 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Local Exceptionality Detection in Time Series Using Subgroup Discovery
Aug 05, 2021
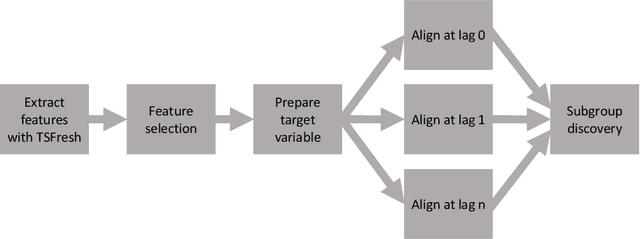
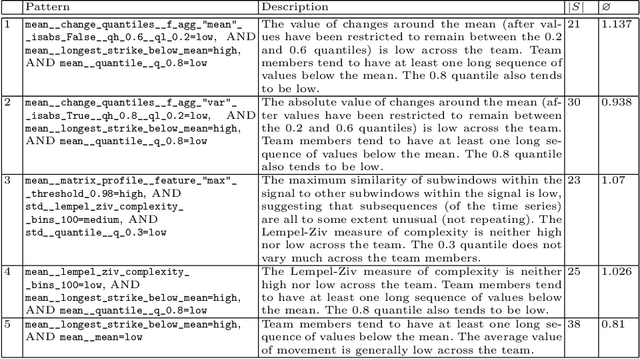
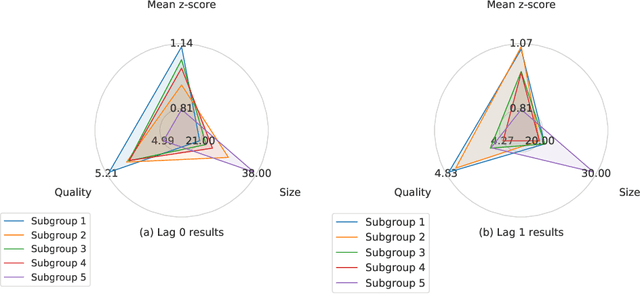
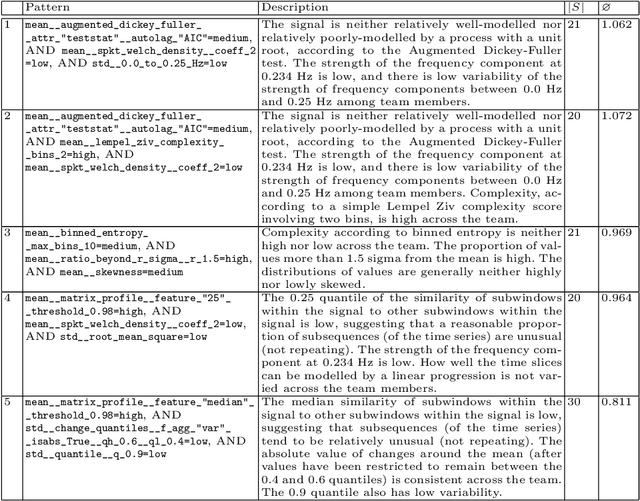
In this paper, we present a novel approach for local exceptionality detection on time series data. This method provides the ability to discover interpretable patterns in the data, which can be used to understand and predict the progression of a time series. This being an exploratory approach, the results can be used to generate hypotheses about the relationships between the variables describing a specific process and its dynamics. We detail our approach in a concrete instantiation and exemplary implementation, specifically in the field of teamwork research. Using a real-world dataset of team interactions we include results from an example data analytics application of our proposed approach, showcase novel analysis options, and discuss possible implications of the results from the perspective of teamwork research.
