 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deep Learning-based Time-varying Channel Estimation for RIS Assisted Communication
Aug 12, 2021



Reconfigurable intelligent surface (RIS) is considered as a revolutionary technology for future wireless communication networks. In this letter, we consider the acquisition of the time-varying cascaded channels, which is a challenging task due to the massive number of passive RIS elements and the small channel coherence time. To reduce the pilot overhead, a deep learning-based channel extrapolation is implemented over both antenna and time domains. We divide the neural network into two parts, i.e., the time-domain and the antenna-domain extrapolation networks, where the neural ordinary differential equations (ODE) are utilized. In the former, ODE accurately describes the dynamics of the RIS channels and improves the recurrent neural network's performance of time series reconstruction. In the latter, ODE is resorted to modify the relations among different data layers in a feedforward neural network. We cascade the two networks and jointly train them. Simulation results show that the proposed scheme can effectively extrapolate the cascaded RIS channels in high mobility scenario.
Extrinsic Camera Calibration with Semantic Segmentation
Aug 08, 2022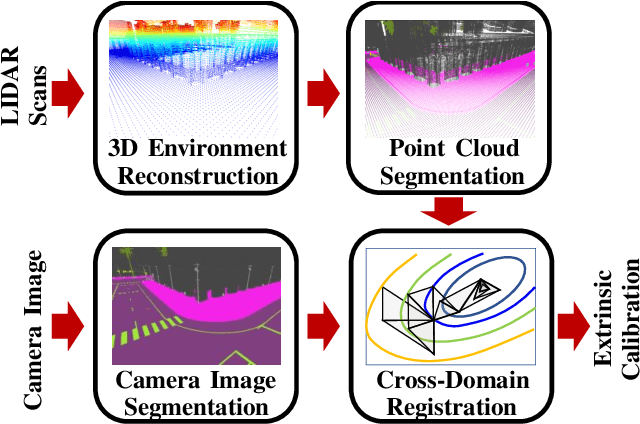
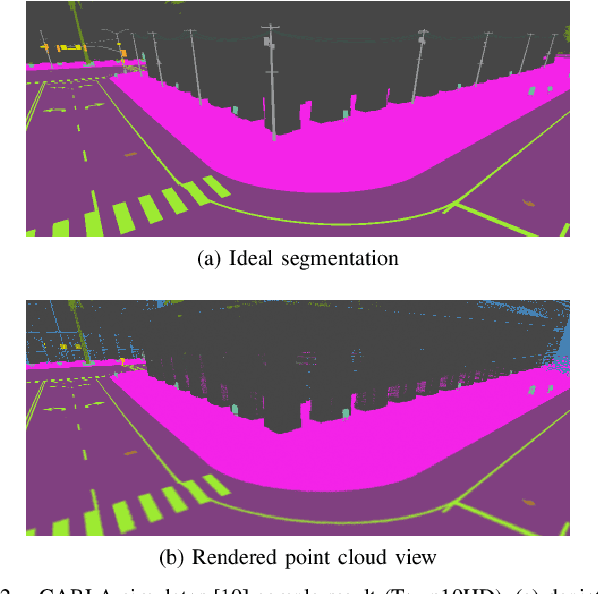

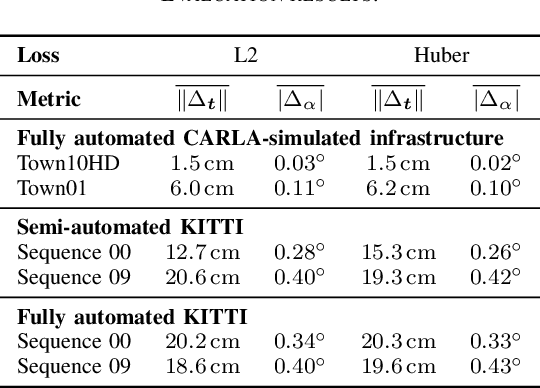
Monocular camera sensors are vital to intelligent vehicle operation and automated driving assistance and are also heavily employed in traffic control infrastructure. Calibrating the monocular camera, though, is time-consuming and often requires significant manual intervention. In this work, we present an extrinsic camera calibration approach that automatizes the parameter estimation by utilizing semantic segmentation information from images and point clouds. Our approach relies on a coarse initial measurement of the camera pose and builds on lidar sensors mounted on a vehicle with high-precision localization to capture a point cloud of the camera environment. Afterward, a mapping between the camera and world coordinate spaces is obtained by performing a lidar-to-camera registration of the semantically segmented sensor data. We evaluate our method on simulated and real-world data to demonstrate low error measurements in the calibration results. Our approach is suitable for infrastructure sensors as well as vehicle sensors, while it does not require motion of the camera platform.
