 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Towards Higher-order Topological Consistency for Unsupervised Network Alignment
Aug 26, 2022
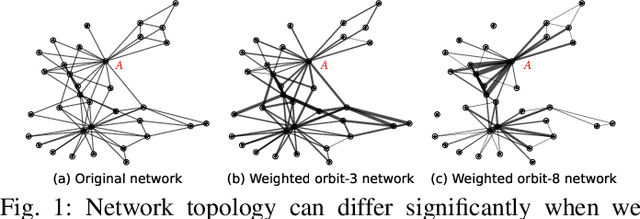
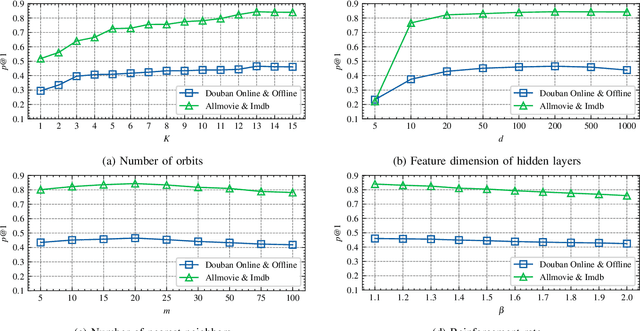
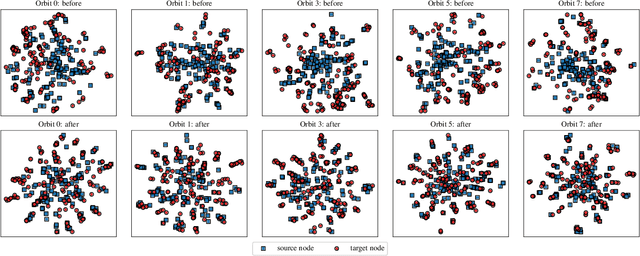
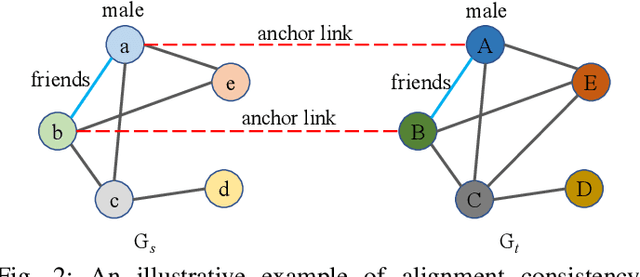
Network alignment task, which aims to identify corresponding nodes in different networks, is of great significance for many subsequent applications. Without the need for labeled anchor links, unsupervised alignment methods have been attracting more and more attention. However, the topological consistency assumptions defined by existing methods are generally low-order and less accurate because only the edge-indiscriminative topological pattern is considered, which is especially risky in an unsupervised setting. To reposition the focus of the alignment process from low-order to higher-order topological consistency, in this paper, we propose a fully unsupervised network alignment framework named HTC. The proposed higher-order topological consistency is formulated based on edge orbits, which is merged into the information aggregation process of a graph convolutional network so that the alignment consistencies are transformed into the similarity of node embeddings. Furthermore, the encoder is trained to be multi-orbit-aware and then be refined to identify more trusted anchor links. Node correspondence is comprehensively evaluated by integrating all different orders of consistency. {In addition to sound theoretical analysis, the superiority of the proposed method is also empirically demonstrated through extensive experimental evaluation. On three pairs of real-world datasets and two pairs of synthetic datasets, our HTC consistently outperforms a wide variety of unsupervised and supervised methods with the least or comparable time consumption. It also exhibits robustness to structural noise as a result of our multi-orbit-aware training mechanism.