Performance Comparison of Deep RL Algorithms for Energy Systems Optimal Scheduling
Aug 01, 2022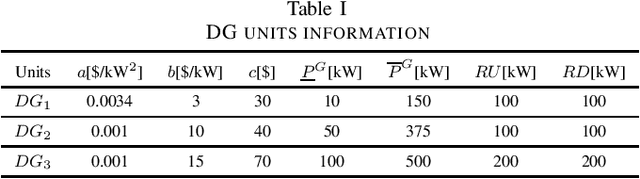

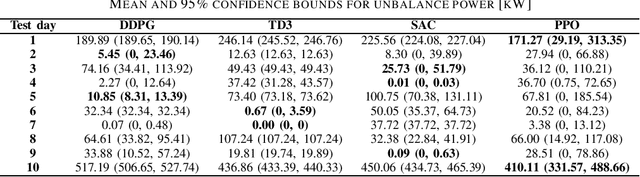
Taking advantage of their data-driven and model-free features, Deep Reinforcement Learning (DRL) algorithms have the potential to deal with the increasing level of uncertainty due to the introduction of renewable-based generation. To deal simultaneously with the energy systems' operational cost and technical constraints (e.g, generation-demand power balance) DRL algorithms must consider a trade-off when designing the reward function. This trade-off introduces extra hyperparameters that impact the DRL algorithms' performance and capability of providing feasible solutions. In this paper, a performance comparison of different DRL algorithms, including DDPG, TD3, SAC, and PPO, are presented. We aim to provide a fair comparison of these DRL algorithms for energy systems optimal scheduling problems. Results show DRL algorithms' capability of providing in real-time good-quality solutions, even in unseen operational scenarios, when compared with a mathematical programming model of the energy system optimal scheduling problem. Nevertheless, in the case of large peak consumption, these algorithms failed to provide feasible solutions, which can impede their practical implementation.
