 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
FADNet++: Real-Time and Accurate Disparity Estimation with Configurable Networks
Oct 06, 2021
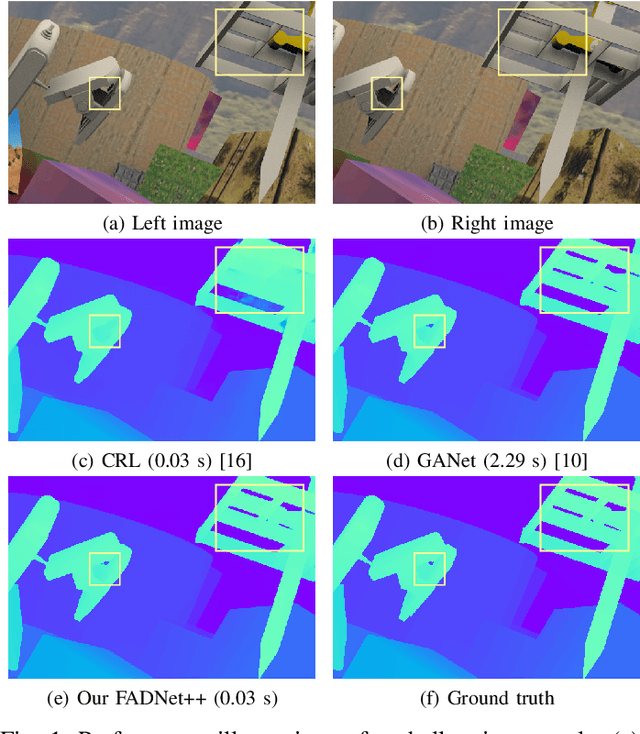
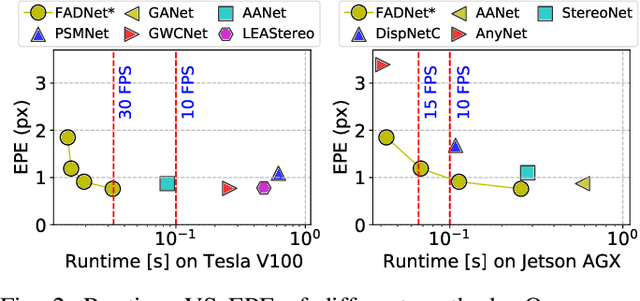
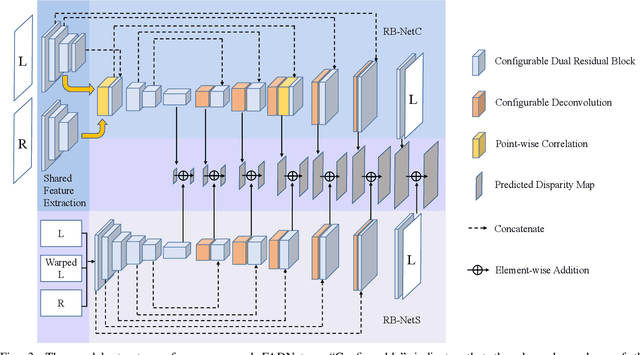
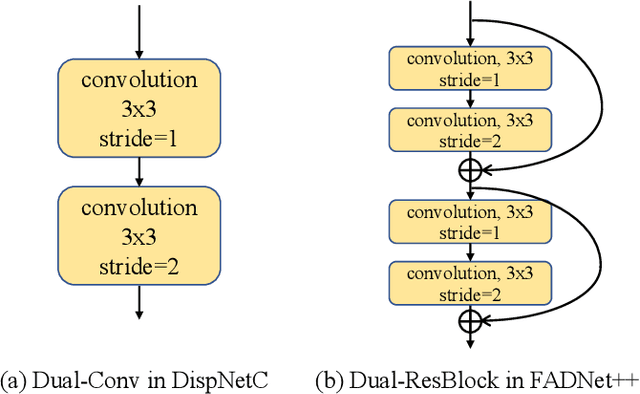
Deep neural networks (DNNs) have achieved great success in the area of computer vision. The disparity estimation problem tends to be addressed by DNNs which achieve much better prediction accuracy than traditional hand-crafted feature-based methods. However, the existing DNNs hardly serve both efficient computation and rich expression capability, which makes them difficult for deployment in real-time and high-quality applications, especially on mobile devices. To this end, we propose an efficient, accurate, and configurable deep network for disparity estimation named FADNet++. Leveraging several liberal network design and training techniques, FADNet++ can boost its accuracy with a fast model inference speed for real-time applications. Besides, it enables users to easily configure different sizes of models for balancing accuracy and inference efficiency. We conduct extensive experiments to demonstrate the effectiveness of FADNet++ on both synthetic and realistic datasets among six GPU devices varying from server to mobile platforms. Experimental results show that FADNet++ and its variants achieve state-of-the-art prediction accuracy, and run at a significant order of magnitude faster speed than existing 3D models. With the constraint of running at above 15 frames per second (FPS) on a mobile GPU, FADNet++ achieves a new state-of-the-art result for the SceneFlow dataset.