A Two-Time-Scale Stochastic Optimization Framework with Applications in Control and Reinforcement Learning
Sep 29, 2021
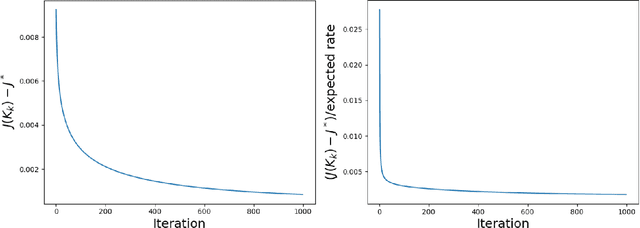
We study a novel two-time-scale stochastic gradient method for solving optimization problems where the gradient samples are generated from a time-varying Markov random process parameterized by the underlying optimization variable. These time-varying samples make the stochastic gradient biased and dependent, which can potentially lead to the divergence of the iterates. To address this issue, we consider a two-time-scale update scheme, where one scale is used to estimate the true gradient from the Markovian samples and the other scale is used to update the decision variable with the estimated gradient. While these two iterates are implemented simultaneously, the former is updated "faster" (using bigger step sizes) than the latter (using smaller step sizes). Our first contribution is to characterize the finite-time complexity of the proposed two-time-scale stochastic gradient method. In particular, we provide explicit formulas for the convergence rates of this method under different objective functions, namely, strong convexity, convexity, non-convexity under the PL condition, and general non-convexity. Our second contribution is to apply our framework to study the performance of the popular actor-critic methods in solving stochastic control and reinforcement learning problems. First, we study an online natural actor-critic algorithm for the linear-quadratic regulator and show that a convergence rate of $\mathcal{O}(k^{-2/3})$ is achieved. This is the first time such a result is known in the literature. Second, we look at the standard online actor-critic algorithm over finite state and action spaces and derive a convergence rate of $\mathcal{O}(k^{-2/5})$, which recovers the best known rate derived specifically for this problem. Finally, we support our theoretical analysis with numerical simulations where the convergence rate is visualized.
Simulation-guided Beam Search for Neural Combinatorial Optimization
Jul 13, 2022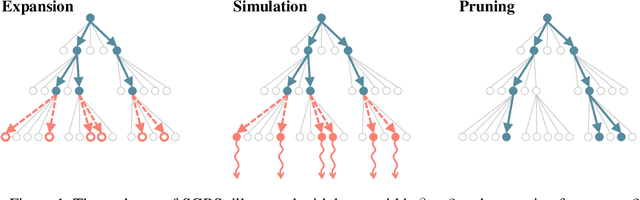
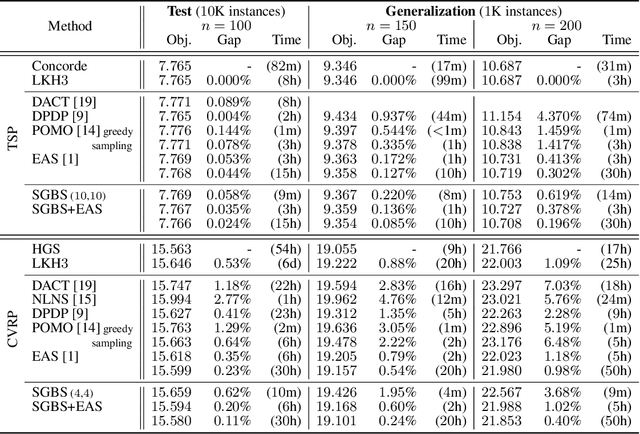
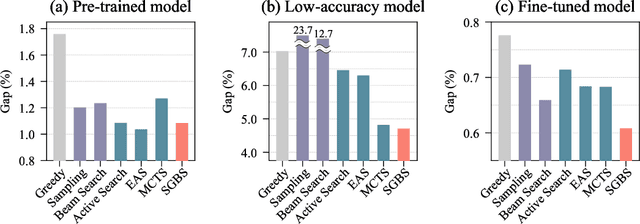
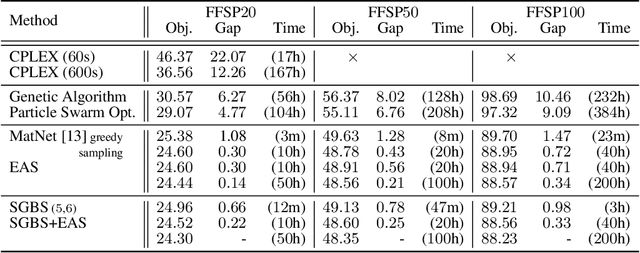
Neural approaches for combinatorial optimization (CO) equip a learning mechanism to discover powerful heuristics for solving complex real-world problems. While neural approaches capable of high-quality solutions in a single shot are emerging, state-of-the-art approaches are often unable to take full advantage of the solving time available to them. In contrast, hand-crafted heuristics perform highly effective search well and exploit the computation time given to them, but contain heuristics that are difficult to adapt to a dataset being solved. With the goal of providing a powerful search procedure to neural CO approaches, we propose simulation-guided beam search (SGBS), which examines candidate solutions within a fixed-width tree search that both a neural net-learned policy and a simulation (rollout) identify as promising. We further hybridize SGBS with efficient active search (EAS), where SGBS enhances the quality of solutions backpropagated in EAS, and EAS improves the quality of the policy used in SGBS. We evaluate our methods on well-known CO benchmarks and show that SGBS significantly improves the quality of the solutions found under reasonable runtime assumptions.