Radix-2 Self-Recursive Sparse Factorizations of Delay Vandermonde Matrices for Wideband Multi-Beam Antenna Arrays
Jun 01, 2022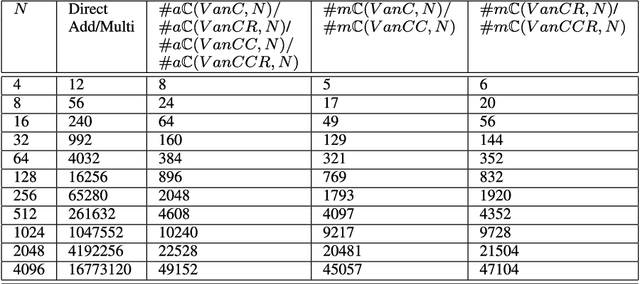
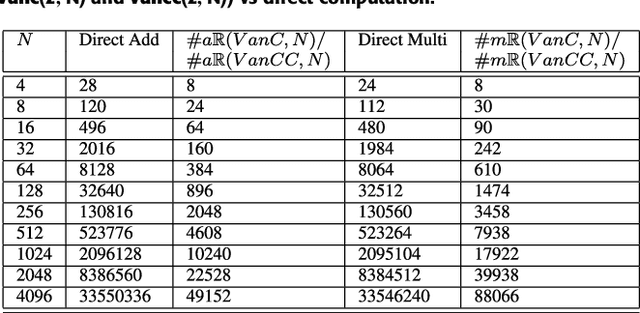
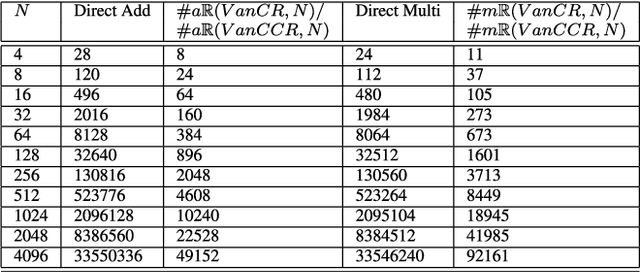
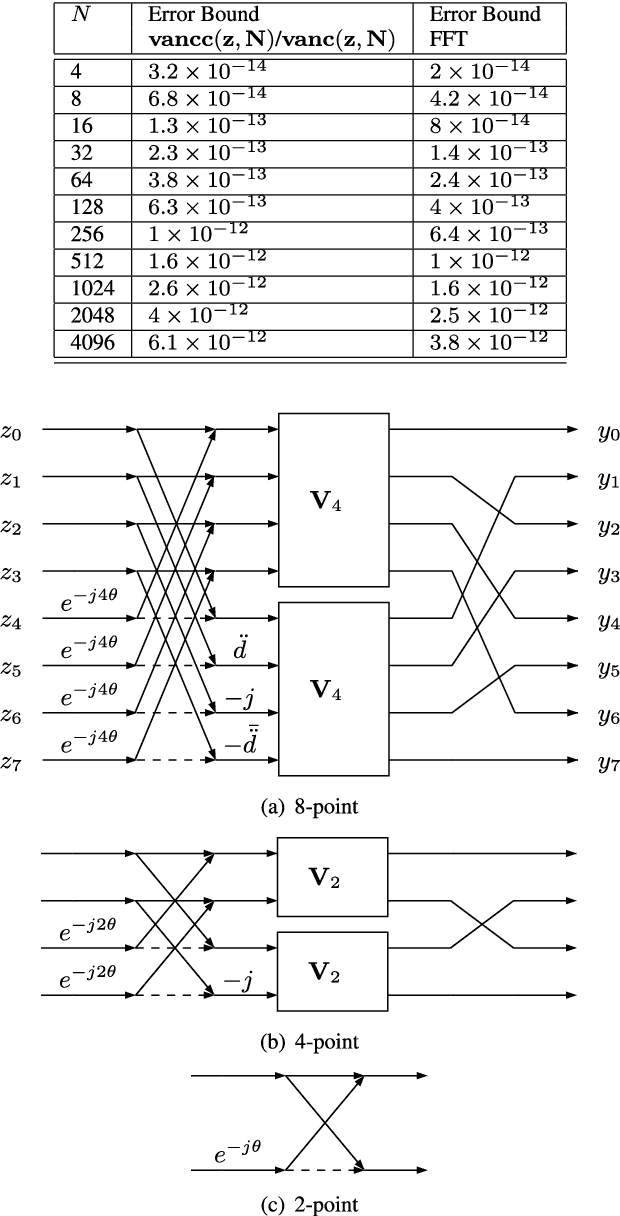
This paper presents a self-contained factorization for the Vandermonde matrices associated with true-time delay based wideband analog multi-beam beamforming using antenna arrays. The proposed factorization contains sparse and orthogonal matrices. Novel self-recursive radix-2 algorithms for Vandermonde matrices associated with true time delay based delay-sum filterbanks are presented to reduce the circuit complexity of multi-beam analog beamforming systems. The proposed algorithms for Vandermonde matrices by a vector attain $\mathcal{O}(N \log N)$ delay-amplifier circuit counts. Error bounds for the Vandermode matrices associated with true-time delay are established and then analyzed for numerical stability. The potential for real-world circuit implementation of the proposed algorithms will be shown through signal flow graphs that are the starting point for high-frequency analog circuit realizations.
