 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Minimax Classification under Concept Drift with Multidimensional Adaptation and Performance Guarantees
May 31, 2022
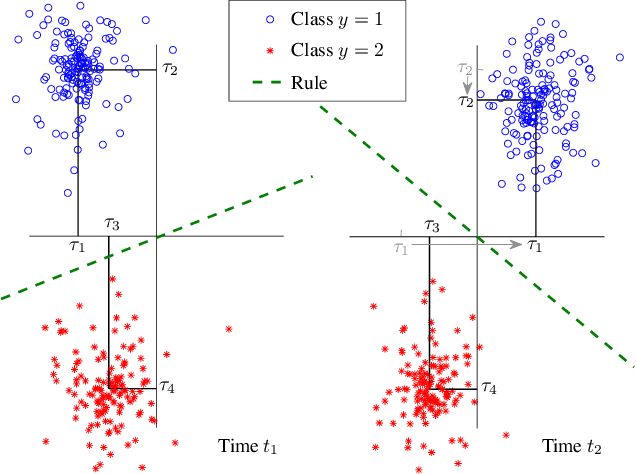
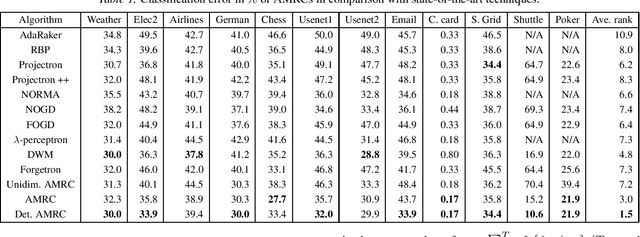
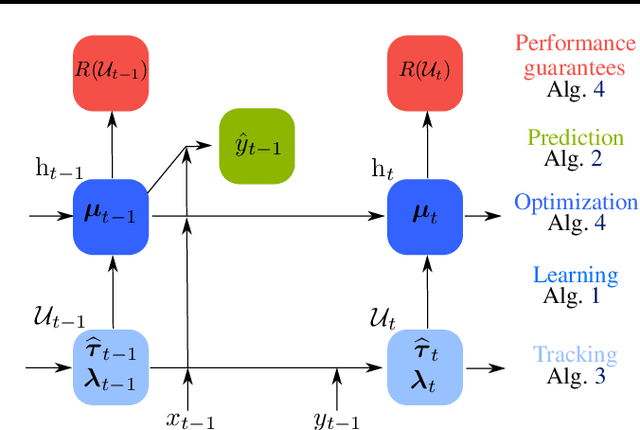
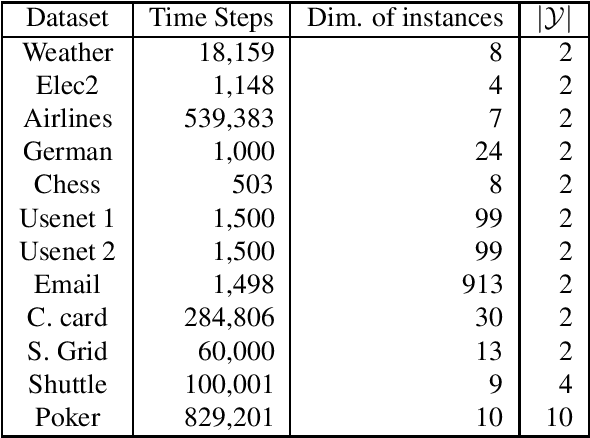
The statistical characteristics of instance-label pairs often change with time in practical scenarios of supervised classification. Conventional learning techniques adapt to such concept drift accounting for a scalar rate of change by means of a carefully chosen learning rate, forgetting factor, or window size. However, the time changes in common scenarios are multidimensional, i.e., different statistical characteristics often change in a different manner. This paper presents adaptive minimax risk classifiers (AMRCs) that account for multidimensional time changes by means of a multivariate and high-order tracking of the time-varying underlying distribution. In addition, differently from conventional techniques, AMRCs can provide computable tight performance guarantees. Experiments on multiple benchmark datasets show the classification improvement of AMRCs compared to the state-of-the-art and the reliability of the presented performance guarantees.
