 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Generalized Beliefs for Cooperative AI
Jun 26, 2022
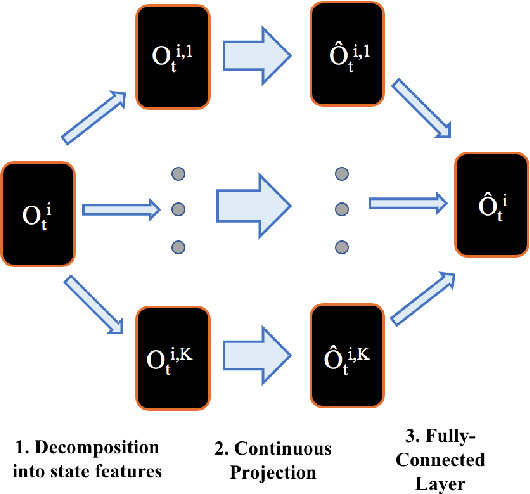
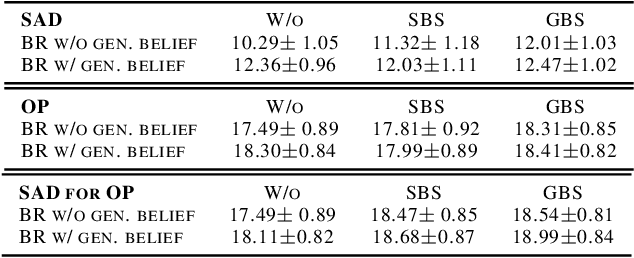
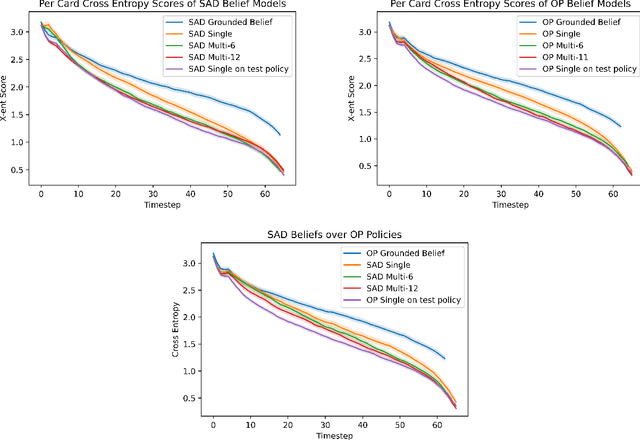

Self-play is a common paradigm for constructing solutions in Markov games that can yield optimal policies in collaborative settings. However, these policies often adopt highly-specialized conventions that make playing with a novel partner difficult. To address this, recent approaches rely on encoding symmetry and convention-awareness into policy training, but these require strong environmental assumptions and can complicate policy training. We therefore propose moving the learning of conventions to the belief space. Specifically, we propose a belief learning model that can maintain beliefs over rollouts of policies not seen at training time, and can thus decode and adapt to novel conventions at test time. We show how to leverage this model for both search and training of a best response over various pools of policies to greatly improve ad-hoc teamplay. We also show how our setup promotes explainability and interpretability of nuanced agent conventions.
AA3DNet: Attention Augmented Real Time 3D Object Detection
Aug 11, 2021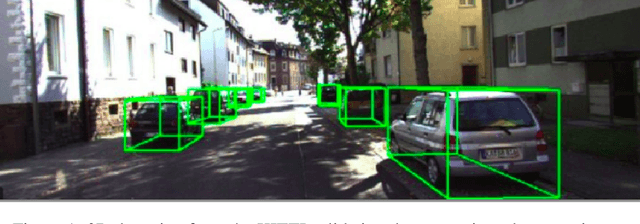
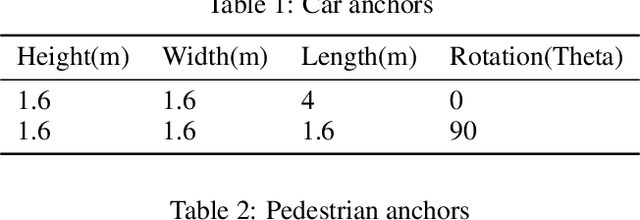
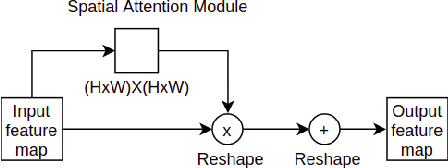
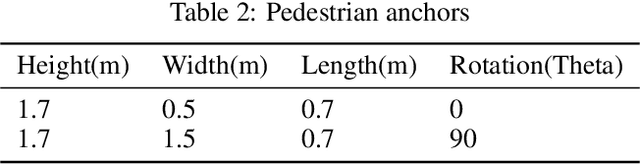
In this work, we address the problem of 3D object detection from point cloud data in real time. For autonomous vehicles to work, it is very important for the perception component to detect the real world objects with both high accuracy and fast inference. We propose a novel neural network architecture along with the training and optimization details for detecting 3D objects using point cloud data. We present anchor design along with custom loss functions used in this work. A combination of spatial and channel wise attention module is used in this work. We use the Kitti 3D Birds Eye View dataset for benchmarking and validating our results. Our method surpasses previous state of the art in this domain both in terms of average precision and speed running at > 30 FPS. Finally, we present the ablation study to demonstrate that the performance of our network is generalizable. This makes it a feasible option to be deployed in real time applications like self driving cars.