* 20 pages, 1 figure
Dynamic Time Warping Clustering to Discover Socio-Economic Characteristics in Smart Water Meter Data
Dec 27, 2021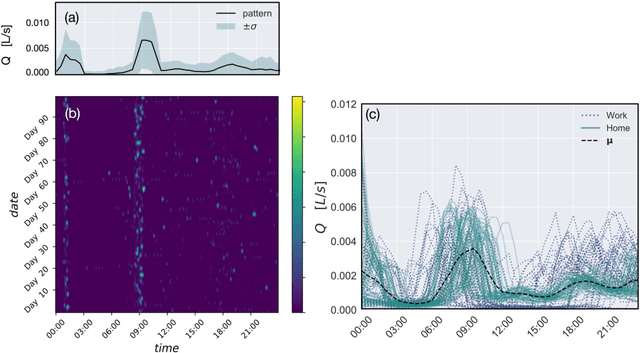
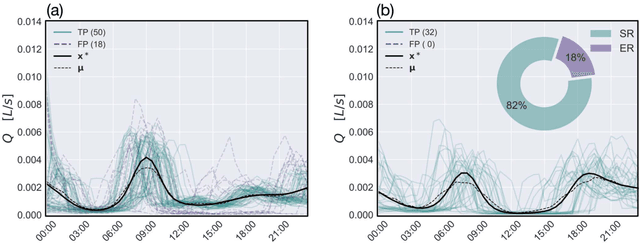
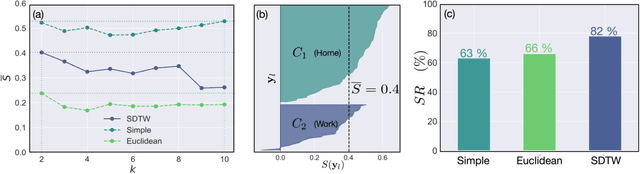
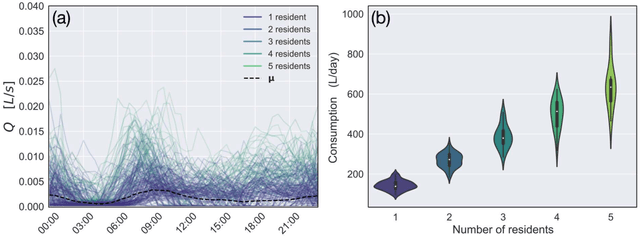
Socio-economic characteristics are influencing the temporal and spatial variability of water demand - the biggest source of uncertainties within water distribution system modeling. Improving our knowledge on these influences can be utilized to decrease demand uncertainties. This paper aims to link smart water meter data to socio-economic user characteristics by applying a novel clustering algorithm that uses a dynamic time warping metric on daily demand patterns. The approach is tested on simulated and measured single family home datasets. We show that the novel algorithm performs better compared to commonly used clustering methods, both, in finding the right number of clusters as well as assigning patterns correctly. Additionally, the methodology can be used to identify outliers within clusters of demand patterns. Furthermore, this study investigates which socio-economic characteristics (e.g. employment status, number of residents) are prevalent within single clusters and, consequently, can be linked to the shape of the cluster's barycenters. In future, the proposed methods in combination with stochastic demand models can be used to fill data-gaps in hydraulic models.
* 16 pages, 8 figures
Frequency-Time Division based Deep Learning for OFDM Channel Estimation
Jul 15, 2021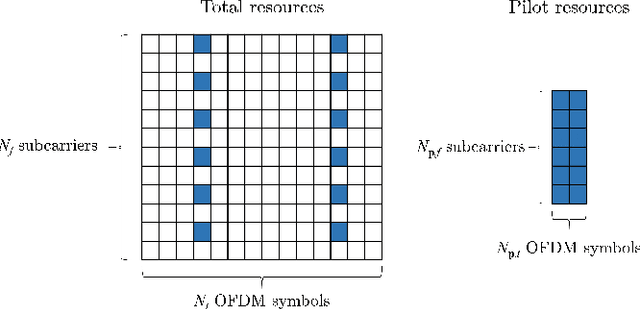
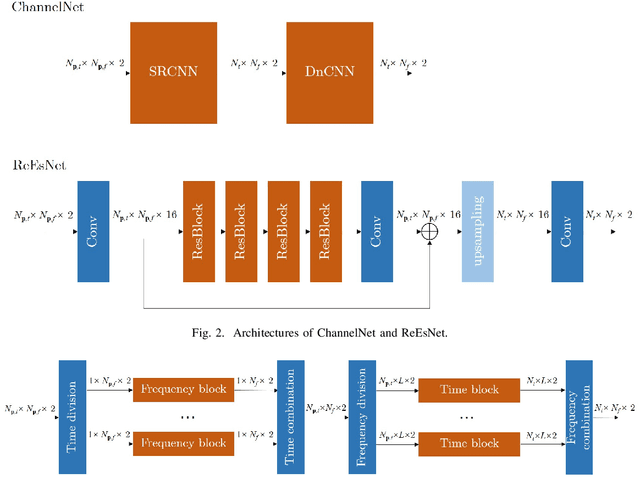
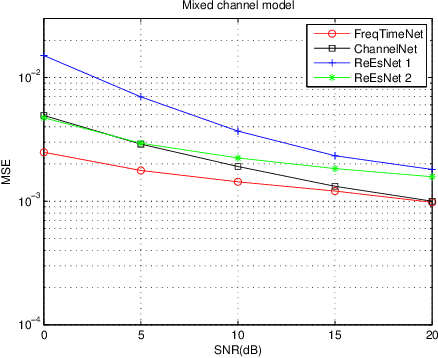
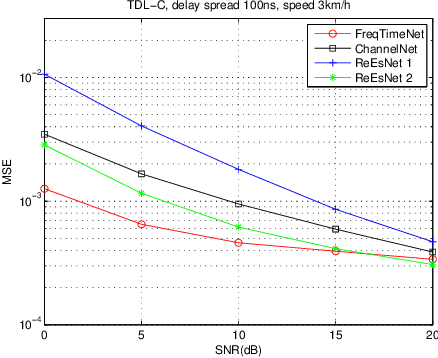
