 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Dynamic Programming Framework for Optimal Planning of Redundant Robots Along Prescribed Paths With Kineto-Dynamic Constraints
Jul 12, 2022
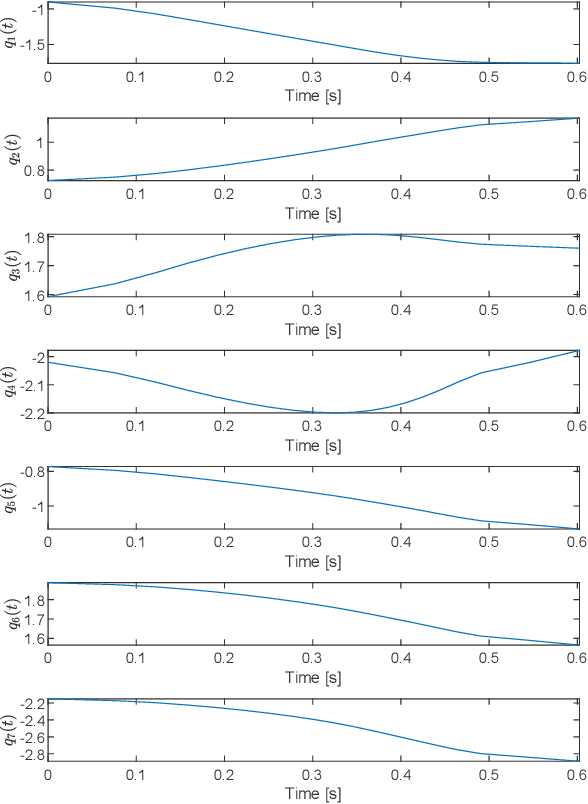
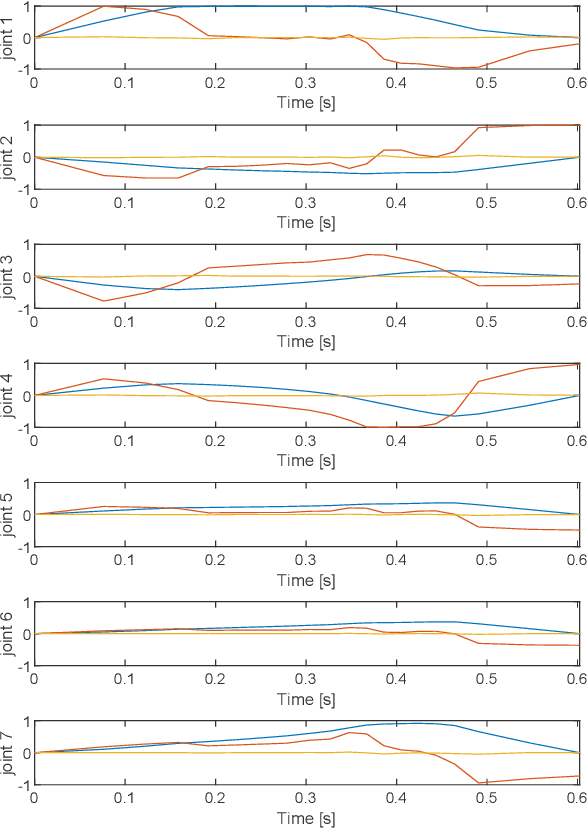
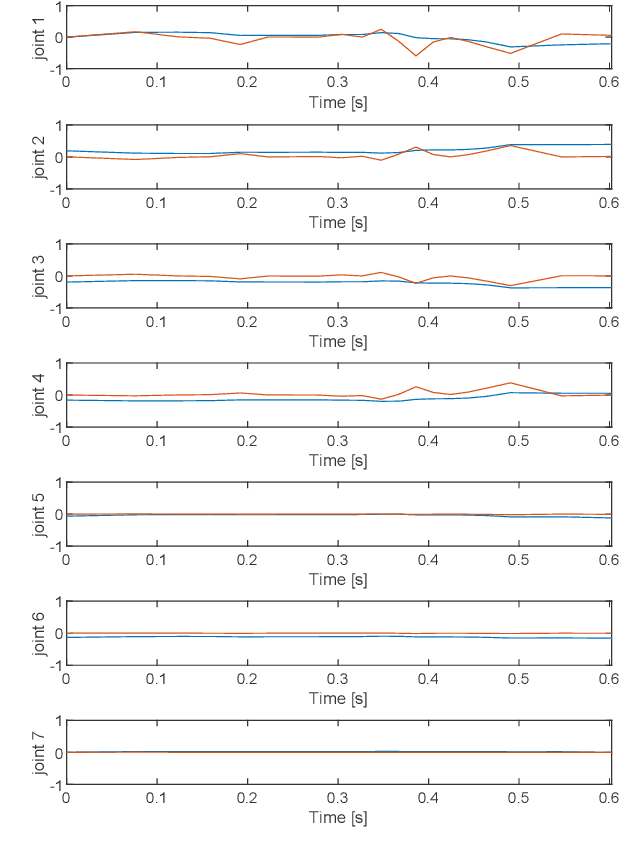
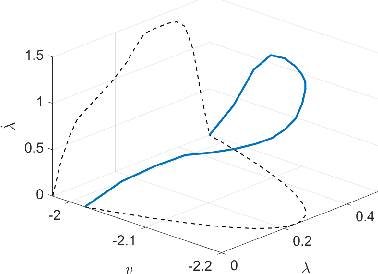
Off-line optimal planning of trajectories for redundant robots along prescribed task space paths is usually broken down into two consecutive processes: first, the task space path is inverted to obtain a joint-space path, then, the latter is parametrized with a time law. If the two processes are separated, they cannot optimize the same objective function, ultimately providing sub-optimal results. In this paper, a unified approach is presented where dynamic programming is the underlying optimization technique. Its flexibility allows accommodating arbitrary constraints and objective functions, thus providing a generic framework for optimal planning of real systems. To demonstrate its applicability to a real world scenario, the framework is instantiated for time-optimality. Compared to numerical solvers, the proposed methodology provides visibility of the underlying resolution process, allowing for further analyses beyond the computation of the optimal trajectory. The effectiveness of the framework is demonstrated on a real 7-degrees-of-freedom serial chain. The issues associated with the execution of optimal