 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Semi-supervised Learning with Deterministic Labeling and Large Margin Projection
Aug 17, 2022
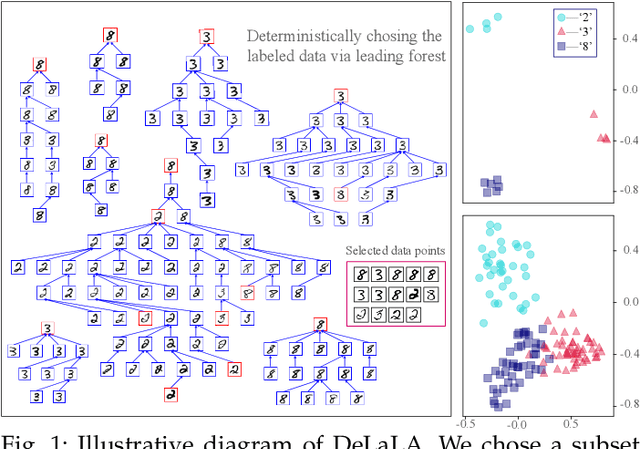
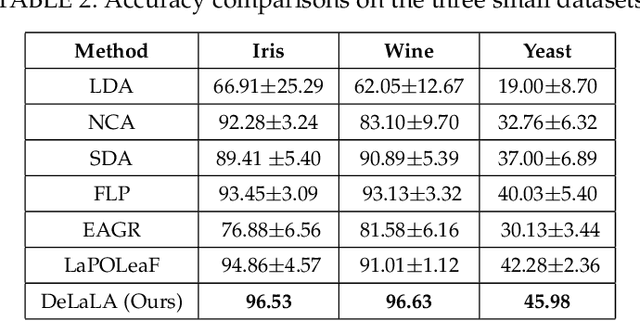
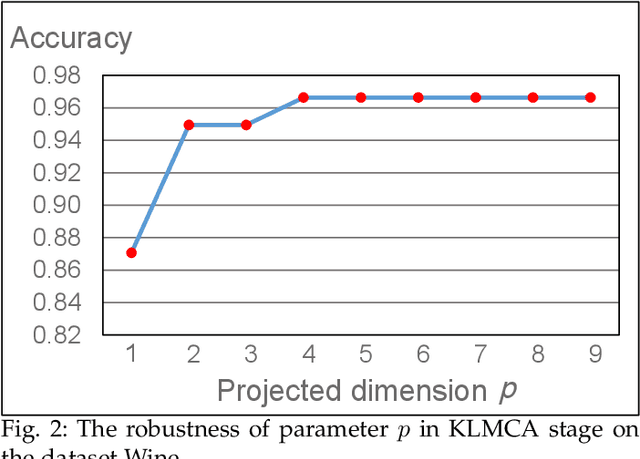
The centrality and diversity of the labeled data are very influential to the performance of semi-supervised learning (SSL), but most SSL models select the labeled data randomly. How to guarantee the centrality and diversity of the labeled data has so far received little research attention. Optimal leading forest (OLF) has been observed to have the advantage of revealing the difference evolution within a class when it was utilized to develop an SSL model. Our key intuition of this study is to learn a kernelized large margin metric for a small amount of most stable and most divergent data that are recognized based on the OLF structure. An optimization problem is formulated to achieve this goal. Also with OLF the multiple local metrics learning is facilitated to address multi-modal and mix-modal problem in SSL. Attribute to this novel design, the accuracy and performance stableness of the SSL model based on OLF is significantly improved compared with its baseline methods without sacrificing much efficiency. The experimental studies have shown that the proposed method achieved encouraging accuracy and running time when compared to the state-of-the-art graph SSL methods. Code has been made available at https://github.com/alanxuji/DeLaLA.
