 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning Branched Fusion and Orthogonal Projection for Face-Voice Association
Aug 22, 2022
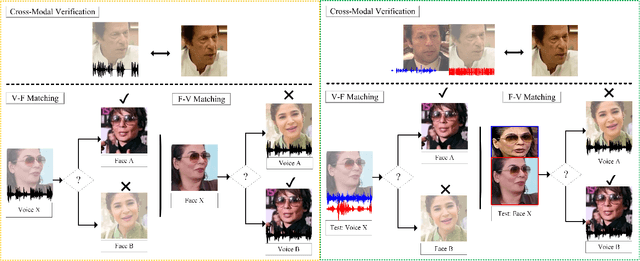
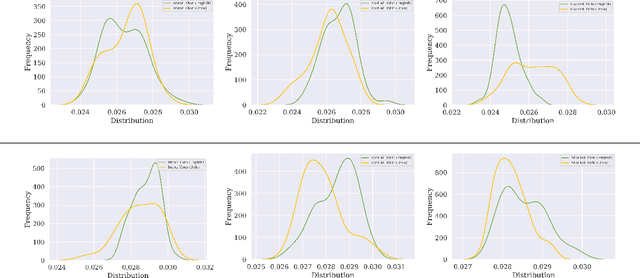
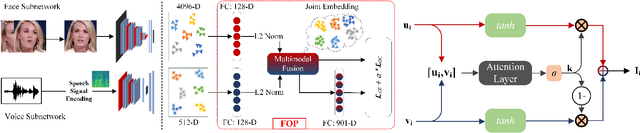
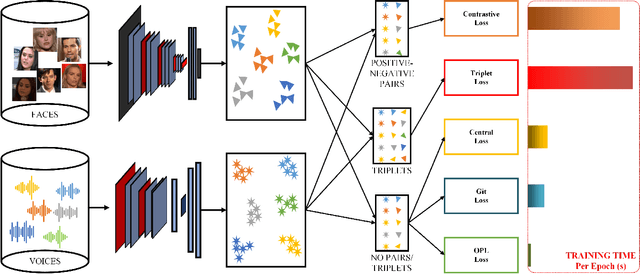
Recent years have seen an increased interest in establishing association between faces and voices of celebrities leveraging audio-visual information from YouTube. Prior works adopt metric learning methods to learn an embedding space that is amenable for associated matching and verification tasks. Albeit showing some progress, such formulations are, however, restrictive due to dependency on distance-dependent margin parameter, poor run-time training complexity, and reliance on carefully crafted negative mining procedures. In this work, we hypothesize that an enriched representation coupled with an effective yet efficient supervision is important towards realizing a discriminative joint embedding space for face-voice association tasks. To this end, we propose a light-weight, plug-and-play mechanism that exploits the complementary cues in both modalities to form enriched fused embeddings and clusters them based on their identity labels via orthogonality constraints. We coin our proposed mechanism as fusion and orthogonal projection (FOP) and instantiate in a two-stream network. The overall resulting framework is evaluated on VoxCeleb1 and MAV-Celeb datasets with a multitude of tasks, including cross-modal verification and matching. Results reveal that our method performs favourably against the current state-of-the-art methods and our proposed formulation of supervision is more effective and efficient than the ones employed by the contemporary methods. In addition, we leverage cross-modal verification and matching tasks to analyze the impact of multiple languages on face-voice association. Code is available: \url{https://github.com/msaadsaeed/FOP}
