 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Global Convergence of Two-timescale Actor-Critic for Solving Linear Quadratic Regulator
Aug 18, 2022
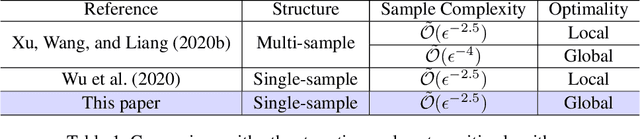
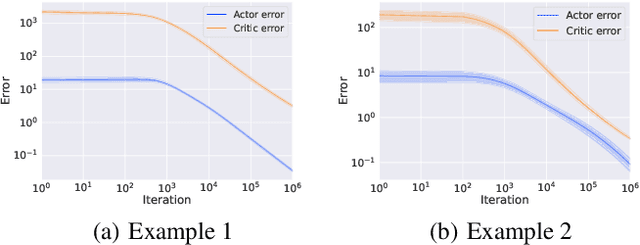

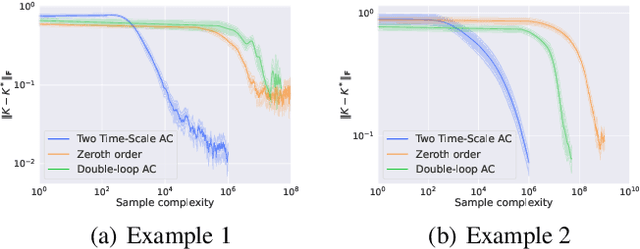
The actor-critic (AC) reinforcement learning algorithms have been the powerhouse behind many challenging applications. Nevertheless, its convergence is fragile in general. To study its instability, existing works mostly consider the uncommon double-loop variant or basic models with finite state and action space. We investigate the more practical single-sample two-timescale AC for solving the canonical linear quadratic regulator (LQR) problem, where the actor and the critic update only once with a single sample in each iteration on an unbounded continuous state and action space. Existing analysis cannot conclude the convergence for such a challenging case. We develop a new analysis framework that allows establishing the global convergence to an $\epsilon$-optimal solution with at most an $\tilde{\mathcal{O}}(\epsilon^{-2.5})$ sample complexity. To our knowledge, this is the first finite-time convergence analysis for the single sample two-timescale AC for solving LQR with global optimality. The sample complexity improves those of other variants by orders, which sheds light on the practical wisdom of single sample algorithms. We also further validate our theoretical findings via comprehensive simulation comparisons.
IRIS: Integrated Retinal Functionality in Image Sensors
Aug 14, 2022Neuromorphic image sensors draw inspiration from the biological retina to implement visual computations in electronic hardware. Gain control in phototransduction and temporal differentiation at the first retinal synapse inspired the first generation of neuromorphic sensors, but processing in downstream retinal circuits, much of which has been discovered in the past decade, has not been implemented in image sensor technology. We present a technology-circuit co-design solution that implements two motion computations occurring at the output of the retina that could have wide applications for vision based decision making in dynamic environments. Our simulations on Globalfoundries 22nm technology node show that, by taking advantage of the recent advances in semiconductor chip stacking technology, the proposed retina-inspired circuits can be fabricated on image sensing platforms in existing semiconductor foundries. Integrated Retinal Functionality in Image Sensors (IRIS) technology could drive advances in machine vision applications that demand robust, high-speed, energy-efficient and low-bandwidth real-time decision making.