Dimension of Activity in Random Neural Networks
Aug 07, 2022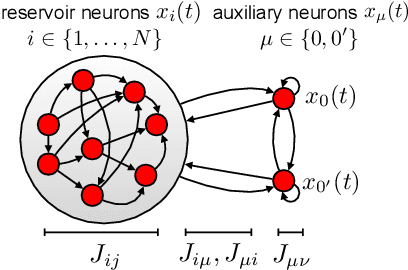
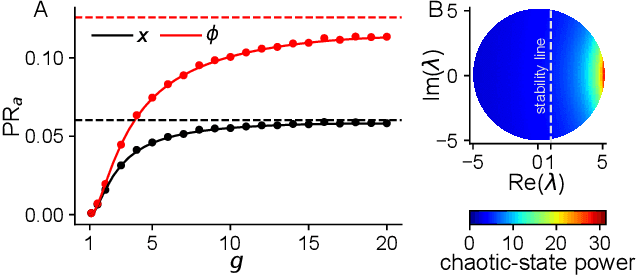
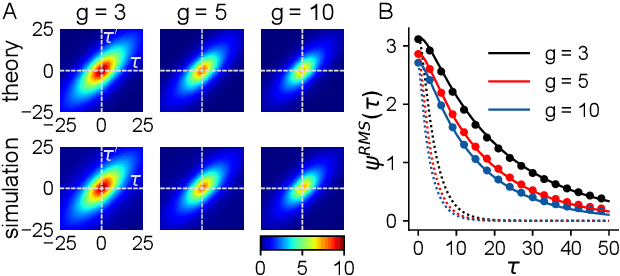
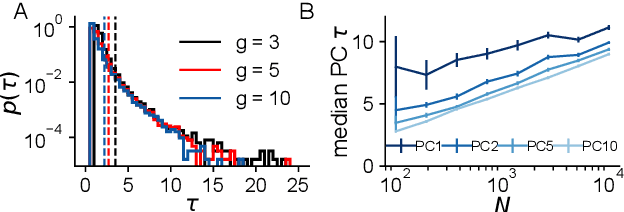
Neural networks are high-dimensional nonlinear dynamical systems that process information through the coordinated activity of many interconnected units. Understanding how biological and machine-learning networks function and learn requires knowledge of the structure of this coordinated activity, information contained in cross-covariances between units. Although dynamical mean field theory (DMFT) has elucidated several features of random neural networks -- in particular, that they can generate chaotic activity -- existing DMFT approaches do not support the calculation of cross-covariances. We solve this longstanding problem by extending the DMFT approach via a two-site cavity method. This reveals, for the first time, several spatial and temporal features of activity coordination, including the effective dimension, defined as the participation ratio of the spectrum of the covariance matrix. Our results provide a general analytical framework for studying the structure of collective activity in random neural networks and, more broadly, in high-dimensional nonlinear dynamical systems with quenched disorder.
Hierarchical Motion Planning Framework for Cooperative Transportation of Multiple Mobile Manipulators
Aug 17, 2022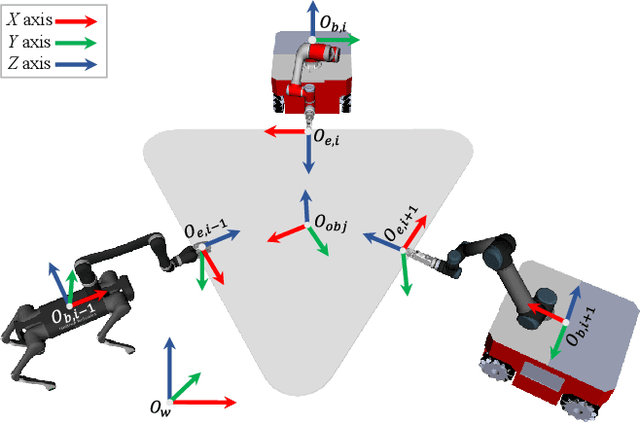



Multiple mobile manipulators show superiority in the tasks requiring mobility and dexterity compared with a single robot, especially when manipulating/transporting bulky objects. When the object and the manipulators are rigidly connected, closed-chain will form and the motion of the whole system will be restricted onto a lower-dimensional manifold. However, current research on multi-robot motion planning did not fully consider the formation of the whole system, the redundancy of the mobile manipulator and obstacles in the environment, which make the tasks challenging. Therefore, this paper proposes a hierarchical framework to efficiently solve the above challenges, where the centralized layer plans the object's motion offline and the decentralized layer independently explores the redundancy of each robot in real-time. In addition, closed-chain, obstacle-avoidance and the lower bound of the formation constraints are guaranteed in the centralized layer, which cannot be achieved simultaneously by other planners. Moreover, capability map, which represents the distribution of the formation constraint, is applied to speed up the two layers. Both simulation and experimental results show that the proposed framework outperforms the benchmark planners significantly. The system could bypass or cross obstacles in cluttered environments, and the framework can be applied to different numbers of heterogeneous mobile manipulators.
