 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
ATCA: an Arc Trajectory Based Model with Curvature Attention for Video Frame Interpolation
Aug 01, 2022
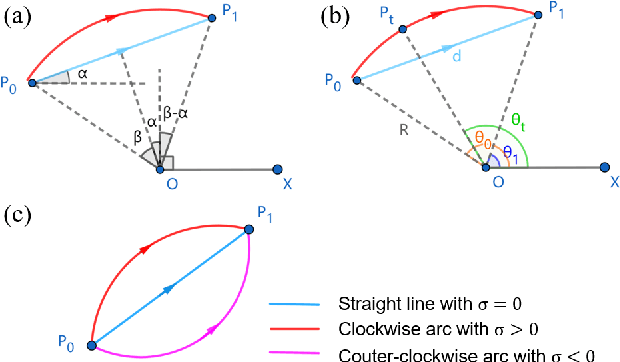
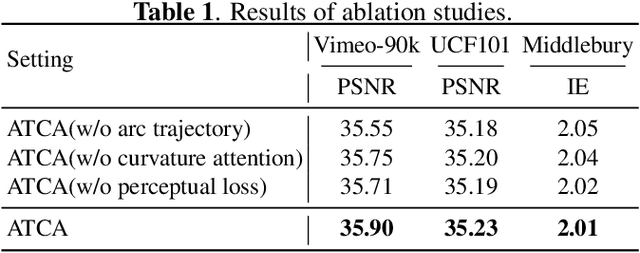
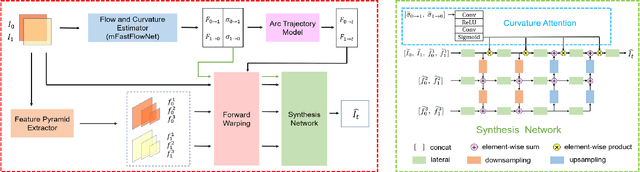
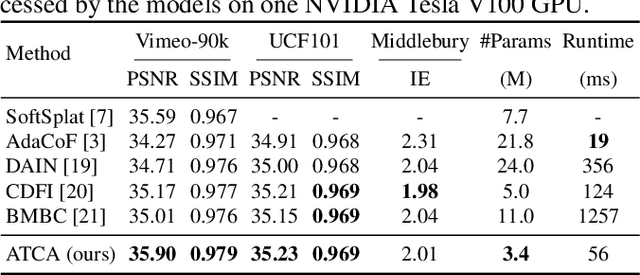
Video frame interpolation is a classic and challenging low-level computer vision task. Recently, deep learning based methods have achieved impressive results, and it has been proven that optical flow based methods can synthesize frames with higher quality. However, most flow-based methods assume a line trajectory with a constant velocity between two input frames. Only a little work enforces predictions with curvilinear trajectory, but this requires more than two frames as input to estimate the acceleration, which takes more time and memory to execute. To address this problem, we propose an arc trajectory based model (ATCA), which learns motion prior from only two consecutive frames and also is lightweight. Experiments show that our approach performs better than many SOTA methods with fewer parameters and faster inference speed.
FLOWGEN: Fast and slow graph generation
Jul 21, 2022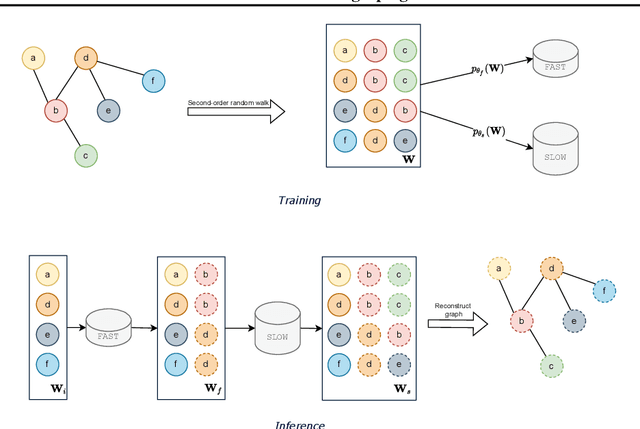

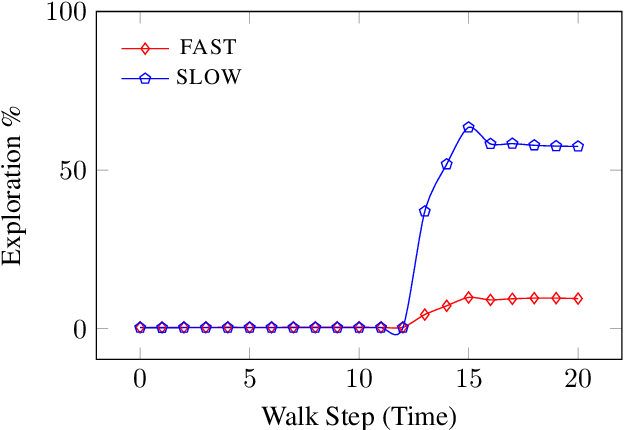

We present FLOWGEN, a graph-generation model inspired by the dual-process theory of mind that generates large graphs incrementally. Depending on the difficulty of completing the graph at the current step, graph generation is routed to either a fast~(weaker) or a slow~(stronger) model. fast and slow models have identical architectures, but vary in the number of parameters and consequently the strength. Experiments on real-world graphs show that ours can successfully generate graphs similar to those generated by a single large model in a fraction of time.
