 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Continual Machine Reading Comprehension via Uncertainty-aware Fixed Memory and Adversarial Domain Adaptation
Aug 10, 2022
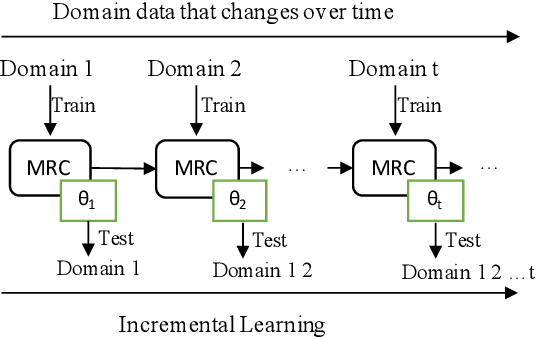
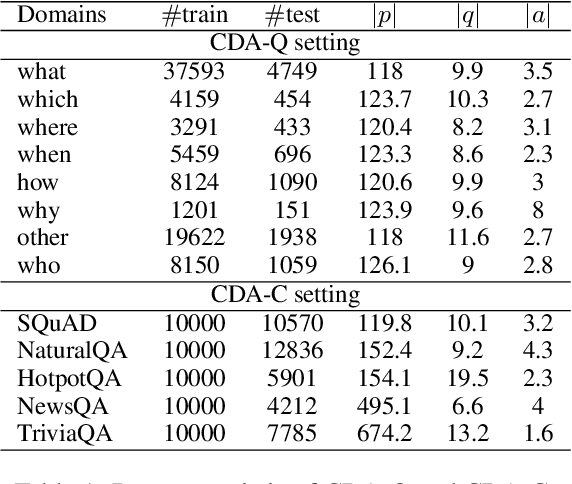
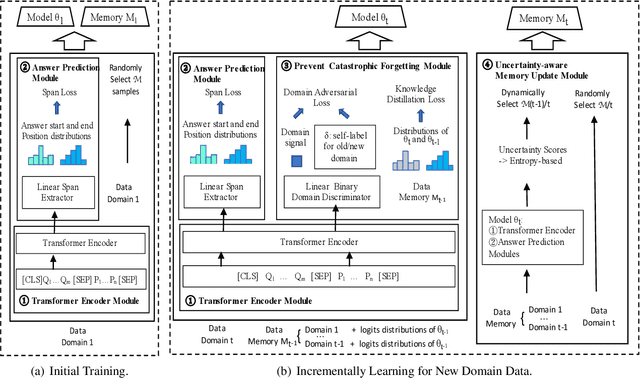
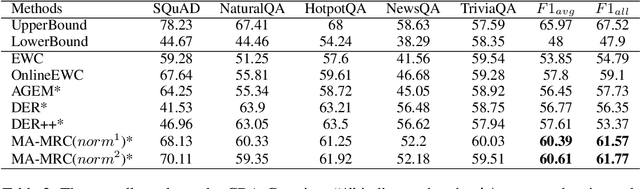
Continual Machine Reading Comprehension aims to incrementally learn from a continuous data stream across time without access the previous seen data, which is crucial for the development of real-world MRC systems. However, it is a great challenge to learn a new domain incrementally without catastrophically forgetting previous knowledge. In this paper, MA-MRC, a continual MRC model with uncertainty-aware fixed Memory and Adversarial domain adaptation, is proposed. In MA-MRC, a fixed size memory stores a small number of samples in previous domain data along with an uncertainty-aware updating strategy when new domain data arrives. For incremental learning, MA-MRC not only keeps a stable understanding by learning both memory and new domain data, but also makes full use of the domain adaptation relationship between them by adversarial learning strategy. The experimental results show that MA-MRC is superior to strong baselines and has a substantial incremental learning ability without catastrophically forgetting under two different continual MRC settings.