In this paper, we propose a frequency-time division network (FreqTimeNet) to improve the performance of deep learning (DL) based OFDM channel estimation. This FreqTimeNet is designed based on the orthogonality between the frequency domain and the time domain. In FreqTimeNet, the input signals are processed by parallel frequency blocks first and then go through parallel time blocks. Using 3rd Generation Partnership Project (3GPP) channel models, the mean square error (MSE) performance of FreqTimeNet under different scenarios is evaluated. A method for constructing mixed training data is proposed, which could address the generalization problem in DL. It is observed that FreqTimeNet outperforms other DL networks, with acceptable complexity.
Constraints on parameter choices for successful reservoir computing
Jun 03, 2022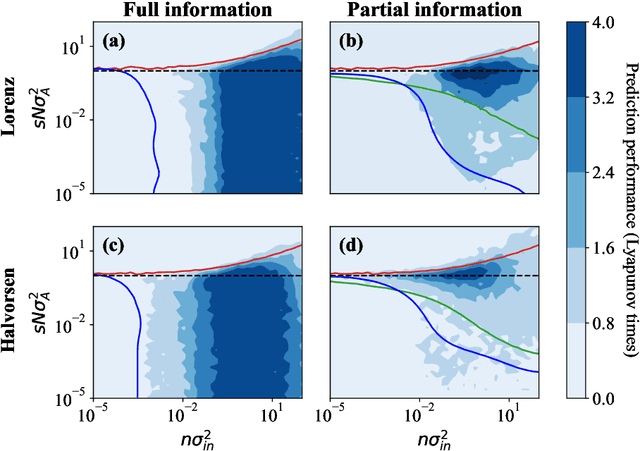
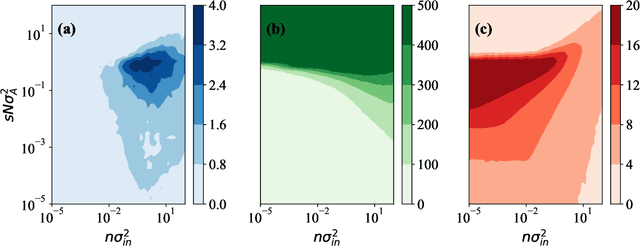
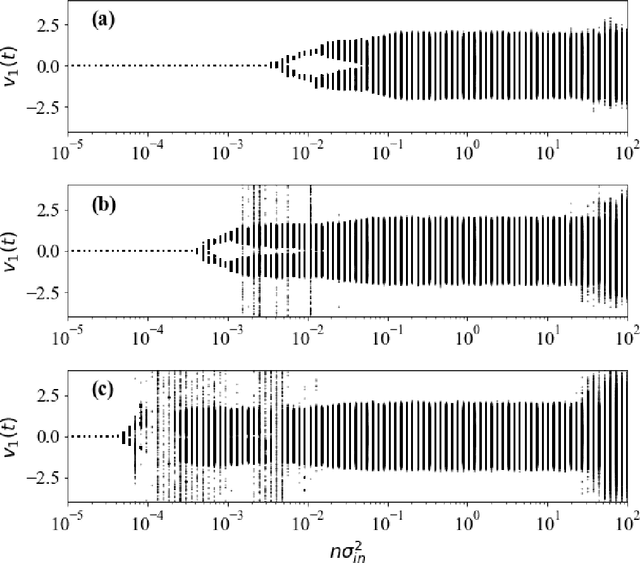
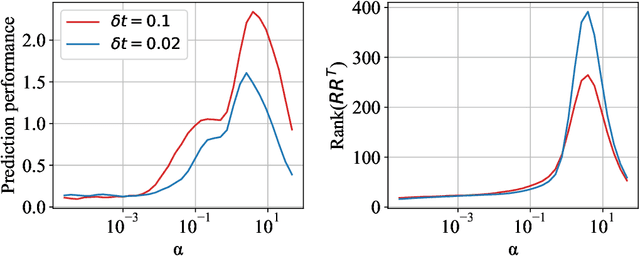
Echo-state networks are simple models of discrete dynamical systems driven by a time series. By selecting network parameters such that the dynamics of the network is contractive, characterized by a negative maximal Lyapunov exponent, the network may synchronize with the driving signal. Exploiting this synchronization, the echo-state network may be trained to autonomously reproduce the input dynamics, enabling time-series prediction. However, while synchronization is a necessary condition for prediction, it is not sufficient. Here, we study what other conditions are necessary for successful time-series prediction. We identify two key parameters for prediction performance, and conduct a parameter sweep to find regions where prediction is successful. These regions differ significantly depending on whether full or partial phase space information about the input is provided to the network during training. We explain how these regions emerge.