Dynamics of information flow and engaging power of narratives in the polarised debate on vaccines
Jul 25, 2022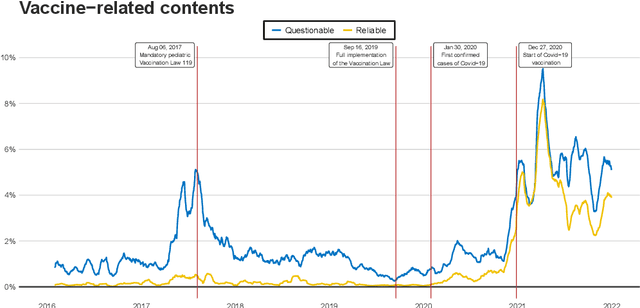
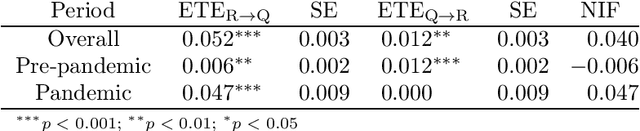
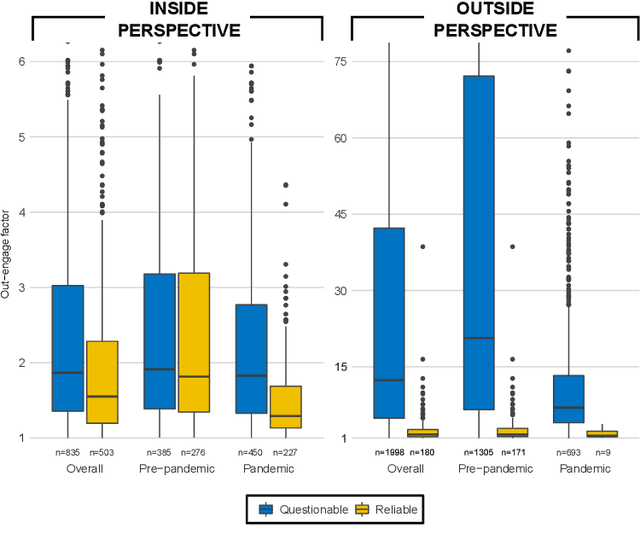
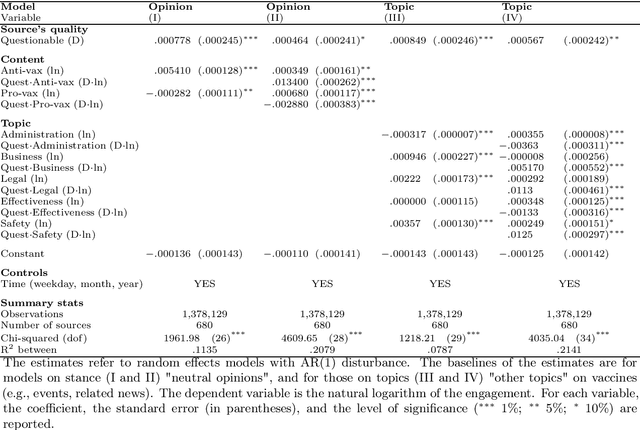
In this study we approach the complexity of the vaccine debate from a new and comprehensive perspective. Focusing on the Italian context, we examine almost all the online information produced in the 2016-2021 timeframe by both sources that have a reputation for misinformation and those that do not. Although reliable sources can rely on larger newsrooms and cover more news than misinformation ones, the transfer entropy analysis of the corresponding time series reveals that the former have not always informationally dominated the latter on the vaccine subject. Indeed, the pre-pandemic period sees misinformation establish itself as leader of the process, even in causal terms, and gain dramatically more user engagement than news from reliable sources. Despite this information gap was filled during the Covid-19 outbreak, the newfound leading role of reliable sources as drivers of the information ecosystem has only partially had a beneficial effect in reducing user engagement with misinformation on vaccines. Our results indeed show that, except for effectiveness of vaccination, reliable sources have never adequately countered the anti-vax narrative, specially in the pre-pandemic period, thus contributing to exacerbate science denial and belief in conspiracy theories. At the same time, however, they confirm the efficacy of assiduously proposing a convincing counter-narrative to misinformation spread. Indeed, effectiveness of vaccination turns out to be the least engaging topic discussed by misinformation