trajectories on a real controller are also discussed and addressed. The experiments show that the proposed framework is able to effectively exploit kinematic redundancy to optimize the performance index defined at planning level and generate feasible trajectories that can be executed on real hardware with satisfactory results.
Heteroscedastic Temporal Variational Autoencoder For Irregularly Sampled Time Series
Jul 23, 2021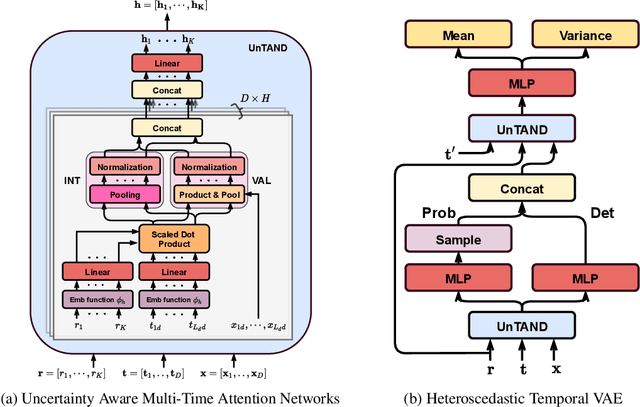
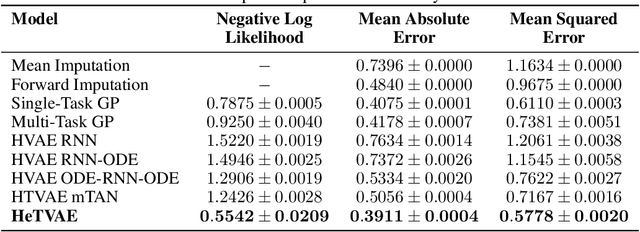
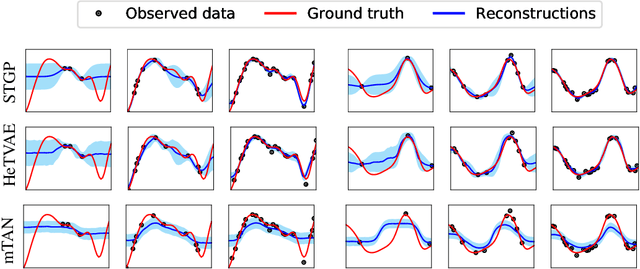
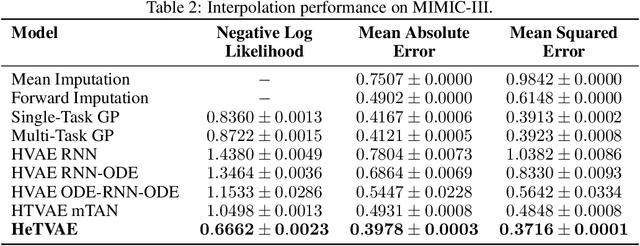
Irregularly sampled time series commonly occur in several domains where they present a significant challenge to standard deep learning models. In this paper, we propose a new deep learning framework for probabilistic interpolation of irregularly sampled time series that we call the Heteroscedastic Temporal Variational Autoencoder (HeTVAE). HeTVAE includes a novel input layer to encode information about input observation sparsity, a temporal VAE architecture to propagate uncertainty due to input sparsity, and a heteroscedastic output layer to enable variable uncertainty in output interpolations. Our results show that the proposed architecture is better able to reflect variable uncertainty through time due to sparse and irregular sampling than a range of baseline and traditional models, as well as recently proposed deep latent variable models that use homoscedastic output layers.
