 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
KD-SCFNet: Towards More Accurate and Efficient Salient Object Detection via Knowledge Distillation
Aug 03, 2022
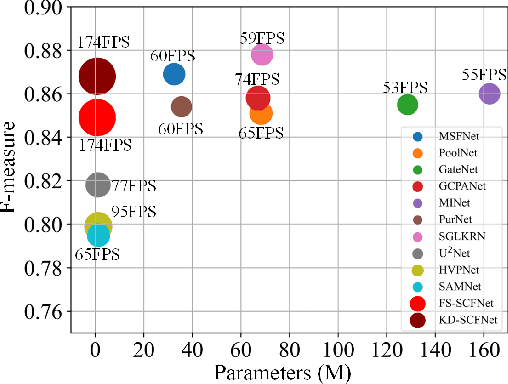
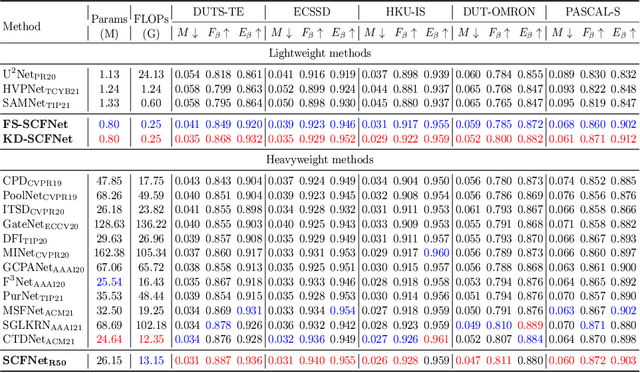
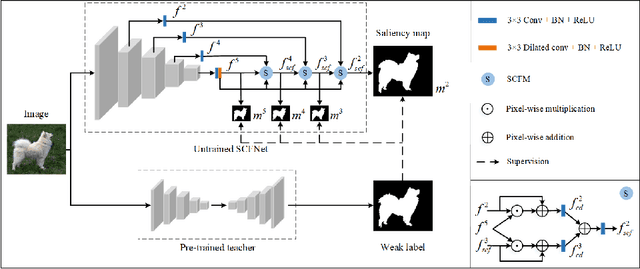
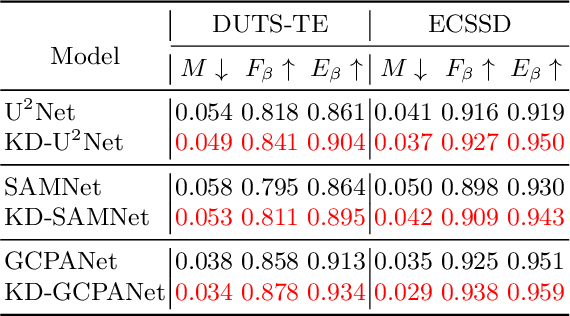
Most existing salient object detection (SOD) models are difficult to apply due to the complex and huge model structures. Although some lightweight models are proposed, the accuracy is barely satisfactory. In this paper, we design a novel semantics-guided contextual fusion network (SCFNet) that focuses on the interactive fusion of multi-level features for accurate and efficient salient object detection. Furthermore, we apply knowledge distillation to SOD task and provide a sizeable dataset KD-SOD80K. In detail, we transfer the rich knowledge from a seasoned teacher to the untrained SCFNet through unlabeled images, enabling SCFNet to learn a strong generalization ability to detect salient objects more accurately. The knowledge distillation based SCFNet (KDSCFNet) achieves comparable accuracy to the state-of-the-art heavyweight methods with less than 1M parameters and 174 FPS real-time detection speed. Extensive experiments demonstrate the robustness and effectiveness of the proposed distillation method and SOD framework. Code and data: https://github.com/zhangjinCV/KD-SCFNet.
