 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Practical Second-order Latent Factor Model via Distributed Particle Swarm Optimization
Aug 12, 2022



Latent Factor (LF) models are effective in representing high-dimension and sparse (HiDS) data via low-rank matrices approximation. Hessian-free (HF) optimization is an efficient method to utilizing second-order information of an LF model's objective function and it has been utilized to optimize second-order LF (SLF) model. However, the low-rank representation ability of a SLF model heavily relies on its multiple hyperparameters. Determining these hyperparameters is time-consuming and it largely reduces the practicability of an SLF model. To address this issue, a practical SLF (PSLF) model is proposed in this work. It realizes hyperparameter self-adaptation with a distributed particle swarm optimizer (DPSO), which is gradient-free and parallelized. Experiments on real HiDS data sets indicate that PSLF model has a competitive advantage over state-of-the-art models in data representation ability.
A Systematic Review and Replicability Study of BERT4Rec for Sequential Recommendation
Jul 15, 2022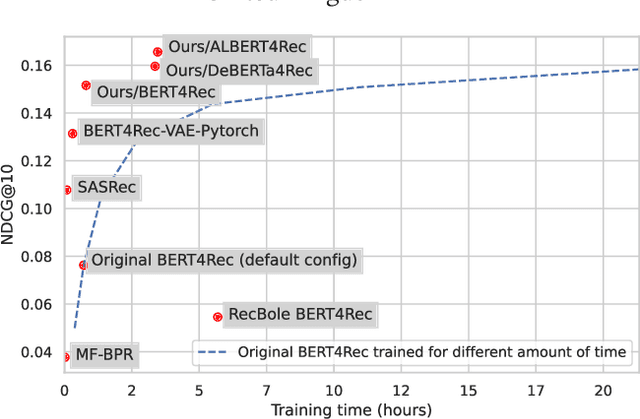
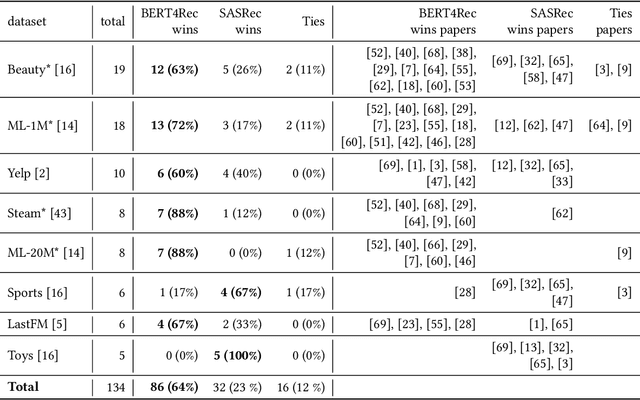
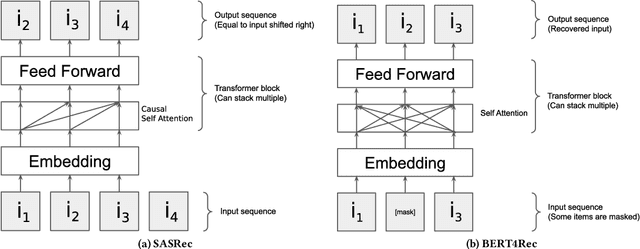

BERT4Rec is an effective model for sequential recommendation based on the Transformer architecture. In the original publication, BERT4Rec claimed superiority over other available sequential recommendation approaches (e.g. SASRec), and it is now frequently being used as a state-of-the art baseline for sequential recommendations. However, not all subsequent publications confirmed this result and proposed other models that were shown to outperform BERT4Rec in effectiveness. In this paper we systematically review all publications that compare BERT4Rec with another popular Transformer-based model, namely SASRec, and show that BERT4Rec results are not consistent within these publications. To understand the reasons behind this inconsistency, we analyse the available implementations of BERT4Rec and show that we fail to reproduce results of the original BERT4Rec publication when using their default configuration parameters. However, we are able to replicate the reported results with the original code if training for a much longer amount of time (up to 30x) compared to the default configuration. We also propose our own implementation of BERT4Rec based on the Hugging Face Transformers library, which we demonstrate replicates the originally reported results on 3 out 4 datasets, while requiring up to 95% less training time to converge. Overall, from our systematic review and detailed experiments, we conclude that BERT4Rec does indeed exhibit state-of-the-art effectiveness for sequential recommendation, but only when trained for a sufficient amount of time. Additionally, we show that our implementation can further benefit from adapting other Transformer architectures that are available in the Hugging Face Transformers library (e.g. using disentangled attention, as provided by DeBERTa, or larger hidden layer size cf. ALBERT).
