 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Fast optical refocusing through multimode fiber bend using Cake-Cutting Hadamard encoding algorithm to improve robustness
Jul 27, 2022
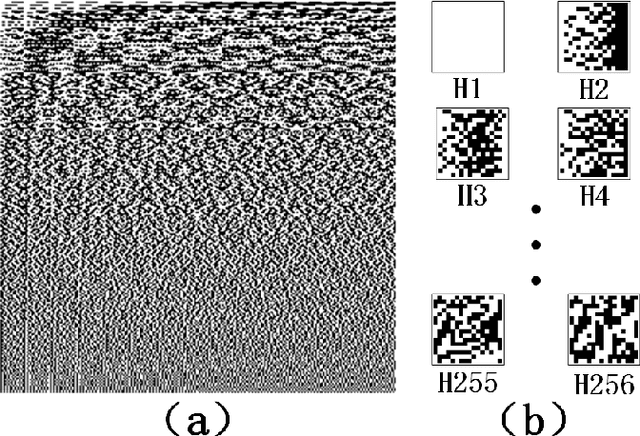

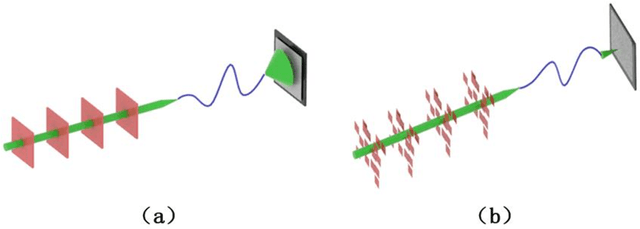
Multimode fibres offer the advantages of high resolution and miniaturization over single mode fibers in the field of optical imaging. However, multimode fibre's imaging is susceptible to perturbations of MMF that can lead to secondary spatial distortions in the transmitted image. Perturbations include random disturbances in the fiber as well as environmental noise. Here, we exploit the fast focusing capability of the Cake-Cutting Hadamard coding algorithm to counteract the effects of perturbations and improve the system's robustness. Simulation shows that it can approach the theoretical enhancement at 2000 measurements. Experimental results show that the algorithm can help the system to refocus in a short time when MMFs are perturbed. This research will further contribute to using multimode fibres in medicine, communication, and detection.
Time-Aware Language Models as Temporal Knowledge Bases
Jun 29, 2021
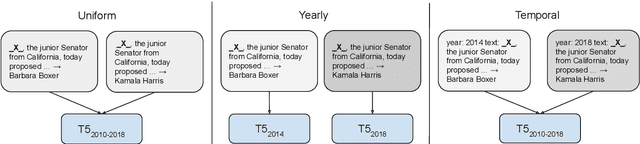
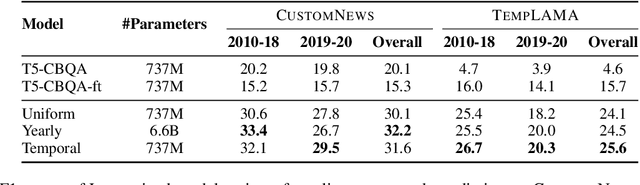
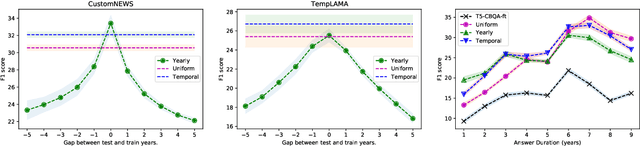
Many facts come with an expiration date, from the name of the President to the basketball team Lebron James plays for. But language models (LMs) are trained on snapshots of data collected at a specific moment in time, and this can limit their utility, especially in the closed-book setting where the pretraining corpus must contain the facts the model should memorize. We introduce a diagnostic dataset aimed at probing LMs for factual knowledge that changes over time and highlight problems with LMs at either end of the spectrum -- those trained on specific slices of temporal data, as well as those trained on a wide range of temporal data. To mitigate these problems, we propose a simple technique for jointly modeling text with its timestamp. This improves memorization of seen facts from the training time period, as well as calibration on predictions about unseen facts from future time periods. We also show that models trained with temporal context can be efficiently ``refreshed'' as new data arrives, without the need for retraining from scratch.
