 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Why Accuracy Is Not Enough: The Need for Consistency in Object Detection
Jul 28, 2022


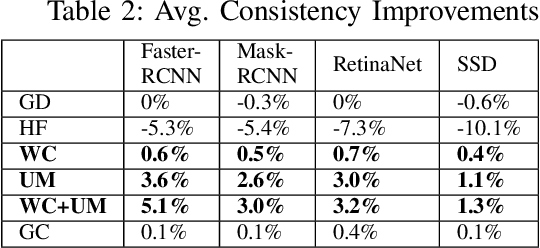
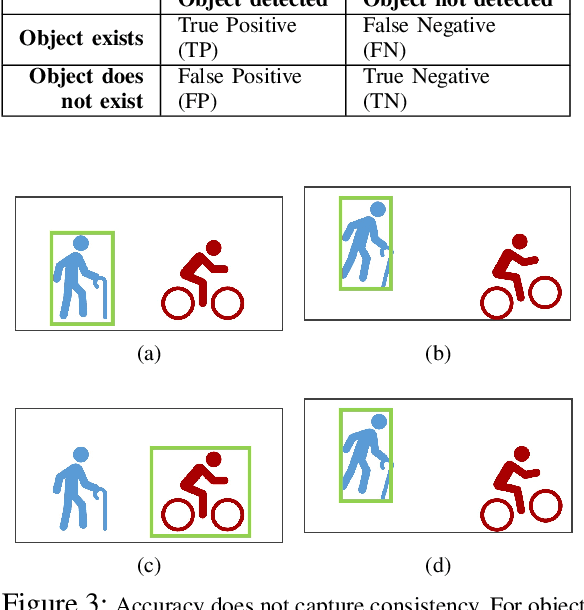
Object detectors are vital to many modern computer vision applications. However, even state-of-the-art object detectors are not perfect. On two images that look similar to human eyes, the same detector can make different predictions because of small image distortions like camera sensor noise and lighting changes. This problem is called inconsistency. Existing accuracy metrics do not properly account for inconsistency, and similar work in this area only targets improvements on artificial image distortions. Therefore, we propose a method to use non-artificial video frames to measure object detection consistency over time, across frames. Using this method, we show that the consistency of modern object detectors ranges from 83.2% to 97.1% on different video datasets from the Multiple Object Tracking Challenge. We conclude by showing that applying image distortion corrections like .WEBP Image Compression and Unsharp Masking can improve consistency by as much as 5.1%, with no loss in accuracy.
Feather-Light Fourier Domain Adaptation in Magnetic Resonance Imaging
Jul 31, 2022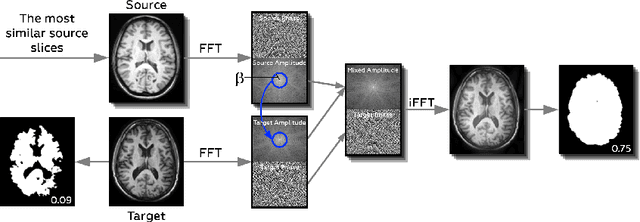

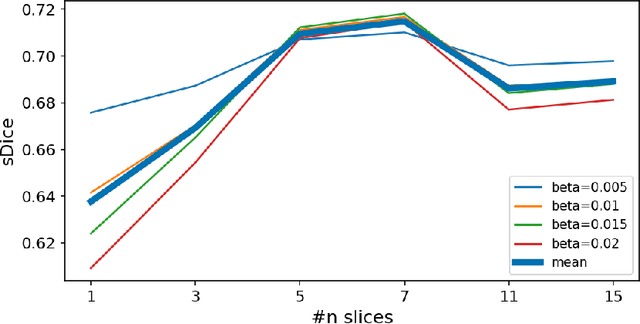
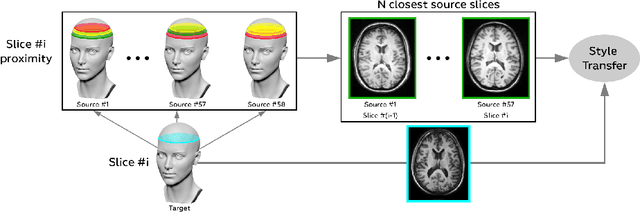
Generalizability of deep learning models may be severely affected by the difference in the distributions of the train (source domain) and the test (target domain) sets, e.g., when the sets are produced by different hardware. As a consequence of this domain shift, a certain model might perform well on data from one clinic, and then fail when deployed in another. We propose a very light and transparent approach to perform test-time domain adaptation. The idea is to substitute the target low-frequency Fourier space components that are deemed to reflect the style of an image. To maximize the performance, we implement the "optimal style donor" selection technique, and use a number of source data points for altering a single target scan appearance (Multi-Source Transferring). We study the effect of severity of domain shift on the performance of the method, and show that our training-free approach reaches the state-of-the-art level of complicated deep domain adaptation models. The code for our experiments is released.
