 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Symbolic Regression is NP-hard
Jul 05, 2022
Symbolic regression (SR) is the task of learning a model of data in the form of a mathematical expression. By their nature, SR models have the potential to be accurate and human-interpretable at the same time. Unfortunately, finding such models, i.e., performing SR, appears to be a computationally intensive task. Historically, SR has been tackled with heuristics such as greedy or genetic algorithms and, while some works have hinted at the possible hardness of SR, no proof has yet been given that SR is, in fact, NP-hard. This begs the question: Is there an exact polynomial-time algorithm to compute SR models? We provide evidence suggesting that the answer is probably negative by showing that SR is NP-hard.
Temporal Fuzzy Utility Maximization with Remaining Measure
Aug 26, 2022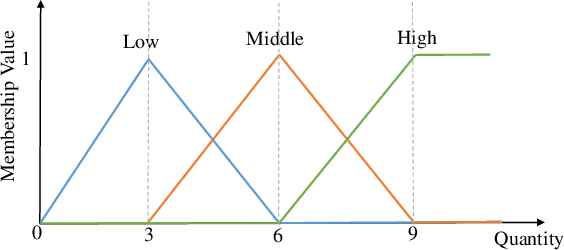
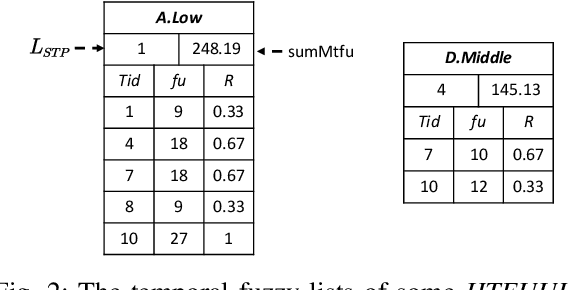
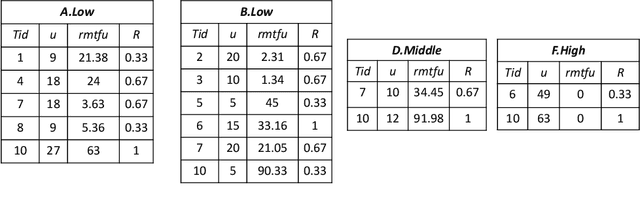
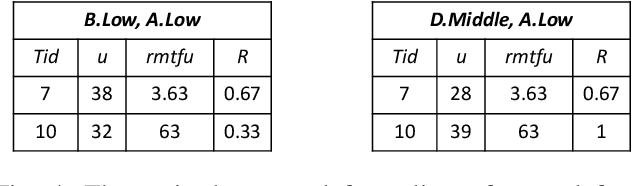
High utility itemset mining approaches discover hidden patterns from large amounts of temporal data. However, an inescapable problem of high utility itemset mining is that its discovered results hide the quantities of patterns, which causes poor interpretability. The results only reflect the shopping trends of customers, which cannot help decision makers quantify collected information. In linguistic terms, computers use mathematical or programming languages that are precisely formalized, but the language used by humans is always ambiguous. In this paper, we propose a novel one-phase temporal fuzzy utility itemset mining approach called TFUM. It revises temporal fuzzy-lists to maintain less but major information about potential high temporal fuzzy utility itemsets in memory, and then discovers a complete set of real interesting patterns in a short time. In particular, the remaining measure is the first adopted in the temporal fuzzy utility itemset mining domain in this paper. The remaining maximal temporal fuzzy utility is a tighter and stronger upper bound than that of previous studies adopted. Hence, it plays an important role in pruning the search space in TFUM. Finally, we also evaluate the efficiency and effectiveness of TFUM on various datasets. Extensive experimental results indicate that TFUM outperforms the state-of-the-art algorithms in terms of runtime cost, memory usage, and scalability. In addition, experiments prove that the remaining measure can significantly prune unnecessary candidates during mining.