Generative adversarial networks in time series: A survey and taxonomy
Jul 23, 2021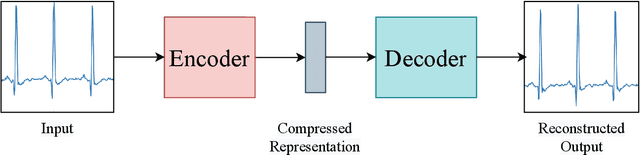
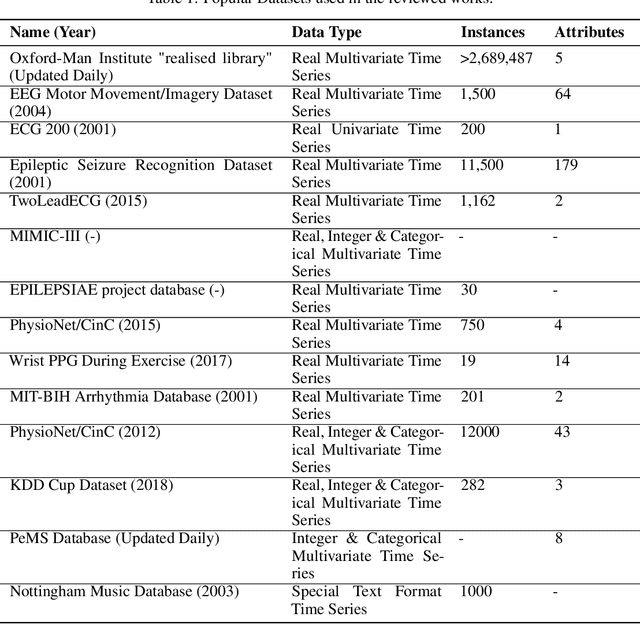
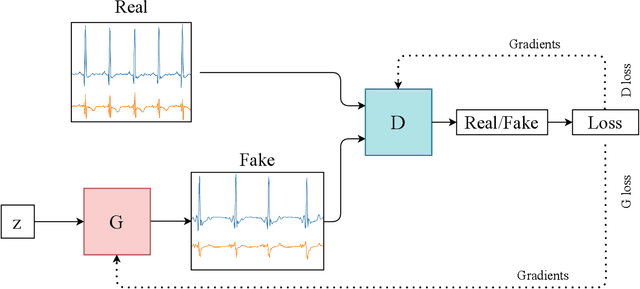
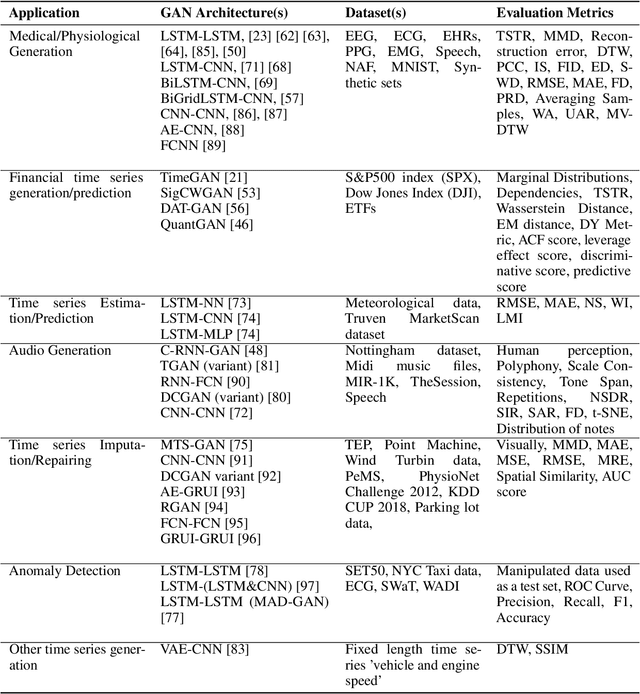
Generative adversarial networks (GANs) studies have grown exponentially in the past few years. Their impact has been seen mainly in the computer vision field with realistic image and video manipulation, especially generation, making significant advancements. While these computer vision advances have garnered much attention, GAN applications have diversified across disciplines such as time series and sequence generation. As a relatively new niche for GANs, fieldwork is ongoing to develop high quality, diverse and private time series data. In this paper, we review GAN variants designed for time series related applications. We propose a taxonomy of discrete-variant GANs and continuous-variant GANs, in which GANs deal with discrete time series and continuous time series data. Here we showcase the latest and most popular literature in this field; their architectures, results, and applications. We also provide a list of the most popular evaluation metrics and their suitability across applications. Also presented is a discussion of privacy measures for these GANs and further protections and directions for dealing with sensitive data. We aim to frame clearly and concisely the latest and state-of-the-art research in this area and their applications to real-world technologies.
Planning and Scheduling in Digital Health with Answer Set Programming
Aug 05, 2022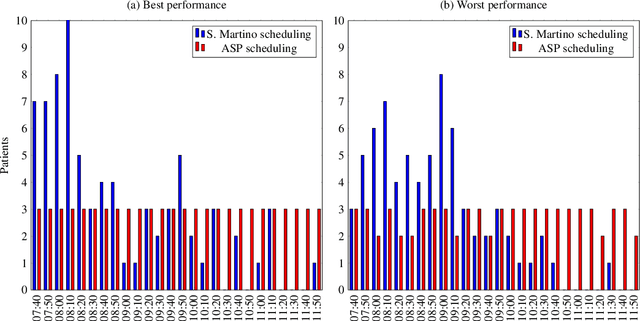
In the hospital world there are several complex combinatory problems, and solving these problems is important to increase the degree of patients' satisfaction and the quality of care offered. The problems in the healthcare are complex since to solve them several constraints and different type of resources should be taken into account. Moreover, the solutions must be evaluated in a small amount of