Causal Navigation by Continuous-time Neural Networks
Jun 15, 2021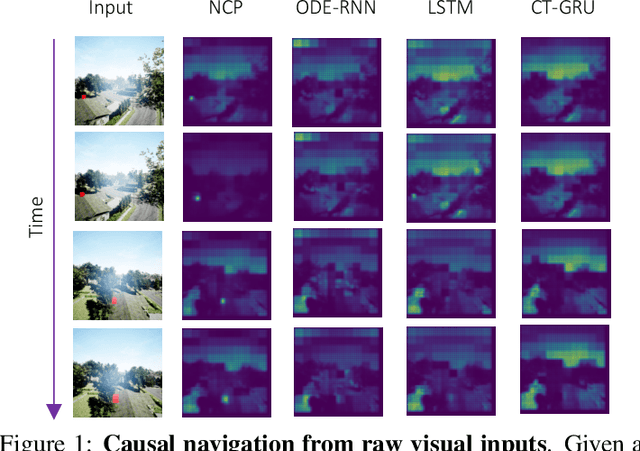
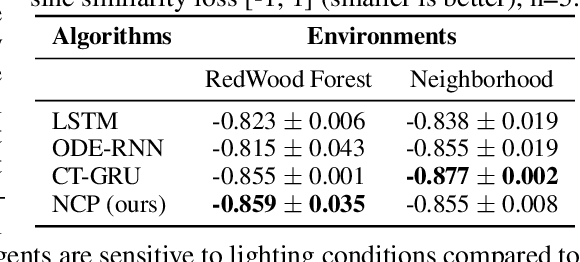

Imitation learning enables high-fidelity, vision-based learning of policies within rich, photorealistic environments. However, such techniques often rely on traditional discrete-time neural models and face difficulties in generalizing to domain shifts by failing to account for the causal relationships between the agent and the environment. In this paper, we propose a theoretical and experimental framework for learning causal representations using continuous-time neural networks, specifically over their discrete-time counterparts. We evaluate our method in the context of visual-control learning of drones over a series of complex tasks, ranging from short- and long-term navigation, to chasing static and dynamic objects through photorealistic environments. Our results demonstrate that causal continuous-time deep models can perform robust navigation tasks, where advanced recurrent models fail. These models learn complex causal control representations directly from raw visual inputs and scale to solve a variety of tasks using imitation learning.
Real-time Online Multi-Object Tracking in Compressed Domain
Apr 05, 2022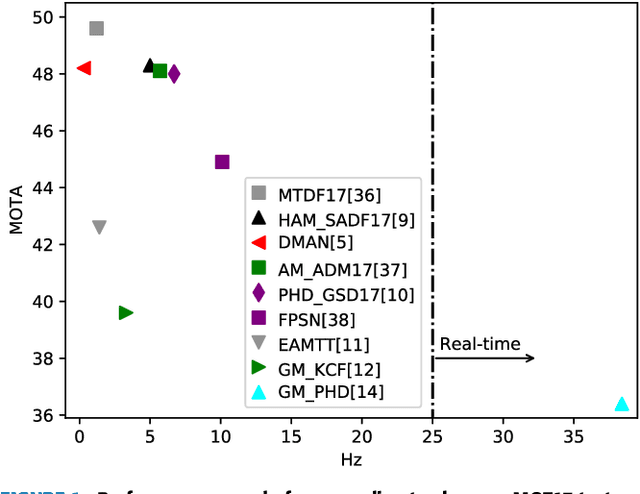

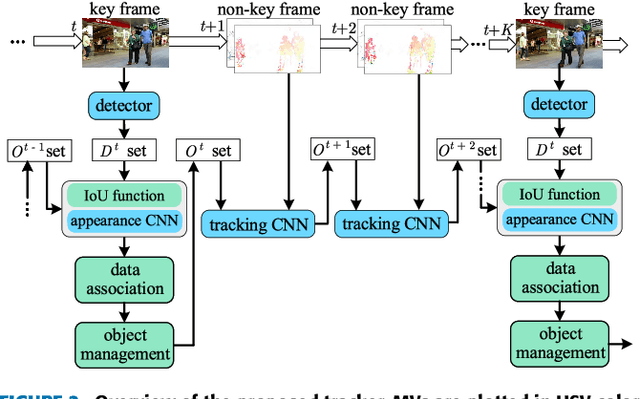
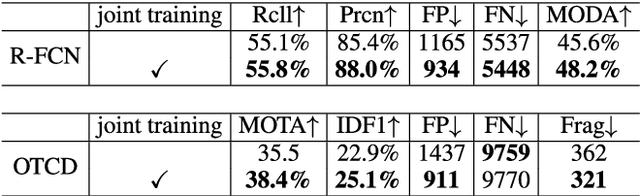
Recent online Multi-Object Tracking (MOT) methods have achieved desirable tracking performance. However, the tracking speed of most existing methods is rather slow. Inspired from the fact that the adjacent frames are highly relevant and redundant, we divide the frames into key and non-key frames respectively and track objects in the compressed domain. For the key frames, the RGB images are restored for detection and data association. To make data association more reliable, an appearance Convolutional Neural Network (CNN) which can be jointly trained with the detector is proposed. For the non-key frames, the objects are directly propagated by a tracking CNN based on the motion information provided in the compressed domain. Compared with the state-of-the-art online MOT methods,our tracker is about 6x faster while maintaining a comparable tracking performance.
