 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Multimodal Estimation of End Point Force During Quasi-dynamic and Dynamic Muscle Contractions Using Deep Learning
Jul 20, 2022
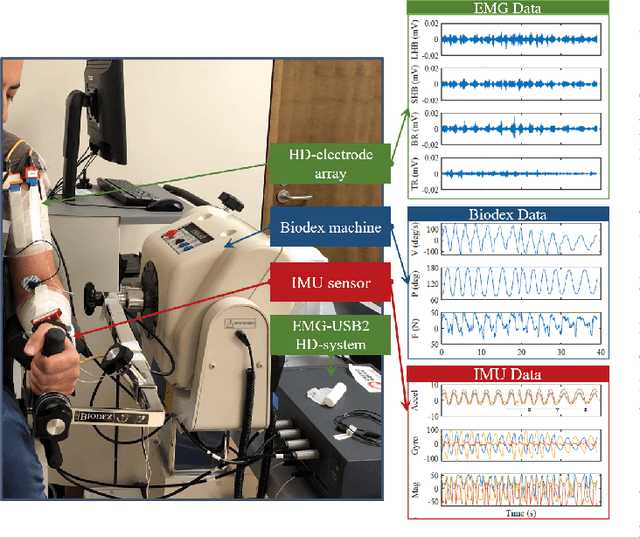
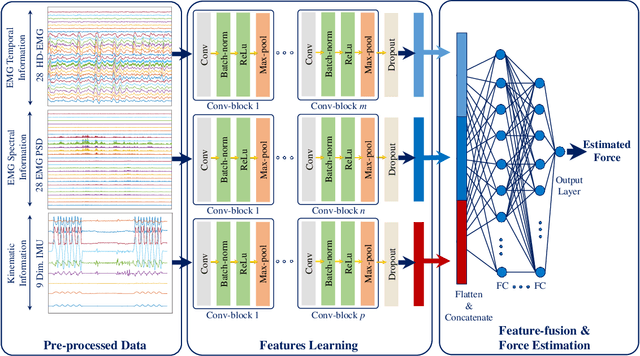
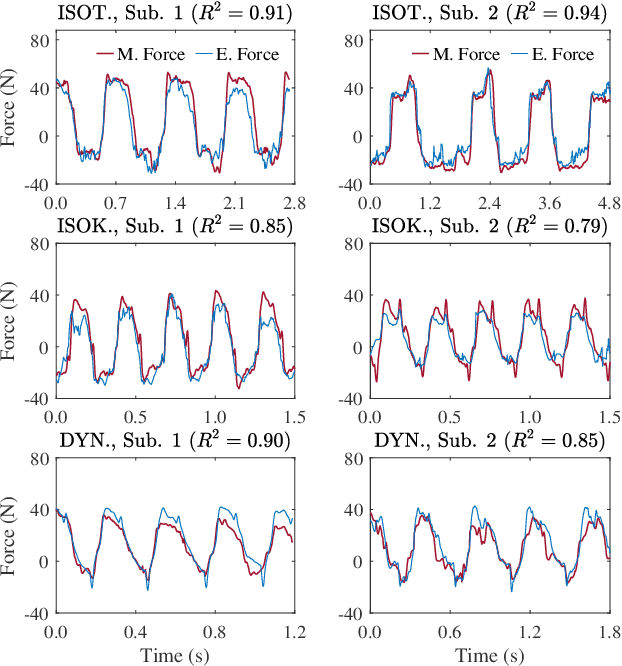
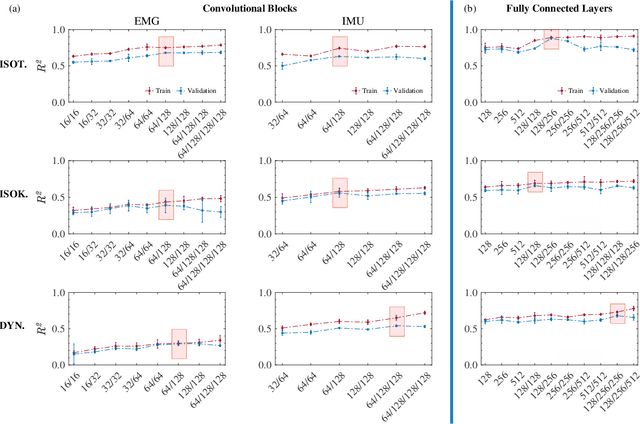
Accurate force/torque estimation is essential for applications such as powered exoskeletons, robotics, and rehabilitation. However, force/torque estimation under dynamic conditions is a challenging due to changing joint angles, force levels, muscle lengths, and movement speeds. We propose a novel method to accurately model the generated force under isotonic, isokinetic (quasi-dynamic), and fully dynamic conditions. Our solution uses a deep multimodal CNN to learn from multimodal EMG-IMU data and estimate the generated force for elbow flexion and extension, for both intra- and inter-subject schemes. The proposed deep multimodal CNN extracts representations from EMG (in time and frequency domains) and IMU (in time domain) and aggregates them to obtain an effective embedding for force estimation. We describe a new dataset containing EMG, IMU, and output force data, collected under a number of different experimental conditions, and use this dataset to evaluate our proposed method. The results show the robustness of our approach in comparison to other baseline methods as well as those in the literature, in different experimental setups and validation schemes. The obtained $R^2$ values are 0.91$\pm$0.034, 0.87$\pm$0.041, and 0.81$\pm$0.037 for the intra-subject and 0.81$\pm$0.048, 0.64$\pm$0.037, and 0.59$\pm$0.042 for the inter-subject scheme, during isotonic, isokinetic, and dynamic contractions, respectively. Additionally, our results indicate that force estimation improves significantly when the kinematic information (IMU data) is included. Average improvements of 13.95\%, 118.18\%, and 50.0\% (intra-subject) and 28.98\%, 41.18\%, and 137.93\% (inter-subject) for isotonic, isokinetic, and dynamic contractions respectively are achieved.
