 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
An Empirical Study of Pseudo-Labeling for Image-based 3D Object Detection
Aug 15, 2022


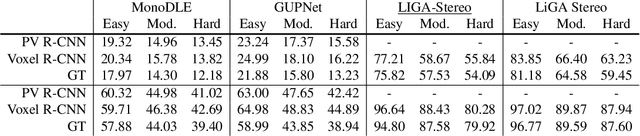
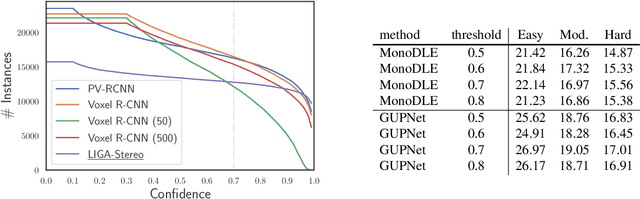
Image-based 3D detection is an indispensable component of the perception system for autonomous driving. However, it still suffers from the unsatisfying performance, one of the main reasons for which is the limited training data. Unfortunately, annotating the objects in the 3D space is extremely time/resource-consuming, which makes it hard to extend the training set arbitrarily. In this work, we focus on the semi-supervised manner and explore the feasibility of a cheaper alternative, i.e. pseudo-labeling, to leverage the unlabeled data. For this purpose, we conduct extensive experiments to investigate whether the pseudo-labels can provide effective supervision for the baseline models under varying settings. The experimental results not only demonstrate the effectiveness of the pseudo-labeling mechanism for image-based 3D detection (e.g. under monocular setting, we achieve 20.23 AP for moderate level on the KITTI-3D testing set without bells and whistles, improving the baseline model by 6.03 AP), but also show several interesting and noteworthy findings (e.g. the models trained with pseudo-labels perform better than that trained with ground-truth annotations based on the same training data). We hope this work can provide insights for the image-based 3D detection community under a semi-supervised setting. The codes, pseudo-labels, and pre-trained models will be publicly available.
Simplifying Sparse Expert Recommendation by Revisiting Graph Diffusion
Aug 04, 2022
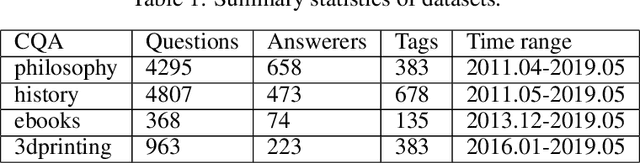
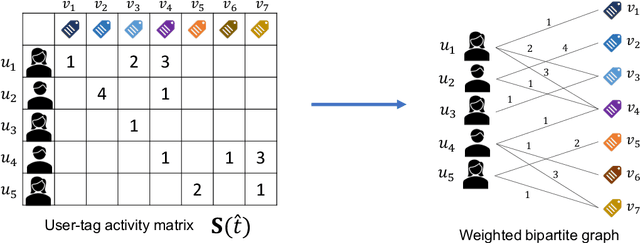
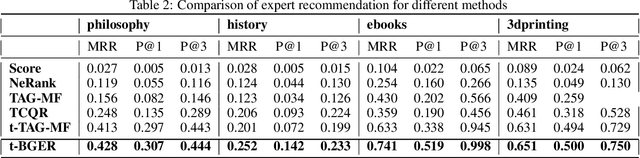
Community Question Answering (CQA) websites have become valuable knowledge repositories where individuals exchange information by asking and answering questions. With an ever-increasing number of questions and high migration of users in and out of communities, a key challenge is to design effective strategies for recommending experts for new questions. In this paper, we propose a simple graph-diffusion expert recommendation model for CQA, that can outperform state-of-the art deep learning representatives and collaborative models. Our proposed method learns users' expertise in the context of both semantic and temporal information to capture their changing interest and activity levels with time. Experiments on five real-world datasets from the Stack Exchange network demonstrate that our approach outperforms competitive baseline methods. Further, experiments on cold-start users (users with a limited historical record) show our model achieves an average of ~ 30% performance gain compared to the best baseline method.
