 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Multi-center Assessment of CNN-Transformer with Belief Matching Loss for Patient-independent Seizure Detection in Scalp and Intracranial EEG
Jul 29, 2022
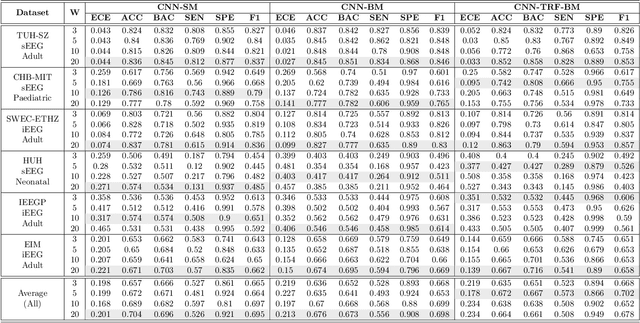
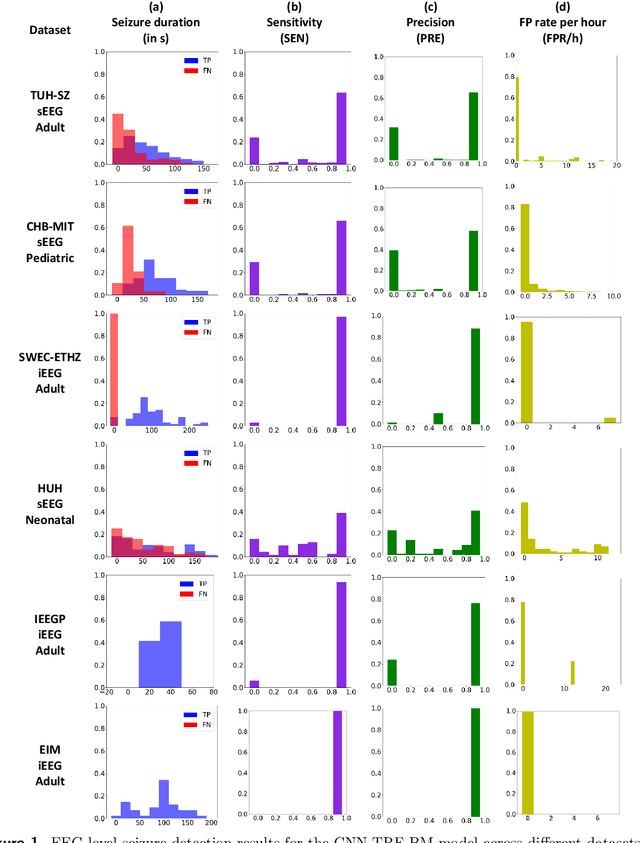
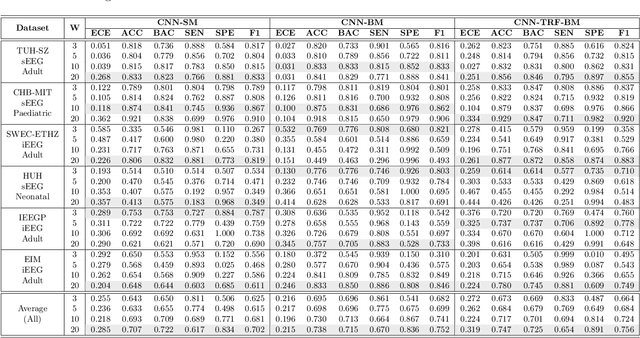
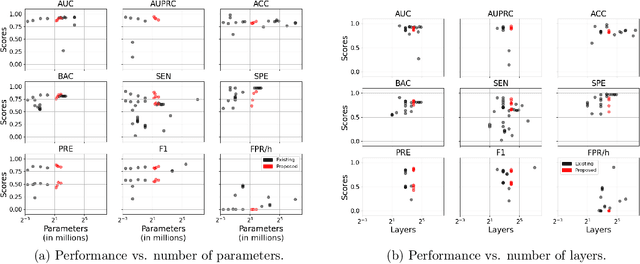
Neurologists typically identify epileptic seizures from electroencephalograms (EEGs) by visual inspection. This process is often time-consuming. To expedite the process, a reliable, automated, and patient-independent seizure detector is essential. However, developing such seizure detector is challenging as seizures exhibit diverse morphologies across different patients. In this study, we propose a patient-independent seizure detector to automatically detect seizures in both scalp EEG (sEEG) and intracranial EEG (iEEG). First, we deploy a convolutional neural network (CNN) with transformers (TRF) and belief matching (BM) loss to detect seizures in single-channel EEG segments. Next, we extract regional features from the channel-level outputs to detect seizures in multi-channel EEG segments. At last, we apply postprocessing filters to the segment-level outputs to determine the start and end points of seizures in multi-channel EEGs. We introduce the minimum overlap evaluation scoring (MOES) as an evaluation metric that accounts for minimum overlap between the detection and seizure, improving upon existing metrics. We trained the seizure detector on the Temple University Hospital Seizure sEEG dataset and evaluated it on five other independent sEEG and iEEG datasets. On the TUH-SZ dataset, the proposed patient-independent seizure detector achieves a sensitivity (SEN), precision (PRE), average and median false positive rate per hour (aFPR/h and mFPR/h), and median offset of 0.772, 0.429, 4.425, 0, and -2.125s, respectively. Across all six datasets, we obtained SEN of 0.227-1.00, PRE of 0.377-1.00, aFPR/h of 0.253-2.037 and mFPR/h of 0-0.559. The proposed seizure detector can reliably detect seizures in EEGs and takes less than 15s for a 30 minutes EEG. Hence, this system could aid the clinicians in reliably identifying seizures expeditiously, allocating more time for devising proper treatment.