A Monitoring and Discovery Approach for Declarative Processes Based on Streams
Aug 10, 2022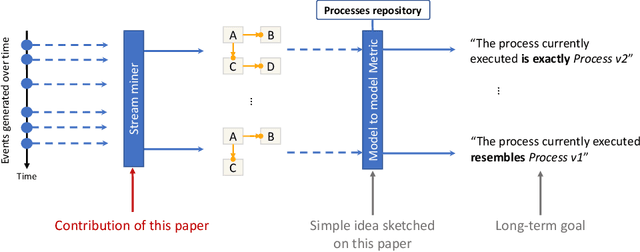
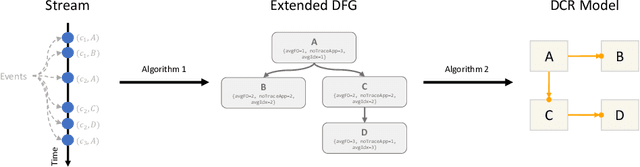
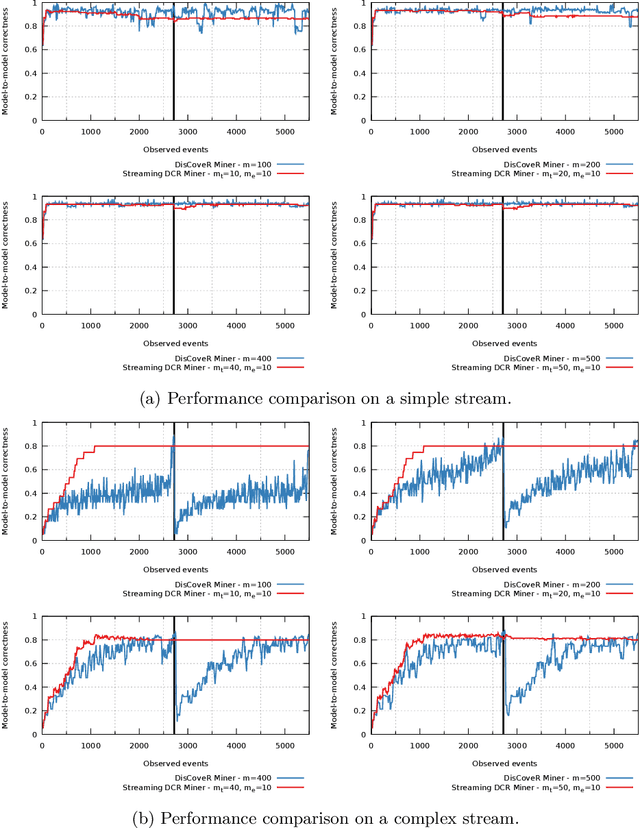
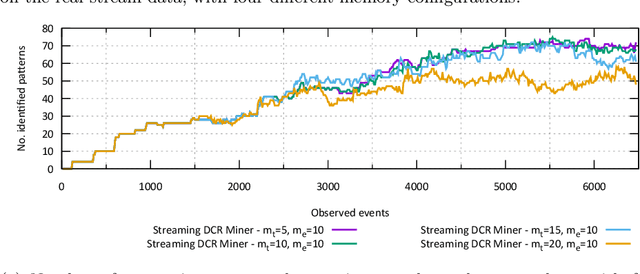
Process discovery is a family of techniques that helps to comprehend processes from their data footprints. Yet, as processes change over time so should their corresponding models, and failure to do so will lead to models that under- or over-approximate behavior. We present a discovery algorithm that extracts declarative processes as Dynamic Condition Response (DCR) graphs from event streams. Streams are monitored to generate temporal representations of the process, later processed to generate declarative models. We validated the technique via quantitative and qualitative evaluations. For the quantitative evaluation, we adopted an extended Jaccard similarity measure to account for process change in a declarative setting. For the qualitative evaluation, we showcase how changes identified by the technique correspond to real changes in an existing process. The technique and the data used for testing are available online.