Detecting User Exits from Online Behavior: A Duration-Dependent Latent State Model
Aug 08, 2022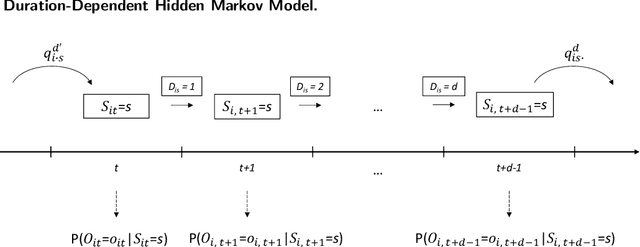
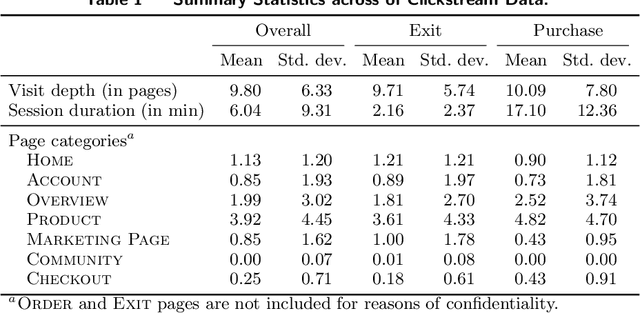
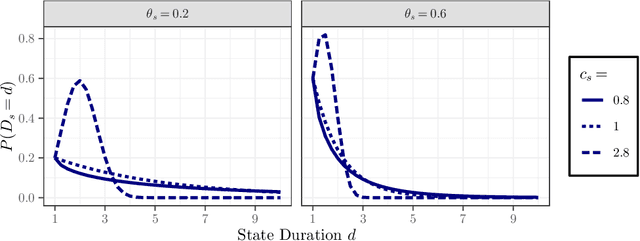
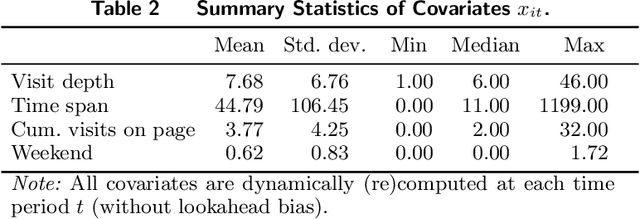
In order to steer e-commerce users towards making a purchase, marketers rely upon predictions of when users exit without purchasing. Previously, such predictions were based upon hidden Markov models (HMMs) due to their ability of modeling latent shopping phases with different user intents. In this work, we develop a duration-dependent hidden Markov model. In contrast to traditional HMMs, it explicitly models the duration of latent states and thereby allows states to become "sticky". The proposed model is superior to prior HMMs in detecting user exits: out of 100 user exits without purchase, it correctly identifies an additional 18. This helps marketers in better managing the online behavior of e-commerce customers. The reason for the superior performance of our model is the duration dependence, which allows our model to recover latent states that are characterized by a distorted sense of time. We finally provide a theoretical explanation for this, which builds upon the concept of "flow".