Environment-Aware Hybrid Beamforming by Leveraging Channel Knowledge Map
Jun 17, 2022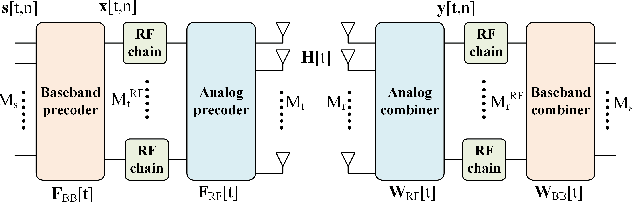
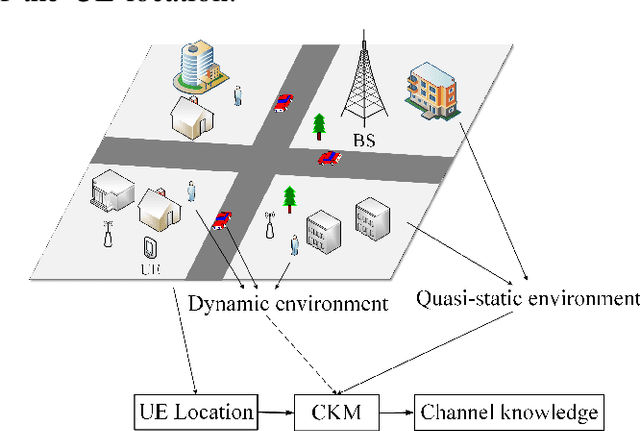
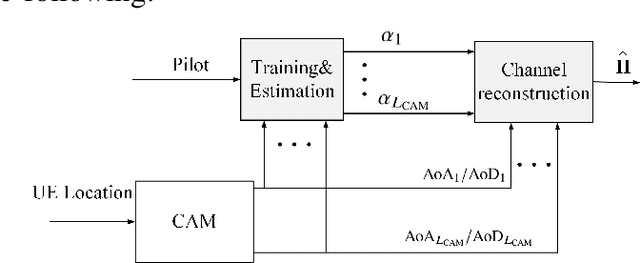
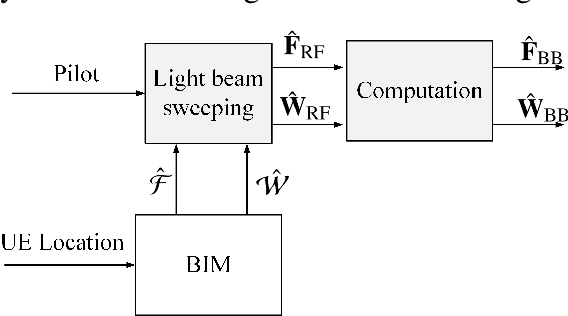
Hybrid analog/digital beamforming is a promising technique to realize millimeter wave (mmWave) massive multiple-input multiple-output (MIMO) systems cost-effectively. However, existing hybrid beamforming designs mainly rely on real-time channel training or beam sweeping to find the desired beams, which incurs prohibitive overhead due to a large number of antennas at both the transmitter and receiver with only limited radio frequency (RF) chains. To resolve this challenging issue, in this paper, we propose a new environment-aware hybrid beamforming technique that requires only light real-time training, by leveraging the useful tool of channel knowledge map (CKM) with the user's location information. CKM is a site-specific database, which offers location-specific channel-relevant information to facilitate or even obviate the acquisition of real-time channel state information (CSI). Two specific types of CKM are proposed in this paper for hybrid beamforming design in mmWave massive MIMO systems, namely channel angle map (CAM) and beam index map (BIM). It is shown that compared with existing environment-unaware schemes, the proposed environment-aware hybrid beamforming scheme based on CKM can drastically improve the effective communication rate, even under moderate user location errors, thanks to its great saving of the prohibitive real-time training overhead.