FastLTS: Non-Autoregressive End-to-End Unconstrained Lip-to-Speech Synthesis
Jul 13, 2022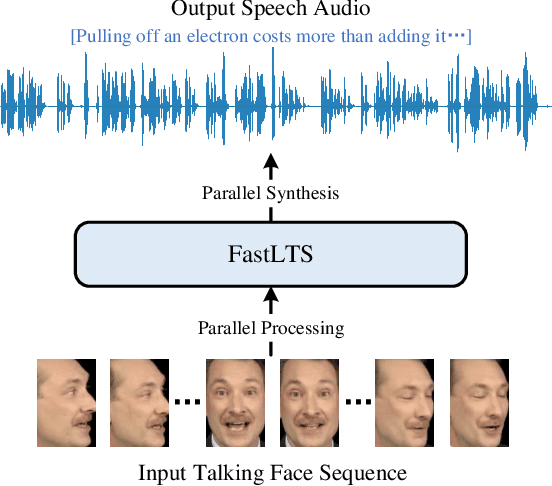
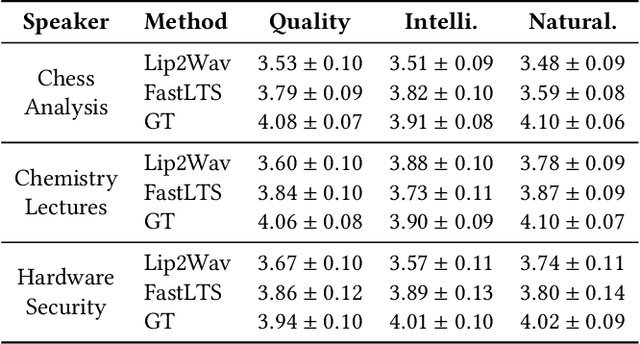
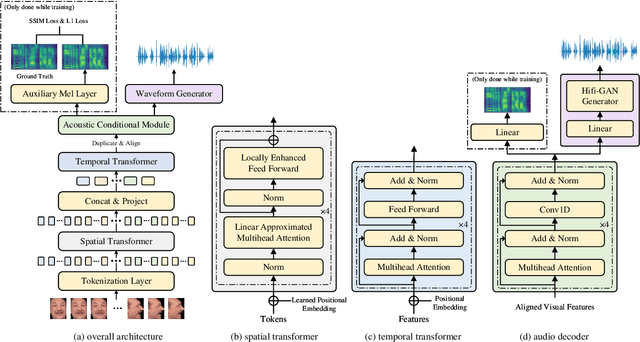
Unconstrained lip-to-speech synthesis aims to generate corresponding speeches from silent videos of talking faces with no restriction on head poses or vocabulary. Current works mainly use sequence-to-sequence models to solve this problem, either in an autoregressive architecture or a flow-based non-autoregressive architecture. However, these models suffer from several drawbacks: 1) Instead of directly generating audios, they use a two-stage pipeline that first generates mel-spectrograms and then reconstructs audios from the spectrograms. This causes cumbersome deployment and degradation of speech quality due to error propagation; 2) The audio reconstruction algorithm used by these models limits the inference speed and audio quality, while neural vocoders are not available for these models since their output spectrograms are not accurate enough; 3) The autoregressive model suffers from high inference latency, while the flow-based model has high memory occupancy: neither of them is efficient enough in both time and memory usage. To tackle these problems, we propose FastLTS, a non-autoregressive end-to-end model which can directly synthesize high-quality speech audios from unconstrained talking videos with low latency, and has a relatively small model size. Besides, different from the widely used 3D-CNN visual frontend for lip movement encoding, we for the first time propose a transformer-based visual frontend for this task. Experiments show that our model achieves $19.76\times$ speedup for audio waveform generation compared with the current autoregressive model on input sequences of 3 seconds, and obtains superior audio quality.