Viskositas: Viscosity Prediction of Multicomponent Chemical Systems
Aug 04, 2022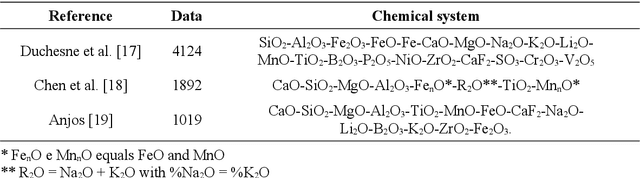
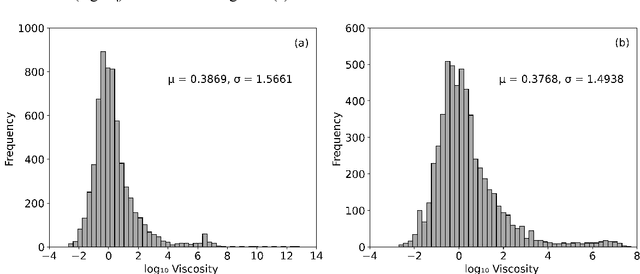
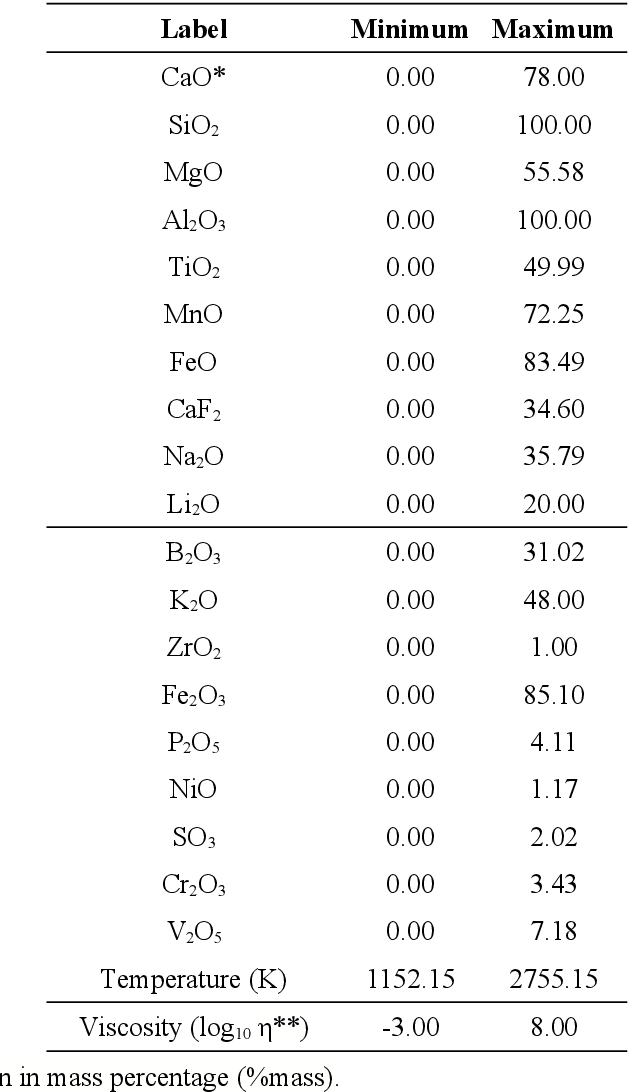
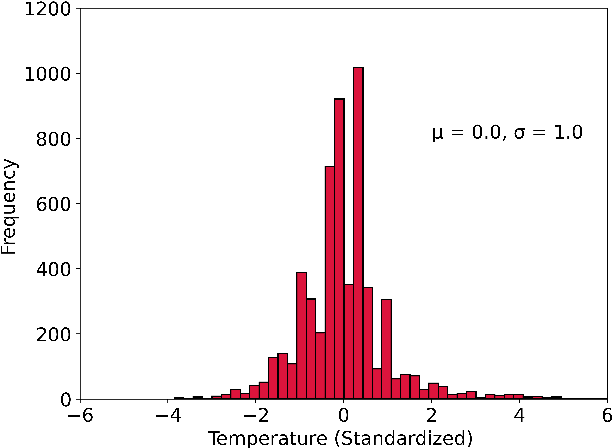
Viscosity in the metallurgical and glass industry plays a fundamental role in its production processes, also in the area of geophysics. As its experimental measurement is financially expensive, also in terms of time, several mathematical models were built to provide viscosity results as a function of several variables, such as chemical composition and temperature, in linear and nonlinear models. A database was built in order to produce a nonlinear model by artificial neural networks by variation of hyperparameters to provide reliable predictions of viscosity in relation to chemical systems and temperatures. The model produced named Viskositas demonstrated better statistical evaluations of mean absolute error, standard deviation and coefficient of determination in relation to the test database when compared to different models from literature and 1 commercial model, offering predictions with lower errors, less variability and less generation of outliers.
