 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Decentralized Machine Learning for Intelligent Health Care Systems on the Computing Continuum
Jul 29, 2022
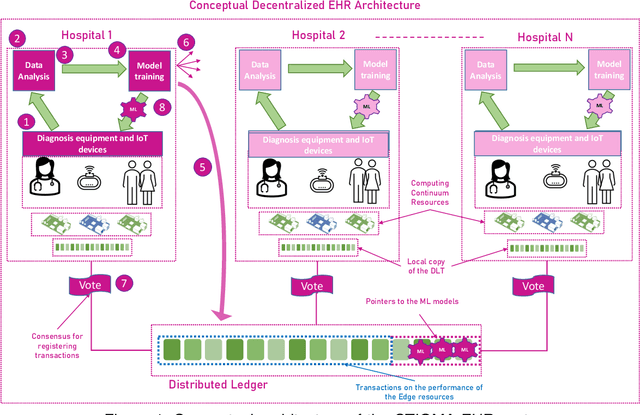
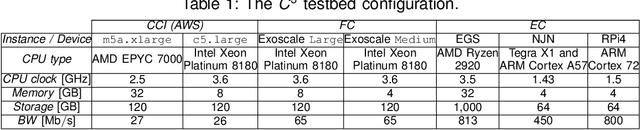
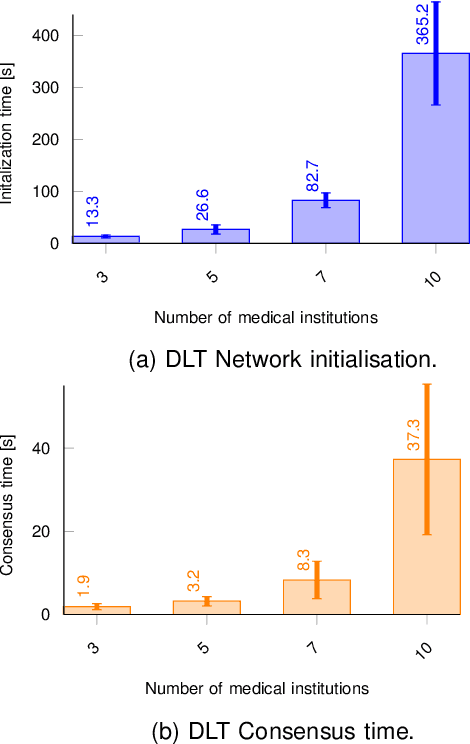
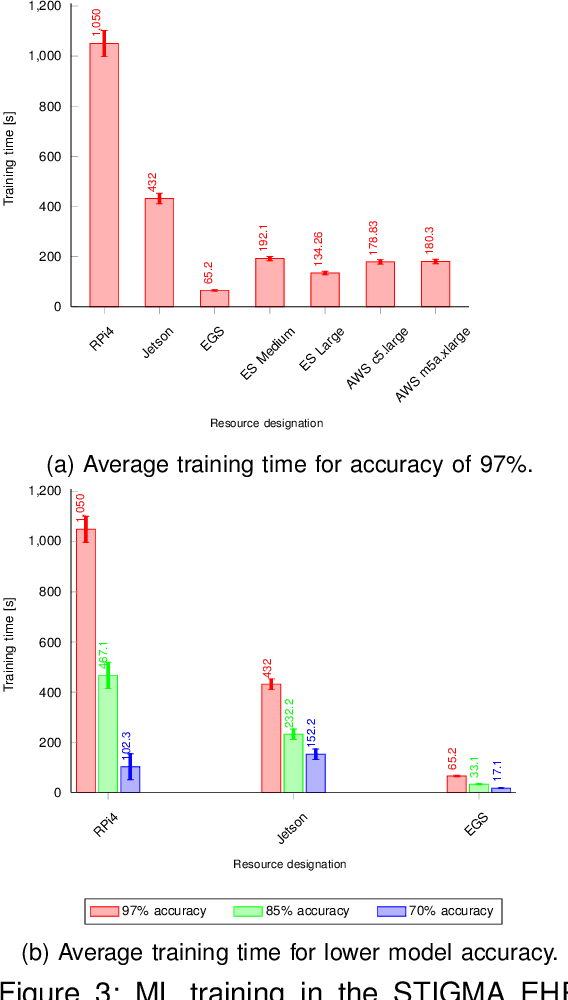
The introduction of electronic personal health records (EHR) enables nationwide information exchange and curation among different health care systems. However, the current EHR systems do not provide transparent means for diagnosis support, medical research or can utilize the omnipresent data produced by the personal medical devices. Besides, the EHR systems are centrally orchestrated, which could potentially lead to a single point of failure. Therefore, in this article, we explore novel approaches for decentralizing machine learning over distributed ledgers to create intelligent EHR systems that can utilize information from personal medical devices for improved knowledge extraction. Consequently, we proposed and evaluated a conceptual EHR to enable anonymous predictive analysis across multiple medical institutions. The evaluation results indicate that the decentralized EHR can be deployed over the computing continuum with reduced machine learning time of up to 60% and consensus latency of below 8 seconds.
