 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Feather-Light Fourier Domain Adaptation in Magnetic Resonance Imaging
Jul 31, 2022
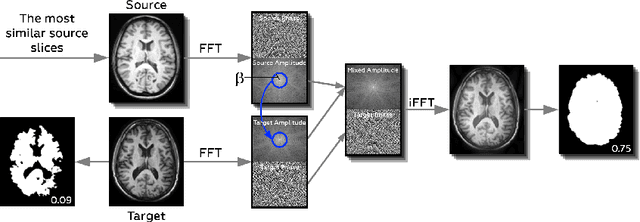

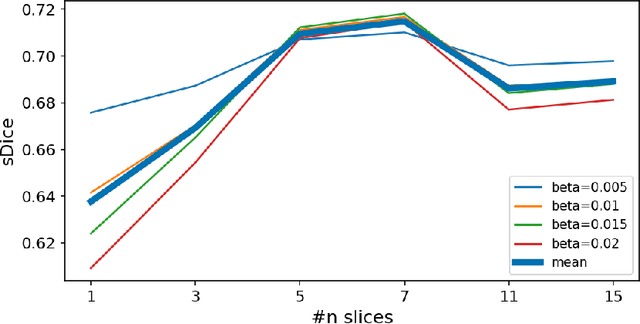
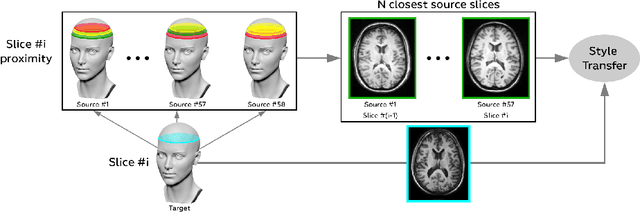
Generalizability of deep learning models may be severely affected by the difference in the distributions of the train (source domain) and the test (target domain) sets, e.g., when the sets are produced by different hardware. As a consequence of this domain shift, a certain model might perform well on data from one clinic, and then fail when deployed in another. We propose a very light and transparent approach to perform test-time domain adaptation. The idea is to substitute the target low-frequency Fourier space components that are deemed to reflect the style of an image. To maximize the performance, we implement the "optimal style donor" selection technique, and use a number of source data points for altering a single target scan appearance (Multi-Source Transferring). We study the effect of severity of domain shift on the performance of the method, and show that our training-free approach reaches the state-of-the-art level of complicated deep domain adaptation models. The code for our experiments is released.