Pattern Spotting and Image Retrieval in Historical Documents using Deep Hashing
Aug 04, 2022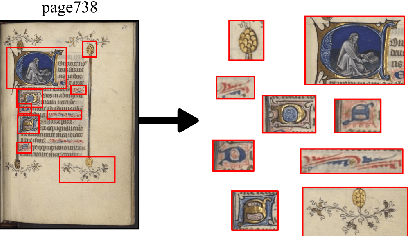
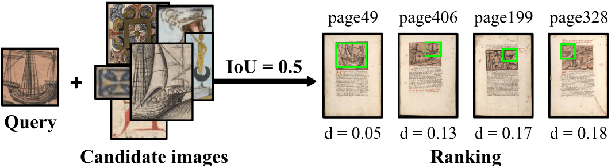


This paper presents a deep learning approach for image retrieval and pattern spotting in digital collections of historical documents. First, a region proposal algorithm detects object candidates in the document page images. Next, deep learning models are used for feature extraction, considering two distinct variants, which provide either real-valued or binary code representations. Finally, candidate images are ranked by computing the feature similarity with a given input query. A robust experimental protocol evaluates the proposed approach considering each representation scheme (real-valued and binary code) on the DocExplore image database. The experimental results show that the proposed deep models compare favorably to the state-of-the-art image retrieval approaches for images of historical documents, outperforming other deep models by 2.56 percentage points using the same techniques for pattern spotting. Besides, the proposed approach also reduces the search time by up to 200x and the storage cost up to 6,000x when compared to related works based on real-valued representations.
Opinion Market Model: Stemming Far-Right Opinion Spread using Positive Interventions
Aug 13, 2022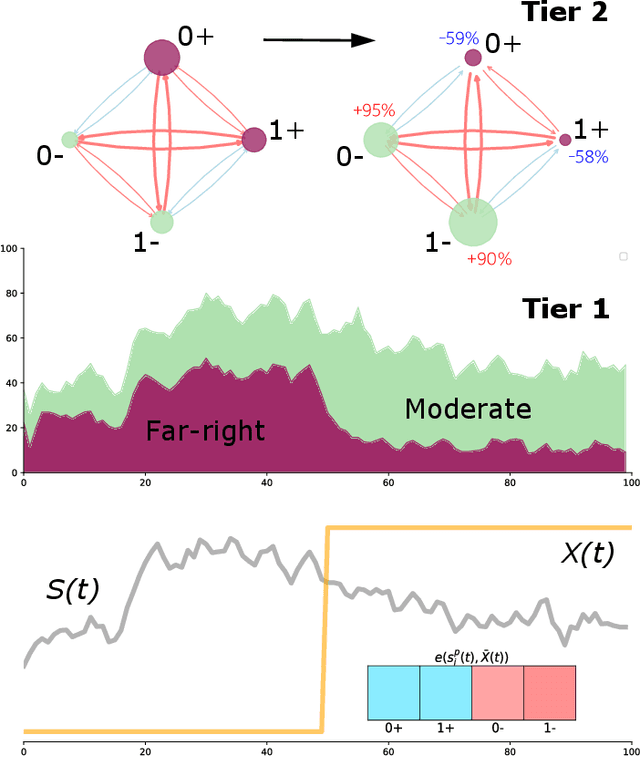
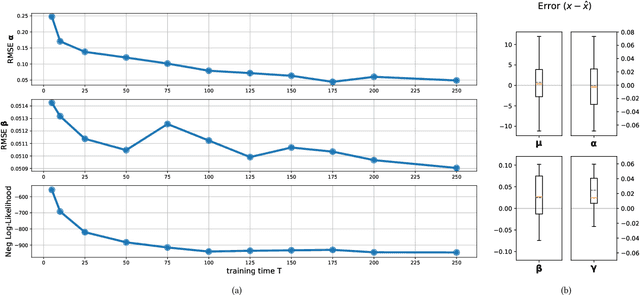
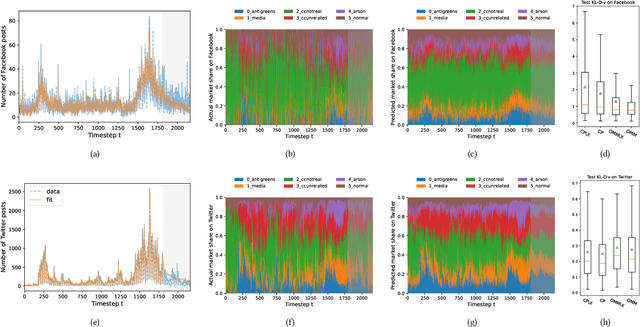
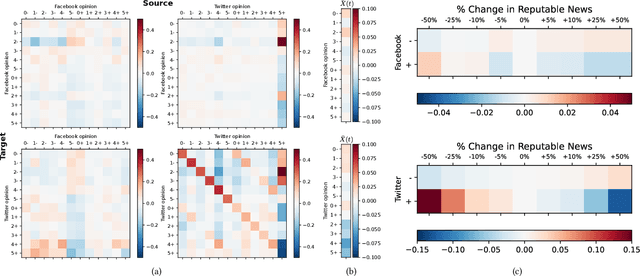
Recent years have seen the rise of extremist views in the opinion ecosystem we call social media. Allowing online extremism to persist has dire societal consequences, and efforts to mitigate it are continuously explored. Positive interventions, controlled signals that add attention to the opinion ecosystem with the aim of boosting certain opinions, are one such pathway for mitigation. This work proposes a platform to test the effectiveness of positive interventions, through the Opinion Market Model (OMM), a two-tier