 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A semi-supervised geometric-driven methodology for supervised fishing activity detection on multi-source AIS tracking messages
Jul 12, 2022
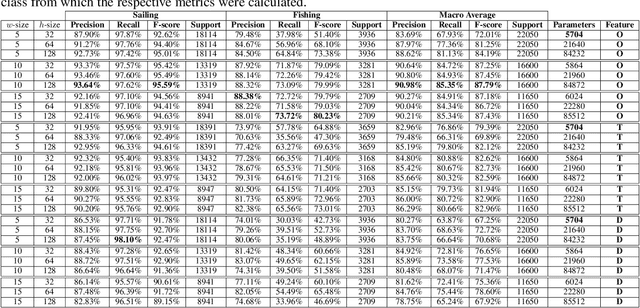
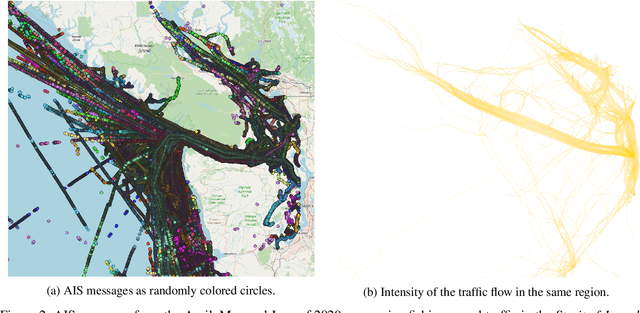

Automatic Identification System (AIS) messages are useful for tracking vessel activity across oceans worldwide using radio links and satellite transceivers. Such data plays a significant role in tracking vessel activity and mapping mobility patterns such as those found in fishing. Accordingly, this paper proposes a geometric-driven semi-supervised approach for fishing activity detection from AIS data. Through the proposed methodology we show how to explore the information included in the messages to extract features describing the geometry of the vessel route. To this end, we leverage the unsupervised nature of cluster analysis to label the trajectory geometry highlighting the changes in the vessel's moving pattern which tends to indicate fishing activity. The labels obtained by the proposed unsupervised approach are used to detect fishing activities, which we approach as a time-series classification task. In this context, we propose a solution using recurrent neural networks on AIS data streams with roughly 87% of the overall $F$-score on the whole trajectories of 50 different unseen fishing vessels. Such results are accompanied by a broad benchmark study assessing the performance of different Recurrent Neural Network (RNN) architectures. In conclusion, this work