Flood Prediction Using Machine Learning Models
Aug 02, 2022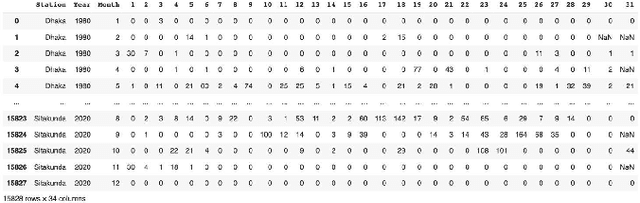
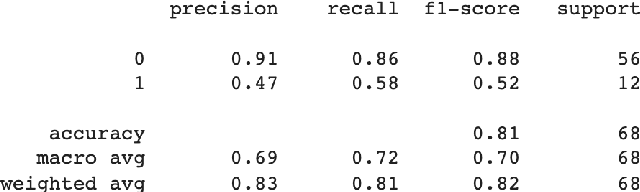
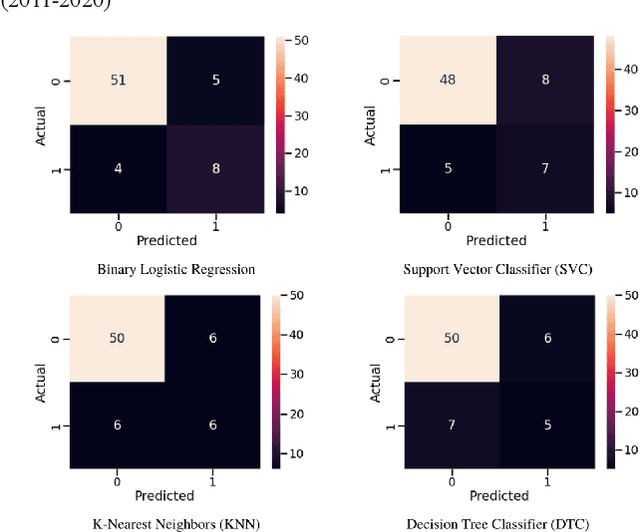
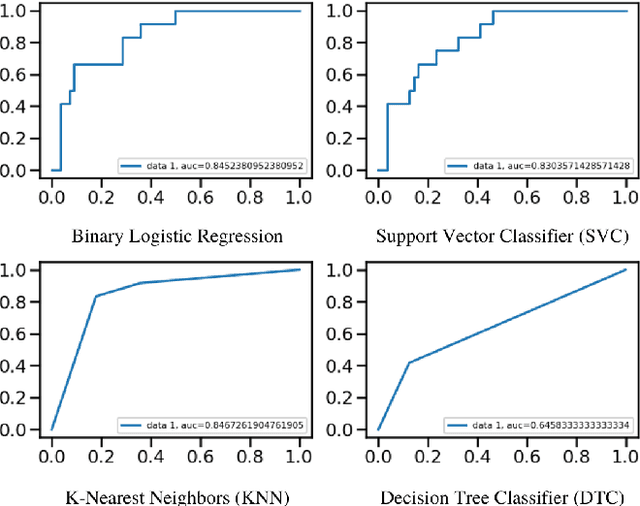
Floods are one of nature's most catastrophic calamities which cause irreversible and immense damage to human life, agriculture, infrastructure and socio-economic system. Several studies on flood catastrophe management and flood forecasting systems have been conducted. The accurate prediction of the onset and progression of floods in real time is challenging. To estimate water levels and velocities across a large area, it is necessary to combine data with computationally demanding flood propagation models. This paper aims to reduce the extreme risks of this natural disaster and also contributes to policy suggestions by providing a prediction for floods using different machine learning models. This research will use Binary Logistic Regression, K-Nearest Neighbor (KNN), Support Vector Classifier (SVC) and Decision tree Classifier to provide an accurate prediction. With the outcome, a comparative analysis will be conducted to understand which model delivers a better accuracy.