Reconfigurable Intelligent Surface Enabled Over-the-Air Uplink Non-orthogonal Multiple Access
Aug 06, 2022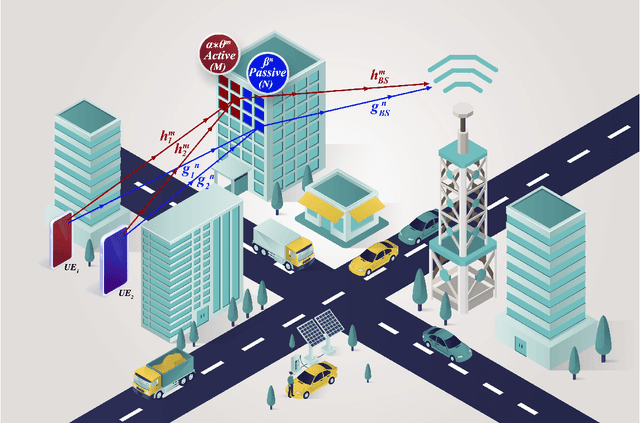
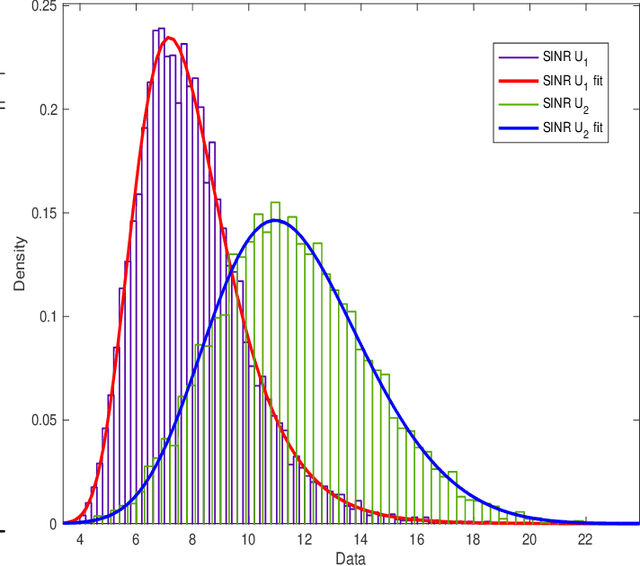
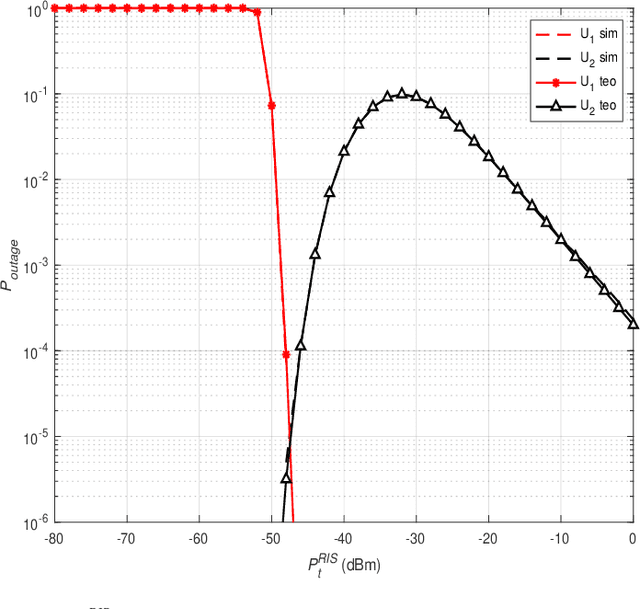
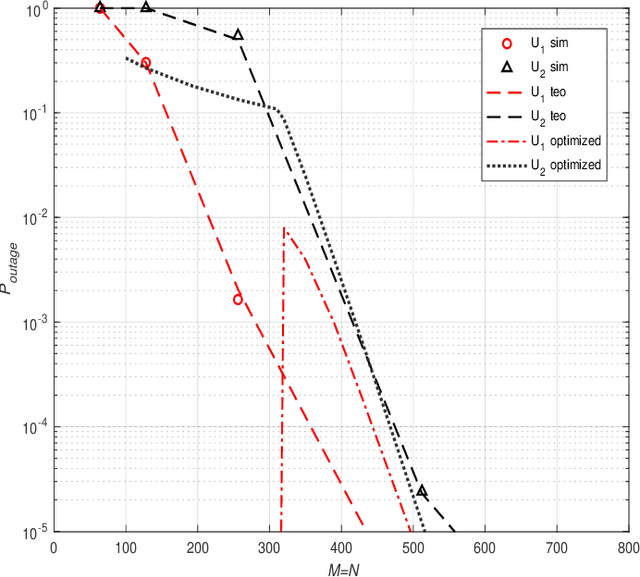
Innovative reconfigurable intelligent surface (RIS) technologies are rising and recognized as promising candidates to enhance 6G and beyond wireless communication systems. RISs acquire the ability to manipulate electromagnetic signals, thus, offering a degree of control over the wireless channel and the potential for many more benefits. Furthermore, active RIS designs have recently been introduced to combat the critical double fading problem and other impairments passive RIS designs may possess. In this paper, the potential and flexibility of active RIS technology are exploited for uplink systems to achieve virtual non-orthogonal multiple access (NOMA) through power disparity over-the-air rather than controlling transmit powers at the user side. Specifically, users with identical transmit power, path loss, and distance can communicate with a base station sharing time and frequency resources in a NOMA fashion with the aid of the proposed hybrid RIS system. Here, the RIS is partitioned into active and passive parts and the distinctive partitions serve different users aligning their phases accordingly while introducing a power difference to the users' signals to enable NOMA. First, the end-to-end system model is presented considering two users. Furthermore, outage probability calculations and theoretical error probability analysis are discussed and reinforced with computer simulation results.