Private Query Release via the Johnson-Lindenstrauss Transform
Aug 15, 2022We introduce a new method for releasing answers to statistical queries with differential privacy, based on the Johnson-Lindenstrauss lemma. The key idea is to randomly project the query answers to a lower dimensional space so that the distance between any two vectors of feasible query answers is preserved up to an additive error. Then we answer the projected queries using a simple noise-adding mechanism, and lift the answers up to the original dimension. Using this method, we give, for the first time, purely differentially private mechanisms with optimal worst case sample complexity under average error for answering a workload of $k$ queries over a universe of size $N$. As other applications, we give the first purely private efficient mechanisms with optimal sample complexity for computing the covariance of a bounded high-dimensional distribution, and for answering 2-way marginal queries. We also show that, up to the dependence on the error, a variant of our mechanism is nearly optimal for every given query workload.
Real-time Multi-Adaptive-Resolution-Surfel 6D LiDAR Odometry using Continuous-time Trajectory Optimization
May 05, 2021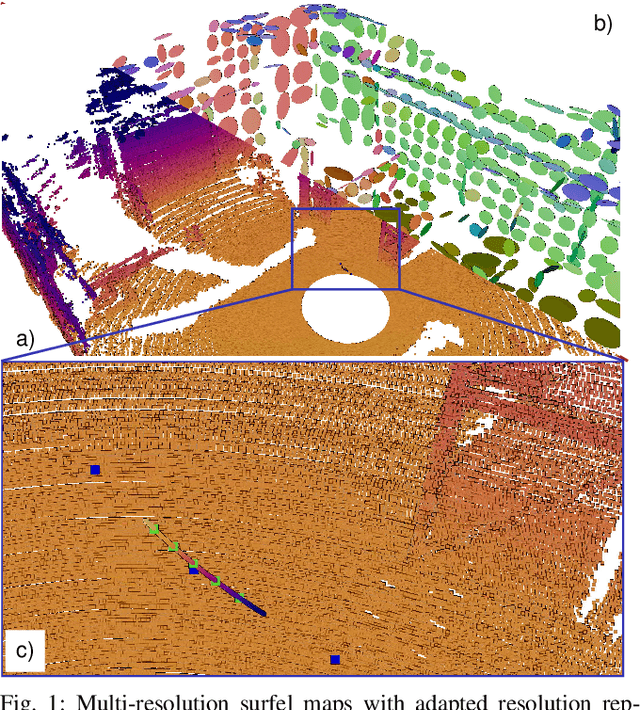
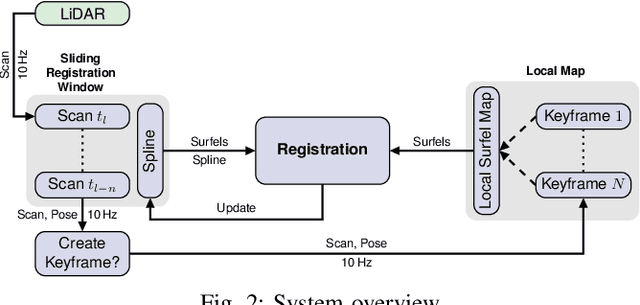
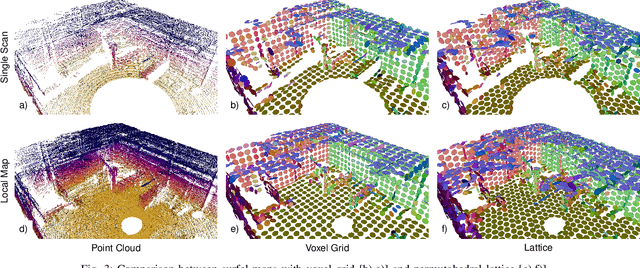
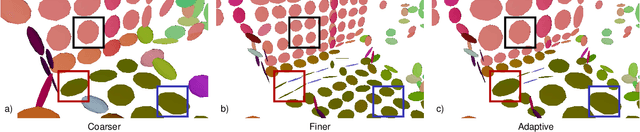
Simultaneous Localization and Mapping (SLAM) is an essential capability for autonomous robots, but due to high data rates of 3D LiDARs real-time SLAM is challenging. We propose a real-time method for 6D LiDAR odometry. Our approach combines a continuous-time B-Spline trajectory representation with a Gaussian Mixture Model (GMM) formulation to jointly align local multi-resolution surfel maps. Sparse voxel grids and permutohedral lattices ensure fast access to map surfels, and an adaptive resolution selection scheme effectively speeds up registration. A thorough experimental evaluation shows the performance of our approach on two datasets and during real-robot experiments.