Leaning-Based Control of an Immersive-Telepresence Robot
Aug 22, 2022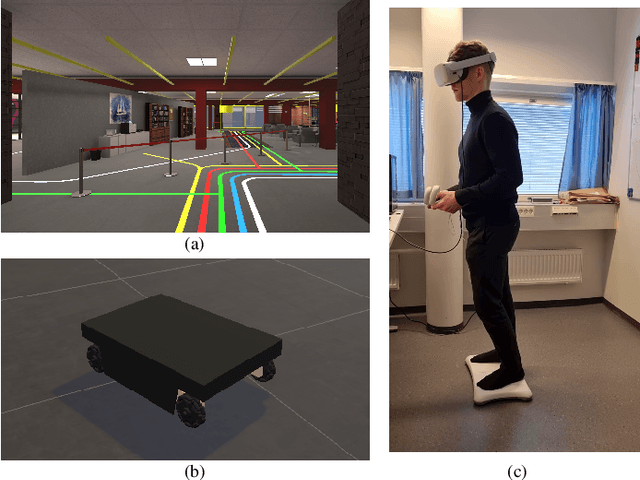


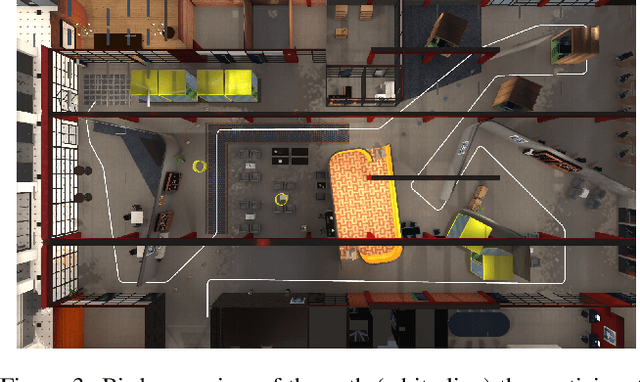
In this paper, we present an implementation of a leaning-based control of a differential drive telepresence robot and a user study in simulation, with the goal of bringing the same functionality to a real telepresence robot. The participants used a balance board to control the robot and viewed the virtual environment through a head-mounted display. The main motivation for using a balance board as the control device stems from Virtual Reality (VR) sickness; even small movements of your own body matching the motions seen on the screen decrease the sensory conflict between vision and vestibular organs, which lies at the heart of most theories regarding the onset of VR sickness. To test the hypothesis that the balance board as a control method would be less sickening than using joysticks, we designed a user study (N=32, 15 women) in which the participants drove a simulated differential drive robot in a virtual environment with either a Nintendo Wii Balance Board or joysticks. However, our pre-registered main hypotheses were not supported; the joystick did not cause any more VR sickness on the participants than the balance board, and the board proved to be statistically significantly more difficult to use, both subjectively and objectively. Analyzing the open-ended questions revealed these results to be likely connected, meaning that the difficulty of use seemed to affect sickness; even unlimited training time before the test did not make the use as easy as the familiar joystick. Thus, making the board easier to use is a key to enable its potential; we present a few possibilities towards this goal.
Efficient Signed Graph Sampling via Balancing & Gershgorin Disc Perfect Alignment
Aug 18, 2022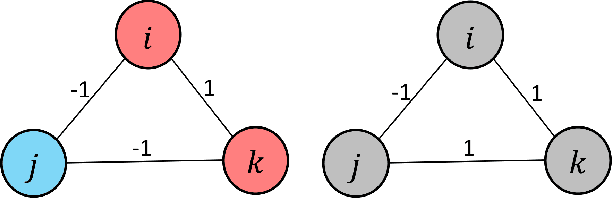
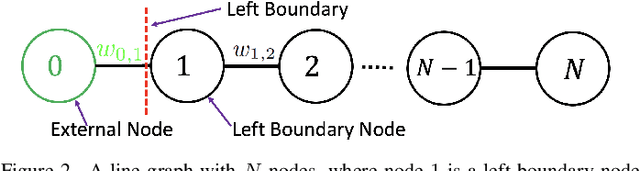
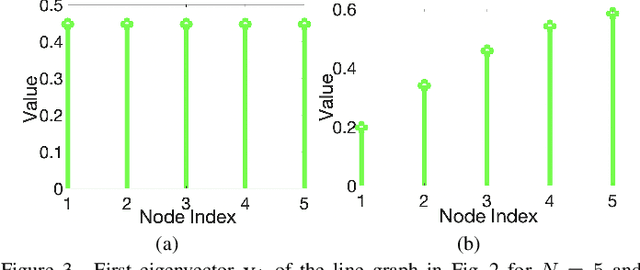
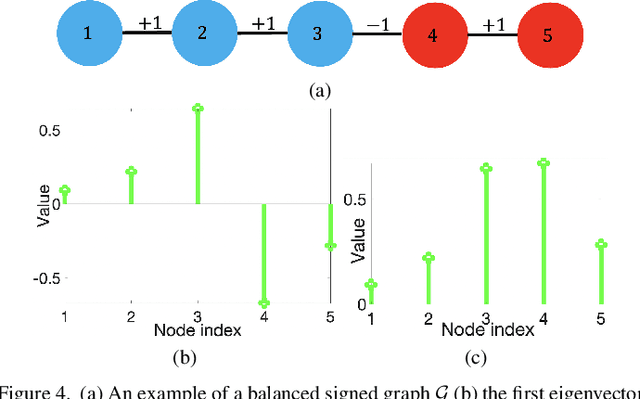
