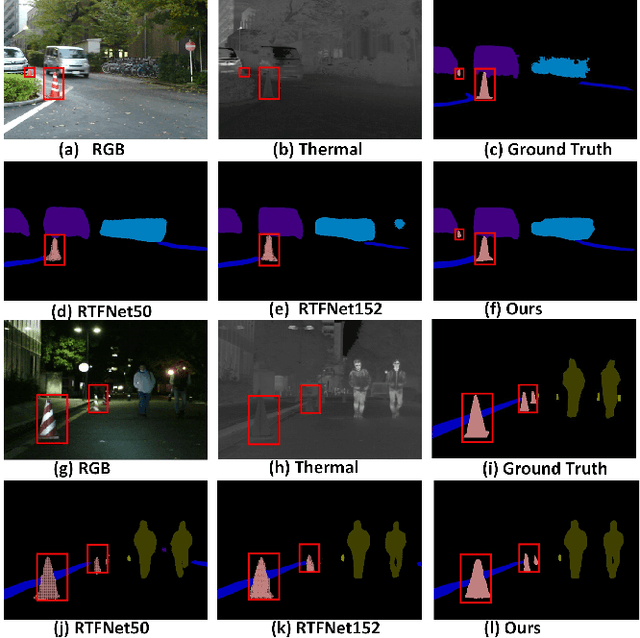
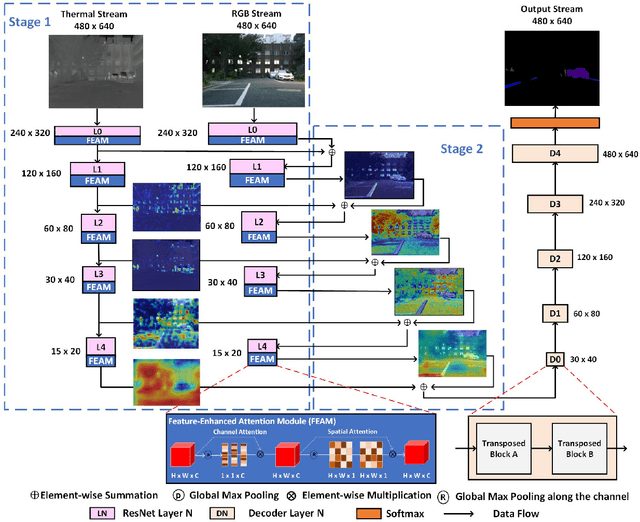
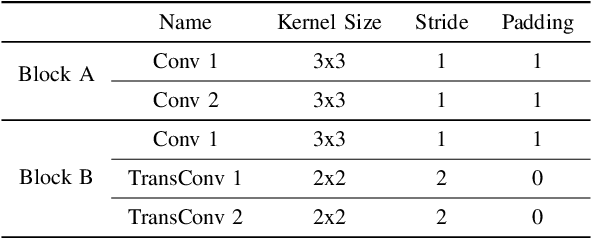
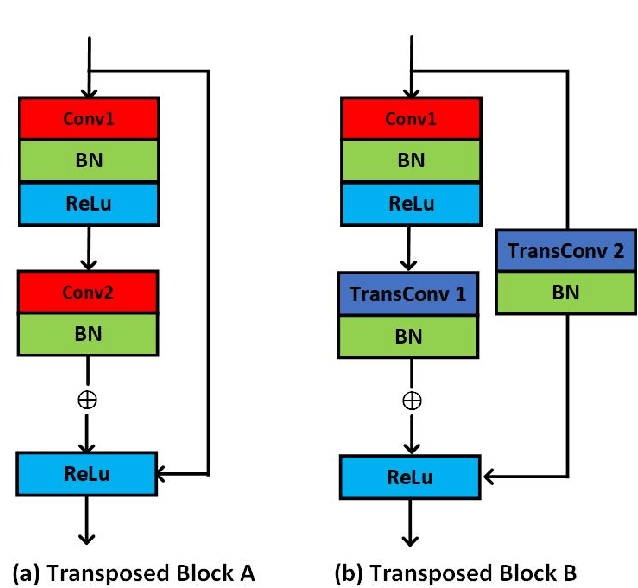
The RGB-Thermal (RGB-T) information for semantic segmentation has been extensively explored in recent years. However, most existing RGB-T semantic segmentation usually compromises spatial resolution to achieve real-time inference speed, which leads to poor performance. To better extract detail spatial information, we propose a two-stage Feature-Enhanced Attention Network (FEANet) for the RGB-T semantic segmentation task. Specifically, we introduce a Feature-Enhanced Attention Module (FEAM) to excavate and enhance multi-level features from both the channel and spatial views. Benefited from the proposed FEAM module, our FEANet can preserve the spatial information and shift more attention to high-resolution features from the fused RGB-T images. Extensive experiments on the urban scene dataset demonstrate that our FEANet outperforms other state-of-the-art (SOTA) RGB-T methods in terms of objective metrics and subjective visual comparison (+2.6% in global mAcc and +0.8% in global mIoU). For the 480 x 640 RGB-T test images, our FEANet can run with a real-time speed on an NVIDIA GeForce RTX 2080 Ti card.