contributes by proposing a thorough process that includes data preparation, labeling, data modeling, and model validation. Therefore, we present a novel solution for mobility pattern detection that relies upon unfolding the trajectory in time and observing their inherent geometry.
ASTA: Learning Analytical Semantics over Tables for Intelligent Data Analysis and Visualization
Aug 08, 2022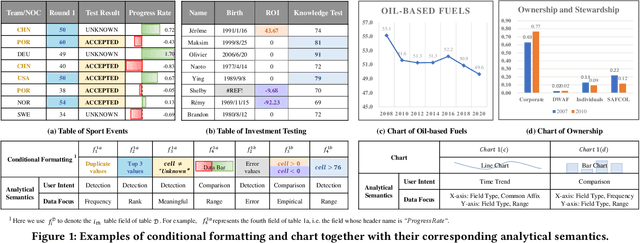

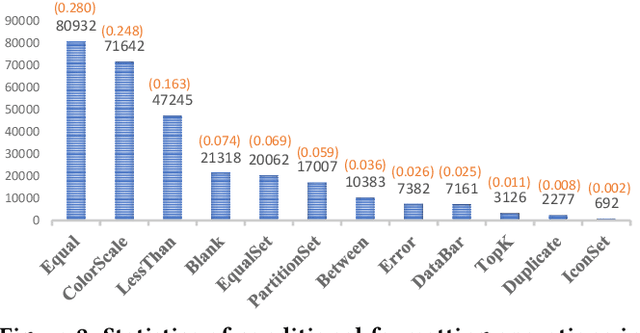
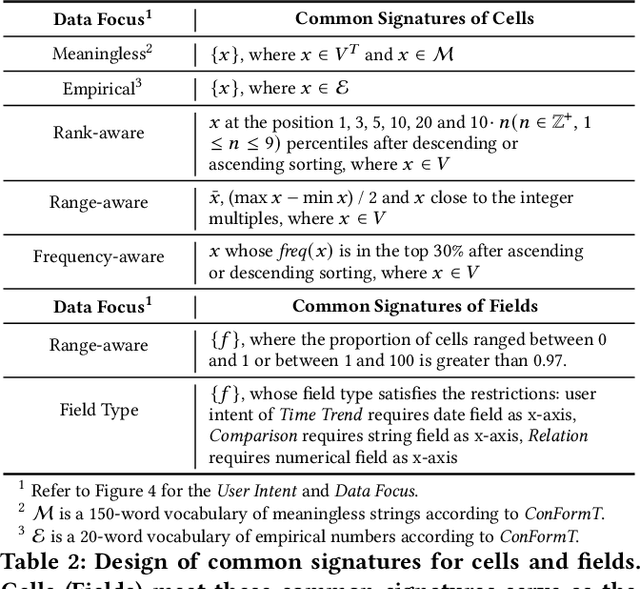
Intelligent analysis and visualization of tables use techniques to automatically recommend useful knowledge from data, thus freeing users from tedious multi-dimension data mining. While many studies have succeeded in automating recommendations through rules or machine learning, it is difficult to generalize expert knowledge and provide explainable recommendations. In this paper, we present the recommendation of conditional formatting for the first time, together with chart recommendation, to exemplify intelligent table analysis. We propose analytical semantics over tables to uncover common analysis pattern behind user-created analyses. Here, we design analytical semantics by separating data focus from user intent, which extract the user motivation from data and human perspective respectively. Furthermore, the ASTA framework is designed by us to apply analytical semantics to multiple automated recommendations. ASTA framework extracts data features by designing signatures based on expert knowledge, and enables data referencing at