 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
LaTiM: Longitudinal representation learning in continuous-time models to predict disease progression
Apr 10, 2024
This work proposes a novel framework for analyzing disease progression using time-aware neural ordinary differential equations (NODE). We introduce a "time-aware head" in a framework trained through self-supervised learning (SSL) to leverage temporal information in latent space for data augmentation. This approach effectively integrates NODEs with SSL, offering significant performance improvements compared to traditional methods that lack explicit temporal integration. We demonstrate the effectiveness of our strategy for diabetic retinopathy progression prediction using the OPHDIAT database. Compared to the baseline, all NODE architectures achieve statistically significant improvements in area under the ROC curve (AUC) and Kappa metrics, highlighting the efficacy of pre-training with SSL-inspired approaches. Additionally, our framework promotes stable training for NODEs, a commonly encountered challenge in time-aware modeling.
TransTARec: Time-Adaptive Translating Embedding Model for Next POI Recommendation
Apr 10, 2024The rapid growth of location acquisition technologies makes Point-of-Interest(POI) recommendation possible due to redundant user check-in records. In this paper, we focus on next POI recommendation in which next POI is based on previous POI. We observe that time plays an important role in next POI recommendation but is neglected in the recent proposed translating embedding methods. To tackle this shortage, we propose a time-adaptive translating embedding model (TransTARec) for next POI recommendation that naturally incorporates temporal influence, sequential dynamics, and user preference within a single component. Methodologically, we treat a (previous timestamp, user, next timestamp) triplet as a union translation vector and develop a neural-based fusion operation to fuse user preference and temporal influence. The superiority of TransTARec, which is confirmed by extensive experiments on real-world datasets, comes from not only the introduction of temporal influence but also the direct unification with user preference and sequential dynamics.
Space-Time Video Super-resolution with Neural Operator
Apr 09, 2024This paper addresses the task of space-time video super-resolution (ST-VSR). Existing methods generally suffer from inaccurate motion estimation and motion compensation (MEMC) problems for large motions. Inspired by recent progress in physics-informed neural networks, we model the challenges of MEMC in ST-VSR as a mapping between two continuous function spaces. Specifically, our approach transforms independent low-resolution representations in the coarse-grained continuous function space into refined representations with enriched spatiotemporal details in the fine-grained continuous function space. To achieve efficient and accurate MEMC, we design a Galerkin-type attention function to perform frame alignment and temporal interpolation. Due to the linear complexity of the Galerkin-type attention mechanism, our model avoids patch partitioning and offers global receptive fields, enabling precise estimation of large motions. The experimental results show that the proposed method surpasses state-of-the-art techniques in both fixed-size and continuous space-time video super-resolution tasks.
SFSORT: Scene Features-based Simple Online Real-Time Tracker
Apr 11, 2024This paper introduces SFSORT, the world's fastest multi-object tracking system based on experiments conducted on MOT Challenge datasets. To achieve an accurate and computationally efficient tracker, this paper employs a tracking-by-detection method, following the online real-time tracking approach established in prior literature. By introducing a novel cost function called the Bounding Box Similarity Index, this work eliminates the Kalman Filter, leading to reduced computational requirements. Additionally, this paper demonstrates the impact of scene features on enhancing object-track association and improving track post-processing. Using a 2.2 GHz Intel Xeon CPU, the proposed method achieves an HOTA of 61.7\% with a processing speed of 2242 Hz on the MOT17 dataset and an HOTA of 60.9\% with a processing speed of 304 Hz on the MOT20 dataset. The tracker's source code, fine-tuned object detection model, and tutorials are available at \url{https://github.com/gitmehrdad/SFSORT}.
Advancing Real-time Pandemic Forecasting Using Large Language Models: A COVID-19 Case Study
Apr 10, 2024Forecasting the short-term spread of an ongoing disease outbreak is a formidable challenge due to the complexity of contributing factors, some of which can be characterized through interlinked, multi-modality variables such as epidemiological time series data, viral biology, population demographics, and the intersection of public policy and human behavior. Existing forecasting model frameworks struggle with the multifaceted nature of relevant data and robust results translation, which hinders their performances and the provision of actionable insights for public health decision-makers. Our work introduces PandemicLLM, a novel framework with multi-modal Large Language Models (LLMs) that reformulates real-time forecasting of disease spread as a text reasoning problem, with the ability to incorporate real-time, complex, non-numerical information that previously unattainable in traditional forecasting models. This approach, through a unique AI-human cooperative prompt design and time series representation learning, encodes multi-modal data for LLMs. The model is applied to the COVID-19 pandemic, and trained to utilize textual public health policies, genomic surveillance, spatial, and epidemiological time series data, and is subsequently tested across all 50 states of the U.S. Empirically, PandemicLLM is shown to be a high-performing pandemic forecasting framework that effectively captures the impact of emerging variants and can provide timely and accurate predictions. The proposed PandemicLLM opens avenues for incorporating various pandemic-related data in heterogeneous formats and exhibits performance benefits over existing models. This study illuminates the potential of adapting LLMs and representation learning to enhance pandemic forecasting, illustrating how AI innovations can strengthen pandemic responses and crisis management in the future.