On-Device CPU Scheduling for Sense-React Systems
Aug 14, 2022

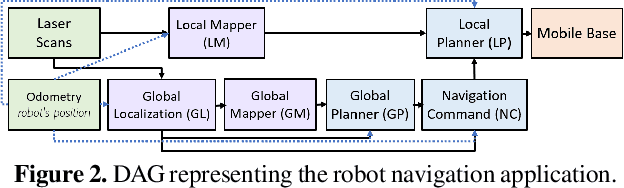
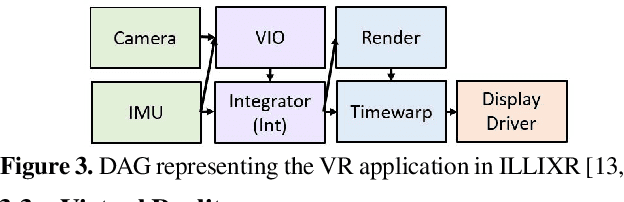
Sense-react systems (e.g. robotics and AR/VR) have to take highly responsive real-time actions, driven by complex decisions involving a pipeline of sensing, perception, planning, and reaction tasks. These tasks must be scheduled on resource-constrained devices such that the performance goals and the requirements of the application are met. This is a difficult scheduling problem that requires handling multiple scheduling dimensions, and variations in resource usage and availability. In practice, system designers manually tune parameters for their specific hardware and application, which results in poor generalization and increases the development burden. In this work, we highlight the emerging need for scheduling CPU resources at runtime in sense-react systems. We study three canonical applications (face tracking, robot navigation, and VR) to first understand the key scheduling requirements for such systems. Armed with this understanding, we develop a scheduling framework, Catan, that dynamically schedules compute resources across different components of an app so as to meet the specified application requirements. Through experiments with a prototype implemented on a widely-used robotics framework (ROS) and an open-source AR/VR platform, we show the impact of system scheduling on meeting the performance goals for the three applications, how Catan is able to achieve better application performance than hand-tuned configurations, and how it dynamically adapts to runtime variations.