time to ensure the usability in real scenarios. We plan to propose solutions to these kind of problems both expanding already tested solutions and by modelling solutions for new problems, taking into account the literature and by using real data when available. Solving these kind of problems is important but, since the European Commission established with the General Data Protection Regulation that each person has the right to ask for explanation of the decision taken by an AI, without developing Explainability methodologies the usage of AI based solvers e.g. those based on Answer Set programming will be limited. Thus, another part of the research will be devoted to study and propose new methodologies for explaining the solutions obtained.
* In Proceedings ICLP 2022, arXiv:2208.02685
Local Strong Convexity of Source Localization and Error Bound for Target Tracking under Time-of-Arrival Measurements
Dec 21, 2021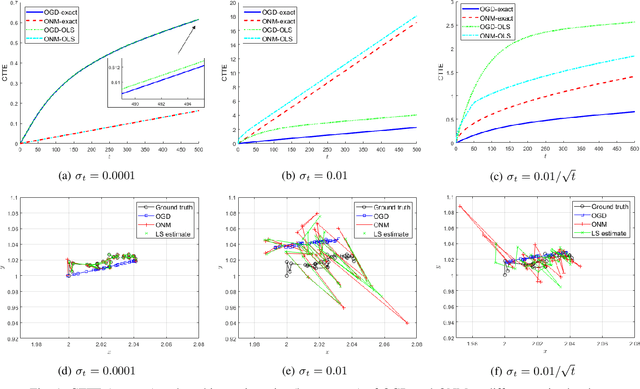
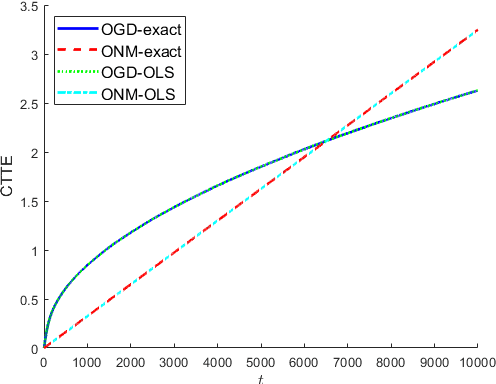
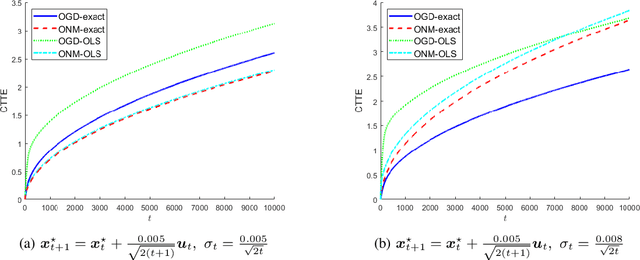
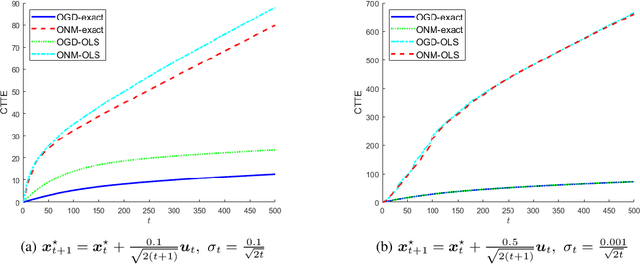
In this paper, we consider a time-varying optimization approach to the problem of tracking a moving target using noisy time-of-arrival (TOA) measurements. Specifically, we formulate the problem as that of sequential TOA-based source localization and apply online gradient descent (OGD) to it to generate the position estimates of the target. To analyze the tracking performance of OGD, we first revisit the classic least-squares formulation of the (static) TOA-based source localization problem and elucidate its estimation and geometric properties. In particular, under standard assumptions on the TOA measurement model, we establish a bound on the distance between an optimal solution to the least-squares formulation and the true target position. Using this bound, we show that the loss function in the formulation, albeit non-convex in general, is locally strongly convex at its global minima. To the best of our knowledge, these results are new and can be of independent