Hitless memory-reconfigurable photonic reservoir computing architecture
Jul 13, 2022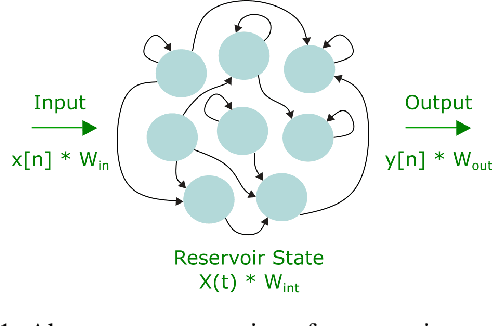
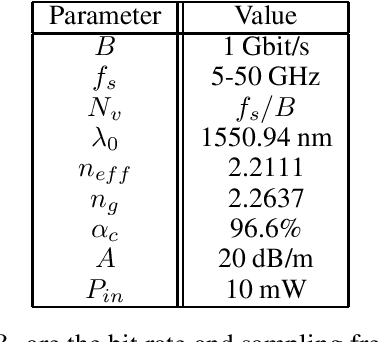
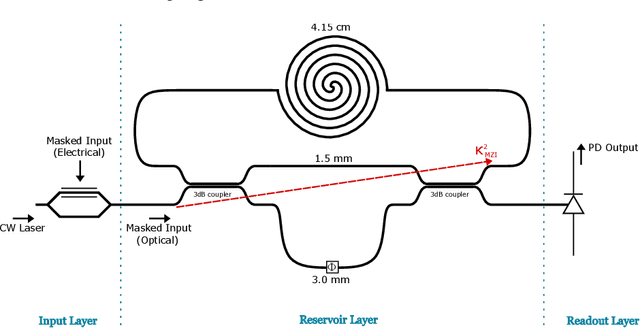

Reservoir computing is an analog bio-inspired computation model for efficiently processing time-dependent signals, the photonic implementations of which promise a combination of massive parallel information processing, low power consumption, and high speed operation. However, most implementations, especially for the case of time-delay reservoir computing (TDRC), require signal attenuation in the reservoir to achieve the desired system dynamics for a specific task, often resulting in large amounts of power being coupled outside of the system. We propose a novel TDRC architecture based on an asymmetric Mach-Zehnder interferometer (MZI) integrated in a resonant cavity which allows the memory capacity of the system to be tuned without the need for an optical attenuator block. Furthermore, this can be leveraged to find the optimal value for the specific components of the total memory capacity metric. We demonstrate this approach on the temporal bitwise XOR task and conclude that this way of memory capacity reconfiguration allows optimal performance to be achieved for memory-specific tasks.