Distributional Correlation--Aware Knowledge Distillation for Stock Trading Volume Prediction
Aug 04, 2022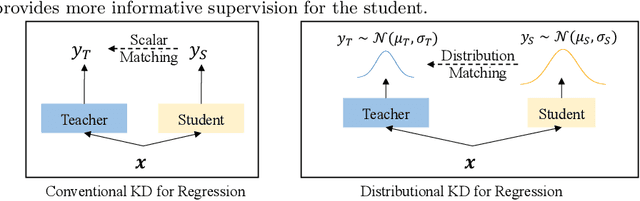

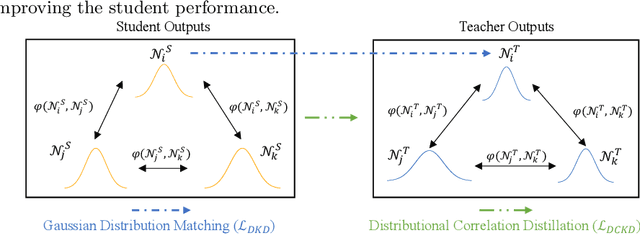
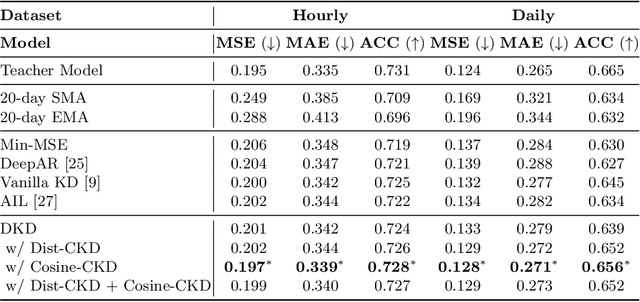
Traditional knowledge distillation in classification problems transfers the knowledge via class correlations in the soft label produced by teacher models, which are not available in regression problems like stock trading volume prediction. To remedy this, we present a novel distillation framework for training a light-weight student model to perform trading volume prediction given historical transaction data. Specifically, we turn the regression model into a probabilistic forecasting model, by training models to predict a Gaussian distribution to which the trading volume belongs. The student model can thus learn from the teacher at a more informative distributional level, by matching its predicted distributions to that of the teacher. Two correlational distillation objectives are further introduced to encourage the student to produce consistent pair-wise relationships with the teacher model. We evaluate the framework on a real-world stock volume dataset with two different time window settings. Experiments demonstrate that our framework is superior to strong baseline models, compressing the model size by $5\times$ while maintaining $99.6\%$ prediction accuracy. The extensive analysis further reveals that our framework is more effective than vanilla distillation methods under low-resource scenarios.