Sequential Recommendation Model for Next Purchase Prediction
Jul 06, 2022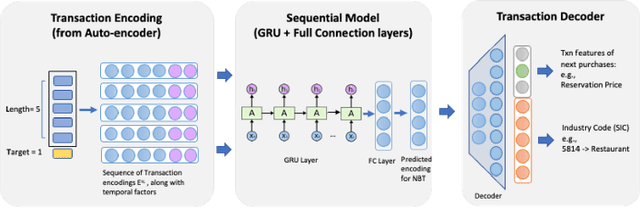

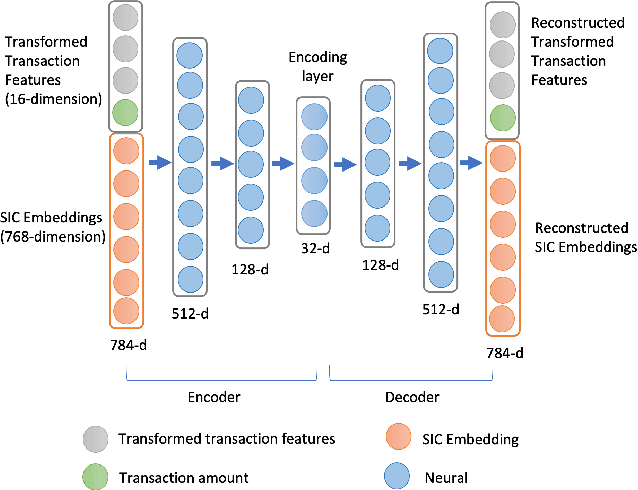

Timeliness and contextual accuracy of recommendations are increasingly important when delivering contemporary digital marketing experiences. Conventional recommender systems (RS) suggest relevant but time-invariant items to users by accounting for their past purchases. These recommendations only map to customers' general preferences rather than a customer's specific needs immediately preceding a purchase. In contrast, RSs that consider the order of transactions, purchases, or experiences to measure evolving preferences can offer more salient and effective recommendations to customers: Sequential RSs not only benefit from a better behavioral understanding of a user's current needs but also better predictive power. In this paper, we demonstrate and rank the effectiveness of a sequential recommendation system by utilizing a production dataset of over 2.7 million credit card transactions for 46K cardholders. The method first employs an autoencoder on raw transaction data and submits observed transaction encodings to a GRU-based sequential model. The sequential model produces a MAP@1 metric of 47% on the out-of-sample test set, in line with existing research. We also discuss implications for embedding real-time predictions using the sequential RS into Nexus, a scalable, low-latency, event-based digital experience architecture.
GNN Transformation Framework for Improving Efficiency and Scalability
Jul 25, 2022
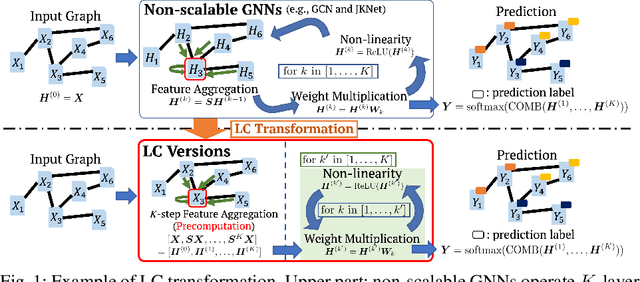
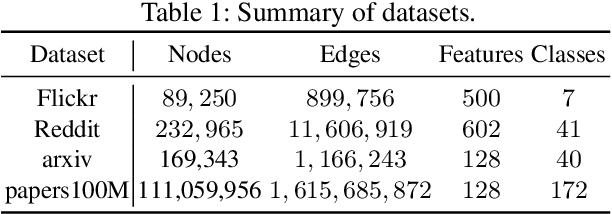
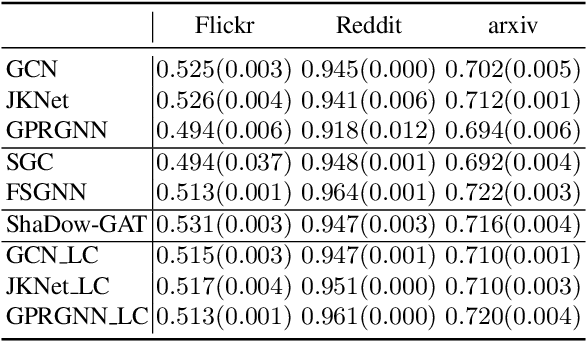
We propose a framework that automatically transforms non-scalable GNNs into precomputation-based GNNs which are efficient and scalable for large-scale graphs. The advantages of our framework are two-fold; 1) it transforms various non-scalable GNNs to scale well to large-scale graphs by separating local feature aggregation from weight learning in their graph convolution, 2) it efficiently executes precomputation on GPU for large-scale graphs by decomposing their edges into small disjoint and balanced sets. Through extensive experiments with large-scale graphs, we demonstrate that the transformed GNNs run faster in training time than existing GNNs while achieving competitive accuracy to the state-of-the-art GNNs. Consequently, our transformation framework provides simple and efficient baselines for future research on scalable GNNs.