Minkowski Tracker: A Sparse Spatio-Temporal R-CNN for Joint Object Detection and Tracking
Aug 26, 2022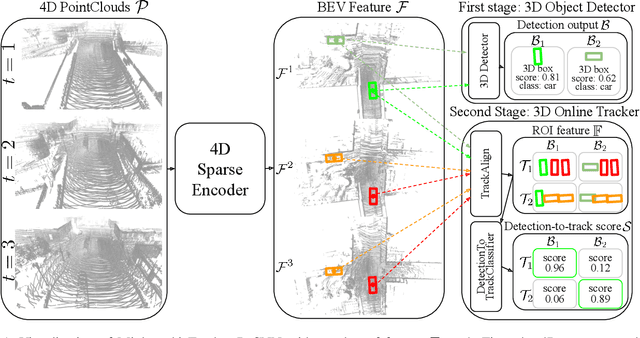
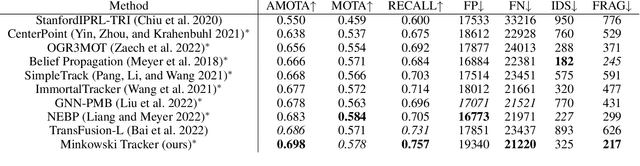
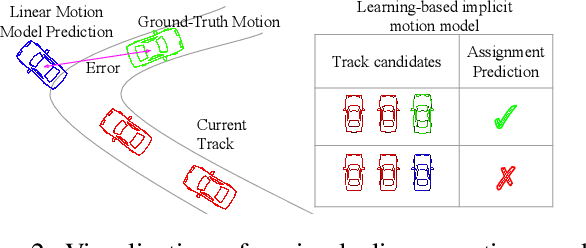
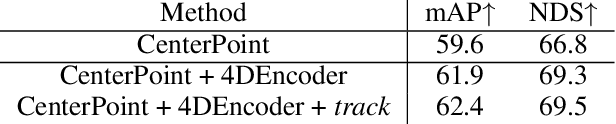
Recent research in multi-task learning reveals the benefit of solving related problems in a single neural network. 3D object detection and multi-object tracking (MOT) are two heavily intertwined problems predicting and associating an object instance location across time. However, most previous works in 3D MOT treat the detector as a preceding separated pipeline, disjointly taking the output of the detector as an input to the tracker. In this work, we present Minkowski Tracker, a sparse spatio-temporal R-CNN that jointly solves object detection and tracking. Inspired by region-based CNN (R-CNN), we propose to solve tracking as a second stage of the object detector R-CNN that predicts assignment probability to tracks. First, Minkowski Tracker takes 4D point clouds as input to generate a spatio-temporal Bird's-eye-view (BEV) feature map through a 4D sparse convolutional encoder network. Then, our proposed TrackAlign aggregates the track region-of-interest (ROI) features from the BEV features. Finally, Minkowski Tracker updates the track and its confidence score based on the detection-to-track match probability predicted from the ROI features. We show in large-scale experiments that the overall performance gain of our method is due to four factors: 1. The temporal reasoning of the 4D encoder improves the detection performance 2. The multi-task learning of object detection and MOT jointly enhances each other 3. The detection-to-track match score learns implicit motion model to enhance track assignment 4. The detection-to-track match score improves the quality of the track confidence score. As a result, Minkowski Tracker achieved the state-of-the-art performance on Nuscenes dataset tracking task without hand-designed motion models.