A soluble walking model for a two-legged robot
Jul 12, 2022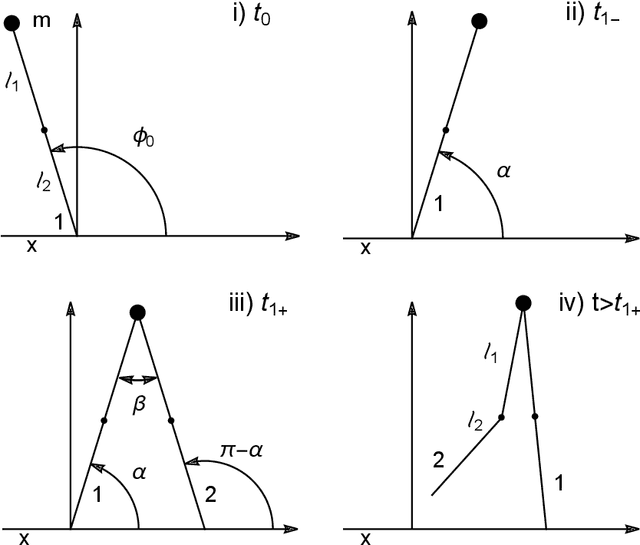
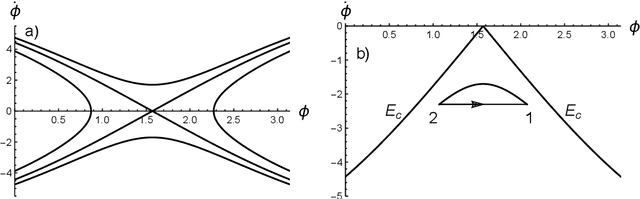
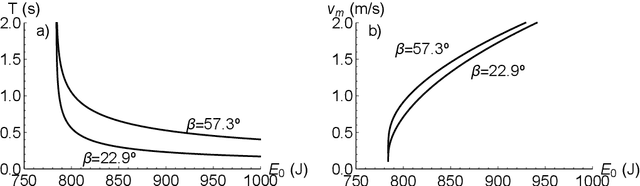
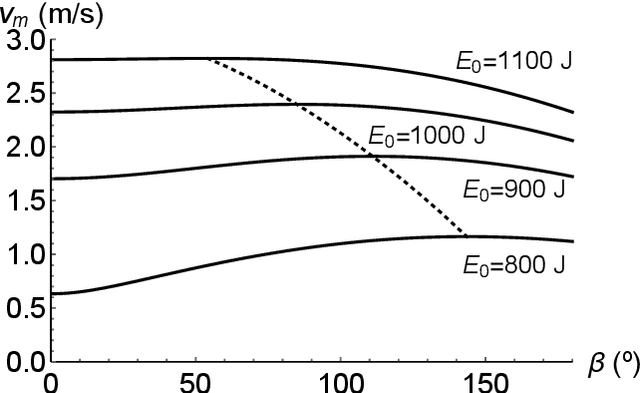
We present a soluble biped walking model based on an inverted pendulum with two massless articulated legs capable of walking on uneven floors and inclined planes. The stride of the two-legged robot results from the pendular motion of a standing leg and the articulated motion of a trailing leg. Gaiting is possible due to the alternating role of the legs, the standing and the trailing leg, and the conservation of energy of the pendular motion. The motion on uneven surfaces and inclined planes is possible by imposing the same maximal opening angle between the two legs in the transition between strides and the adaptability of the time of each stride. This model is soluble in closed form and is reversible in time, modelling different types of biped motion. Several optimisation results for the speed of gaiting as a function of the robot parameters have been derived.
