 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Fuse and Attend: Generalized Embedding Learning for Art and Sketches
Aug 20, 2022
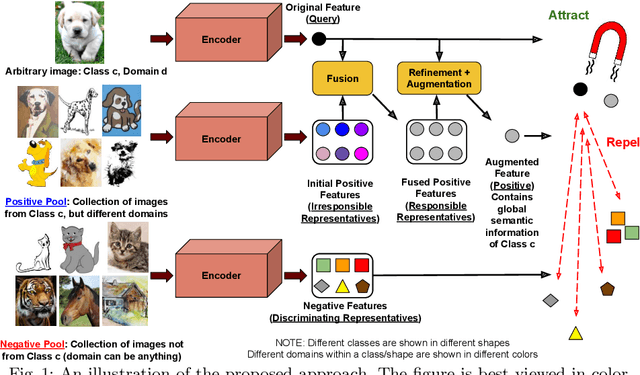
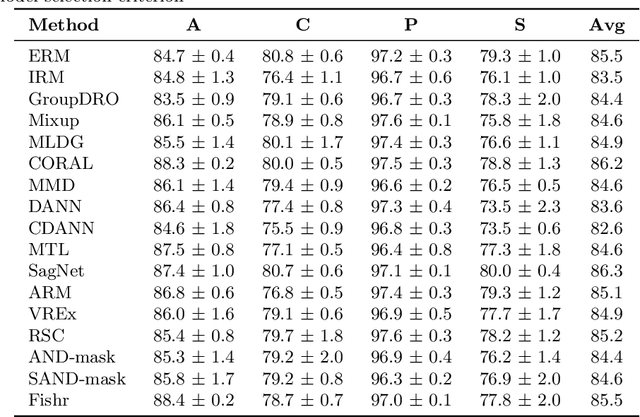
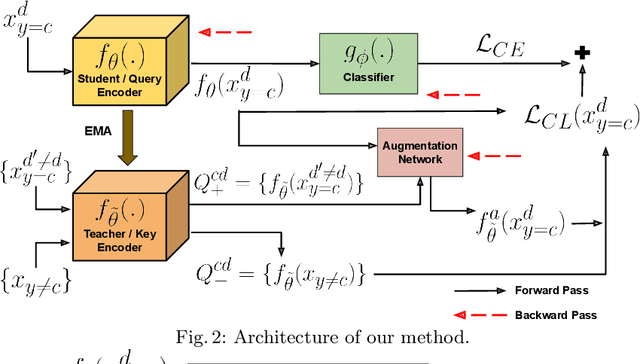
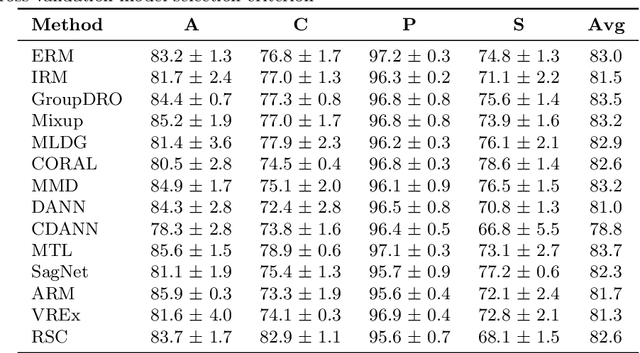
While deep Embedding Learning approaches have witnessed widespread success in multiple computer vision tasks, the state-of-the-art methods for representing natural images need not necessarily perform well on images from other domains, such as paintings, cartoons, and sketch. This is because of the huge shift in the distribution of data from across these domains, as compared to natural images. Domains like sketch often contain sparse informative pixels. However, recognizing objects in such domains is crucial, given multiple relevant applications leveraging such data, for instance, sketch to image retrieval. Thus, achieving an Embedding Learning model that could perform well across multiple domains is not only challenging, but plays a pivotal role in computer vision. To this end, in this paper, we propose a novel Embedding Learning approach with the goal of generalizing across different domains. During training, given a query image from a domain, we employ gated fusion and attention to generate a positive example, which carries a broad notion of the semantics of the query object category (from across multiple domains). By virtue of Contrastive Learning, we pull the embeddings of the query and positive, in order to learn a representation which is robust across domains. At the same time, to teach the model to be discriminative against examples from different semantic categories (across domains), we also maintain a pool of negative embeddings (from different categories). We show the prowess of our method using the DomainBed framework, on the popular PACS (Photo, Art painting, Cartoon, and Sketch) dataset.