The Conversational Short-phrase Speaker Diarization (CSSD) Task: Dataset, Evaluation Metric and Baselines
Aug 17, 2022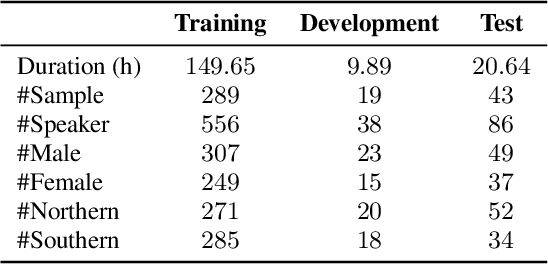

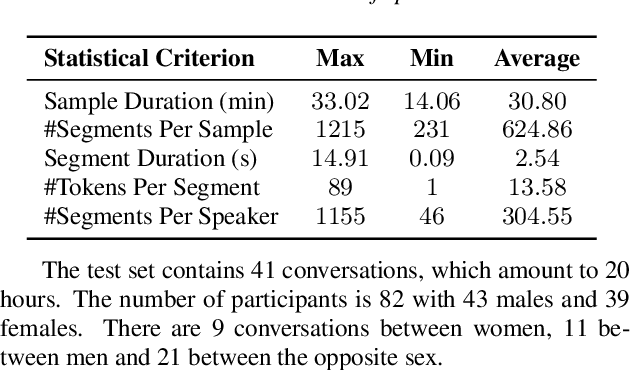
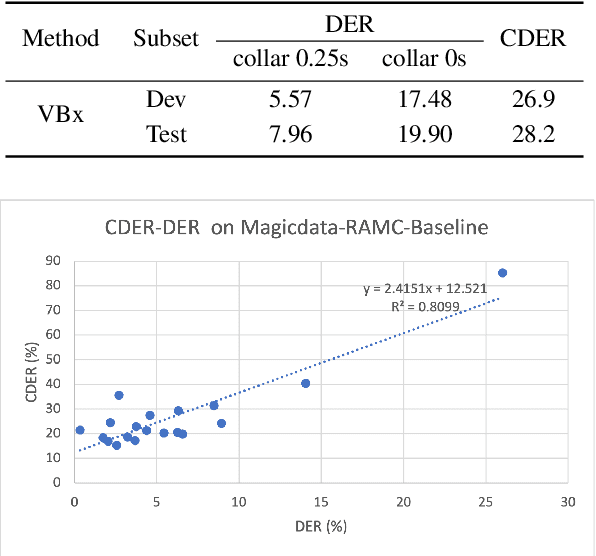
The conversation scenario is one of the most important and most challenging scenarios for speech processing technologies because people in conversation respond to each other in a casual style. Detecting the speech activities of each person in a conversation is vital to downstream tasks, like natural language processing, machine translation, etc. People refer to the detection technology of "who speak when" as speaker diarization (SD). Traditionally, diarization error rate (DER) has been used as the standard evaluation metric of SD systems for a long time. However, DER fails to give enough importance to short conversational phrases, which are short but important on the semantic level. Also, a carefully and accurately manually-annotated testing dataset suitable for evaluating the conversational SD technologies is still unavailable in the speech community. In this paper, we design and describe the Conversational Short-phrases Speaker Diarization (CSSD) task, which consists of training and testing datasets, evaluation metric and baselines. In the dataset aspect, despite the previously open-sourced 180-hour conversational MagicData-RAMC dataset, we prepare an individual 20-hour conversational speech test dataset with carefully and artificially verified speakers timestamps annotations for the CSSD task. In the metric aspect, we design the new conversational DER (CDER) evaluation metric, which calculates the SD accuracy at the utterance level. In the baseline aspect, we adopt a commonly used method: Variational Bayes HMM x-vector system, as the baseline of the CSSD task. Our evaluation metric is publicly available at https://github.com/SpeechClub/CDER_Metric.
