 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
N2NSkip: Learning Highly Sparse Networks using Neuron-to-Neuron Skip Connections
Aug 07, 2022
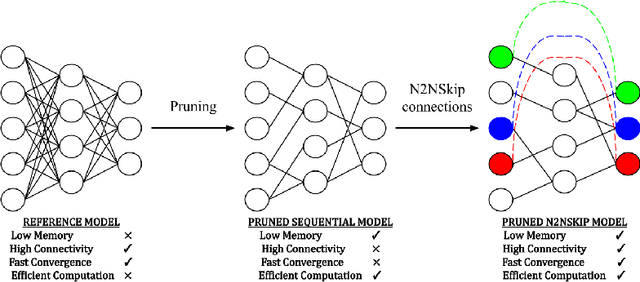
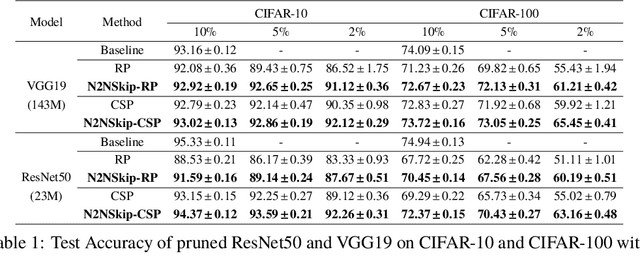
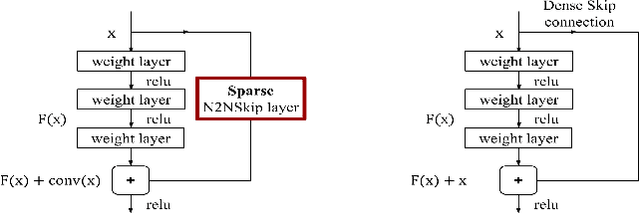

The over-parametrized nature of Deep Neural Networks leads to considerable hindrances during deployment on low-end devices with time and space constraints. Network pruning strategies that sparsify DNNs using iterative prune-train schemes are often computationally expensive. As a result, techniques that prune at initialization, prior to training, have become increasingly popular. In this work, we propose neuron-to-neuron skip connections, which act as sparse weighted skip connections, to enhance the overall connectivity of pruned DNNs. Following a preliminary pruning step, N2NSkip connections are randomly added between individual neurons/channels of the pruned network, while maintaining the overall sparsity of the network. We demonstrate that introducing N2NSkip connections in pruned networks enables significantly superior performance, especially at high sparsity levels, as compared to pruned networks without N2NSkip connections. Additionally, we present a heat diffusion-based connectivity analysis to quantitatively determine the connectivity of the pruned network with respect to the reference network. We evaluate the efficacy of our approach on two different preliminary pruning methods which prune at initialization, and consistently obtain superior performance by exploiting the enhanced connectivity resulting from N2NSkip connections.
ParaColorizer: Realistic Image Colorization using Parallel Generative Networks
Aug 17, 2022


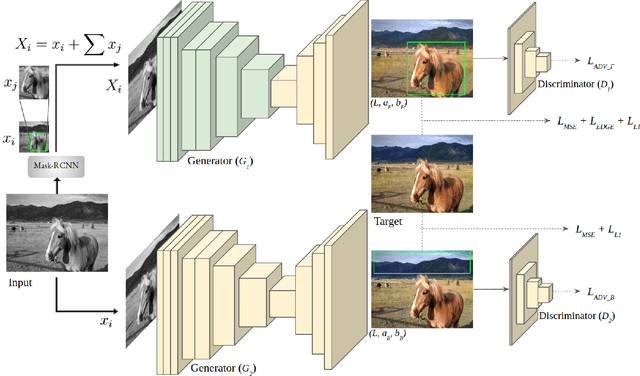
Grayscale image colorization is a fascinating application of AI for information restoration. The inherently ill-posed nature of the problem makes it even more challenging since the outputs could be multi-modal. The learning-based methods currently in use produce acceptable results for straightforward cases but usually fail to restore the contextual information in the absence of clear figure-ground separation. Also, the images suffer from color bleeding and desaturated backgrounds since a single model trained on full image features is insufficient for learning the diverse data modes. To address these issues, we present a parallel GAN-based colorization framework. In our approach, each separately tailored GAN pipeline colorizes the foreground (using object-level features) or the background (using full-image features). The foreground pipeline employs a Residual-UNet with self-attention as its generator trained using the full-image features and the corresponding object-level features from the COCO dataset. The background pipeline relies on full-image features and additional training examples from the Places dataset. We design a DenseFuse-based fusion network to obtain the final colorized image by feature-based fusion of the parallelly generated outputs. We show the shortcomings of the non-perceptual evaluation metrics commonly used to assess multi-modal problems like image colorization and perform extensive performance evaluation of our framework using multiple perceptual metrics. Our approach outperforms most of the existing learning-based methods and produces results comparable to the state-of-the-art. Further, we performed a runtime analysis and obtained an average inference time of 24ms per image.