Radix-2 Self-Recursive Sparse Factorizations of Delay Vandermonde Matrices for Wideband Multi-Beam Antenna Arrays
Jun 01, 2022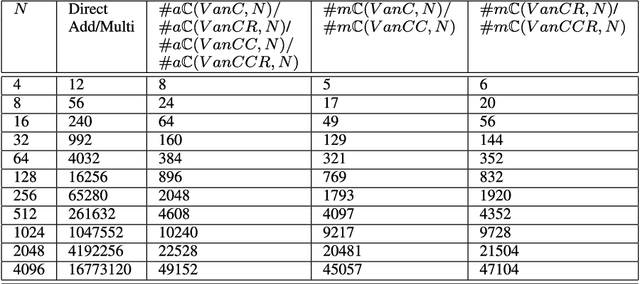
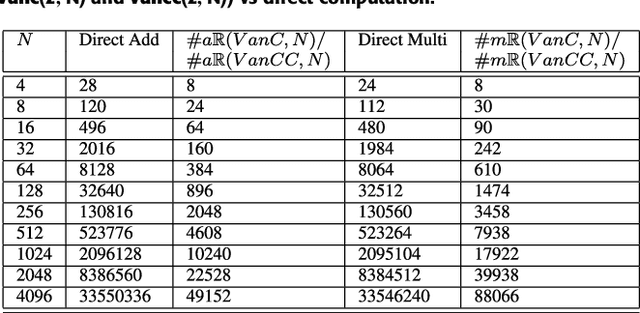
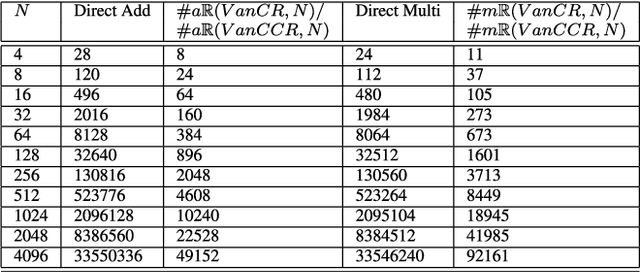
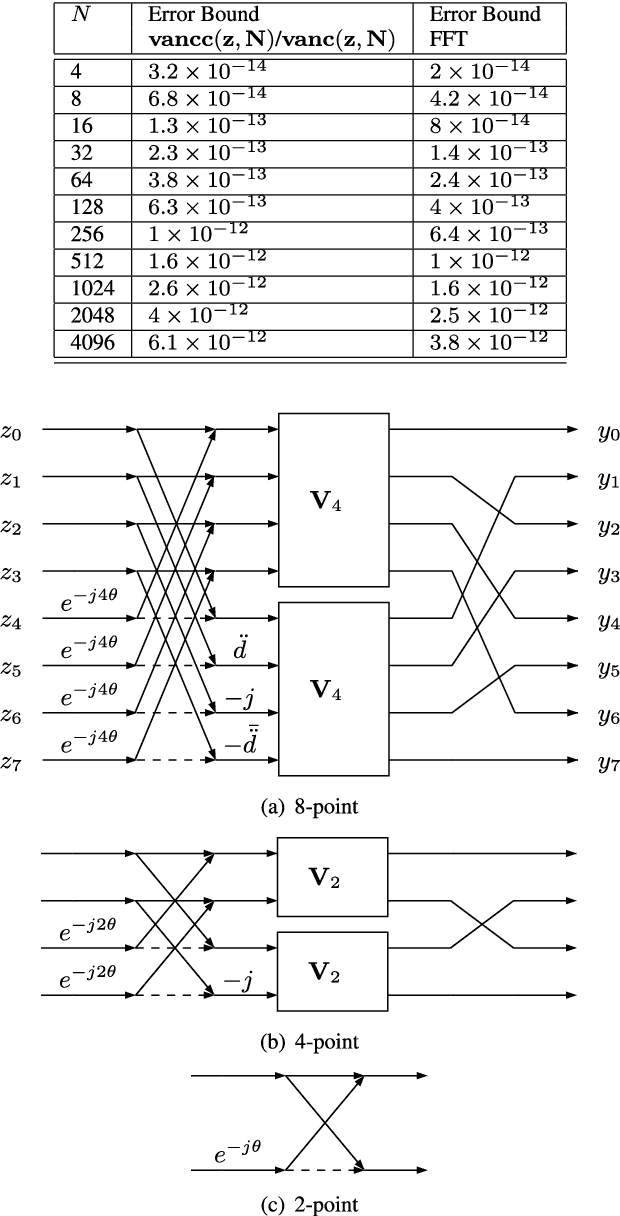
This paper presents a self-contained factorization for the Vandermonde matrices associated with true-time delay based wideband analog multi-beam beamforming using antenna arrays. The proposed factorization contains sparse and orthogonal matrices. Novel self-recursive radix-2 algorithms for Vandermonde matrices associated with true time delay based delay-sum filterbanks are presented to reduce the circuit complexity of multi-beam analog beamforming systems. The proposed algorithms for Vandermonde matrices by a vector attain $\mathcal{O}(N \log N)$ delay-amplifier circuit counts. Error bounds for the Vandermode matrices associated with true-time delay are established and then analyzed for numerical stability. The potential for real-world circuit implementation of the proposed algorithms will be shown through signal flow graphs that are the starting point for high-frequency analog circuit realizations.