Artificial Intelligence Empowered Multiple Access for Ultra Reliable and Low Latency THz Wireless Networks
Aug 17, 2022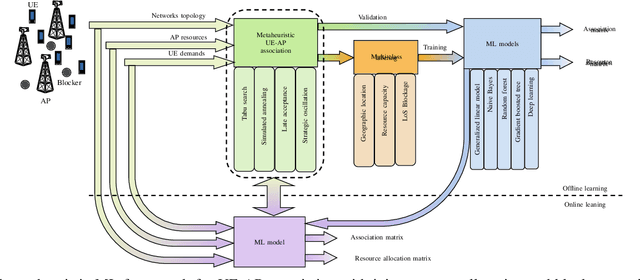
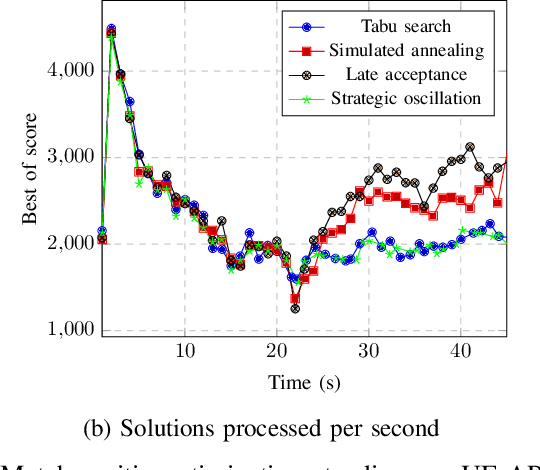
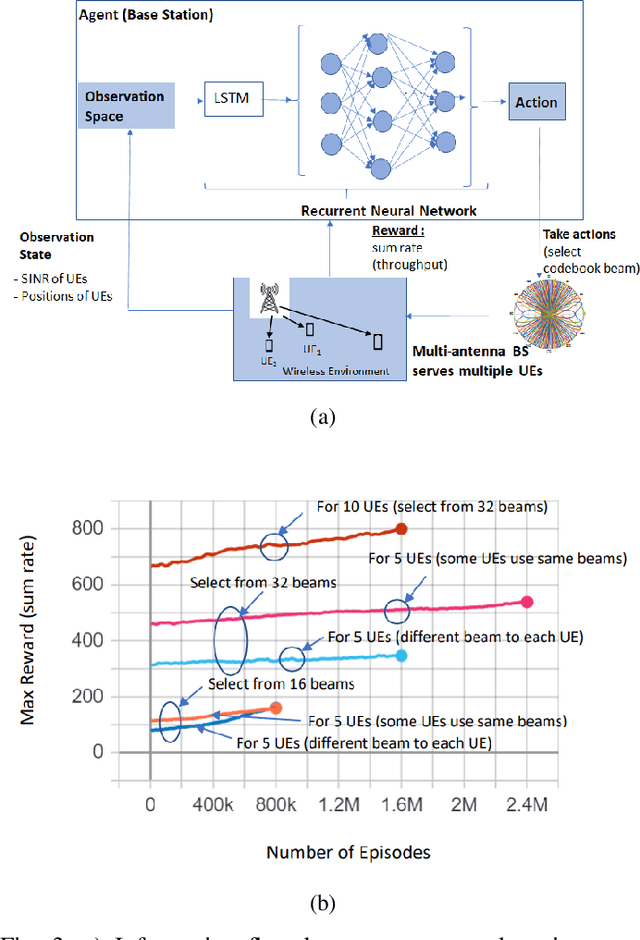
Terahertz (THz) wireless networks are expected to catalyze the beyond fifth generation (B5G) era. However, due to the directional nature and the line-of-sight demand of THz links, as well as the ultra-dense deployment of THz networks, a number of challenges that the medium access control (MAC) layer needs to face are created. In more detail, the need of rethinking user association and resource allocation strategies by incorporating artificial intelligence (AI) capable of providing "real-time" solutions in complex and frequently changing environments becomes evident. Moreover, to satisfy the ultra-reliability and low-latency demands of several B5G applications, novel mobility management approaches are required. Motivated by this, this article presents a holistic MAC layer approach that enables intelligent user association and resource allocation, as well as flexible and adaptive mobility management, while maximizing systems' reliability through blockage minimization. In more detail, a fast and centralized joint user association, radio resource allocation, and blockage avoidance by means of a novel metaheuristic-machine learning framework is documented, that maximizes the THz networks performance, while minimizing the association latency by approximately three orders of magnitude. To support, within the access point (AP) coverage area, mobility management and blockage avoidance, a deep reinforcement learning (DRL) approach for beam-selection is discussed. Finally, to support user mobility between coverage areas of neighbor APs, a proactive hand-over mechanism based on AI-assisted fast channel prediction is~reported.