voxel2vec: A Natural Language Processing Approach to Learning Distributed Representations for Scientific Data
Jul 06, 2022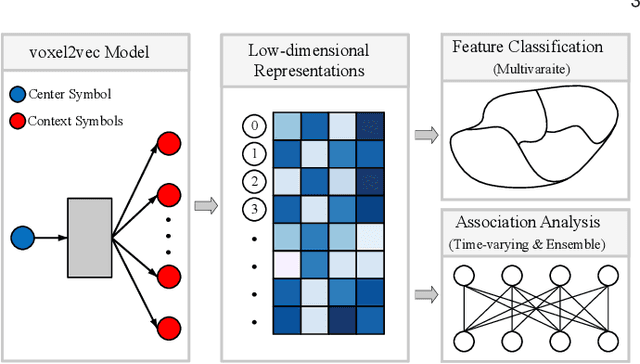

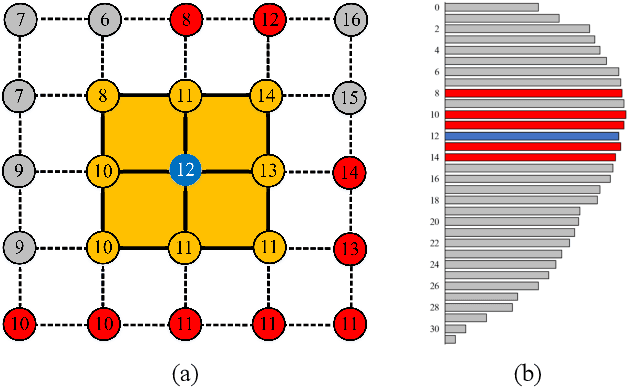

Relationships in scientific data, such as the numerical and spatial distribution relations of features in univariate data, the scalar-value combinations' relations in multivariate data, and the association of volumes in time-varying and ensemble data, are intricate and complex. This paper presents voxel2vec, a novel unsupervised representation learning model, which is used to learn distributed representations of scalar values/scalar-value combinations in a low-dimensional vector space. Its basic assumption is that if two scalar values/scalar-value combinations have similar contexts, they usually have high similarity in terms of features. By representing scalar values/scalar-value combinations as symbols, voxel2vec learns the similarity between them in the context of spatial distribution and then allows us to explore the overall association between volumes by transfer prediction. We demonstrate the usefulness and effectiveness of voxel2vec by comparing it with the isosurface similarity map of univariate data and applying the learned distributed representations to feature classification for multivariate data and to association analysis for time-varying and ensemble data.