model of the online opinion ecosystem jointly accounting for both inter-opinion interactions and the role of positive interventions. The first tier models the size of the opinion attention market using the multivariate discrete-time Hawkes process; the second tier leverages the market share attraction model to model opinions cooperating and competing for market share given limited attention. On a synthetic dataset, we show the convergence of our proposed estimation scheme. On a dataset of Facebook and Twitter discussions containing moderate and far-right opinions about bushfires and climate change, we show superior predictive performance over the state-of-the-art and the ability to uncover latent opinion interactions. Lastly, we use OMM to demonstrate the effectiveness of mainstream media coverage as a positive intervention in suppressing far-right opinions.
Runtime Analysis of Competitive co-Evolutionary Algorithms for Maximin Optimisation of a Bilinear Function
Jun 30, 2022
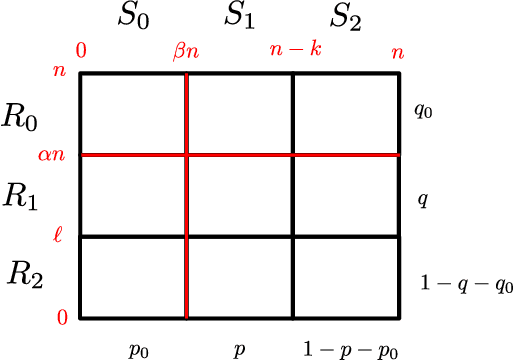
Co-evolutionary algorithms have a wide range of applications, such as in hardware design, evolution of strategies for board games, and patching software bugs. However, these algorithms are poorly understood and applications are often limited by pathological behaviour, such as loss of gradient, relative over-generalisation, and mediocre objective stasis. It is an open challenge to develop a theory that can predict when co-evolutionary algorithms find solutions efficiently and reliable. This paper provides a first step in developing runtime analysis for population-based competitive co-evolutionary algorithms. We provide a mathematical framework for describing and reasoning about the performance of co-evolutionary processes. An example application of the framework shows a scenario where a simple co-evolutionary algorithm obtains a solution in polynomial expected time. Finally, we describe settings where the co-evolutionary algorithm needs exponential time with overwhelmingly high probability to obtain a solution.