Prior-Aware Synthetic Data to the Rescue: Animal Pose Estimation with Very Limited Real Data
Aug 30, 2022
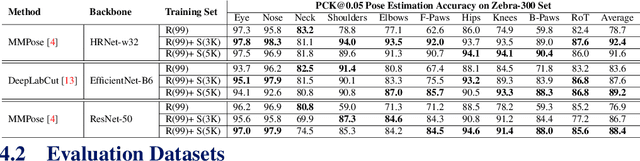
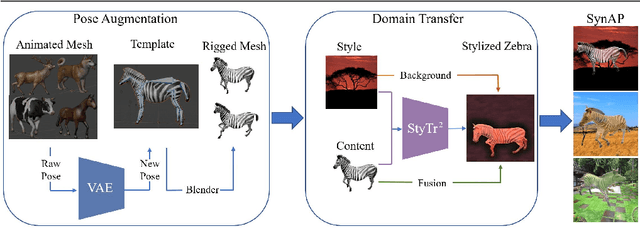
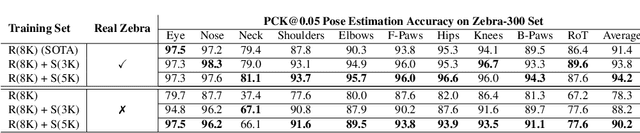
Accurately annotated image datasets are essential components for studying animal behaviors from their poses. Compared to the number of species we know and may exist, the existing labeled pose datasets cover only a small portion of them, while building comprehensive large-scale datasets is prohibitively expensive. Here, we present a very data efficient strategy targeted for pose estimation in quadrupeds that requires only a small amount of real images from the target animal. It is confirmed that fine-tuning a backbone network with pretrained weights on generic image datasets such as ImageNet can mitigate the high demand for target animal pose data and shorten the training time by learning the the prior knowledge of object segmentation and keypoint estimation in advance. However, when faced with serious data scarcity (i.e., $<10^2$ real images), the model performance stays unsatisfactory, particularly for limbs with considerable flexibility and several comparable parts. We therefore introduce a prior-aware synthetic animal data generation pipeline called PASyn to augment the animal pose data essential for robust pose estimation. PASyn generates a probabilistically-valid synthetic pose dataset, SynAP, through training a variational generative model on several animated 3D animal models. In addition, a style transfer strategy is utilized to blend the synthetic animal image into the real backgrounds. We evaluate the improvement made by our approach with three popular backbone networks and test their pose estimation accuracy on publicly available animal pose images as well as collected from real animals in a zoo.