during the pandemic period, when compared to other polarising arguments such as safety concerns, legal issues and vaccine business. By highlighting the strengths and weaknesses of institutional and mainstream communication, our findings can be a valuable asset for improving and better targeting campaigns against misinformation on vaccines.
Modeling Network-level Traffic Flow Transitions on Sparse Data
Aug 13, 2022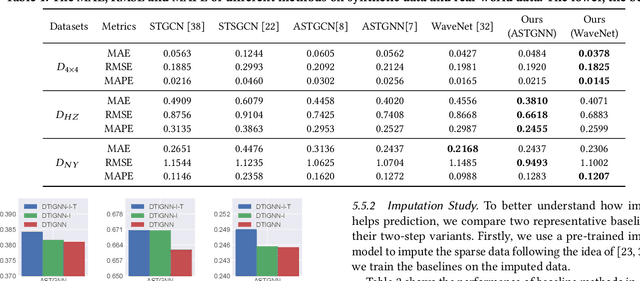
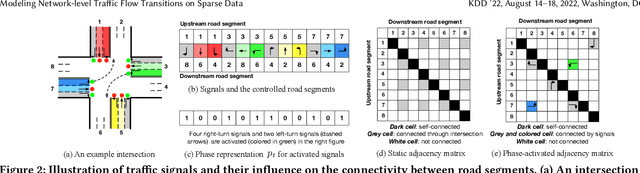
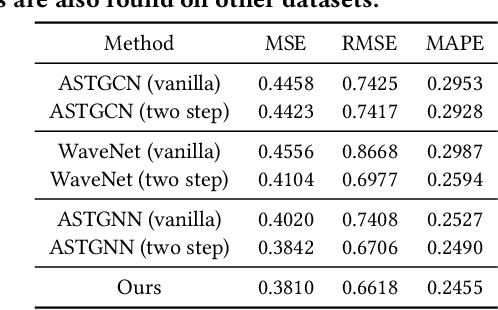
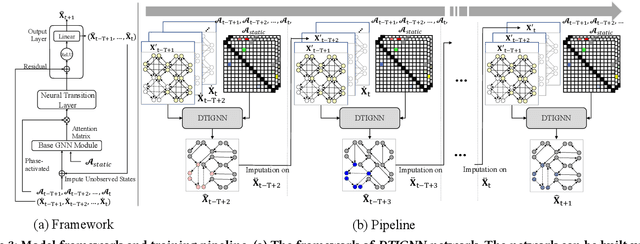
Modeling how network-level traffic flow changes in the urban environment is useful for decision-making in transportation, public safety and urban planning. The traffic flow system can be viewed as a dynamic process that transits between states (e.g., traffic volumes on each road segment) over time. In the real-world traffic system with traffic operation actions like traffic signal control or reversible lane changing, the system's state is influenced by both the historical states and the actions of traffic operations. In this paper, we consider the problem of modeling network-level traffic flow under a real-world setting, where the available data is sparse (i.e., only part of the traffic system is observed). We present DTIGNN, an approach that can predict network-level traffic flows from sparse data. DTIGNN models the traffic system as a dynamic graph influenced by traffic signals, learns the transition models grounded by fundamental transition equations from transportation, and predicts future traffic states with imputation in the process. Through comprehensive experiments, we demonstrate that our method outperforms state-of-the-art methods and can better support decision-making in transportation.