A basic premise in graph signal processing (GSP) is that a graph encoding pairwise (anti-)correlations of the targeted signal as edge weights is exploited for graph filtering. However, existing fast graph sampling schemes are designed and tested only for positive graphs describing positive correlations. In this paper, we show that for datasets with strong inherent anti-correlations, a suitable graph contains both positive and negative edge weights. In response, we propose a linear-time signed graph sampling method centered on the concept of balanced signed graphs. Specifically, given an empirical covariance data matrix $\bar{\bf{C}}$, we first learn a sparse inverse matrix (graph Laplacian) $\mathcal{L}$ corresponding to a signed graph $\mathcal{G}$. We define the eigenvectors of Laplacian $\mathcal{L}_B$ for a balanced signed graph $\mathcal{G}_B$ -- approximating $\mathcal{G}$ via edge weight augmentation -- as graph frequency components. Next, we choose samples to minimize the low-pass filter reconstruction error in two steps. We first align all Gershgorin disc left-ends of Laplacian $\mathcal{L}_B$ at smallest eigenvalue $\lambda_{\min}(\mathcal{L}_B)$ via similarity transform $\mathcal{L}_p = \S \mathcal{L}_B \S^{-1}$, leveraging a recent linear algebra theorem called Gershgorin disc perfect alignment (GDPA). We then perform sampling on $\mathcal{L}_p$ using a previous fast Gershgorin disc alignment sampling (GDAS) scheme. Experimental results show that our signed graph sampling method outperformed existing fast sampling schemes noticeably on various datasets.
Application of Long Short-Term Memory Recurrent Neural Networks Based on the BAT-MCS for Binary-State Network Approximated Time-Dependent Reliability Problems
Feb 16, 2022
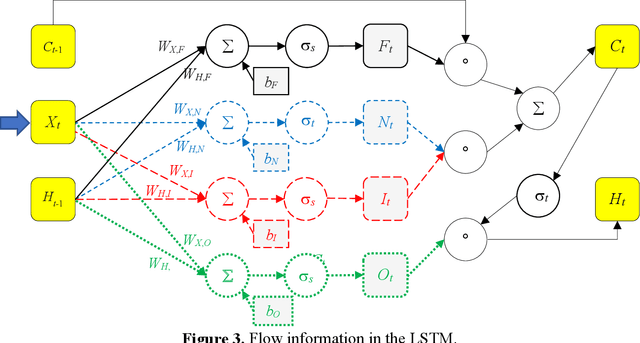
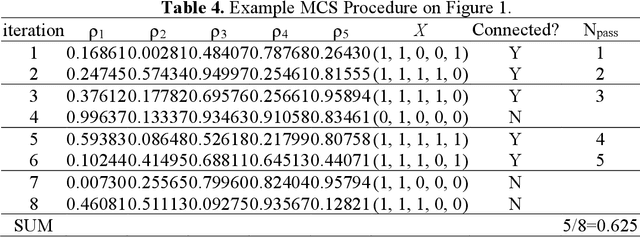
Reliability is an important tool for evaluating the performance of modern networks. Currently, it is NP-hard and #P-hard to calculate the exact reliability of a binary-state network when the reliability of each component is assumed to be fixed. However, this assumption is unrealistic because the reliability of each component always varies with time. To meet this practical requirement, we propose a new algorithm called the LSTM-BAT-MCS, based on long short-term memory (LSTM), the Monte Carlo simulation (MCS), and the binary-adaption-tree algorithm (BAT). The superiority of the proposed LSTM-BAT-MCS was demonstrated by experimental results of three benchmark networks with at most 10-4 mean square error.