LIP: Lightweight Intelligent Preprocessor for meaningful text-to-speech
Jul 11, 2022
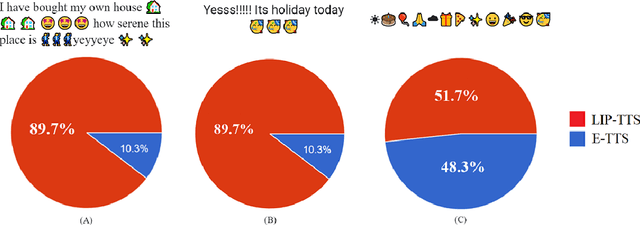
Existing Text-to-Speech (TTS) systems need to read messages from the email which may have Personal Identifiable Information (PII) to text messages that can have a streak of emojis and punctuation. 92% of the world's online population use emoji with more than 10 billion emojis sent everyday. Lack of preprocessor leads to messages being read as-is including punctuation and infographics like emoticons. This problem worsens if there is a continuous sequence of punctuation/emojis that are quite common in real-world communications like messaging, Social Networking Site (SNS) interactions, etc. In this work, we aim to introduce a lightweight intelligent preprocessor (LIP) that can enhance the readability of a message before being passed downstream to existing TTS systems. We propose multiple sub-modules including: expanding contraction, censoring swear words, and masking of PII, as part of our preprocessor to enhance the readability of text. With a memory footprint of only 3.55 MB and inference time of 4 ms for up to 50-character text, our solution is suitable for real-time deployment. This work being the first of its kind, we try to benchmark with an open independent survey, the result of which shows 76.5% preference towards LIP enabled TTS engine as compared to standard TTS.
A real-time spatiotemporal AI model analyzes skill in open surgical videos
Dec 14, 2021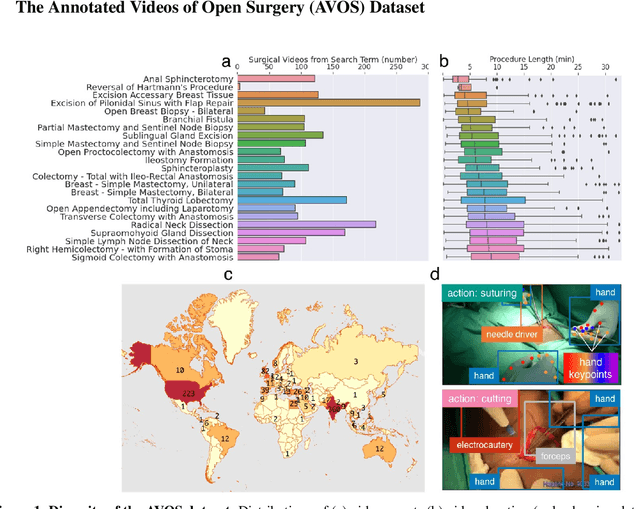
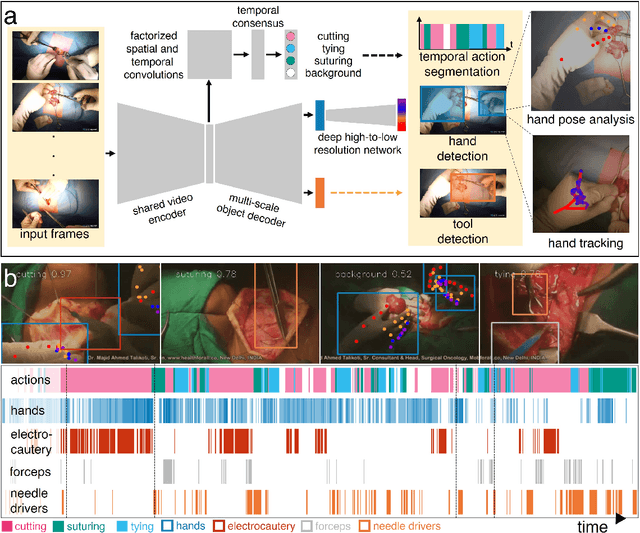
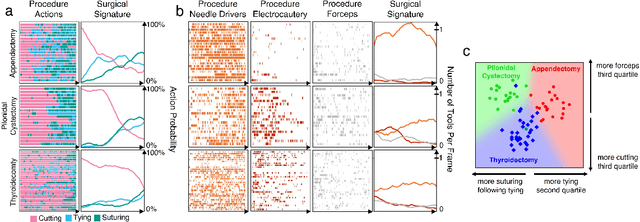
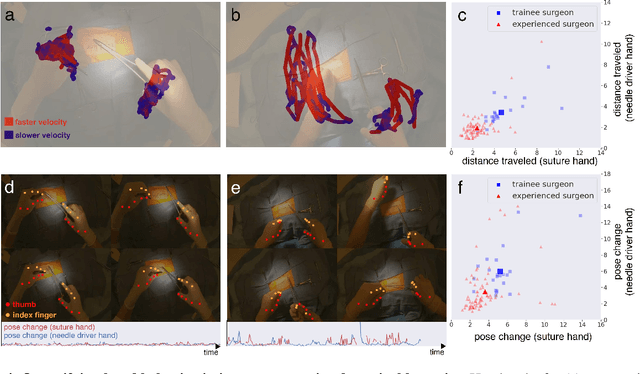