Traffic-Twitter Transformer: A Nature Language Processing-joined Framework For Network-wide Traffic Forecasting
Jun 28, 2022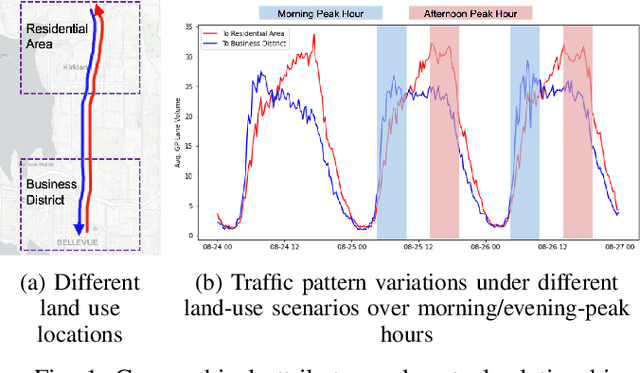
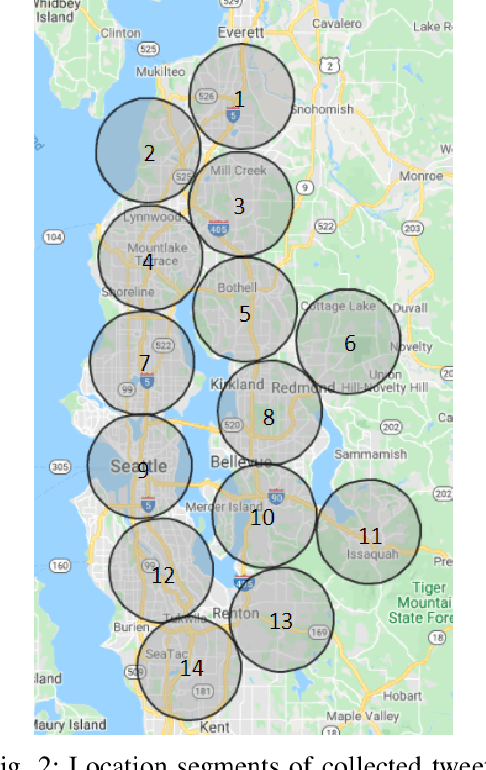
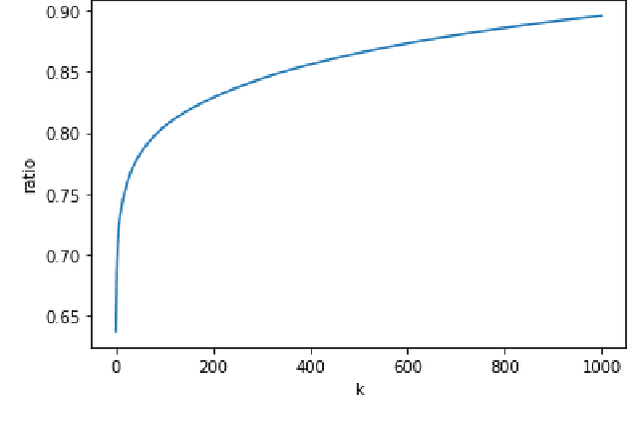
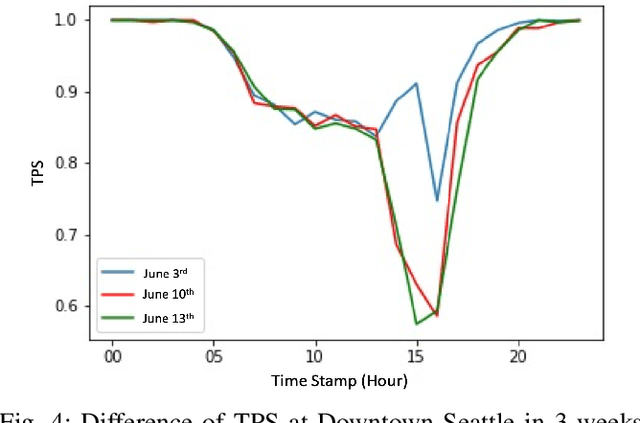
With accurate and timely traffic forecasting, the impacted traffic conditions can be predicted in advance to guide agencies and residents to respond to changes in traffic patterns appropriately. However, existing works on traffic forecasting mainly relied on historical traffic patterns confining to short-term prediction, under 1 hour, for instance. To better manage future roadway capacity and accommodate social and human impacts, it is crucial to propose a flexible and comprehensive framework to predict physical-aware long-term traffic conditions for public users and transportation agencies. In this paper, the gap of robust long-term traffic forecasting was bridged by taking social media features into consideration. A correlation study and a linear regression model were first implemented to evaluate the significance of the correlation between two time-series data, traffic intensity and Twitter data intensity. Two time-series data were then fed into our proposed social-aware framework, Traffic-Twitter Transformer, which integrated Nature Language representations into time-series records for long-term traffic prediction. Experimental results in the Great Seattle Area showed that our proposed model outperformed baseline models in all evaluation matrices. This NLP-joined social-aware framework can become a valuable implement of network-wide traffic prediction and management for traffic agencies.