Supervised and Reinforcement Learning from Observations in Reconnaissance Blind Chess
Aug 03, 2022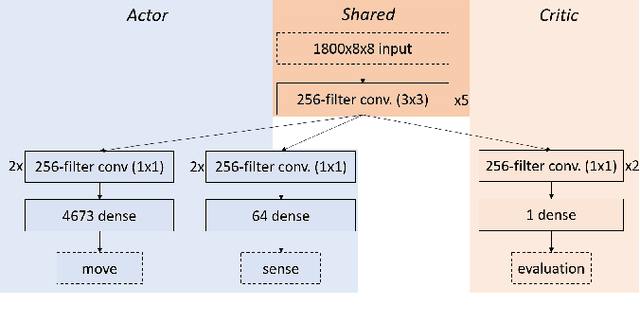
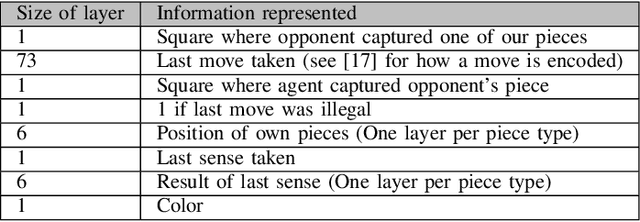
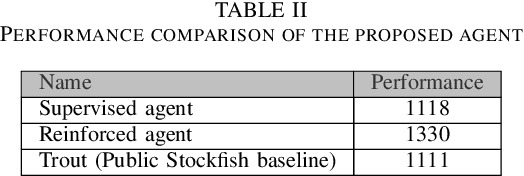
In this work, we adapt a training approach inspired by the original AlphaGo system to play the imperfect information game of Reconnaissance Blind Chess. Using only the observations instead of a full description of the game state, we first train a supervised agent on publicly available game records. Next, we increase the performance of the agent through self-play with the on-policy reinforcement learning algorithm Proximal Policy Optimization. We do not use any search to avoid problems caused by the partial observability of game states and only use the policy network to generate moves when playing. With this approach, we achieve an ELO of 1330 on the RBC leaderboard, which places our agent at position 27 at the time of this writing. We see that self-play significantly improves performance and that the agent plays acceptably well without search and without making assumptions about the true game state.
Analog Bits: Generating Discrete Data using Diffusion Models with Self-Conditioning
Aug 08, 2022
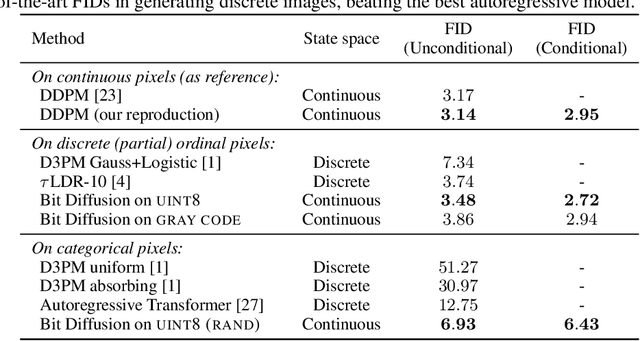


We present Bit Diffusion: a simple and generic approach for generating discrete data with continuous diffusion models. The main idea behind our approach is to first represent the discrete data as binary bits, and then train a continuous diffusion model to model these bits as real numbers which we call analog bits. To generate samples, the model first generates the analog bits, which are then thresholded to obtain the bits that represent the discrete variables. We further propose two simple techniques, namely Self-Conditioning and Asymmetric Time Intervals, which lead to a significant improvement in sample quality. Despite its simplicity, the proposed approach can achieve strong performance in both discrete image generation and image captioning tasks. For discrete image generation, we significantly improve previous state-of-the-art on both CIFAR-10 (which has 3K discrete 8-bit tokens) and ImageNet-64x64 (which has 12K discrete 8-bit tokens), outperforming the best autoregressive model in both sample quality (measured by FID) and efficiency. For image captioning on MS-COCO dataset, our approach achieves competitive results compared to autoregressive models.