interest. By combining them with existing techniques from online strongly convex optimization, we then establish the first non-trivial bound on the cumulative target tracking error of OGD. Our numerical results corroborate the theoretical findings and show that OGD can effectively track the target at different noise levels.
Friendly Noise against Adversarial Noise: A Powerful Defense against Data Poisoning Attacks
Aug 14, 2022
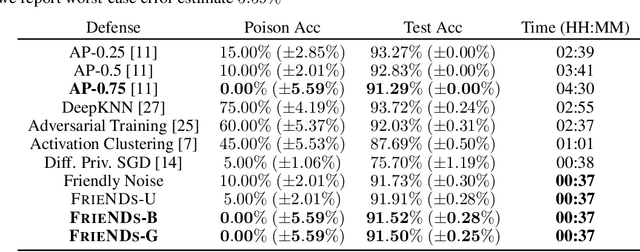
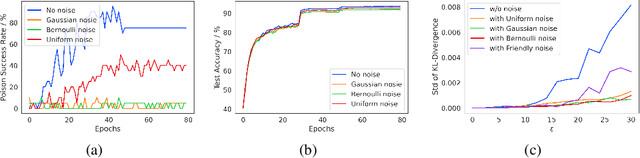
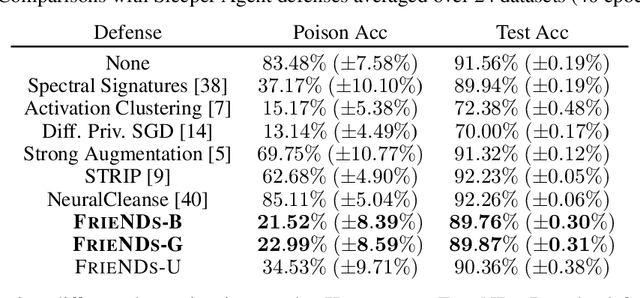
A powerful category of data poisoning attacks modify a subset of training examples by small adversarial perturbations to change the prediction of certain test-time data. Existing defense mechanisms are not desirable to deploy in practice, as they often drastically harm the generalization performance, or are attack-specific and prohibitively slow to apply. Here, we propose a simple but highly effective approach that unlike existing methods breaks various types of poisoning attacks with the slightest drop in the generalization performance. We make the key observation that attacks exploit sharp loss regions to craft adversarial perturbations which can substantially alter examples' gradient or representations under small perturbations. To break poisoning attacks, our approach comprises two components: an optimized friendly noise that is generated to maximally perturb examples without degrading the performance, and a random varying noise component. The first component takes examples farther away from the sharp loss regions, and the second component smooths out the loss landscape. The combination of both components builds a very light-weight but extremely effective defense against the most powerful triggerless targeted and hidden-trigger backdoor poisoning attacks, including Gradient Matching, Bulls-eye Polytope, and Sleeper Agent. We show that our friendly noise is transferable to other architectures, and adaptive attacks cannot break our defense due to its random noise component.