Lyapunov function approach for approximation algorithm design and analysis: with applications in submodular maximization
May 27, 2022We propose a two-phase systematical framework for approximation algorithm design and analysis via Lyapunov function. The first phase consists of using Lyapunov function as an input and outputs a continuous-time approximation algorithm with a provable approximation ratio. The second phase then converts this continuous-time algorithm to a discrete-time algorithm with almost the same approximation ratio along with provable time complexity. One distinctive feature of our framework is that we only need to know the parametric form of the Lyapunov function whose complete specification will not be decided until the end of the first phase by maximizing the approximation ratio of the continuous-time algorithm. Some immediate benefits of the Lyapunov function approach include: (i) unifying many existing algorithms; (ii) providing a guideline to design and analyze new algorithms; and (iii) offer new perspectives to potentially improve existing algorithms. We use various submodular maximization problems as running examples to illustrate our framework.
YOLOV: Making Still Image Object Detectors Great at Video Object Detection
Aug 20, 2022
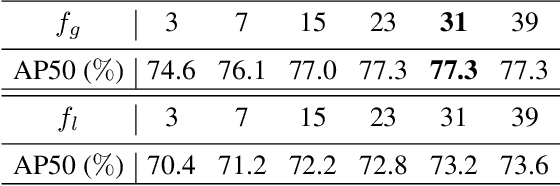
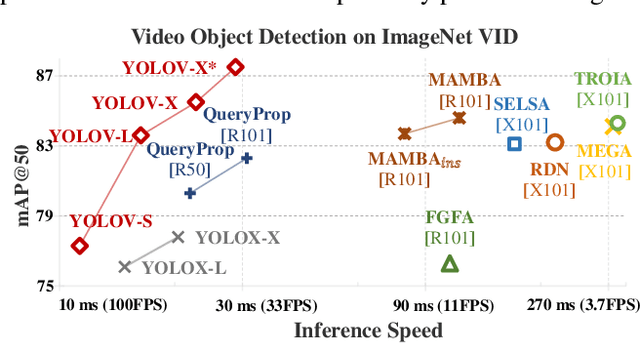

Video object detection (VID) is challenging because of the high variation of object appearance as well as the diverse deterioration in some frames. On the positive side, the detection in a certain frame of a video, compared with in a still image, can draw support from other frames. Hence, how to aggregate features across different frames is pivotal to the VID problem. Most of existing aggregation algorithms are customized for two-stage detectors. But, the detectors in this category are usually computationally expensive due to the two-stage nature. This work proposes a simple yet effective strategy to address the above concerns, which spends marginal overheads with significant gains in accuracy. Concretely, different from the traditional two-stage pipeline, we advocate putting the region-level selection after the one-stage detection to avoid processing massive low-quality candidates. Besides, a novel module is constructed to evaluate the relationship between a target frame and its reference ones, and guide the aggregation. Extensive experiments and ablation studies are conducted to verify the efficacy of our design, and reveal its superiority over other state-of-the-art VID approaches in both effectiveness and efficiency. Our YOLOX-based model can achieve promising performance (e.g., 87.5\% AP50 at over 30 FPS on the ImageNet VID dataset on a single 2080Ti GPU), making it attractive for large-scale or real-time applications. The implementation is simple, the demo code and models have been made available at https://github.com/YuHengsss/YOLOV .