Open procedures represent the dominant form of surgery worldwide. Artificial intelligence (AI) has the potential to optimize surgical practice and improve patient outcomes, but efforts have focused primarily on minimally invasive techniques. Our work overcomes existing data limitations for training AI models by curating, from YouTube, the largest dataset of open surgical videos to date: 1997 videos from 23 surgical procedures uploaded from 50 countries. Using this dataset, we developed a multi-task AI model capable of real-time understanding of surgical behaviors, hands, and tools - the building blocks of procedural flow and surgeon skill. We show that our model generalizes across diverse surgery types and environments. Illustrating this generalizability, we directly applied our YouTube-trained model to analyze open surgeries prospectively collected at an academic medical center and identified kinematic descriptors of surgical skill related to efficiency of hand motion. Our Annotated Videos of Open Surgery (AVOS) dataset and trained model will be made available for further development of surgical AI.
Deep Unsupervised Domain Adaptation: A Review of Recent Advances and Perspectives
Aug 15, 2022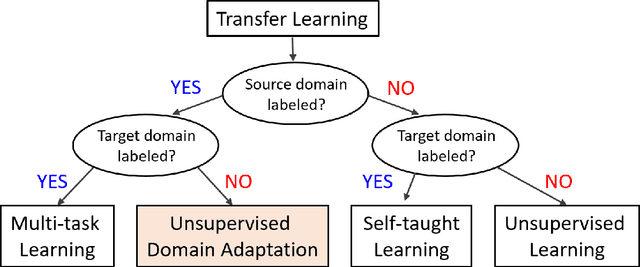

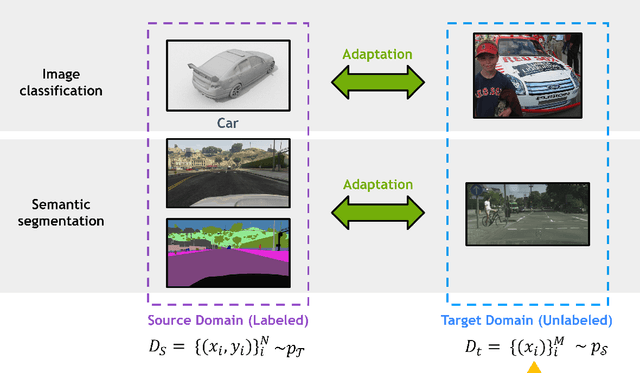
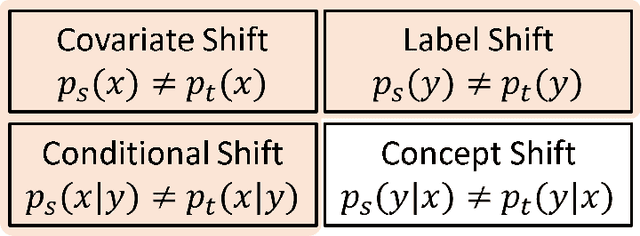
Deep learning has become the method of choice to tackle real-world problems in different domains, partly because of its ability to learn from data and achieve impressive performance on a wide range of applications. However, its success usually relies on two assumptions: (i) vast troves of labeled datasets are required for accurate model fitting, and (ii) training and testing data are independent and identically distributed. Its performance on unseen target domains, thus, is not guaranteed, especially when encountering out-of-distribution data at the adaptation stage. The performance drop on data in a target domain is a critical problem in deploying deep neural networks that are successfully trained