TIM: A Time Interval Machine for Audio-Visual Action Recognition
Apr 09, 2024Diverse actions give rise to rich audio-visual signals in long videos. Recent works showcase that the two modalities of audio and video exhibit different temporal extents of events and distinct labels. We address the interplay between the two modalities in long videos by explicitly modelling the temporal extents of audio and visual events. We propose the Time Interval Machine (TIM) where a modality-specific time interval poses as a query to a transformer encoder that ingests a long video input. The encoder then attends to the specified interval, as well as the surrounding context in both modalities, in order to recognise the ongoing action. We test TIM on three long audio-visual video datasets: EPIC-KITCHENS, Perception Test, and AVE, reporting state-of-the-art (SOTA) for recognition. On EPIC-KITCHENS, we beat previous SOTA that utilises LLMs and significantly larger pre-training by 2.9% top-1 action recognition accuracy. Additionally, we show that TIM can be adapted for action detection, using dense multi-scale interval queries, outperforming SOTA on EPIC-KITCHENS-100 for most metrics, and showing strong performance on the Perception Test. Our ablations show the critical role of integrating the two modalities and modelling their time intervals in achieving this performance. Code and models at: https://github.com/JacobChalk/TIM
TFB: Towards Comprehensive and Fair Benchmarking of Time Series Forecasting Methods
Apr 08, 2024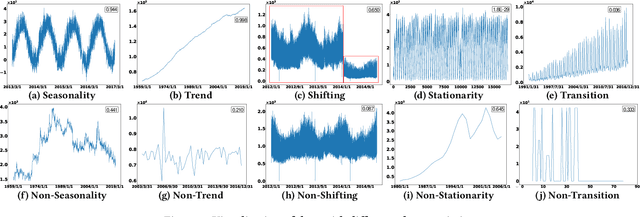
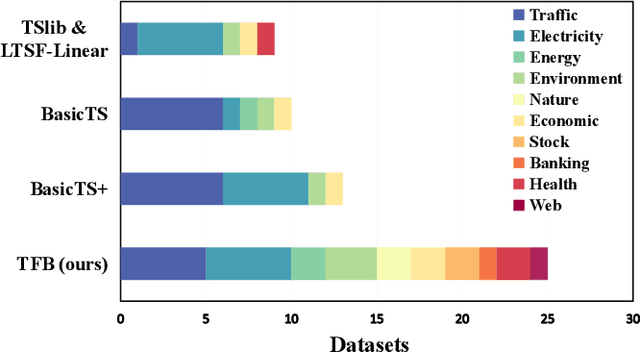

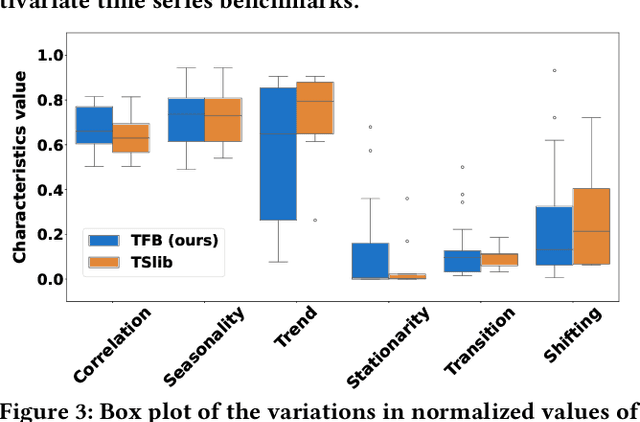
Time series are generated in diverse domains such as economic, traffic, health, and energy, where forecasting of future values has numerous important applications. Not surprisingly, many forecasting methods are being proposed. To ensure progress, it is essential to be able to study and compare such methods empirically in a comprehensive and reliable manner. To achieve this, we propose TFB, an automated benchmark for Time Series Forecasting (TSF) methods. TFB advances the state-of-the-art by addressing shortcomings related to datasets, comparison methods, and evaluation pipelines: 1) insufficient coverage of data domains, 2) stereotype bias against traditional methods, and 3) inconsistent and inflexible pipelines. To achieve better domain coverage, we include datasets from 10 different domains: traffic, electricity, energy, the environment, nature, economic, stock markets, banking, health, and the web. We also provide a time series characterization to ensure that the selected datasets are comprehensive. To remove biases against some methods, we include a diverse range of methods, including statistical learning, machine learning, and deep learning methods, and we also support a variety of evaluation strategies and metrics to ensure a more comprehensive evaluations of different methods. To support the integration of different methods into the benchmark and enable fair comparisons, TFB features a flexible and scalable pipeline that eliminates biases. Next, we employ TFB to perform a thorough evaluation of 21 Univariate Time Series Forecasting (UTSF) methods on 8,068 univariate time series and 14 Multivariate Time Series Forecasting (MTSF) methods on 25 datasets. The benchmark code and data are available at https://github.com/decisionintelligence/TFB.