Deep Odometry Systems on Edge with EKF-LoRa Backend for Real-Time Positioning in Adverse Environment
Dec 10, 2021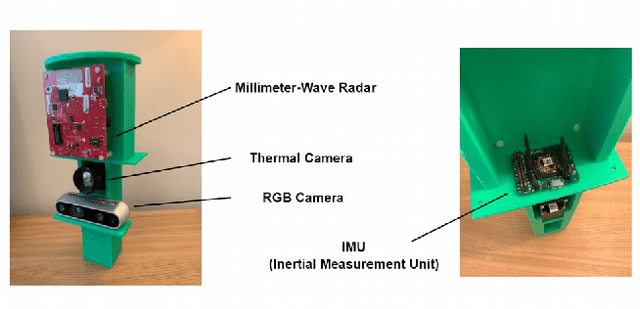
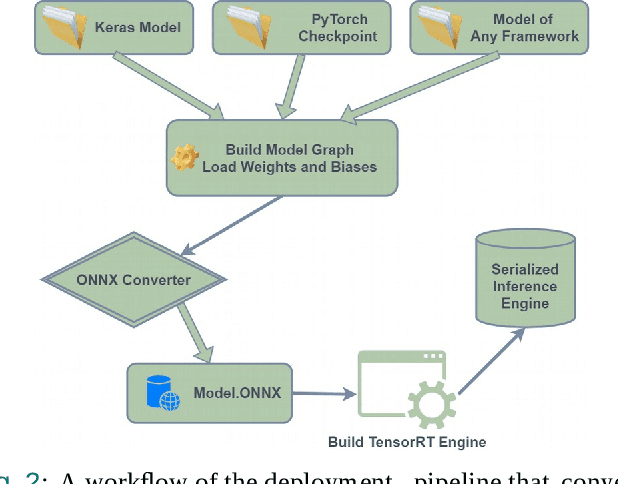
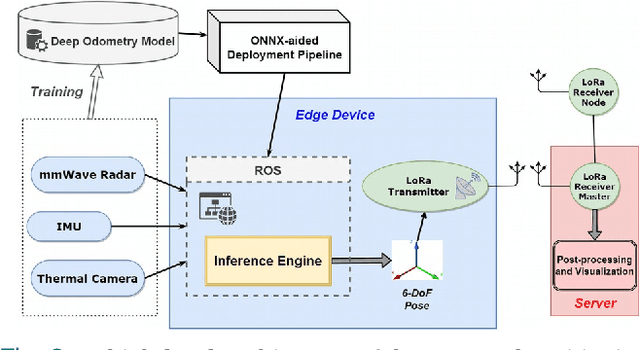
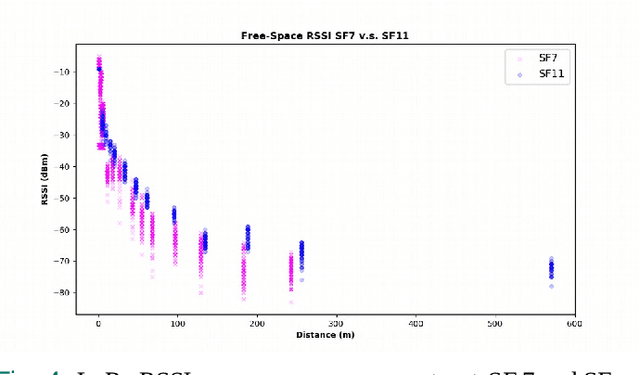
Ubiquitous positioning for pedestrian in adverse environment has served a long standing challenge. Despite dramatic progress made by Deep Learning, multi-sensor deep odometry systems yet pose a high computational cost and suffer from cumulative drifting errors over time. Thanks to the increasing computational power of edge devices, we propose a novel ubiquitous positioning solution by integrating state-of-the-art deep odometry models on edge with an EKF (Extended Kalman Filter)-LoRa backend. We carefully compare and select three sensor modalities, i.e., an Inertial Measurement Unit (IMU), a millimetre-wave (mmWave) radar, and a thermal infrared camera, and realise their deep odometry inference engines which runs in real-time. A pipeline of deploying deep odometry considering accuracy, complexity, and edge platform is proposed. We design a LoRa link for positional data backhaul and projecting aggregated positions of deep odometry into the global frame. We find that a simple EKF based fusion module is sufficient for generic positioning calibration with over 34% accuracy gains against any standalone deep odometry system. Extensive tests in different environments validate the efficiency and efficacy of our proposed positioning system.