Nonlinear Model Predictive Control for Quadrupedal Locomotion Using Second-Order Sensitivity Analysis
Jul 21, 2022
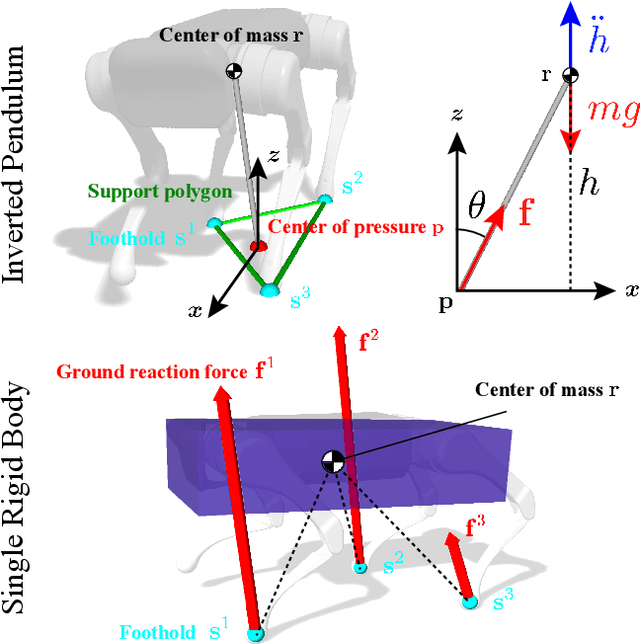

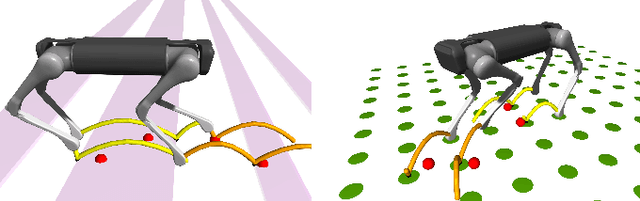
We present a versatile nonlinear model predictive control (NMPC) formulation for quadrupedal locomotion. Our formulation jointly optimizes a base trajectory and a set of footholds over a finite time horizon based on simplified dynamics models. We leverage second-order sensitivity analysis and a sparse Gauss-Newton (SGN) method to solve the resulting optimal control problems. We further describe our ongoing effort to verify our approach through simulation and hardware experiments. Finally, we extend our locomotion framework to deal with challenging tasks that comprise gap crossing, movement on stepping stones, and multi-robot control.
WeightMom: Learning Sparse Networks using Iterative Momentum-based pruning
Aug 11, 2022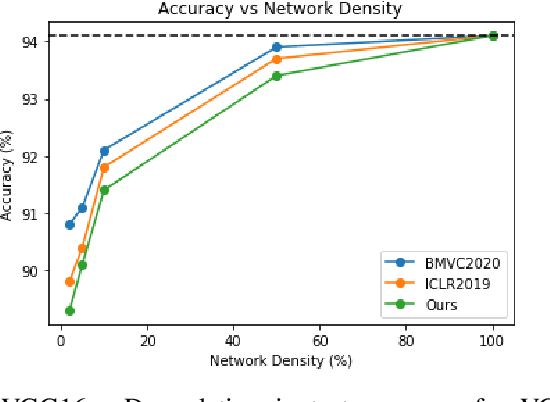
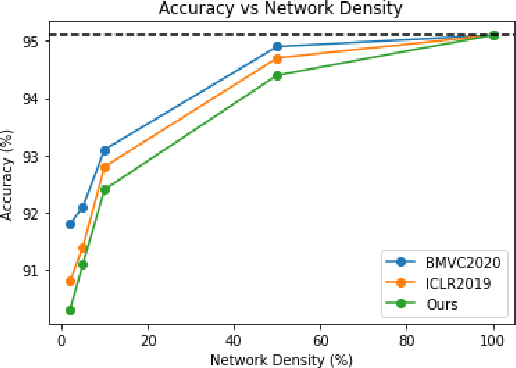
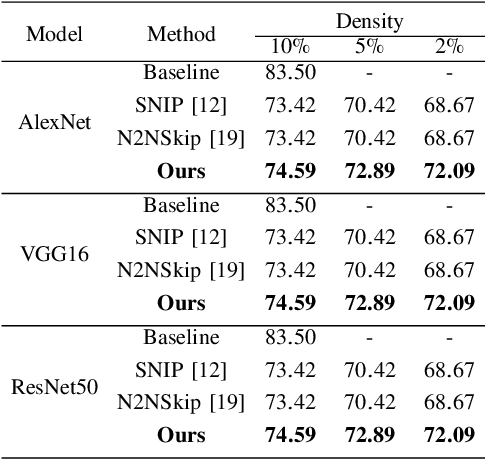
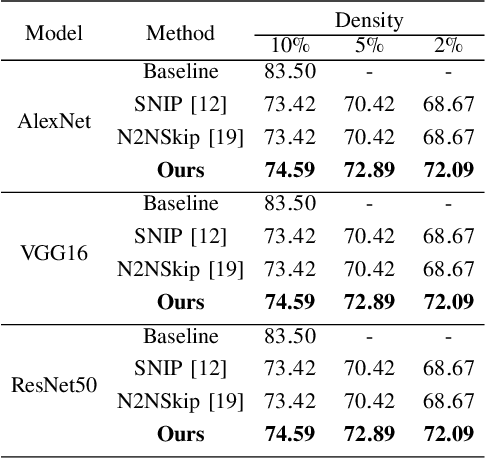
Deep Neural Networks have been used in a wide variety of applications with significant success. However, their highly complex nature owing to comprising millions of parameters has lead to problems during deployment in pipelines with low latency requirements. As a result, it is more desirable to obtain lightweight neural networks which have the same performance during inference time. In this work, we propose a weight based pruning approach in which the weights are pruned gradually based on their momentum of the previous iterations. Each layer of the neural network is assigned an importance value based on their relative sparsity, followed by the magnitude of the weight in the previous iterations. We evaluate our approach on networks such as AlexNet, VGG16 and ResNet50 with image classification datasets such as CIFAR-10 and CIFAR-100. We found that the results outperformed the previous approaches with respect to accuracy and compression ratio. Our method is able to obtain a compression of 15% for the same degradation in accuracy on both the datasets.