* 20 pages, 1 figure
Why Accuracy Is Not Enough: The Need for Consistency in Object Detection
Jul 28, 2022

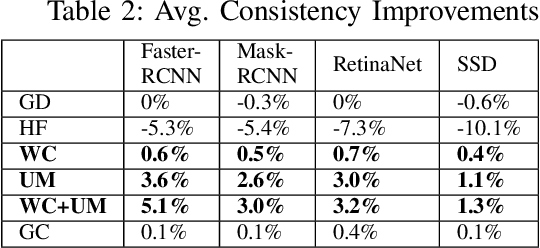
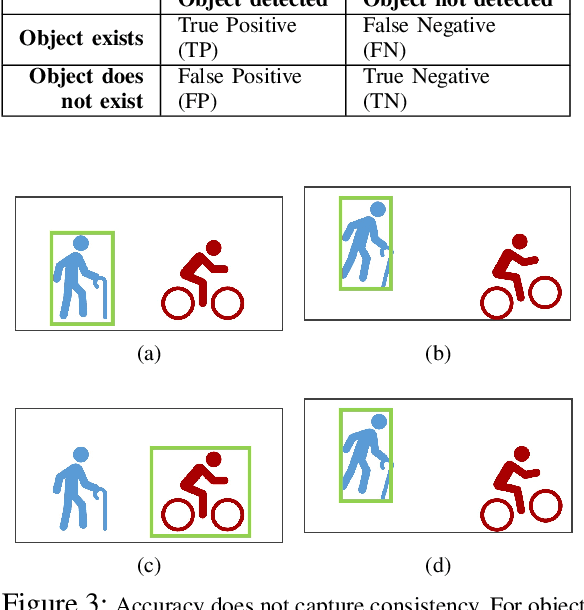
Object detectors are vital to many modern computer vision applications. However, even state-of-the-art object detectors are not perfect. On two images that look similar to human eyes, the same detector can make different predictions because of small image distortions like camera sensor noise and lighting changes. This problem is called inconsistency. Existing accuracy metrics do not properly account for inconsistency, and similar work in this area only targets improvements on artificial image distortions. Therefore, we propose a method to use non-artificial video frames to measure object detection consistency over time, across frames. Using this method, we show that the consistency of modern object detectors ranges from 83.2% to 97.1% on different video datasets from the Multiple Object Tracking Challenge. We conclude by showing that applying image distortion corrections like .WEBP Image Compression and Unsharp Masking can improve consistency by as much as 5.1%, with no loss in accuracy.
Copulaboost: additive modeling with copula-based model components
Aug 09, 2022
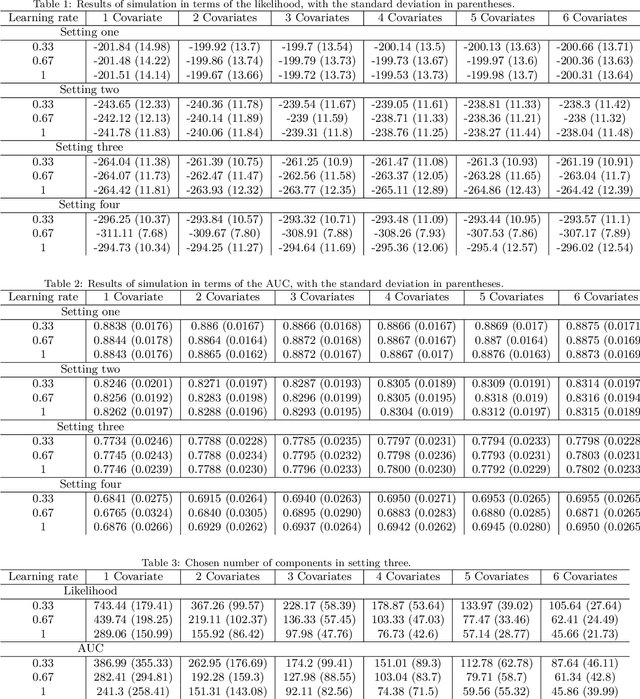
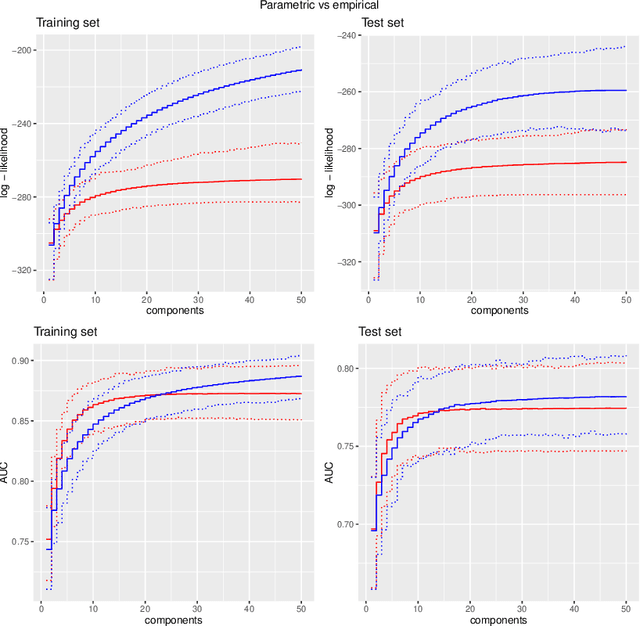
We propose a type of generalised additive models with of model components based on pair-copula constructions, with prediction as a main aim. The model components are designed such that our model may capture potentially complex interaction effects in the relationship between the response covariates. In addition, our model does not require discretisation of continuous covariates, and is therefore suitable for problems with many such covariates. Further, we have designed a fitting algorithm inspired by gradient boosting, as well as efficient procedures for model selection and evaluation of the model components, through constraints on the model space and approximations, that speed up time-costly computations. In addition to being absolutely necessary for our model to be a realistic alternative in higher dimensions, these techniques may also be useful as a basis for designing efficient models selection algorithms for other types of copula regression models. We have explored the characteristics of our method in a simulation study, in particular comparing it to natural alternatives, such as logic regression, classic boosting models and penalised logistic regression. We have also illustrated our approach on the Wisconsin breast cancer dataset and on the Boston housing dataset. The results show that our method has a prediction performance that is either better than or comparable to the other methods, even when the proportion of discrete covariates is high.