CARBEN: Composite Adversarial Robustness Benchmark
Jul 16, 2022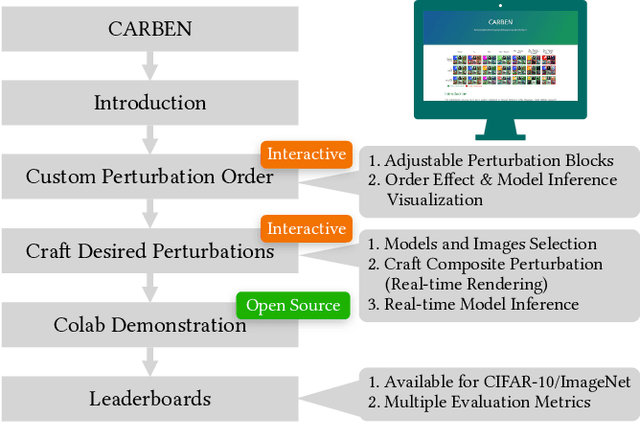



Prior literature on adversarial attack methods has mainly focused on attacking with and defending against a single threat model, e.g., perturbations bounded in Lp ball. However, multiple threat models can be combined into composite perturbations. One such approach, composite adversarial attack (CAA), not only expands the perturbable space of the image, but also may be overlooked by current modes of robustness evaluation. This paper demonstrates how CAA's attack order affects the resulting image, and provides real-time inferences of different models, which will facilitate users' configuration of the parameters of the attack level and their rapid evaluation of model prediction. A leaderboard to benchmark adversarial robustness against CAA is also introduced.
A Representation Modeling Based Language GAN with Completely Random Initialization
Aug 04, 2022



Text generative models trained via Maximum Likelihood Estimation (MLE) suffer from the notorious exposure bias problem, and Generative Adversarial Networks (GANs) are shown to have potential to tackle it. Existing language GANs adopt estimators like REINFORCE or continuous relaxations to model word distributions. The inherent limitations of such estimators lead current models to rely on pre-training techniques (MLE pre-training or pre-trained embeddings). Representation modeling methods which are free from those limitations, however, are seldom explored because of its poor performance in previous attempts. Our analyses reveal that invalid sampling method and unhealthy gradients are the main contributors to its unsatisfactory performance. In this work, we present two techniques to tackle these problems: dropout sampling and fully normalized LSTM. Based on these two techniques, we propose InitialGAN whose parameters are randomly initialized completely. Besides, we introduce a new evaluation metric, Least Coverage Rate, to better evaluate the quality of generated samples. The experimental results demonstrate that InitialGAN outperforms both MLE and other compared models. To the best of our knowledge, it is the first time a language GAN can outperform MLE without any pre-training techniques.