SDWPF: A Dataset for Spatial Dynamic Wind Power Forecasting Challenge at KDD Cup 2022
Aug 08, 2022

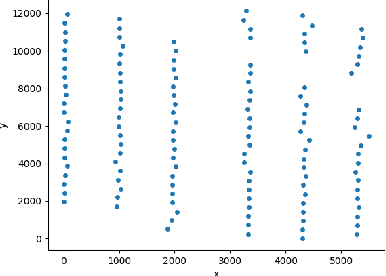

The variability of wind power supply can present substantial challenges to incorporating wind power into a grid system. Thus, Wind Power Forecasting (WPF) has been widely recognized as one of the most critical issues in wind power integration and operation. There has been an explosion of studies on wind power forecasting problems in the past decades. Nevertheless, how to well handle the WPF problem is still challenging, since high prediction accuracy is always demanded to ensure grid stability and security of supply. We present a unique Spatial Dynamic Wind Power Forecasting dataset: SDWPF, which includes the spatial distribution of wind turbines, as well as the dynamic context factors. Whereas, most of the existing datasets have only a small number of wind turbines without knowing the locations and context information of wind turbines at a fine-grained time scale. By contrast, SDWPF provides the wind power data of 134 wind turbines from a wind farm over half a year with their relative positions and internal statuses. We use this dataset to launch the Baidu KDD Cup 2022 to examine the limit of current WPF solutions. The dataset is released at https://aistudio.baidu.com/aistudio/competition/detail/152/0/datasets.
A semi-supervised geometric-driven methodology for supervised fishing activity detection on multi-source AIS tracking messages
Jul 12, 2022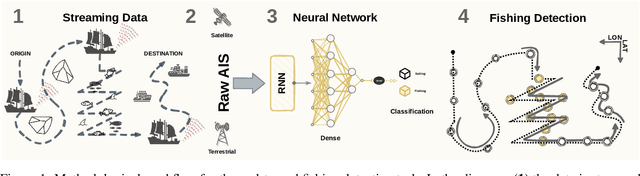
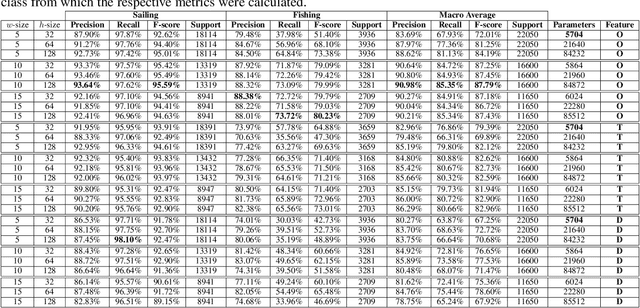
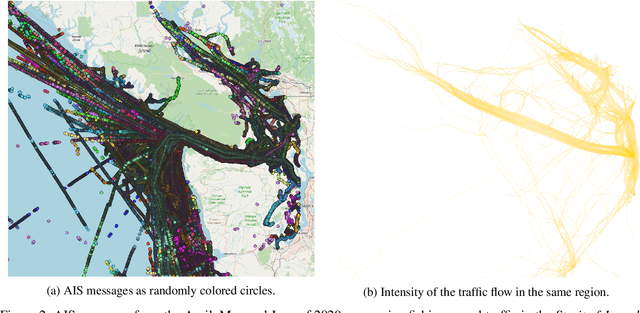

Automatic Identification System (AIS) messages are useful for tracking vessel activity across oceans worldwide using radio links and satellite transceivers. Such data plays a significant role in tracking vessel activity and mapping mobility patterns such as those found in fishing. Accordingly, this paper proposes a geometric-driven semi-supervised approach for fishing activity detection from AIS data. Through the proposed methodology we show how to explore the information included in the messages to extract features describing the geometry of the vessel route. To this end, we leverage the unsupervised nature of cluster analysis to label the trajectory geometry highlighting the changes in the vessel's moving pattern which tends to indicate fishing activity. The labels obtained by the proposed unsupervised approach are used to detect fishing activities, which we approach as a time-series classification task. In this context, we propose a solution using recurrent neural networks on AIS data streams with roughly 87% of the overall $F$-score on the whole trajectories of 50 different unseen fishing vessels. Such results are accompanied by a broad benchmark study assessing the performance of different Recurrent Neural Network (RNN) architectures. In conclusion, this work contributes by proposing a thorough process that includes data preparation, labeling, data modeling, and model validation. Therefore, we present a novel solution for mobility pattern detection that relies upon unfolding the trajectory in time and observing their inherent geometry.