Quantum-Inspired Tensor Neural Networks for Partial Differential Equations
Aug 10, 2022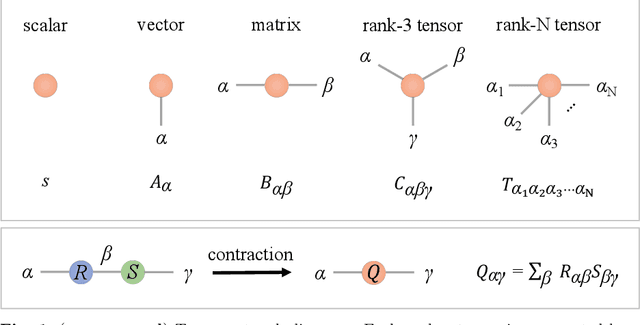
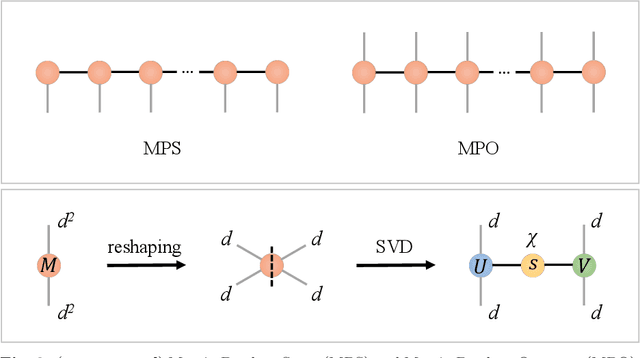
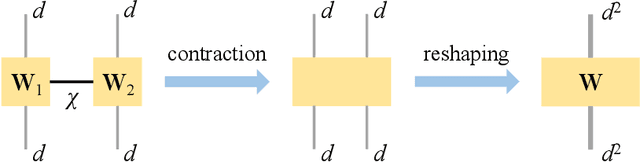
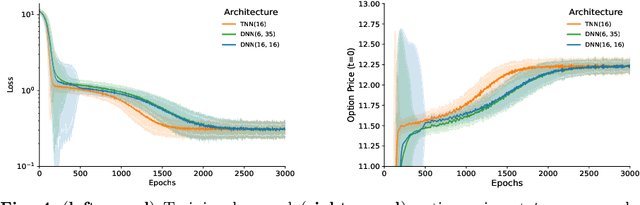
Partial Differential Equations (PDEs) are used to model a variety of dynamical systems in science and engineering. Recent advances in deep learning have enabled us to solve them in a higher dimension by addressing the curse of dimensionality in new ways. However, deep learning methods are constrained by training time and memory. To tackle these shortcomings, we implement Tensor Neural Networks (TNN), a quantum-inspired neural network architecture that leverages Tensor Network ideas to improve upon deep learning approaches. We demonstrate that TNN provide significant parameter savings while attaining the same accuracy as compared to the classical Dense Neural Network (DNN). In addition, we also show how TNN can be trained faster than DNN for the same accuracy. We benchmark TNN by applying them to solve parabolic PDEs, specifically the Black-Scholes-Barenblatt equation, widely used in financial pricing theory, empirically showing the advantages of TNN over DNN. Further examples, such as the Hamilton-Jacobi-Bellman equation, are also discussed.
KEEP: An Industrial Pre-Training Framework for Online Recommendation via Knowledge Extraction and Plugging
Aug 22, 2022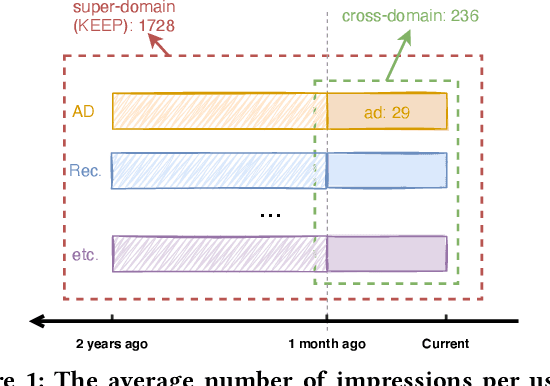

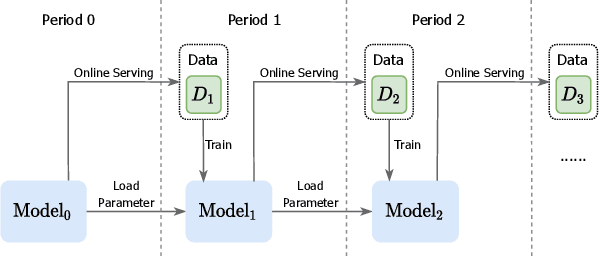
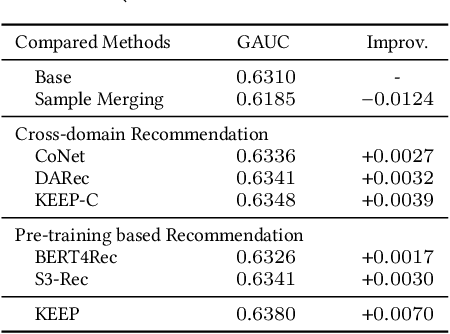
An industrial recommender system generally presents a hybrid list that contains results from multiple subsystems. In practice, each subsystem is optimized with its own feedback data to avoid the disturbance among different subsystems. However, we argue that such data usage may lead to sub-optimal online performance because of the \textit{data sparsity}. To alleviate this issue, we propose to extract knowledge from the \textit{super-domain} that contains web-scale and long-time impression data, and further assist the online