Time-Frequency Localization Using Deep Convolutional Maxout Neural Network in Persian Speech Recognition
Sep 06, 2021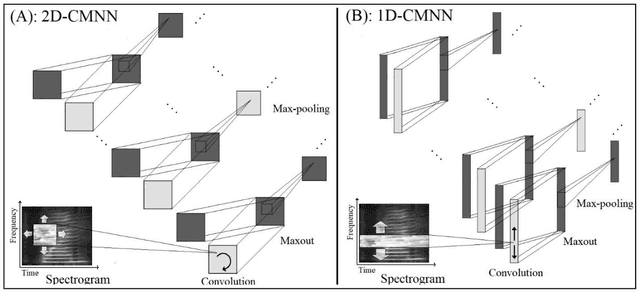
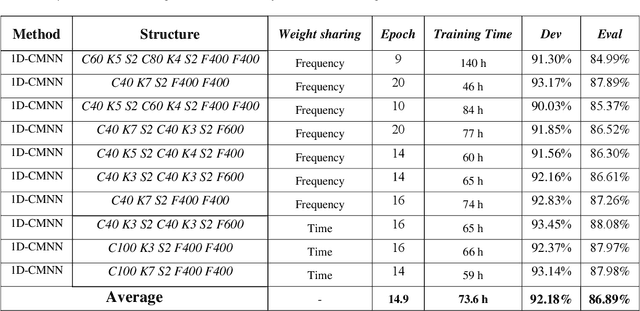
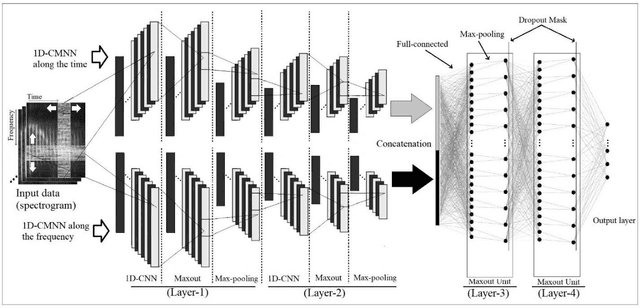
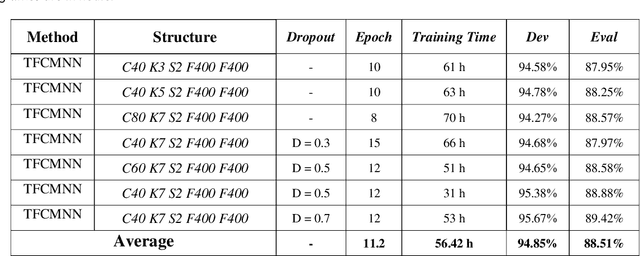
In this paper, a CNN-based structure for time-frequency localization of information in the ASR acoustic model is proposed for Persian speech recognition. Research has shown that the receptive fields' spectrotemporal plasticity of some neurons in mammals' primary auditory cortex and midbrain makes localization facilities that improve recognition performance. As biosystems have inspired many man-maid systems because of their high efficiency and performance, in the last few years, much work has been done to localize time-frequency information in ASR systems, which has used the spatial or temporal immutability properties of methods such as TDNN, CNN, and LSTM-RNN. However, most of these models have large parameter volumes and are challenging to train. We have presented a structure called Time-Frequency Convolutional Maxout Neural Network (TFCMNN) in which two parallel time-domain and frequency-domain 1D-CMNN are used. These two blocks are applied simultaneously but independently to the spectrogram, and then their output is concatenated and applied jointly to a fully connected Maxout network for classification. To improve the performance of this structure, we have used newly developed methods and models such as Dropout, maxout, and weight normalization. Two sets of experiments were designed and implemented on the Persian FARSDAT speech dataset to evaluate the performance of this model compared to conventional 1D-CMNN models. According to the experimental results, the average recognition score of TFCMNN models is about 1.6% higher than the average of conventional models. In addition, the average training time of the TFCMNN models is about 17 hours lower than the average training time of traditional models. Therefore, as proven in other sources, we can say that time-frequency localization in ASR systems increases system accuracy and speeds up the training process.