Artifact Identification in X-ray Diffraction Data using Machine Learning Methods
Jul 29, 2022
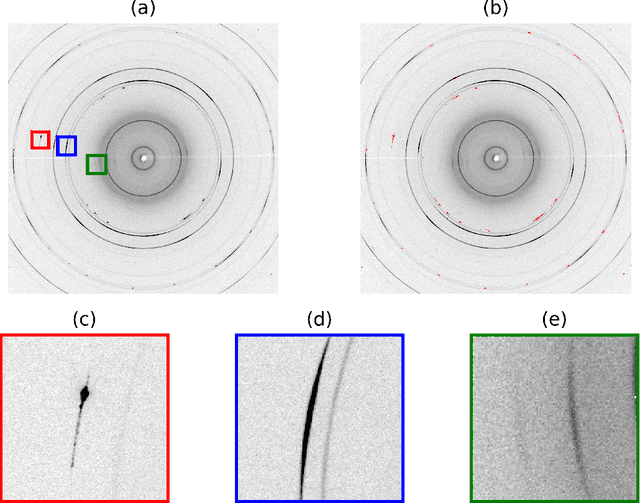
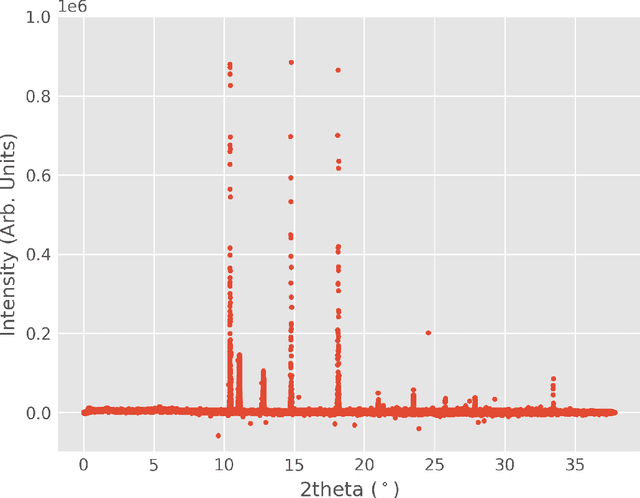
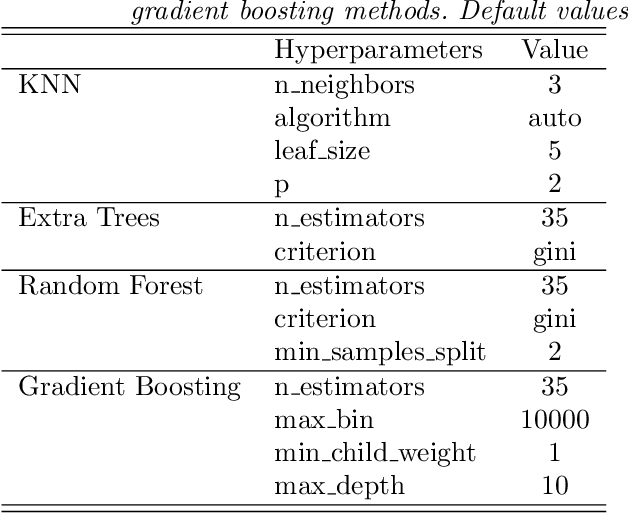
The in situ synchrotron high-energy X-ray powder diffraction (XRD) technique is highly utilized by researchers to analyze the crystallographic structures of materials in functional devices (e.g., battery materials) or in complex sample environments (e.g., diamond anvil cells or syntheses reactors). An atomic structure of a material can be identified by its diffraction pattern, along with detailed analysis such as Rietveld refinement which indicates how the measured structure deviates from the ideal structure (e.g., internal stresses or defects). For in situ experiments, a series of XRD images is usually collected on the same sample at different conditions (e.g., adiabatic conditions), yielding different states of matter, or simply collected continuously as a function of time to track the change of a sample over a chemical or physical process. In situ experiments are usually performed with area detectors, collecting 2D images composed of diffraction rings for ideal powders. Depending on the material's form, one may observe different characteristics other than the typical Debye Scherrer rings for a realistic sample and its environments, such as textures or preferred orientations and single crystal diffraction spots in the 2D XRD image. In this work, we present an investigation of machine learning methods for fast and reliable identification and separation of the single crystal diffraction spots in XRD images. The exclusion of artifacts during an XRD image integration process allows a precise analysis of the powder diffraction rings of interest. We observe that the gradient boosting method can consistently produce high accuracy results when it is trained with small subsets of highly diverse datasets. The method dramatically decreases the amount of time spent on identifying and separating single crystal spots in comparison to the conventional method.