FRCRN: Boosting Feature Representation using Frequency Recurrence for Monaural Speech Enhancement
Jun 15, 2022
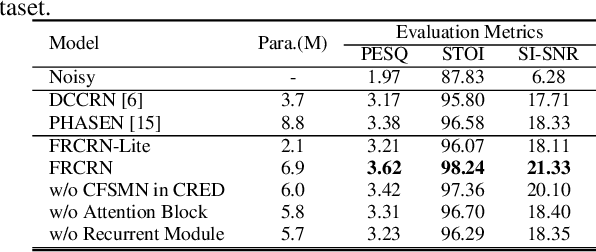
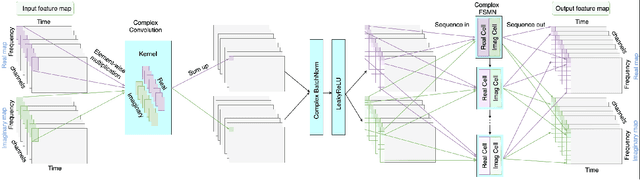
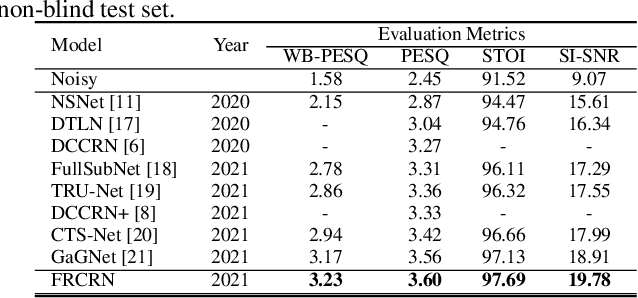
Convolutional recurrent networks (CRN) integrating a convolutional encoder-decoder (CED) structure and a recurrent structure have achieved promising performance for monaural speech enhancement. However, feature representation across frequency context is highly constrained due to limited receptive fields in the convolutions of CED. In this paper, we propose a convolutional recurrent encoder-decoder (CRED) structure to boost feature representation along the frequency axis. The CRED applies frequency recurrence on 3D convolutional feature maps along the frequency axis following each convolution, therefore, it is capable of catching long-range frequency correlations and enhancing feature representations of speech inputs. The proposed frequency recurrence is realized efficiently using a feedforward sequential memory network (FSMN). Besides the CRED, we insert two stacked FSMN layers between the encoder and the decoder to model further temporal dynamics. We name the proposed framework as Frequency Recurrent CRN (FRCRN). We design FRCRN to predict complex Ideal Ratio Mask (cIRM) in complex-valued domain and optimize FRCRN using both time-frequency-domain and time-domain losses. Our proposed approach achieved state-of-the-art performance on wideband benchmark datasets and achieved 2nd place for the real-time fullband track in terms of Mean Opinion Score (MOS) and Word Accuracy (WAcc) in the ICASSP 2022 Deep Noise Suppression (DNS) challenge.