on data in a source domain. Unsupervised domain adaptation (UDA) is proposed to counter this, by leveraging both labeled source domain data and unlabeled target domain data to carry out various tasks in the target domain. UDA has yielded promising results on natural image processing, video analysis, natural language processing, time-series data analysis, medical image analysis, etc. In this review, as a rapidly evolving topic, we provide a systematic comparison of its methods and applications. In addition, the connection of UDA with its closely related tasks, e.g., domain generalization and out-of-distribution detection, has also been discussed. Furthermore, deficiencies in current methods and possible promising directions are highlighted.
A Framework for Imbalanced Time-series Forecasting
Jul 22, 2021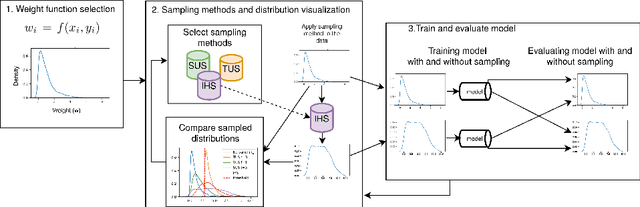
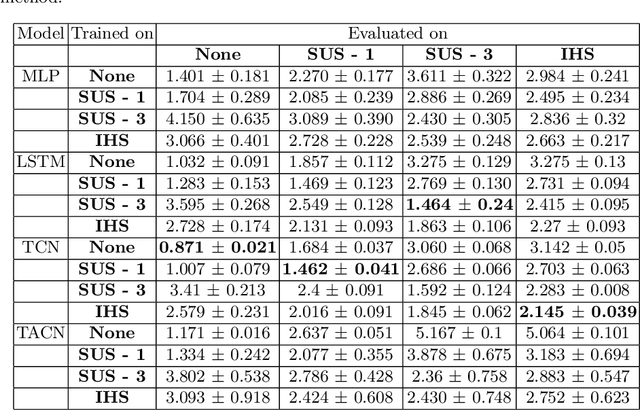
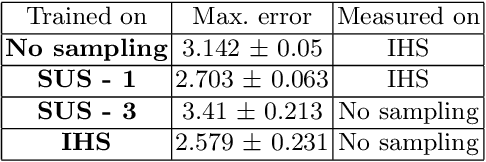
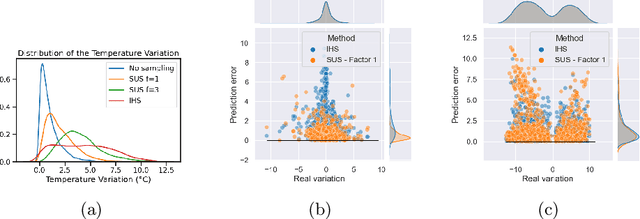
Time-series forecasting plays an important role in many domains. Boosted by the advances in Deep Learning algorithms, it has for instance been used to predict wind power for eolic energy production, stock market fluctuations, or motor overheating. In some of these tasks, we are interested in predicting accurately some particular moments which often are underrepresented in the dataset, resulting in a problem known as imbalanced regression. In the literature, while recognized as a challenging problem, limited attention has been devoted on how to handle the problem in a practical setting. In this paper, we put forward a general approach to analyze time-series forecasting problems focusing on those underrepresented moments to reduce imbalances. Our approach has been developed based on a case study in a large industrial company, which we use to exemplify the approach.