Towards FPGA Implementation of Neural Network-Based Nonlinearity Mitigation Equalizers in Coherent Optical Transmission Systems
Jun 24, 2022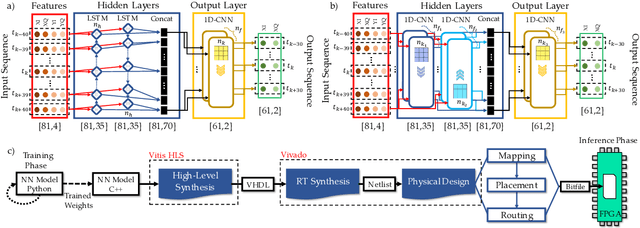
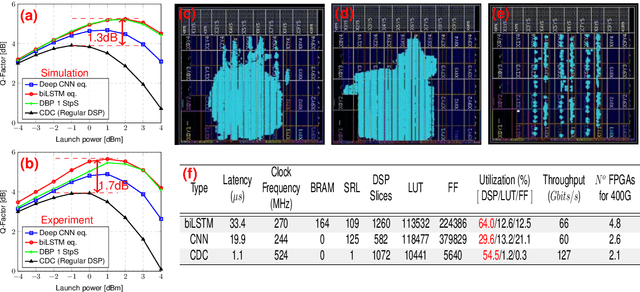
For the first time, recurrent and feedforward neural network-based equalizers for nonlinearity compensation are implemented in an FPGA, with a level of complexity comparable to that of a dispersion equalizer. We demonstrate that the NN-based equalizers can outperform a 1 step-per-span DBP.
Constraints on parameter choices for successful reservoir computing
Jun 03, 2022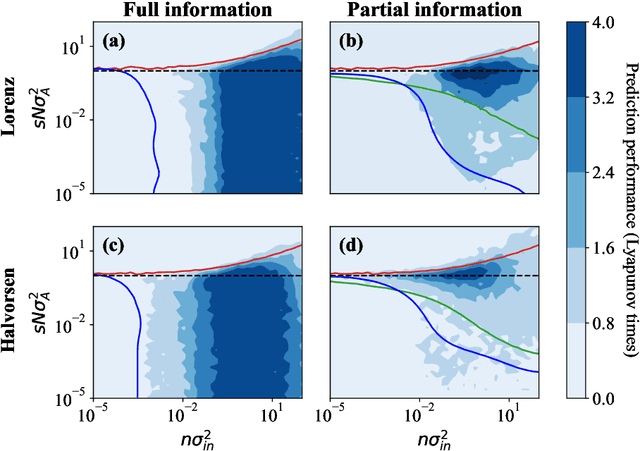
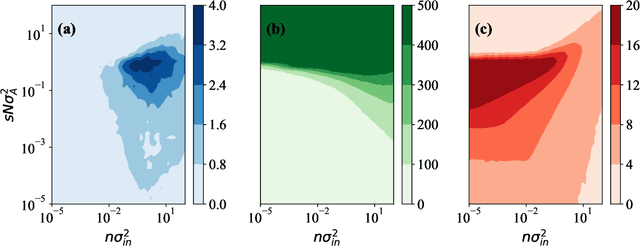
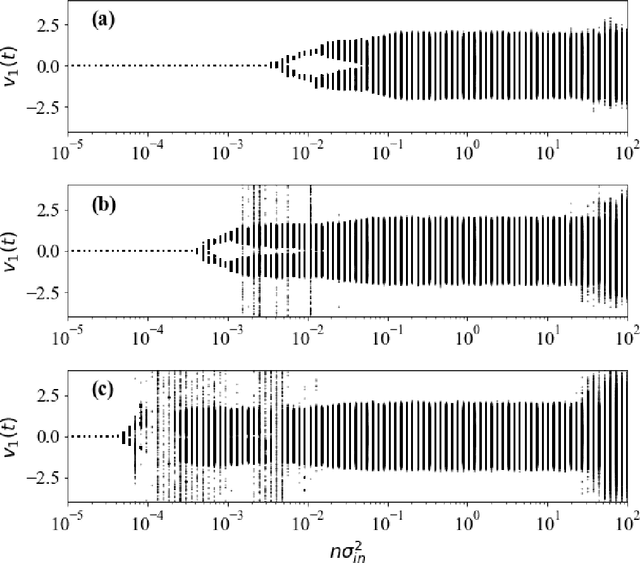
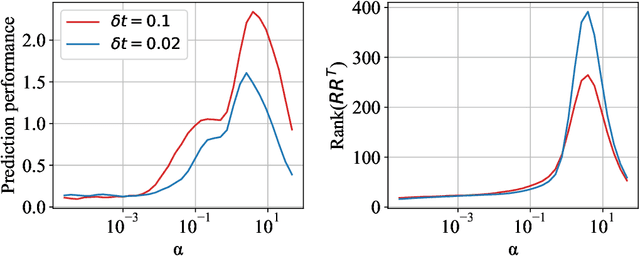
Echo-state networks are simple models of discrete dynamical systems driven by a time series. By selecting network parameters such that the dynamics of the network is contractive, characterized by a negative maximal Lyapunov exponent, the network may synchronize with the driving signal. Exploiting this synchronization, the echo-state network may be trained to autonomously reproduce the input dynamics, enabling time-series prediction. However, while synchronization is a necessary condition for prediction, it is not sufficient. Here, we study what other conditions are necessary for successful time-series prediction. We identify two key parameters for prediction performance, and conduct a parameter sweep to find regions where prediction is successful. These regions differ significantly depending on whether full or partial phase space information about the input is provided to the network during training. We explain how these regions emerge.