Looking for a Needle in a Haystack: A Comprehensive Study of Hallucinations in Neural Machine Translation
Aug 10, 2022

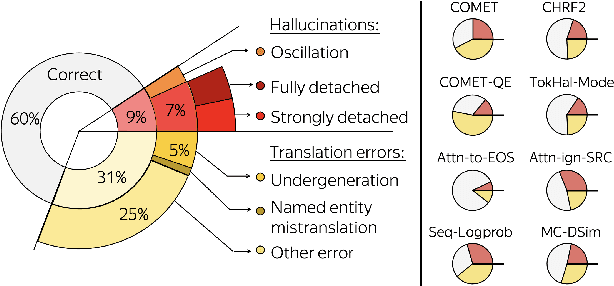
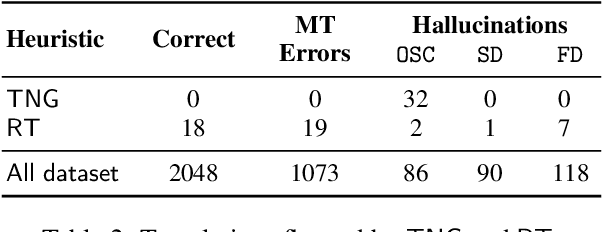
Although the problem of hallucinations in neural machine translation (NMT) has received some attention, research on this highly pathological phenomenon lacks solid ground. Previous work has been limited in several ways: it often resorts to artificial settings where the problem is amplified, it disregards some (common) types of hallucinations, and it does not validate adequacy of detection heuristics. In this paper, we set foundations for the study of NMT hallucinations. First, we work in a natural setting, i.e., in-domain data without artificial noise neither in training nor in inference. Next, we annotate a dataset of over 3.4k sentences indicating different kinds of critical errors and hallucinations. Then, we turn to detection methods and both revisit methods used previously and propose using glass-box uncertainty-based detectors. Overall, we show that for preventive settings, (i) previously used methods are largely inadequate, (ii) sequence log-probability works best and performs on par with reference-based methods. Finally, we propose DeHallucinator, a simple method for alleviating hallucinations at test time that significantly reduces the hallucinatory rate. To ease future research, we release our annotated dataset for WMT18 German-English data, along with the model, training data, and code.
Time Adaptive Gaussian Model
Feb 03, 2021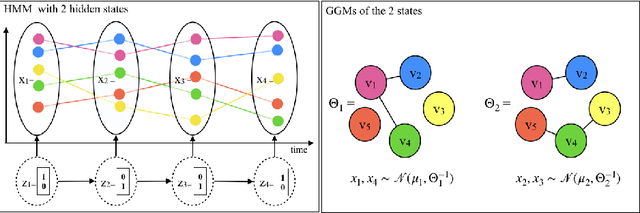
Multivariate time series analysis is becoming an integral part of data analysis pipelines. Understanding the individual time point connections between covariates as well as how these connections change in time is non-trivial. To this aim, we propose a novel method that leverages on Hidden Markov Models and Gaussian Graphical Models -- Time Adaptive Gaussian Model (TAGM). Our model is a generalization of state-of-the-art methods for the inference of temporal graphical models, its formulation leverages on both aspects of these models providing better results than current methods. In particular,it performs pattern recognition by clustering data points in time; and, it finds probabilistic (and possibly causal) relationships among the observed variables. Compared to current methods for temporal network inference, it reduces the basic assumptions while still showing good inference performances.
Factorizable Joint Shift in Multinomial Classification
Jul 29, 2022Factorizable joint shift was recently proposed as a type of dataset shift for which the characteristics can be estimated from observed data. For the multinomial (multi-class) classification setting, we derive a representation of factorizable joint shift in terms of the source (training) distribution, the target (test) prior class probabilities and the target marginal distribution of the features. On the basis of this result, we propose alternatives to joint importance aligning, at the same time pointing out the limitations encountered when making an assumption of factorizable joint shift. Other results of the paper include correction formulae for the posterior class probabilities both under general dataset shift and factorizable joint shift. In addition, we investigate the consequences of assuming factorizable joint shift for the bias caused by sample selection.
