 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Looking for a Needle in a Haystack: A Comprehensive Study of Hallucinations in Neural Machine Translation
Aug 10, 2022


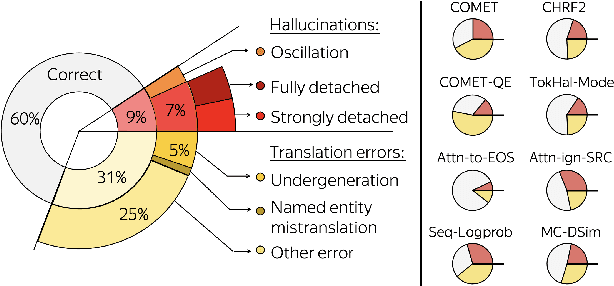
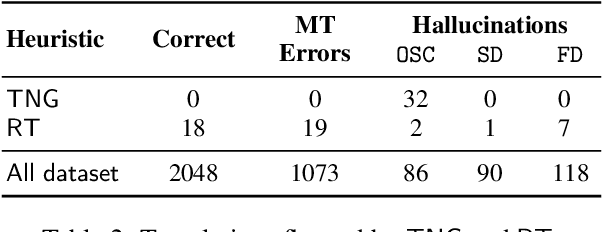
Although the problem of hallucinations in neural machine translation (NMT) has received some attention, research on this highly pathological phenomenon lacks solid ground. Previous work has been limited in several ways: it often resorts to artificial settings where the problem is amplified, it disregards some (common) types of hallucinations, and it does not validate adequacy of detection heuristics. In this paper, we set foundations for the study of NMT hallucinations. First, we work in a natural setting, i.e., in-domain data without artificial noise neither in training nor in inference. Next, we annotate a dataset of over 3.4k sentences indicating different kinds of critical errors and hallucinations. Then, we turn to detection methods and both revisit methods used previously and propose using glass-box uncertainty-based detectors. Overall, we show that for preventive settings, (i) previously used methods are largely inadequate, (ii) sequence log-probability works best and performs on par with reference-based methods. Finally, we propose DeHallucinator, a simple method for alleviating hallucinations at test time that significantly reduces the hallucinatory rate. To ease future research, we release our annotated dataset for WMT18 German-English data, along with the model, training data, and code.
Graph Neural Networks Extract High-Resolution Cultivated Land Maps from Sentinel-2 Image Series
Aug 03, 2022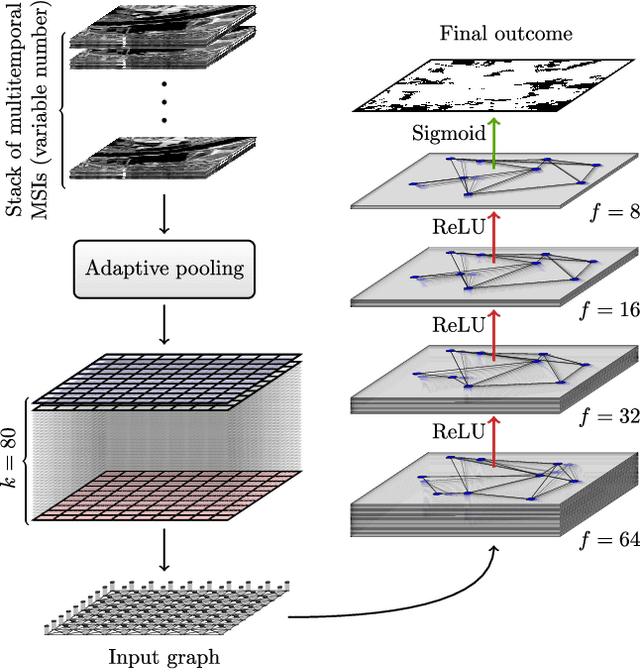

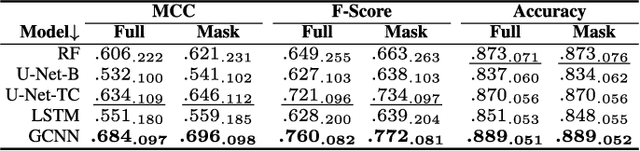
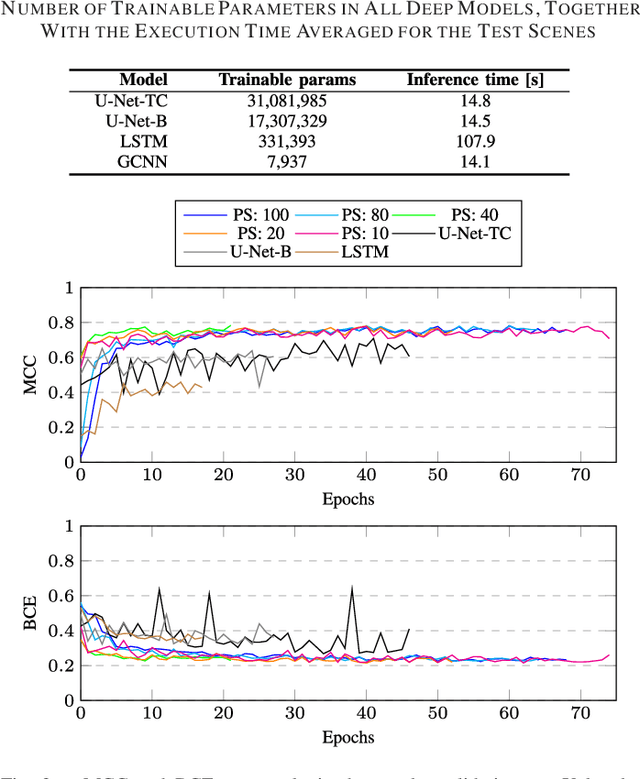