Waveform Design and Hybrid Duplex Exploiting Radar Features for Joint Communication and Sensing
Jul 07, 2022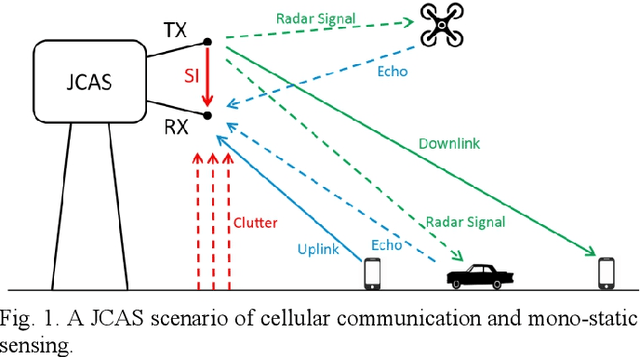
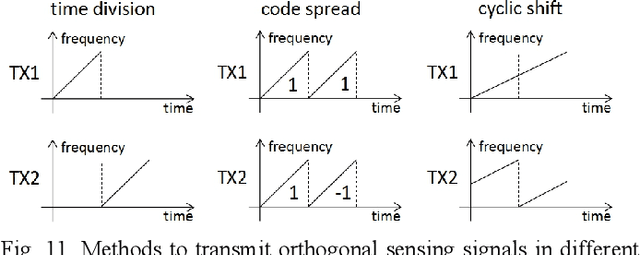
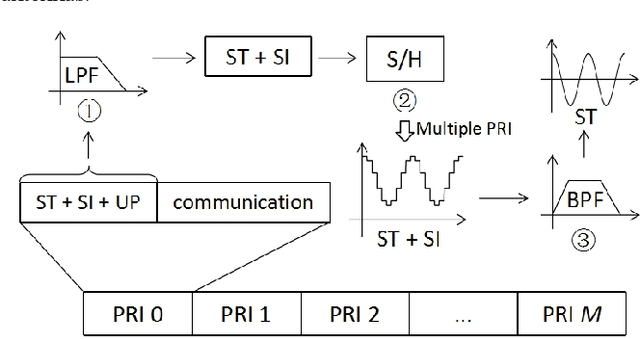
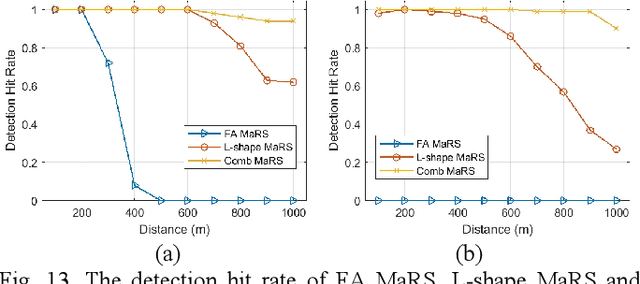
Joint communication and sensing (JCAS) is a very promising 6G technology, which attracts more and more research attention. Unlike communication, radar has many unique features in terms of waveform criteria, self-interference cancellation (SIC), aperture-dependent resolution, and virtual aperture. This paper proposes a waveform design named max-aperture radar slicing (MaRS) to gain a large time-frequency aperture, which reuses the orthogonal frequency division multiplexing (OFDM) hardware and occupies only a tiny fraction of OFDM resources. The proposed MaRS keeps the radar advantages of constant modulus, zero auto-correlation, and simple SIC. Joint space-time processing algorithms are proposed to recover the range-velocity-angle information from strong clutters. Furthermore, this paper proposes a hybrid-duplex JCAS scheme where communication is half-duplex while radar is full-duplex. In this scheme, the half-duplex communication antenna array is reused, and a small sensing-dedicated antenna array is specially designed. Using these two arrays, a large space-domain aperture is virtually formed to greatly improve the angle resolution. The numerical results show that the proposed MaRS and hybrid-duplex schemes achieve a high sensing resolution with less than 0.4% OFDM resources and gain an almost 100% hit rate for both car and UAV detection at a range up to 1 km.