Multi-Scale User Behavior Network for Entire Space Multi-Task Learning
Aug 03, 2022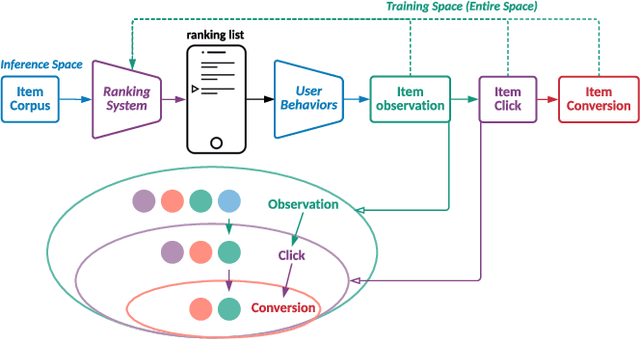

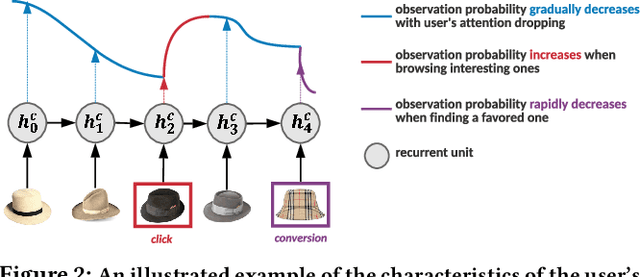
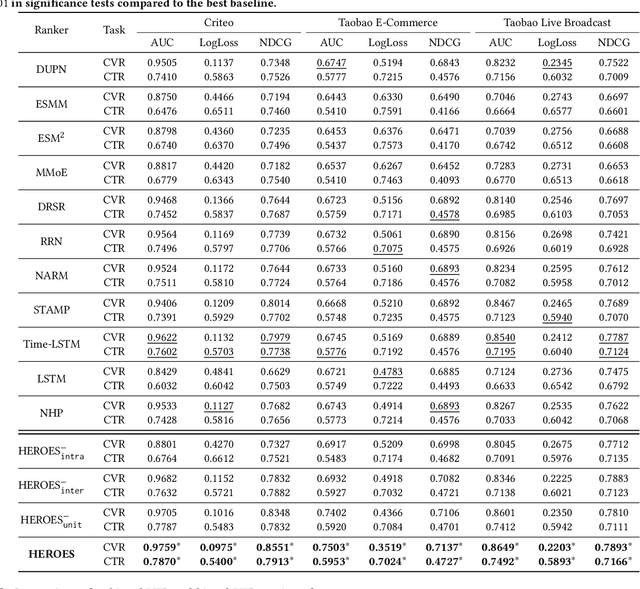
Modelling the user's multiple behaviors is an essential part of modern e-commerce, whose widely adopted application is to jointly optimize click-through rate (CTR) and conversion rate (CVR) predictions. Most of existing methods overlook the effect of two key characteristics of the user's behaviors: for each item list, (i) contextual dependence refers to that the user's behaviors on any item are not purely determinated by the item itself but also are influenced by the user's previous behaviors (e.g., clicks, purchases) on other items in the same sequence; (ii) multiple time scales means that users are likely to click frequently but purchase periodically. To this end, we develop a new multi-scale user behavior network named Hierarchical rEcurrent Ranking On the Entire Space (HEROES) which incorporates the contextual information to estimate the user multiple behaviors in a multi-scale fashion. Concretely, we introduce a hierarchical framework, where the lower layer models the user's engagement behaviors while the upper layer estimates the user's satisfaction behaviors. The proposed architecture can automatically learn a suitable time scale for each layer to capture the dynamic user's behavioral patterns. Besides the architecture, we also introduce the Hawkes process to form a novel recurrent unit which can not only encode the items' features in the context but also formulate the excitation or discouragement from the user's previous behaviors. We further show that HEROES can be extended to build unbiased ranking systems through combinations with the survival analysis technique. Extensive experiments over three large-scale industrial datasets demonstrate the superiority of our model compared with the state-of-the-art methods.
Efficient Algorithms for Sparse Moment Problems without Separation
Jul 26, 2022
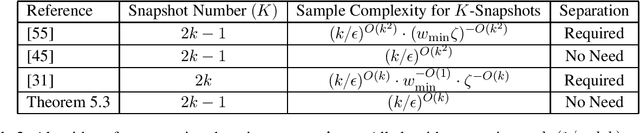
We consider the sparse moment problem of learning a $k$-spike mixture in high dimensional space from its noisy moment information in any dimension. We measure the accuracy of the learned mixtures using transportation distance. Previous algorithms either assume certain separation assumptions, use more recovery moments, or run in (super) exponential time. Our algorithm for the 1-dimension problem (also called the sparse Hausdorff moment problem) is a robust version of the classic Prony's method, and our contribution mainly lies in the analysis. We adopt a global and much tighter analysis than previous work (which analyzes the perturbation of the intermediate results of Prony's method). A useful technical ingredient is a connection between the linear system defined by the Vandermonde matrix and the Schur polynomial, which allows us to provide tight perturbation bound independent of the separation and may be useful in other contexts. To tackle the high dimensional problem, we first solve the 2-dimensional problem by extending the 1-dimension algorithm and analysis to complex numbers. Our algorithm for the high dimensional case determines the coordinates of each spike by aligning a 1-d projection of the mixture to a random vector and a set of 2d-projections of the mixture. Our results have applications to learning topic models and Gaussian mixtures, implying improved sample complexity results or running time over prior work.