Streaming-capable High-performance Architecture of Learned Image Compression Codecs
Aug 02, 2022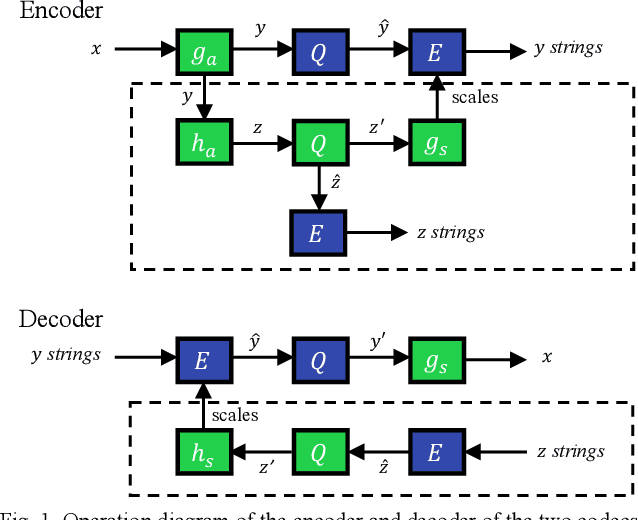
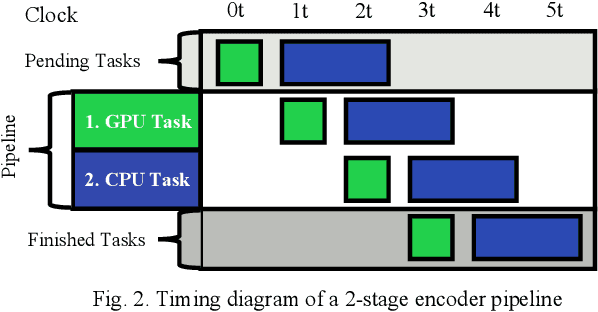
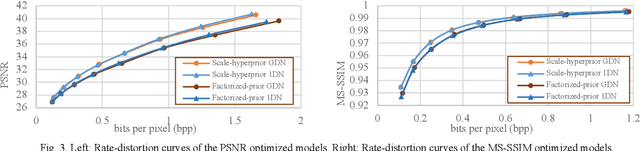
Learned image compression allows achieving state-of-the-art accuracy and compression ratios, but their relatively slow runtime performance limits their usage. While previous attempts on optimizing learned image codecs focused more on the neural model and entropy coding, we present an alternative method to improving the runtime performance of various learned image compression models. We introduce multi-threaded pipelining and an optimized memory model to enable GPU and CPU workloads asynchronous execution, fully taking advantage of computational resources. Our architecture alone already produces excellent performance without any change to the neural model itself. We also demonstrate that combining our architecture with previous tweaks to the neural models can further improve runtime performance. We show that our implementations excel in throughput and latency compared to the baseline and demonstrate the performance of our implementations by creating a real-time video streaming encoder-decoder sample application, with the encoder running on an embedded device.