Conformal Prediction with Temporal Quantile Adjustments
May 23, 2022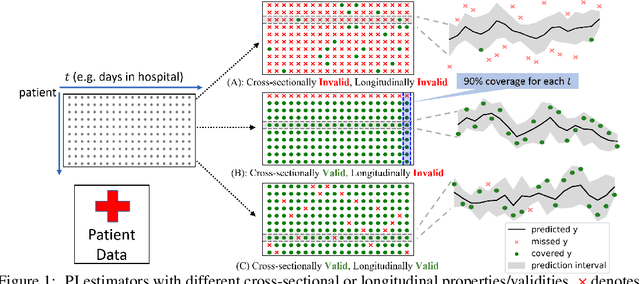
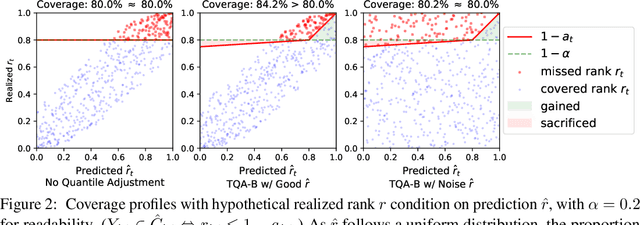
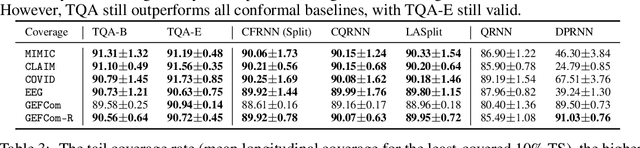
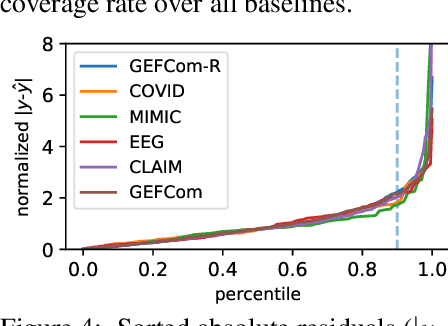
We develop Temporal Quantile Adjustment (TQA), a general method to construct efficient and valid prediction intervals (PIs) for regression on cross-sectional time series data. Such data is common in many domains, including econometrics and healthcare. A canonical example in healthcare is predicting patient outcomes using physiological time-series data, where a population of patients composes a cross-section. Reliable PI estimators in this setting must address two distinct notions of coverage: cross-sectional coverage across a cross-sectional slice, and longitudinal coverage along the temporal dimension for each time series. Recent works have explored adapting Conformal Prediction (CP) to obtain PIs in the time series context. However, none handles both notions of coverage simultaneously. CP methods typically query a pre-specified quantile from the distribution of nonconformity scores on a calibration set. TQA adjusts the quantile to query in CP at each time $t$, accounting for both cross-sectional and longitudinal coverage in a theoretically-grounded manner. The post-hoc nature of TQA facilitates its use as a general wrapper around any time series regression model. We validate TQA's performance through extensive experimentation: TQA generally obtains efficient PIs and improves longitudinal coverage while preserving cross-sectional coverage.