Training Process of Unsupervised Learning Architecture for Gravity Spy Dataset
Aug 07, 2022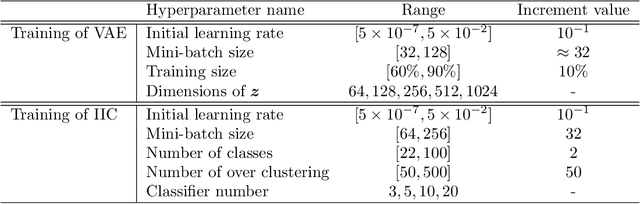
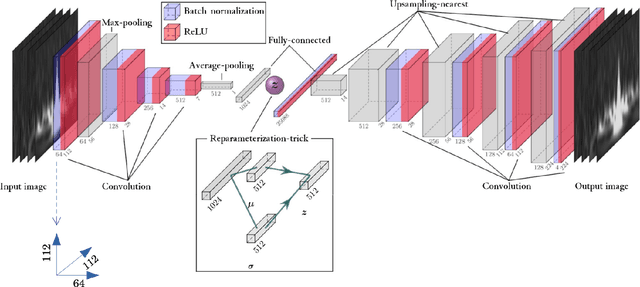
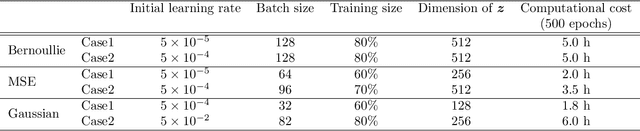
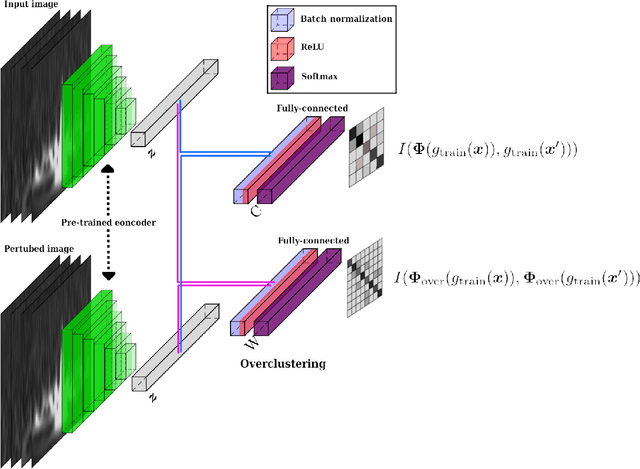
Transient noise appearing in the data from gravitational-wave detectors frequently causes problems, such as instability of the detectors and overlapping or mimicking gravitational-wave signals. Because transient noise is considered to be associated with the environment and instrument, its classification would help to understand its origin and improve the detector's performance. In a previous study, an architecture for classifying transient noise using a time-frequency 2D image (spectrogram) is proposed, which uses unsupervised deep learning combined with variational autoencoder and invariant information clustering. The proposed unsupervised-learning architecture is applied to the Gravity Spy dataset, which consists of Advanced Laser Interferometer Gravitational-Wave Observatory (Advanced LIGO) transient noises with their associated metadata to discuss the potential for online or offline data analysis. In this study, focused on the Gravity Spy dataset, the training process of unsupervised-learning architecture of the previous study is examined and reported.
* 17 pages, 10 figures, Matches version published in Annalen der Physik
SDA-SNE: Spatial Discontinuity-Aware Surface Normal Estimation via Multi-Directional Dynamic Programming
Aug 18, 2022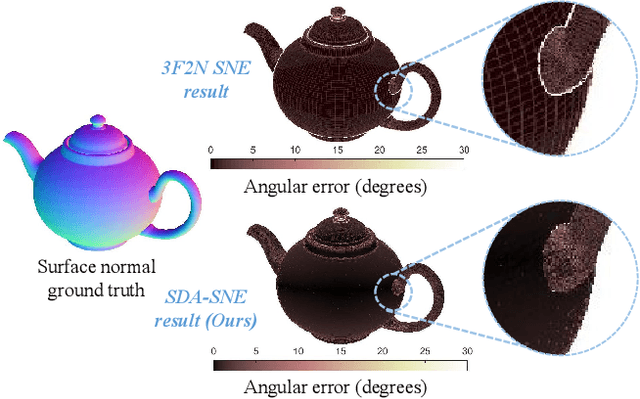
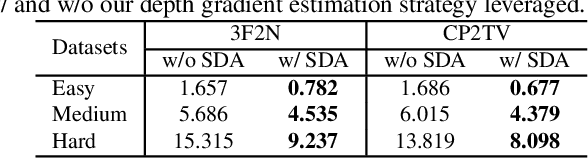
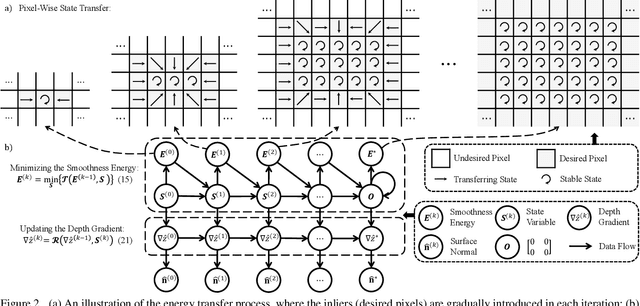
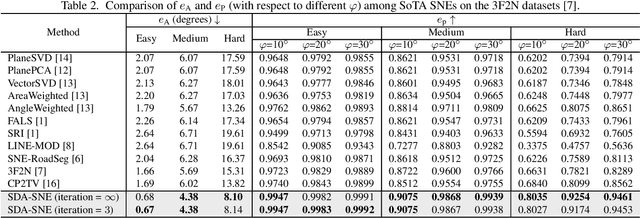
The state-of-the-art (SoTA) surface normal estimators (SNEs) generally translate depth images into surface normal maps in an end-to-end fashion. Although such SNEs have greatly minimized the trade-off between efficiency and accuracy, their performance on spatial discontinuities, e.g., edges and ridges, is still unsatisfactory. To address this issue, this paper first introduces a novel multi-directional dynamic programming strategy to adaptively determine inliers (co-planar 3D points) by minimizing a (path) smoothness