Shielding Federated Learning Systems against Inference Attacks with ARM TrustZone
Aug 11, 2022
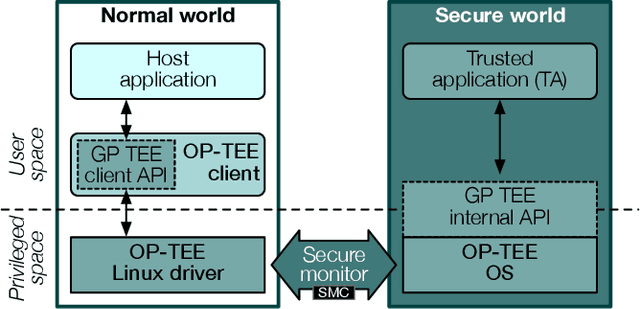
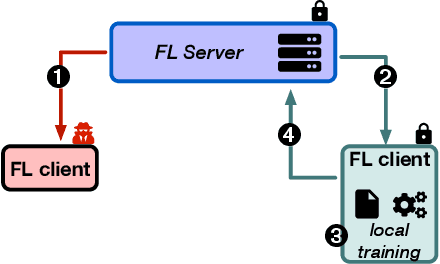
Federated Learning (FL) opens new perspectives for training machine learning models while keeping personal data on the users premises. Specifically, in FL, models are trained on the users devices and only model updates (i.e., gradients) are sent to a central server for aggregation purposes. However, the long list of inference attacks that leak private data from gradients, published in the recent years, have emphasized the need of devising effective protection mechanisms to incentivize the adoption of FL at scale. While there exist solutions to mitigate these attacks on the server side, little has been done to protect users from attacks performed on the client side. In this context, the use of Trusted Execution Environments (TEEs) on the client side are among the most proposing solutions. However, existing frameworks (e.g., DarkneTZ) require statically putting a large portion of the machine learning model into the TEE to effectively protect against complex attacks or a combination of attacks. We present GradSec, a solution that allows protecting in a TEE only sensitive layers of a machine learning model, either statically or dynamically, hence reducing both the TCB size and the overall training time by up to 30% and 56%, respectively compared to state-of-the-art competitors.
Fast 3D Sparse Topological Skeleton Graph Generation for Mobile Robot Global Planning
Aug 08, 2022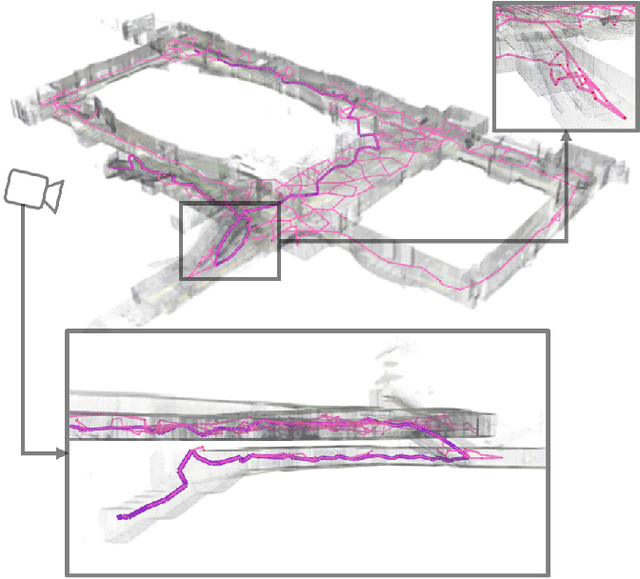
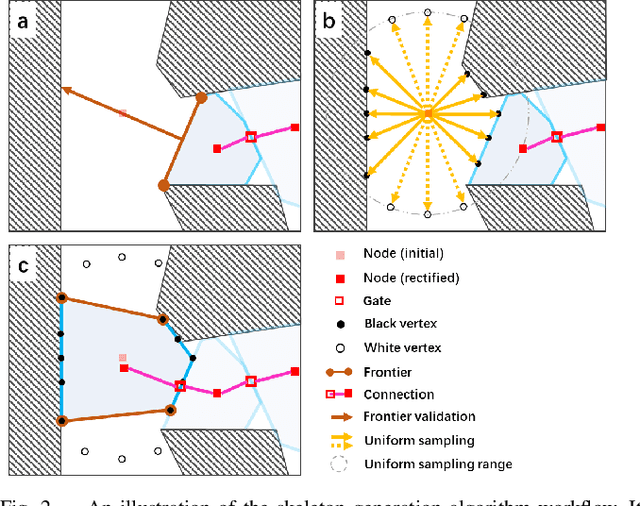
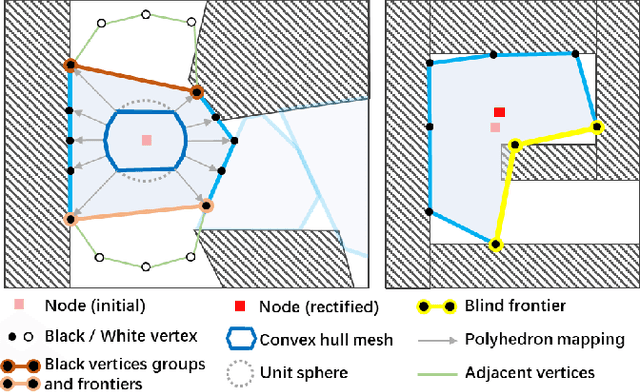
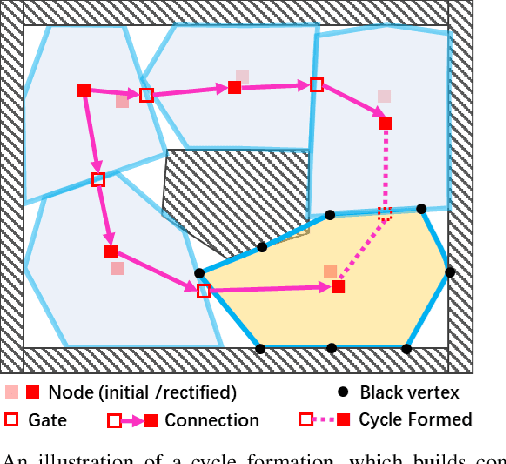
In recent years, mobile robots are becoming ambitious and deployed in large-scale scenarios. Serving as a high-level understanding of environments, a sparse skeleton graph is beneficial for more efficient global planning. Currently, existing solutions for skeleton graph generation suffer from several major limitations, including poor adaptiveness to different map representations, dependency on robot inspection