Short-Term Trajectory Prediction for Full-Immersive Multiuser Virtual Reality with Redirected Walking
Jul 15, 2022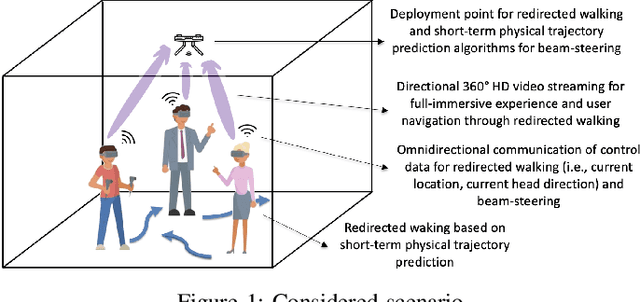
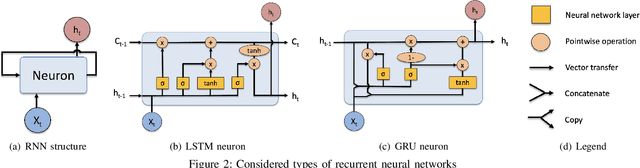
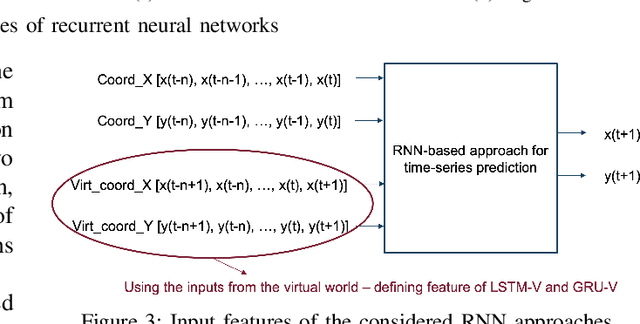
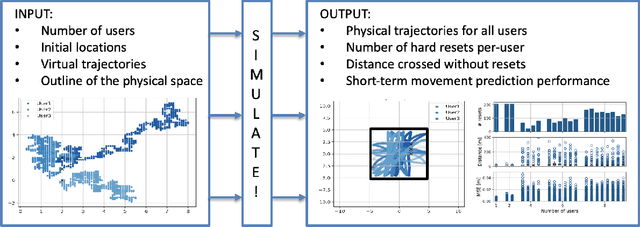
Full-immersive multiuser Virtual Reality (VR) envisions supporting unconstrained mobility of the users in the virtual worlds, while at the same time constraining their physical movements inside VR setups through redirected walking. For enabling delivery of high data rate video content in real-time, the supporting wireless networks will leverage highly directional communication links that will "track" the users for maintaining the Line-of-Sight (LoS) connectivity. Recurrent Neural Networks (RNNs) and in particular Long Short-Term Memory (LSTM) networks have historically presented themselves as a suitable candidate for near-term movement trajectory prediction for natural human mobility, and have also recently been shown as applicable in predicting VR users' mobility under the constraints of redirected walking. In this work, we extend these initial findings by showing that Gated Recurrent Unit (GRU) networks, another candidate from the RNN family, generally outperform the traditionally utilized LSTMs. Second, we show that context from a virtual world can enhance the accuracy of the prediction if used as an additional input feature in comparison to the more traditional utilization of solely the historical physical movements of the VR users. Finally, we show that the prediction system trained on a static number of coexisting VR users be scaled to a multi-user system without significant accuracy degradation.