Fast-Vid2Vid: Spatial-Temporal Compression for Video-to-Video Synthesis
Jul 11, 2022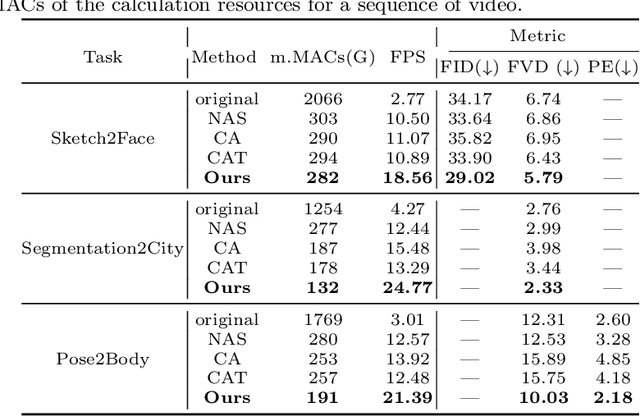
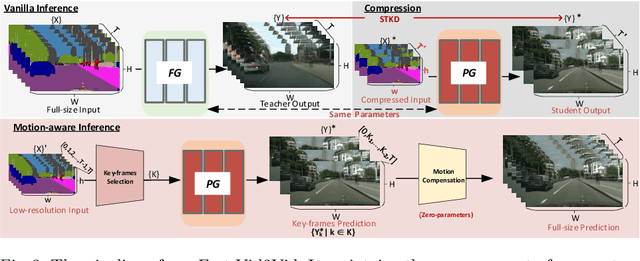
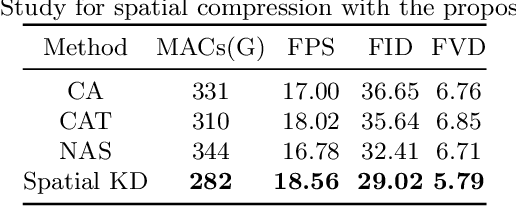
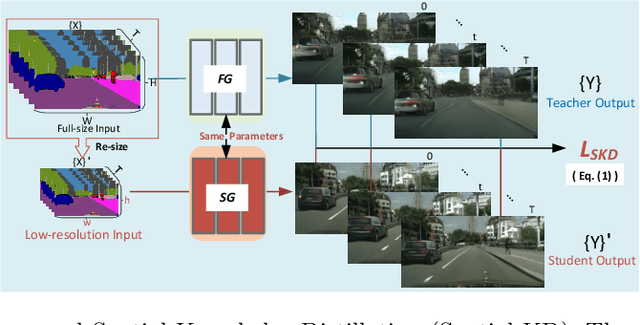
Video-to-Video synthesis (Vid2Vid) has achieved remarkable results in generating a photo-realistic video from a sequence of semantic maps. However, this pipeline suffers from high computational cost and long inference latency, which largely depends on two essential factors: 1) network architecture parameters, 2) sequential data stream. Recently, the parameters of image-based generative models have been significantly compressed via more efficient network architectures. Nevertheless, existing methods mainly focus on slimming network architectures and ignore the size of the sequential data stream. Moreover, due to the lack of temporal coherence, image-based compression is not sufficient for the compression of the video task. In this paper, we present a spatial-temporal compression framework, \textbf{Fast-Vid2Vid}, which focuses on data aspects of generative models. It makes the first attempt at time dimension to reduce computational resources and accelerate inference. Specifically, we compress the input data stream spatially and reduce the temporal redundancy. After the proposed spatial-temporal knowledge distillation, our model can synthesize key-frames using the low-resolution data stream. Finally, Fast-Vid2Vid interpolates intermediate frames by motion compensation with slight latency. On standard benchmarks, Fast-Vid2Vid achieves around real-time performance as 20 FPS and saves around 8x computational cost on a single V100 GPU.