Recurrent Neural Network-based Anti-jamming Framework for Defense Against Multiple Jamming Policies
Aug 19, 2022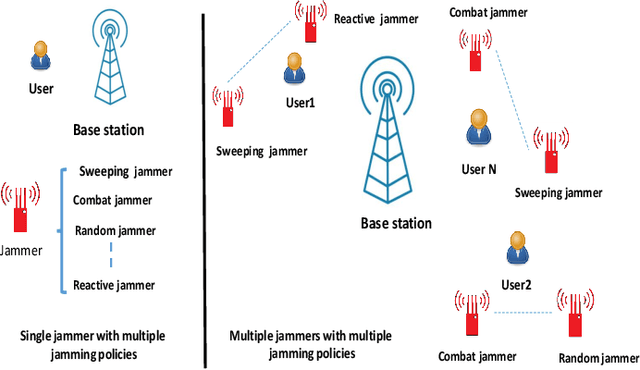
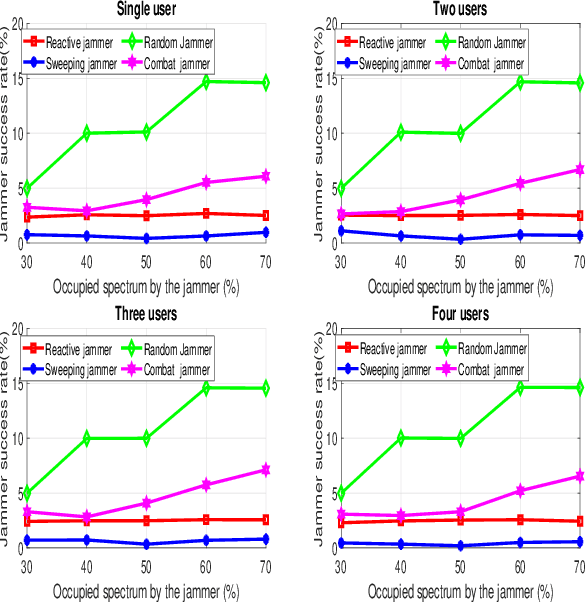
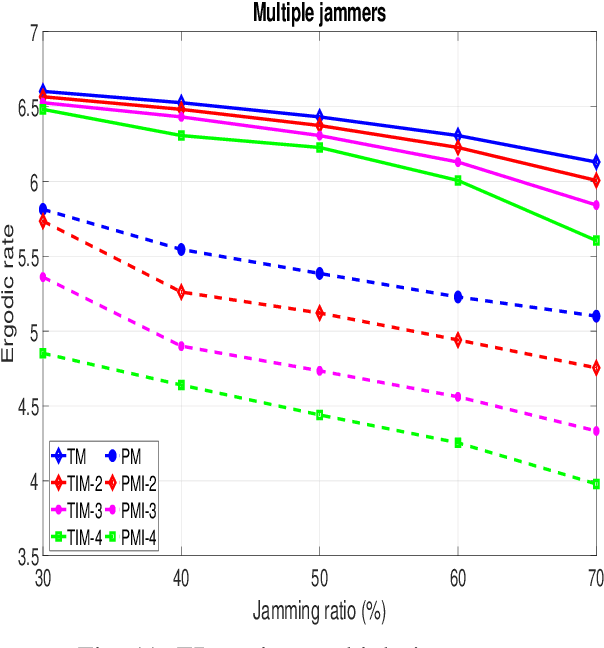
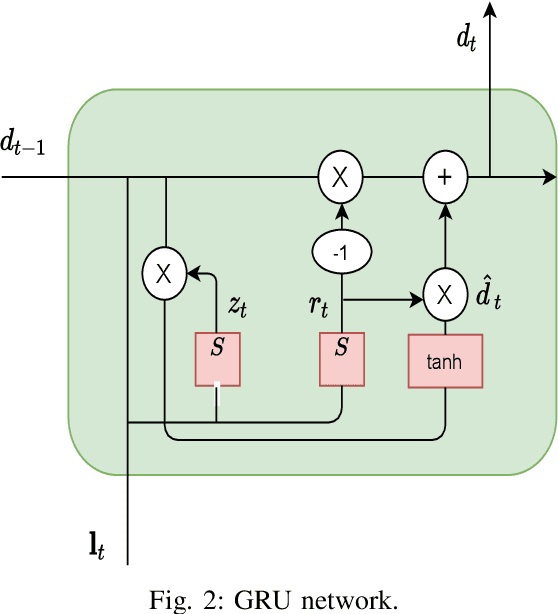
Conventional anti-jamming methods mainly focus on preventing single jammer attacks with an invariant jamming policy or jamming attacks from multiple jammers with similar jamming policies. These anti-jamming methods are ineffective against a single jammer following several different jamming policies or multiple jammers with distinct policies. Therefore, this paper proposes an anti-jamming method that can adapt its policy to the current jamming attack. Moreover, for the multiple jammers scenario, an anti-jamming method that estimates the future occupied channels using the jammers' occupied channels in previous time slots is proposed. In both single and multiple jammers scenarios, the interaction between the users and jammers is modeled using recurrent neural networks (RNN)s. The performance of the proposed anti-jamming methods is evaluated by calculating the users' successful transmission rate (STR) and ergodic rate (ER), and compared to a baseline based on Q-learning (DQL). Simulation results show that for the single jammer scenario, all the considered jamming policies are perfectly detected and high STR and ER are maintained. Moreover, when 70 % of the spectrum is under jamming attacks from multiple jammers, the proposed method achieves an STR and ER greater than 75 % and 80 %, respectively. These values rise to 90 % when 30 % of the spectrum is under jamming attacks. In addition, the proposed anti-jamming methods significantly outperform the DQL method for all the considered cases and jamming scenarios.