Fast Offline Policy Optimization for Large Scale Recommendation
Aug 11, 2022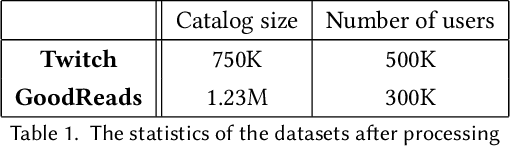
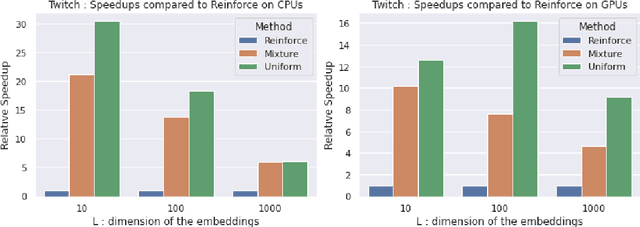
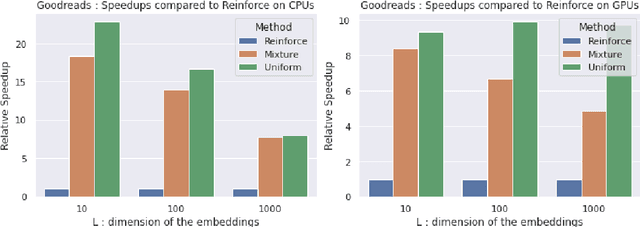
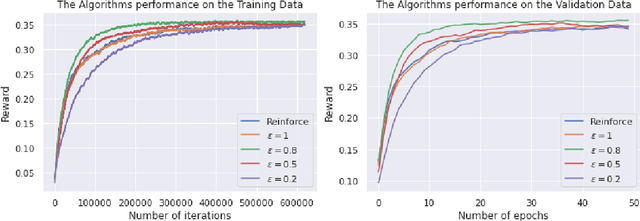
Personalised interactive systems such as recommender systems require selecting relevant items dependent on context. Production systems need to identify the items rapidly from very large catalogues which can be efficiently solved using maximum inner product search technology. Offline optimisation of maximum inner product search can be achieved by a relaxation of the discrete problem resulting in policy learning or reinforce style learning algorithms. Unfortunately this relaxation step requires computing a sum over the entire catalogue making the complexity of the evaluation of the gradient (and hence each stochastic gradient descent iterations) linear in the catalogue size. This calculation is untenable in many real world examples such as large catalogue recommender systems severely limiting the usefulness of this method in practice. In this paper we show how it is possible to produce an excellent approximation of these policy learning algorithms that scale logarithmically with the catalogue size. Our contribution is based upon combining three novel ideas: a new Monte Carlo estimate of the gradient of a policy, the self normalised importance sampling estimator and the use of fast maximum inner product search at training time. Extensive experiments show our algorithm is an order of magnitude faster than naive approaches yet produces equally good policies.
Sequential Recommendation Model for Next Purchase Prediction
Jul 06, 2022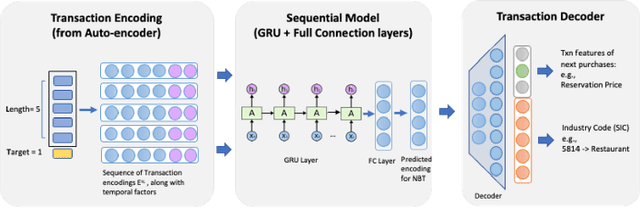

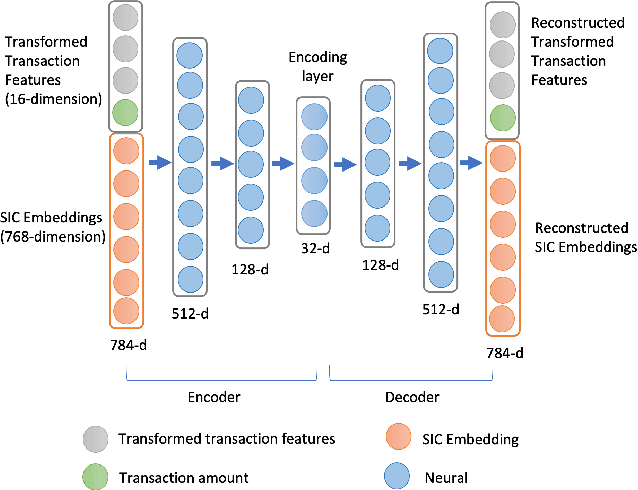

Timeliness and contextual accuracy of recommendations are increasingly important when delivering contemporary digital marketing experiences. Conventional recommender systems (RS) suggest relevant but time-invariant items to users by accounting for their past purchases. These recommendations only map to customers' general preferences rather than a customer's specific needs immediately preceding a purchase. In contrast, RSs that consider the order of transactions, purchases, or experiences to measure evolving preferences can offer more salient and effective recommendations to customers: Sequential RSs not only benefit from a better behavioral understanding of a user's current needs but also better predictive power. In this paper, we demonstrate and rank the effectiveness of a sequential recommendation system by utilizing a production dataset of over 2.7 million credit card transactions for 46K cardholders. The method first employs an autoencoder on raw transaction data and submits observed transaction encodings to a GRU-based sequential model. The sequential model produces a MAP@1 metric of 47% on the out-of-sample test set, in line with existing research. We also discuss implications for embedding real-time predictions using the sequential RS into Nexus, a scalable, low-latency, event-based digital experience architecture.