energy. The depth gradients can then be refined iteratively using a novel recursive polynomial interpolation algorithm, which helps yield more reasonable surface normals. Our introduced spatial discontinuity-aware (SDA) depth gradient refinement strategy is compatible with any depth-to-normal SNEs. Our proposed SDA-SNE achieves much greater performance than all other SoTA approaches, especially near/on spatial discontinuities. We further evaluate the performance of SDA-SNE with respect to different iterations, and the results suggest that it converges fast after only a few iterations. This ensures its high efficiency in various robotics and computer vision applications requiring real-time performance. Additional experiments on the datasets with different extents of random noise further validate our SDA-SNE's robustness and environmental adaptability. Our source code, demo video, and supplementary material are publicly available at mias.group/SDA-SNE.
Prediction of Solar Radiation Based on Spatial and Temporal Embeddings for Solar Generation Forecast
Jun 17, 2022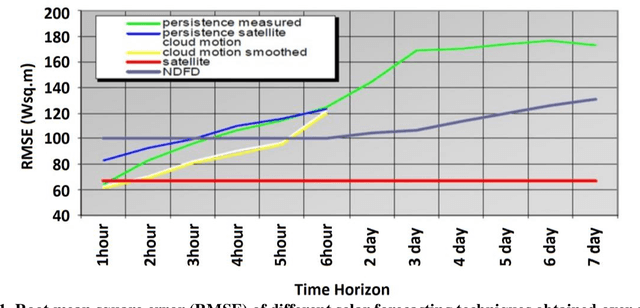
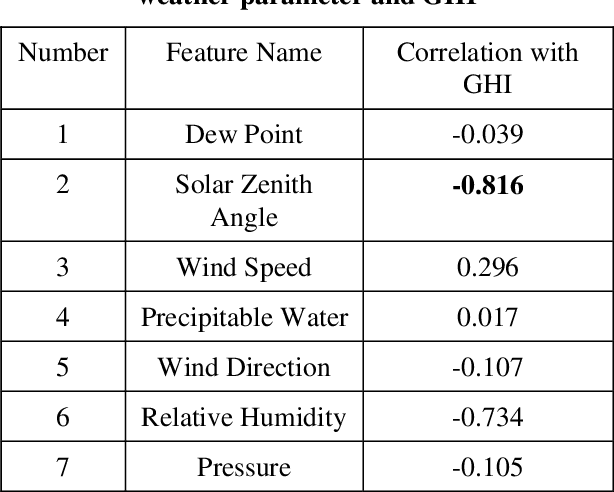
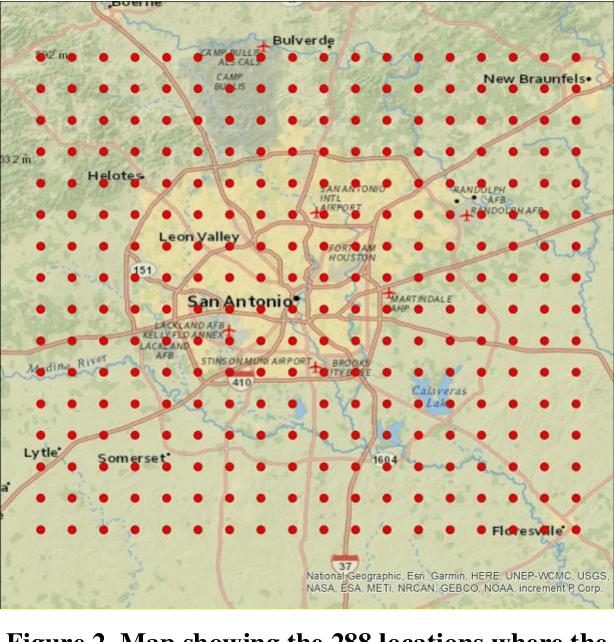
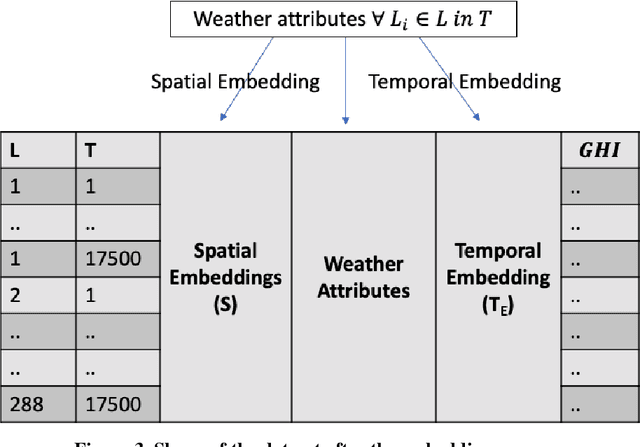
A novel method for real-time solar generation forecast using weather data, while exploiting both spatial and temporal structural dependencies is proposed. The network observed over time is projected to a lower-dimensional representation where a variety of weather measurements are used to train a structured regression model while weather forecast is used at the inference stage. Experiments were conducted at 288 locations in the San Antonio, TX area on obtained from the National Solar Radiation Database. The model predicts solar irradiance with a good accuracy (R2 0.91 for the summer, 0.85 for the winter, and 0.89 for the global model). The best accuracy was obtained by the Random Forest Regressor. Multiple experiments were conducted to characterize influence of missing data and different time horizons providing evidence that the new algorithm is robust for data missing not only completely at random but also when the mechanism is spatial, and temporal.