field- (chart) or cell-level (conditional formatting) with pre-trained models. Experiments show that our framework achieves recall at top 1 of 62.86% on public chart corpora, outperforming the best baseline about 14%, and achieves 72.31% on the collected corpus ConFormT, validating that ASTA framework is effective in providing accurate and explainable recommendations.
TsFeX: Contact Tracing Model using Time Series Feature Extraction and Gradient Boosting
Dec 04, 2021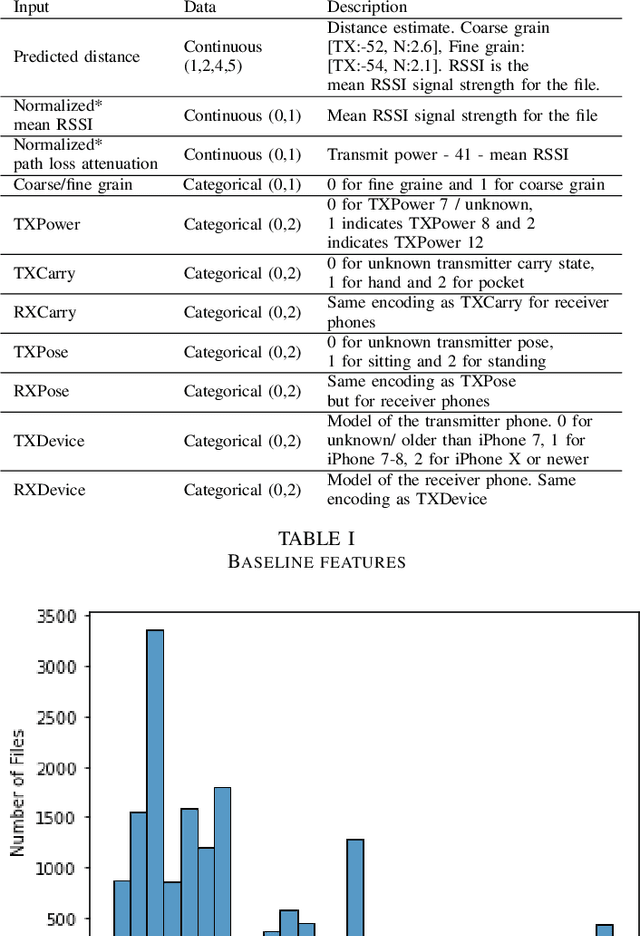
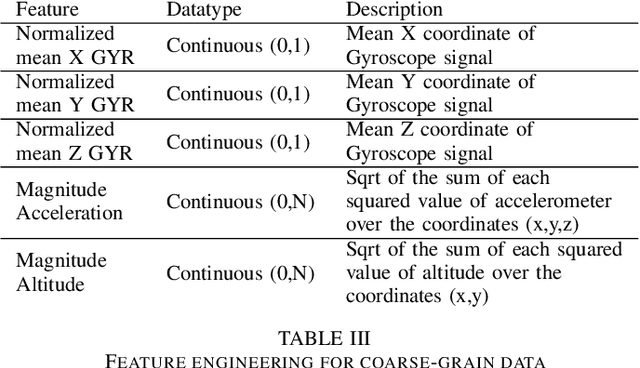
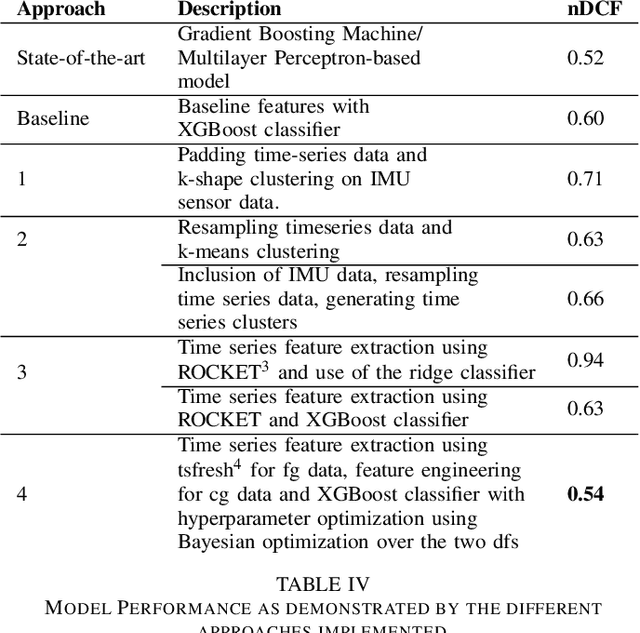
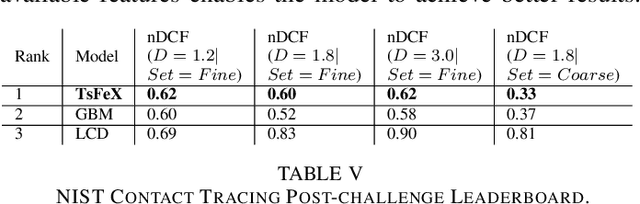
With the outbreak of COVID-19 pandemic, a dire need to effectively identify the individuals who may have come in close-contact to others who have been infected with COVID-19 has risen. This process of identifying individuals, also termed as 'Contact tracing', has significant implications for the containment and control of the spread of this virus. However, manual tracing has proven to be ineffective calling for automated contact tracing approaches. As such, this research presents an automated machine learning system for identifying individuals who may have come in contact with others infected with COVID-19 using sensor data transmitted through handheld devices. This paper describes the different approaches followed in arriving at an optimal solution model that effectually predicts whether a person has been in close proximity to an infected individual using a gradient boosting algorithm and time series feature extraction.