Autonomous Resource Management in Construction Companies Using Deep Reinforcement Learning Based on IoT
Aug 17, 2022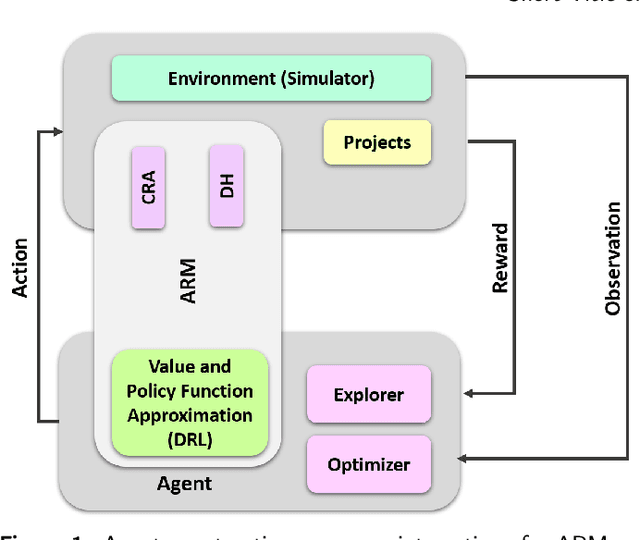
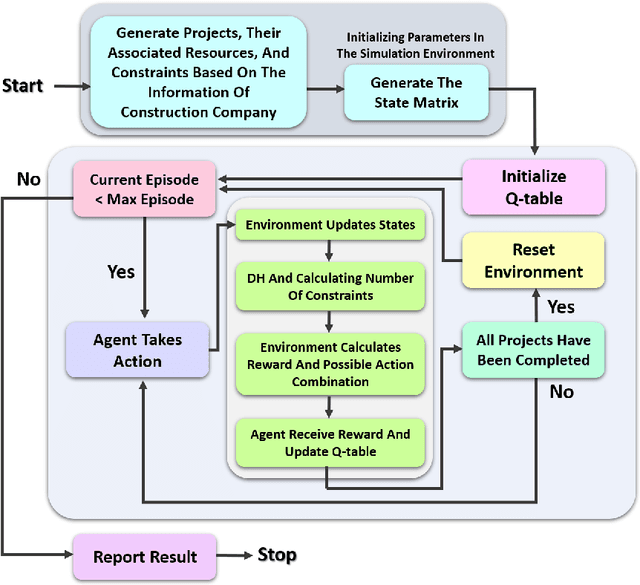

Resource allocation is one of the most critical issues in planning construction projects, due to its direct impact on cost, time, and quality. There are usually specific allocation methods for autonomous resource management according to the projects objectives. However, integrated planning and optimization of utilizing resources in an entire construction organization are scarce. The purpose of this study is to present an automatic resource allocation structure for construction companies based on Deep Reinforcement Learning (DRL), which can be used in various situations. In this structure, Data Harvesting (DH) gathers resource information from the distributed Internet of Things (IoT) sensor devices all over the companys projects to be employed in the autonomous resource management approach. Then, Coverage Resources Allocation (CRA) is compared to the information obtained from DH in which the Autonomous Resource Management (ARM) determines the project of interest. Likewise, Double Deep Q-Networks (DDQNs) with similar models are trained on two distinct assignment situations based on structured resource information of the company to balance objectives with resource constraints. The suggested technique in this paper can efficiently adjust to large resource management systems by combining portfolio information with adopted individual project