A Supervised Tensor Dimension Reduction-Based Prognostics Model for Applications with Incomplete Imaging Data
Jul 22, 2022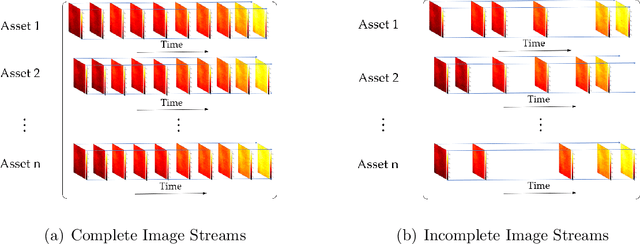
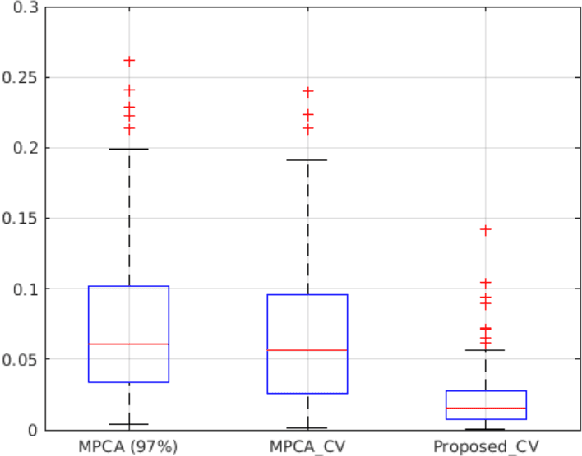
This paper proposes a supervised dimension reduction methodology for tensor data which has two advantages over most image-based prognostic models. First, the model does not require tensor data to be complete which expands its application to incomplete data. Second, it utilizes time-to-failure (TTF) to supervise the extraction of low-dimensional features which makes the extracted features more effective for the subsequent prognostic. Besides, an optimization algorithm is proposed for parameter estimation and closed-form solutions are derived under certain distributions.
Efficient Attention-free Video Shift Transformers
Aug 23, 2022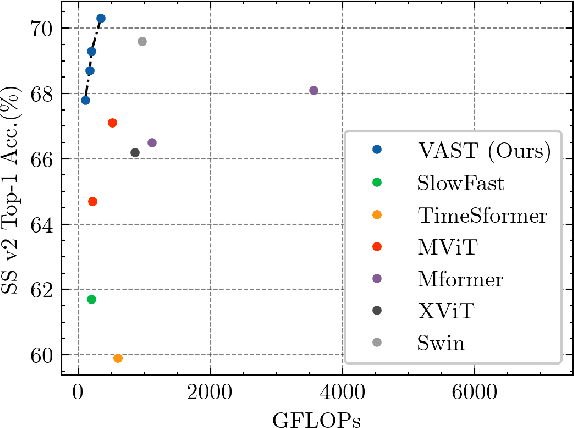

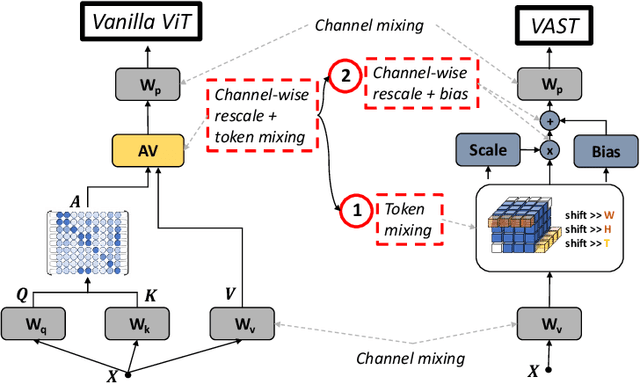
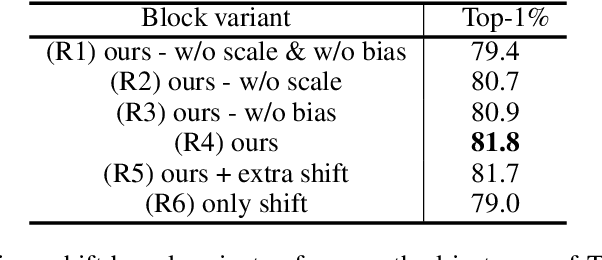
This paper tackles the problem of efficient video recognition. In this area, video transformers have recently dominated the efficiency (top-1 accuracy vs FLOPs) spectrum. At the same time, there have been some attempts in the image domain which challenge the necessity of the self-attention operation within the transformer architecture, advocating the use of simpler approaches for token mixing. However, there are no results yet for the case of video recognition, where the self-attention operator has a significantly higher impact (compared to the case of images) on efficiency. To address this gap, in this paper, we make the following contributions: (a) we construct a highly efficient \& accurate attention-free block based on the shift operator, coined Affine-Shift block, specifically designed to approximate as closely as possible the operations in the