TASKOGRAPHY: Evaluating robot task planning over large 3D scene graphs
Jul 11, 2022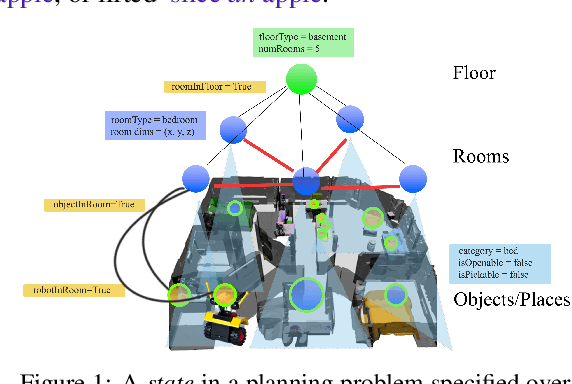
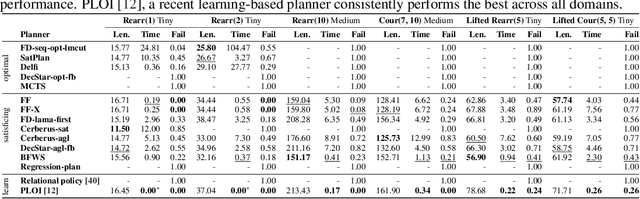
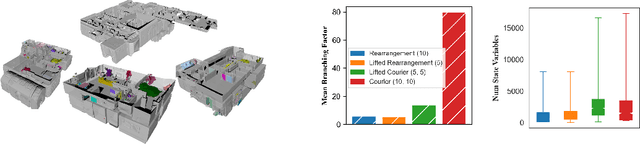
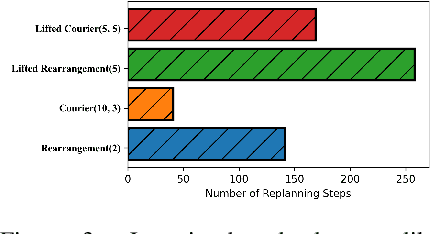
3D scene graphs (3DSGs) are an emerging description; unifying symbolic, topological, and metric scene representations. However, typical 3DSGs contain hundreds of objects and symbols even for small environments; rendering task planning on the full graph impractical. We construct TASKOGRAPHY, the first large-scale robotic task planning benchmark over 3DSGs. While most benchmarking efforts in this area focus on vision-based planning, we systematically study symbolic planning, to decouple planning performance from visual representation learning. We observe that, among existing methods, neither classical nor learning-based planners are capable of real-time planning over full 3DSGs. Enabling real-time planning demands progress on both (a) sparsifying 3DSGs for tractable planning and (b) designing planners that better exploit 3DSG hierarchies. Towards the former goal, we propose SCRUB, a task-conditioned 3DSG sparsification method; enabling classical planners to match and in some cases surpass state-of-the-art learning-based planners. Towards the latter goal, we propose SEEK, a procedure enabling learning-based planners to exploit 3DSG structure, reducing the number of replanning queries required by current best approaches by an order of magnitude. We will open-source all code and baselines to spur further research along the intersections of robot task planning, learning and 3DSGs.