information. Also, the effects of important information processing parameters on resource allocation performance are analyzed in detail. Moreover, the results of the generalizability of management approaches are presented, indicating no need for additional training when the variables of situations change.
LuMaMi28: Real-Time Millimeter-Wave Massive MIMO Systems with Antenna Selection
Sep 07, 2021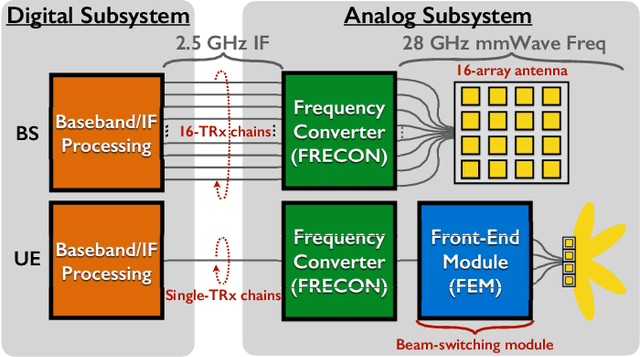
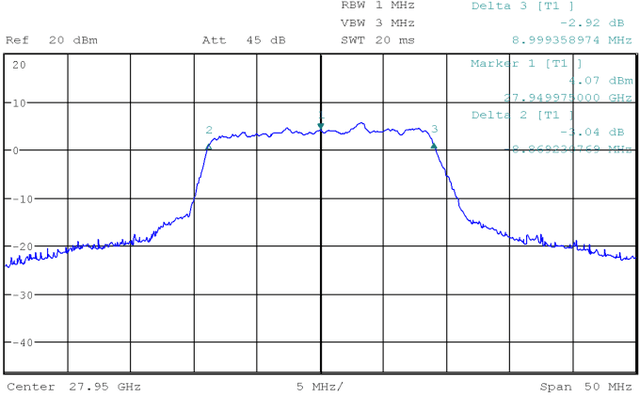
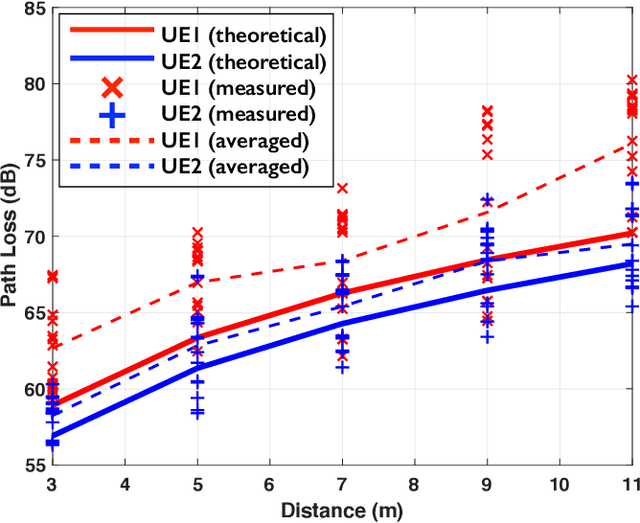
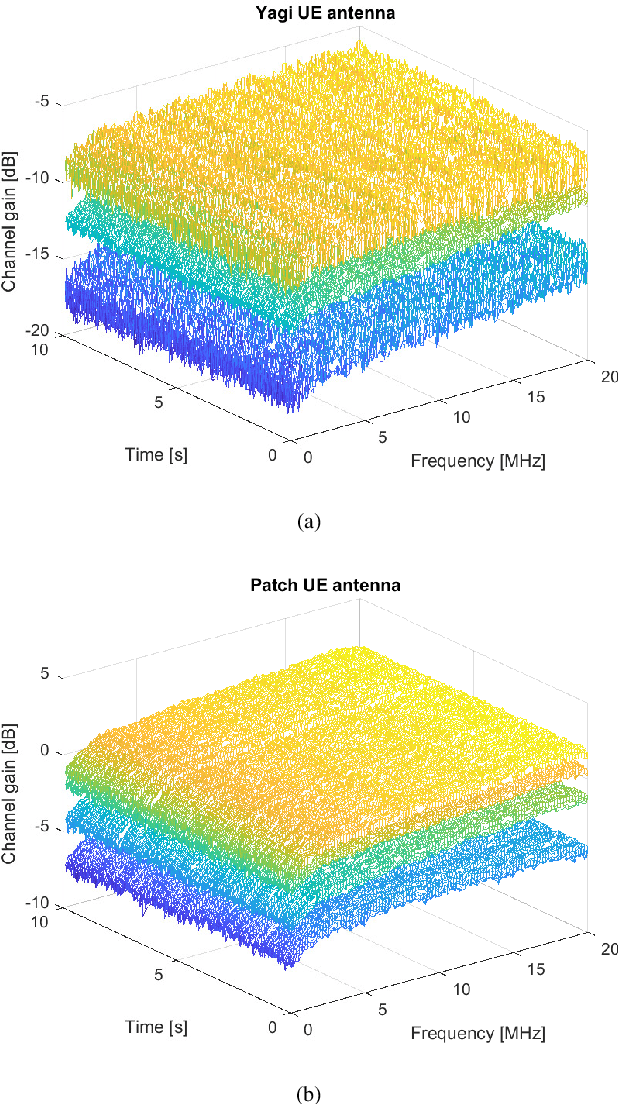
This paper presents LuMaMi28, a real-time 28 GHz massive multiple-input multiple-output (MIMO) testbed. In this testbed, the base station has 16 transceiver chains with a fully-digital beamforming architecture (with different pre-coding algorithms) and simultaneously supports multiple user equipments (UEs) with spatial multiplexing. The UEs are equipped with a beam-switchable antenna array for real-time antenna selection where the one with the highest channel magnitude, out of four pre-defined beams, is selected. For the beam-switchable antenna array, we consider two kinds of UE antennas, with different beam-width and different peak-gain. Based on this testbed, we provide measurement results for millimeter-wave (mmWave) massive MIMO performance in different real-life scenarios with static and mobile UEs. We explore the potential benefit of the mmWave massive MIMO systems with antenna selection based on measured channel data, and discuss the performance results through real-time measurements.