XAI Methods for Neural Time Series Classification: A Brief Review
Aug 18, 2021Deep learning models have recently demonstrated remarkable results in a variety of tasks, which is why they are being increasingly applied in high-stake domains, such as industry, medicine, and finance. Considering that automatic predictions in these domains might have a substantial impact on the well-being of a person, as well as considerable financial and legal consequences to an individual or a company, all actions and decisions that result from applying these models have to be accountable. Given that a substantial amount of data that is collected in high-stake domains are in the form of time series, in this paper we examine the current state of eXplainable AI (XAI) methods with a focus on approaches for opening up deep learning black boxes for the task of time series classification. Finally, our contribution also aims at deriving promising directions for future work, to advance XAI for deep learning on time series data.
* 8 pages, 0 figures, Accepted as a poster presentation
Recognition of All Categories of Entities by AI
Aug 17, 2022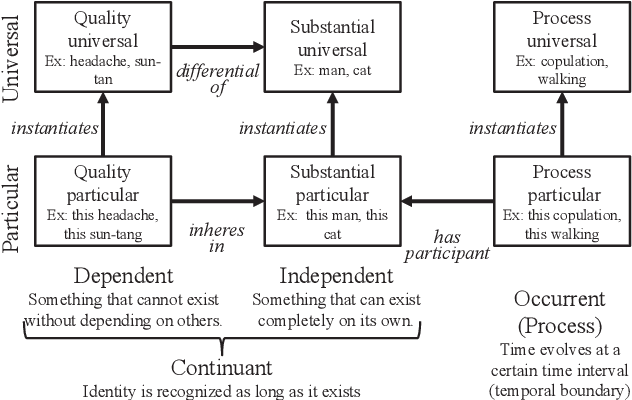
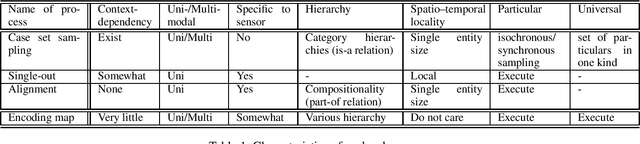
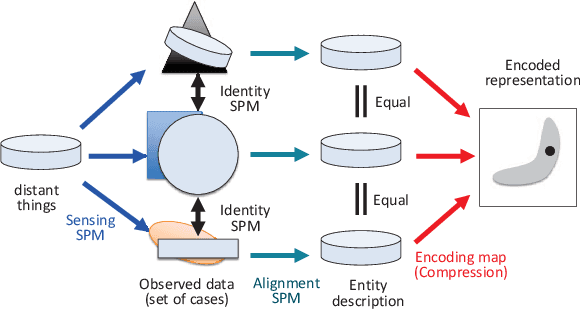
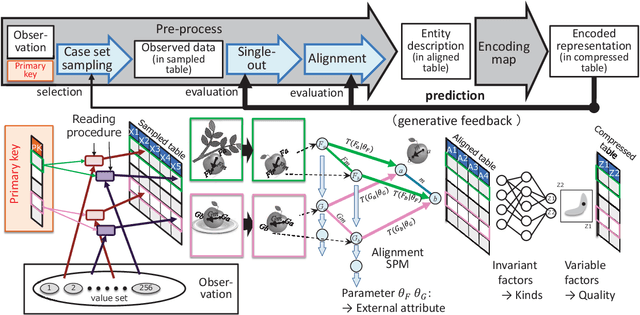
Human-level AI will have significant impacts on human society. However, estimates for the realization time are debatable. To arrive at human-level AI, artificial general intelligence (AGI), as opposed to AI systems that are specialized for a specific task, was set as a technically meaningful long-term goal. But now, propelled by advances in deep learning, that achievement is getting much closer. Considering the recent technological developments, it would be meaningful to discuss the completion date of human-level AI through the "comprehensive technology map approach," wherein we map human-level capabilities at a reasonable granularity, identify the current range of technology, and discuss the technical challenges in traversing unexplored areas and predict when all of them will be overcome. This paper presents a new argumentative option to view the