Leukocyte Classification using Multimodal Architecture Enhanced by Knowledge Distillation
Aug 17, 2022
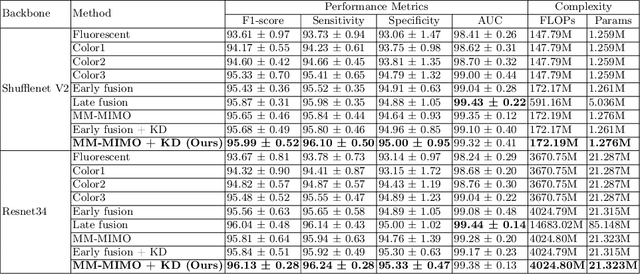
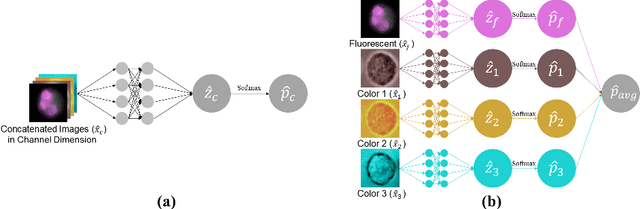
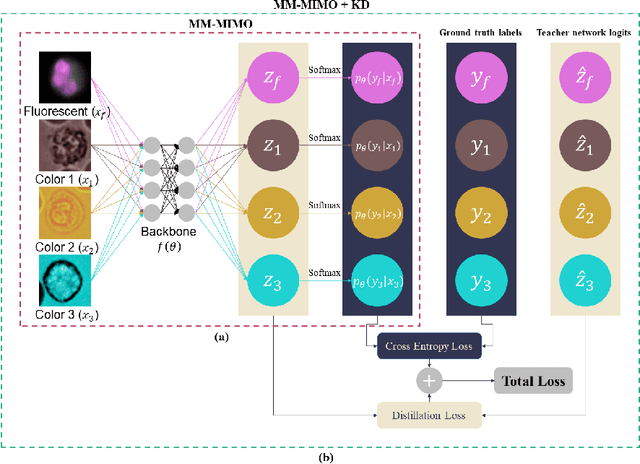
Recently, a lot of automated white blood cells (WBC) or leukocyte classification techniques have been developed. However, all of these methods only utilize a single modality microscopic image i.e. either blood smear or fluorescence based, thus missing the potential of a better learning from multimodal images. In this work, we develop an efficient multimodal architecture based on a first of its kind multimodal WBC dataset for the task of WBC classification. Specifically, our proposed idea is developed in two steps - 1) First, we learn modality specific independent subnetworks inside a single network only; 2) We further enhance the learning capability of the independent subnetworks by distilling knowledge from high complexity independent teacher networks. With this, our proposed framework can achieve a high performance while maintaining low complexity for a multimodal dataset. Our unique contribution is two-fold - 1) We present a first of its kind multimodal WBC dataset for WBC classification; 2) We develop a high performing multimodal architecture which is also efficient and low in complexity at the same time.
AvatarPoser: Articulated Full-Body Pose Tracking from Sparse Motion Sensing
Jul 27, 2022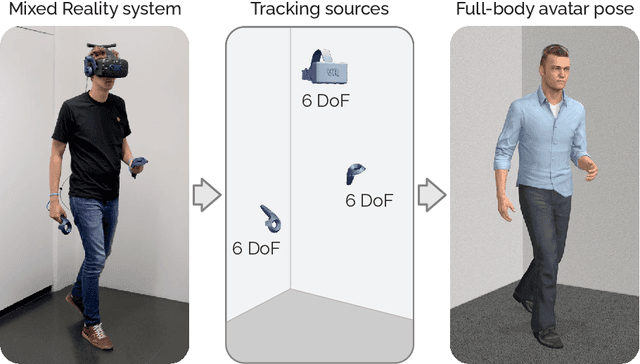
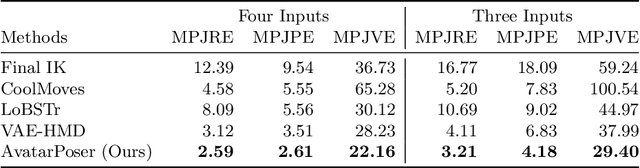
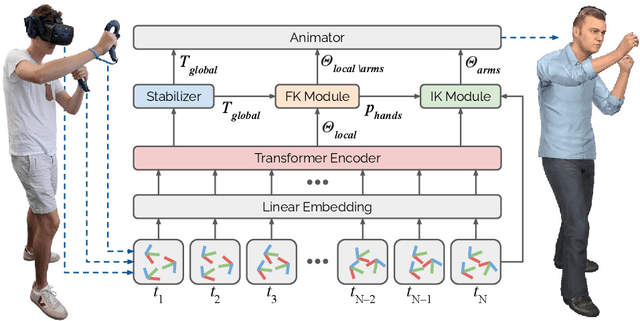
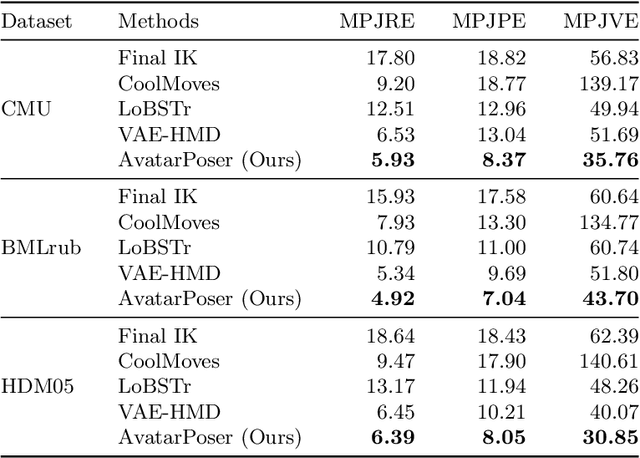
Today's Mixed Reality head-mounted displays track the user's head pose in world space as well as the user's hands for interaction in both Augmented Reality and Virtual Reality scenarios. While this is adequate to support user input, it unfortunately limits users' virtual representations to just their upper bodies. Current systems thus resort to floating avatars, whose limitation is particularly evident in collaborative settings. To estimate full-body poses