trajectories and high computational overhead. In this paper, we propose an efficient and flexible algorithm generating a trajectory-independent 3D sparse topological skeleton graph capturing the spatial structure of the free space. In our method, an efficient ray sampling and validating mechanism are adopted to find distinctive free space regions, which contributes to skeleton graph vertices, with traversability between adjacent vertices as edges. A cycle formation scheme is also utilized to maintain skeleton graph compactness. Benchmark comparison with state-of-the-art works demonstrates that our approach generates sparse graphs in a substantially shorter time, giving high-quality global planning paths. Experiments conducted in real-world maps further validate the capability of our method in real-world scenarios. Our method will be made open source to benefit the community.
Planning and Scheduling in Digital Health with Answer Set Programming
Aug 05, 2022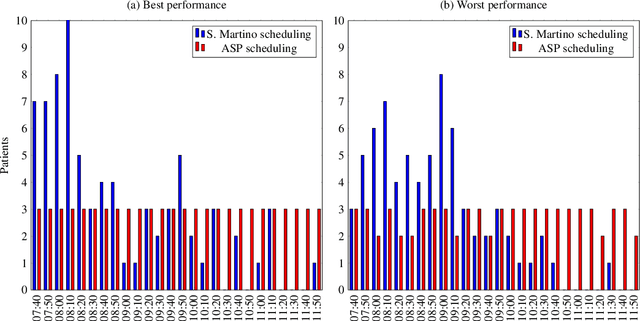
In the hospital world there are several complex combinatory problems, and solving these problems is important to increase the degree of patients' satisfaction and the quality of care offered. The problems in the healthcare are complex since to solve them several constraints and different type of resources should be taken into account. Moreover, the solutions must be evaluated in a small amount of time to ensure the usability in real scenarios. We plan to propose solutions to these kind of problems both expanding already tested solutions and by modelling solutions for new problems, taking into account the literature and by using real data when available. Solving these kind of problems is important but, since the European Commission established with the General Data Protection Regulation that each person has the right to ask for explanation of the decision taken by an AI, without developing Explainability methodologies the usage of AI based solvers e.g. those based on Answer Set programming will be limited. Thus, another part of the research will be devoted to study and propose new methodologies for explaining the solutions obtained.