ontological sextet, which encompasses entities in a way that is consistent with our everyday intuition and scientific practice, as a comprehensive technological map. Because most of the modeling of the world, in terms of how to interpret it, by an intelligent subject is the recognition of distal entities and the prediction of their temporal evolution, being able to handle all distal entities is a reasonable goal. Based on the findings of philosophy and engineering cognitive technology, we predict that in the relatively near future, AI will be able to recognize various entities to the same degree as humans.
A developmental approach for training deep belief networks
Jul 12, 2022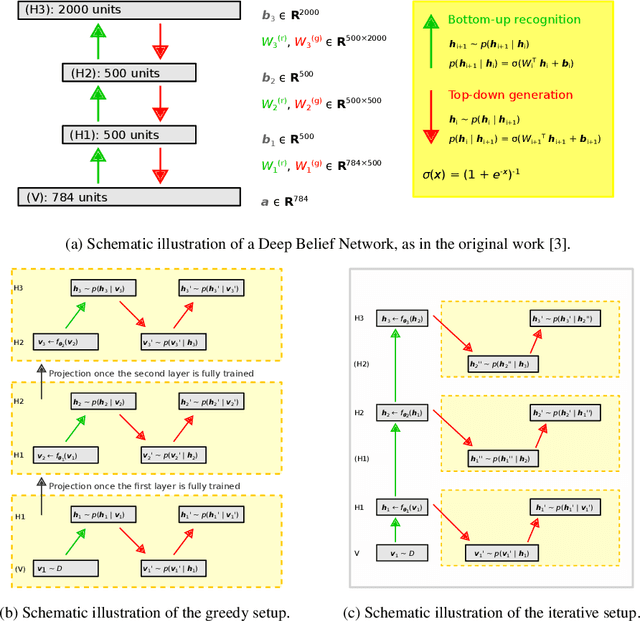
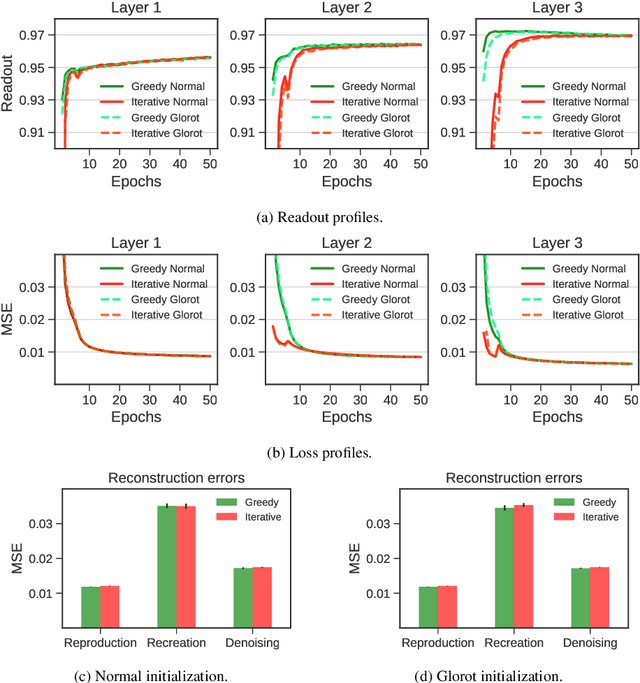
Deep belief networks (DBNs) are stochastic neural networks that can extract rich internal representations of the environment from the sensory data. DBNs had a catalytic effect in triggering the deep learning revolution, demonstrating for the very first time the feasibility of unsupervised learning in networks with many layers of hidden neurons. Thanks to their biological and cognitive plausibility, these hierarchical architectures have been also successfully exploited to build computational models of human perception and cognition in a variety of domains. However, learning in DBNs is usually carried out in a greedy, layer-wise fashion, which does not allow to simulate the holistic development of cortical circuits. Here we present iDBN, an iterative learning algorithm for DBNs that allows to jointly update the connection weights across all layers of the hierarchy. We test our algorithm on two different sets of visual stimuli, and we show that network development can also be tracked in terms of graph theoretical properties. DBNs trained using our iterative approach achieve a final performance comparable to that of the greedy counterparts, at the same time allowing to accurately analyze the gradual development of internal representations in the generative model. Our work paves the way to the use of iDBN for modeling neurocognitive development.