Fast Auto-Differentiable Digitally Reconstructed Radiographs for Solving Inverse Problems in Intraoperative Imaging
Aug 26, 2022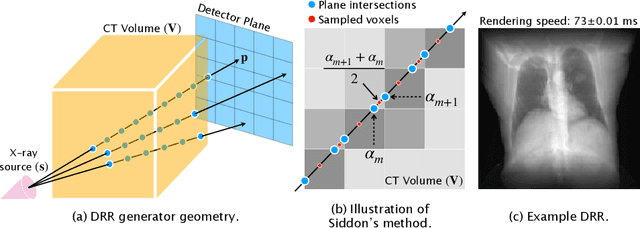
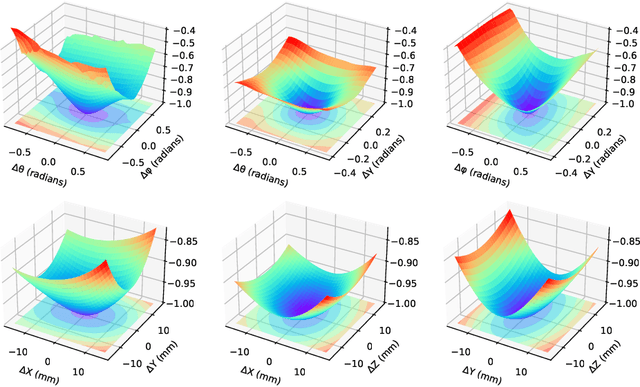
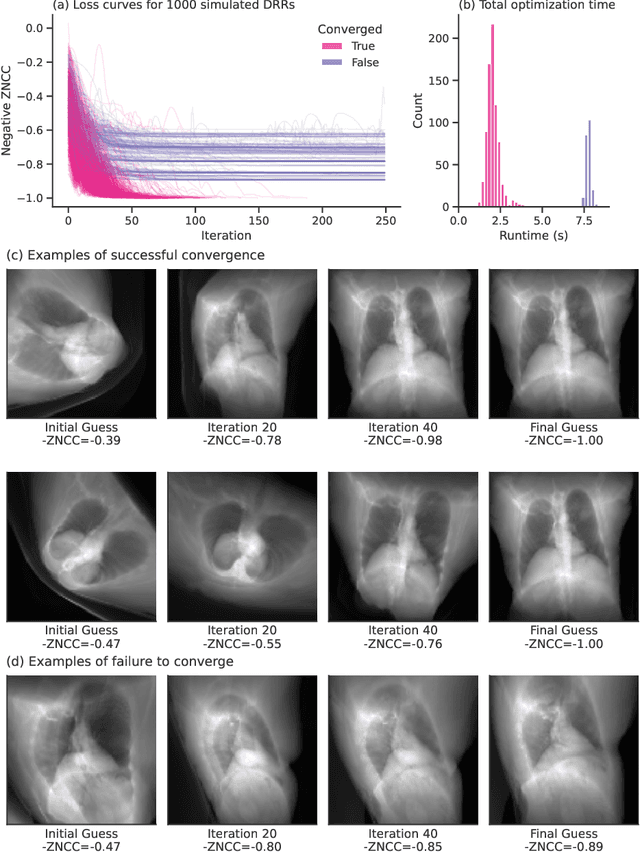
The use of digitally reconstructed radiographs (DRRs) to solve inverse problems such as slice-to-volume registration and 3D reconstruction is well-studied in preoperative settings. In intraoperative imaging, the utility of DRRs is limited by the challenges in generating them in real-time and supporting optimization procedures that rely on repeated DRR synthesis. While immense progress has been made in accelerating the generation of DRRs through algorithmic refinements and GPU implementations, DRR-based optimization remains slow because most DRR generators do not offer a straightforward way to obtain gradients with respect to the imaging parameters. To make DRRs interoperable with gradient-based optimization and deep learning frameworks, we have reformulated Siddon's method, the most popular ray-tracing algorithm used in DRR generation, as a series of vectorized tensor operations. We implemented this vectorized version of Siddon's method in PyTorch, taking advantage of the library's strong automatic differentiation engine to make this DRR generator fully differentiable with respect to its parameters. Additionally, using GPU-accelerated tensor computation enables our vectorized implementation to achieve rendering speeds equivalent to state-of-the-art DRR generators implemented in CUDA and C++. We illustrate the resulting method in the context of slice-to-volume registration. Moreover, our simulations suggest that the loss landscapes for the slice-to-volume registration problem are convex in the neighborhood of the optimal solution, and gradient-based registration promises a much faster solution than prevailing gradient-free optimization strategies. The proposed DRR generator enables fast computer vision algorithms to support image guidance in minimally invasive procedures. Our implementation is publically available at https://github.com/v715/DiffDRR.