CCRL: Contrastive Cell Representation Learning
Aug 12, 2022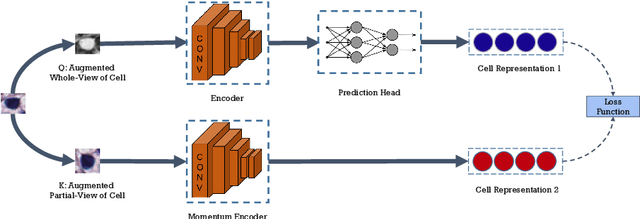
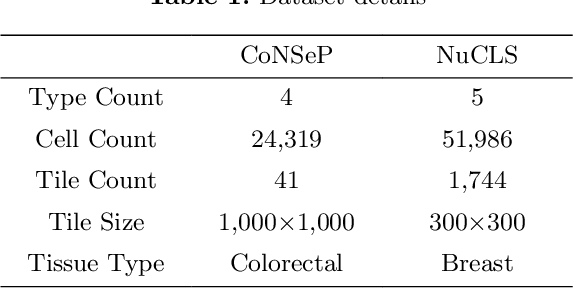
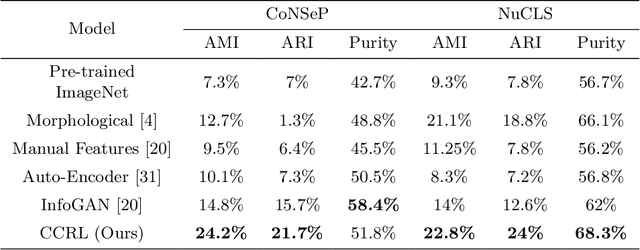
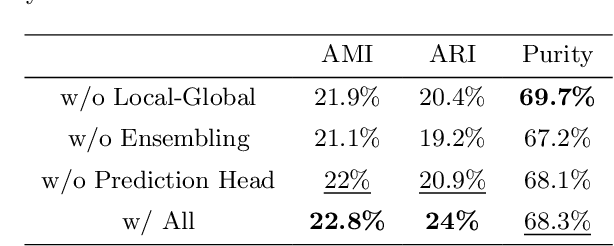
Cell identification within the H&E slides is an essential prerequisite that can pave the way towards further pathology analyses including tissue classification, cancer grading, and phenotype prediction. However, performing such a task using deep learning techniques requires a large cell-level annotated dataset. Although previous studies have investigated the performance of contrastive self-supervised methods in tissue classification, the utility of this class of algorithms in cell identification and clustering is still unknown. In this work, we investigated the utility of Self-Supervised Learning (SSL) in cell clustering by proposing the Contrastive Cell Representation Learning (CCRL) model. Through comprehensive comparisons, we show that this model can outperform all currently available cell clustering models by a large margin across two datasets from different tissue types. More interestingly, the results show that our proposed model worked well with a few number of cell categories while the utility of SSL models has been mainly shown in the context of natural image datasets with large numbers of classes (e.g., ImageNet). The unsupervised representation learning approach proposed in this research eliminates the time-consuming step of data annotation in cell classification tasks, which enables us to train our model on a much larger dataset compared to previous methods. Therefore, considering the promising outcome, this approach can open a new avenue to automatic cell representation learning.