* Video: https://www.youtube.com/watch?v=mM4v5hP4LdA&ab_channel=KrishnaMurthy . Project page: https://taskography.github.io/ . 18 pages, 7 figures. In proceedings of Conference on Robot Learning (CoRL) 2021. The first two authors contributed equally
Quantum-Inspired Tensor Neural Networks for Partial Differential Equations
Aug 03, 2022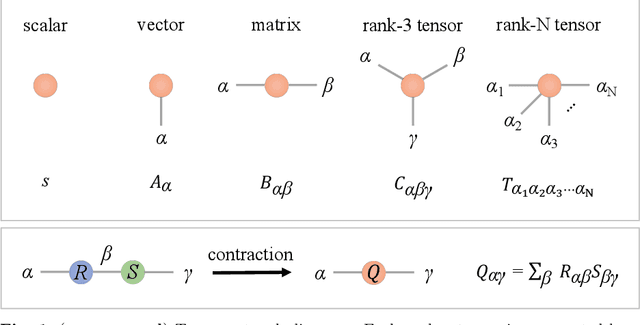
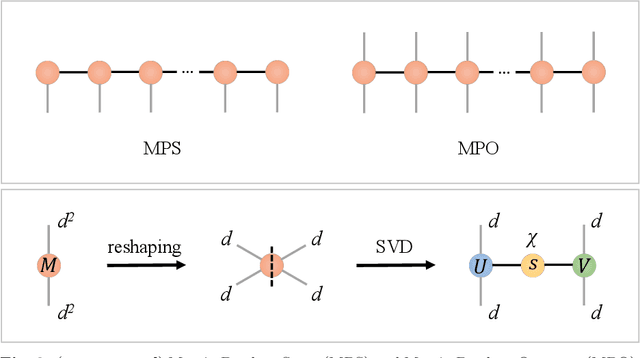
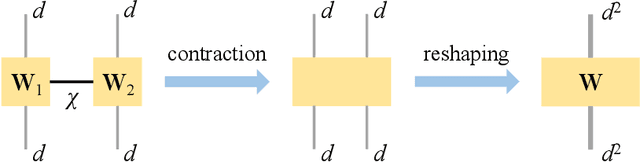
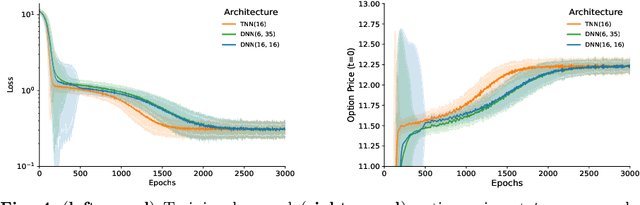
Partial Differential Equations (PDEs) are used to model a variety of dynamical systems in science and engineering. Recent advances in deep learning have enabled us to solve them in a higher dimension by addressing the curse of dimensionality in new ways. However, deep learning methods are constrained by training time and memory. To tackle these shortcomings, we implement Tensor Neural Networks (TNN), a quantum-inspired neural network architecture that leverages Tensor Network ideas to improve upon deep learning approaches. We demonstrate that TNN provide significant parameter savings while attaining the same accuracy as compared to the classical Dense Neural Network (DNN). In addition, we also show how TNN can be trained faster than DNN for the same accuracy. We benchmark TNN by applying them to solve parabolic PDEs, specifically the Black-Scholes-Barenblatt equation, widely used in financial pricing theory, empirically showing the advantages of TNN over DNN. Further examples, such as the Hamilton-Jacobi-Bellman equation, are also discussed.
A Time-Series Scale Mixture Model of EEG with a Hidden Markov Structure for Epileptic Seizure Detection
Nov 12, 2021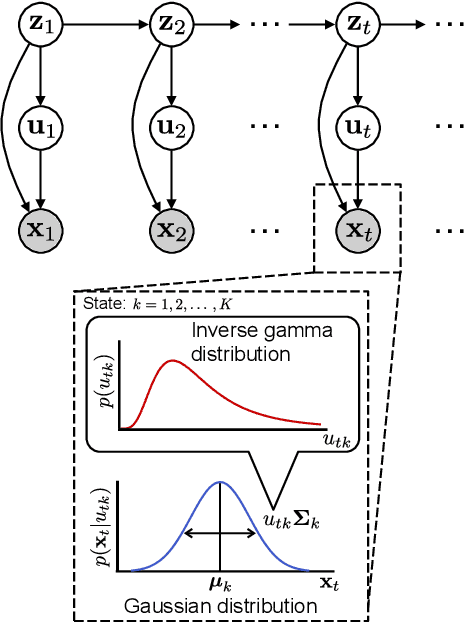
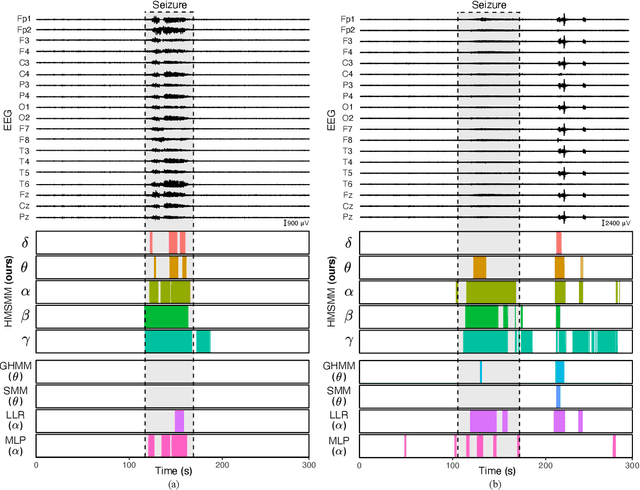
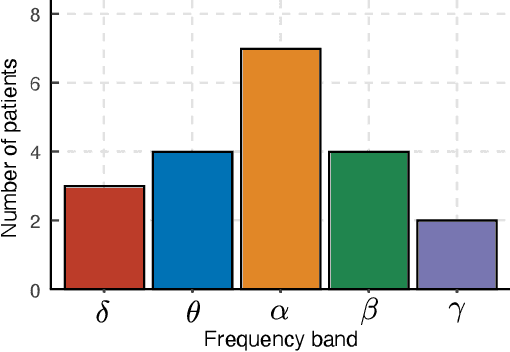
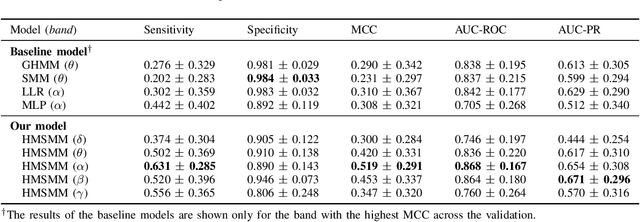