Modeling Randomly Walking Volatility with Chained Gamma Distributions
Jul 04, 2022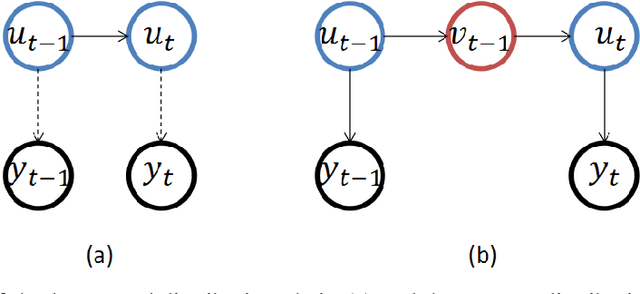
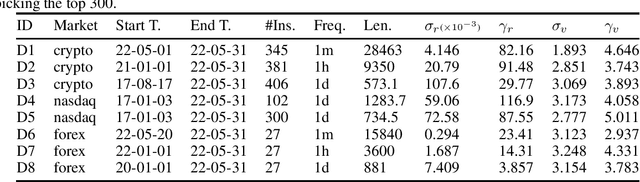
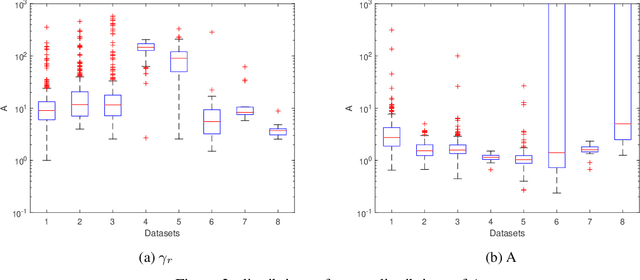
Volatility clustering is a common phenomenon in financial time series. Typically, linear models are used to describe the temporal autocorrelation of the (logarithmic) variance of returns. Considering the difficulty in estimation of this model, we construct a Dynamic Bayesian Network, which utilizes the conjugate prior relation of normal-gamma and gamma-gamma, so that at each node, its posterior form locally remains unchanged. This makes it possible to quickly find approximate solutions using variational methods. Furthermore, we ensure that the volatility expressed by the model is an independent incremental process after inserting dummy gamma nodes between adjacent time steps. We have found that, this model has two advantages: 1) It can be proved that it can express heavier tails than Gaussians, i.e., have positive excess kurtosis, compared to popular linear models. 2) If the variational inference(VI) is used for state estimation, it runs much faster than Monte Carlo(MC) methods, since the calculation of the posterior uses only basic arithmetic operations. And, its convergence process is deterministic. We tested the model, named Gam-Chain, using recent Crypto, Nasdaq, and Forex records of varying resolutions. The results show that: 1) In the same case of using MC, this model can achieve comparable state estimation results with the regular lognormal chain. 2) In the case of only using VI, this model can obtain accuracy that are slightly worse than MC, but still acceptable in practice; 3) Only using VI, the running time of Gam-Chain, under the most conservative settings, can be reduced to below 20% of that based on the lognormal chain via MC.
Probabilistic Time Series Forecasting with Implicit Quantile Networks
Jul 08, 2021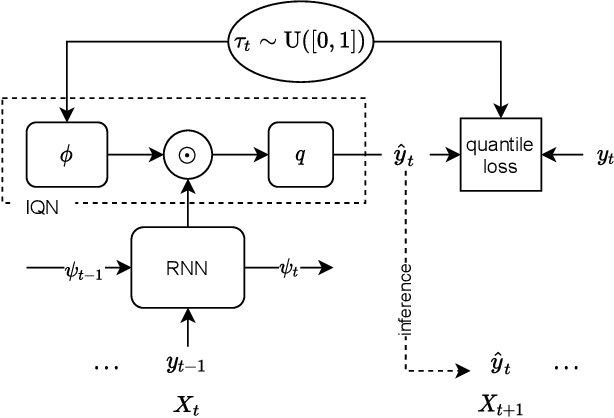