LEO Satellite-Enabled Grant-Free Random Access with MIMO-OTFS
Aug 03, 2022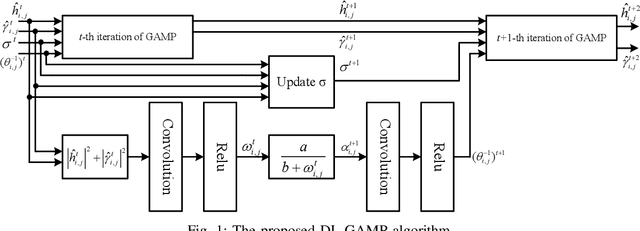
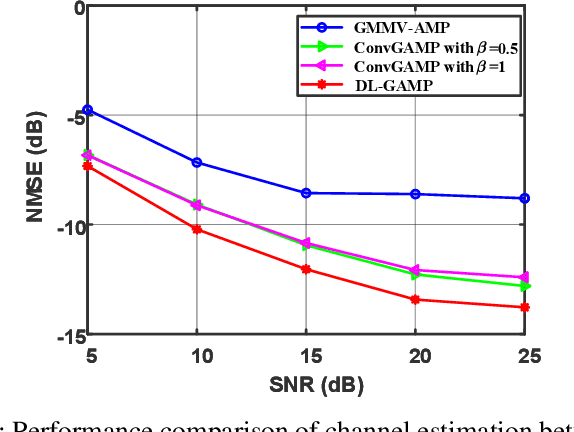
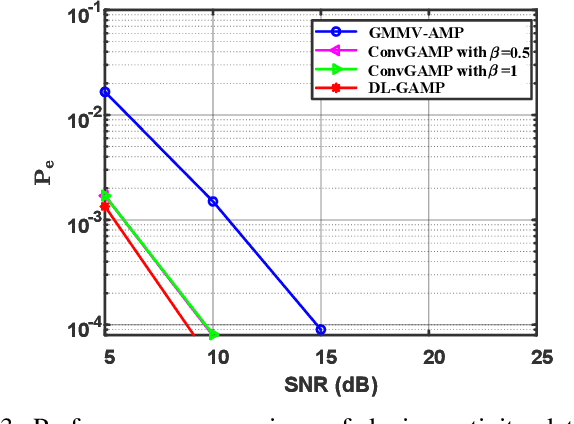
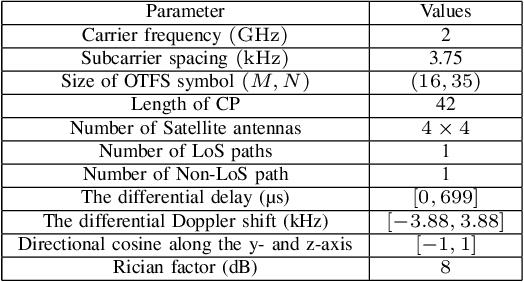
This paper investigates joint channel estimation and device activity detection in the LEO satellite-enabled grant-free random access systems with large differential delay and Doppler shift. In addition, the multiple-input multiple-output (MIMO) with orthogonal time-frequency space modulation (OTFS) is utilized to combat the dynamics of the terrestrial-satellite link. To simplify the computation process, we estimate the channel tensor in parallel along the delay dimension. Then, the deep learning and expectation-maximization approach are integrated into the generalized approximate message passing with cross-correlation--based Gaussian prior to capture the channel sparsity in the delay-Doppler-angle domain and learn the hyperparameters. Finally, active devices are detected by computing energy of the estimated channel. Simulation results demonstrate that the proposed algorithms outperform conventional methods.