A Physics-based Domain Adaptation framework for modelling and forecasting building energy systems
Aug 19, 2022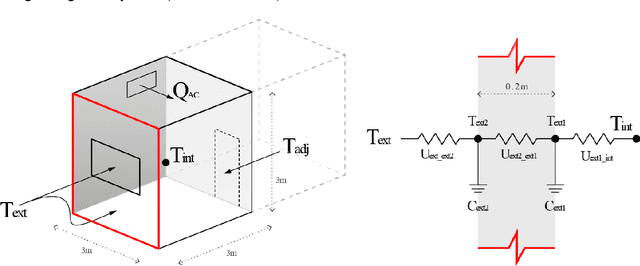

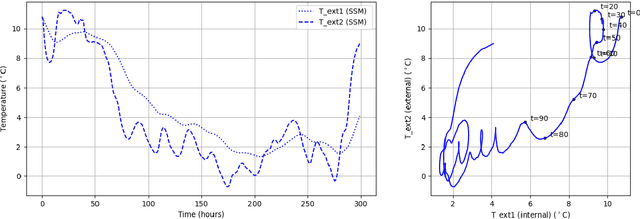

State-of-the-art machine-learning based models are a popular choice for modelling and forecasting energy behaviour in buildings because given enough data, they are good at finding spatiotemporal patterns and structures even in scenarios where the complexity prohibits analytical descriptions. However, machine-learning based models for building energy forecasting have difficulty generalizing to out-of-sample scenarios that are not represented in the data because their architecture typically does not hold physical correspondence to mechanistic structures linked with governing phenomena of energy transfer. Thus, their ability to forecast for unseen initial conditions and boundary conditions wholly depends on the representativeness in the data, which is not guaranteed in building measurement data. Consequently, these limitations impede their application to real-world engineering applications such as energy management in Digital Twins. In response, we present a Domain Adaptation framework that aims to leverage well-known understanding of phenomenon governing energy behavior in buildings to forecast for out of sample scenarios beyond building measurement data. More specifically, we represent mechanistic knowledge of energy behavior using low-rank linear time-invariant state space models and subsequently leverage their governing structure to forecast for a target energy system for which only building measurement data is available. We achieve this by aligning the Physics-derived subspace that governs global state space behavior closer towards the target subspace derived from the measurement data. In this initial exploration we focus on linear energy systems; we test the subspace-based DA framework on a 1D heat conduction scenario by varying the thermophysical properties of the source and target systems to demonstrate the transferability of mechanistic models from Physics to measurement data.