Maintaining farm sustainability through optimizing the agricultural management practices helps build more planet-friendly environment. The emerging satellite missions can acquire multi- and hyperspectral imagery which captures more detailed spectral information concerning the scanned area, hence allows us to benefit from subtle spectral features during the analysis process in agricultural applications. We introduce an approach for extracting 2.5 m cultivated land maps from 10 m Sentinel-2 multispectral image series which benefits from a compact graph convolutional neural network. The experiments indicate that our models not only outperform classical and deep machine learning techniques through delivering higher-quality segmentation maps, but also dramatically reduce the memory footprint when compared to U-Nets (almost 8k trainable parameters of our models, with up to 31M parameters of U-Nets). Such memory frugality is pivotal in the missions which allow us to uplink a model to the AI-powered satellite once it is in orbit, as sending large nets is impossible due to the time constraints.
* 7 pages (including supplementary material), published in IEEE Geoscience and Remote Sensing Letters
Space-time Mixing Attention for Video Transformer
Jun 11, 2021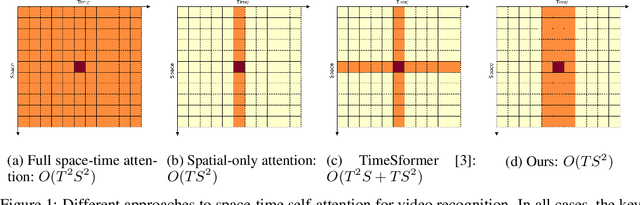
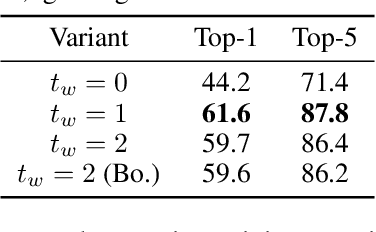
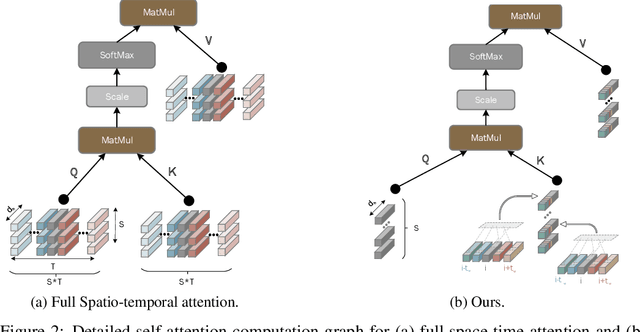
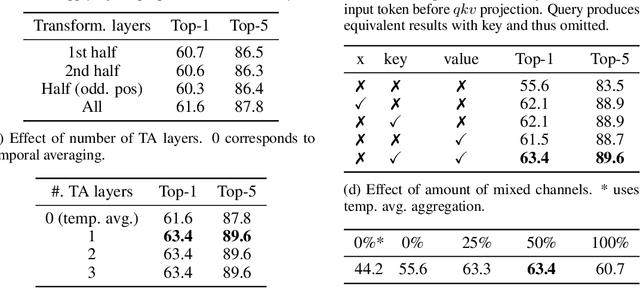
This paper is on video recognition using Transformers. Very recent attempts in this area have demonstrated promising results in terms of recognition accuracy, yet they have been also shown to induce, in many cases, significant computational overheads due to the additional modelling of the temporal information. In this work, we propose a Video Transformer model the complexity of which scales linearly with the number of frames in the video sequence and hence induces no overhead compared to an image-based Transformer model. To achieve this, our model makes two approximations to the full space-time attention used in Video Transformers: (a) It restricts time attention to a local temporal window and capitalizes on the Transformer's depth to obtain full temporal coverage of the video sequence. (b) It uses efficient space-time mixing to attend jointly spatial and temporal locations without inducing any additional cost on top of a spatial-only attention model. We also show how to integrate 