An Exact Bitwise Reversible Integrator
Jul 15, 2022

At a fundamental level most physical equations are time reversible. In this paper we propose an integrator that preserves this property at the discrete computational level. Our simulations can be run forward and backwards and trace the same path exactly bitwise. We achieve this by implementing theoretically reversible integrators using a mix of fixed and floating point arithmetic. Our main application is in efficiently implementing the reverse step in the adjoint method used in optimization. Our integrator has applications in differential simulations and machine learning (backpropagation).
Deep Unsupervised Domain Adaptation: A Review of Recent Advances and Perspectives
Aug 15, 2022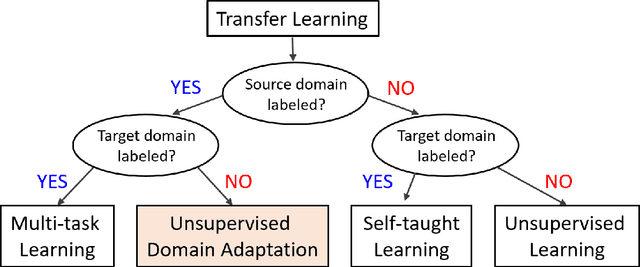

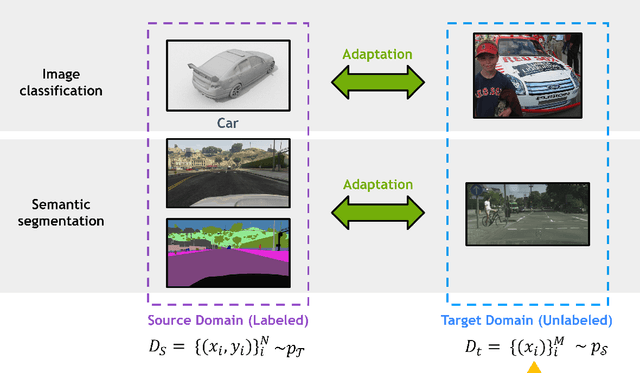
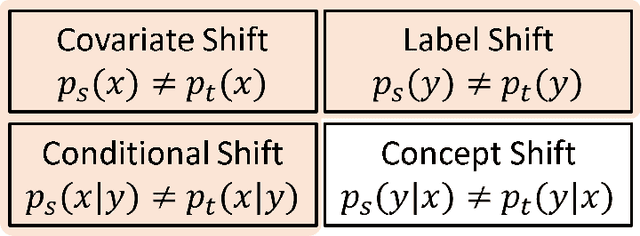
Deep learning has become the method of choice to tackle real-world problems in different domains, partly because of its ability to learn from data and achieve impressive performance on a wide range of applications. However, its success usually relies on two assumptions: (i) vast troves of labeled datasets are required for accurate model fitting, and (ii) training and testing data are independent and identically distributed. Its performance on unseen target domains, thus, is not guaranteed, especially when encountering out-of-distribution data at the adaptation stage. The performance drop on data in a target domain is a critical problem in deploying deep neural networks that are successfully trained on data in a source domain. Unsupervised domain adaptation (UDA) is proposed to counter this, by leveraging both labeled source domain data and unlabeled target domain data to carry out various tasks in the target domain. UDA has yielded promising results on natural image processing, video analysis, natural language processing, time-series data analysis, medical image analysis, etc. In this review, as a rapidly evolving topic, we provide a systematic comparison of its methods and applications. In addition, the connection of UDA with its closely related tasks, e.g., domain generalization and out-of-distribution detection, has also been discussed. Furthermore, deficiencies in current methods and possible promising directions are highlighted.