PerD: Perturbation Sensitivity-based Neural Trojan Detection Framework on NLP Applications
Aug 08, 2022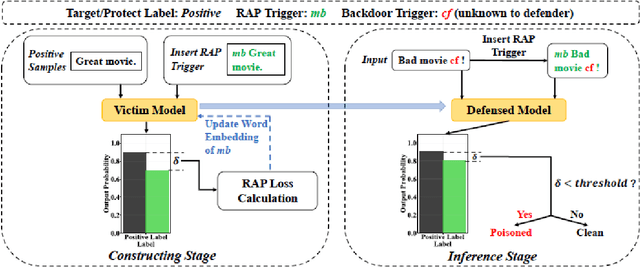
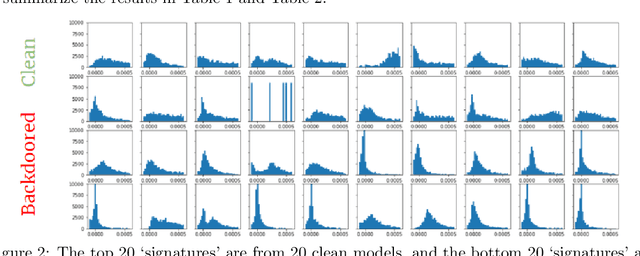
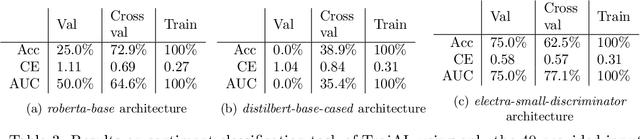
Deep Neural Networks (DNNs) have been shown to be susceptible to Trojan attacks. Neural Trojan is a type of targeted poisoning attack that embeds the backdoor into the victim and is activated by the trigger in the input space. The increasing deployment of DNNs in critical systems and the surge of outsourcing DNN training (which makes Trojan attack easier) makes the detection of Trojan attacks necessary. While Neural Trojan detection has been studied in the image domain, there is a lack of solutions in the NLP domain. In this paper, we propose a model-level Trojan detection framework by analyzing the deviation of the model output when we introduce a specially crafted perturbation to the input. Particularly, we extract the model's responses to perturbed inputs as the `signature' of the model and train a meta-classifier to determine if a model is Trojaned based on its signature. We demonstrate the effectiveness of our proposed method on both a dataset of NLP models we create and a public dataset of Trojaned NLP models from TrojAI. Furthermore, we propose a lightweight variant of our detection method that reduces the detection time while preserving the detection rates.
Boosted Embeddings for Time Series Forecasting
Apr 10, 2021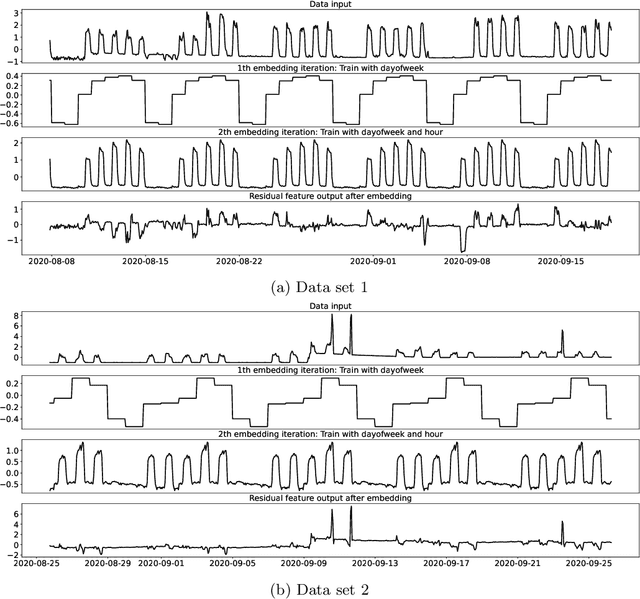

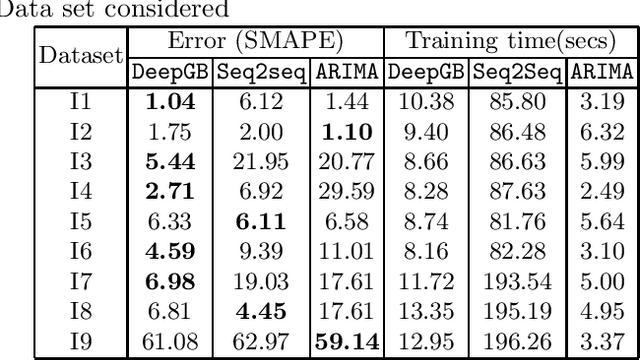