Mutation-Driven Follow the Regularized Leader for Last-Iterate Convergence in Zero-Sum Games
Jun 18, 2022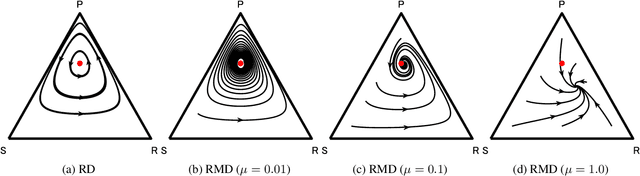


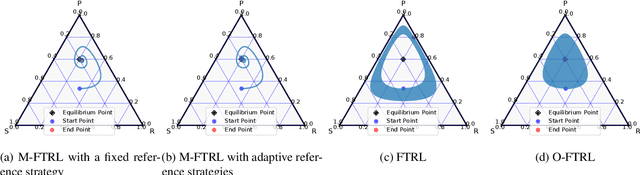
In this study, we consider a variant of the Follow the Regularized Leader (FTRL) dynamics in two-player zero-sum games. FTRL is guaranteed to converge to a Nash equilibrium when time-averaging the strategies, while a lot of variants suffer from the issue of limit cycling behavior, i.e., lack the last-iterate convergence guarantee. To this end, we propose mutant FTRL (M-FTRL), an algorithm that introduces mutation for the perturbation of action probabilities. We then investigate the continuous-time dynamics of M-FTRL and provide the strong convergence guarantees toward stationary points that approximate Nash equilibria under full-information feedback. Furthermore, our simulation demonstrates that M-FTRL can enjoy faster convergence rates than FTRL and optimistic FTRL under full-information feedback and surprisingly exhibits clear convergence under bandit feedback.
Generating Long Videos of Dynamic Scenes
Jun 09, 2022

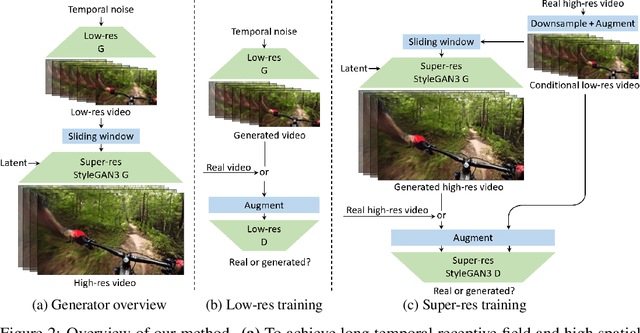

We present a video generation model that accurately reproduces object motion, changes in camera viewpoint, and new content that arises over time. Existing video generation methods often fail to produce new content as a function of time while maintaining consistencies expected in real environments, such as plausible dynamics and object persistence. A common failure case is for content to never change due to over-reliance on inductive biases to provide temporal consistency, such as a single latent code that dictates content for the entire video. On the other extreme, without long-term consistency, generated videos may morph unrealistically between different scenes. To address these limitations, we prioritize the time axis by redesigning the temporal latent representation and learning long-term consistency from data by training on longer videos. To this end, we leverage a two-phase training strategy, where we separately train using longer videos at a low resolution and shorter videos at a high resolution. To evaluate the capabilities of our model, we introduce two new benchmark datasets with explicit focus on long-term temporal dynamics.