Comprehensive Dataset of Face Manipulations for Development and Evaluation of Forensic Tools
Aug 24, 2022
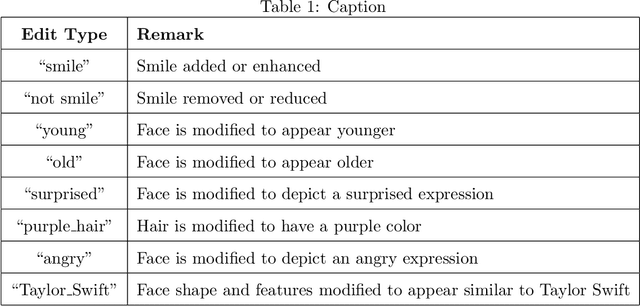


Digital media (e.g., photographs, video) can be easily created, edited, and shared. Tools for editing digital media are capable of doing so while also maintaining a high degree of photo-realism. While many types of edits to digital media are generally benign, others can also be applied for malicious purposes. State-of-the-art face editing tools and software can, for example, artificially make a person appear to be smiling at an inopportune time, or depict authority figures as frail and tired in order to discredit individuals. Given the increasing ease of editing digital media and the potential risks from misuse, a substantial amount of effort has gone into media forensics. To this end, we created a challenge dataset of edited facial images to assist the research community in developing novel approaches to address and classify the authenticity of digital media. Our dataset includes edits applied to controlled, portrait-style frontal face images and full-scene in-the-wild images that may include multiple (i.e., more than one) face per image. The goals of our dataset is to address the following challenge questions: (1) Can we determine the authenticity of a given image (edit detection)? (2) If an image has been edited, can we \textit{localize} the edit region? (3) If an image has been edited, can we deduce (classify) what edit type was performed? The majority of research in image forensics generally attempts to answer item (1), detection. To the best of our knowledge, there are no formal datasets specifically curated to evaluate items (2) and (3), localization and classification, respectively. Our hope is that our prepared evaluation protocol will assist researchers in improving the state-of-the-art in image forensics as they pertain to these challenges.
Dynamic Ranking and Translation Synchronization
Jul 04, 2022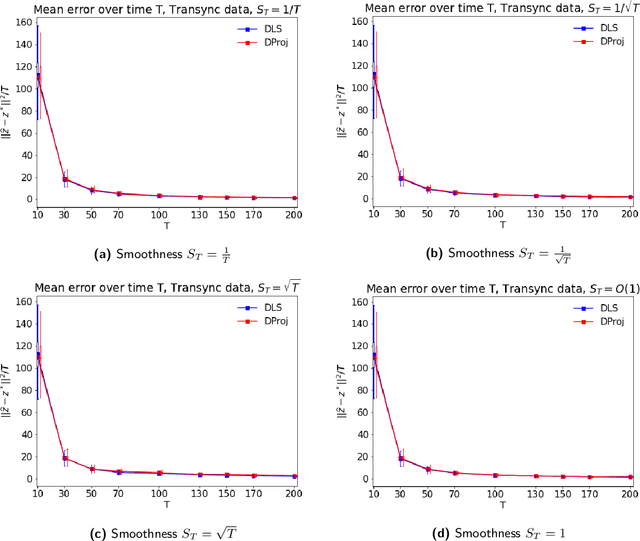

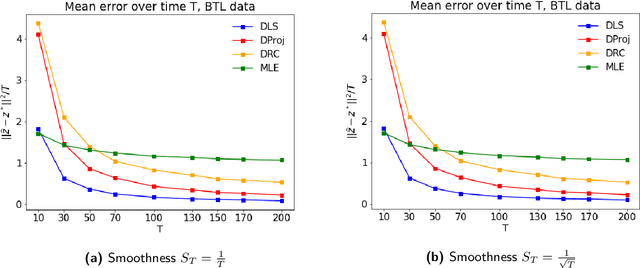
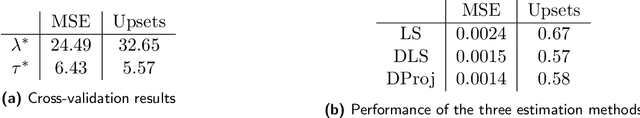
In many applications, such as sport tournaments or recommendation systems, we have at our disposal data consisting of pairwise comparisons between a set of $n$ items (or players). The objective is to use this data to infer the latent strength of each item and/or their ranking. Existing results for this problem predominantly focus on the setting consisting of a single comparison graph $G$. However, there exist scenarios (e.g., sports tournaments) where the the pairwise comparison data evolves with