RHA-Net: An Encoder-Decoder Network with Residual Blocks and Hybrid Attention Mechanisms for Pavement Crack Segmentation
Jul 28, 2022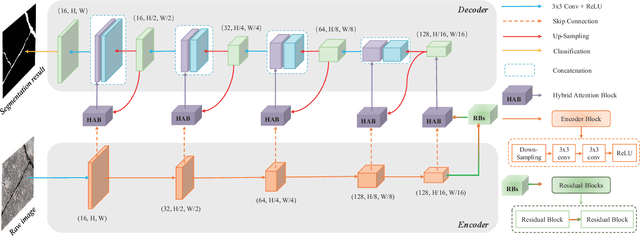

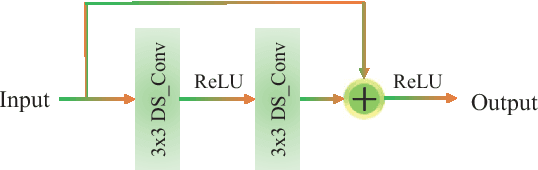
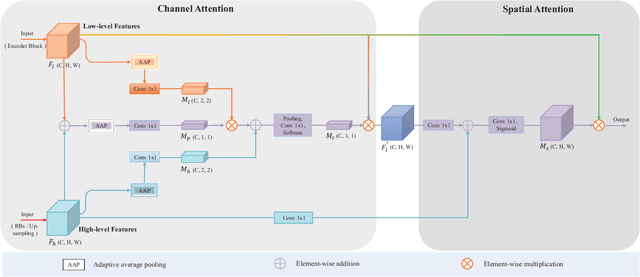
The acquisition and evaluation of pavement surface data play an essential role in pavement condition evaluation. In this paper, an efficient and effective end-to-end network for automatic pavement crack segmentation, called RHA-Net, is proposed to improve the pavement crack segmentation accuracy. The RHA-Net is built by integrating residual blocks (ResBlocks) and hybrid attention blocks into the encoder-decoder architecture. The ResBlocks are used to improve the ability of RHA-Net to extract high-level abstract features. The hybrid attention blocks are designed to fuse both low-level features and high-level features to help the model focus on correct channels and areas of cracks, thereby improving the feature presentation ability of RHA-Net. An image data set containing 789 pavement crack images collected by a self-designed mobile robot is constructed and used for training and evaluating the proposed model. Compared with other state-of-the-art networks, the proposed model achieves better performance and the functionalities of adding residual blocks and hybrid attention mechanisms are validated in a comprehensive ablation study. Additionally, a light-weighted version of the model generated by introducing depthwise separable convolution achieves better a performance and a much faster processing