from the sparse input sources, prior work has incorporated additional trackers and sensors at the pelvis or lower body, which increases setup complexity and limits practical application in mobile settings. In this paper, we present AvatarPoser, the first learning-based method that predicts full-body poses in world coordinates using only motion input from the user's head and hands. Our method builds on a Transformer encoder to extract deep features from the input signals and decouples global motion from the learned local joint orientations to guide pose estimation. To obtain accurate full-body motions that resemble motion capture animations, we refine the arm joints' positions using an optimization routine with inverse kinematics to match the original tracking input. In our evaluation, AvatarPoser achieved new state-of-the-art results in evaluations on large motion capture datasets (AMASS). At the same time, our method's inference speed supports real-time operation, providing a practical interface to support holistic avatar control and representation for Metaverse applications.
DNN-Free Low-Latency Adaptive Speech Enhancement Based on Frame-Online Beamforming Powered by Block-Online FastMNMF
Jul 22, 2022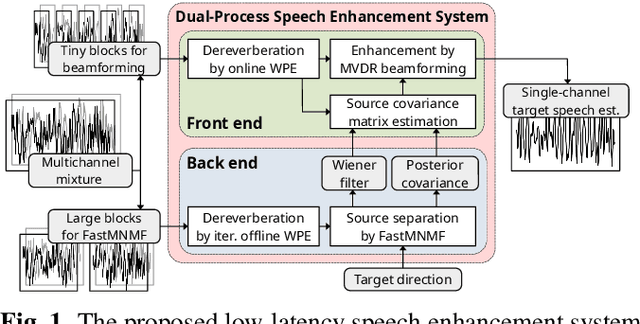
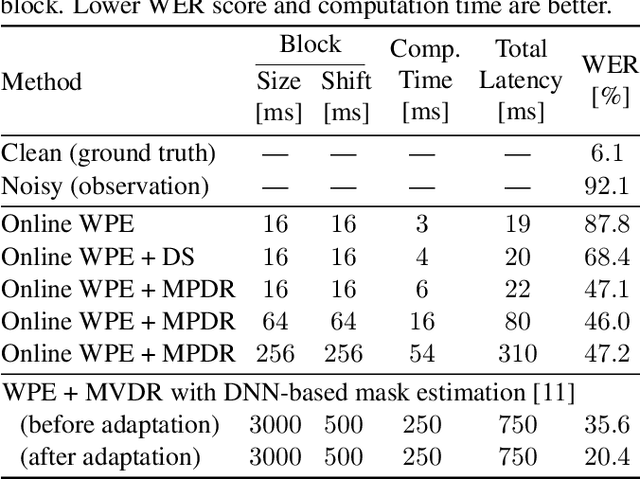

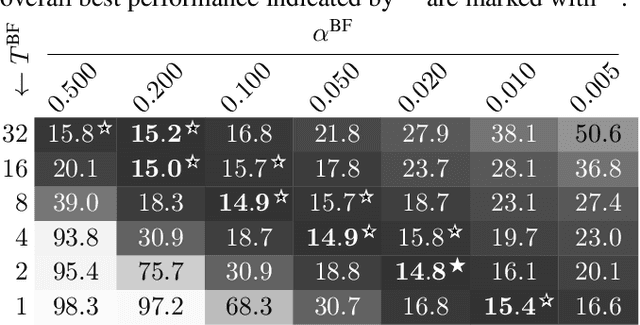
This paper describes a practical dual-process speech enhancement system that adapts environment-sensitive frame-online beamforming (front-end) with help from environment-free block-online source separation (back-end). To use minimum variance distortionless response (MVDR) beamforming, one may train a deep neural network (DNN) that estimates time-frequency masks used for computing the covariance matrices of sources (speech and noise). Backpropagation-based run-time adaptation of the DNN was proposed for dealing with the mismatched training-test conditions. Instead, one may try to directly estimate the source covariance matrices with a state-of-the-art blind source separation method called fast multichannel