2 very lightweight mechanisms for global temporal-only attention which provide additional accuracy improvements at minimal computational cost. We demonstrate that our model produces very high recognition accuracy on the most popular video recognition datasets while at the same time being significantly more efficient than other Video Transformer models. Code will be made available.
Near-optimal control of dynamical systems with neural ordinary differential equations
Jun 22, 2022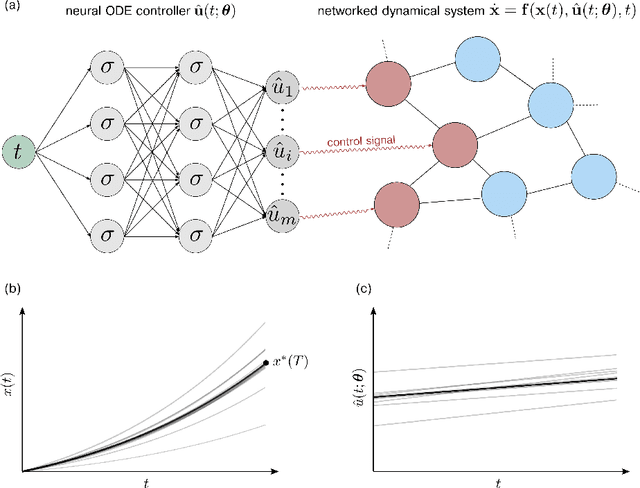
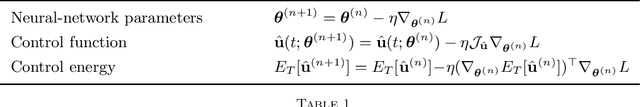
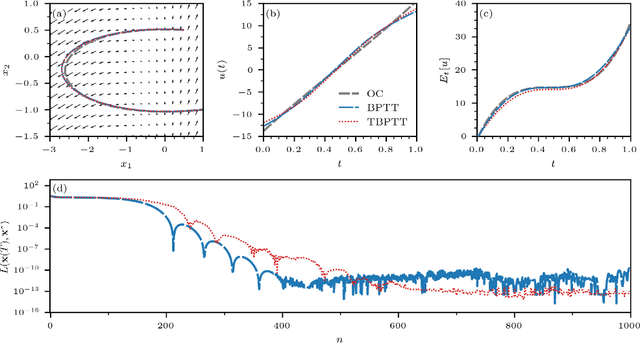
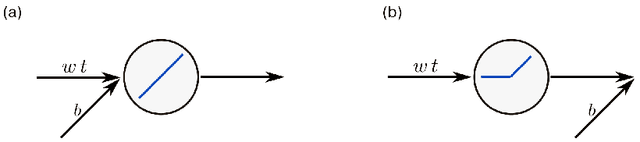
Optimal control problems naturally arise in many scientific applications where one wishes to steer a dynamical system from a certain initial state $\mathbf{x}_0$ to a desired target state $\mathbf{x}^*$ in finite time $T$. Recent advances in deep learning and neural network-based optimization have contributed to the development of methods that can help solve control problems involving high-dimensional dynamical systems. In particular, the framework of neural ordinary differential equations (neural ODEs) provides an efficient means to iteratively approximate continuous time control functions associated with analytically intractable and computationally demanding control tasks. Although neural ODE controllers have shown great potential in solving complex control problems, the understanding of the effects of hyperparameters such as network structure and optimizers on learning performance is still very limited. Our work aims at addressing some of these knowledge gaps to conduct efficient hyperparameter optimization. To this end, we first analyze how truncated and non-truncated backpropagation through time affect runtime performance and the ability of neural networks to learn optimal control functions. Using analytical and numerical methods, we then study the role of parameter initializations, optimizers, and neural-network architecture. Finally, we connect our results to the ability of neural ODE controllers to implicitly regularize control energy.