Choose qualified instructor for university based on rule-based weighted expert system
Aug 09, 2022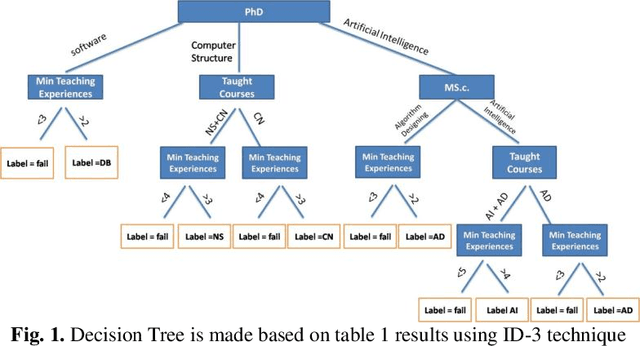
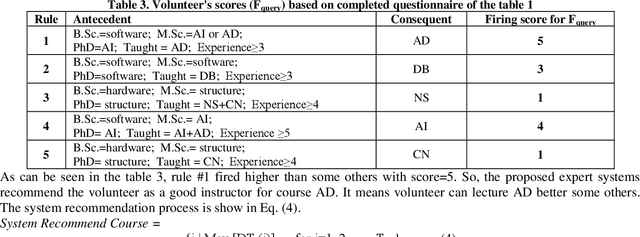
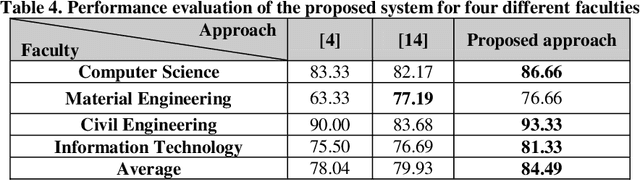
Near the entire university faculty directors must select some qualified professors for respected courses in each academic semester. In this sense, factors such as teaching experience, academic training, competition, etc. are considered. This work is usually done by experts, such as faculty directors, which is time consuming. Up to now, several semi-automatic systems have been proposed to assist heads. In this article, a fully automatic rule-based expert system is developed. The proposed expert system consists of three main stages. First, the knowledge of human experts is entered and designed as a decision tree. In the second step, an expert system is designed based on the provided rules of the generated decision tree. In the third step, an algorithm is proposed to weight the results of the tree based on the quality of the experts. To improve the performance of the expert system, a majority voting algorithm is developed as a post-process step to select the qualified trainer who satisfies the most expert decision tree for each course. The quality of the proposed expert system is evaluated using real data from Iranian universities. The calculated accuracy rate is 85.55, demonstrating the robustness and accuracy of the proposed system. The proposed system has little computational complexity compared to related efficient works. Also, simple implementation and transparent box are other features of the proposed system.