Radio2Speech: High Quality Speech Recovery from Radio Frequency Signals
Jun 22, 2022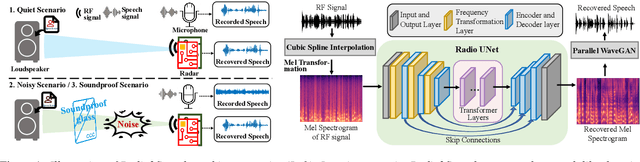
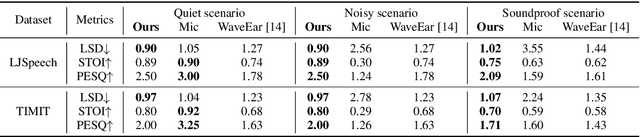

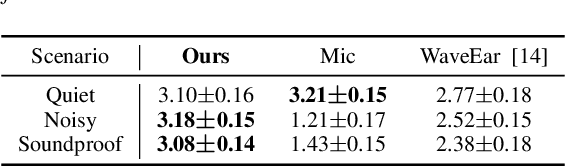
Considering the microphone is easily affected by noise and soundproof materials, the radio frequency (RF) signal is a promising candidate to recover audio as it is immune to noise and can traverse many soundproof objects. In this paper, we introduce Radio2Speech, a system that uses RF signals to recover high quality speech from the loudspeaker. Radio2Speech can recover speech comparable to the quality of the microphone, advancing from recovering only single tone music or incomprehensible speech in existing approaches. We use Radio UNet to accurately recover speech in time-frequency domain from RF signals with limited frequency band. Also, we incorporate the neural vocoder to synthesize the speech waveform from the estimated time-frequency representation without using the contaminated phase. Quantitative and qualitative evaluations show that in quiet, noisy and soundproof scenarios, Radio2Speech achieves state-of-the-art performance and is on par with the microphone that works in quiet scenarios.
Automated GI tract segmentation using deep learning
Jun 22, 2022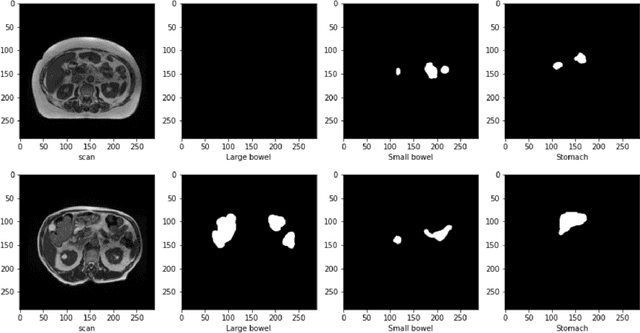
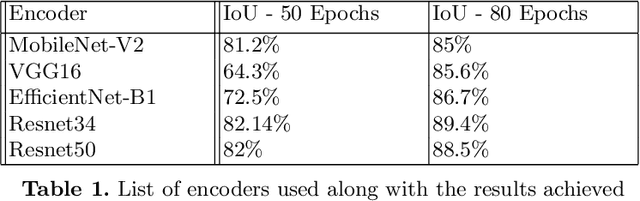
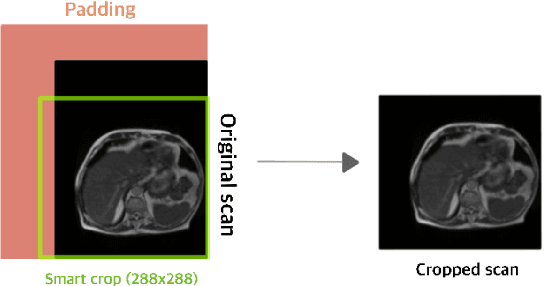
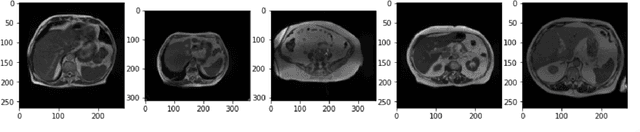
The job of Radiation oncologists is to deliver x-ray beams pointed toward the tumor and at the same time avoid the stomach and intestines. With MR-Linacs (magnetic resonance imaging and linear accelerator systems), oncologists can visualize the position of the tumor and allow for precise dose according to tumor cell presence which can vary from day to day. The current job of outlining the position of the stomach and intestines to adjust the X-ray beams direction for the dose delivery to the tumor while avoiding the organs. This is a time-consuming and labor-intensive process that can easily prolong treatments from 15 minutes to an hour a day unless deep learning methods can automate the segmentation process. This paper discusses an automated segmentation process using deep learning to make this process faster and allow more patients to get effective treatment.