non-negative matrix factorization (FastMNMF). In practice, however, neither the DNN nor the FastMNMF can be updated in a frame-online manner due to its computationally-expensive iterative nature. Our DNN-free system leverages the posteriors of the latest source spectrograms given by block-online FastMNMF to derive the current source covariance matrices for frame-online beamforming. The evaluation shows that our frame-online system can quickly respond to scene changes caused by interfering speaker movements and outperformed an existing block-online system with DNN-based beamforming by 5.0 points in terms of the word error rate.
Rethink Dilated Convolution for Real-time Semantic Segmentation
Nov 18, 2021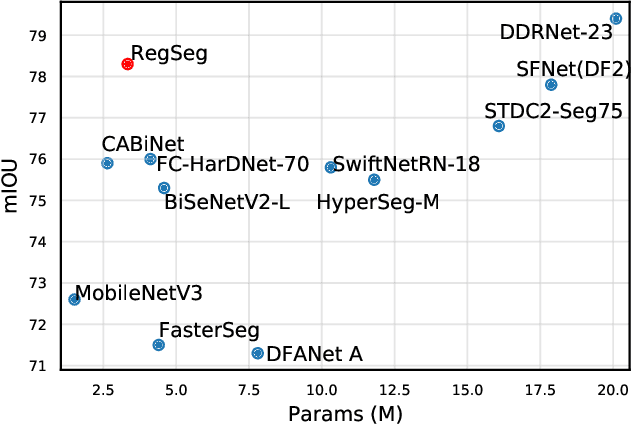
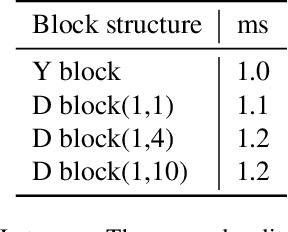
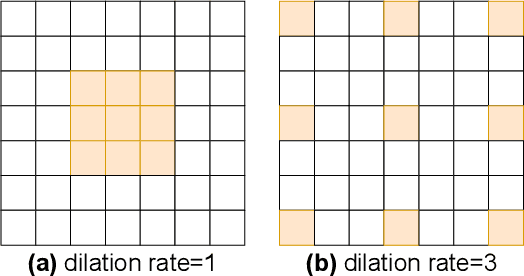
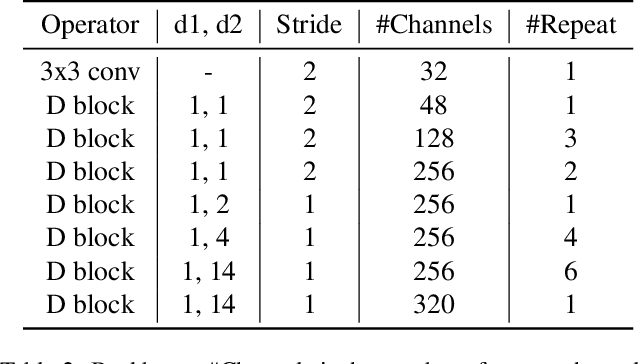
Recent advances in semantic segmentation generally adapt an ImageNet pretrained backbone with a special context module after it to quickly increase the field-of-view. Although successful, the backbone, in which most of the computation lies, does not have a large enough field-of-view to make the best decisions. Some recent advances tackle this problem by rapidly downsampling the resolution in the backbone while also having one or more parallel branches with higher resolutions. We take a different approach by designing a ResNeXt inspired block structure that uses two parallel 3x3 convolutional layers with different dilation rates to increase the field-of-view while also preserving the local details. By repeating this block structure in the backbone, we do not need to append any special context module after it. In addition, we propose a lightweight decoder that restores local information better than common alternatives. To demonstrate the effectiveness of our approach, our model RegSeg achieves state-of-the-art results on real-time Cityscapes and CamVid datasets. Using a T4 GPU with mixed precision, RegSeg achieves 78.3 mIOU on Cityscapes test set at 30 FPS, and 80.9 mIOU on CamVid test set at 70 FPS, both without ImageNet pretraining.