Application of Long Short-Term Memory Recurrent Neural Networks Based on the BAT-MCS for Binary-State Network Approximated Time-Dependent Reliability Problems
Feb 16, 2022
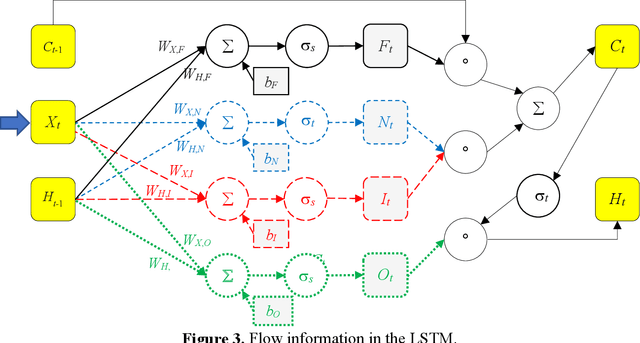
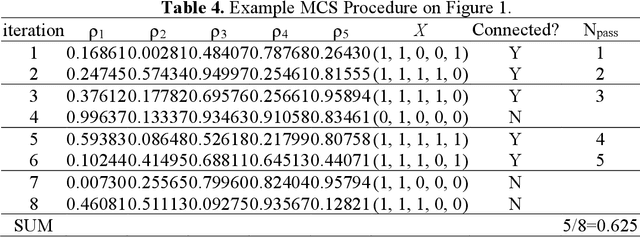
Reliability is an important tool for evaluating the performance of modern networks. Currently, it is NP-hard and #P-hard to calculate the exact reliability of a binary-state network when the reliability of each component is assumed to be fixed. However, this assumption is unrealistic because the reliability of each component always varies with time. To meet this practical requirement, we propose a new algorithm called the LSTM-BAT-MCS, based on long short-term memory (LSTM), the Monte Carlo simulation (MCS), and the binary-adaption-tree algorithm (BAT). The superiority of the proposed LSTM-BAT-MCS was demonstrated by experimental results of three benchmark networks with at most 10-4 mean square error.
Learning to Coordinate for a Worker-Station Multi-robot System in Planar Coverage Tasks
Aug 05, 2022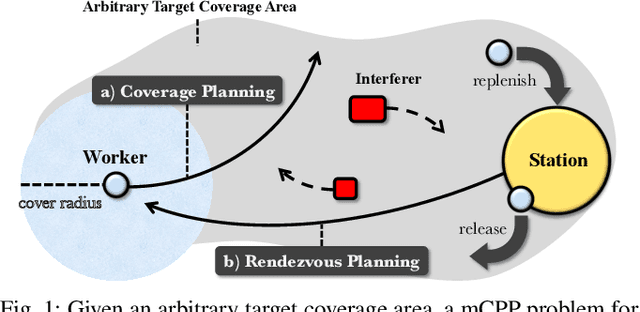
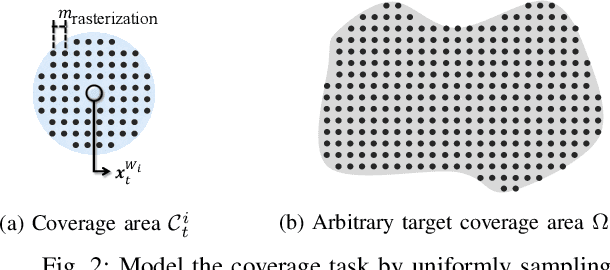
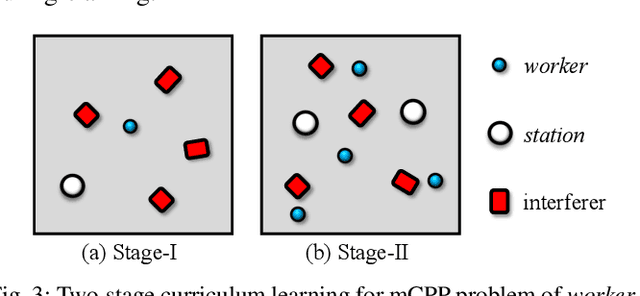
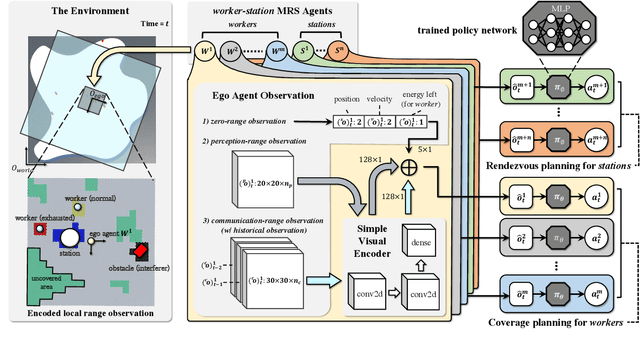
For massive large-scale tasks, a multi-robot system (MRS) can effectively improve efficiency by utilizing each robot's different capabilities, mobility, and functionality. In this paper, we focus on the multi-robot coverage path planning (mCPP) problem in large-scale planar areas with random dynamic interferers in the environment, where the robots have limited resources. We introduce a worker-station MRS consisting of multiple workers with limited resources for actual work, and one station with enough resources for resource replenishment. We aim to solve the mCPP problem for the worker-station MRS by formulating it as a fully cooperative multi-agent reinforcement learning problem. Then we propose an end-to-end decentralized online planning method, which simultaneously solves coverage planning for workers and rendezvous planning for station. Our method manages to reduce the influence of random dynamic interferers on planning, while the robots can avoid collisions with them. We conduct simulation and real robot experiments, and the comparison results show that our method has competitive performance in solving the mCPP problem for worker-station MRS in metric of task finish time.