A Recursive Delay Estimation Algorithm for Linear Multivariable Systems with Time-varying Delays
Sep 06, 2021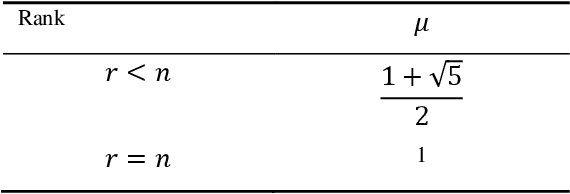
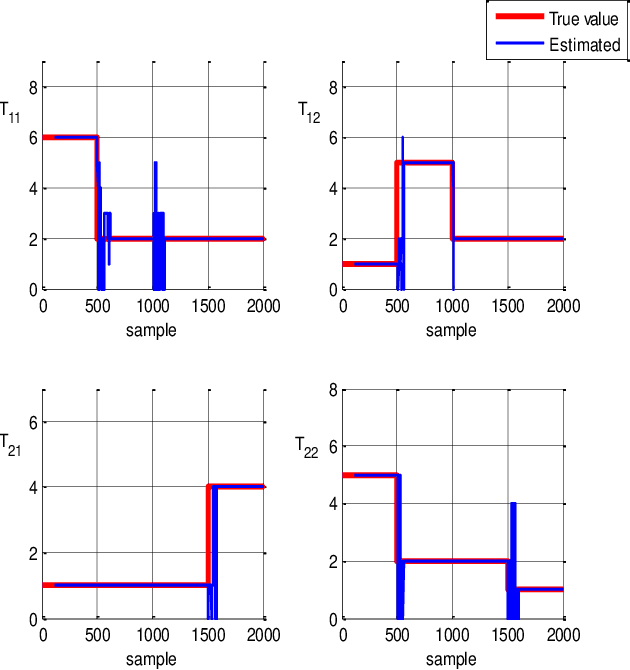
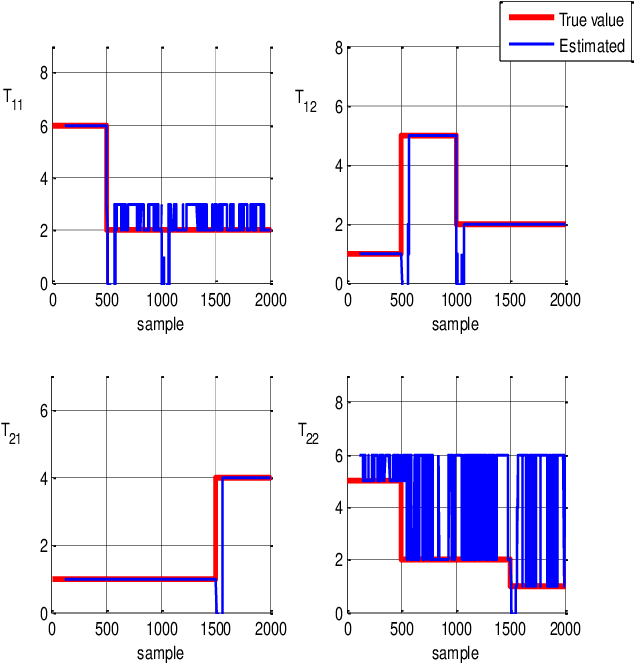
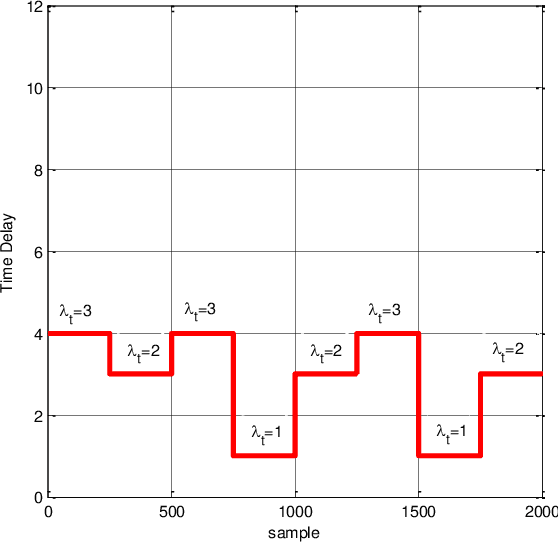
Time delay estimation plays a critical role in control, stabilization and state estimation of many practical system with time delay. In this paper, we propose a method to estimate delay for discrete time linear multiple-input multiple-output systems with time-varying input delays. This method is purposefully given for situations where only a limited amount of information is available for the system. Although, this approach is primarily developed in a deterministic framework, it can also be applied to noisy data under special circumstances. In addition, switched linear autoregressive models with exogenous inputs are introduced as possible applications of the presented algorithm provided that the switching frequencies are small. Finally, effectiveness of the algorithm is illustrated by two numerical examples.