* In Proceedings ICLP 2022, arXiv:2208.02685
Tractable Dendritic RNNs for Reconstructing Nonlinear Dynamical Systems
Jul 06, 2022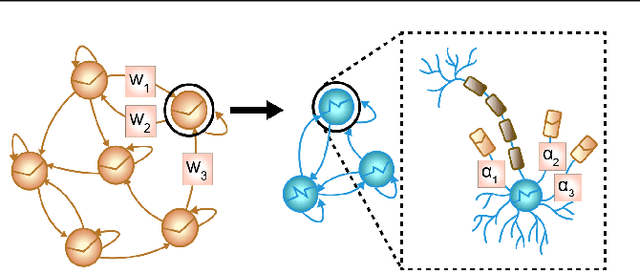
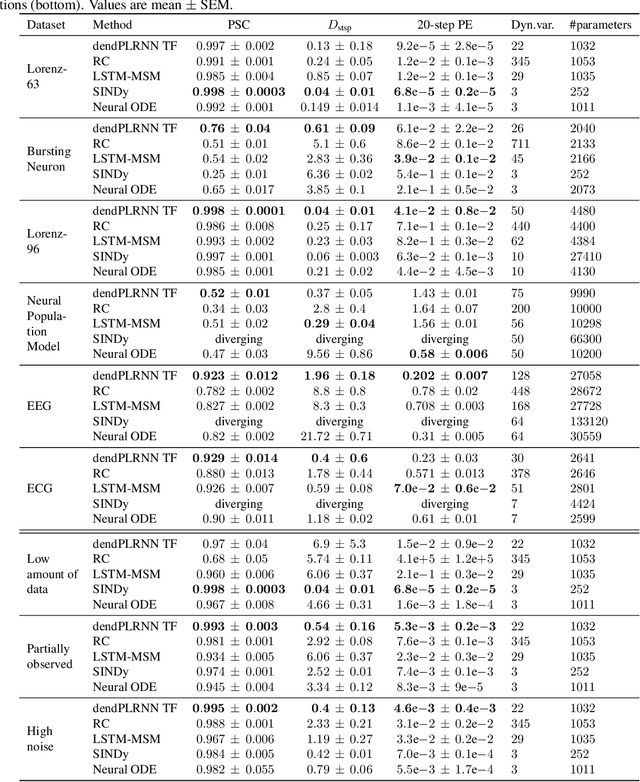
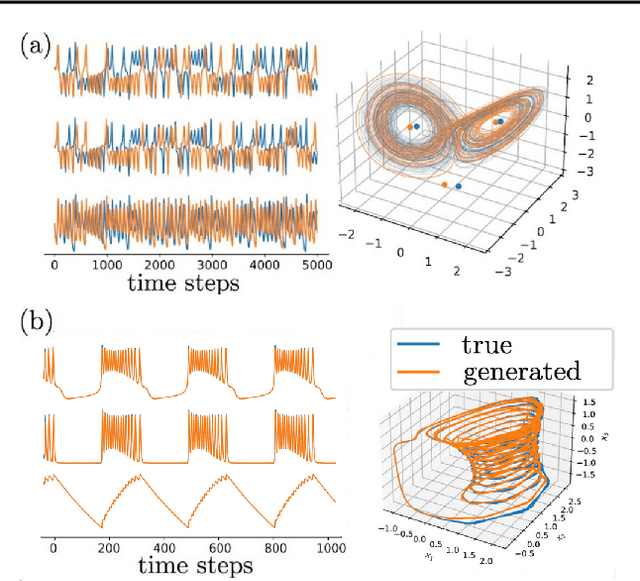
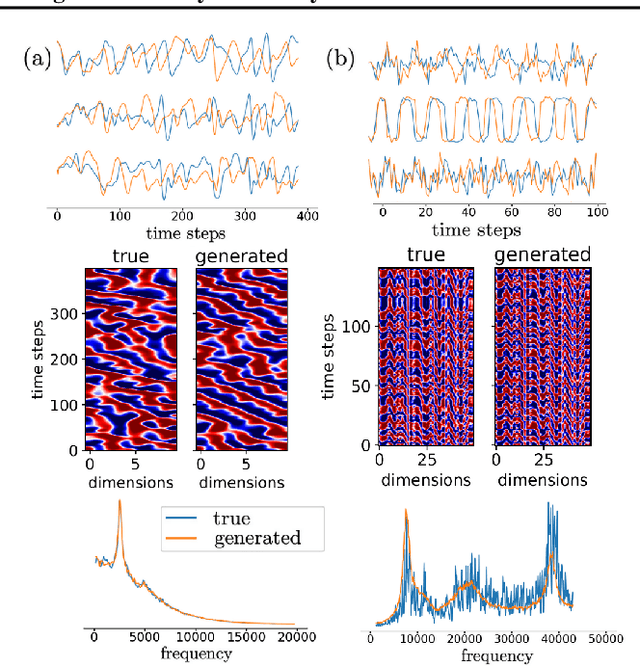
In many scientific disciplines, we are interested in inferring the nonlinear dynamical system underlying a set of observed time series, a challenging task in the face of chaotic behavior and noise. Previous deep learning approaches toward this goal often suffered from a lack of interpretability and tractability. In particular, the high-dimensional latent spaces often required for a faithful embedding, even when the underlying dynamics lives on a lower-dimensional manifold, can hamper theoretical analysis. Motivated by the emerging principles of dendritic computation, we augment a dynamically interpretable and mathematically tractable piecewise-linear (PL) recurrent neural network (RNN) by a linear spline basis expansion. We show that this approach retains all the theoretically appealing properties of the simple PLRNN, yet boosts its capacity for approximating arbitrary nonlinear dynamical systems in comparatively low dimensions. We employ two frameworks for training the system, one combining back-propagation-through-time (BPTT) with teacher forcing, and another based on fast and scalable variational inference. We show that the dendritically expanded PLRNN achieves better reconstructions with fewer parameters and dimensions on various dynamical systems benchmarks and compares favorably to other methods, while retaining a tractable and interpretable structure.