DLCFT: Deep Linear Continual Fine-Tuning for General Incremental Learning
Aug 17, 2022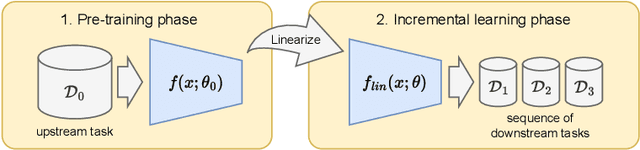
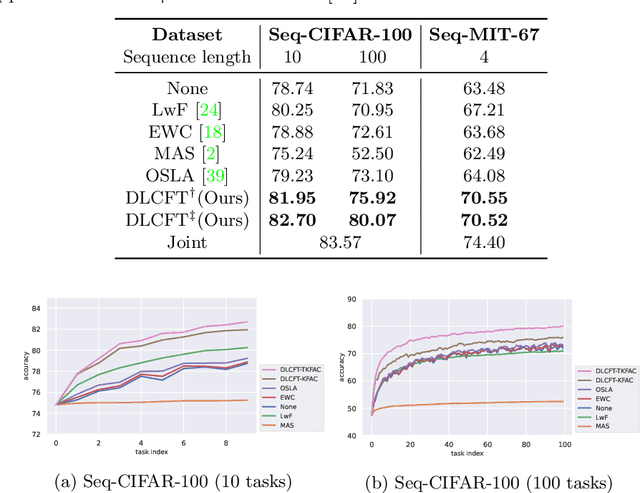
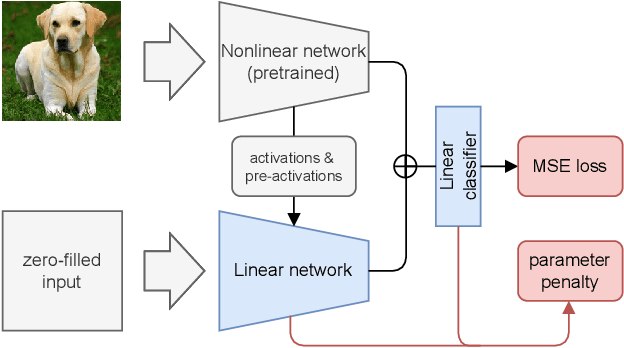
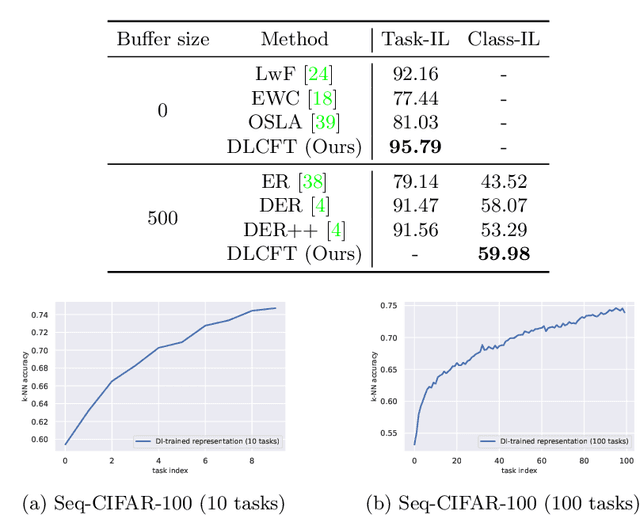
Pre-trained representation is one of the key elements in the success of modern deep learning. However, existing works on continual learning methods have mostly focused on learning models incrementally from scratch. In this paper, we explore an alternative framework to incremental learning where we continually fine-tune the model from a pre-trained representation. Our method takes advantage of linearization technique of a pre-trained neural network for simple and effective continual learning. We show that this allows us to design a linear model where quadratic parameter regularization method is placed as the optimal continual learning policy, and at the same time enjoying the high performance of neural networks. We also show that the proposed algorithm enables parameter regularization methods to be applied to class-incremental problems. Additionally, we provide a theoretical reason why the existing parameter-space regularization algorithms such as EWC underperform on neural networks trained with cross-entropy loss. We show that the proposed method can prevent forgetting while achieving high continual fine-tuning performance on image classification tasks. To show that our method can be applied to general continual learning settings, we evaluate our method in data-incremental, task-incremental, and class-incremental learning problems.