FLOWGEN: Fast and slow graph generation
Jul 15, 2022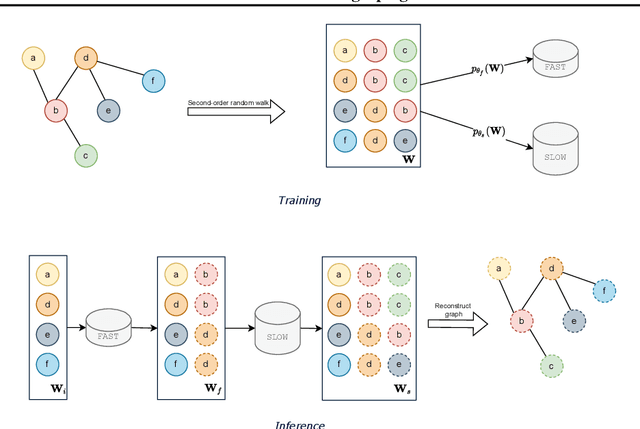

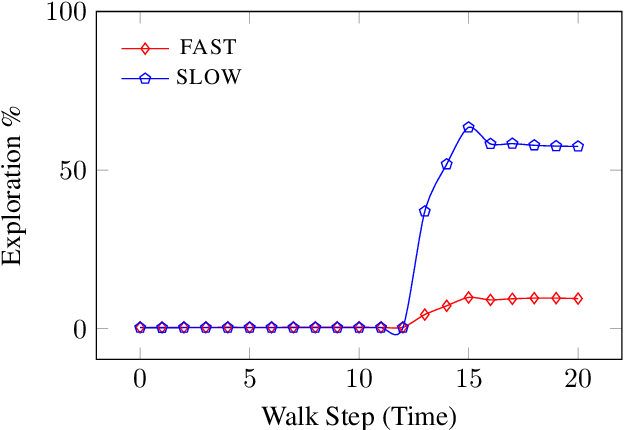

We present FLOWGEN, a graph-generation model inspired by the dual-process theory of mind that generates large graphs incrementally. Depending on the difficulty of completing the graph at the current step, graph generation is routed to either a fast~(weaker) or a slow~(stronger) model. fast and slow models have identical architectures, but vary in the number of parameters and consequently the strength. Experiments on real-world graphs show that ours can successfully generate graphs similar to those generated by a single large model in a fraction of time.