MHSA block of a Transformer layer. Based on our Affine-Shift block, we construct our Affine-Shift Transformer and show that it already outperforms all existing shift/MLP--based architectures for ImageNet classification. (b) We extend our formulation in the video domain to construct Video Affine-Shift Transformer (VAST), the very first purely attention-free shift-based video transformer. (c) We show that VAST significantly outperforms recent state-of-the-art transformers on the most popular action recognition benchmarks for the case of models with low computational and memory footprint. Code will be made available.
Online Segmentation of LiDAR Sequences: Dataset and Algorithm
Jun 16, 2022
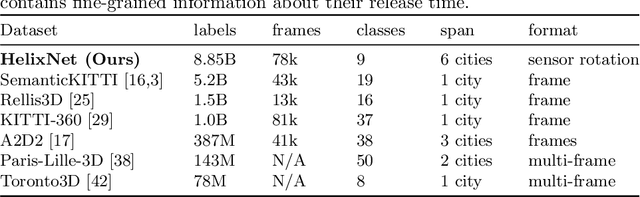
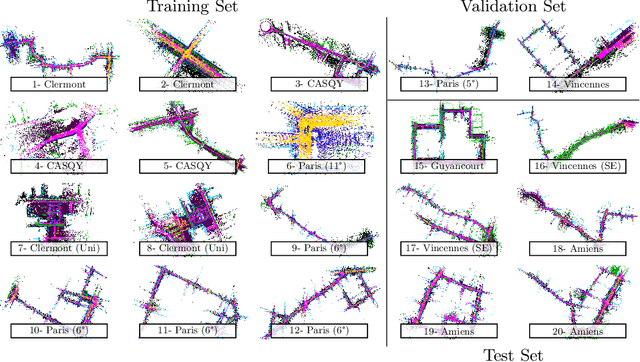
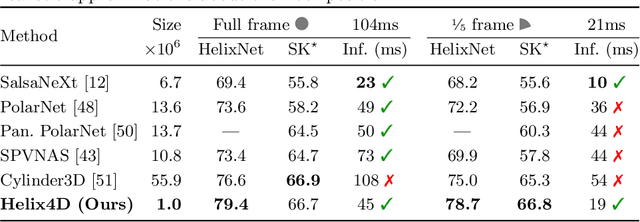
Roof-mounted spinning LiDAR sensors are widely used by autonomous vehicles, driving the need for real-time processing of 3D point sequences. However, most LiDAR semantic segmentation datasets and algorithms split these acquisitions into $360^\circ$ frames, leading to acquisition latency that is incompatible with realistic real-time applications and evaluations. We address this issue with two key contributions. First, we introduce HelixNet, a $10$ billion point dataset with fine-grained labels, timestamps, and sensor rotation information that allows an accurate assessment of real-time readiness of segmentation algorithms. Second, we propose Helix4D, a compact and efficient spatio-temporal transformer architecture specifically designed for rotating LiDAR point sequences. Helix4D operates on acquisition slices that correspond to a fraction of a full rotation of the sensor, significantly reducing the total latency. We present an extensive benchmark of the performance and real-time readiness of