Metal artifact correction in cone beam computed tomography using synthetic X-ray data
Aug 17, 2022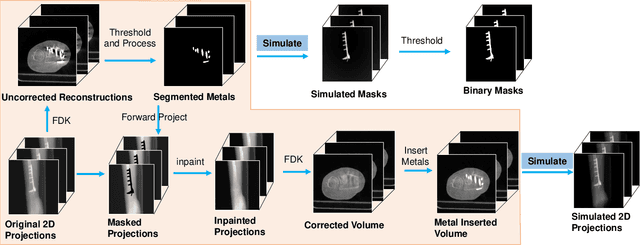
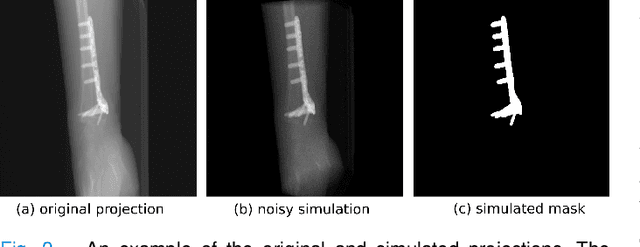
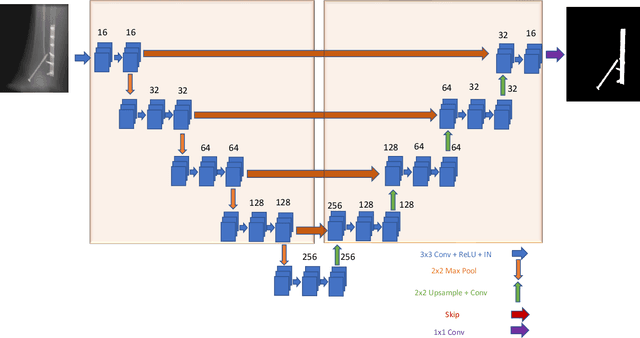
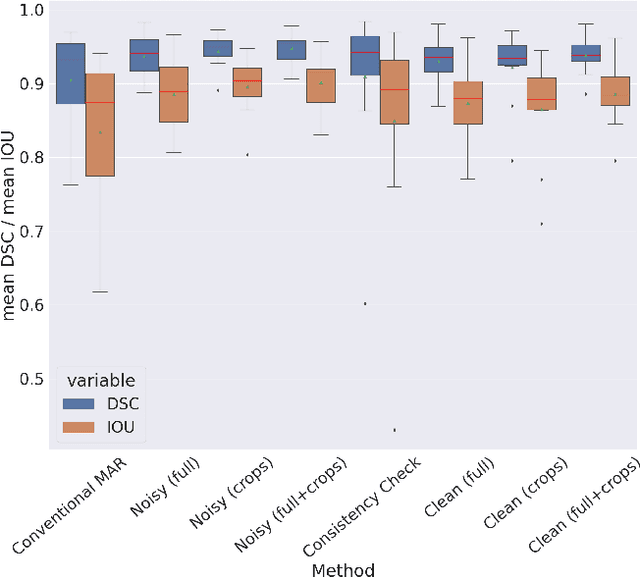
Metal artifact correction is a challenging problem in cone beam computed tomography (CBCT) scanning. Metal implants inserted into the anatomy cause severe artifacts in reconstructed images. Widely used inpainting-based metal artifact reduction (MAR) methods require segmentation of metal traces in the projections as a first step which is a challenging task. One approach is to use a deep learning method to segment metals in the projections. However, the success of deep learning methods is limited by the availability of realistic training data. It is challenging and time consuming to get reliable ground truth annotations due to unclear implant boundary and large number of projections. We propose to use X-ray simulations to generate synthetic metal segmentation training dataset from clinical CBCT scans. We compare the effect of simulations with different number of photons and also compare several training strategies to augment the available data. We compare our model's performance on real clinical scans with conventional threshold-based MAR and a recent deep learning method. We show that simulations with relatively small number of photons are suitable for the metal segmentation task and that training the deep learning model with full size and cropped projections together improves the robustness of the model. We show substantial improvement in the image quality affected by severe motion, voxel size under-sampling, and out-of-FOV metals. Our method can be easily implemented into the existing projection-based MAR pipeline to get improved image quality. This method can provide a novel paradigm to accurately segment metals in CBCT projections.