Time Alignment using Lip Images for Frame-based Electrolaryngeal Voice Conversion
Sep 08, 2021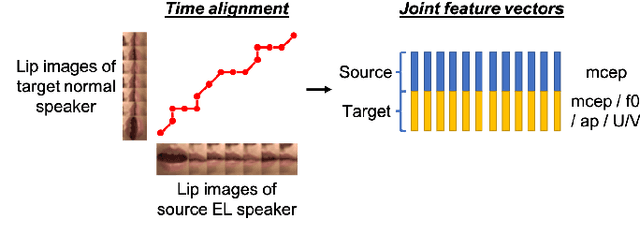
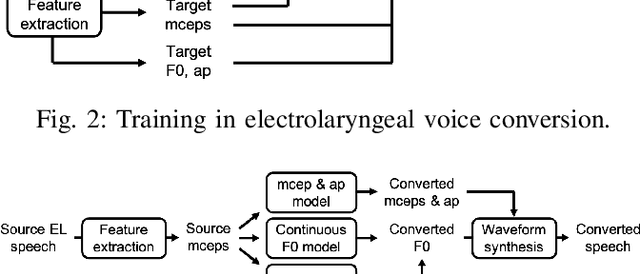
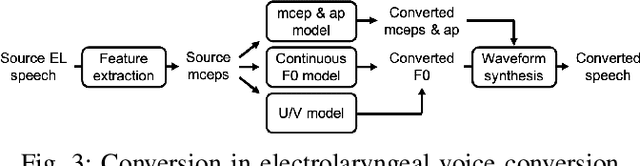
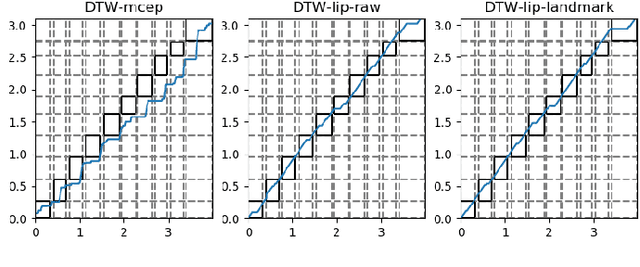
Voice conversion (VC) is an effective approach to electrolaryngeal (EL) speech enhancement, a task that aims to improve the quality of the artificial voice from an electrolarynx device. In frame-based VC methods, time alignment needs to be performed prior to model training, and the dynamic time warping (DTW) algorithm is widely adopted to compute the best time alignment between each utterance pair. The validity is based on the assumption that the same phonemes of the speakers have similar features and can be mapped by measuring a pre-defined distance between speech frames of the source and the target. However, the special characteristics of the EL speech can break the assumption, resulting in a sub-optimal DTW alignment. In this work, we propose to use lip images for time alignment, as we assume that the lip movements of laryngectomee remain normal compared to healthy people. We investigate two naive lip representations and distance metrics, and experimental results demonstrate that the proposed method can significantly outperform the audio-only alignment in terms of objective and subjective evaluations.