several state-of-the-art models on HelixNet and SemanticKITTI. Helix4D reaches accuracy on par with the best segmentation algorithms with a reduction of more than $5\times$ in terms of latency and $50\times$ in model size. Code and data are available at: https://romainloiseau.fr/helixnet
ConMatch: Semi-Supervised Learning with Confidence-Guided Consistency Regularization
Aug 18, 2022
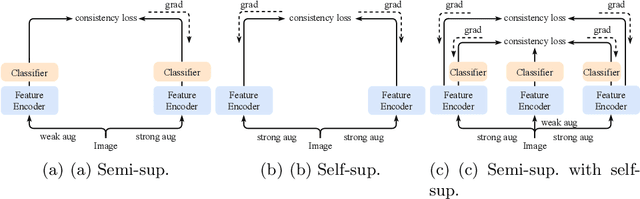
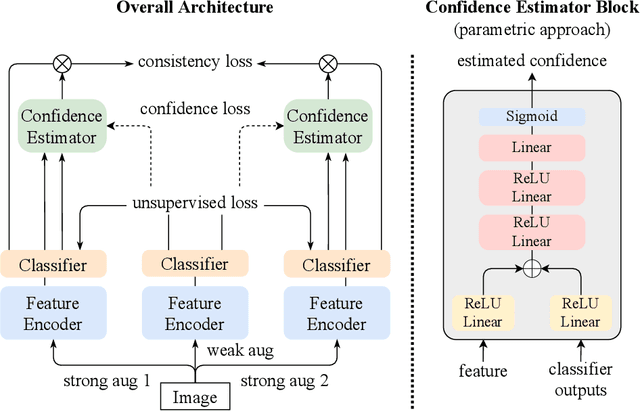
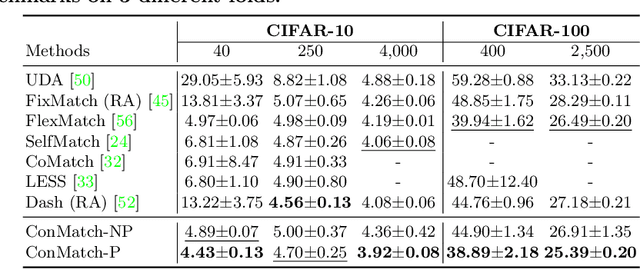
We present a novel semi-supervised learning framework that intelligently leverages the consistency regularization between the model's predictions from two strongly-augmented views of an image, weighted by a confidence of pseudo-label, dubbed ConMatch. While the latest semi-supervised learning methods use weakly- and strongly-augmented views of an image to define a directional consistency loss, how to define such direction for the consistency regularization between two strongly-augmented views remains unexplored. To account for this, we present novel confidence measures for pseudo-labels from strongly-augmented views by means of weakly-augmented view as an anchor in non-parametric and parametric approaches. Especially, in parametric approach, we present, for the first time, to learn the confidence of pseudo-label within the networks, which is learned with backbone model in an end-to-end manner. In addition, we also present a stage-wise training to boost the convergence of training. When incorporated in existing semi-supervised learners, ConMatch consistently boosts the performance. We conduct experiments to demonstrate the effectiveness of our ConMatch over the latest methods and provide extensive ablation studies. Code has been made publicly available at https://github.com/JiwonCocoder/ConMatch.