In this paper, we propose a time-series stochastic model based on a scale mixture distribution with Markov transitions to detect epileptic seizures in electroencephalography (EEG). In the proposed model, an EEG signal at each time point is assumed to be a random variable following a Gaussian distribution. The covariance matrix of the Gaussian distribution is weighted with a latent scale parameter, which is also a random variable, resulting in the stochastic fluctuations of covariances. By introducing a latent state variable with a Markov chain in the background of this stochastic relationship, time-series changes in the distribution of latent scale parameters can be represented according to the state of epileptic seizures. In an experiment, we evaluated the performance of the proposed model for seizure detection using EEGs with multiple frequency bands decomposed from a clinical dataset. The results demonstrated that the proposed model can detect seizures with high sensitivity and outperformed several baselines.
Estimating Uncertainty of Autonomous Vehicle Systems with Generalized Polynomial Chaos
Aug 03, 2022

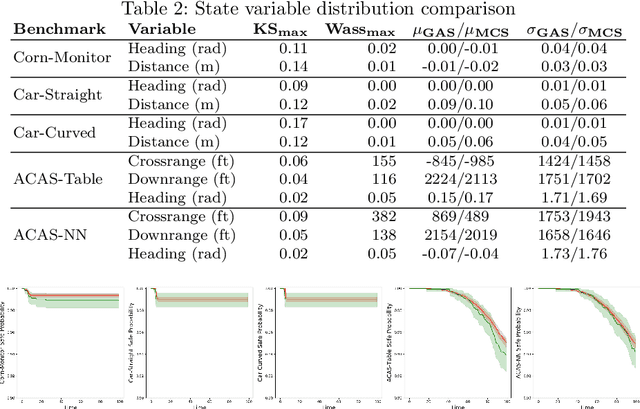

Modern autonomous vehicle systems use complex perception and control components and must cope with uncertain data received from sensors. To estimate the probability that such vehicles remain in a safe state, developers often resort to time-consuming simulation methods. This paper presents an alternative methodology for analyzing autonomy pipelines in vehicular systems, based on Generalized Polynomial Chaos (GPC). We also present GAS, the first algorithm for creating and using GPC models of complex vehicle systems. GAS replaces complex perception components with a perception model to reduce complexity. Then, it constructs the GPC model and uses it for estimating state distribution and/or probability of entering an unsafe state. We evaluate GAS on five scenarios used in crop management vehicles, self driving cars, and aerial drones - each system uses at least one complex perception or control component. We show that GAS calculates state distributions that closely match those produced by Monte Carlo Simulation, while also providing 2.3x-3.0x speedups.