recommendation task (downstream task). To this end, we propose a novel industrial \textbf{K}nowl\textbf{E}dge \textbf{E}xtraction and \textbf{P}lugging (\textbf{KEEP}) framework, which is a two-stage framework that consists of 1) a supervised pre-training knowledge extraction module on super-domain, and 2) a plug-in network that incorporates the extracted knowledge into the downstream model. This makes it friendly for incremental training of online recommendation. Moreover, we design an efficient empirical approach for KEEP and introduce our hands-on experience during the implementation of KEEP in a large-scale industrial system. Experiments conducted on two real-world datasets demonstrate that KEEP can achieve promising results. It is notable that KEEP has also been deployed on the display advertising system in Alibaba, bringing a lift of $+5.4\%$ CTR and $+4.7\%$ RPM.
A Reduced-Complexity Maximum-Likelihood Detection with a sub-optimal BER Requirement
Aug 10, 2022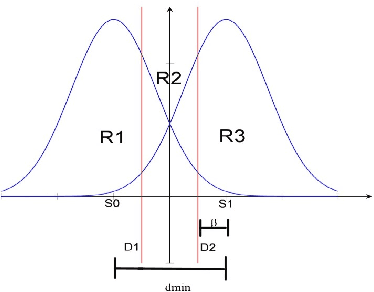
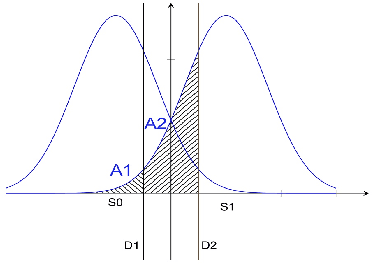
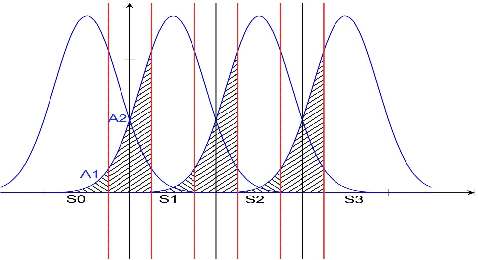
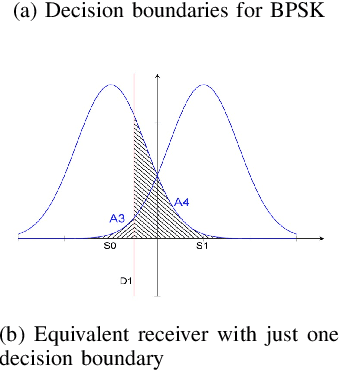
Maximum likelihood (ML) detection is an optimal signal detection scheme, which is often difficult to implement due to its high computational complexity, especially in a multiple-input multiple-output (MIMO) scenario. In a system with $N_t$ transmit antennas employing $M$-ary modulation, the ML-MIMO detector requires $M^{N_t}$ cost function (CF) evaluations followed by a search operation for detecting the symbol with the minimum CF value. However, a practical system needs the bit-error ratio (BER) to be application-dependent which could be sub-optimal. This implies that it may not be necessary to have the minimal CF solution all the time. Rather it is desirable to search for a solution that meets the required sub-optimal BER. In this work, we propose a new detector design for a SISO/MIMO system by obtaining the relation between BER and CF which also improves the computational complexity of the ML detector for a sub-optimal BER.