Federated Variational Learning for Anomaly Detection in Multivariate Time Series
Aug 29, 2021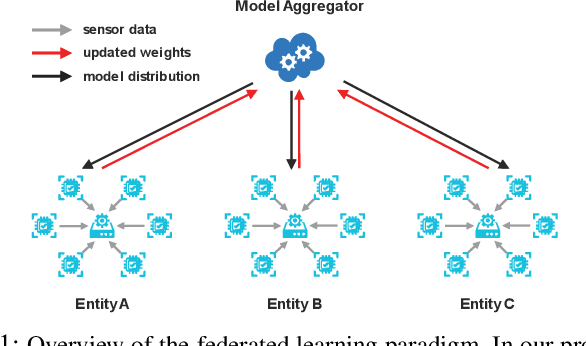
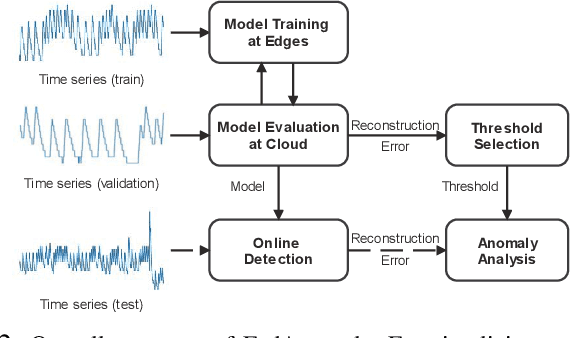
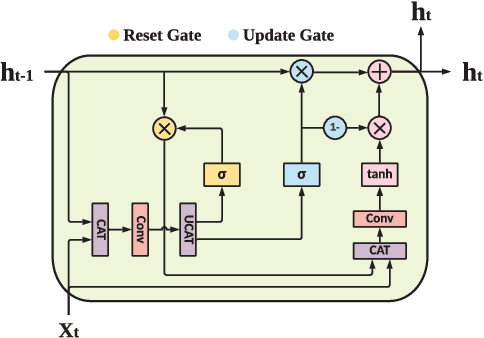
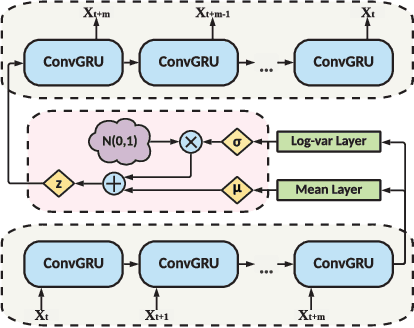
Anomaly detection has been a challenging task given high-dimensional multivariate time series data generated by networked sensors and actuators in Cyber-Physical Systems (CPS). Besides the highly nonlinear, complex, and dynamic natures of such time series, the lack of labeled data impedes data exploitation in a supervised manner and thus prevents an accurate detection of abnormal phenomenons. On the other hand, the collected data at the edge of the network is often privacy sensitive and large in quantity, which may hinder the centralized training at the main server. To tackle these issues, we propose an unsupervised time series anomaly detection framework in a federated fashion to continuously monitor the behaviors of interconnected devices within a network and alerts for abnormal incidents so that countermeasures can be taken before undesired consequences occur. To be specific, we leave the training data distributed at the edge to learn a shared Variational Autoencoder (VAE) based on Convolutional Gated Recurrent Unit (ConvGRU) model, which jointly captures feature and temporal dependencies in the multivariate time series data for representation learning and downstream anomaly detection tasks. Experiments on three real-world networked sensor datasets illustrate the advantage of our approach over other state-of-the-art models. We also conduct extensive experiments to demonstrate the effectiveness of our detection framework under non-federated and federated settings in terms of overall performance and detection latency.
Uncertainty Quantification for Traffic Forecasting: A Unified Approach
Aug 11, 2022
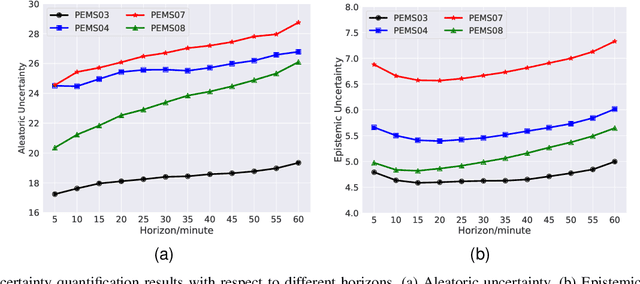
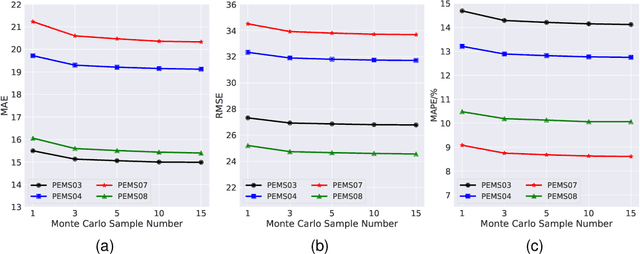
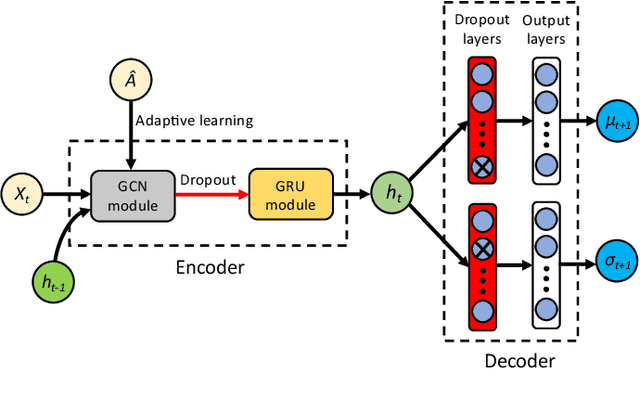
Uncertainty is an essential consideration for time series forecasting tasks. In this work, we specifically focus on quantifying the uncertainty of traffic forecasting. To achieve this, we develop Deep Spatio-Temporal Uncertainty Quantification (DeepSTUQ), which can estimate both aleatoric and epistemic uncertainty. We first leverage a spatio-temporal model to model the complex spatio-temporal correlations of traffic data. Subsequently, two