Self-supervised Transformer for Multivariate Clinical Time-Series with Missing Values
Jul 29, 2021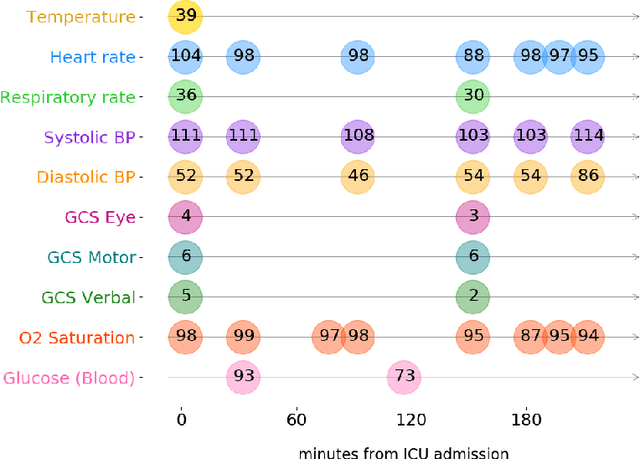
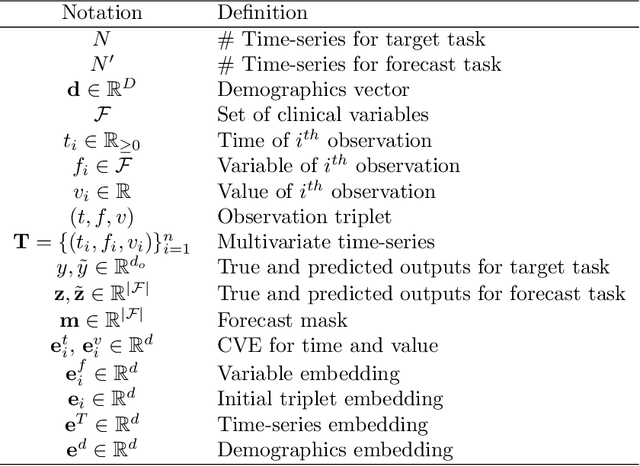
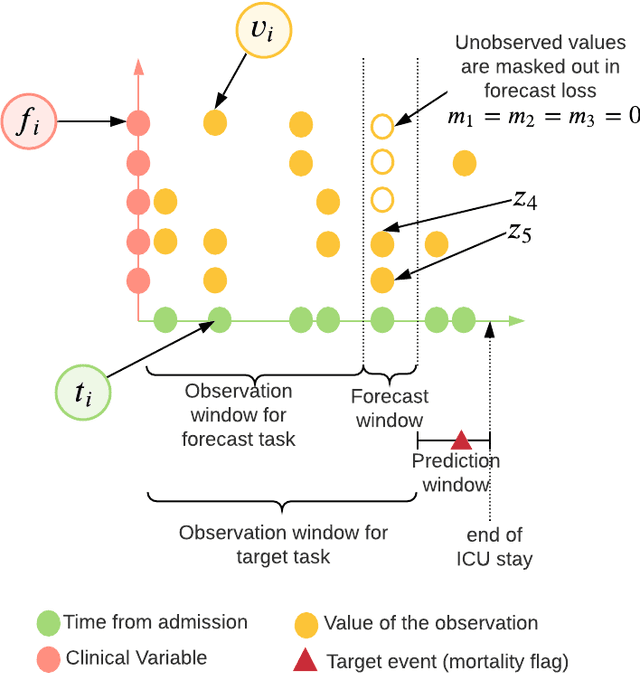
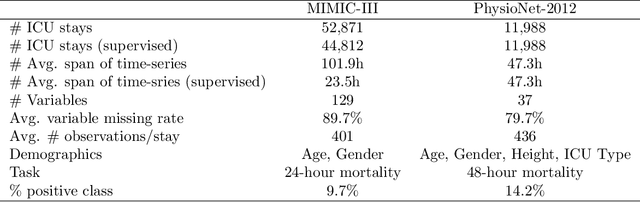
Multivariate time-series (MVTS) data are frequently observed in critical care settings and are typically characterized by excessive missingness and irregular time intervals. Existing approaches for learning representations in this domain handle such issues by either aggregation or imputation of values, which in-turn suppresses the fine-grained information and adds undesirable noise/overhead into the machine learning model. To tackle this challenge, we propose STraTS (Self-supervised Transformer for TimeSeries) model which bypasses these pitfalls by treating time-series as a set of observation triplets instead of using the traditional dense matrix representation. It employs a novel Continuous Value Embedding (CVE) technique to encode continuous time and variable values without the need for discretization. It is composed of a Transformer component with Multi-head attention layers which enables it to learn contextual triplet embeddings while avoiding problems of recurrence and vanishing gradients that occur in recurrent architectures. Many healthcare datasets also suffer from the limited availability of labeled data. Our model utilizes self-supervision by leveraging unlabeled data to learn better representations by performing time-series forecasting as a self-supervision task. Experiments on real-world multivariate clinical time-series benchmark datasets show that STraTS shows better prediction performance than state-of-the-art methods for mortality prediction, especially when labeled data is limited. Finally, we also present an interpretable version of STraTS which can identify important measurements in the time-series data.