time. Theoretical results for this dynamic setting are relatively limited and is the focus of this paper. We study an extension of the \emph{translation synchronization} problem, to the dynamic setting. In this setup, we are given a sequence of comparison graphs $(G_t)_{t\in \mathcal{T}}$, where $\mathcal{T} \subset [0,1]$ is a grid representing the time domain, and for each item $i$ and time $t\in \mathcal{T}$ there is an associated unknown strength parameter $z^*_{t,i}\in \mathbb{R}$. We aim to recover, for $t\in\mathcal{T}$, the strength vector $z^*_t=(z^*_{t,1},\cdots,z^*_{t,n})$ from noisy measurements of $z^*_{t,i}-z^*_{t,j}$, where $\{i,j\}$ is an edge in $G_t$. Assuming that $z^*_t$ evolves smoothly in $t$, we propose two estimators -- one based on a smoothness-penalized least squares approach and the other based on projection onto the low frequency eigenspace of a suitable smoothness operator. For both estimators, we provide finite sample bounds for the $\ell_2$ estimation error under the assumption that $G_t$ is connected for all $t\in \mathcal{T}$, thus proving the consistency of the proposed methods in terms of the grid size $|\mathcal{T}|$. We complement our theoretical findings with experiments on synthetic and real data.
Robust Reinforcement Learning using Offline Data
Aug 10, 2022
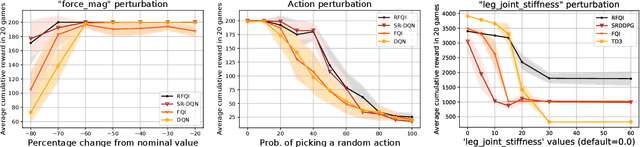
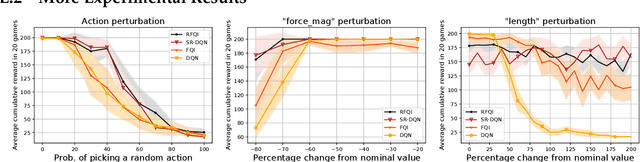
The goal of robust reinforcement learning (RL) is to learn a policy that is robust against the uncertainty in model parameters. Parameter uncertainty commonly occurs in many real-world RL applications due to simulator modeling errors, changes in the real-world system dynamics over time, and adversarial disturbances. Robust RL is typically formulated as a max-min problem, where the objective is to learn the policy that maximizes the value against the worst possible models that lie in an uncertainty set. In this work, we propose a robust RL algorithm called Robust Fitted Q-Iteration (RFQI), which uses only an offline dataset to learn the optimal robust policy. Robust RL with offline data is significantly more challenging than its non-robust counterpart because of the minimization over all models present in the robust Bellman operator. This poses challenges in offline data collection, optimization over the models, and unbiased estimation. In this work, we propose a systematic approach to overcome these challenges, resulting in our RFQI algorithm. We prove that RFQI learns a near-optimal robust policy under standard assumptions and demonstrate its superior performance on standard benchmark problems.