Continuous-Time Deep Glioma Growth Models
Jul 02, 2021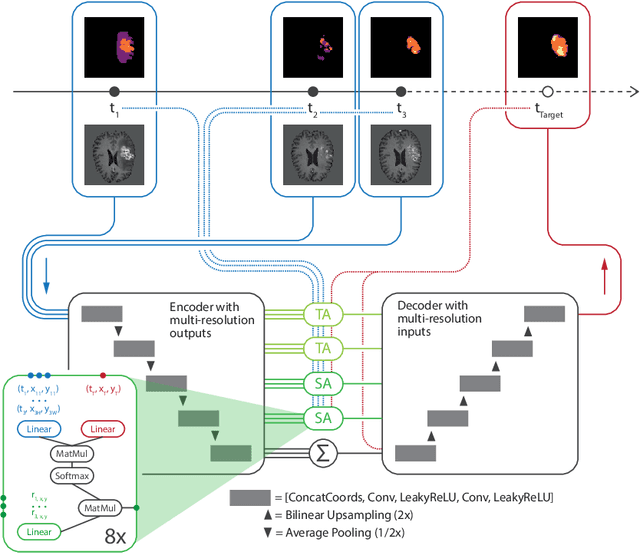


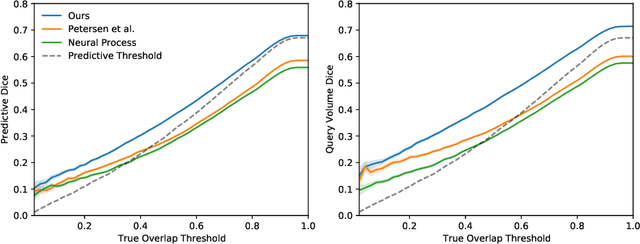
The ability to estimate how a tumor might evolve in the future could have tremendous clinical benefits, from improved treatment decisions to better dose distribution in radiation therapy. Recent work has approached the glioma growth modeling problem via deep learning and variational inference, thus learning growth dynamics entirely from a real patient data distribution. So far, this approach was constrained to predefined image acquisition intervals and sequences of fixed length, which limits its applicability in more realistic scenarios. We overcome these limitations by extending Neural Processes, a class of conditional generative models for stochastic time series, with a hierarchical multi-scale representation encoding including a spatio-temporal attention mechanism. The result is a learned growth model that can be conditioned on an arbitrary number of observations, and that can produce a distribution of temporally consistent growth trajectories on a continuous time axis. On a dataset of 379 patients, the approach successfully captures both global and finer-grained variations in the images, exhibiting superior performance compared to other learned growth models.