Area Coverage with Multiple Capacity-Constrained Robots
Aug 21, 2022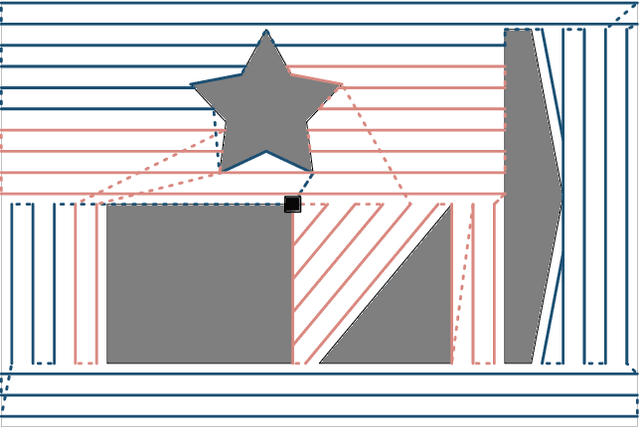
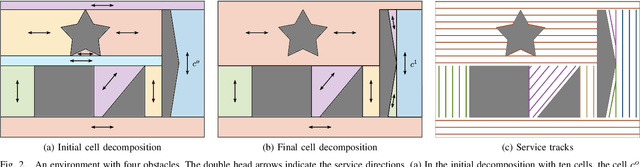
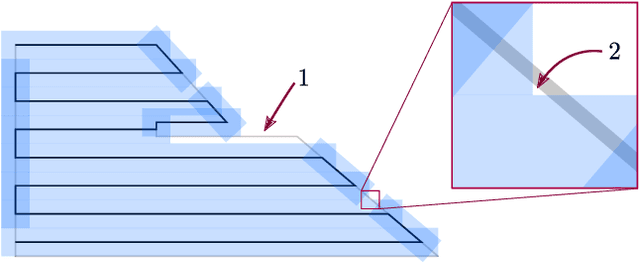
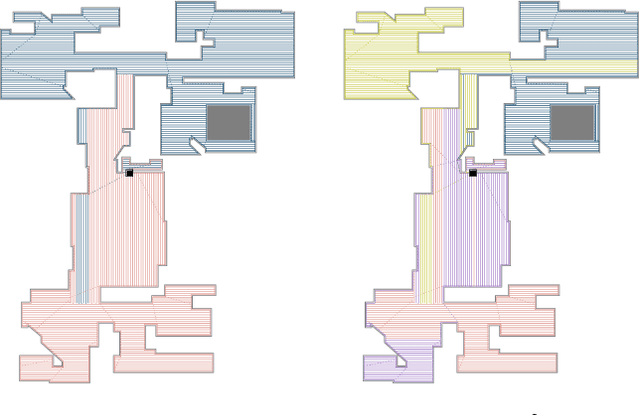
The area coverage problem is the task of efficiently servicing a given two-dimensional surface using sensors mounted on robots such as unmanned aerial vehicles (UAVs) and unmanned ground vehicles (UGVs). We present a novel formulation for generating coverage routes for multiple capacity-constrained robots, where capacity can be specified in terms of battery life or flight time. Traversing the environment incurs demands on the robot resources, which have capacity limits. The central aspect of our approach is transforming the area coverage problem into a line coverage problem (i.e., coverage of linear features), and then generating routes that minimize the total cost of travel while respecting the capacity constraints. We define two modes of travel: (1) servicing and (2) deadheading, which correspond to whether a robot is performing task-specific actions or not. Our formulation allows separate and asymmetric travel costs and demands for the two modes. Furthermore, the cells computed from cell decomposition, aimed at minimizing the number of turns, are not required to be monotone polygons. We develop new procedures for cell decomposition and generation of service tracks that can handle non-monotone polygons with or without holes. We establish the efficacy of our algorithm on a ground robot dataset with 25 indoor environments and an aerial robot dataset with 300 outdoor environments. The algorithm generates solutions whose costs are 10% lower on average than state-of-the-art methods. We additionally demonstrate our algorithm in experiments with UAVs.