Towards Interpretable Video Super-Resolution via Alternating Optimization
Jul 21, 2022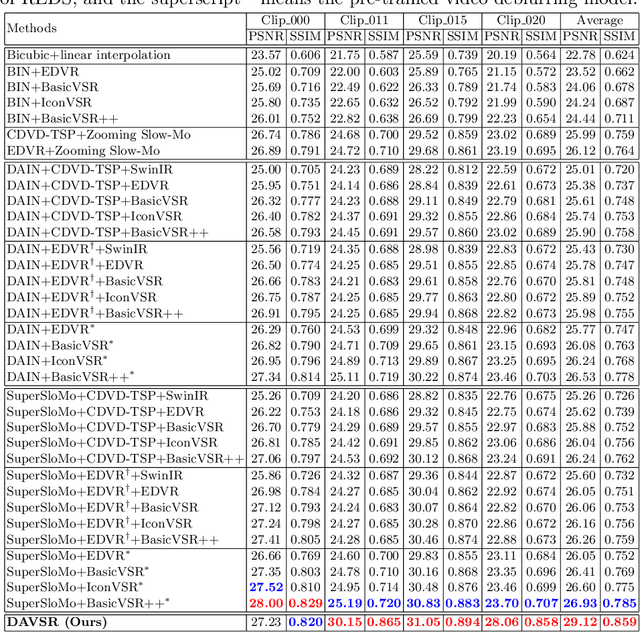
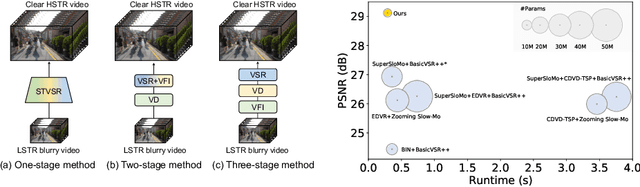
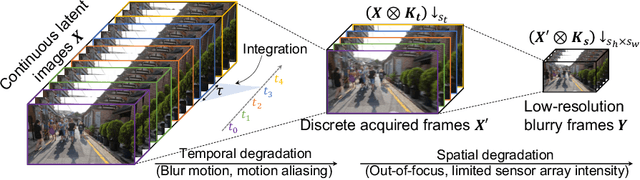
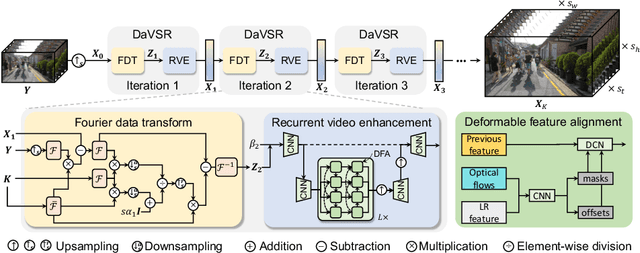
In this paper, we study a practical space-time video super-resolution (STVSR) problem which aims at generating a high-framerate high-resolution sharp video from a low-framerate low-resolution blurry video. Such problem often occurs when recording a fast dynamic event with a low-framerate and low-resolution camera, and the captured video would suffer from three typical issues: i) motion blur occurs due to object/camera motions during exposure time; ii) motion aliasing is unavoidable when the event temporal frequency exceeds the Nyquist limit of temporal sampling; iii) high-frequency details are lost because of the low spatial sampling rate. These issues can be alleviated by a cascade of three separate sub-tasks, including video deblurring, frame interpolation, and super-resolution, which, however, would fail to capture the spatial and temporal correlations among video sequences. To address this, we propose an interpretable STVSR framework by leveraging both model-based and learning-based methods. Specifically, we formulate STVSR as a joint video deblurring, frame interpolation, and super-resolution problem, and solve it as two sub-problems in an alternate way. For the first sub-problem, we derive an interpretable analytical solution and use it as a Fourier data transform layer. Then, we propose a recurrent video enhancement layer for the second sub-problem to further recover high-frequency details. Extensive experiments demonstrate the superiority of our method in terms of quantitative metrics and visual quality.