speed with 1/30 of the number of U-Net parameters. The developed system can segment pavement crack in real-time on an embedded device Jetson TX2 (25 FPS). The video taken in real-time experiments is released at https://youtu.be/3XIogk0fiG4.
Back to the Future: Efficient, Time-Consistent Solutions in Reach-Avoid Games
Sep 16, 2021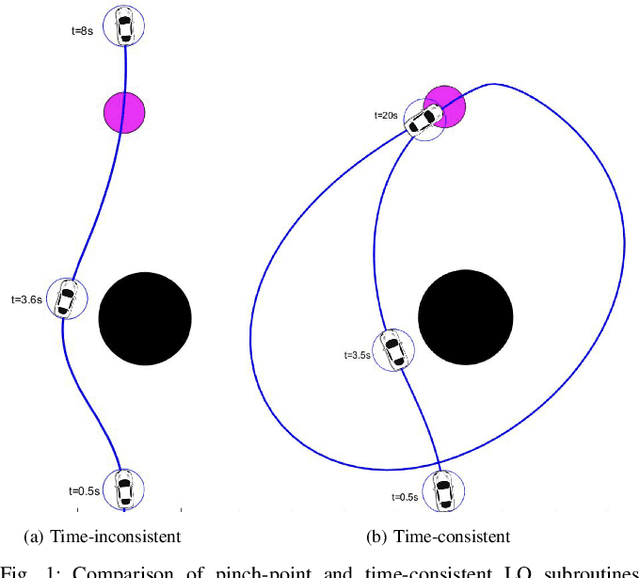
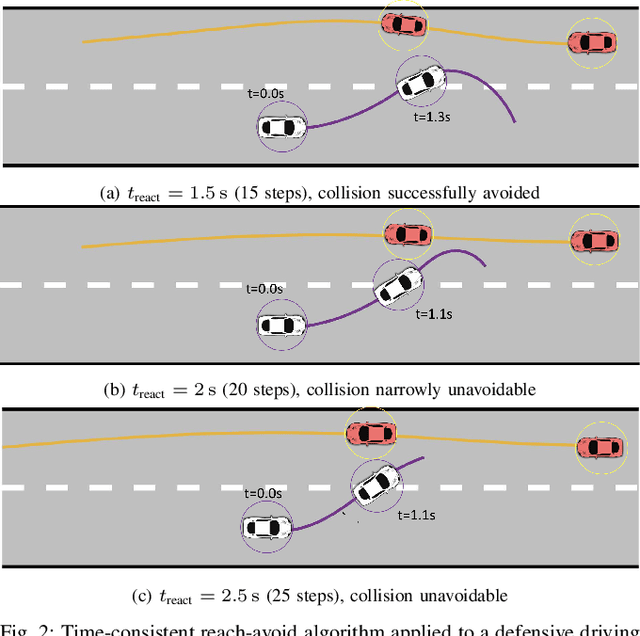
We study the class of reach-avoid dynamic games in which multiple agents interact noncooperatively, and each wishes to satisfy a distinct target condition while avoiding a failure condition. Reach-avoid games are commonly used to express safety-critical optimal control problems found in mobile robot motion planning. While a wide variety of approaches exist for these motion planning problems, we focus on finding time-consistent solutions, in which planned future motion is still optimal despite prior suboptimal actions. Though abstract, time consistency encapsulates an extremely desirable property: namely, time-consistent motion plans remain optimal even when a robot's motion diverges from the plan early on due to, e.g., intrinsic dynamic uncertainty or extrinsic environment disturbances. Our main contribution is a computationally-efficient algorithm for multi-agent reach-avoid games which renders time-consistent solutions. We demonstrate our approach in a simulated driving scenario, where we construct a two-player adversarial game to model a range of defensive driving behaviors.
RZSR: Reference-based Zero-Shot Super-Resolution with Depth Guided Self-Exemplars