A Deep-Learning Usability Expansion Model of Ocean Observations
Jun 03, 2022
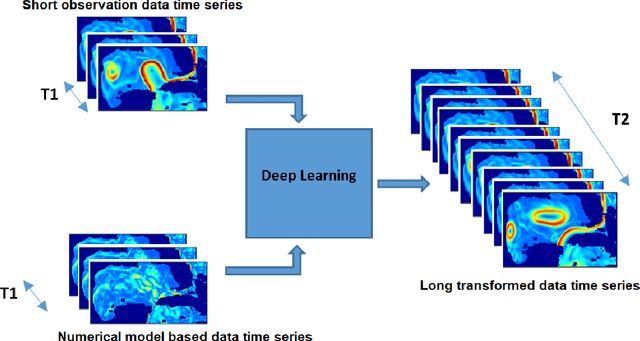
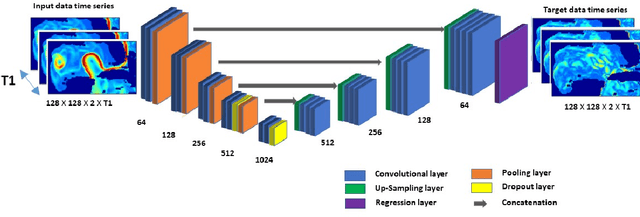
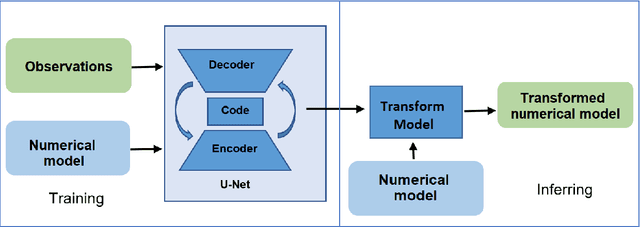
Today's ocean numerical prediction skills depend on the availability of in-situ and remote ocean observations at the time of the predictions only. Because observations are scarce and discontinuous in time and space, numerical models are often unable to accurately model and predict real ocean dynamics, leading to a lack of fulfillment of a range of services that require reliable predictions at various temporal and spatial scales. The process of constraining free numerical models with observations is known as data assimilation. The primary objective is to minimize the misfit of model states with the observations while respecting the rules of physics. The caveat of this approach is that measurements are used only once, at the time of the prediction. The information contained in the history of the measurements and its role in the determinism of the prediction is, therefore, not accounted for. Consequently, historical measurement cannot be used in real-time forecasting systems. The research presented in this paper provides a novel approach rooted in artificial intelligence to expand the usability of observations made before the time of the prediction. Our approach is based on the re-purpose of an existing deep learning model, called U-Net, designed specifically for image segmentation analysis in the biomedical field. U-Net is used here to create a Transform Model that retains the temporal and spatial evolution of the differences between model and observations to produce a correction in the form of regression weights that evolves spatially and temporally with the model both forward and backward in time, beyond the observation period. Using virtual observations, we show that the usability of the observation can be extended up to a one year prior or post observations.