Probabilistic Time Series Forecasting with Implicit Quantile Networks
Jul 08, 2021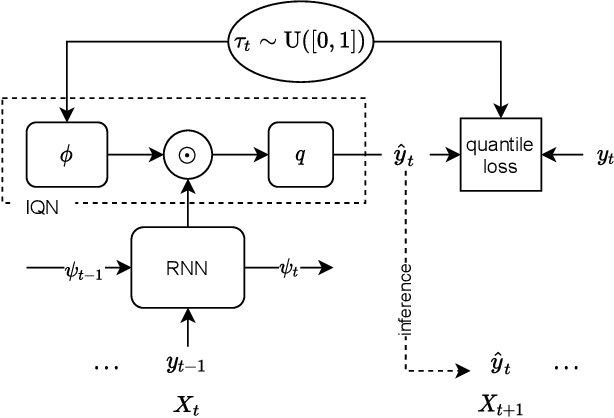
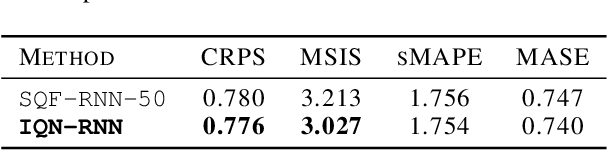
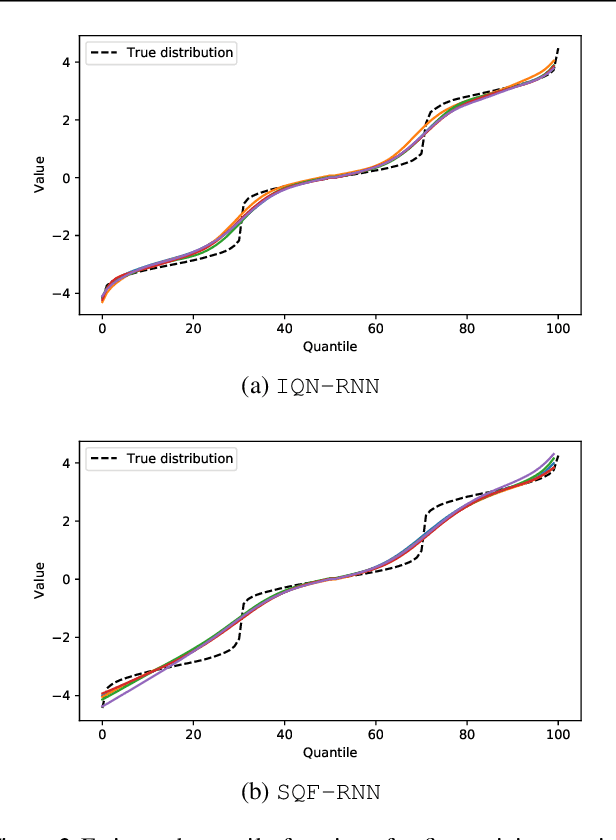
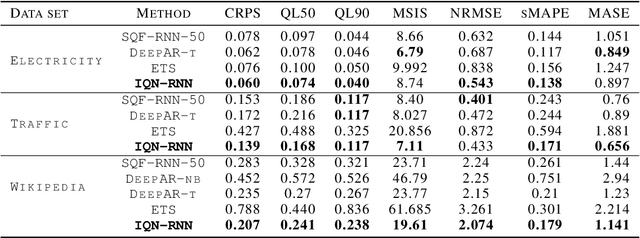
Here, we propose a general method for probabilistic time series forecasting. We combine an autoregressive recurrent neural network to model temporal dynamics with Implicit Quantile Networks to learn a large class of distributions over a time-series target. When compared to other probabilistic neural forecasting models on real- and simulated data, our approach is favorable in terms of point-wise prediction accuracy as well as on estimating the underlying temporal distribution.