Training Latent Variable Models with Auto-encoding Variational Bayes: A Tutorial
Aug 16, 2022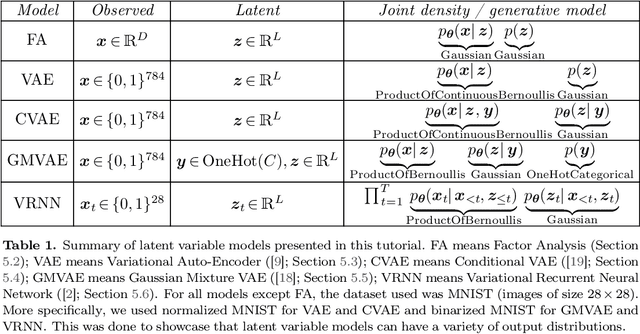
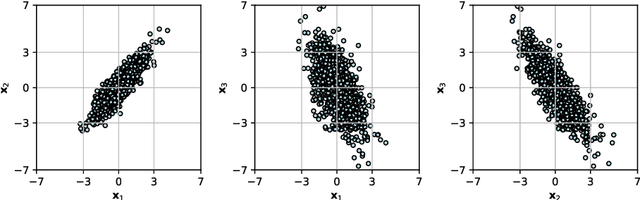
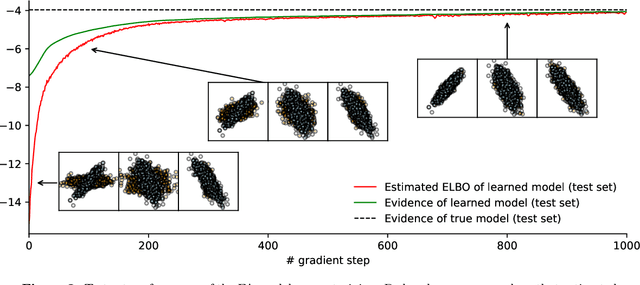
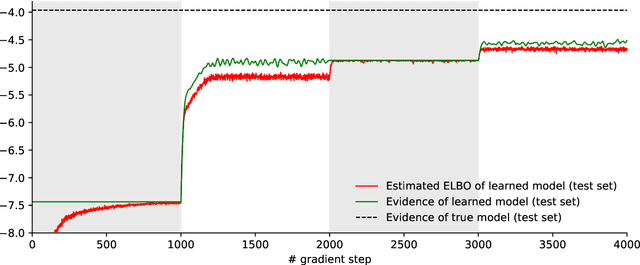
Auto-encoding Variational Bayes (AEVB) is a powerful and general algorithm for fitting latent variable models (a promising direction for unsupervised learning), and is well-known for training the Variational Auto-Encoder (VAE). In this tutorial, we focus on motivating AEVB from the classic Expectation Maximization (EM) algorithm, as opposed to from deterministic auto-encoders. Though natural and somewhat self-evident, the connection between EM and AEVB is not emphasized in the recent deep learning literature, and we believe that emphasizing this connection can improve the community's understanding of AEVB. In particular, we find it especially helpful to view (1) optimizing the evidence lower bound (ELBO) with respect to inference parameters as approximate E-step and (2) optimizing ELBO with respect to generative parameters as approximate M-step; doing both simultaneously as in AEVB is then simply tightening and pushing up ELBO at the same time. We discuss how approximate E-step can be interpreted as performing variational inference. Important concepts such as amortization and the reparametrization trick are discussed in great detail. Finally, we derive from scratch the AEVB training procedures of a non-deep and several deep latent variable models, including VAE, Conditional VAE, Gaussian Mixture VAE and Variational RNN. It is our hope that readers would recognize AEVB as a general algorithm that can be used to fit a wide range of latent variable models (not just VAE), and apply AEVB to such models that arise in their own fields of research. PyTorch code for all included models are publicly available.