Medical image analysis based on transformer: A Review
Aug 13, 2022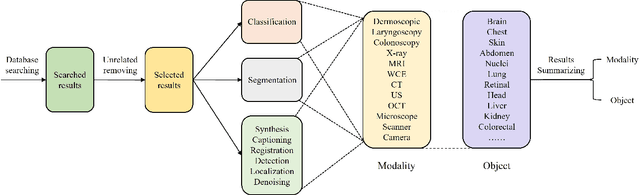

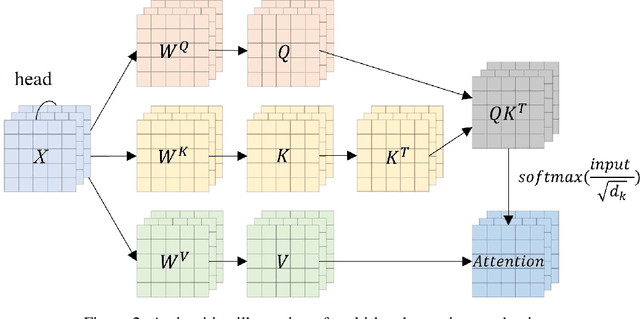
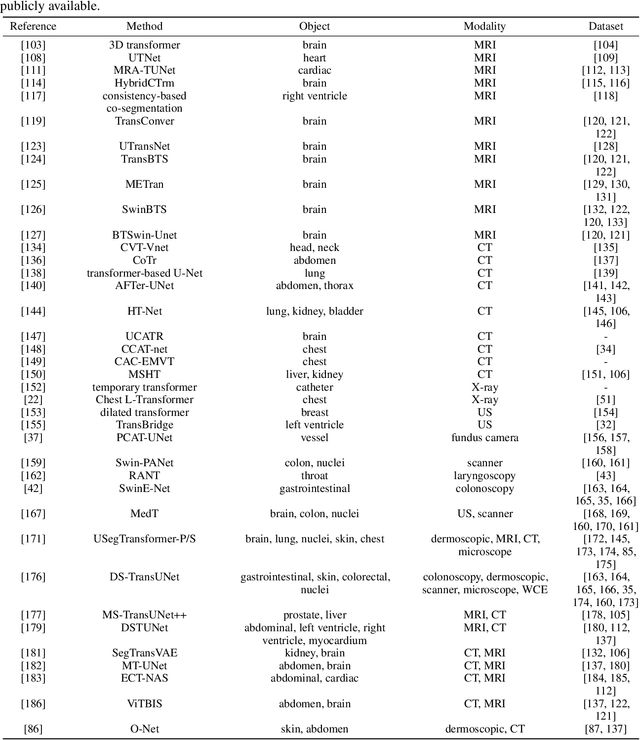
The transformer has dominated the natural language processing (NLP) field for a long time. Recently, the transformer-based method is adopt into the computer vision (CV) field and shows promising results. As an important branch of the CV field, medical image analysis joins the wave of the transformer-based method rightfully. In this paper, we illustrate the principle of the attention mechanism, and the detailed structures of the transformer, and depict how the transformer is adopted into the CV field. We organize the transformer-based medical image analysis applications in the sequence of different CV tasks, including classification, segmentation, synthesis, registration, localization, detection, captioning, and denoising. For the mainstream classification and segmentation tasks, we further divided the corresponding works based on different medical imaging modalities. We include thirteen modalities and more than twenty objects in our work. We also visualize the proportion that each modality and object occupy to give the readers an intuitive impression. We hope our work can contribute to the development of transformer-based medical image analysis in the future.