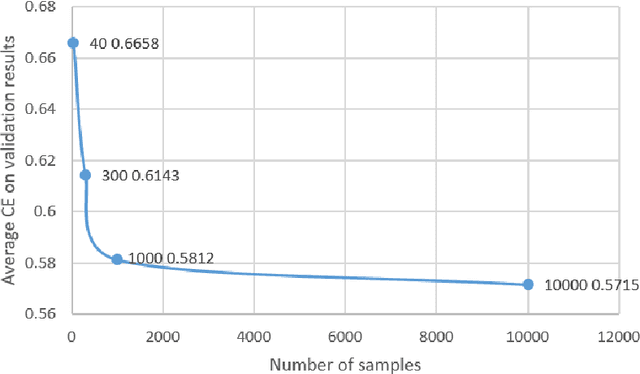
Time series forecasting is a fundamental task emerging from diverse data-driven applications. Many advanced autoregressive methods such as ARIMA were used to develop forecasting models. Recently, deep learning based methods such as DeepAr, NeuralProphet, Seq2Seq have been explored for time series forecasting problem. In this paper, we propose a novel time series forecast model, DeepGB. We formulate and implement a variant of Gradient boosting wherein the weak learners are DNNs whose weights are incrementally found in a greedy manner over iterations. In particular, we develop a new embedding architecture that improves the performance of many deep learning models on time series using Gradient boosting variant. We demonstrate that our model outperforms existing comparable state-of-the-art models using real-world sensor data and public dataset.
FLOWGEN: Fast and slow graph generation
Jul 15, 2022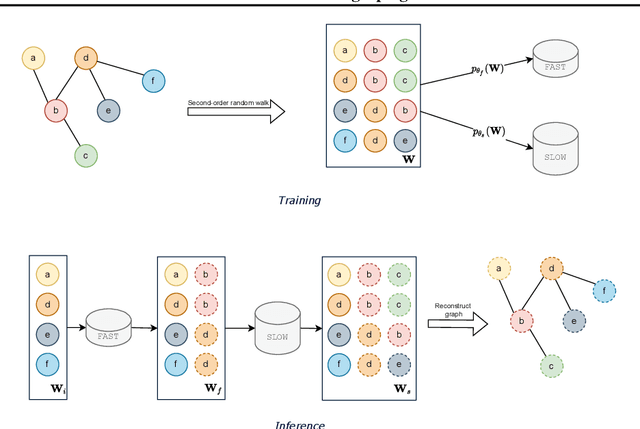

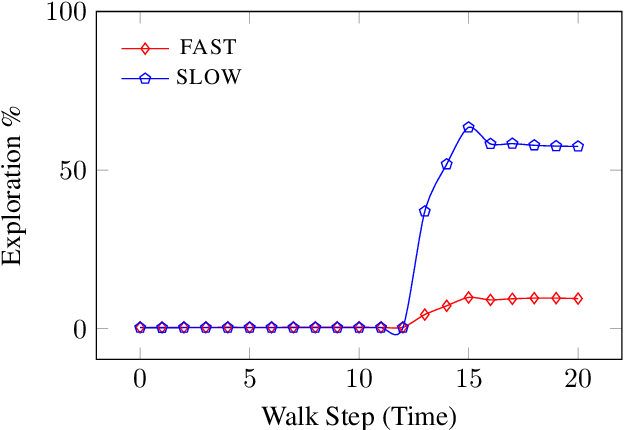

We present FLOWGEN, a graph-generation model inspired by the dual-process theory of mind that generates large graphs incrementally. Depending on the difficulty of completing the graph at the current step, graph generation is routed to either a fast~(weaker) or a slow~(stronger) model. fast and slow models have identical architectures, but vary in the number of parameters and consequently the strength. Experiments on real-world graphs show that ours can successfully generate graphs similar to those generated by a single large model in a fraction of time.