Aug 24, 2022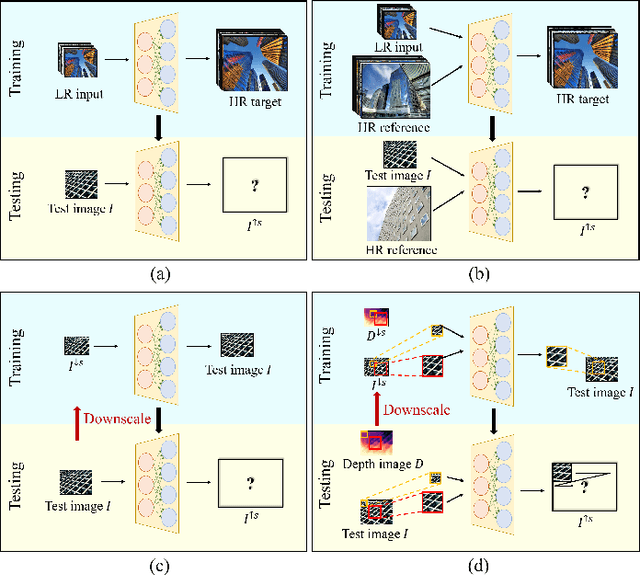
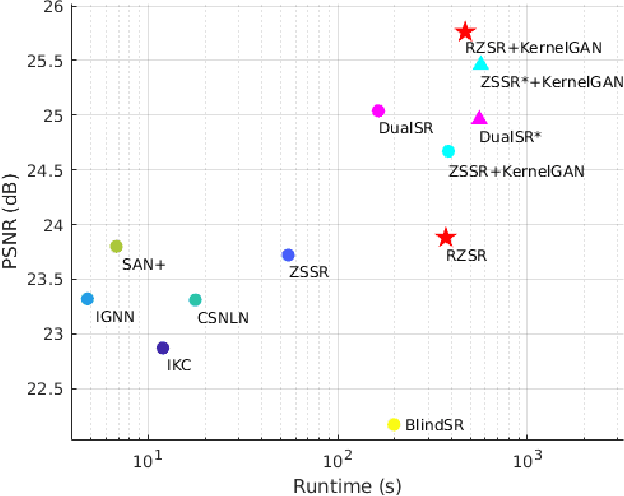
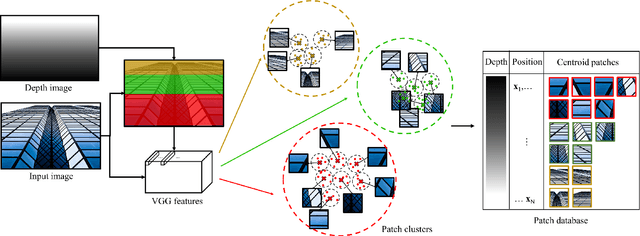
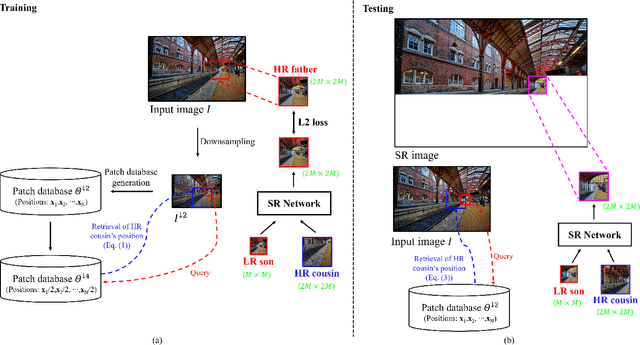
Recent methods for single image super-resolution (SISR) have demonstrated outstanding performance in generating high-resolution (HR) images from low-resolution (LR) images. However, most of these methods show their superiority using synthetically generated LR images, and their generalizability to real-world images is often not satisfactory. In this paper, we pay attention to two well-known strategies developed for robust super-resolution (SR), i.e., reference-based SR (RefSR) and zero-shot SR (ZSSR), and propose an integrated solution, called reference-based zero-shot SR (RZSR). Following the principle of ZSSR, we train an image-specific SR network at test time using training samples extracted only from the input image itself. To advance ZSSR, we obtain reference image patches with rich textures and high-frequency details which are also extracted only from the input image using cross-scale matching. To this end, we construct an internal reference dataset and retrieve reference image patches from the dataset using depth information. Using LR patches and their corresponding HR reference patches, we train a RefSR network that is embodied with a non-local attention module. Experimental results demonstrate the superiority of the proposed RZSR compared to the previous ZSSR methods and robustness to unseen images compared to other fully supervised SISR methods.