ClearBuds: Wireless Binaural Earbuds for Learning-Based Speech Enhancement
Jun 27, 2022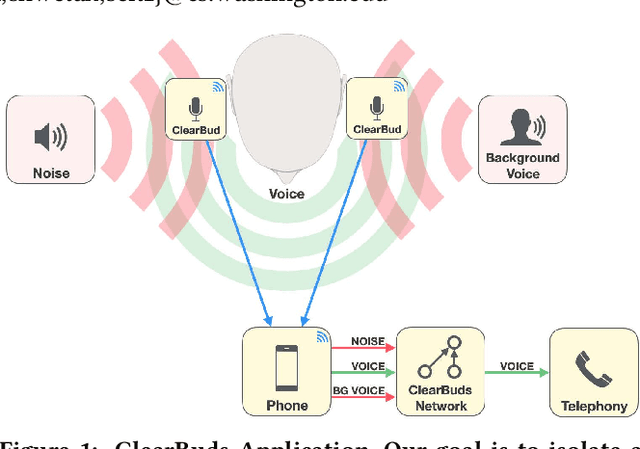

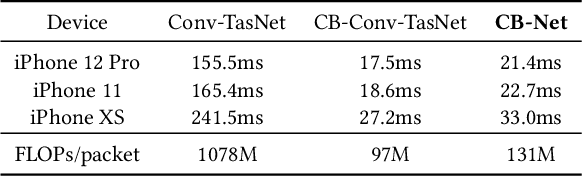
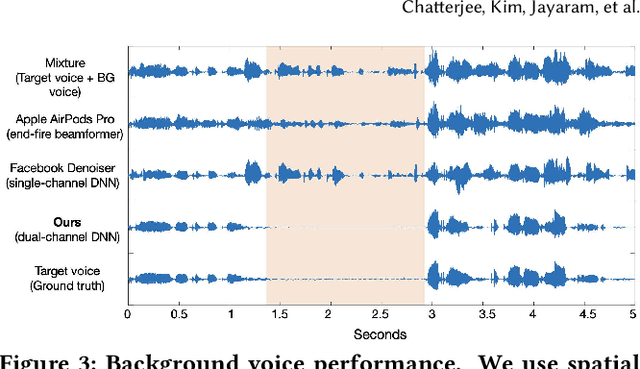
We present ClearBuds, the first hardware and software system that utilizes a neural network to enhance speech streamed from two wireless earbuds. Real-time speech enhancement for wireless earbuds requires high-quality sound separation and background cancellation, operating in real-time and on a mobile phone. Clear-Buds bridges state-of-the-art deep learning for blind audio source separation and in-ear mobile systems by making two key technical contributions: 1) a new wireless earbud design capable of operating as a synchronized, binaural microphone array, and 2) a lightweight dual-channel speech enhancement neural network that runs on a mobile device. Our neural network has a novel cascaded architecture that combines a time-domain conventional neural network with a spectrogram-based frequency masking neural network to reduce the artifacts in the audio output. Results show that our wireless earbuds achieve a synchronization error less than 64 microseconds and our network has a runtime of 21.4 milliseconds on an accompanying mobile phone. In-the-wild evaluation with eight users in previously unseen indoor and outdoor multipath scenarios demonstrates that our neural network generalizes to learn both spatial and acoustic cues to perform noise suppression and background speech removal. In a user-study with 37 participants who spent over 15.4 hours rating 1041 audio samples collected in-the-wild, our system achieves improved mean opinion score and background noise suppression. Project page with demos: https://clearbuds.cs.washington.edu