Efficient Adversarial Training With Data Pruning
Jul 01, 2022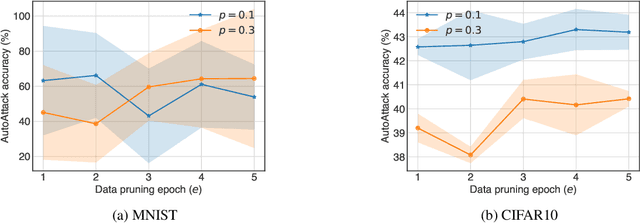
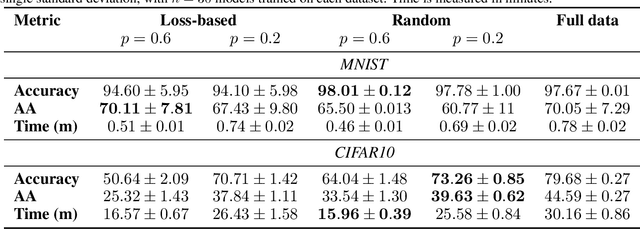
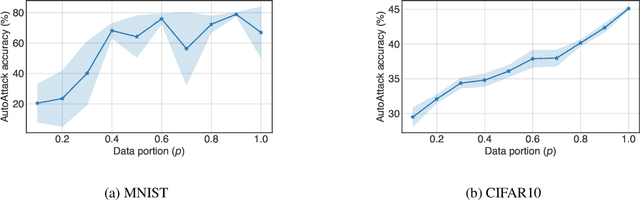

Neural networks are susceptible to adversarial examples-small input perturbations that cause models to fail. Adversarial training is one of the solutions that stops adversarial examples; models are exposed to attacks during training and learn to be resilient to them. Yet, such a procedure is currently expensive-it takes a long time to produce and train models with adversarial samples, and, what is worse, it occasionally fails. In this paper we demonstrate data pruning-a method for increasing adversarial training efficiency through data sub-sampling.We empirically show that data pruning leads to improvements in convergence and reliability of adversarial training, albeit with different levels of utility degradation. For example, we observe that using random sub-sampling of CIFAR10 to drop 40% of data, we lose 8% adversarial accuracy against the strongest attackers, while by using only 20% of data we lose 14% adversarial accuracy and reduce runtime by a factor of 3. Interestingly, we discover that in some settings data pruning brings benefits from both worlds-it both improves adversarial accuracy and training time.
Automatic Landmark Detection and Registration of Brain Cortical Surfaces via Quasi-Conformal Geometry and Convolutional Neural Networks
Aug 15, 2022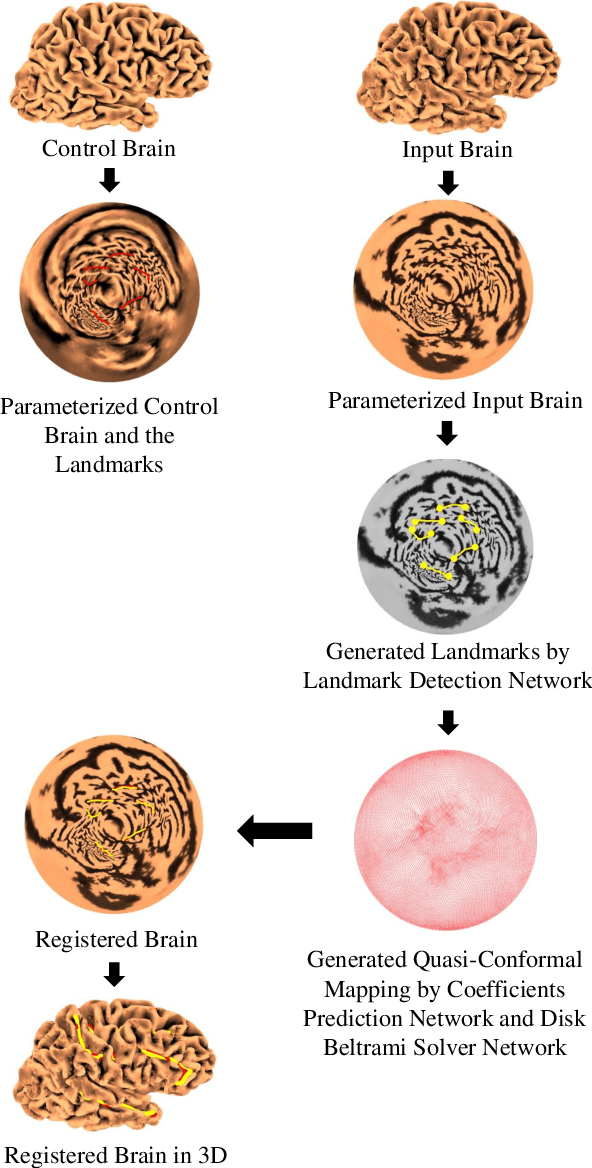

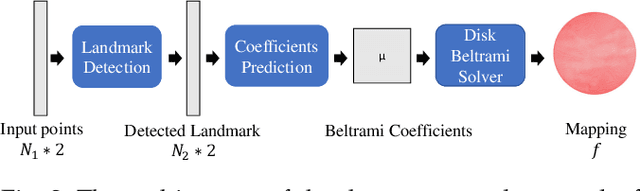

In medical imaging, surface registration is extensively used for performing systematic comparisons between anatomical structures, with a prime example being the highly convoluted brain cortical surfaces. To obtain a meaningful registration, a common approach is to identify prominent features on the surfaces and establish a low-distortion mapping between them with the feature correspondence encoded as landmark constraints. Prior registration works have primarily focused on using manually labeled landmarks and solving highly nonlinear optimization problems, which are time-consuming and hence hinder practical applications. In this work, we propose a novel framework for the automatic landmark detection and registration of brain cortical surfaces using quasi-conformal geometry and convolutional neural networks. We first develop a landmark detection network (LD-Net) that allows for the automatic extraction of landmark