Deep Reinforcement Learning for RIS-aided Multiuser Full-Duplex Secure Communications with Hardware Impairments
Aug 16, 2022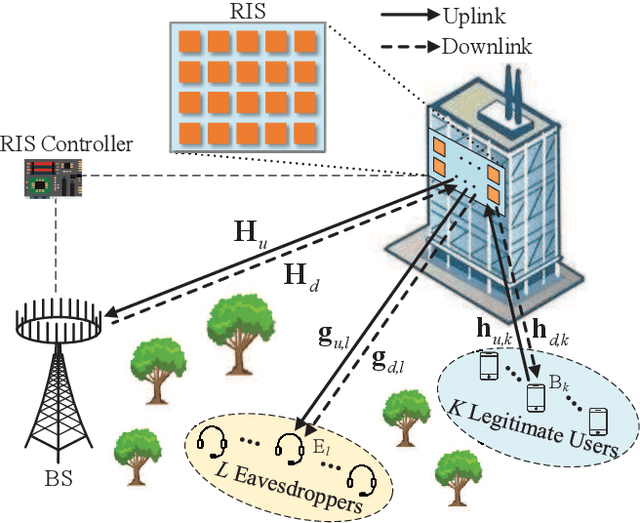
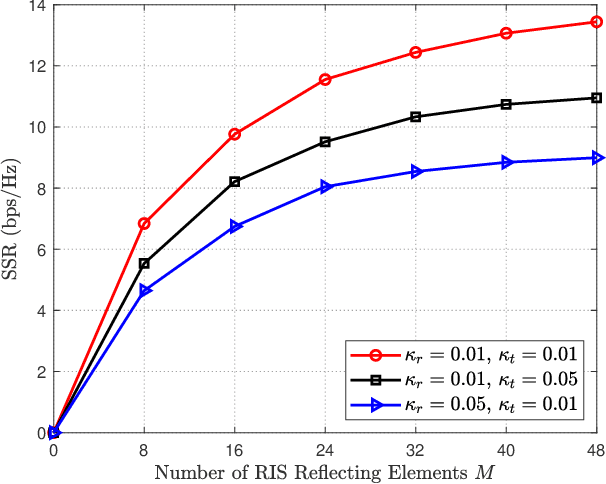
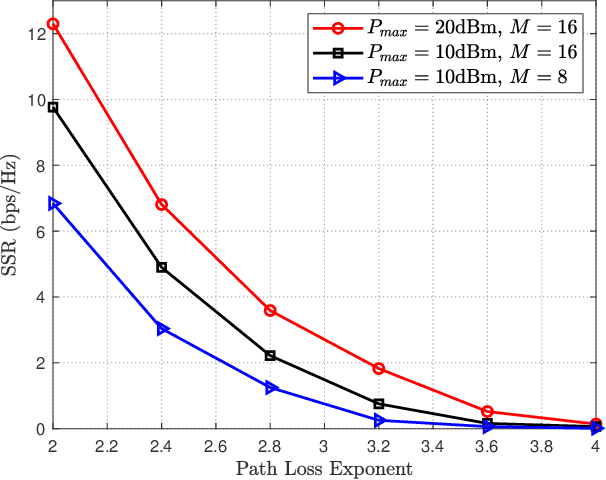
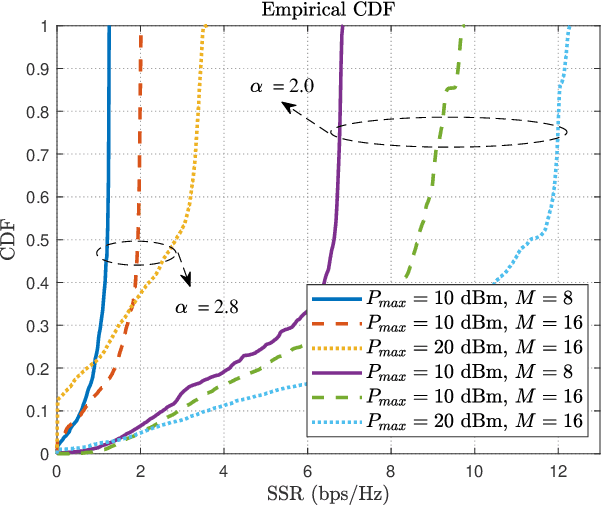
In this paper, we investigate a reconfigurable intelligent surface (RIS)-aided multiuser full-duplex secure communication system with hardware impairments at transceivers and RIS, where multiple eavesdroppers overhear the two-way transmitted signals simultaneously, and an RIS is applied to enhance the secrecy performance. Aiming at maximizing the sum secrecy rate (SSR), a joint optimization problem of the transmit beamforming at the base station (BS) and the reflecting beamforming at the RIS is formulated under the transmit power constraint of the BS and the unit modulus constraint of the phase shifters. As the environment is time-varying and the system is high-dimensional, this non-convex optimization problem is mathematically intractable. A deep reinforcement learning (DRL)-based algorithm is explored to obtain the satisfactory solution by repeatedly interacting with and learning from the dynamic environment. Extensive simulation results illustrate that the DRL-based secure beamforming algorithm is proved to be significantly effective in improving the SSR. It is also found that the performance of the DRL-based method can be greatly improved and the convergence speed of neural network can be accelerated with appropriate neural network parameters.