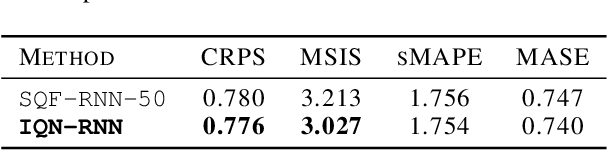
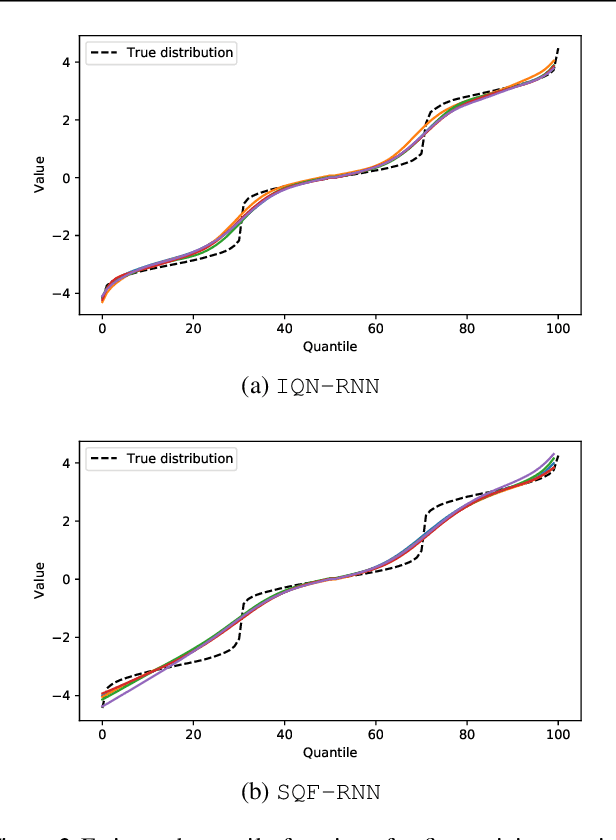
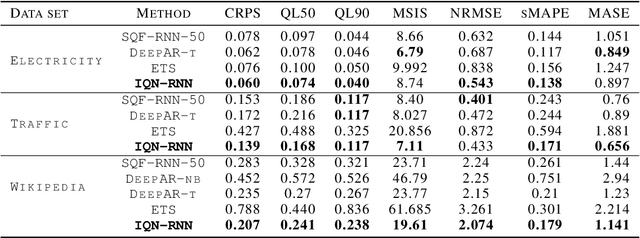
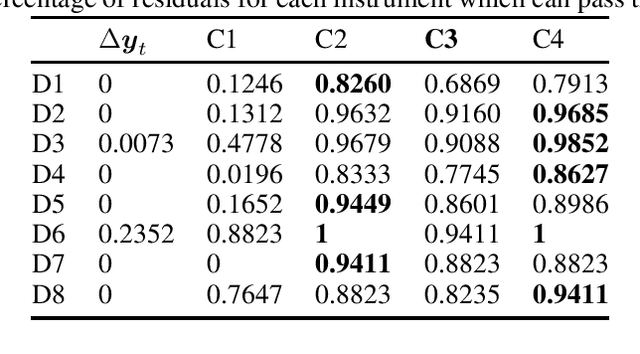
Here, we propose a general method for probabilistic time series forecasting. We combine an autoregressive recurrent neural network to model temporal dynamics with Implicit Quantile Networks to learn a large class of distributions over a time-series target. When compared to other probabilistic neural forecasting models on real- and simulated data, our approach is favorable in terms of point-wise prediction accuracy as well as on estimating the underlying temporal distribution.
Plotting time: On the usage of CNNs for time series classification
Feb 08, 2021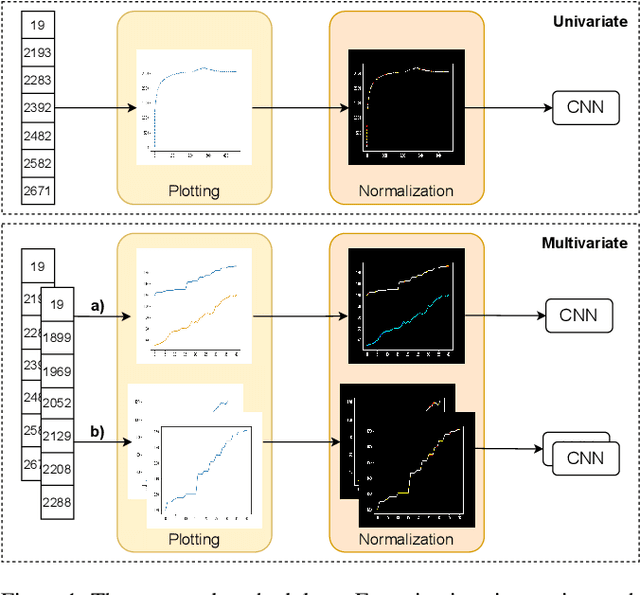

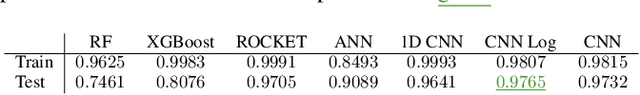
We present a novel approach for time series classification where we represent time series data as plot images and feed them to a simple CNN, outperforming several state-of-the-art methods. We propose a simple and highly replicable way of plotting the time series, and feed these images as input to a non-optimized shallow CNN, without any normalization or residual connections. These representations are no more than default line plots using the time series data, where the only pre-processing applied is to reduce the number of white pixels in the image. We compare our method with different state-of-the-art methods specialized in time series classification on two real-world non public datasets, as well as 98 datasets of the UCR dataset collection. The results show that our approach is very promising, achieving the best results on both real-world datasets and matching / beating the best state-of-the-art methods in six UCR datasets. We argue that, if a simple naive design like ours can obtain such good results, it is worth further exploring the capabilities of using image representation of time series data, along with more powerful CNNs, for classification and other related tasks.