Dimension of Activity in Random Neural Networks
Aug 07, 2022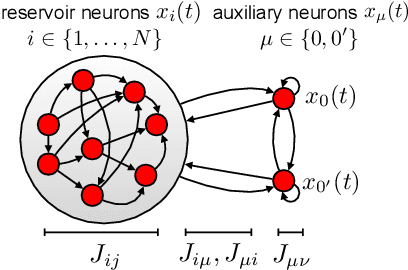
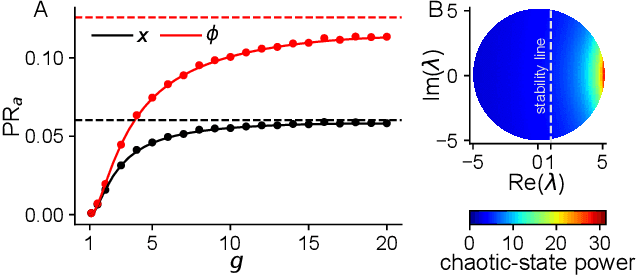
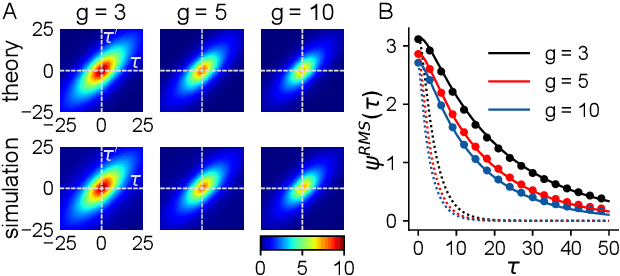
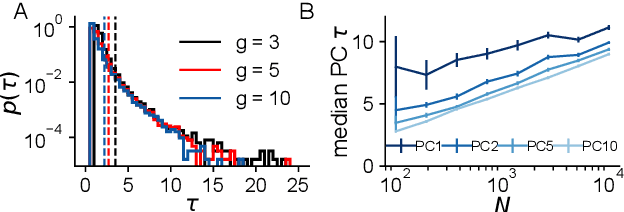
Neural networks are high-dimensional nonlinear dynamical systems that process information through the coordinated activity of many interconnected units. Understanding how biological and machine-learning networks function and learn requires knowledge of the structure of this coordinated activity, information contained in cross-covariances between units. Although dynamical mean field theory (DMFT) has elucidated several features of random neural networks -- in particular, that they can generate chaotic activity -- existing DMFT approaches do not support the calculation of cross-covariances. We solve this longstanding problem by extending the DMFT approach via a two-site cavity method. This reveals, for the first time, several spatial and temporal features of activity coordination, including the effective dimension, defined as the participation ratio of the spectrum of the covariance matrix. Our results provide a general analytical framework for studying the structure of collective activity in random neural networks and, more broadly, in high-dimensional nonlinear dynamical systems with quenched disorder.