Capturing Dependencies within Machine Learning via a Formal Process Model
Aug 10, 2022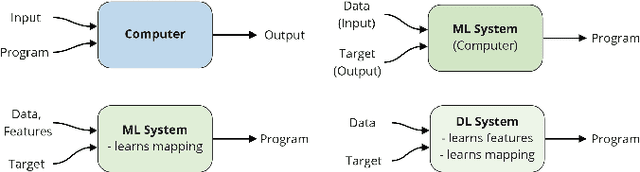
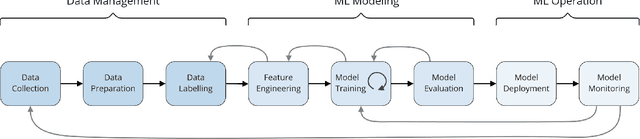
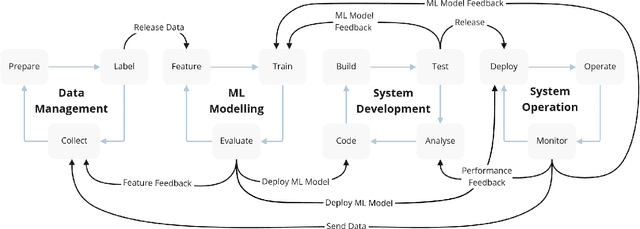
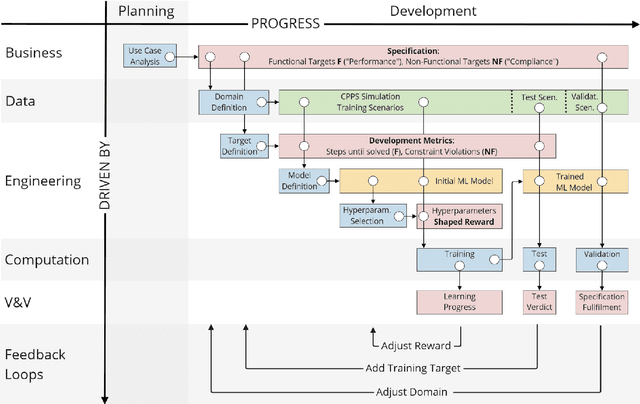
The development of Machine Learning (ML) models is more than just a special case of software development (SD): ML models acquire properties and fulfill requirements even without direct human interaction in a seemingly uncontrollable manner. Nonetheless, the underlying processes can be described in a formal way. We define a comprehensive SD process model for ML that encompasses most tasks and artifacts described in the literature in a consistent way. In addition to the production of the necessary artifacts, we also focus on generating and validating fitting descriptions in the form of specifications. We stress the importance of further evolving the ML model throughout its life-cycle even after initial training and testing. Thus, we provide various interaction points with standard SD processes in which ML often is an encapsulated task. Further, our SD process model allows to formulate ML as a (meta-) optimization problem. If automated rigorously, it can be used to realize self-adaptive autonomous systems. Finally, our SD process model features a description of time that allows to reason about the progress within ML development processes. This might lead to further applications of formal methods within the field of ML.