A Ptolemaic Partitioning Mechanism
Aug 19, 2022
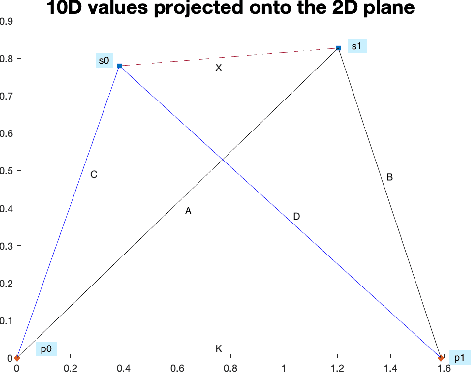

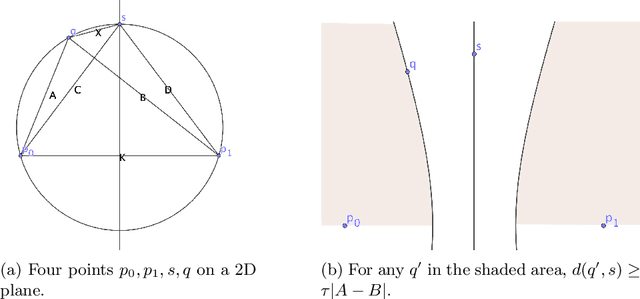
For many years, exact metric search relied upon the property of triangle inequality to give a lower bound on uncalculated distances. Two exclusion mechanisms derive from this property, generally known as pivot exclusion and hyperplane exclusion. These mechanisms work in any proper metric space and are the basis of many metric indexing mechanisms. More recently, the Ptolemaic and four-point lower bound properties have been shown to give tighter bounds in some subclasses of metric space. Both triangle inequality and the four-point lower bound directly imply straightforward partitioning mechanisms: that is, a method of dividing a finite space according to a fixed partition, in order that one or more classes of the partition can be eliminated from a search at query time. However, up to now, no partitioning principle has been identified for the Ptolemaic inequality, which has been used only as a filtering mechanism. Here, a novel partitioning mechanism for the Ptolemaic lower bound is presented. It is always better than either pivot or hyperplane partitioning. While the exclusion condition itself is weaker than Hilbert (four-point) exclusion, its calculation is cheaper. Furthermore, it can be combined with Hilbert exclusion to give a new maximum for exclusion power with respect to the number of distances measured per query.
A User-Centered Investigation of Personal Music Tours
Aug 16, 2022
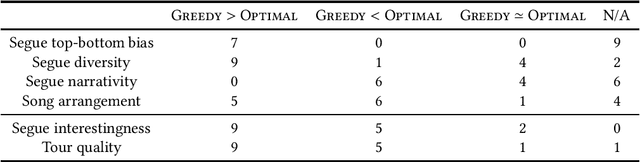
Streaming services use recommender systems to surface the right music to users. Playlists are a popular way to present music in a list-like fashion, ie as a plain list of songs. An alternative are tours, where the songs alternate segues, which explain the connections between consecutive songs. Tours address the user need of seeking background information about songs, and are found to be superior to playlists, given the right user context. In this work, we provide, for the first time, a user-centered evaluation of two tour-generation algorithms (Greedy and Optimal) using semi-structured interviews. We assess the algorithms, we discuss attributes of the tours that the algorithms produce, we identify which attributes are desirable and which are not, and we enumerate several possible improvements to the algorithms, along with practical suggestions on how to implement the improvements. Our main findings are that Greedy generates more likeable tours than Optimal, and that three important attributes of tours are segue diversity, song arrangement and song familiarity. More generally, we provide insights into how to present music to users, which could inform the design of user-centered recommender systems.