Rearrangement-Based Manipulation via Kinodynamic Planning and Dynamic Planning Horizons
Aug 03, 2022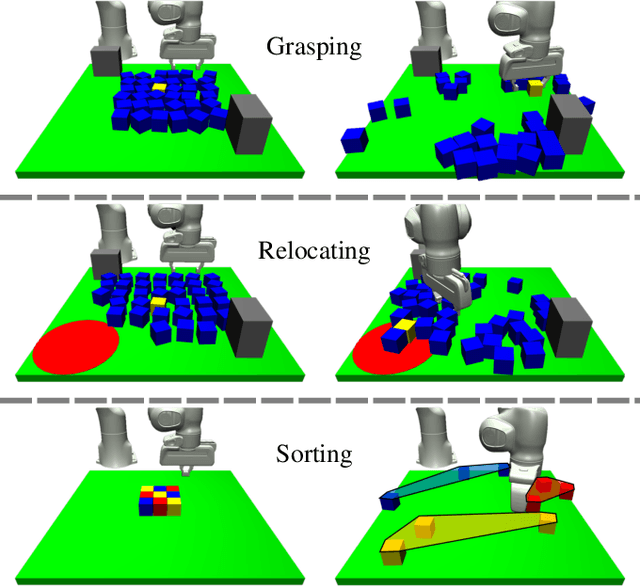
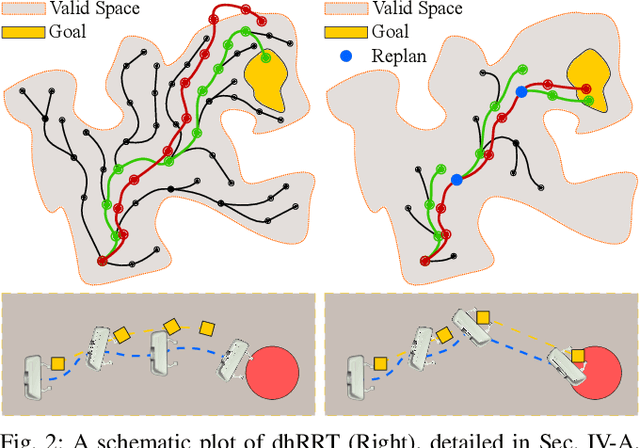

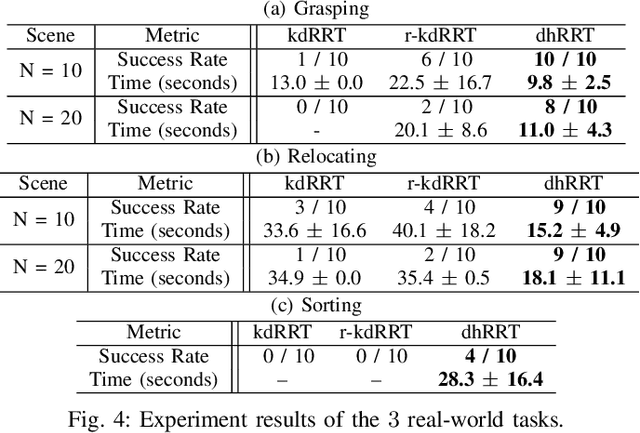
Robot manipulation in cluttered environments often requires complex and sequential rearrangement of multiple objects in order to achieve the desired reconfiguration of the target objects. Due to the sophisticated physical interactions involved in such scenarios, rearrangement-based manipulation is still limited to a small range of tasks and is especially vulnerable to physical uncertainties and perception noise. This paper presents a planning framework that leverages the efficiency of sampling-based planning approaches, and closes the manipulation loop by dynamically controlling the planning horizon. Our approach interleaves planning and execution to progressively approach the manipulation goal while correcting any errors or path deviations along the process. Meanwhile, our framework allows the definition of manipulation goals without requiring explicit goal configurations, enabling the robot to flexibly interact with all objects to facilitate the manipulation of the target ones. With extensive experiments both in simulation and on a real robot, we evaluate our framework on three manipulation tasks in cluttered environments: grasping, relocating, and sorting. In comparison with two baseline approaches, we show that our framework can significantly improve planning efficiency, robustness against physical uncertainties, and task success rate under limited time budgets.