BCRLSP: An Offline Reinforcement Learning Framework for Sequential Targeted Promotion
Jul 16, 2022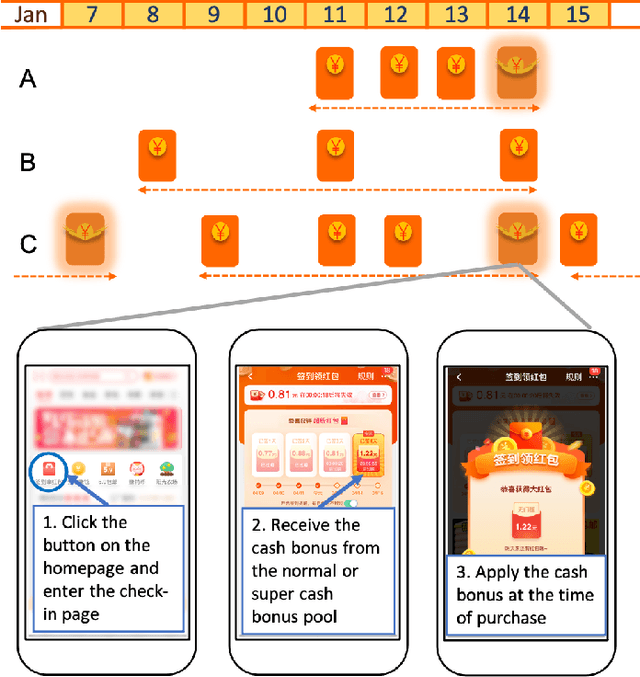
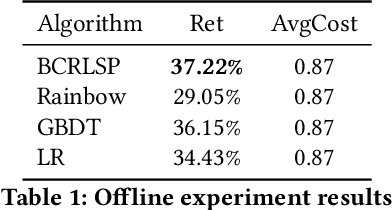
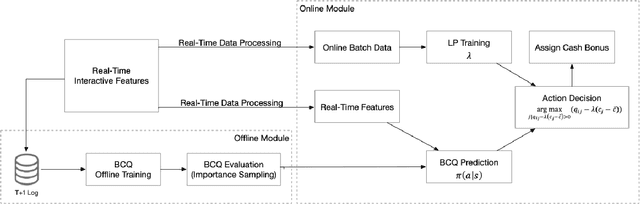
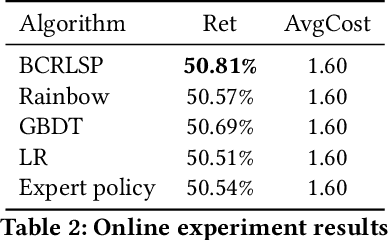
We utilize an offline reinforcement learning (RL) model for sequential targeted promotion in the presence of budget constraints in a real-world business environment. In our application, the mobile app aims to boost customer retention by sending cash bonuses to customers and control the costs of such cash bonuses during each time period. To achieve the multi-task goal, we propose the Budget Constrained Reinforcement Learning for Sequential Promotion (BCRLSP) framework to determine the value of cash bonuses to be sent to users. We first find out the target policy and the associated Q-values that maximizes the user retention rate using an RL model. A linear programming (LP) model is then added to satisfy the constraints of promotion costs. We solve the LP problem by maximizing the Q-values of actions learned from the RL model given the budget constraints. During deployment, we combine the offline RL model with the LP model to generate a robust policy under the budget constraints. Using both online and offline experiments, we demonstrate the efficacy of our approach by showing that BCRLSP achieves a higher long-term customer retention rate and a lower cost than various baselines. Taking advantage of the near real-time cost control method, the proposed framework can easily adapt to data with a noisy behavioral policy and/or meet flexible budget constraints.