Scaling Up Dynamic Graph Representation Learning via Spiking Neural Networks
Aug 15, 2022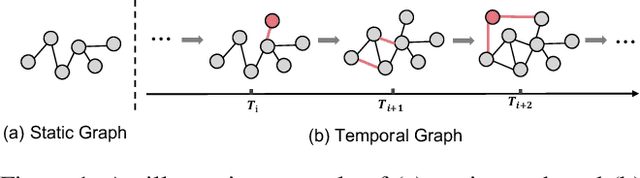
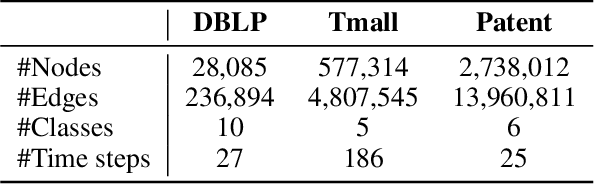
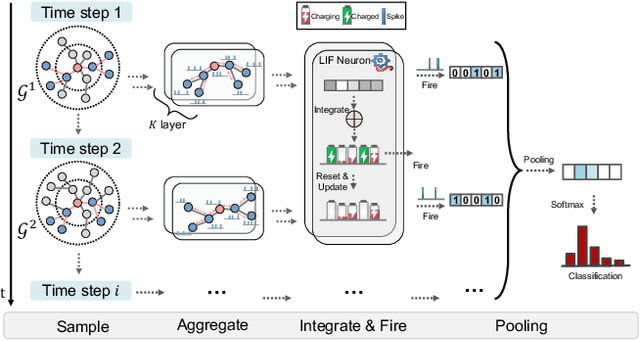
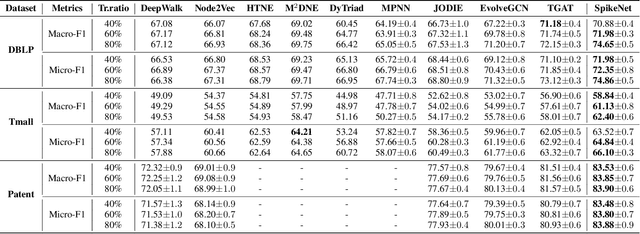
Recent years have seen a surge in research on dynamic graph representation learning, which aims to model temporal graphs that are dynamic and evolving constantly over time. However, current work typically models graph dynamics with recurrent neural networks (RNNs), making them suffer seriously from computation and memory overheads on large temporal graphs. So far, scalability of dynamic graph representation learning on large temporal graphs remains one of the major challenges. In this paper, we present a scalable framework, namely SpikeNet, to efficiently capture the temporal and structural patterns of temporal graphs. We explore a new direction in that we can capture the evolving dynamics of temporal graphs with spiking neural networks (SNNs) instead of RNNs. As a low-power alternative to RNNs, SNNs explicitly model graph dynamics as spike trains of neuron populations and enable spike-based propagation in an efficient way. Experiments on three large real-world temporal graph datasets demonstrate that SpikeNet outperforms strong baselines on the temporal node classification task with lower computational costs. Particularly, SpikeNet generalizes to a large temporal graph (2M nodes and 13M edges) with significantly fewer parameters and computation overheads. Our code is publicly available at https://github.com/EdisonLeeeee/SpikeNet
How Much More Data Do I Need? Estimating Requirements for Downstream Tasks
Jul 13, 2022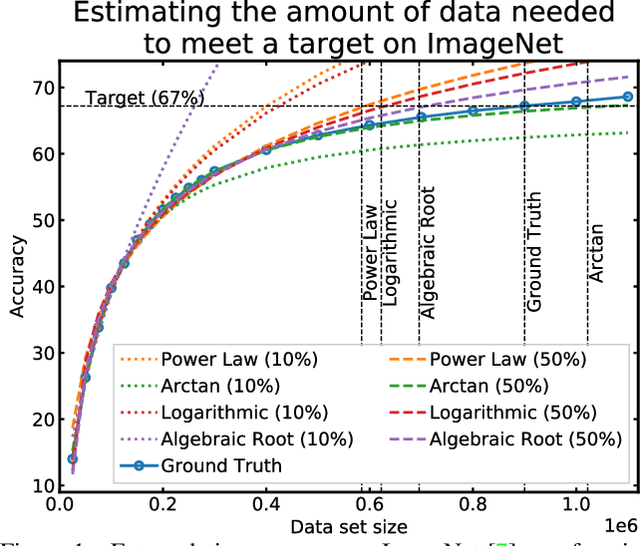

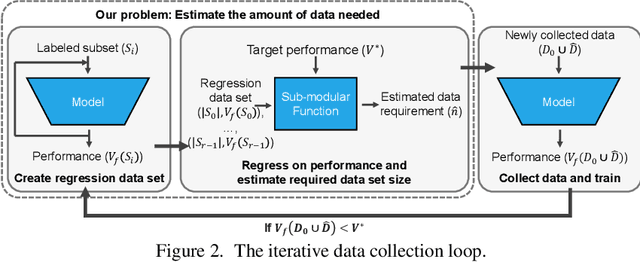
Given a small training data set and a learning algorithm, how much more data is necessary to reach a target validation or test performance? This question is of critical importance in applications such as autonomous driving or medical imaging where collecting data is expensive and time-consuming. Overestimating or underestimating data requirements incurs substantial costs that could be avoided with an adequate budget. Prior work on neural scaling laws suggest that the power-law function can fit the validation performance curve and extrapolate it to larger data set sizes. We find that this does not immediately translate to the more difficult downstream task of estimating the required data set size to meet a target performance. In this work, we consider a broad class of computer vision tasks and systematically investigate a family of functions that generalize the power-law function to allow for better estimation of data requirements. Finally, we show that incorporating a tuned correction factor and collecting over multiple rounds significantly improves the performance of the data estimators. Using our guidelines, practitioners can accurately estimate data requirements of machine learning systems to gain savings in both development time and data acquisition costs.