curves given two prescribed starting and ending points based on the surface geometry. We then utilize the detected landmarks and quasi-conformal theory for achieving the surface registration. Specifically, we develop a coefficient prediction network (CP-Net) for predicting the Beltrami coefficients associated with the desired landmark-based registration and a mapping network called the disk Beltrami solver network (DBS-Net) for generating quasi-conformal mappings from the predicted Beltrami coefficients, with the bijectivity guaranteed by quasi-conformal theory. Experimental results are presented to demonstrate the effectiveness of our proposed framework. Altogether, our work paves a new way for surface-based morphometry and medical shape analysis.
SST-Calib: Simultaneous Spatial-Temporal Parameter Calibration between LIDAR and Camera
Jul 08, 2022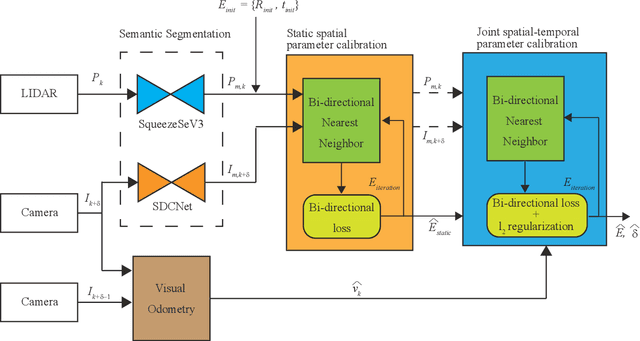
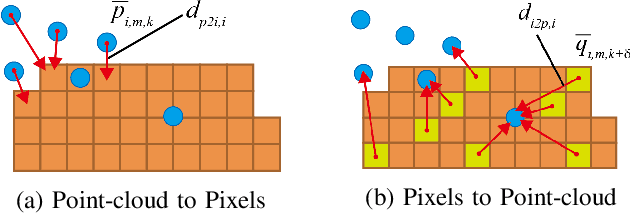

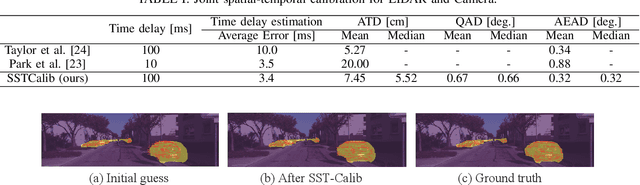
With information from multiple input modalities, sensor fusion-based algorithms usually out-perform their single-modality counterparts in robotics. Camera and LIDAR, with complementary semantic and depth information, are the typical choices for detection tasks in complicated driving environments. For most camera-LIDAR fusion algorithms, however, the calibration of the sensor suite will greatly impact the performance. More specifically, the detection algorithm usually requires an accurate geometric relationship among multiple sensors as the input, and it is often assumed that the contents from these sensors are captured at the same time. Preparing such sensor suites involves carefully designed calibration rigs and accurate synchronization mechanisms, and the preparation process is usually done offline. In this work, a segmentation-based framework is proposed to jointly estimate the geometrical and temporal parameters in the calibration of a camera-LIDAR suite. A semantic segmentation mask is first applied to both sensor modalities, and the calibration parameters are optimized through pixel-wise bidirectional loss. We specifically incorporated the velocity information from optical flow for temporal parameters. Since supervision is only performed at the segmentation level, no calibration label is needed within the framework. The proposed algorithm is tested on the KITTI dataset, and the result shows an accurate real-time calibration of both geometric and temporal parameters.