Improving Streaming End-to-End ASR on Transformer-based Causal Models with Encoder States Revision Strategies
Jul 06, 2022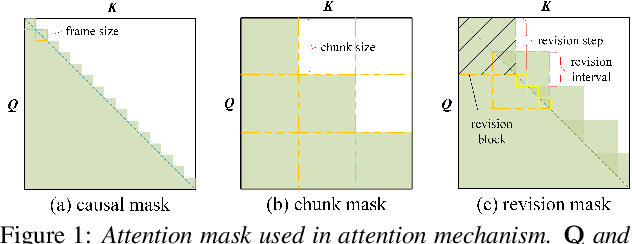
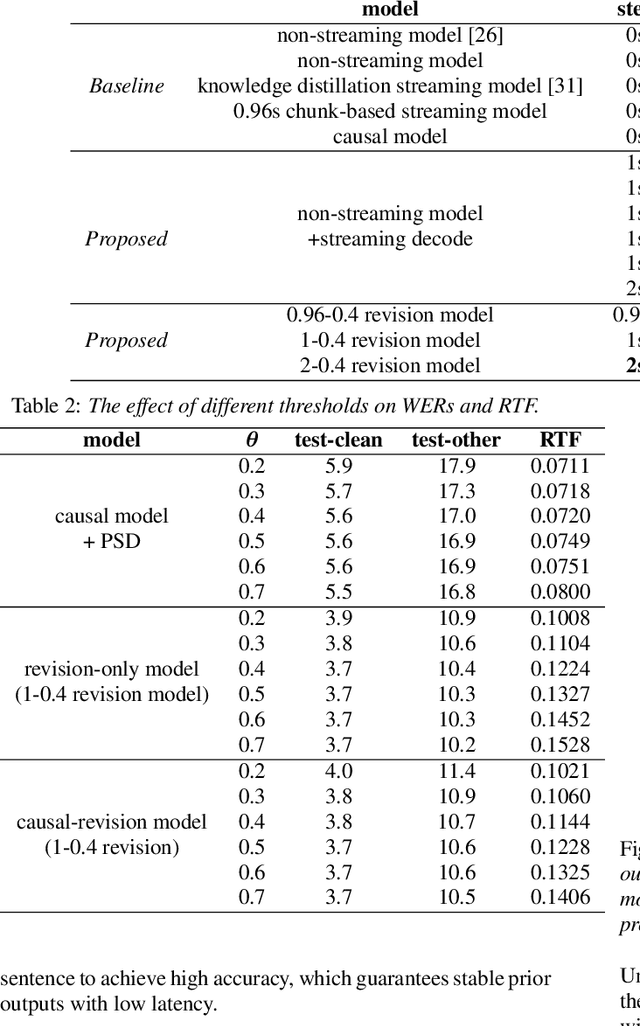
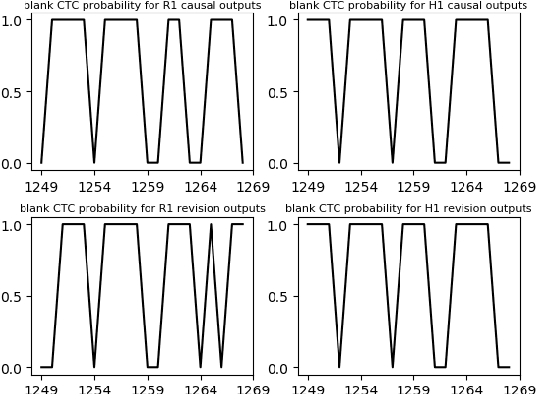
There is often a trade-off between performance and latency in streaming automatic speech recognition (ASR). Traditional methods such as look-ahead and chunk-based methods, usually require information from future frames to advance recognition accuracy, which incurs inevitable latency even if the computation is fast enough. A causal model that computes without any future frames can avoid this latency, but its performance is significantly worse than traditional methods. In this paper, we propose corresponding revision strategies to improve the causal model. Firstly, we introduce a real-time encoder states revision strategy to modify previous states. Encoder forward computation starts once the data is received and revises the previous encoder states after several frames, which is no need to wait for any right context. Furthermore, a CTC spike position alignment decoding algorithm is designed to reduce time costs brought by the revision strategy. Experiments are all conducted on Librispeech datasets. Fine-tuning on the CTC-based wav2vec2.0 model, our best method can achieve 3.7/9.2 WERs on test-clean/other sets, which is also competitive with the chunk-based methods and the knowledge distillation methods.