Two-Step mmWave Positioning Scheme with RIS-Part II: Position Estimation and Error Analysis
Aug 16, 2022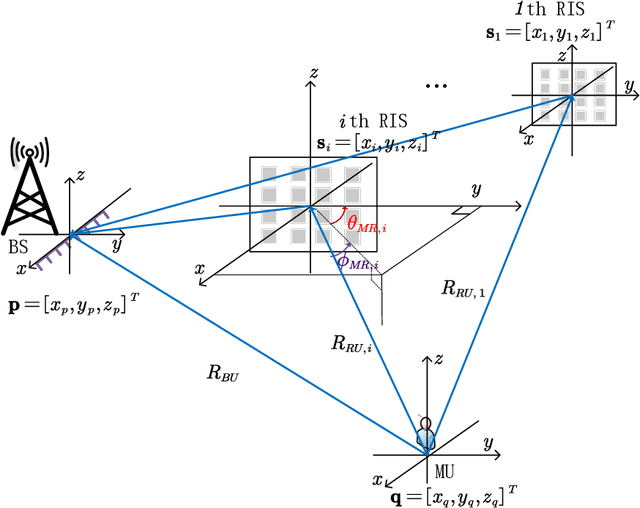
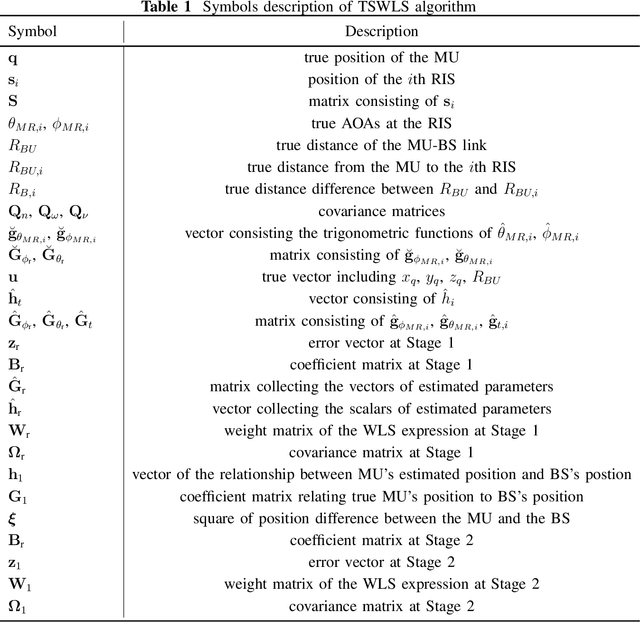
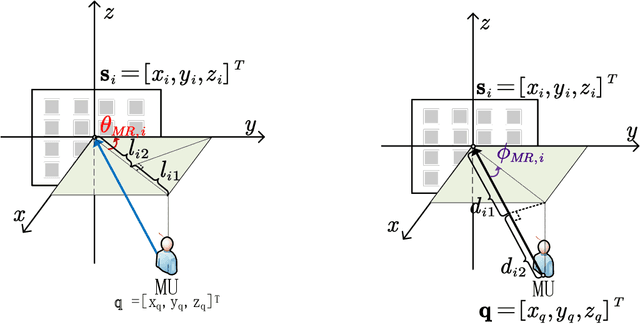
In this series of work, we propose a comprehensive two-step three-dimensional (3D) positioning scheme in a millimeter wave (mmWave) system, where the reconfigurable intelligent surface (RIS) is leveraged to enhance the positioning performance of mobile users (MUs). Specifically, the first step is the estimation error modeling and analysis, while the second step is the corresponding positioning algorithm design and bias analysis. The first step is introduced in Part I of this series of work, and the second step is investigated in this paper. Our aim in this series of work is to obtain the closed-form solution of the MU's position through a two-stage weight least square (TSWLS) algorithm. In the first stage, we construct the pseudolinear equations based on the angle of arrival (AOA) and the time difference of arrival (TDOA) estimation at the RISs, then we obtain a preliminary estimation by solving these equations using the weight least square (WLS) method. Based on the preliminary estimation in the first stage, a new set of pseudolinear equations are obtained, and a finer estimation is obtained by solving the equations using the WLS method in the second stage. By combining the estimation of both stages, the final estimation of the MU's position is obtained. Further, we study the theoretical bias of the proposed algorithm by considering the estimation error in both stages. Simulation results demonstrate the superiority of the proposed positioning scheme.