Fly Out The Window: Exploiting Discrete-Time Flatness for Fast Vision-Based Multirotor Flight
Sep 30, 2021
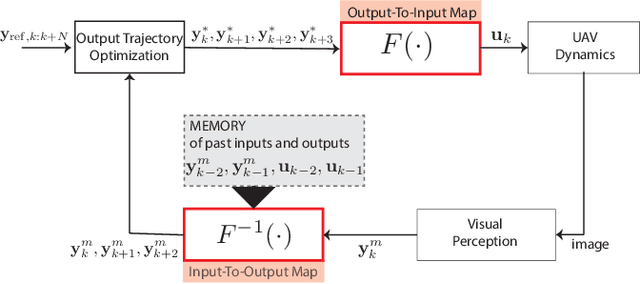
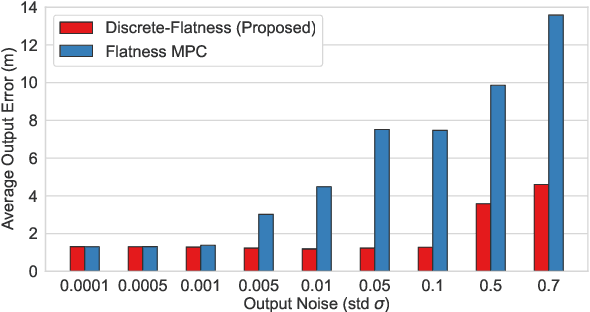
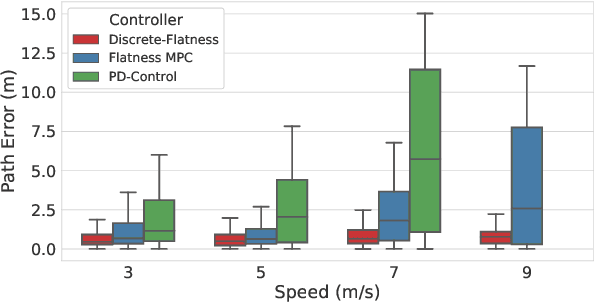
Current control design for fast vision-based flight tends to rely on high-rate, high-dimensional and perfect state estimation. This is challenging in real-world environments due to imperfect sensing and state estimation drift and noise. In this letter, we present an alternative control design that bypasses the need for a state estimate by exploiting discrete-time flatness. To the best of our knowledge, this is the first work to demonstrate that discrete-time flatness holds for the Euler discretization of multirotor dynamics. This allows us to design a controller using only a window of input and output information. We highlight in simulation how exploiting this property in control design can provide robustness to noisy output measurements (where estimating higher-order derivatives and the full state can be challenging). Fast vision-based navigation requires high performance flight despite possibly noisy high-rate real-time position estimation. In outdoor experiments, we show the application of discrete-time flatness to vision-based flight at speeds up to 10 m/s and how it can outperform controllers that hinge on accurate state estimation.
A Framework for Imbalanced Time-series Forecasting
Jul 22, 2021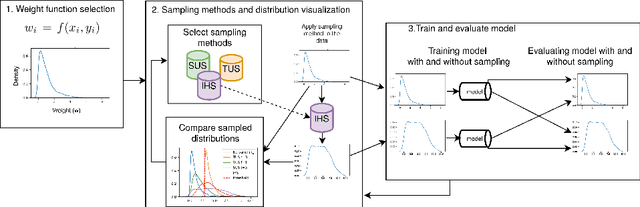
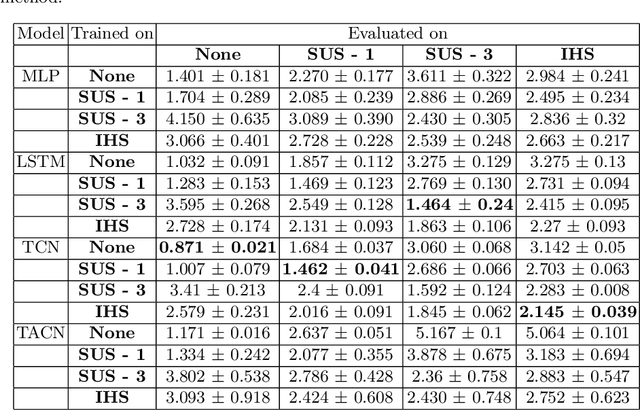
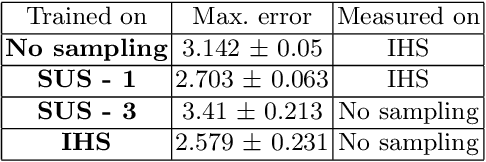
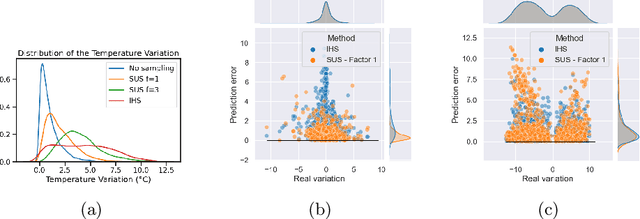
Time-series forecasting plays an important role in many domains. Boosted by the advances in Deep Learning algorithms, it has for instance been used to predict wind power for eolic energy production, stock market fluctuations, or motor overheating. In some of these tasks, we are interested in predicting accurately some particular moments which often are underrepresented in the dataset, resulting in a problem known as imbalanced regression. In the literature, while recognized as a challenging problem, limited attention has been devoted on how to handle the problem in a practical setting. In this paper, we put forward a general approach to analyze time-series forecasting problems focusing on those underrepresented moments to reduce imbalances. Our approach has been developed based on a case study in a large industrial company, which we use to exemplify the approach.