Robust Contact State Estimation in Humanoid Walking Gaits
Jul 30, 2022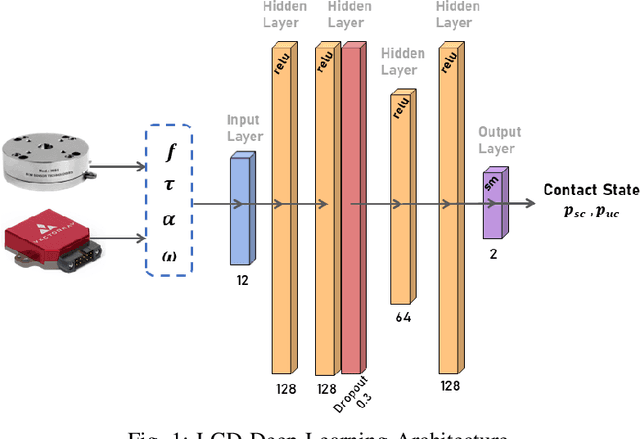
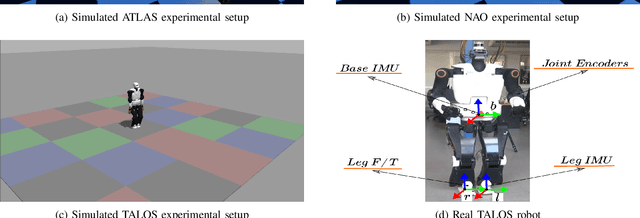

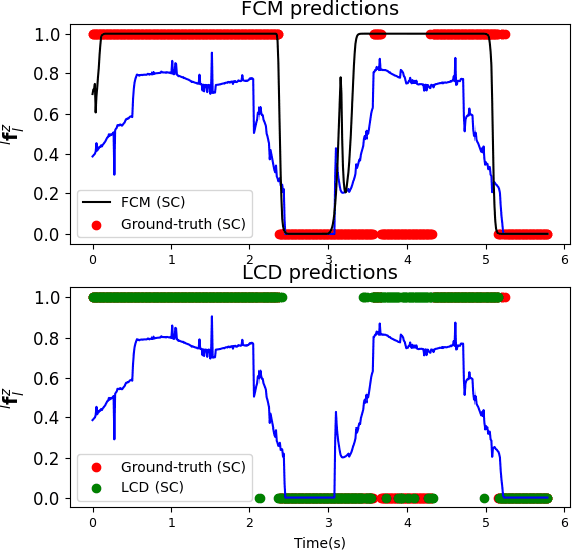
In this article, we propose a deep learning framework that provides a unified approach to the problem of leg contact detection in humanoid robot walking gaits. Our formulation accomplishes to accurately and robustly estimate the contact state probability for each leg (i.e., stable or slip/no contact). The proposed framework employs solely proprioceptive sensing and although it relies on simulated ground-truth contact data for the classification process, we demonstrate that it generalizes across varying friction surfaces and different legged robotic platforms and, at the same time, is readily transferred from simulation to practice. The framework is quantitatively and qualitatively assessed in simulation via the use of ground-truth contact data and is contrasted against state of-the-art methods with an ATLAS, a NAO, and a TALOS humanoid robot. Furthermore, its efficacy is demonstrated in base estimation with a real TALOS humanoid. To reinforce further research endeavors, our implementation is offered as an open-source ROS/Python package, coined Legged Contact Detection (LCD).