Modelling Neighbor Relation in Joint Space-Time Graph for Video Correspondence Learning
Sep 28, 2021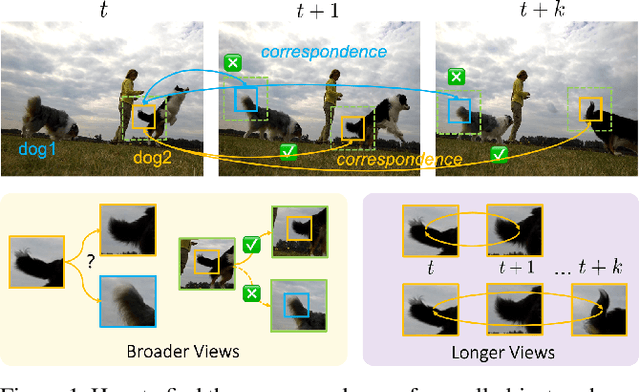
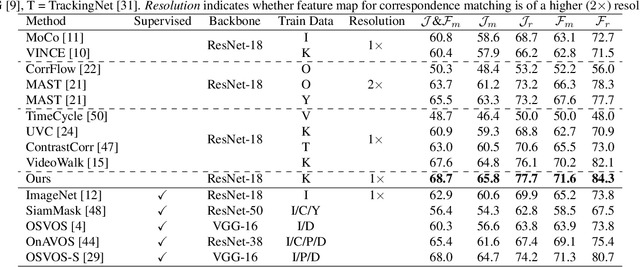
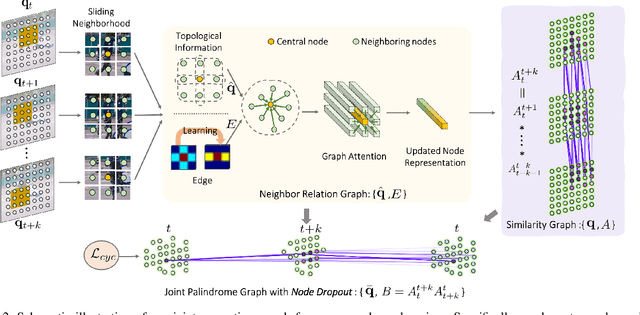
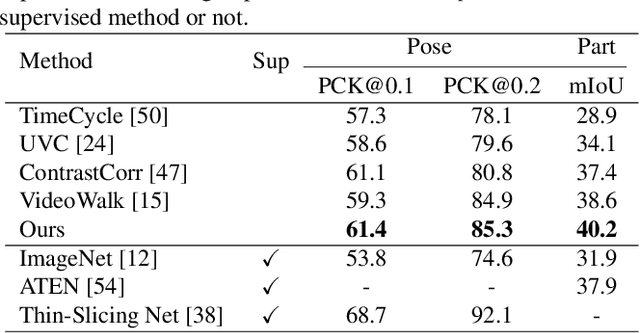
This paper presents a self-supervised method for learning reliable visual correspondence from unlabeled videos. We formulate the correspondence as finding paths in a joint space-time graph, where nodes are grid patches sampled from frames, and are linked by two types of edges: (i) neighbor relations that determine the aggregation strength from intra-frame neighbors in space, and (ii) similarity relations that indicate the transition probability of inter-frame paths across time. Leveraging the cycle-consistency in videos, our contrastive learning objective discriminates dynamic objects from both their neighboring views and temporal views. Compared with prior works, our approach actively explores the neighbor relations of central instances to learn a latent association between center-neighbor pairs (e.g., "hand -- arm") across time, thus improving the instance discrimination. Without fine-tuning, our learned representation outperforms the state-of-the-art self-supervised methods on a variety of visual tasks including video object propagation, part propagation, and pose keypoint tracking. Our self-supervised method also surpasses some fully supervised algorithms designed for the specific tasks.
Computing High-Quality Solutions for the Patient Admission Scheduling Problem using Evolutionary Diversity Optimisation
Jul 28, 2022

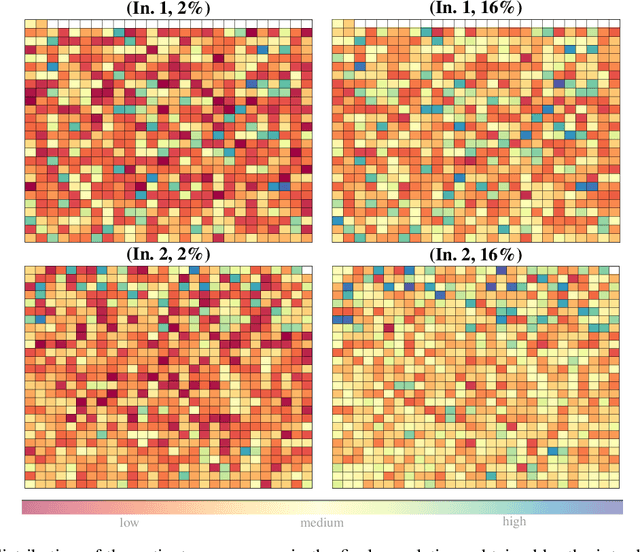
Diversification in a set of solutions has become a hot research topic in the evolutionary computation community. It has been proven beneficial for optimisation problems in several ways, such as computing a diverse set of high-quality solutions and obtaining robustness against imperfect modeling. For the first time in the literature, we adapt the evolutionary diversity optimisation for a real-world combinatorial problem, namely patient admission scheduling. We introduce an evolutionary algorithm to achieve structural diversity in a set of solutions subjected to the quality of each solution. We also introduce a mutation operator biased towards diversity maximisation. Finally, we demonstrate the importance of diversity for the aforementioned problem through a simulation.