MagicTime: Time-lapse Video Generation Models as Metamorphic Simulators
Apr 07, 2024Recent advances in Text-to-Video generation (T2V) have achieved remarkable success in synthesizing high-quality general videos from textual descriptions. A largely overlooked problem in T2V is that existing models have not adequately encoded physical knowledge of the real world, thus generated videos tend to have limited motion and poor variations. In this paper, we propose \textbf{MagicTime}, a metamorphic time-lapse video generation model, which learns real-world physics knowledge from time-lapse videos and implements metamorphic generation. First, we design a MagicAdapter scheme to decouple spatial and temporal training, encode more physical knowledge from metamorphic videos, and transform pre-trained T2V models to generate metamorphic videos. Second, we introduce a Dynamic Frames Extraction strategy to adapt to metamorphic time-lapse videos, which have a wider variation range and cover dramatic object metamorphic processes, thus embodying more physical knowledge than general videos. Finally, we introduce a Magic Text-Encoder to improve the understanding of metamorphic video prompts. Furthermore, we create a time-lapse video-text dataset called \textbf{ChronoMagic}, specifically curated to unlock the metamorphic video generation ability. Extensive experiments demonstrate the superiority and effectiveness of MagicTime for generating high-quality and dynamic metamorphic videos, suggesting time-lapse video generation is a promising path toward building metamorphic simulators of the physical world.
Towards Efficient and Real-Time Piano Transcription Using Neural Autoregressive Models
Apr 10, 2024In recent years, advancements in neural network designs and the availability of large-scale labeled datasets have led to significant improvements in the accuracy of piano transcription models. However, most previous work focused on high-performance offline transcription, neglecting deliberate consideration of model size. The goal of this work is to implement real-time inference for piano transcription while ensuring both high performance and lightweight. To this end, we propose novel architectures for convolutional recurrent neural networks, redesigning an existing autoregressive piano transcription model. First, we extend the acoustic module by adding a frequency-conditioned FiLM layer to the CNN module to adapt the convolutional filters on the frequency axis. Second, we improve note-state sequence modeling by using a pitchwise LSTM that focuses on note-state transitions within a note. In addition, we augment the autoregressive connection with an enhanced recursive context. Using these components, we propose two types of models; one for high performance and the other for high compactness. Through extensive experiments, we show that the proposed models are comparable to state-of-the-art models in terms of note accuracy on the MAESTRO dataset. We also investigate the effective model size and real-time inference latency by gradually streamlining the architecture. Finally, we conduct cross-data evaluation on unseen piano datasets and in-depth analysis to elucidate the effect of the proposed components in the view of note length and pitch range.
Active Test-Time Adaptation: Theoretical Analyses and An Algorithm
Apr 07, 2024Test-time adaptation (TTA) addresses distribution shifts for streaming test data in unsupervised settings. Currently, most TTA methods can only deal with minor shifts and rely heavily on heuristic and empirical studies. To advance TTA under domain shifts, we propose the novel problem setting of active test-time adaptation (ATTA) that integrates active learning within the fully TTA setting. We provide a learning theory analysis, demonstrating that incorporating limited labeled test instances enhances overall performances across test domains with a theoretical guarantee. We also present a sample entropy balancing for implementing ATTA while avoiding catastrophic forgetting (CF). We introduce a simple yet effective ATTA algorithm, known as SimATTA, using real-time sample selection techniques. Extensive experimental results confirm consistency with our theoretical analyses and show that the proposed ATTA method yields substantial performance improvements over TTA methods while maintaining efficiency and shares similar effectiveness to the more demanding active domain adaptation (ADA) methods. Our code is available at https://github.com/divelab/ATTA