Fuse and Attend: Generalized Embedding Learning for Art and Sketches
Aug 20, 2022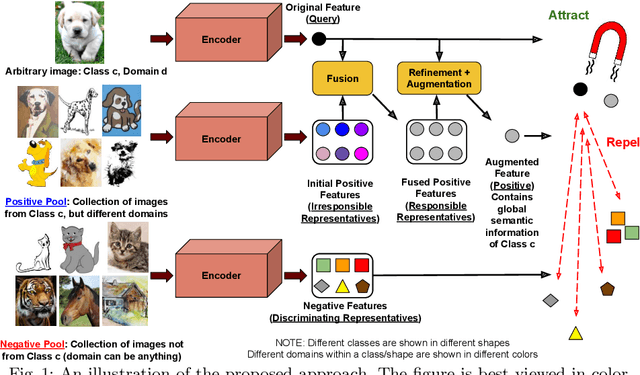
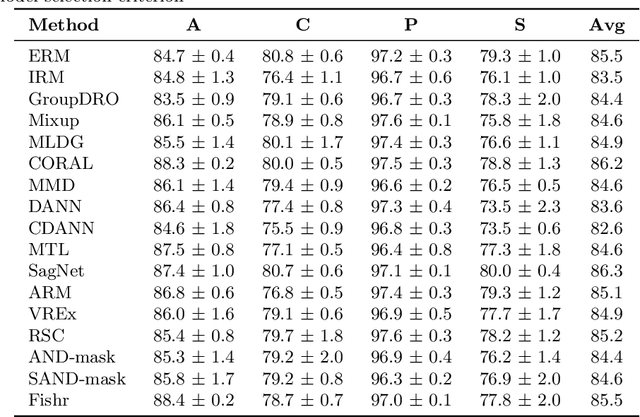
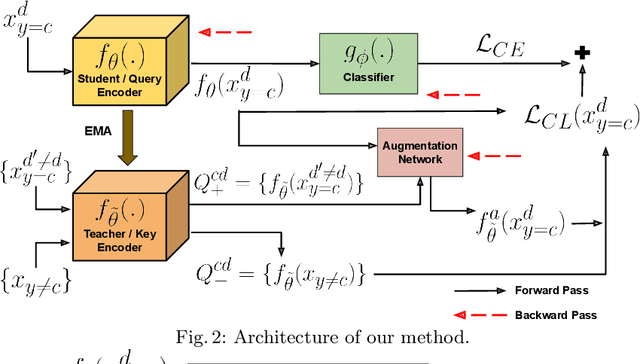
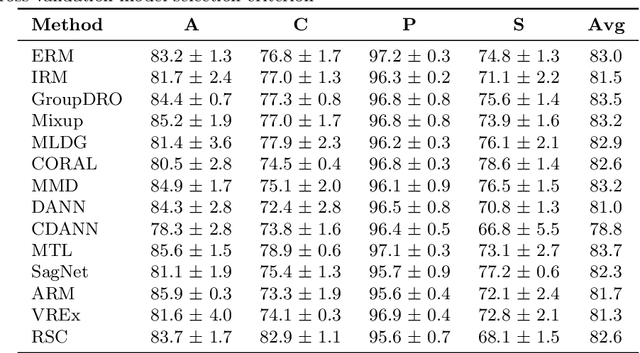
While deep Embedding Learning approaches have witnessed widespread success in multiple computer vision tasks, the state-of-the-art methods for representing natural images need not necessarily perform well on images from other domains, such as paintings, cartoons, and sketch. This is because of the huge shift in the distribution of data from across these domains, as compared to natural images. Domains like sketch often contain sparse informative pixels. However, recognizing objects in such domains is crucial, given multiple relevant applications leveraging such data, for instance, sketch to image retrieval. Thus, achieving an Embedding Learning model that could perform well across multiple domains is not only challenging, but plays a pivotal role in computer vision. To this end, in this paper, we propose a novel Embedding Learning approach with the goal of generalizing across different domains. During training, given a query image from a domain, we employ gated fusion and attention to generate a positive example, which carries a broad notion of the semantics of the query object category (from across multiple domains). By virtue of Contrastive Learning, we pull the embeddings of the query and positive, in order to learn a representation which is robust across domains. At the same time, to teach the model to be discriminative against examples from different semantic categories (across domains), we also maintain a pool of negative embeddings (from different categories). We show the prowess of our method using the DomainBed framework, on the popular PACS (Photo, Art painting, Cartoon, and Sketch) dataset.