State Supervised Steering Function for Sampling-based Kinodynamic Planning
Jun 15, 2022

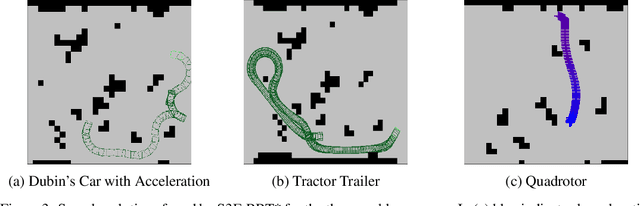
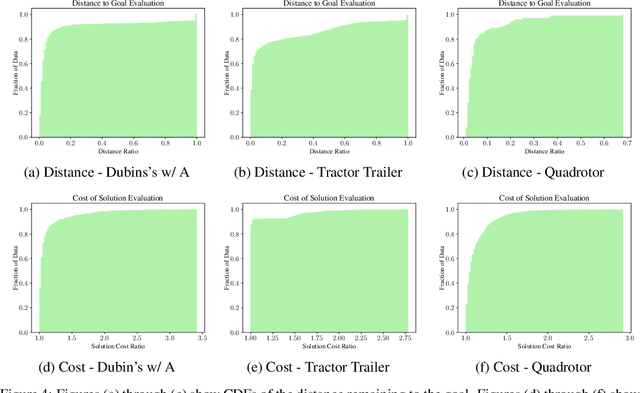
Sampling-based motion planners such as RRT* and BIT*, when applied to kinodynamic motion planning, rely on steering functions to generate time-optimal solutions connecting sampled states. Implementing exact steering functions requires either analytical solutions to the time-optimal control problem, or nonlinear programming (NLP) solvers to solve the boundary value problem given the system's kinodynamic equations. Unfortunately, analytical solutions are unavailable for many real-world domains, and NLP solvers are prohibitively computationally expensive, hence fast and optimal kinodynamic motion planning remains an open problem. We provide a solution to this problem by introducing State Supervised Steering Function (S3F), a novel approach to learn time-optimal steering functions. S3F is able to produce near-optimal solutions to the steering function orders of magnitude faster than its NLP counterpart. Experiments conducted on three challenging robot domains show that RRT* using S3F significantly outperforms state-of-the-art planning approaches on both solution cost and runtime. We further provide a proof of probabilistic completeness of RRT* modified to use S3F.