Multimodal 4DVarNets for the reconstruction of sea surface dynamics from SST-SSH synergies
Jul 04, 2022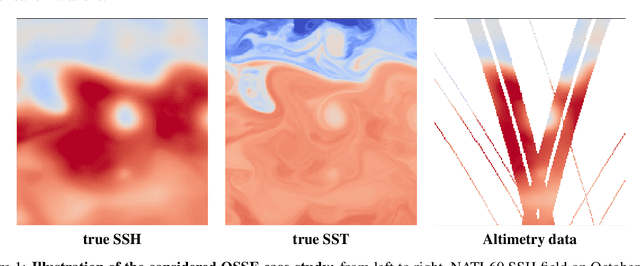
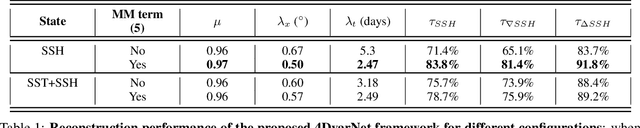
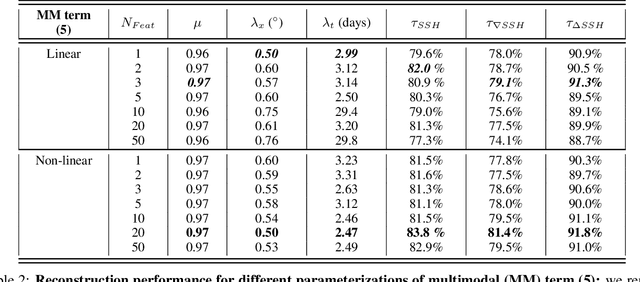

Due to the irregular space-time sampling of sea surface observations, the reconstruction of sea surface dynamics is a challenging inverse problem. While satellite altimetry provides a direct observation of the sea surface height (SSH), which relates to the divergence-free component of sea surface currents, the associated sampling pattern prevents from retrieving fine-scale sea surface dynamics, typically below a 10-day time scale. By contrast, other satellite sensors provide higher-resolution observations of sea surface tracers such as sea surface temperature (SST). Multimodal inversion schemes then arise as an appealing strategy. Though theoretical evidence supports the existence of an explicit relationship between sea surface temperature and sea surface dynamics under specific dynamical regimes, the generalization to the variety of upper ocean dynamical regimes is complex. Here, we investigate this issue from a physics-informed learning perspective. We introduce a trainable multimodal inversion scheme for the reconstruction of sea surface dynamics from multi-source satellite-derived observations. The proposed 4DVarNet schemes combine a variational formulation involving trainable observation and a priori terms with a trainable gradient-based solver. We report an application to the reconstruction of the divergence-free component of sea surface dynamics from satellite-derived SSH and SST data. An observing system simulation experiment for a Gulf Stream region supports the relevance of our approach compared with state-of-the-art schemes. We report relative improvement greater than 50% compared with the operational altimetry product in terms of root mean square error and resolved space-time scales. We discuss further the application and extension of the proposed approach for the reconstruction and forecasting of geophysical dynamics from irregularly-sampled satellite observations.
Upper Limb Movement Recognition utilising EEG and EMG Signals for Rehabilitative Robotics