Enabling Weakly-Supervised Temporal Action Localization from On-Device Learning of the Video Stream
Aug 25, 2022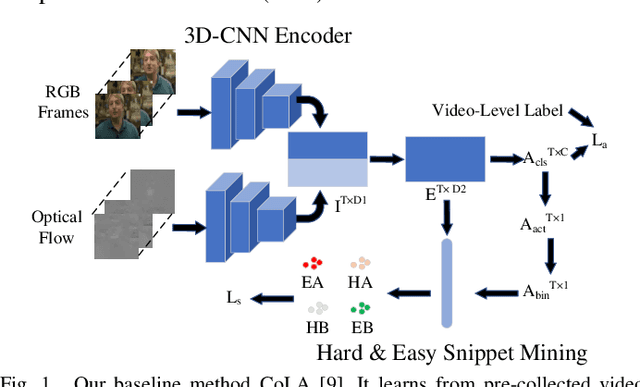
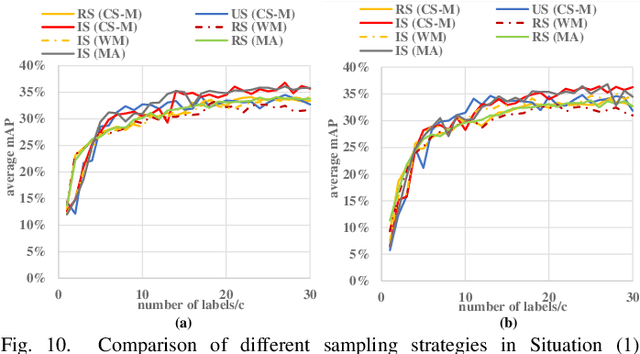
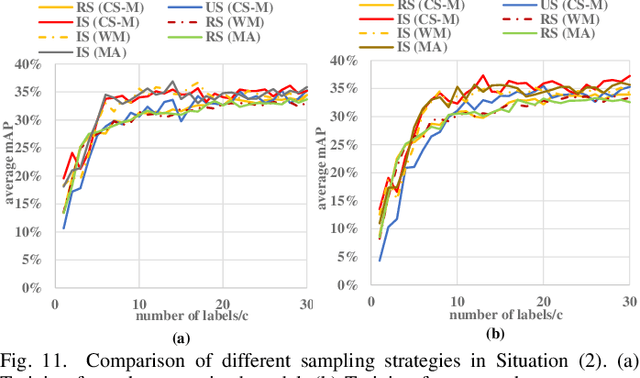
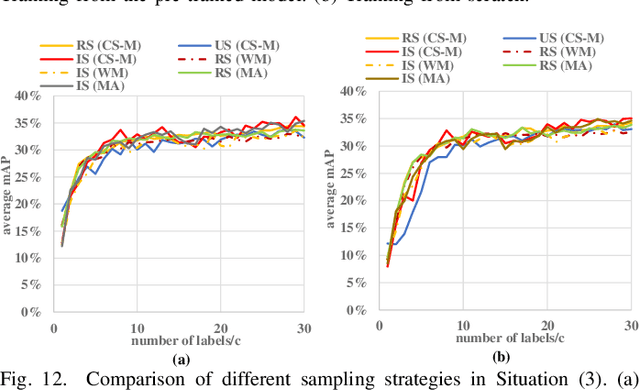
Detecting actions in videos have been widely applied in on-device applications. Practical on-device videos are always untrimmed with both action and background. It is desirable for a model to both recognize the class of action and localize the temporal position where the action happens. Such a task is called temporal action location (TAL), which is always trained on the cloud where multiple untrimmed videos are collected and labeled. It is desirable for a TAL model to continuously and locally learn from new data, which can directly improve the action detection precision while protecting customers' privacy. However, it is non-trivial to train a TAL model, since tremendous video samples with temporal annotations are required. However, annotating videos frame by frame is exorbitantly time-consuming and expensive. Although weakly-supervised TAL (W-TAL) has been proposed to learn from untrimmed videos with only video-level labels, such an approach is also not suitable for on-device learning scenarios. In practical on-device learning applications, data are collected in streaming. Dividing such a long video stream into multiple video segments requires lots of human effort, which hinders the exploration of applying the TAL tasks to realistic on-device learning applications. To enable W-TAL models to learn from a long, untrimmed streaming video, we propose an efficient video learning approach