Exploiting the Power of Levenberg-Marquardt Optimizer with Anomaly Detection in Time Series
Nov 11, 2021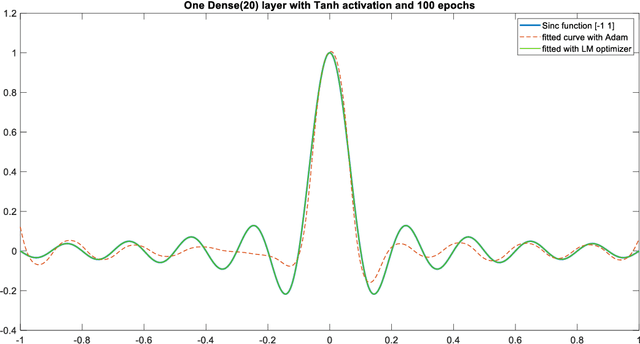
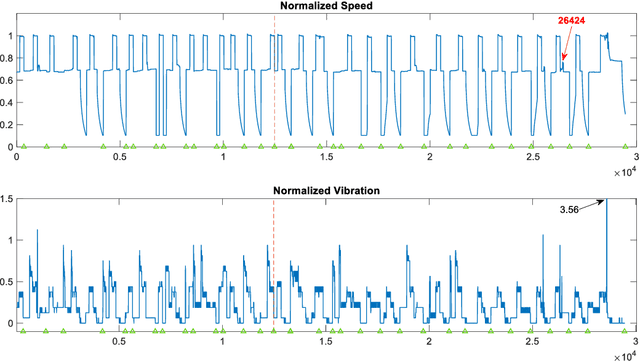
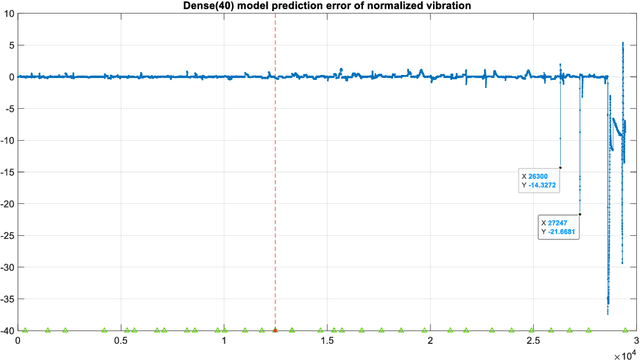
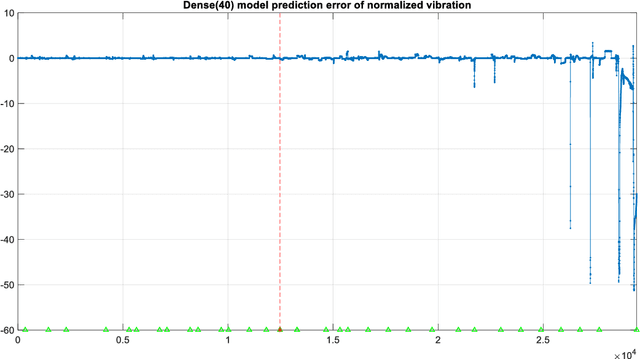
The Levenberg-Marquardt (LM) optimization algorithm has been widely used for solving machine learning problems. Literature reviews have shown that the LM can be very powerful and effective on moderate function approximation problems when the number of weights in the network is not more than a couple of hundred. In contrast, the LM does not seem to perform as well when dealing with pattern recognition or classification problems, and inefficient when networks become large (e.g. with more than 500 weights). In this paper, we exploit the true power of LM algorithm using some real world aircraft datasets. On these datasets most other commonly used optimizers are unable to detect the anomalies caused by the changing conditions of the aircraft engine. The challenging nature of the datasets are the abrupt changes in the time series data. We find that the LM optimizer has a much better ability to approximate abrupt changes and detect anomalies than other optimizers. We compare the performance, in addressing this anomaly/change detection problem, of the LM and several other optimizers. We assess the relative performance based on a range of measures including network complexity (i.e. number of weights), fitting accuracy, over fitting, training time, use of GPUs and memory requirement etc. We also discuss the issue of robust LM implementation in MATLAB and Tensorflow for promoting more popular usage of the LM algorithm and potential use of LM optimizer for large-scale problems.