Exploring and Evaluating Personalized Models for Code Generation
Aug 29, 2022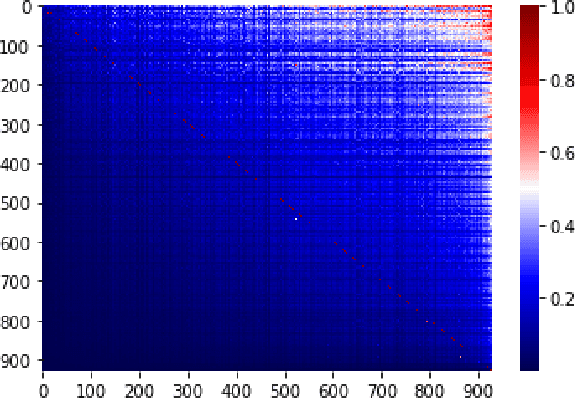
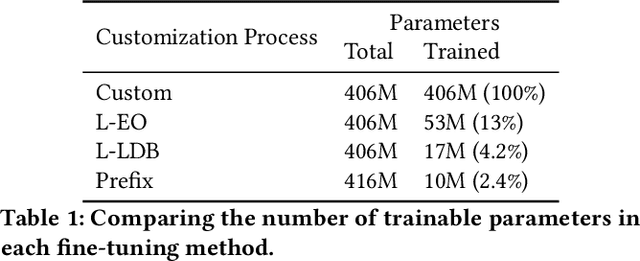
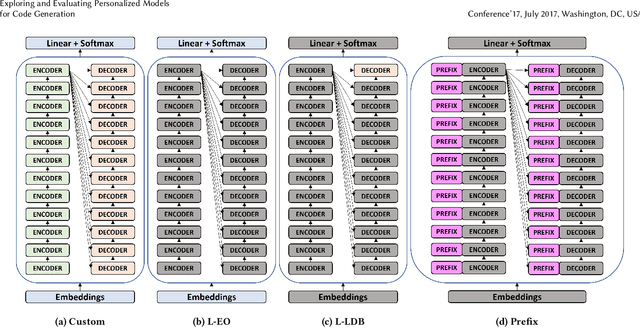
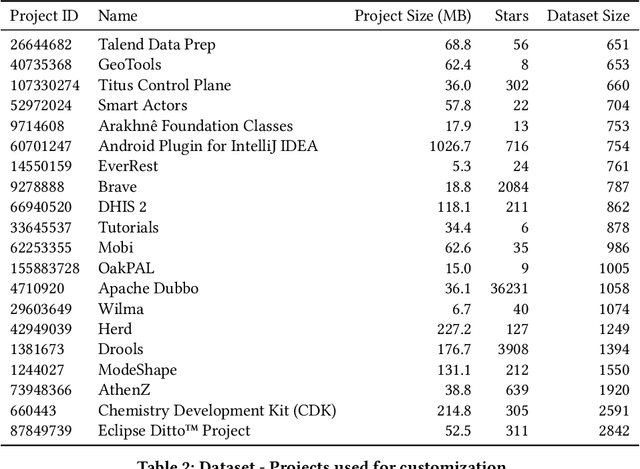
Large Transformer models achieved the state-of-the-art status for Natural Language Understanding tasks and are increasingly becoming the baseline model architecture for modeling source code. Transformers are usually pre-trained on large unsupervised corpora, learning token representations and transformations relevant to modeling generally available text, and are then fine-tuned on a particular downstream task of interest. While fine-tuning is a tried-and-true method for adapting a model to a new domain -- for example, question-answering on a given topic -- generalization remains an on-going challenge. In this paper, we explore and evaluate transformer model fine-tuning for personalization. In the context of generating unit tests for Java methods, we evaluate learning to personalize to a specific software project using several personalization techniques. We consider three key approaches: (i) custom fine-tuning, which allows all the model parameters to be tuned; (ii) lightweight fine-tuning, which freezes most of the model's parameters, allowing tuning of the token embeddings and softmax layer only or the final layer alone; (iii) prefix tuning, which keeps model parameters frozen, but optimizes a small project-specific prefix vector. Each of these techniques offers a trade-off in total compute cost and predictive performance, which we evaluate by code and task-specific metrics, training time, and total computational operations. We compare these fine-tuning strategies for code generation and discuss the potential generalization and cost benefits of each in various deployment scenarios.