Scaling up Continuous-Time Markov Chains Helps Resolve Underspecification
Jul 06, 2021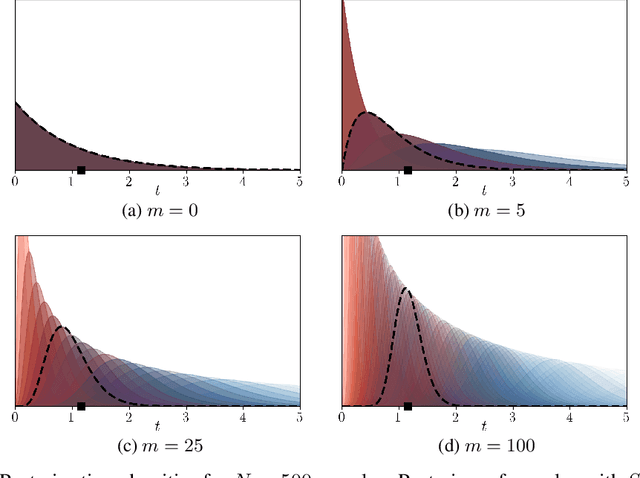
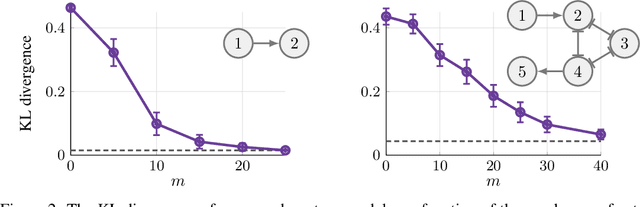
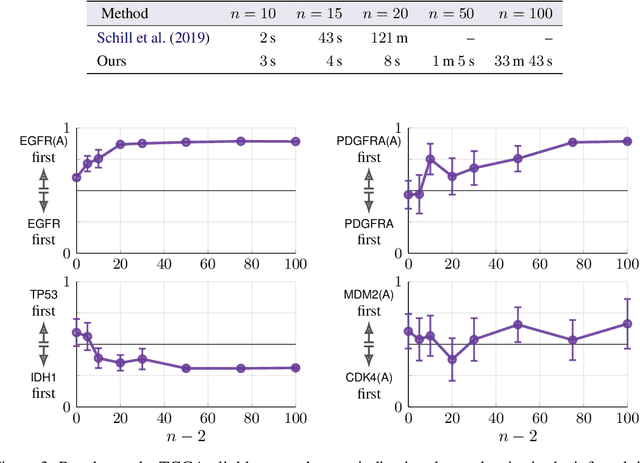
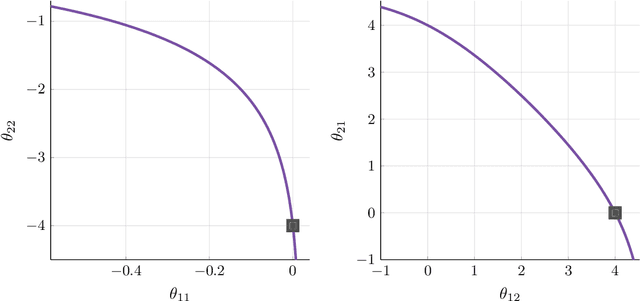
Modeling the time evolution of discrete sets of items (e.g., genetic mutations) is a fundamental problem in many biomedical applications. We approach this problem through the lens of continuous-time Markov chains, and show that the resulting learning task is generally underspecified in the usual setting of cross-sectional data. We explore a perhaps surprising remedy: including a number of additional independent items can help determine time order, and hence resolve underspecification. This is in sharp contrast to the common practice of limiting the analysis to a small subset of relevant items, which is followed largely due to poor scaling of existing methods. To put our theoretical insight into practice, we develop an approximate likelihood maximization method for learning continuous-time Markov chains, which can scale to hundreds of items and is orders of magnitude faster than previous methods. We demonstrate the effectiveness of our approach on synthetic and real cancer data.