DeeperDive: The Unreasonable Effectiveness of Weak Supervision in Document Understanding A Case Study in Collaboration with UiPath Inc
Aug 17, 2022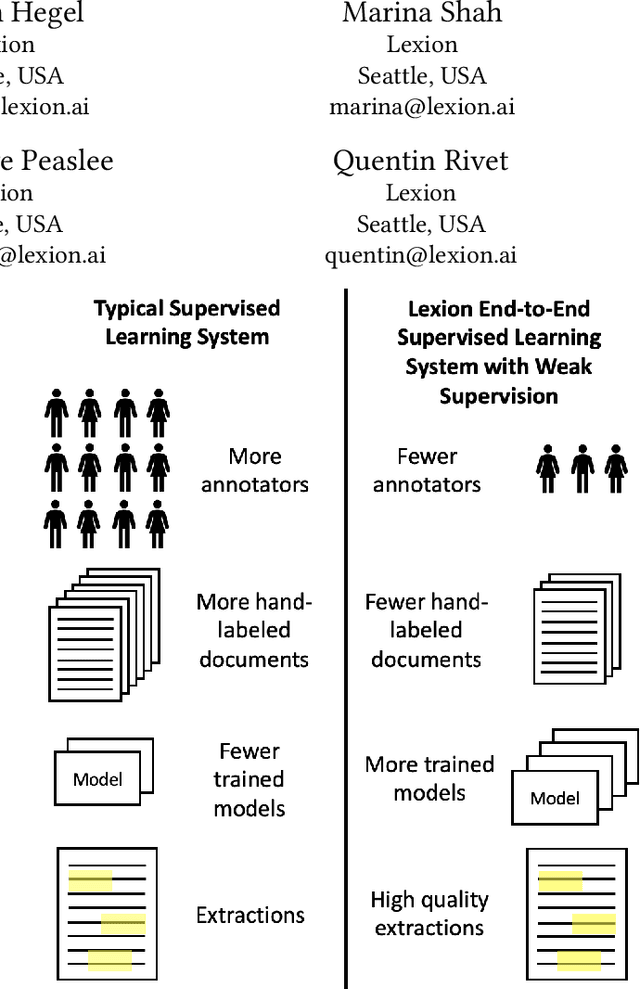


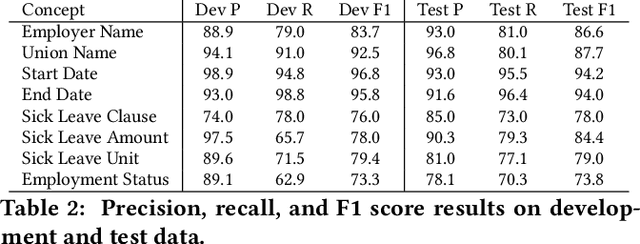
Weak supervision has been applied to various Natural Language Understanding tasks in recent years. Due to technical challenges with scaling weak supervision to work on long-form documents, spanning up to hundreds of pages, applications in the document understanding space have been limited. At Lexion, we built a weak supervision-based system tailored for long-form (10-200 pages long) PDF documents. We use this platform for building dozens of language understanding models and have applied it successfully to various domains, from commercial agreements to corporate formation documents. In this paper, we demonstrate the effectiveness of supervised learning with weak supervision in a situation with limited time, workforce, and training data. We built 8 high quality machine learning models in the span of one week, with the help of a small team of just 3 annotators working with a dataset of under 300 documents. We share some details about our overall architecture, how we utilize weak supervision, and what results we are able to achieve. We also include the dataset for researchers who would like to experiment with alternate approaches or refine ours. Furthermore, we shed some light on the additional complexities that arise when working with poorly scanned long-form documents in PDF format, and some of the techniques that help us achieve state-of-the-art performance on such data.