AuxAdapt: Stable and Efficient Test-Time Adaptation for Temporally Consistent Video Semantic Segmentation
Oct 24, 2021
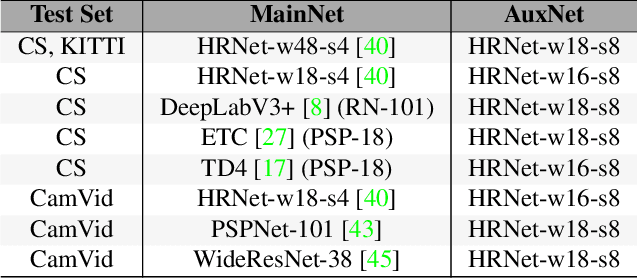
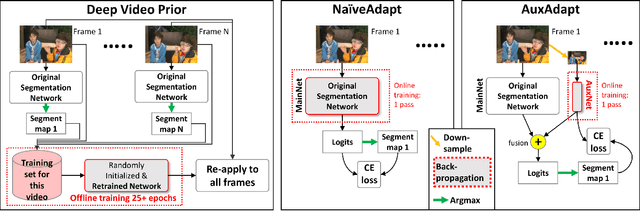
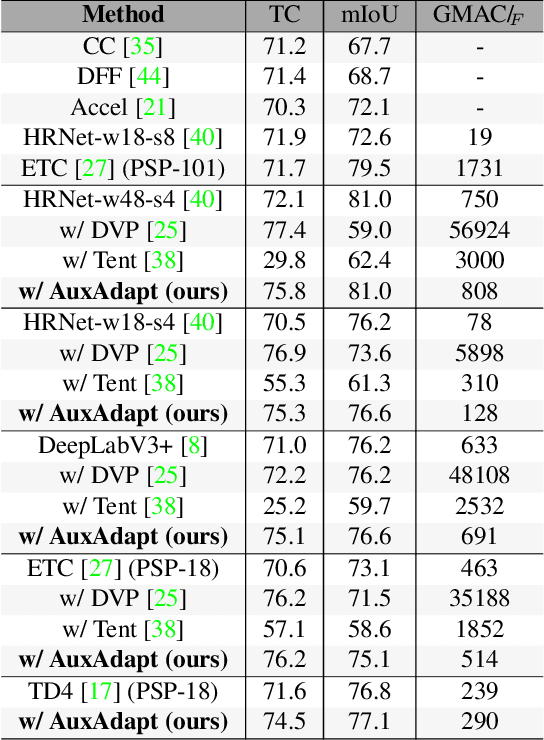
In video segmentation, generating temporally consistent results across frames is as important as achieving frame-wise accuracy. Existing methods rely either on optical flow regularization or fine-tuning with test data to attain temporal consistency. However, optical flow is not always avail-able and reliable. Besides, it is expensive to compute. Fine-tuning the original model in test time is cost sensitive. This paper presents an efficient, intuitive, and unsupervised online adaptation method, AuxAdapt, for improving the temporal consistency of most neural network models. It does not require optical flow and only takes one pass of the video. Since inconsistency mainly arises from the model's uncertainty in its output, we propose an adaptation scheme where the model learns from its own segmentation decisions as it streams a video, which allows producing more confident and temporally consistent labeling for similarly-looking pixels across frames. For stability and efficiency, we leverage a small auxiliary segmentation network (AuxNet) to assist with this adaptation. More specifically, AuxNet readjusts the decision of the original segmentation network (Main-Net) by adding its own estimations to that of MainNet. At every frame, only AuxNet is updated via back-propagation while keeping MainNet fixed. We extensively evaluate our test-time adaptation approach on standard video benchmarks, including Cityscapes, CamVid, and KITTI. The results demonstrate that our approach provides label-wise accurate, temporally consistent, and computationally efficient adaptation (5+ folds overhead reduction comparing to state-of-the-art test-time adaptation methods).