independent sub-neural networks maximizing the heterogeneous log-likelihood are developed to estimate aleatoric uncertainty. For estimating epistemic uncertainty, we combine the merits of variational inference and deep ensembling by integrating the Monte Carlo dropout and the Adaptive Weight Averaging re-training methods, respectively. Finally, we propose a post-processing calibration approach based on Temperature Scaling, which improves the model's generalization ability to estimate uncertainty. Extensive experiments are conducted on four public datasets, and the empirical results suggest that the proposed method outperforms state-of-the-art methods in terms of both point prediction and uncertainty quantification.
Upper Limb Movement Recognition utilising EEG and EMG Signals for Rehabilitative Robotics
Jul 25, 2022
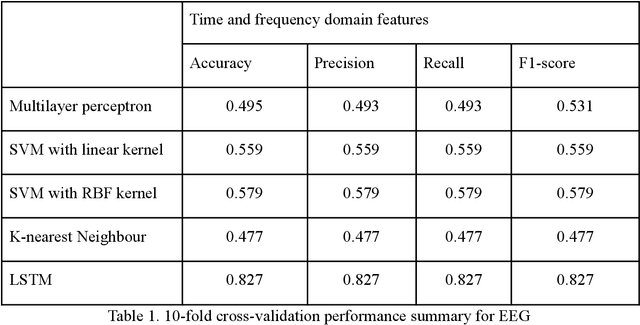
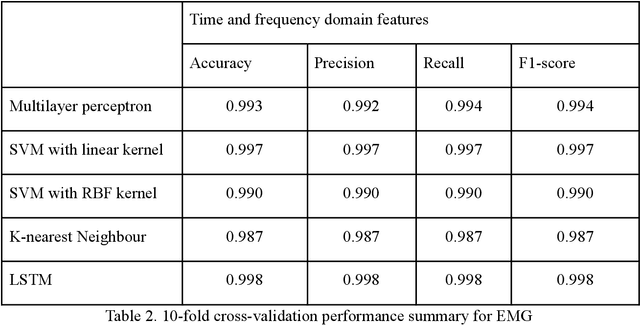
Upper limb movement classification, which maps input signals to the target activities, is one of the crucial areas in the control of rehabilitative robotics. Classifiers are trained for the rehabilitative system to comprehend the desires of the patient whose upper limbs do not function properly. Electromyography (EMG) signals and Electroencephalography (EEG) signals are used widely for upper limb movement classification. By analysing the classification results of the real-time EEG and EMG signals, the system can understand the intention of the user and predict the events that one would like to carry out. Accordingly, it will provide external help to the user to assist one to perform the activities. However, not all users process effective EEG and EMG signals due to the noisy environment. The noise in the real-time data collection process contaminates the effectiveness of the data. Moreover, not all patients process strong EMG signals due to muscle damage and neuromuscular disorder. To address these issues, we would like to propose a novel decision-level multisensor fusion technique. In short, the system will integrate EEG signals with EMG signals, retrieve effective information from both sources to understand and predict the desire of the user, and thus provide assistance. By testing out the proposed technique on a publicly available WAY-EEG-GAL dataset, which contains EEG and EMG signals that were recorded simultaneously, we manage to conclude the feasibility and effectiveness of the novel system.