Beyond Parallel Pancakes: Quasi-Polynomial Time Guarantees for Non-Spherical Gaussian Mixtures
Dec 10, 2021We consider mixtures of $k\geq 2$ Gaussian components with unknown means and unknown covariance (identical for all components) that are well-separated, i.e., distinct components have statistical overlap at most $k^{-C}$ for a large enough constant $C\ge 1$. Previous statistical-query lower bounds [DKS17] give formal evidence that even distinguishing such mixtures from (pure) Gaussians may be exponentially hard (in $k$). We show that this kind of hardness can only appear if mixing weights are allowed to be exponentially small, and that for polynomially lower bounded mixing weights non-trivial algorithmic guarantees are possible in quasi-polynomial time. Concretely, we develop an algorithm based on the sum-of-squares method with running time quasi-polynomial in the minimum mixing weight. The algorithm can reliably distinguish between a mixture of $k\ge 2$ well-separated Gaussian components and a (pure) Gaussian distribution. As a certificate, the algorithm computes a bipartition of the input sample that separates a pair of mixture components, i.e., both sides of the bipartition contain most of the sample points of at least one component. For the special case of colinear means, our algorithm outputs a $k$ clustering of the input sample that is approximately consistent with the components of the mixture. A significant challenge for our results is that they appear to be inherently sensitive to small fractions of adversarial outliers unlike most previous results for Gaussian mixtures. The reason is that such outliers can simulate exponentially small mixing weights even for mixtures with polynomially lower bounded mixing weights. A key technical ingredient is a characterization of separating directions for well-separated Gaussian components in terms of ratios of polynomials that correspond to moments of two carefully chosen orders logarithmic in the minimum mixing weight.