A data-driven modular architecture with denoising autoencoders for health indicator construction in a manufacturing process
Aug 10, 2022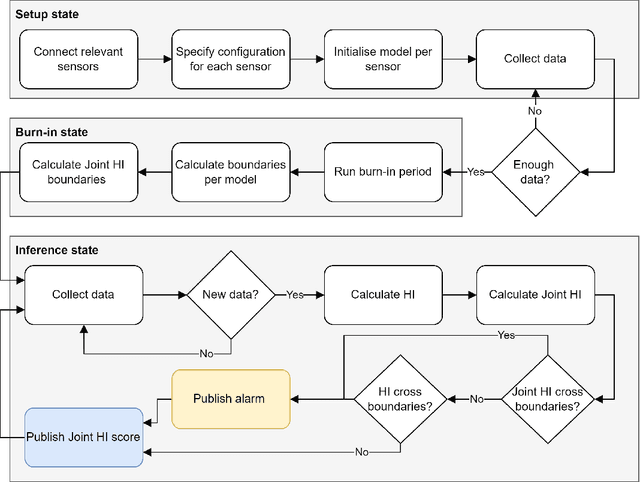
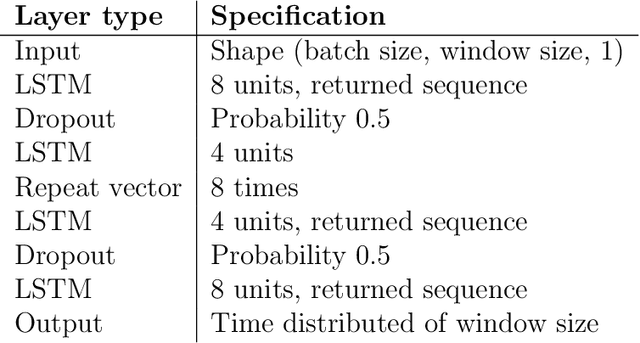
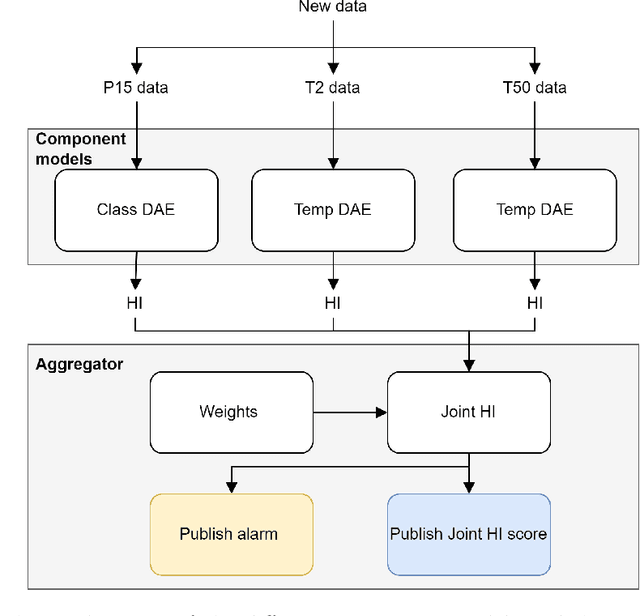

Within the field of prognostics and health management (PHM), health indicators (HI) can be used to aid the production and, e.g. schedule maintenance and avoid failures. However, HI is often engineered to a specific process and typically requires large amounts of historical data for set-up. This is especially a challenge for SMEs, which often lack sufficient resources and knowledge to benefit from PHM. In this paper, we propose ModularHI, a modular approach in the construction of HI for a system without historical data. With ModularHI, the operator chooses which sensor inputs are available, and then ModularHI will compute a baseline model based on data collected during a burn-in state. This baseline model will then be used to detect if the system starts to degrade over time. We test the ModularHI on two open datasets, CMAPSS and N-CMAPSS. Results from the former dataset showcase our system's ability to detect degradation, while results from the latter point to directions for further research within the area. The results shows that our novel approach is able to detect system degradation without historical data.