Adaptive Sampling of Latent Phenomena using Heterogeneous Robot Teams (ASLaP-HR)
Aug 11, 2022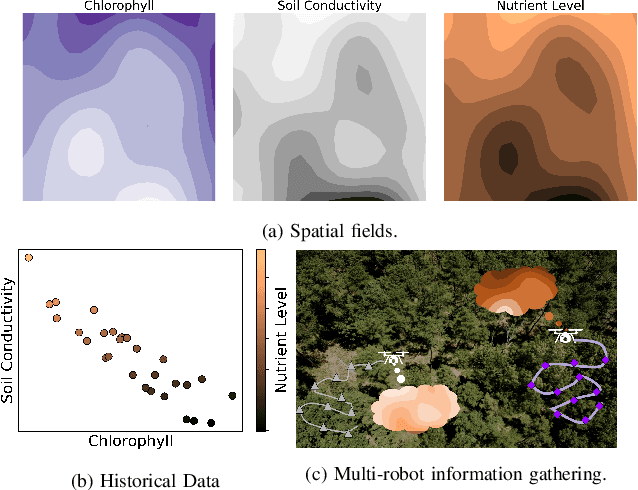
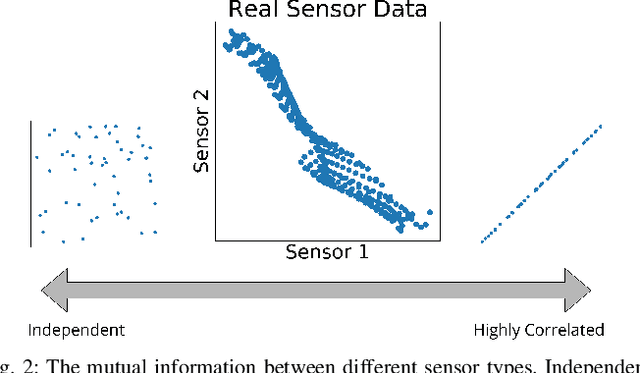
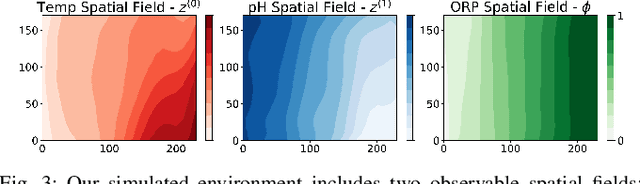
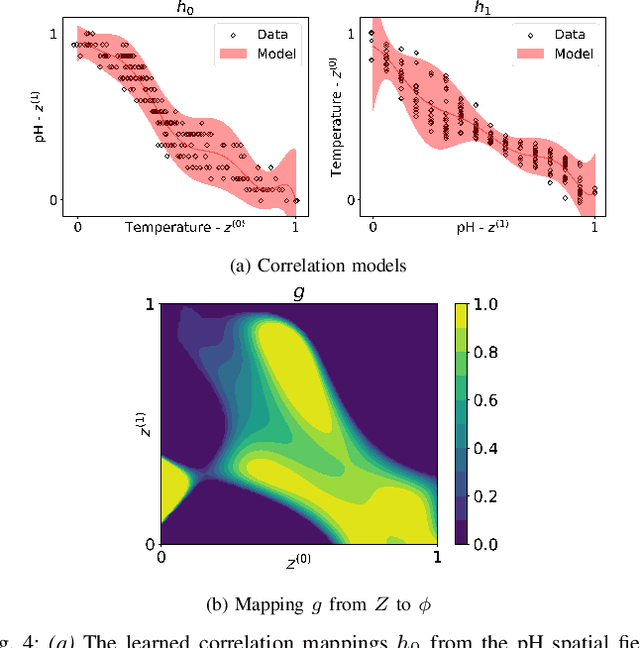
In this paper, we present an online adaptive planning strategy for a team of robots with heterogeneous sensors to sample from a latent spatial field using a learned model for decision making. Current robotic sampling methods seek to gather information about an observable spatial field. However, many applications, such as environmental monitoring and precision agriculture, involve phenomena that are not directly observable or are costly to measure, called latent phenomena. In our approach, we seek to reason about the latent phenomenon in real-time by effectively sampling the observable spatial fields using a team of robots with heterogeneous sensors, where each robot has a distinct sensor to measure a different observable field. The information gain is estimated using a learned model that maps from the observable spatial fields to the latent phenomenon. This model captures aleatoric uncertainty in the relationship to allow for information theoretic measures. Additionally, we explicitly consider the correlations among the observable spatial fields, capturing the relationship between sensor types whose observations are not independent. We show it is possible to learn these correlations, and investigate the impact of the learned correlation models on the performance of our sampling approach. Through our qualitative and quantitative results, we illustrate that empirically learned correlations improve the overall sampling efficiency of the team. We simulate our approach using a data set of sensor measurements collected on Lac Hertel, in Quebec, which we make publicly available.