Real-Time Predictive Maintenance using Autoencoder Reconstruction and Anomaly Detection
Oct 01, 2021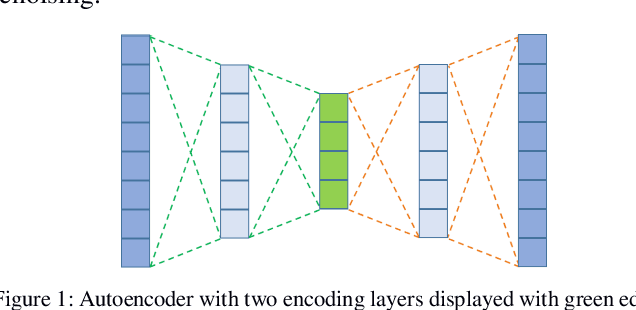
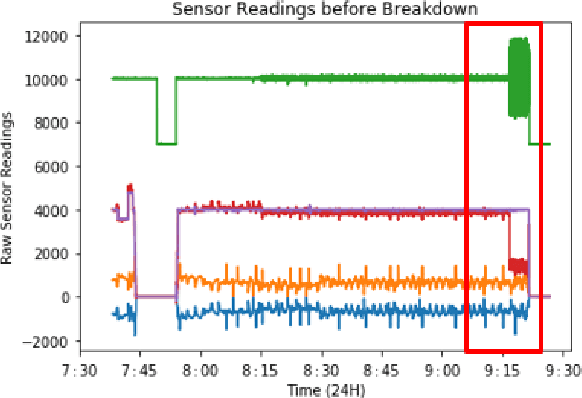
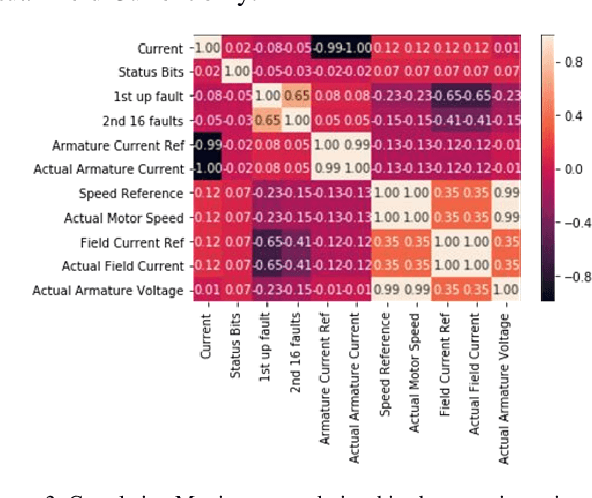
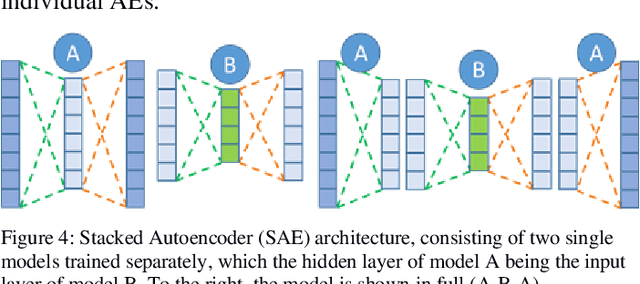
Rotary machine breakdown detection systems are outdated and dependent upon routine testing to discover faults. This is costly and often reactive in nature. Real-time monitoring offers a solution for detecting faults without the need for manual observation. However, manual interpretation for threshold anomaly detection is often subjective and varies between industrial experts. This approach is ridged and prone to a large number of false positives. To address this issue, we propose a Machine Learning (ML) approach to model normal working operation and detect anomalies. The approach extracts key features from signals representing known normal operation to model machine behaviour and automatically identify anomalies. The ML learns generalisations and generates thresholds based on fault severity. This provides engineers with a traffic light system were green is normal behaviour, amber is worrying and red signifies a machine fault. This scale allows engineers to undertake early intervention measures at the appropriate time. The approach is evaluated on windowed real machine sensor data to observe normal and abnormal behaviour. The results demonstrate that it is possible to detect anomalies within the amber range and raise alarms before machine failure.