Hilti-Oxford Dataset: A Millimetre-Accurate Benchmark for Simultaneous Localization and Mapping
Aug 21, 2022



Simultaneous Localization and Mapping (SLAM) is being deployed in real-world applications, however many state-of-the-art solutions still struggle in many common scenarios. A key necessity in progressing SLAM research is the availability of high-quality datasets and fair and transparent benchmarking. To this end, we have created the Hilti-Oxford Dataset, to push state-of-the-art SLAM systems to their limits. The dataset has a variety of challenges ranging from sparse and regular construction sites to a 17th century neoclassical building with fine details and curved surfaces. To encourage multi-modal SLAM approaches, we designed a data collection platform featuring a lidar, five cameras, and an IMU (Inertial Measurement Unit). With the goal of benchmarking SLAM algorithms for tasks where accuracy and robustness are paramount, we implemented a novel ground truth collection method that enables our dataset to accurately measure SLAM pose errors with millimeter accuracy. To further ensure accuracy, the extrinsics of our platform were verified with a micrometer-accurate scanner, and temporal calibration was managed online using hardware time synchronization. The multi-modality and diversity of our dataset attracted a large field of academic and industrial researchers to enter the second edition of the Hilti SLAM challenge, which concluded in June 2022. The results of the challenge show that while the top three teams could achieve accuracy of 2cm or better for some sequences, the performance dropped off in more difficult sequences.
Using Twitter Data to Understand Public Perceptions of Approved versus Off-label Use for COVID-19-related Medications
Jun 29, 2022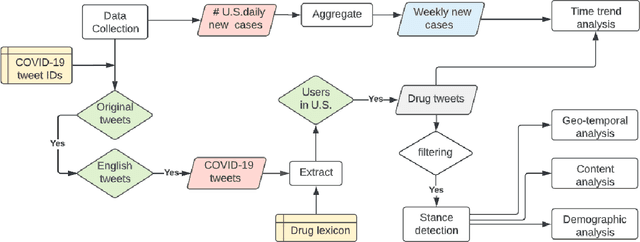

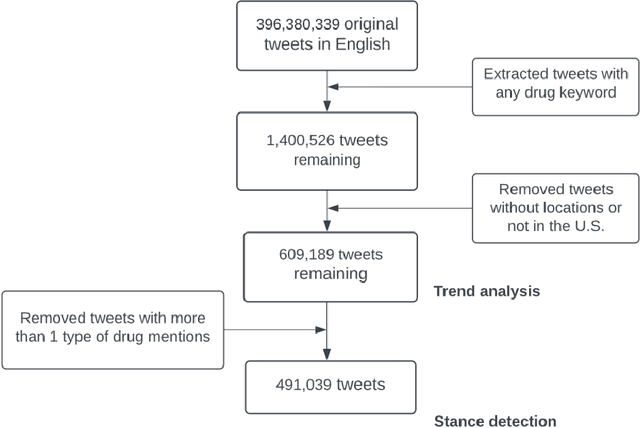
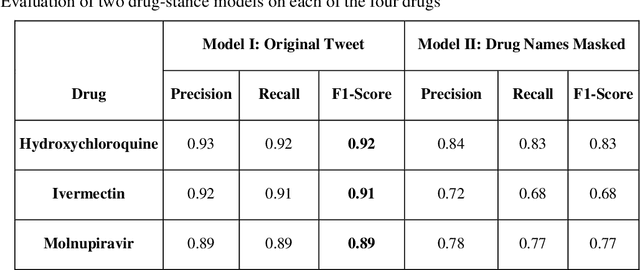
Understanding public discourse on emergency use of unproven therapeutics is essential to monitor safe use and combat misinformation. We developed a natural language processing (NLP)-based pipeline to understand public perceptions of and stances on COVID-19-related drugs on Twitter across time. This retrospective study included 609,189 US-based tweets between January 29th, 2020 and November 30th, 2021 on four drugs that gained wide public attention during the COVID-19 pandemic: 1) Hydroxychloroquine and Ivermectin, drug therapies with anecdotal evidence; and 2) Molnupiravir and Remdesivir, FDA-approved treatment options for eligible patients. Time-trend analysis was used to understand the popularity and related events. Content and demographic analyses were conducted to explore potential rationales of people's stances on each drug. Time-trend analysis revealed that Hydroxychloroquine and Ivermectin received much more discussion than Molnupiravir and Remdesivir, particularly during COVID-19 surges. Hydroxychloroquine and Ivermectin were highly politicized, related to conspiracy theories, hearsay, celebrity effects, etc. The distribution of stance between the two major US political parties was significantly different (p<0.001); Republicans were much more likely to support Hydroxychloroquine (+55%) and Ivermectin (+30%) than Democrats. People with healthcare backgrounds tended to oppose Hydroxychloroquine (+7%) more than the general population; in contrast, the general population was more likely to support Ivermectin (+14%). We make all the data, code, and models available at https://github.com/ningkko/COVID-drug.