Jul 18, 2022
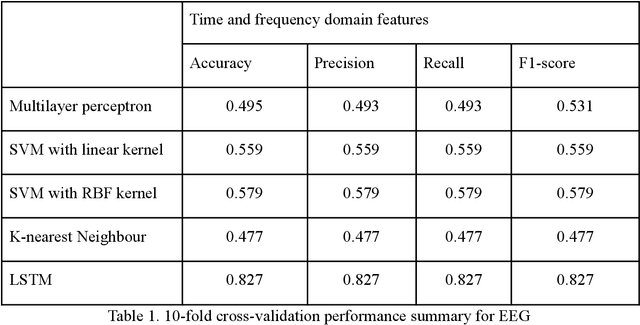
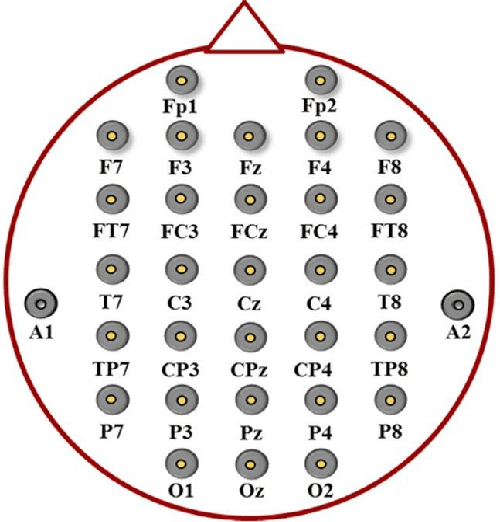
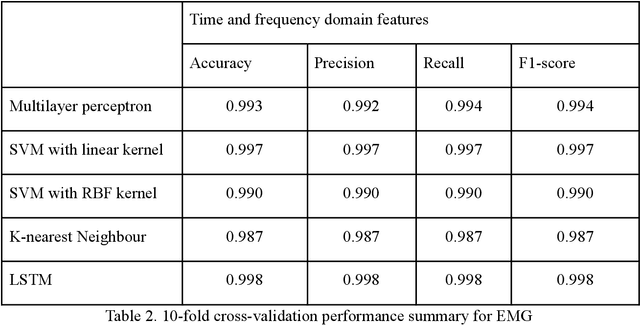
Upper limb movement classification, which maps input signals to the target activities, is one of the crucial areas in the control of rehabilitative robotics. Classifiers are trained for the rehabilitative system to comprehend the desires of the patient whose upper limbs do not function properly. Electromyography (EMG) signals and Electroencephalography (EEG) signals are used widely for upper limb movement classification. By analysing the classification results of the real-time EEG and EMG signals, the system can understand the intention of the user and predict the events that one would like to carry out. Accordingly, it will provide external help to the user to assist one to perform the activities. However, not all users process effective EEG and EMG signals due to the noisy environment. The noise in the real-time data collection process contaminates the effectiveness of the data. Moreover, not all patients process strong EMG signals due to muscle damage and neuromuscular disorder. To address these issues, we would like to propose a novel decision-level multisensor fusion technique. In short, the system will integrate EEG signals with EMG signals, retrieve effective information from both sources to understand and predict the desire of the user, and thus provide assistance. By testing out the proposed technique on a publicly available WAY-EEG-GAL dataset, which contains EEG and EMG signals that were recorded simultaneously, we manage to conclude the feasibility and effectiveness of the novel system.
Speech Enhancement and Dereverberation with Diffusion-based Generative Models
Aug 11, 2022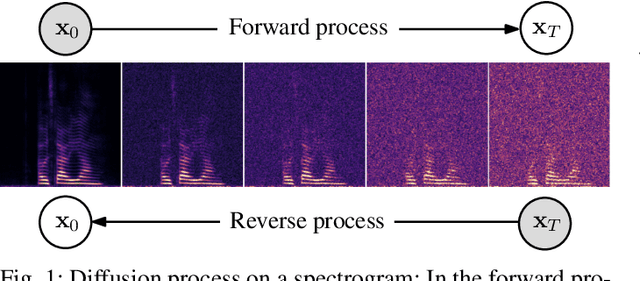
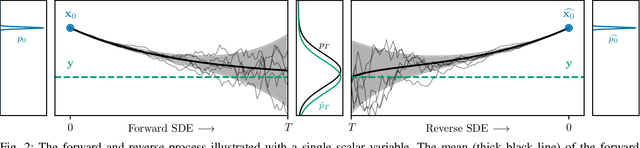
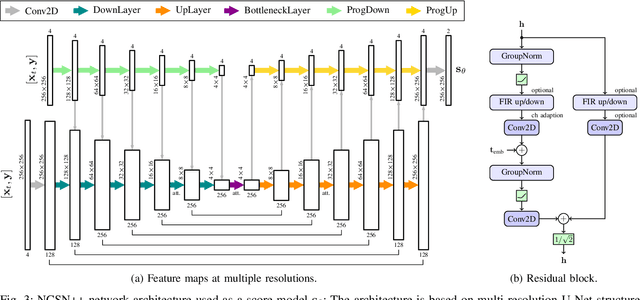
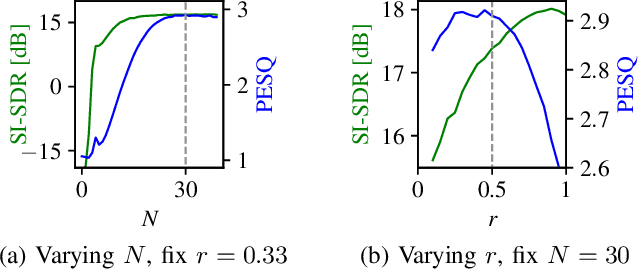