Multidimensional orthogonal matching pursuit: theory and application to high accuracy joint localization and communication at mmWave
Aug 24, 2022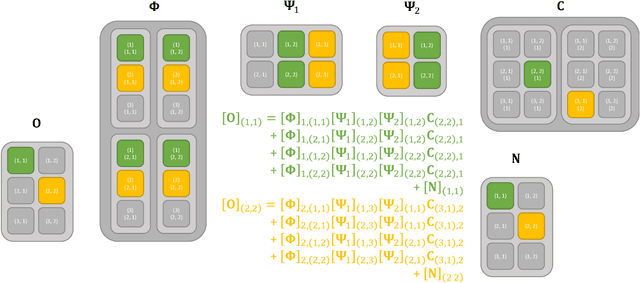
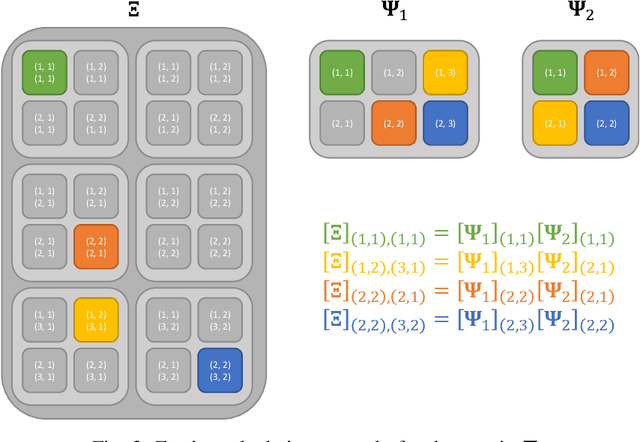
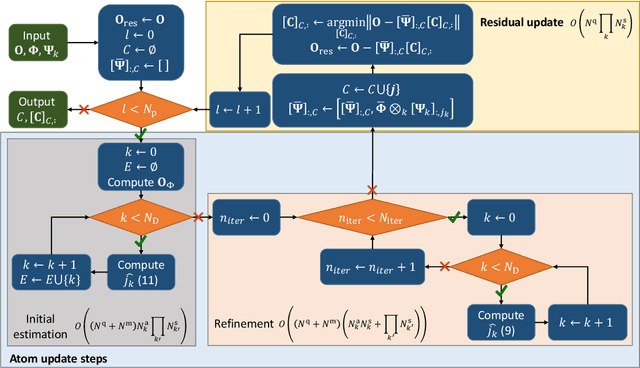
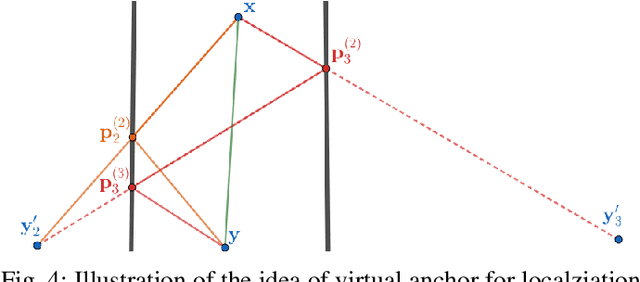
Greedy approaches in general, and orthogonal matching pursuit in particular, are the most commonly used sparse recovery techniques in a wide range of applications. The complexity of these approaches is highly dependent on the size of the dictionary chosen to represent the sparse signal. When the dictionary has to be large to enable high accuracy reconstructions, greedy strategies might however incur in prohibitive complexity. In this paper, we propose first the formulation of a new type of sparse recovery problems where the sparse signal is represented by a set of independent and smaller dictionaries instead of a large single one. Then, we derive a low complexity multdimensional orthogonal matching pursuit (MOMP) strategy for sparse recovery with a multdimensional dictionary. The projection step is performed iteratively on every dimension of the dictionary while fixing all other dimensions to achieve high accuracy estimation at a reasonable complexity. Finally, we formulate the problem of high resolution time domain channel estimation at millimeter wave (mmWave) frequencies as a multidimensional sparse recovery problem that can be solved with MOMP. The channel estimates are later transformed into high accuracy user position estimates exploiting a new localization algorithm that leverages the particular geometry of indoor channels. Simulation results show the effectiveness of MOMP for high accuracy localization at millimeter wave frequencies when operating in realistic 3D scenarios, with practical MIMO architectures feasible at mmWave, and without resorting to perfect synchronization assumptions that simplify the problem.