* This is a preliminary version. For full paper please refer to JAMIA
A Simple Self-calibration Method for The Internal Time Synchronization of MEMS LiDAR
Sep 26, 2021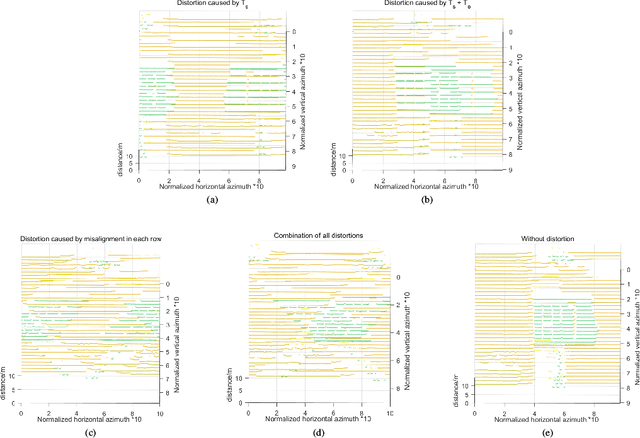
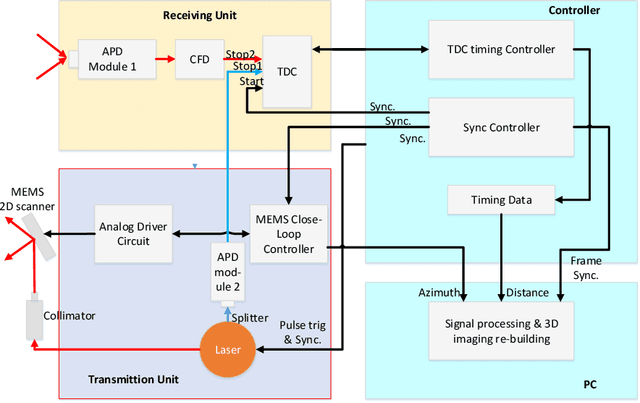
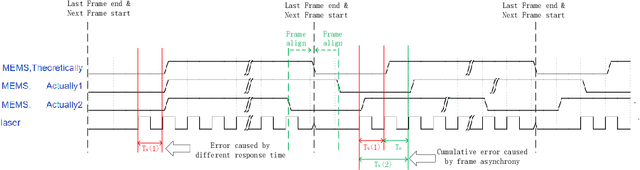
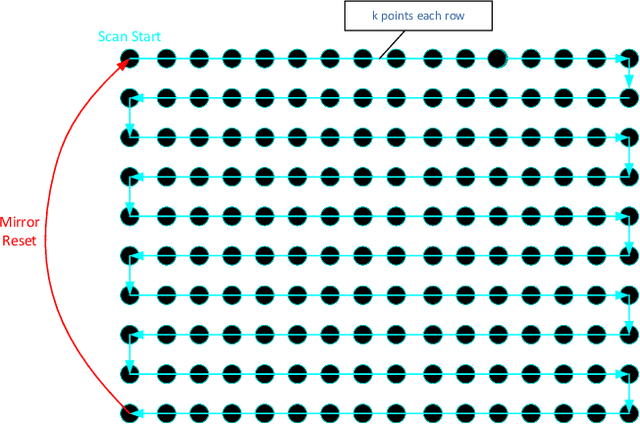
This paper proposes a simple self-calibration method for the internal time synchronization of MEMS(Micro-electromechanical systems) LiDAR during research and development. Firstly, we introduced the problem of internal time misalignment in MEMS lidar. Then, a robust Minimum Vertical Gradient(MVG) prior is proposed to calibrate the time difference between the laser and MEMS mirror, which can be calculated automatically without any artificial participation or specially designed cooperation target. Finally, actual experiments on MEMS LiDARs are implemented to demonstrate the effectiveness of the proposed method. It should be noted that the calibration can be implemented in a simple laboratory environment without any ranging equipment and artificial participation, which greatly accelerate the progress of research and development in practical applications.