Recently, diffusion-based generative models have been introduced to the task of speech enhancement. The corruption of clean speech is modeled as a fixed forward process in which increasing amounts of noise are gradually added. By learning to reverse this process in an iterative fashion conditioned on the noisy input, clean speech is generated. We build upon our previous work and derive the training task within the formalism of stochastic differential equations. We present a detailed theoretical review of the underlying score matching objective and explore different sampler configurations for solving the reverse process at test time. By using a sophisticated network architecture from natural image generation literature, we significantly improve performance compared to our previous publication. We also show that we can compete with recent discriminative models and achieve better generalization when evaluating on a different corpus than used for training. We complement the evaluation results with a subjective listening test, in which our proposed method is rated best. Furthermore, we show that the proposed method achieves remarkable state-of-the-art performance in single-channel speech dereverberation. Our code and audio examples are available online, see https://uhh.de/inf-sp-sgmse
MotionMixer: MLP-based 3D Human Body Pose Forecasting
Jul 01, 2022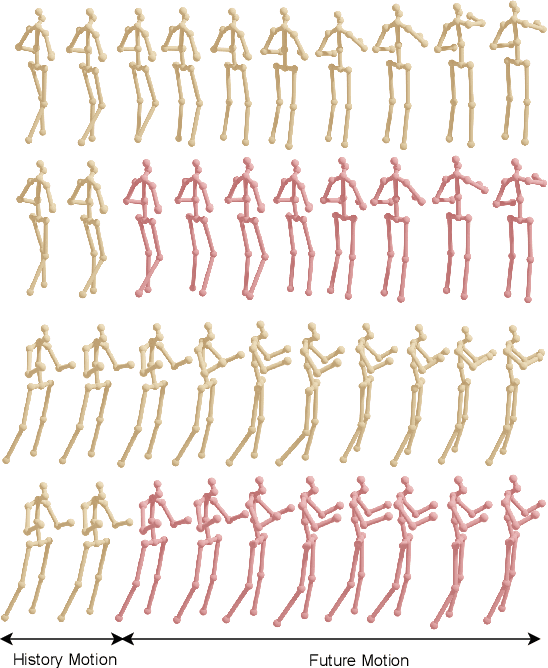
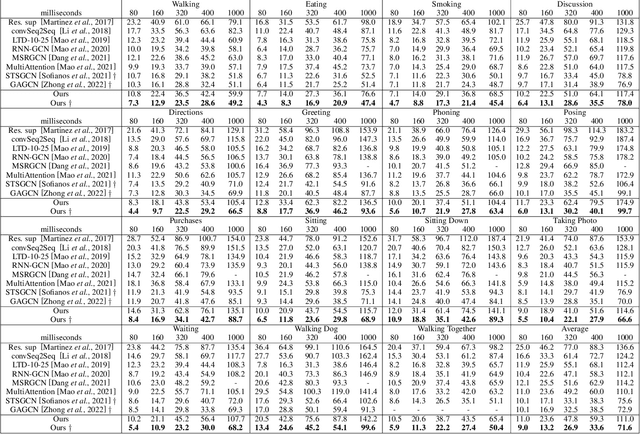
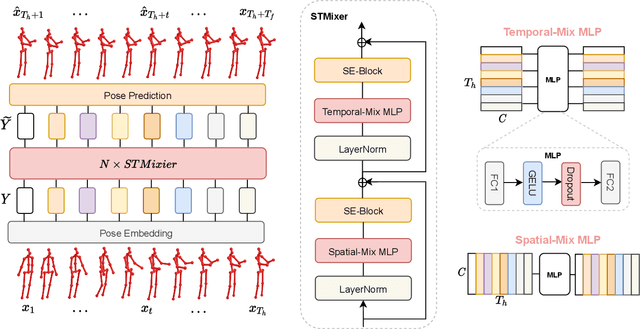
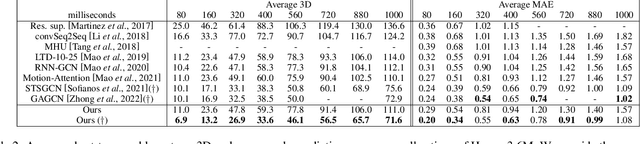
In this work, we present MotionMixer, an efficient 3D human body pose forecasting model based solely on multi-layer perceptrons (MLPs). MotionMixer learns the spatial-temporal 3D body pose dependencies by sequentially mixing both modalities. Given a stacked sequence of 3D body poses, a spatial-MLP extracts fine grained spatial dependencies of the body joints. The interaction of the body joints over time is then modelled by a temporal MLP. The spatial-temporal mixed features are finally aggregated and decoded to obtain the future motion. To calibrate the influence of each time step in the pose sequence, we make use of squeeze-and-excitation (SE) blocks. We evaluate our approach on Human3.6M, AMASS, and 3DPW datasets using the standard evaluation protocols. For all evaluations, we demonstrate state-of-the-art performance, while having a model with a smaller number of parameters. Our code is available at: https://github.com/MotionMLP/MotionMixer