Pyramidal Predictive Network: A Model for Visual-frame Prediction Based on Predictive Coding Theory
Aug 15, 2022
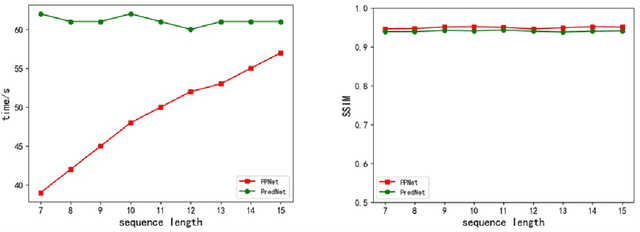
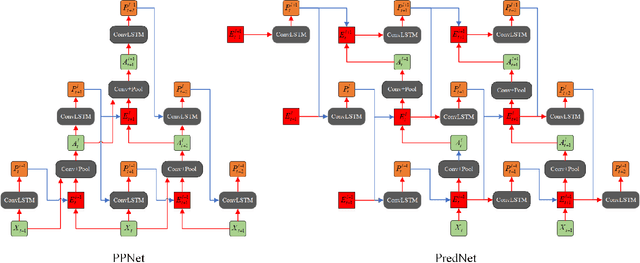
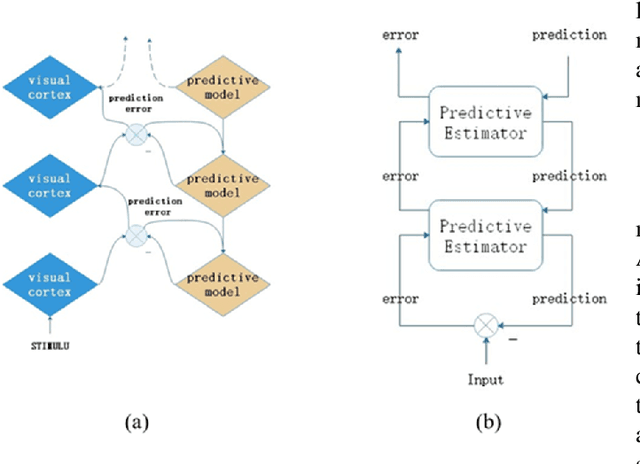
Inspired by the well-known predictive coding theory in cognitive science, we propose a novel neural network model for the task of visual-frame prediction. In this paper, our main work is to combine the theoretical framework of predictive coding and deep learning architectures, to design an efficient predictive network model for visual-frame prediction. The model is composed of a series of recurrent and convolutional units forming the top-down and bottom-up streams, respectively. It learns to predict future frames in a visual sequence, with ConvLSTMs on each layer in the network making local prediction from top to down. The main innovation of our model is that the update frequency of neural units on each of the layer decreases with the increasing of network levels, which results in the model appears like a pyramid from the perspective of time dimension, so we call it the Pyramid Predictive Network (PPNet). Particularly, this pyramid-like design is consistent to the neuronal activities in the neuroscience findings involved in the predictive coding framework. According to the experimental results, this model shows better compactness and comparable predictive performance with existing works, implying lower computational cost and higher prediction accuracy. Code will be available at https://github.com/Ling-CF/PPNet.