A Comparison of Reinforcement Learning Frameworks for Software Testing Tasks
Aug 25, 2022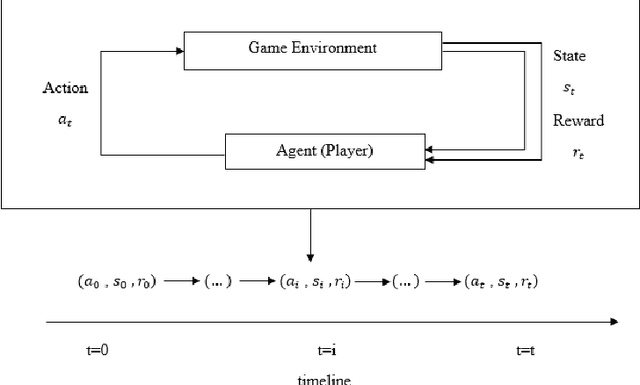
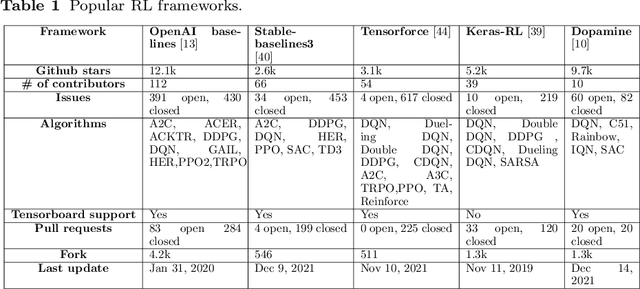
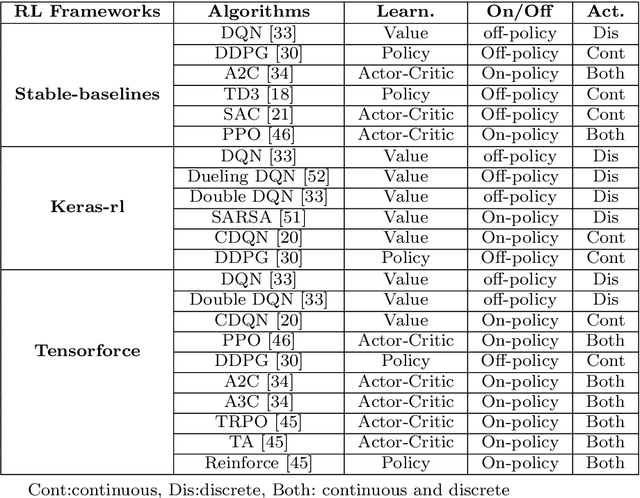
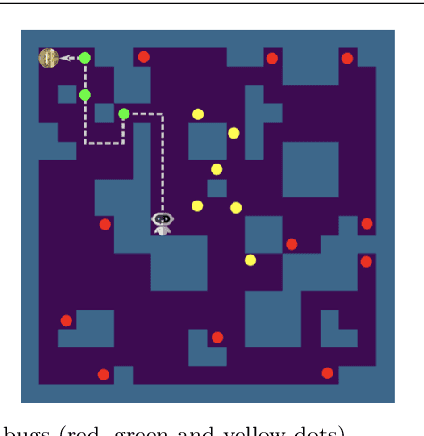
Software testing activities aim to find the possible defects of a software product and ensure that the product meets its expected requirements. Some software testing approached are lacking automation or are partly automated which increases the testing time and overall software testing costs. Recently, Reinforcement Learning (RL) has been successfully employed in complex testing tasks such as game testing, regression testing, and test case prioritization to automate the process and provide continuous adaptation. Practitioners can employ RL by implementing from scratch an RL algorithm or use an RL framework. Developers have widely used these frameworks to solve problems in various domains including software testing. However, to the best of our knowledge, there is no study that empirically evaluates the effectiveness and performance of pre-implemented algorithms in RL frameworks. In this paper, we empirically investigate the applications of carefully selected RL algorithms on two important software testing tasks: test case prioritization in the context of Continuous Integration (CI) and game testing. For the game testing task, we conduct experiments on a simple game and use RL algorithms to explore the game to detect bugs. Results show that some of the selected RL frameworks such as Tensorforce outperform recent approaches in the literature. To prioritize test cases, we run experiments on a CI environment where RL algorithms from different frameworks are used to rank the test cases. Our results show that the performance difference between pre-implemented algorithms in some cases is considerable, motivating further investigation. Moreover, empirical evaluations on some benchmark problems are recommended for researchers looking to select RL frameworks, to make sure that RL algorithms perform as intended.