ASUMAN: Age Sense Updating Multiple Access in Networks
Jul 14, 2022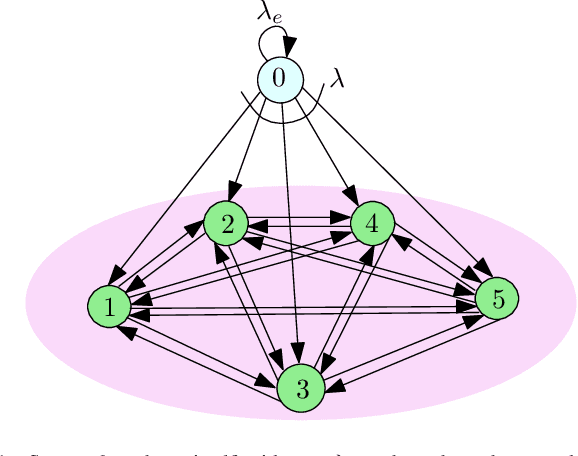
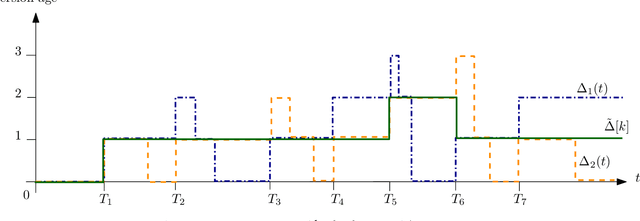
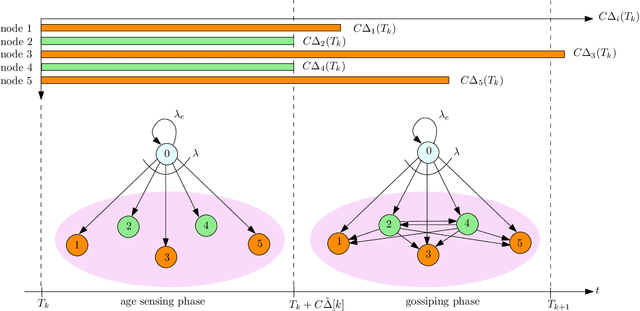
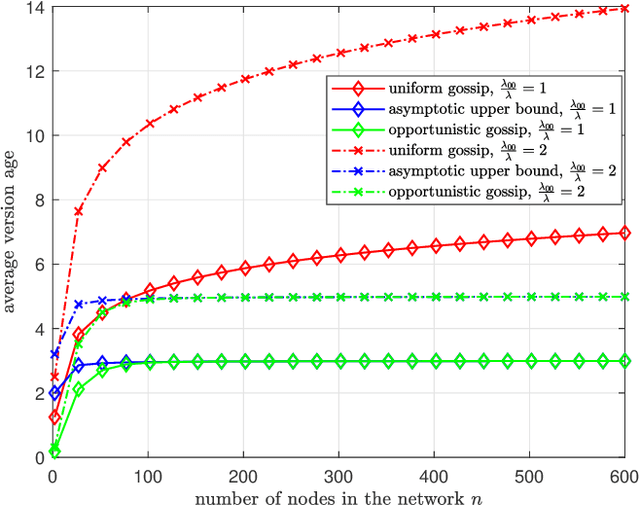
We consider a fully-connected wireless gossip network which consists of a source and $n$ receiver nodes. The source updates itself with a Poisson process and also sends updates to the nodes as Poisson arrivals. Upon receiving the updates, the nodes update their knowledge about the source. The nodes gossip the data among themselves in the form of Poisson arrivals to disperse their knowledge about the source. The total gossiping rate is bounded by a constraint. The goal of the network is to be as timely as possible with the source. In this work, we propose ASUMAN, a distributed opportunistic gossiping scheme, where after each time the source updates itself, each node waits for a time proportional to its current age and broadcasts a signal to the other nodes of the network. This allows the nodes in the network which have higher age to remain silent and only the low-age nodes to gossip, thus utilizing a significant portion of the constrained total gossip rate. We calculate the average age for a typical node in such a network with symmetric settings and show that the theoretical upper bound on the age scales as $O(1)$. ASUMAN, with an average age of $O(1)$, offers significant gains compared to a system where the nodes just gossip blindly with a fixed update rate in which case the age scales as $O(\log n)$.