Learning to Generate 3D Shapes from a Single Example
Aug 05, 2022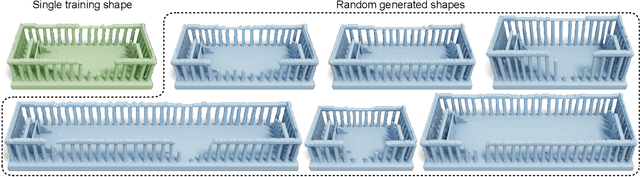
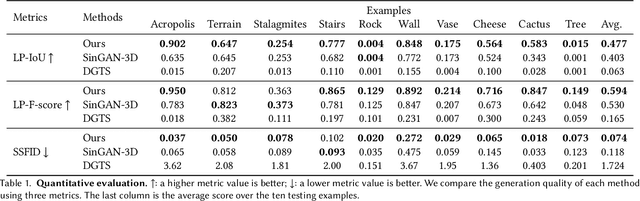
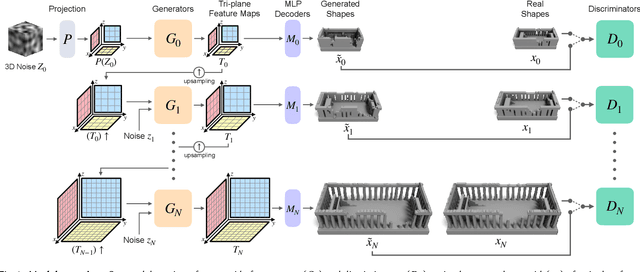
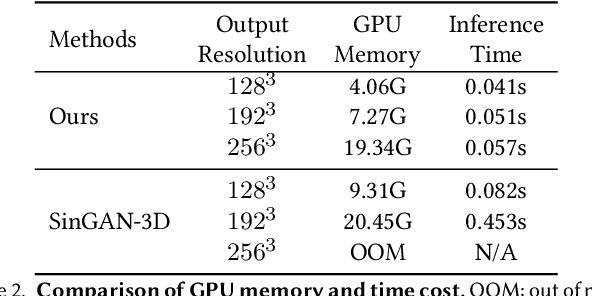
Existing generative models for 3D shapes are typically trained on a large 3D dataset, often of a specific object category. In this paper, we investigate the deep generative model that learns from only a single reference 3D shape. Specifically, we present a multi-scale GAN-based model designed to capture the input shape's geometric features across a range of spatial scales. To avoid large memory and computational cost induced by operating on the 3D volume, we build our generator atop the tri-plane hybrid representation, which requires only 2D convolutions. We train our generative model on a voxel pyramid of the reference shape, without the need of any external supervision or manual annotation. Once trained, our model can generate diverse and high-quality 3D shapes possibly of different sizes and aspect ratios. The resulting shapes present variations across different scales, and at the same time retain the global structure of the reference shape. Through extensive evaluation, both qualitative and quantitative, we demonstrate that our model can generate 3D shapes of various types.
XInsight: eXplainable Data Analysis Through The Lens of Causality
Aug 05, 2022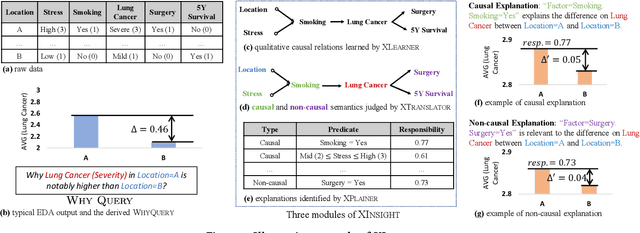


In light of the growing popularity of Exploratory Data Analysis (EDA), understanding the underlying causes of the knowledge acquired by EDA is crucial, but remains under-researched. This study promotes for the first time a transparent and explicable perspective on data analysis, called eXplainable Data Analysis (XDA). XDA provides data analysis with qualitative and quantitative explanations of causal and non-causal semantics. This way, XDA will significantly improve human understanding and confidence in the outcomes of data analysis, facilitating accurate data interpretation and decision-making in the real world. For this purpose, we present XInsight, a general framework for XDA. XInsight is a three-module, end-to-end pipeline designed to extract causal graphs, translate causal primitives into XDA semantics, and quantify the quantitative contribution of each explanation to a data fact. XInsight uses a set of design concepts and optimizations to address the inherent difficulties associated with integrating causality into XDA. Experiments on synthetic and real-world datasets as well as human evaluations demonstrate the highly promising capabilities of XInsight.