Real-time 3D Object Detection using Feature Map Flow
Jun 26, 2021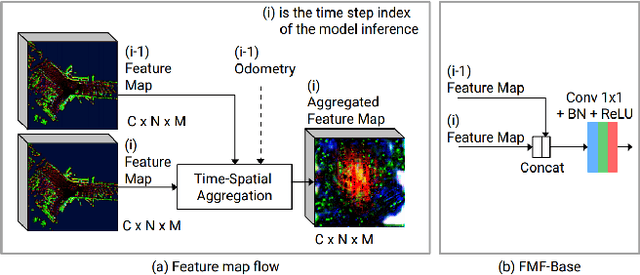

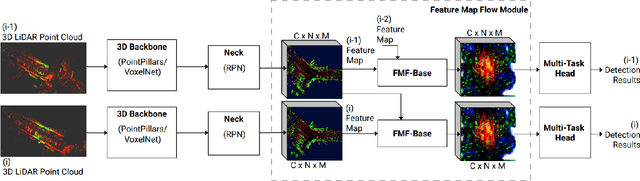

In this paper, we present a real-time 3D detection approach considering time-spatial feature map aggregation from different time steps of deep neural model inference (named feature map flow, FMF). Proposed approach improves the quality of 3D detection center-based baseline and provides real-time performance on the nuScenes and Waymo benchmark. Code is available at https://github.com/YoushaaMurhij/FMFNet
STrajNet: Occupancy Flow Prediction via Multi-modal Swin Transformer
Jul 31, 2022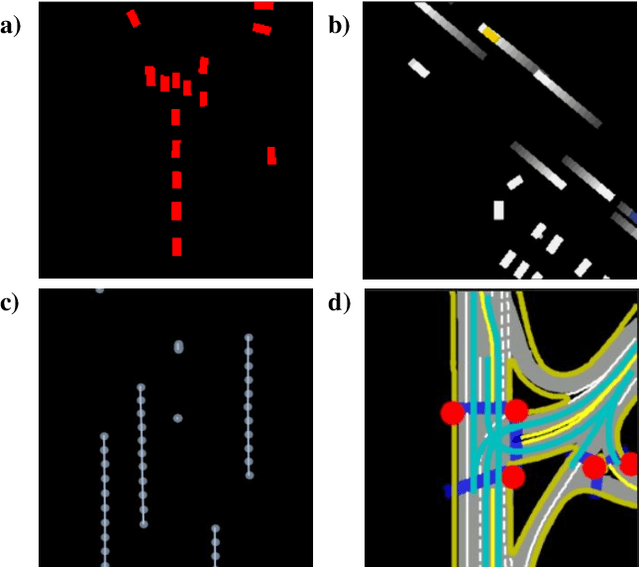

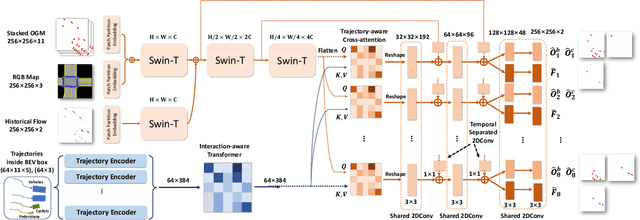
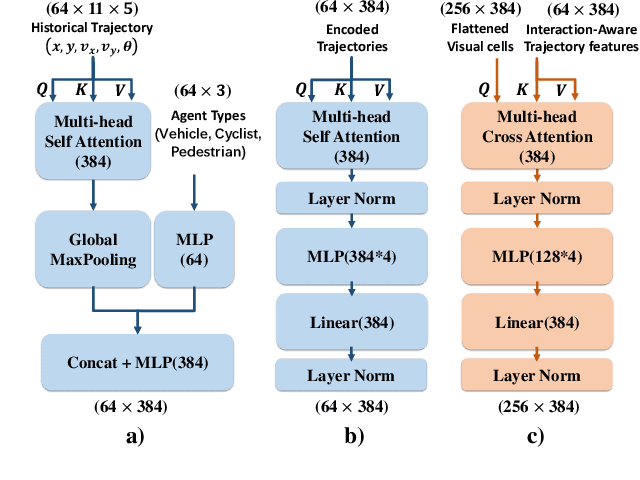
Making an accurate prediction of occupancy and flow is essential to enable better safety and interaction for autonomous vehicles under complex traffic scenarios. This work proposes STrajNet: a multi-modal Swin Transformerbased framework for effective scene occupancy and flow predictions. We employ Swin Transformer to encode the image and interaction-aware motion representations and propose a cross-attention module to inject motion awareness into grid cells across different time steps. Flow and occupancy predictions are then decoded through temporalsharing Pyramid decoders. The proposed method shows competitive prediction accuracy and other evaluation metrics in the Waymo Open Dataset benchmark.