Quantum-Inspired Tensor Neural Networks for Partial Differential Equations
Aug 03, 2022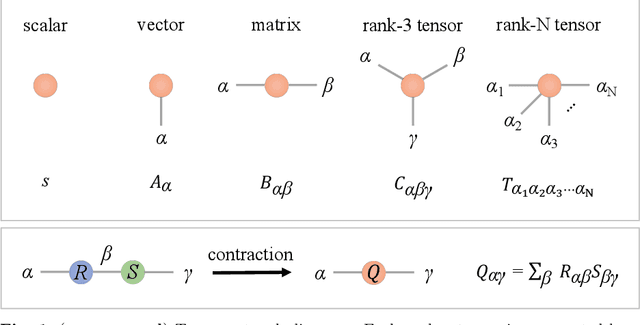
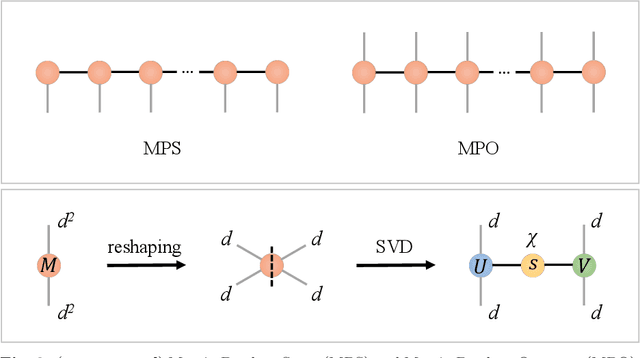
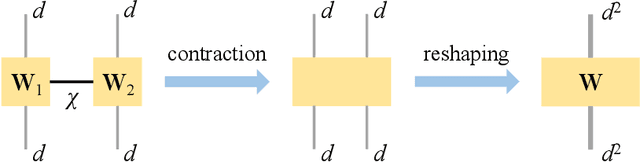
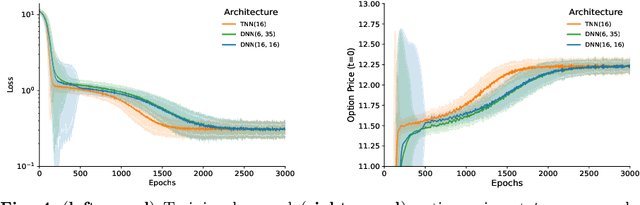
Partial Differential Equations (PDEs) are used to model a variety of dynamical systems in science and engineering. Recent advances in deep learning have enabled us to solve them in a higher dimension by addressing the curse of dimensionality in new ways. However, deep learning methods are constrained by training time and memory. To tackle these shortcomings, we implement Tensor Neural Networks (TNN), a quantum-inspired neural network architecture that leverages Tensor Network ideas to improve upon deep learning approaches. We demonstrate that TNN provide significant parameter savings while attaining the same accuracy as compared to the classical Dense Neural Network (DNN). In addition, we also show how TNN can be trained faster than DNN for the same accuracy. We benchmark TNN by applying them to solve parabolic PDEs, specifically the Black-Scholes-Barenblatt equation, widely used in financial pricing theory, empirically showing the advantages of TNN over DNN. Further examples, such as the Hamilton-Jacobi-Bellman equation, are also discussed.
Estimating Uncertainty of Autonomous Vehicle Systems with Generalized Polynomial Chaos
Aug 03, 2022

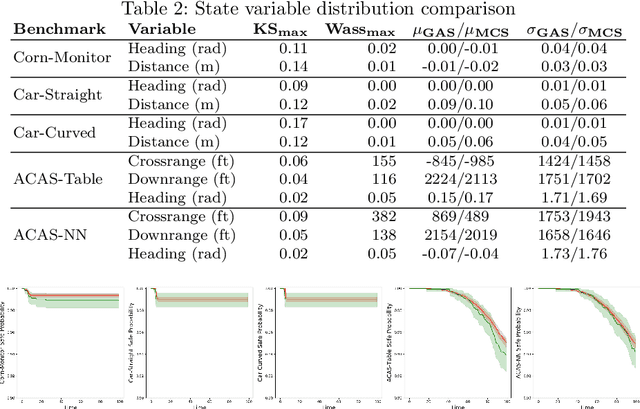

Modern autonomous vehicle systems use complex perception and control components and must cope with uncertain data received from sensors. To estimate the probability that such vehicles remain in a safe state, developers often resort to time-consuming simulation methods. This paper presents an alternative methodology for analyzing autonomy pipelines in vehicular systems, based on Generalized Polynomial Chaos (GPC). We also present GAS, the first algorithm for creating and using GPC models of complex vehicle systems. GAS replaces complex perception components with a perception model to reduce complexity. Then, it constructs the GPC model and uses it for estimating state distribution and/or probability of entering an unsafe state. We evaluate GAS on five scenarios used in crop management vehicles, self driving cars, and aerial drones - each system uses at least one complex perception or control component. We show that GAS calculates state distributions that closely match those produced by Monte Carlo Simulation, while also providing 2.3x-3.0x speedups.