A Multibranch Convolutional Neural Network for Hyperspectral Unmixing
Aug 03, 2022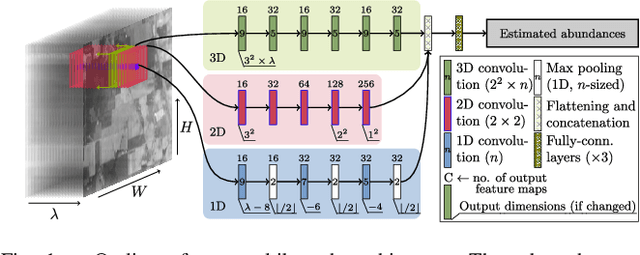
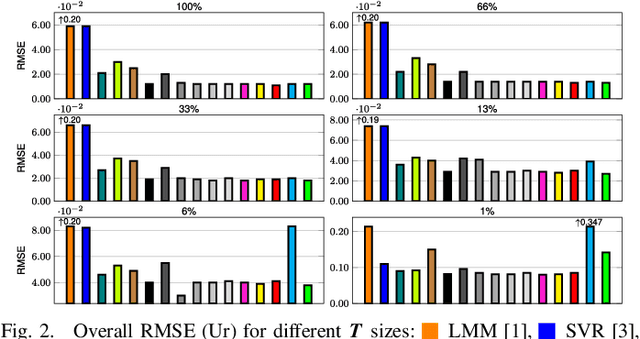
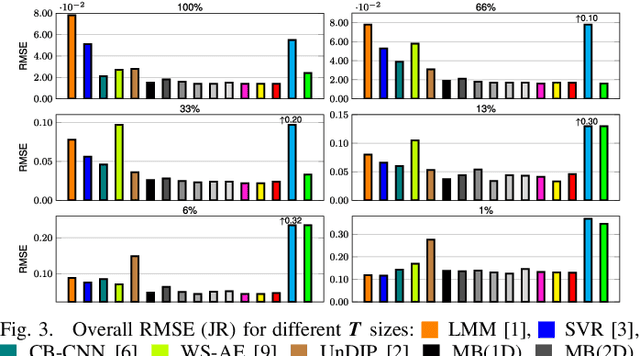
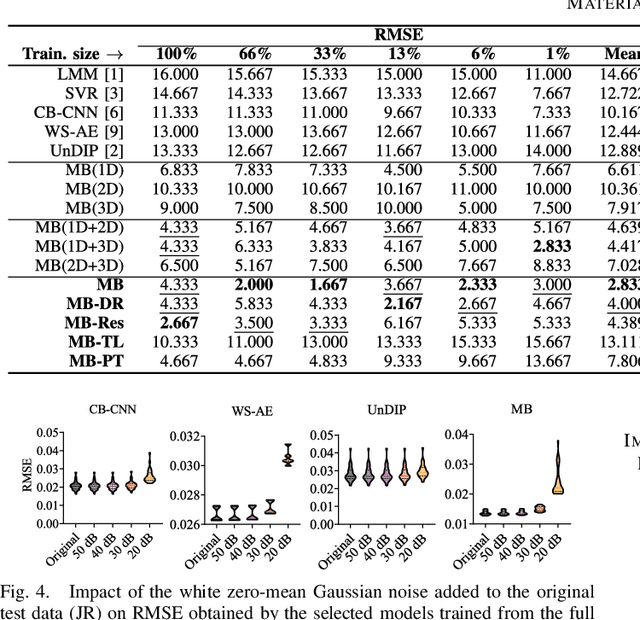
Hyperspectral unmixing remains one of the most challenging tasks in the analysis of such data. Deep learning has been blooming in the field and proved to outperform other classic unmixing techniques, and can be effectively deployed onboard Earth observation satellites equipped with hyperspectral imagers. In this letter, we follow this research pathway and propose a multi-branch convolutional neural network that benefits from fusing spectral, spatial, and spectral-spatial features in the unmixing process. The results of our experiments, backed up with the ablation study, revealed that our techniques outperform others from the literature and lead to higher-quality fractional abundance estimation. Also, we investigated the influence of reducing the training sets on the capabilities of all algorithms and their robustness against noise, as capturing large and representative ground-truth sets is time-consuming and costly in practice, especially in emerging Earth observation scenarios.
* 14 pages (including supplementary material), published in IEEE Geoscience and Remote Sensing Letters