Adaptive Admittance Control for Safety-Critical Physical Human Robot Collaboration
Aug 09, 2022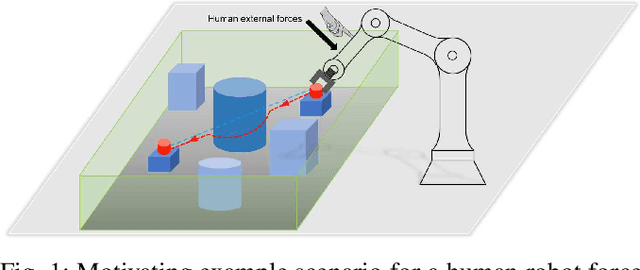
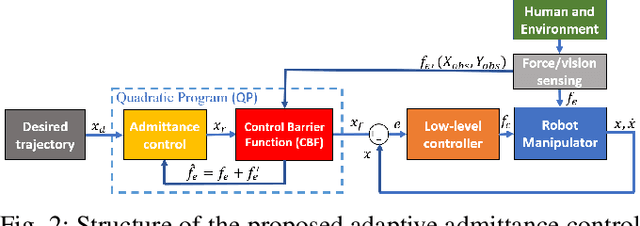
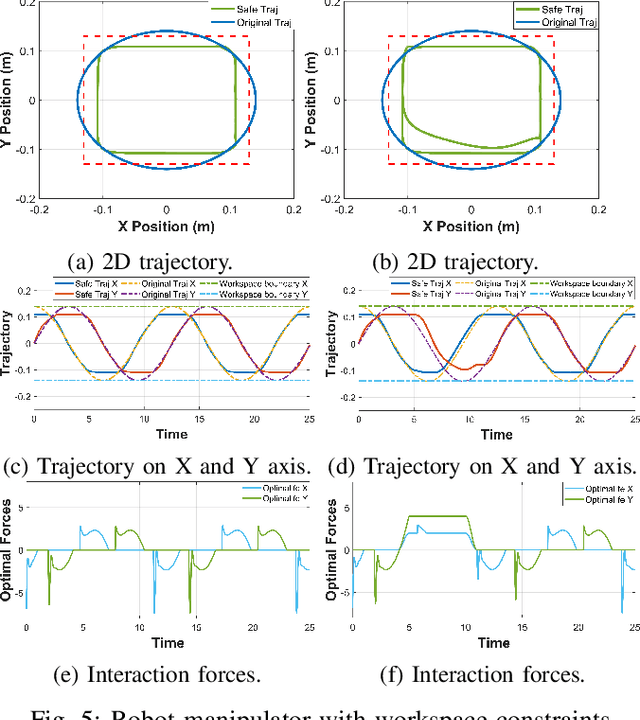
Physical human-robot collaboration requires strict safety guarantees since robots and humans work in a shared workspace. This letter presents a novel control framework to handle safety-critical position-based constraints for human-robot physical interaction. The proposed methodology is based on admittance control, exponential control barrier functions (ECBFs) and quadratic program (QP) to achieve compliance during the force interaction between human and robot, while simultaneously guaranteeing safety constraints. In particular, the formulation of admittance control is rewritten as a second-order nonlinear control system, and the interaction forces between humans and robots are regarded as the control input. A virtual force feedback for admittance control is provided in real-time by using the ECBFs-QP framework as a compensator of the external human forces. A safe trajectory is therefore derived from the proposed adaptive admittance control scheme for a low-level controller to track. The innovation of the proposed approach is that the proposed controller will enable the robot to comply with human forces with natural fluidity without violation of any safety constraints even in cases where human external forces incidentally force the robot to violate constraints. The effectiveness of our approach is demonstrated in simulation studies on a two-link planar robot manipulator.