DeepVisualInsight: Time-Travelling Visualization for Spatio-Temporal Causality of Deep Classification Training
Dec 31, 2021
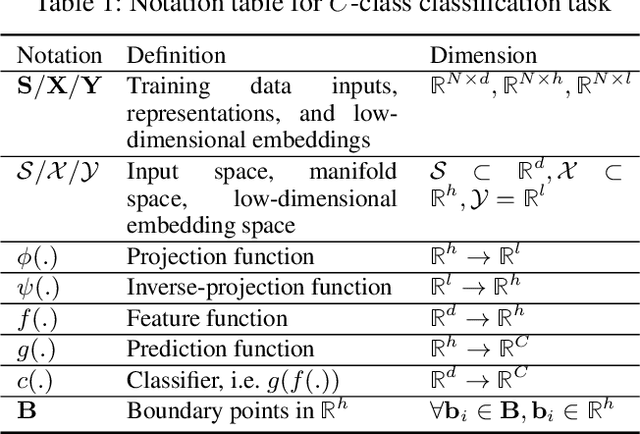
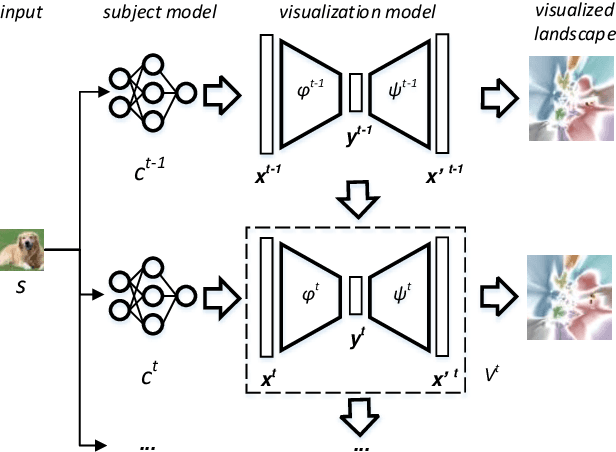
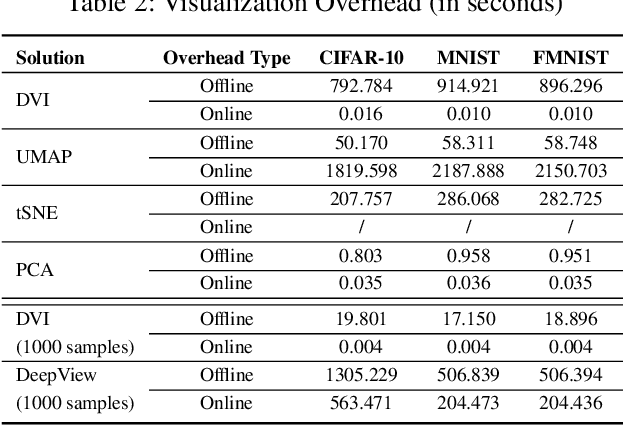
Understanding how the predictions of deep learning models are formed during the training process is crucial to improve model performance and fix model defects, especially when we need to investigate nontrivial training strategies such as active learning, and track the root cause of unexpected training results such as performance degeneration. In this work, we propose a time-travelling visual solution DeepVisualInsight (DVI), aiming to manifest the spatio-temporal causality while training a deep learning image classifier. The spatio-temporal causality demonstrates how the gradient-descent algorithm and various training data sampling techniques can influence and reshape the layout of learnt input representation and the classification boundaries in consecutive epochs. Such causality allows us to observe and analyze the whole learning process in the visible low dimensional space. Technically, we propose four spatial and temporal properties and design our visualization solution to satisfy them. These properties preserve the most important information when inverse-)projecting input samples between the visible low-dimensional and the invisible high-dimensional space, for causal analyses. Our extensive experiments show that, comparing to baseline approaches, we achieve the best visualization performance regarding the spatial/temporal properties and visualization efficiency. Moreover, our case study shows that our visual solution can well reflect the characteristics of various training scenarios, showing good potential of DVI as a debugging tool for analyzing deep learning training processes.