A Hybrid Method for Condition Monitoring and Fault Diagnosis of Rolling Bearings With Low System Delay
Aug 11, 2022
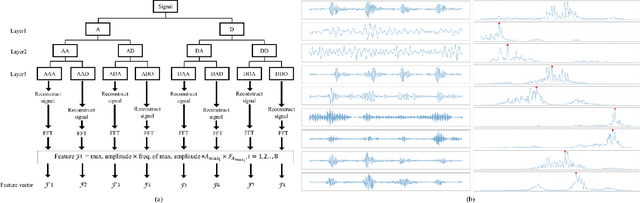
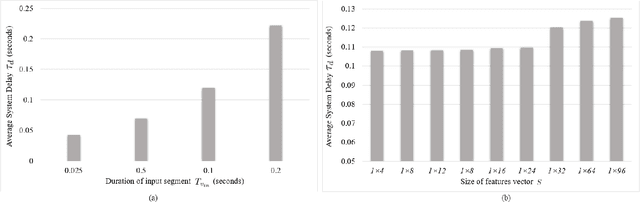
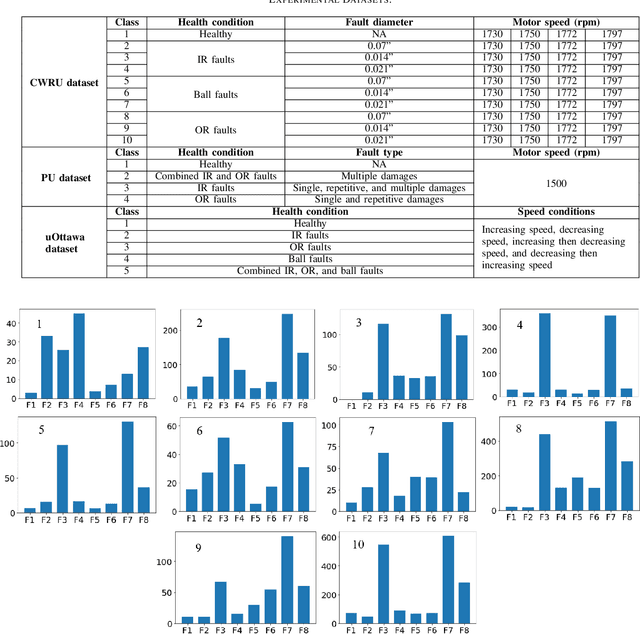
Vibration-based condition monitoring techniques are commonly used to detect and diagnose failures of rolling bearings. Accuracy and delay in detecting and diagnosing different types of failures are the main performance measures in condition monitoring. Achieving high accuracy with low delay improves system reliability and prevents catastrophic equipment failure. Further, delay is crucial to remote condition monitoring and time-sensitive industrial applications. While most of the proposed methods focus on accuracy, slight attention has been paid to addressing the delay introduced in the condition monitoring process. In this paper, we attempt to bridge this gap and propose a hybrid method for vibration-based condition monitoring and fault diagnosis of rolling bearings that outperforms previous methods in terms of accuracy and delay. Specifically, we address the overall delay in vibration-based condition monitoring systems and introduce the concept of system delay to assess it. Then, we present the proposed method for condition monitoring. It uses Wavelet Packet Transform (WPT) and Fourier analysis to decompose short-duration input segments of the vibration signal into elementary waveforms and obtain their spectral contents. Accordingly, energy concentration in the spectral components-caused by defect induced transient vibrations-is utilized to extract a small number of features with high discriminative capabilities. Consequently, Bayesian optimization-based Random Forest (RF) algorithm is used to classify healthy and faulty operating conditions under varying motor speeds. The experimental results show that the proposed method can achieve high accuracy with low system delay.