Heteroscedastic Temporal Variational Autoencoder For Irregularly Sampled Time Series
Jul 23, 2021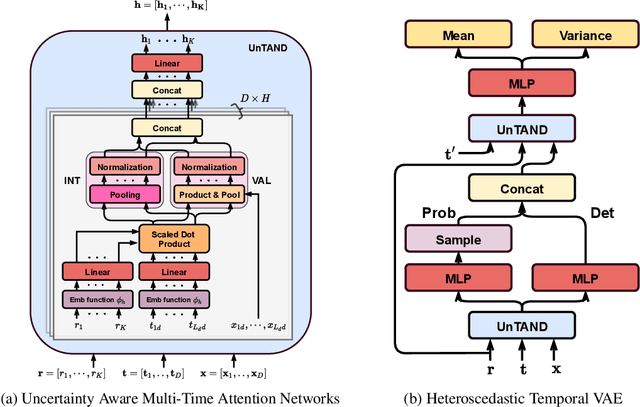
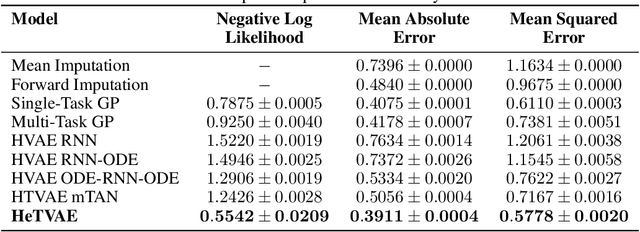
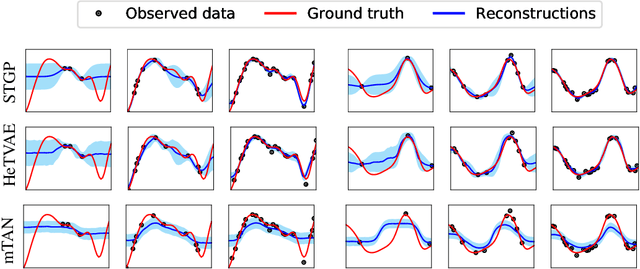
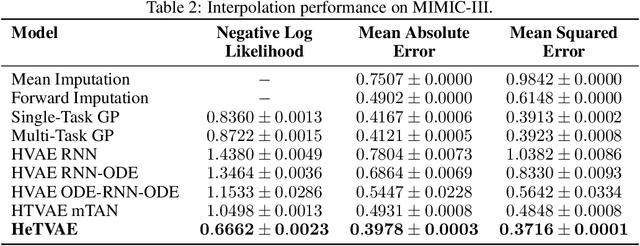
Irregularly sampled time series commonly occur in several domains where they present a significant challenge to standard deep learning models. In this paper, we propose a new deep learning framework for probabilistic interpolation of irregularly sampled time series that we call the Heteroscedastic Temporal Variational Autoencoder (HeTVAE). HeTVAE includes a novel input layer to encode information about input observation sparsity, a temporal VAE architecture to propagate uncertainty due to input sparsity, and a heteroscedastic output layer to enable variable uncertainty in output interpolations. Our results show that the proposed architecture is better able to reflect variable uncertainty through time due to sparse and irregular sampling than a range of baseline and traditional models, as well as recently proposed deep latent variable models that use homoscedastic output layers.
Semi-supervised Learning with Deterministic Labeling and Large Margin Projection
Aug 17, 2022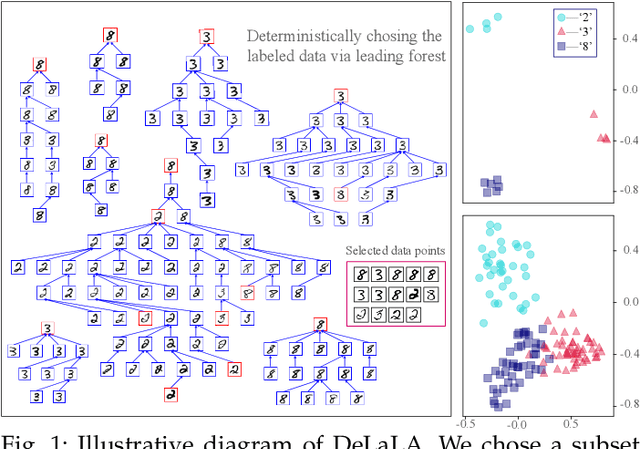
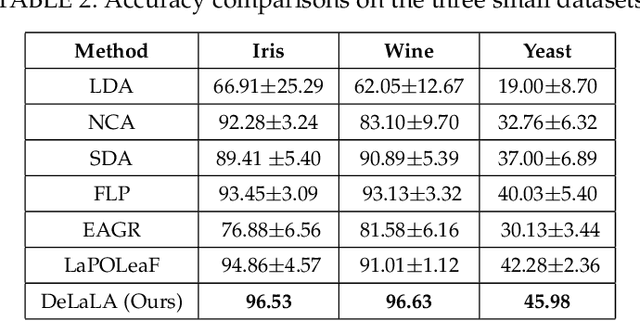
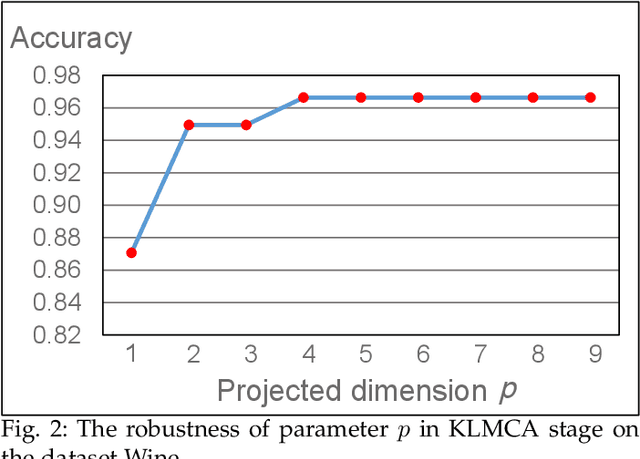
The centrality and diversity of the labeled data are very influential to the performance of semi-supervised learning (SSL), but most SSL models select the labeled data randomly. How to guarantee the centrality and diversity of the labeled data has so far received little research attention. Optimal leading forest (OLF) has been observed to have the advantage of revealing the difference evolution within a class when it was utilized to develop an SSL model. Our key intuition of this study is to learn a kernelized large margin metric for a small amount of most stable and most divergent data that are recognized based on the OLF structure. An optimization problem is formulated to achieve this goal. Also with OLF the multiple local metrics