that can directly adapt to new environments. We first propose a self-adaptive video dividing approach with a contrast score-based segment merging approach to convert the video stream into multiple segments. Then, we explore different sampling strategies on the TAL tasks to request as few labels as possible. To the best of our knowledge, we are the first attempt to directly learn from the on-device, long video stream.
Analyzing social media with crowdsourcing in Crowd4SDG
Aug 04, 2022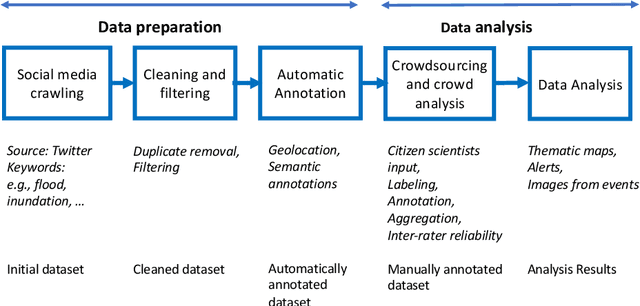

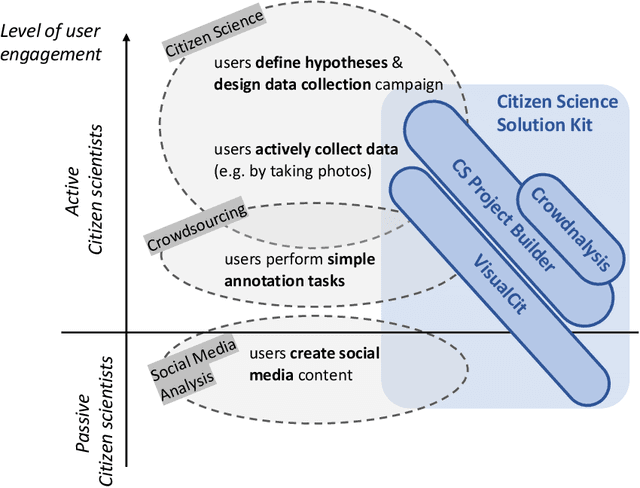
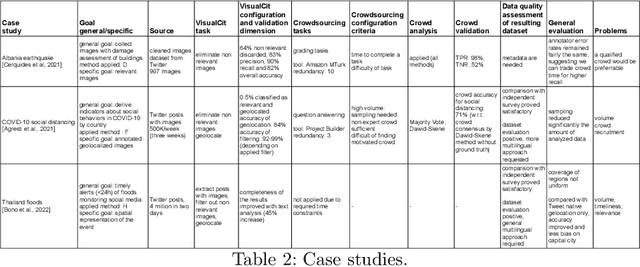
Social media have the potential to provide timely information about emergency situations and sudden events. However, finding relevant information among millions of posts being posted every day can be difficult, and developing a data analysis project usually requires time and technical skills. This study presents an approach that provides flexible support for analyzing social media, particularly during emergencies. Different use cases in which social media analysis can be adopted are introduced, and the challenges of retrieving information from large sets of posts are discussed. The focus is on analyzing images and text contained in social media posts and a set of automatic data processing tools for filtering, classification, and geolocation of content with a human-in-the-loop approach to support the data analyst. Such support includes both feedback and suggestions to configure automated tools, and crowdsourcing to gather inputs from citizens. The results are validated by discussing three case studies developed within the Crowd4SDG H2020 European project.