Slimmable Quantum Federated Learning
Jul 20, 2022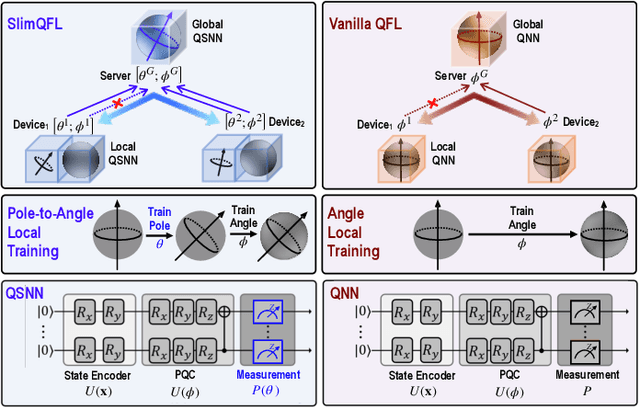
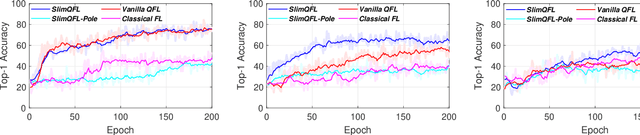


Quantum federated learning (QFL) has recently received increasing attention, where quantum neural networks (QNNs) are integrated into federated learning (FL). In contrast to the existing static QFL methods, we propose slimmable QFL (SlimQFL) in this article, which is a dynamic QFL framework that can cope with time-varying communication channels and computing energy limitations. This is made viable by leveraging the unique nature of a QNN where its angle parameters and pole parameters can be separately trained and dynamically exploited. Simulation results corroborate that SlimQFL achieves higher classification accuracy than Vanilla QFL, particularly under poor channel conditions on average.
Self-supervised Transformer for Multivariate Clinical Time-Series with Missing Values
Jul 29, 2021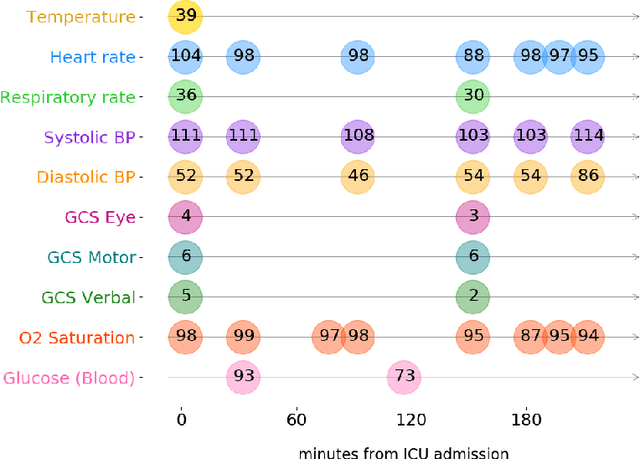
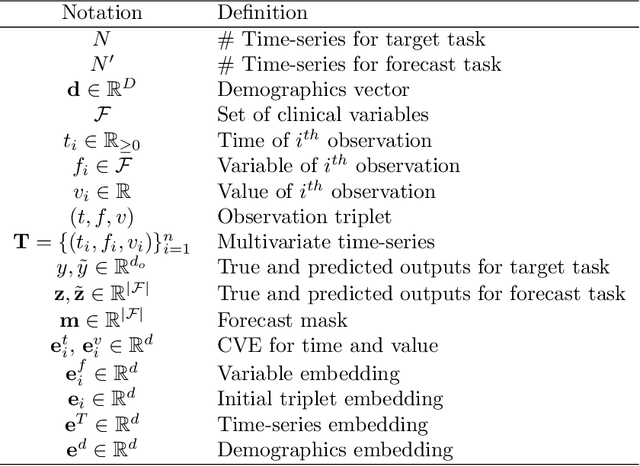
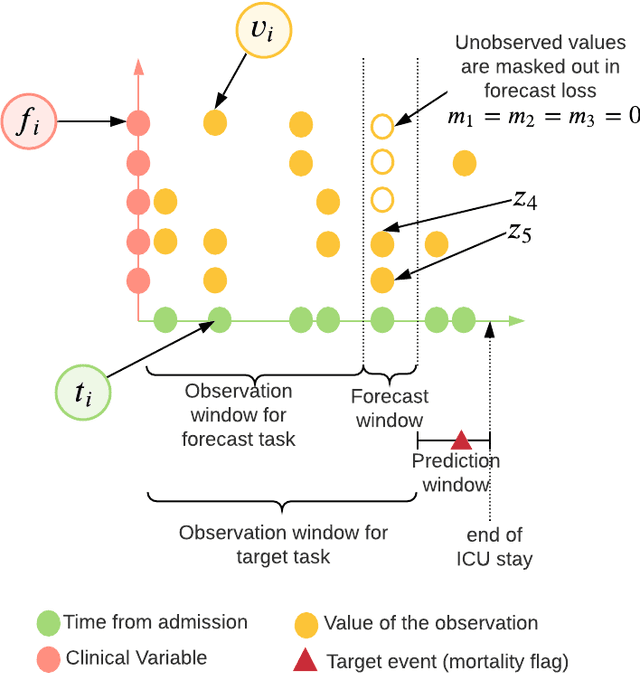
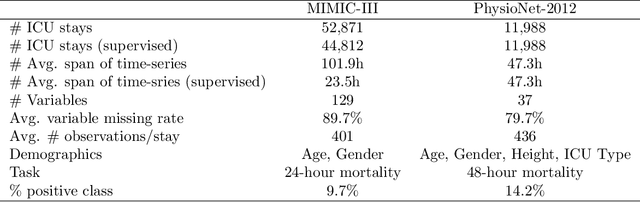
Multivariate time-series (MVTS) data are frequently observed in critical care settings and are typically characterized by excessive missingness and irregular time intervals. Existing approaches for learning representations in this domain handle such issues by either aggregation or imputation of values, which in-turn suppresses the fine-grained information and adds undesirable noise/overhead into the machine learning model. To tackle this challenge, we propose STraTS (Self-supervised Transformer for TimeSeries) model which bypasses these pitfalls by treating time-series as a set of observation triplets instead of using the traditional dense matrix representation. It employs a novel Continuous Value Embedding (CVE) technique to encode continuous time and variable values without the need for discretization. It is composed of a Transformer component with Multi-head attention layers which enables it to learn contextual triplet embeddings while avoiding problems of recurrence and vanishing gradients that occur in recurrent architectures. Many healthcare datasets also suffer from the limited availability of labeled data. Our model utilizes self-supervision by leveraging unlabeled data to learn better representations by performing time-series forecasting as a self-supervision task. Experiments on real-world multivariate clinical time-series benchmark datasets show that STraTS shows better prediction performance than state-of-the-art methods for mortality prediction, especially when labeled data is limited. Finally, we also present an interpretable version of STraTS which can identify important measurements in the time-series data.