learning is facilitated to address multi-modal and mix-modal problem in SSL. Attribute to this novel design, the accuracy and performance stableness of the SSL model based on OLF is significantly improved compared with its baseline methods without sacrificing much efficiency. The experimental studies have shown that the proposed method achieved encouraging accuracy and running time when compared to the state-of-the-art graph SSL methods. Code has been made available at https://github.com/alanxuji/DeLaLA.
Hierarchical Motion Planning Framework for Cooperative Transportation of Multiple Mobile Manipulators
Aug 17, 2022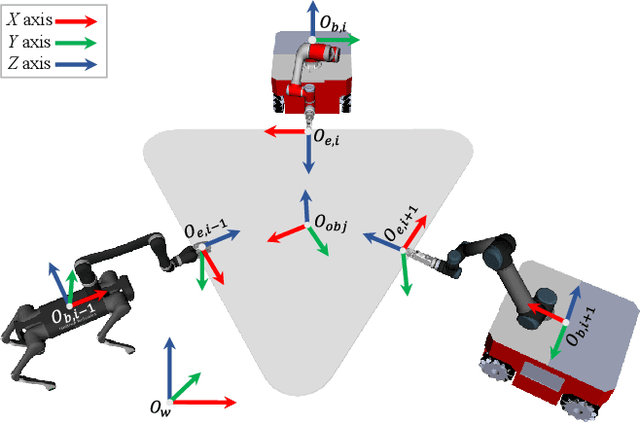



Multiple mobile manipulators show superiority in the tasks requiring mobility and dexterity compared with a single robot, especially when manipulating/transporting bulky objects. When the object and the manipulators are rigidly connected, closed-chain will form and the motion of the whole system will be restricted onto a lower-dimensional manifold. However, current research on multi-robot motion planning did not fully consider the formation of the whole system, the redundancy of the mobile manipulator and obstacles in the environment, which make the tasks challenging. Therefore, this paper proposes a hierarchical framework to efficiently solve the above challenges, where the centralized layer plans the object's motion offline and the decentralized layer independently explores the redundancy of each robot in real-time. In addition, closed-chain, obstacle-avoidance and the lower bound of the formation constraints are guaranteed in the centralized layer, which cannot be achieved simultaneously by other planners. Moreover, capability map, which represents the distribution of the formation constraint, is applied to speed up the two layers. Both simulation and experimental results show that the proposed framework outperforms the benchmark planners significantly. The system could bypass or cross obstacles in cluttered environments, and the framework can be applied to different numbers of heterogeneous mobile manipulators.