Accelerating Numerical Solvers for Large-Scale Simulation of Dynamical System via NeurVec
Aug 07, 2022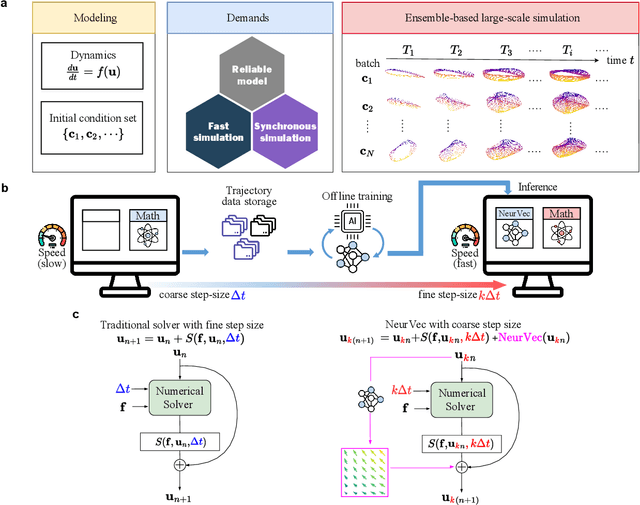

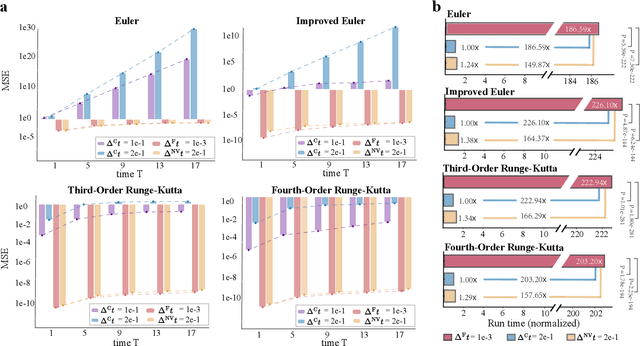
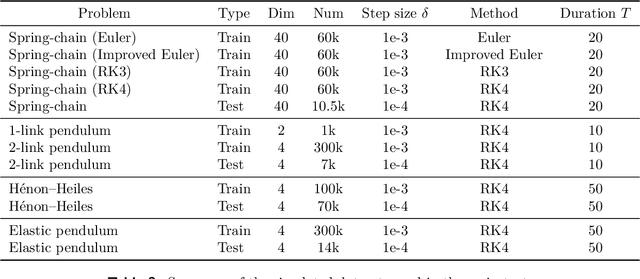
Ensemble-based large-scale simulation of dynamical systems is essential to a wide range of science and engineering problems. Conventional numerical solvers used in the simulation are significantly limited by the step size for time integration, which hampers efficiency and feasibility especially when high accuracy is desired. To overcome this limitation, we propose a data-driven corrector method that allows using large step sizes while compensating for the integration error for high accuracy. This corrector is represented in the form of a vector-valued function and is modeled by a neural network to regress the error in the phase space. Hence we name the corrector neural vector (NeurVec). We show that NeurVec can achieve the same accuracy as traditional solvers with much larger step sizes. We empirically demonstrate that NeurVec can accelerate a variety of numerical solvers significantly and overcome the stability restriction of these solvers. Our results on benchmark problems, ranging from high-dimensional problems to chaotic systems, suggest that NeurVec is capable of capturing the leading error term and maintaining the statistics of ensemble forecasts.