Convolutional Ensembling based Few-Shot Defect Detection Technique
Aug 05, 2022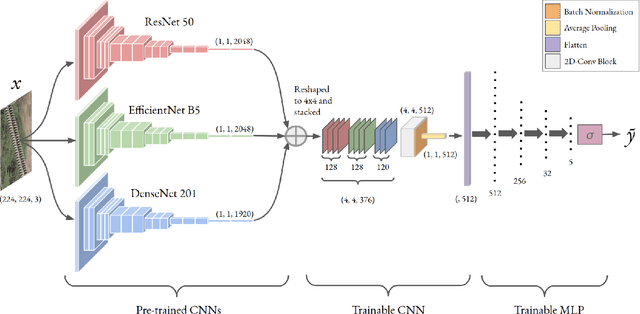
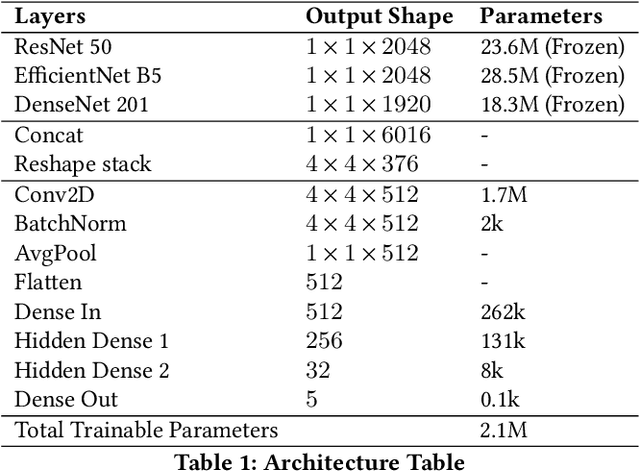
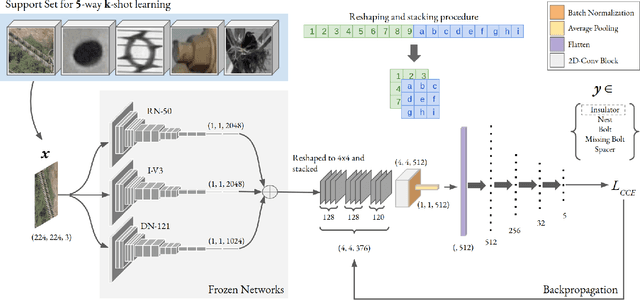
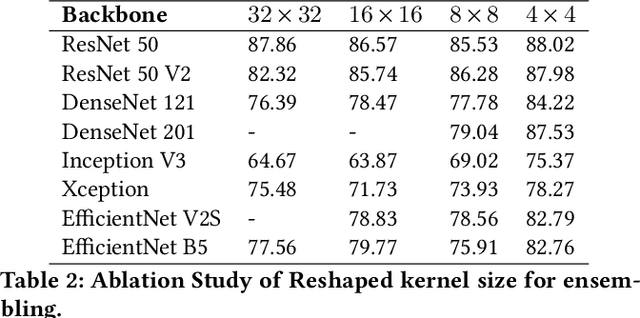
Over the past few years, there has been a significant improvement in the domain of few-shot learning. This learning paradigm has shown promising results for the challenging problem of anomaly detection, where the general task is to deal with heavy class imbalance. Our paper presents a new approach to few-shot classification, where we employ the knowledge-base of multiple pre-trained convolutional models that act as the backbone for our proposed few-shot framework. Our framework uses a novel ensembling technique for boosting the accuracy while drastically decreasing the total parameter count, thus paving the way for real-time implementation. We perform an extensive hyperparameter search using a power-line defect detection dataset and obtain an accuracy of 92.30% for the 5-way 5-shot task. Without further tuning, we evaluate our model on competing standards with the existing state-of-the-art methods and outperform them.