An Empirical Study of Quantum Dynamics as a Ground State Problem with Neural Quantum States
Jun 18, 2022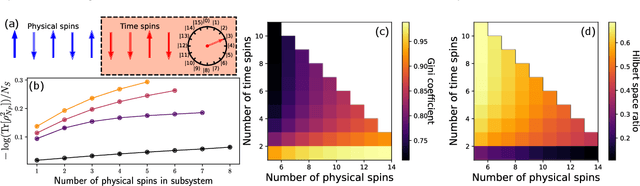
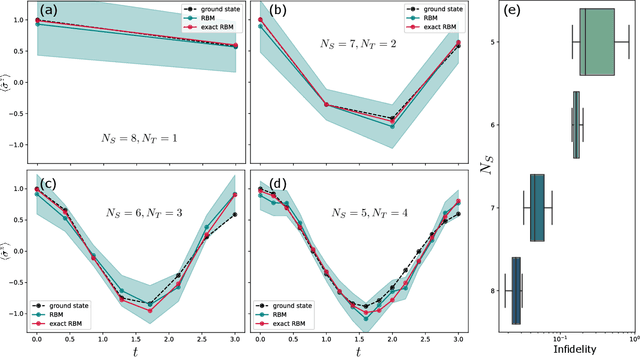

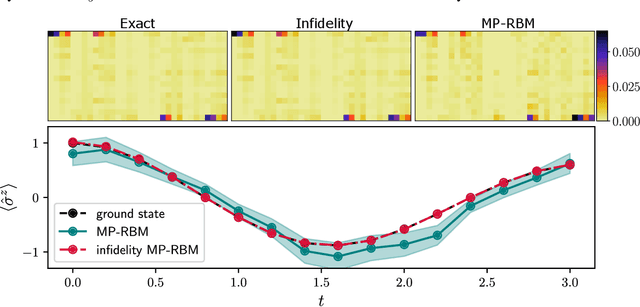
Neural quantum states are variational wave functions parameterised by artificial neural networks, a mathematical model studied for decades in the machine learning community. In the context of many-body physics, methods such as variational Monte Carlo with neural quantum states as variational wave functions are successful in approximating, with great accuracy, the ground-state of a quantum Hamiltonian. However, all the difficulties of proposing neural network architectures, along with exploring their expressivity and trainability, permeate their application as neural quantum states. In this paper, we consider the Feynman-Kitaev Hamiltonian for the transverse field Ising model, whose ground state encodes the time evolution of a spin chain at discrete time steps. We show how this ground state problem specifically challenges the neural quantum state trainability as the time steps increase because the true ground state becomes more entangled, and the probability distribution starts to spread across the Hilbert space. Our results indicate that the considered neural quantum states are capable of accurately approximating the true ground state of the system, i.e., they are expressive enough. However, extensive hyper-parameter tuning experiments point towards the empirical fact that it is poor trainability--in the variational Monte Carlo setup--that prevents a faithful approximation of the true ground state.
Asymptotic Tracking Control of Uncertain MIMO Nonlinear Systems with Less Conservative Controllability Conditions
Aug 03, 2022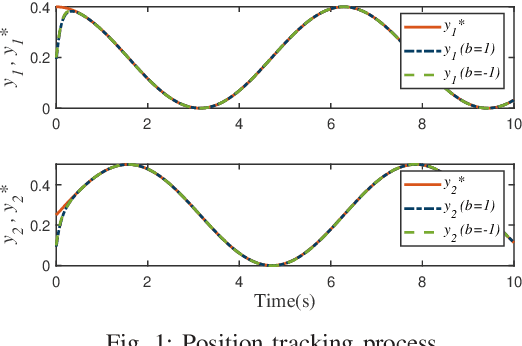
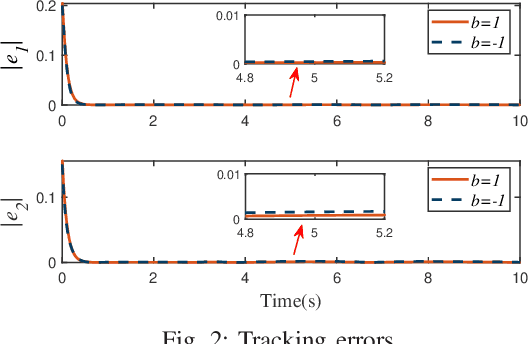
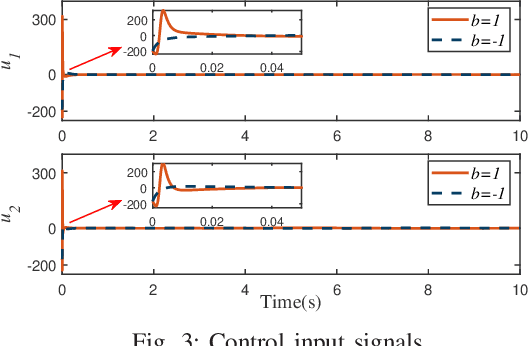
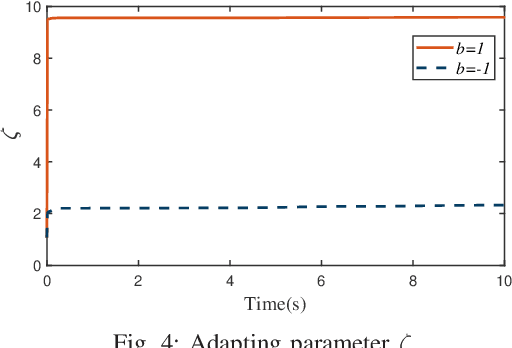
For uncertain multiple inputs multi-outputs (MIMO) nonlinear systems, it is nontrivial to achieve asymptotic tracking, and most existing methods normally demand certain controllability conditions that are rather restrictive or even impractical if unexpected actuator faults are involved. In this note, we present a method capable of achieving zero-error steady-state tracking with less conservative (more practical) controllability condition. By incorporating a novel Nussbaum gain technique and some positive integrable function into the control design, we develop a robust adaptive asymptotic tracking control scheme for the system with time-varying control gain being unknown its magnitude and direction. By resorting to the existence of some feasible auxiliary matrix, the current state-of-art controllability condition is further relaxed, which enlarges the class of systems that can be considered in the proposed control scheme. All the closed-loop signals are ensured to be globally ultimately uniformly bounded. Moreover, such control methodology is further extended to the case involving intermittent actuator faults, with application to robotic systems. Finally, simulation studies are carried out to demonstrate the effectiveness and flexibility of this method.