Rearrangement-Based Manipulation via Kinodynamic Planning and Dynamic Planning Horizons
Aug 03, 2022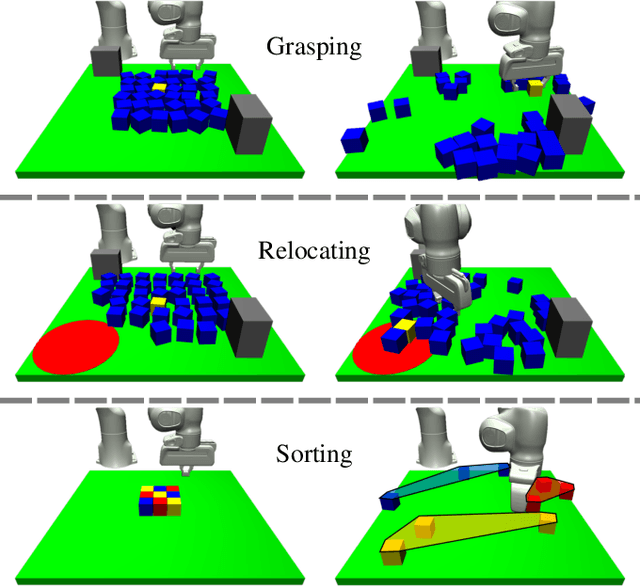
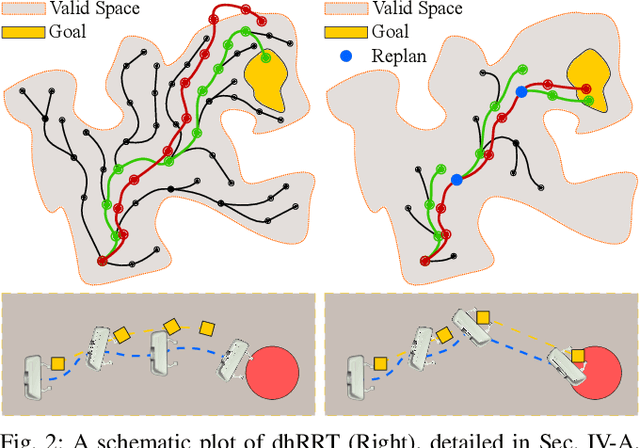

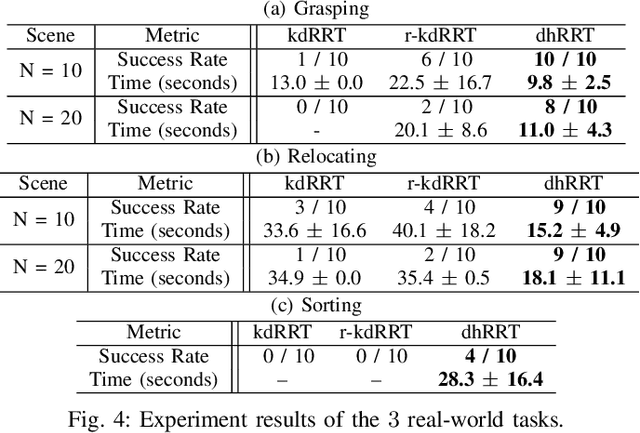
Robot manipulation in cluttered environments often requires complex and sequential rearrangement of multiple objects in order to achieve the desired reconfiguration of the target objects. Due to the sophisticated physical interactions involved in such scenarios, rearrangement-based manipulation is still limited to a small range of tasks and is especially vulnerable to physical uncertainties and perception noise. This paper presents a planning framework that leverages the efficiency of sampling-based planning approaches, and closes the manipulation loop by dynamically controlling the planning horizon. Our approach interleaves planning and execution to progressively approach the manipulation goal while correcting any errors or path deviations along the process. Meanwhile, our framework allows the definition of manipulation goals without requiring explicit goal configurations, enabling the robot to flexibly interact with all objects to facilitate the manipulation of the target ones. With extensive experiments both in simulation and on a real robot, we evaluate our framework on three manipulation tasks in cluttered environments: grasping, relocating, and sorting. In comparison with two baseline approaches, we show that our framework can significantly improve planning efficiency, robustness against physical uncertainties, and task success rate under limited time budgets.