Delay-Doppler Reversal for OTFS System in Doubly-selective Fading Channels
Jul 22, 2022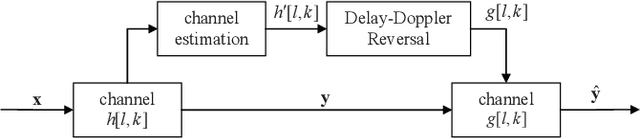
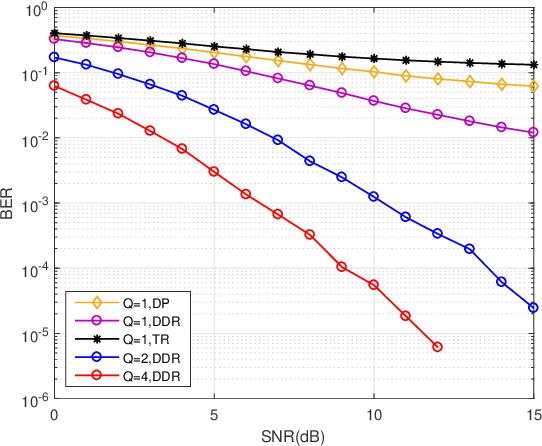
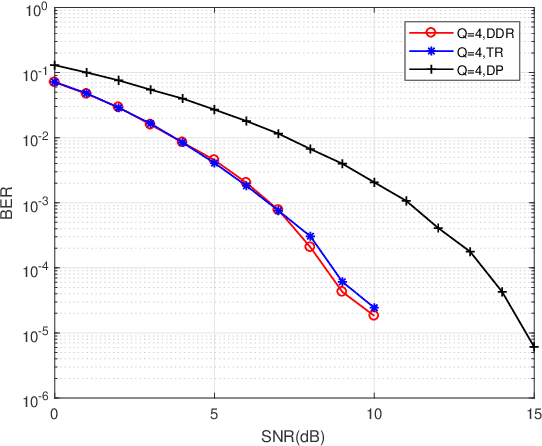
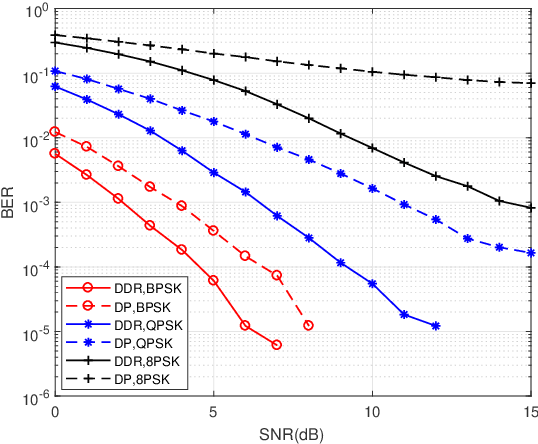
The recent proposed orthogonal time frequency space (OTFS) modulation shows signifcant advantages than conventional orthogonal frequency division multiplexing (OFDM) for high mobility wireless communications. However, a challenging problem is the development of effcient receivers for practical OTFS systems with low complexity. In this paper, we propose a novel delay-Doppler reversal (DDR) technology for OTFS system with desired performance and low complexity. We present the DDR technology from a perspective of two-dimensional cascaded channel model, analyze its computational complexity and also analyze its performance gain compared to the direct processing (DP) receiver without DDR. Simulation results demonstrate that our proposed DDR receiver outperforms traditional receivers in doubly-selective fading channels.