A comprehensive survey on computer-aided diagnostic systems in diabetic retinopathy screening
Aug 03, 2022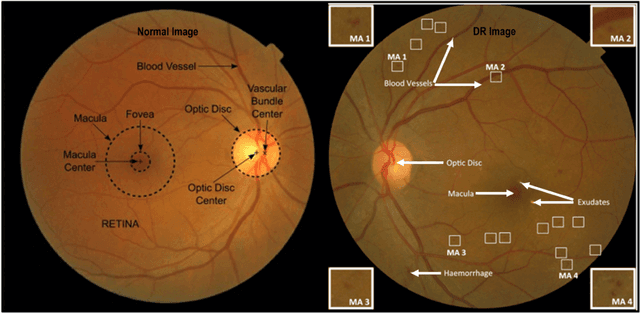

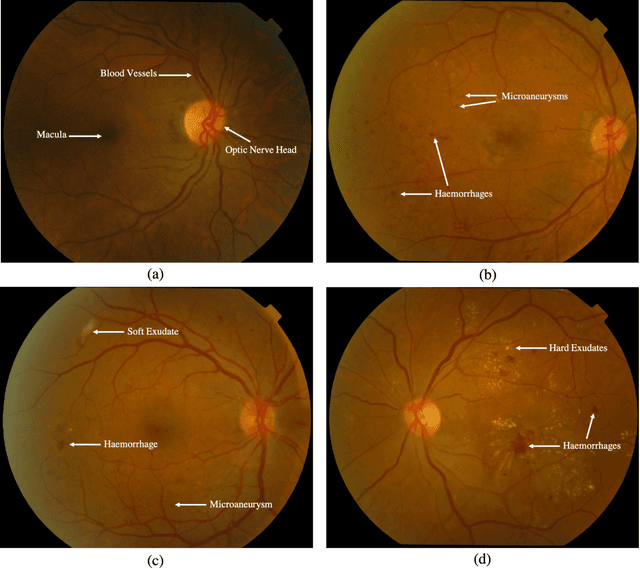
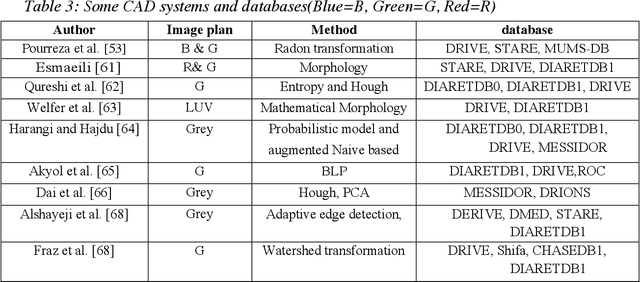
Diabetes Mellitus (DM) can lead to significant microvasculature disruptions that eventually causes diabetic retinopathy (DR), or complications in the eye due to diabetes. If left unchecked, this disease can increase over time and eventually cause complete vision loss. The general method to detect such optical developments is through examining the vessels, optic nerve head, microaneurysms, haemorrhage, exudates, etc. from retinal images. Ultimately this is limited by the number of experienced ophthalmologists and the vastly growing number of DM cases. To enable earlier and efficient DR diagnosis, the field of ophthalmology requires robust computer aided diagnosis (CAD) systems. Our review is intended for anyone, from student to established researcher, who wants to understand what can be accomplished with CAD systems and their algorithms to modeling and where the field of retinal image processing in computer vision and pattern recognition is headed. For someone just getting started, we place a special emphasis on the logic, strengths and shortcomings of different databases and algorithms frameworks with a focus on very recent approaches.