Waveform Design for Mutual Interference Mitigation in Automotive Radar
Aug 08, 2022
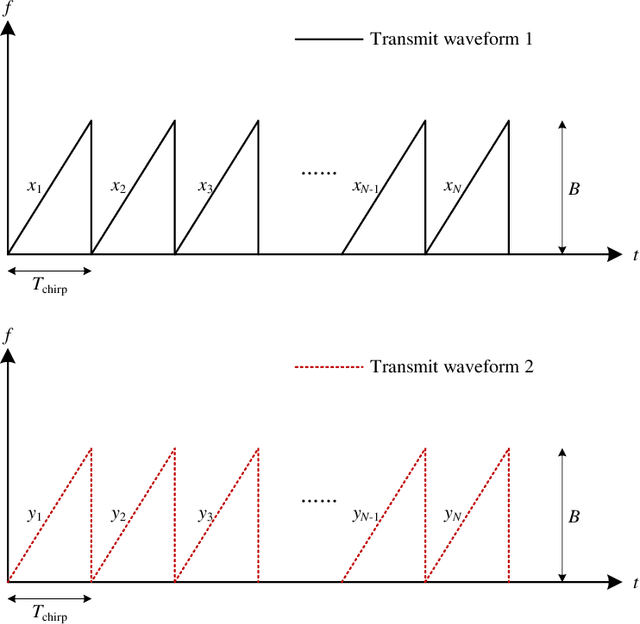
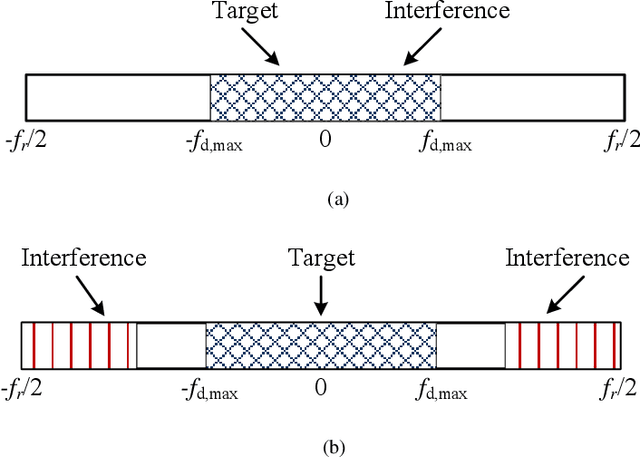
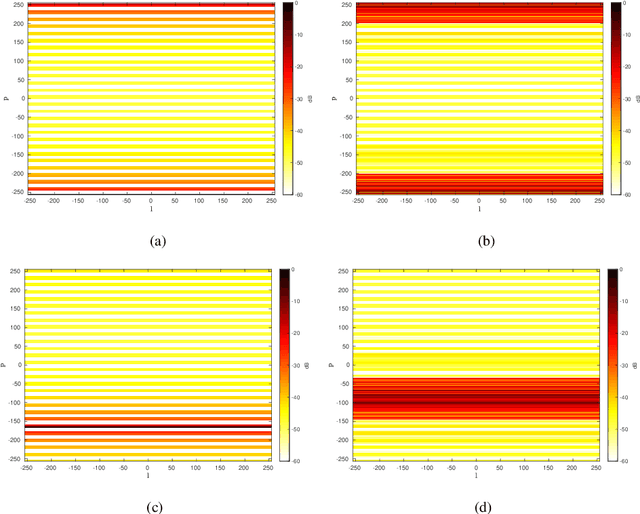
The mutual interference between similar radar systems can result in reduced radar sensitivity and increased false alarm rates. To address the synchronous and asynchronous interference mitigation problems in similar radar systems, we first propose herein two slow-time coding schemes to modulate the pulses within a coherent processing interval (CPI) for a single-input-single-output (SISO) scenario. Specifically, the first coding scheme relies on Doppler shifting and the second one is devised based on an optimization approach. We further extend our discussion to the more general case of multiple-input-multiple-output (MIMO) radars and propose an efficient algorithm to design waveforms to mitigate mutual interference in such systems. The proposed coding schemes are computationally efficient in practice and the incorporation of the coding schemes requires only a slight modification of the existing systems. Our numerical examples indicate that the proposed coding schemes can reduce the interference power level in a desired area of the cross-ambiguity function significantly.