Adaptation Strategy for a Distributed Autonomous UAV Formation in Case of Aircraft Loss
Aug 04, 2022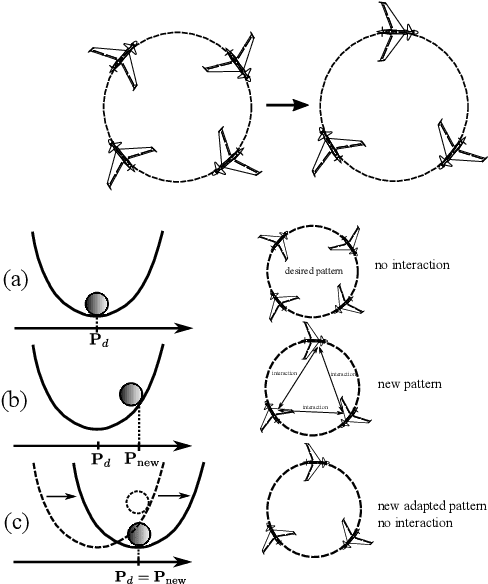
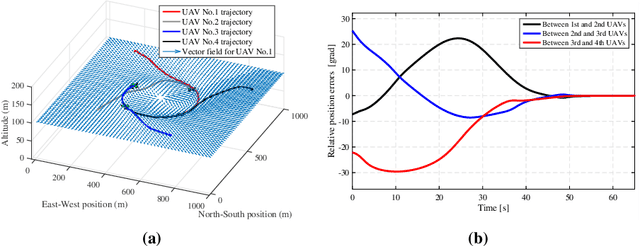
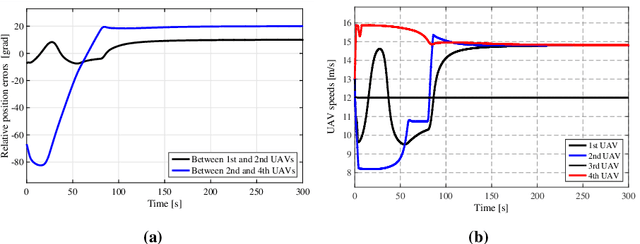
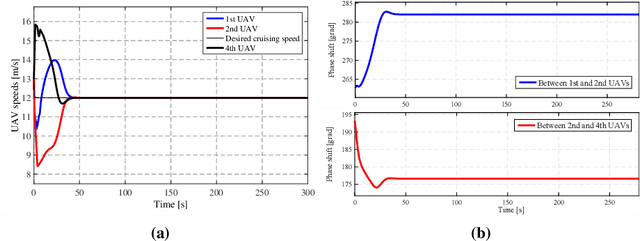
Controlling a distributed autonomous unmanned aerial vehicle (UAV) formation is usually considered in the context of recovering the connectivity graph should a single UAV agent be lost. At the same time, little focus is made on how such loss affects the dynamics of the formation as a system. To compensate for the negative effects, we propose an adaptation algorithm that reduces the increasing interaction between the UAV agents that remain in the formation. This algorithm enables the autonomous system to adjust to the new equilibrium state. The algorithm has been tested by computer simulation on full nonlinear UAV models. Simulation results prove the negative effect (the increased final cruising speed of the formation) to be completely eliminated.
TANDEM: Tracking and Dense Mapping in Real-time using Deep Multi-view Stereo
Nov 14, 2021

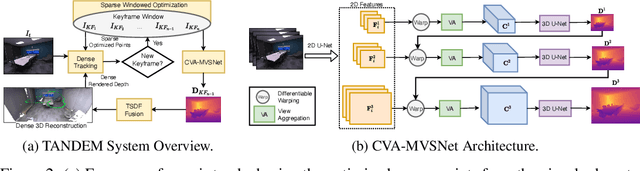
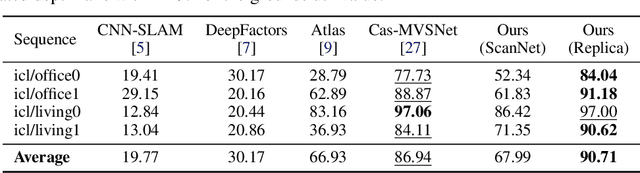
In this paper, we present TANDEM a real-time monocular tracking and dense mapping framework. For pose estimation, TANDEM performs photometric bundle adjustment based on a sliding window of keyframes. To increase the robustness, we propose a novel tracking front-end that performs dense direct image alignment using depth maps rendered from a global model that is built incrementally from dense depth predictions. To predict the dense depth maps, we propose Cascade View-Aggregation MVSNet (CVA-MVSNet) that utilizes the entire active keyframe window by hierarchically constructing 3D cost volumes with adaptive view aggregation to balance the different stereo baselines between the keyframes. Finally, the predicted depth maps are fused into a consistent global map represented as a truncated signed distance function (TSDF) voxel grid. Our experimental results show that TANDEM outperforms other state-of-the-art traditional and learning-based monocular visual odometry (VO) methods in terms of camera tracking. Moreover, TANDEM shows state-of-the-art real-time 3D reconstruction performance.