* 65 pages, 7 figures, 9 tables
Geometric deep learning for computational mechanics Part II: Graph embedding for interpretable multiscale plasticity
Jul 30, 2022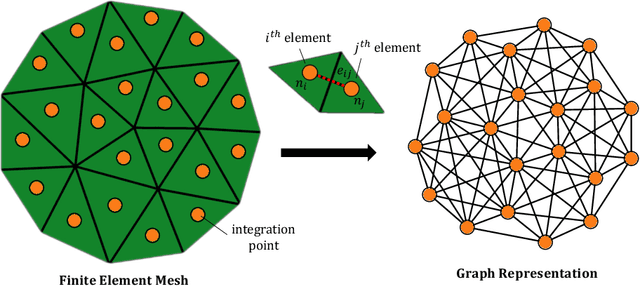
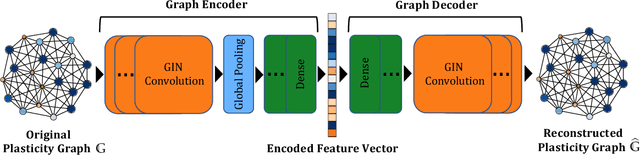

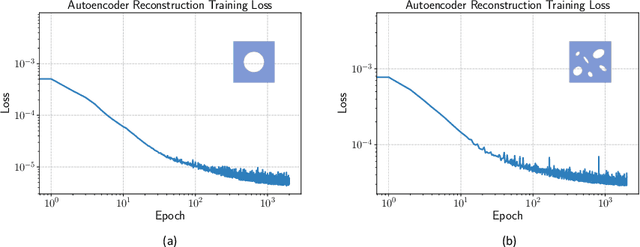
The history-dependent behaviors of classical plasticity models are often driven by internal variables evolved according to phenomenological laws. The difficulty to interpret how these internal variables represent a history of deformation, the lack of direct measurement of these internal variables for calibration and validation, and the weak physical underpinning of those phenomenological laws have long been criticized as barriers to creating realistic models. In this work, geometric machine learning on graph data (e.g. finite element solutions) is used as a means to establish a connection between nonlinear dimensional reduction techniques and plasticity models. Geometric learning-based encoding on graphs allows the embedding of rich time-history data onto a low-dimensional Euclidean space such that the evolution of plastic deformation can be predicted in the embedded feature space. A corresponding decoder can then convert these low-dimensional internal variables back into a weighted graph such that the dominating topological features of plastic deformation can be observed and analyzed.
Wave simulation in non-smooth media by PINN with quadratic neural network and PML condition
Aug 16, 2022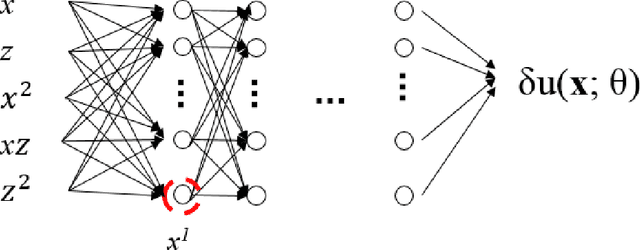
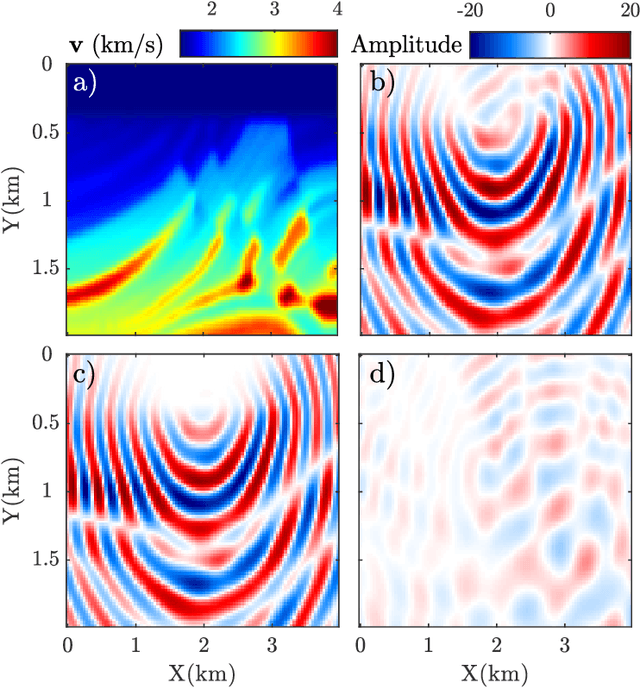
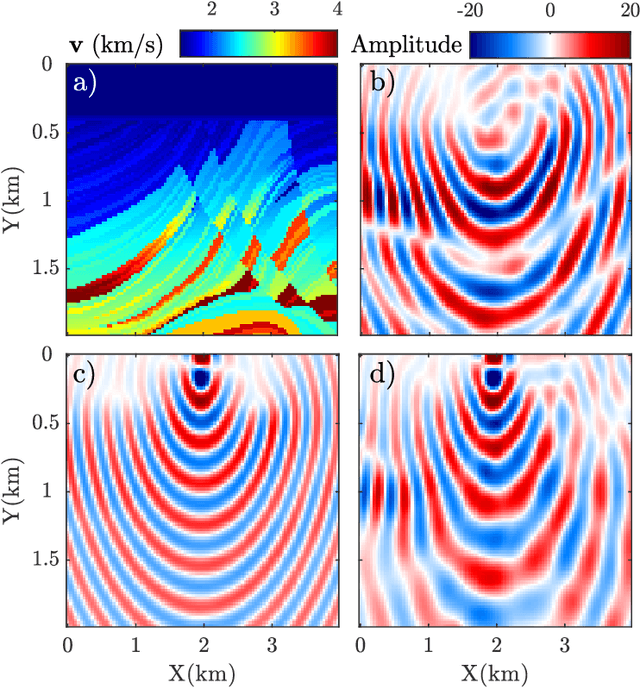
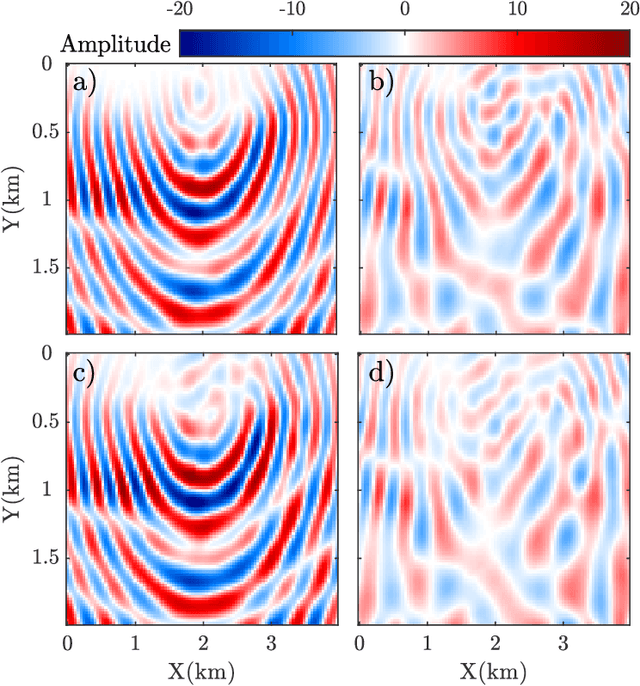
Frequency-domain simulation of seismic waves plays an important role in seismic inversion, but it remains challenging in large models. The recently proposed physics-informed neural network (PINN), as an effective deep learning method, has achieved successful applications in solving a wide range of partial differential equations (PDEs), and there is still room for improvement on this front. For example, PINN can lead to inaccurate solutions when PDE coefficients are non-smooth and describe structurally-complex media. In this paper, we solve the acoustic and visco-acoustic scattered-field wave equation in the frequency domain with PINN instead of the wave equation to remove source singularity. We first illustrate that non-smooth velocity models lead to inaccurate wavefields when no boundary conditions are implemented in the loss function. Then, we add the perfectly matched layer (PML) conditions in the loss function of PINN and design a quadratic neural network to overcome the detrimental effects of non-smooth models in PINN. We show that PML and quadratic neurons improve the results as well as attenuation and discuss the reason for this improvement. We also illustrate that a network trained during a wavefield simulation can be used to pre-train the neural network of another wavefield simulation after PDE-coefficient alteration and improve the convergence speed accordingly. This pre-training strategy should find application in iterative full waveform inversion (FWI) and time-lag target-oriented imaging when the model perturbation between two consecutive iterations or two consecutive experiments can be small.