Auditing Membership Leakages of Multi-Exit Networks
Aug 23, 2022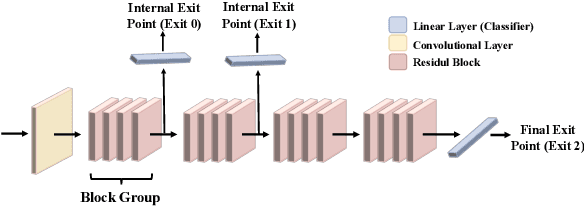
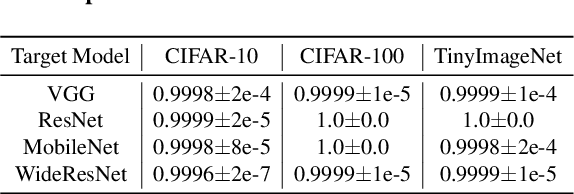
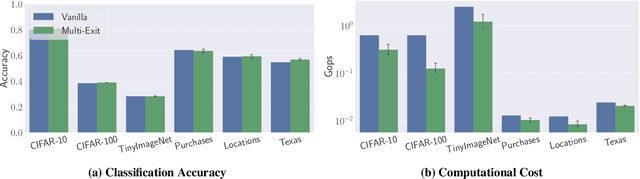
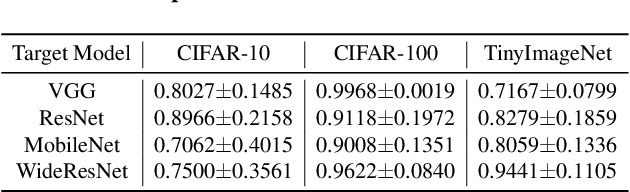
Relying on the fact that not all inputs require the same amount of computation to yield a confident prediction, multi-exit networks are gaining attention as a prominent approach for pushing the limits of efficient deployment. Multi-exit networks endow a backbone model with early exits, allowing to obtain predictions at intermediate layers of the model and thus save computation time and/or energy. However, current various designs of multi-exit networks are only considered to achieve the best trade-off between resource usage efficiency and prediction accuracy, the privacy risks stemming from them have never been explored. This prompts the need for a comprehensive investigation of privacy risks in multi-exit networks. In this paper, we perform the first privacy analysis of multi-exit networks through the lens of membership leakages. In particular, we first leverage the existing attack methodologies to quantify the multi-exit networks' vulnerability to membership leakages. Our experimental results show that multi-exit networks are less vulnerable to membership leakages and the exit (number and depth) attached to the backbone model is highly correlated with the attack performance. Furthermore, we propose a hybrid attack that exploits the exit information to improve the performance of existing attacks. We evaluate membership leakage threat caused by our hybrid attack under three different adversarial setups, ultimately arriving at a model-free and data-free adversary. These results clearly demonstrate that our hybrid attacks are very broadly applicable, thereby the corresponding risks are much more severe than shown by existing membership inference attacks. We further present a defense mechanism called TimeGuard specifically for multi-exit networks and show that TimeGuard mitigates the newly proposed attacks perfectly.
Robotic Depowdering for Additive Manufacturing via Pose Tracking
Jul 09, 2022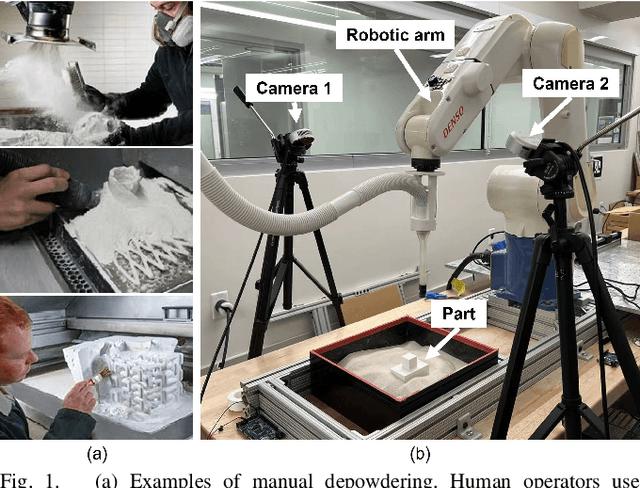
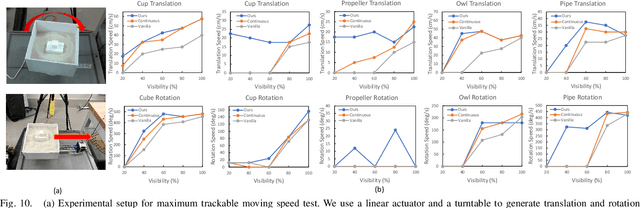


With the rapid development of powder-based additive manufacturing, depowdering, a process of removing unfused powder that covers 3D-printed parts, has become a major bottleneck to further improve its productiveness. Traditional manual depowdering is extremely time-consuming and costly, and some prior automated systems either require pre-depowdering or lack adaptability to different 3D-printed parts. To solve these problems, we introduce a robotic system that automatically removes unfused powder from the surface of 3D-printed parts. The key component is a visual perception system, which consists of a pose-tracking module that tracks the 6D pose of powder-occluded parts in real-time, and a progress estimation module that estimates the depowdering completion percentage. The tracking module can be run efficiently on a laptop CPU at up to 60 FPS. Experiments show that our depowdering system can remove unfused powder from the surface of various 3D-printed parts without causing any damage. To the best of our knowledge, this is one of the first vision-based robotic depowdering systems that adapt to parts with various shapes without the need for pre-depowdering.