PiFeNet: Pillar-Feature Network for Real-Time 3D Pedestrian Detection from Point Cloud
Dec 31, 2021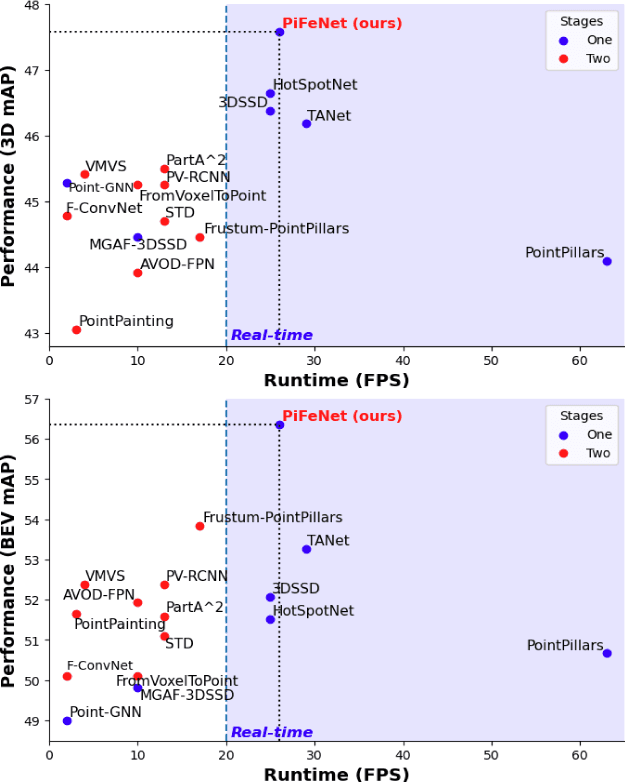
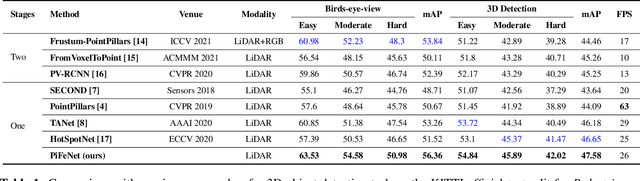
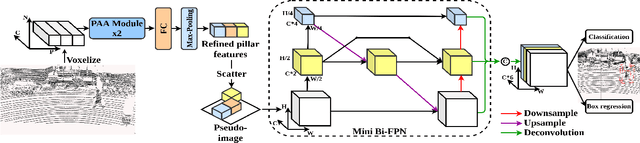

We present PiFeNet, an efficient and accurate real-time 3D detector for pedestrian detection from point clouds. We address two challenges that 3D object detection frameworks encounter when detecting pedestrians: low expressiveness of pillar features and small occupation areas of pedestrians in point clouds. Firstly, we introduce a stackable Pillar Aware Attention (PAA) module for enhanced pillar features extraction while suppressing noises in the point clouds. By integrating multi-point-aware-pooling, point-wise, channel-wise, and task-aware attention into a simple module, the representation capabilities are boosted while requiring little additional computing resources. We also present Mini-BiFPN, a small yet effective feature network that creates bidirectional information flow and multi-level cross-scale feature fusion to better integrate multi-resolution features. Our approach is ranked 1st in KITTI pedestrian BEV and 3D leaderboards while running at 26 frames per second (FPS), and achieves state-of-the-art performance on Nuscenes detection benchmark.
Label Sleuth: From Unlabeled Text to a Classifier in a Few Hours
Aug 02, 2022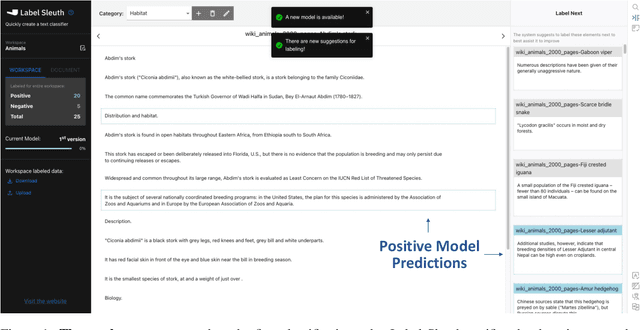

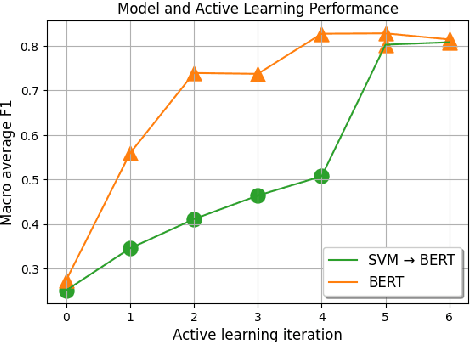

Text classification can be useful in many real-world scenarios, saving a lot of time for end users. However, building a custom classifier typically requires coding skills and ML knowledge, which poses a significant barrier for many potential users. To lift this barrier, we introduce Label Sleuth, a free open source system for labeling and creating text classifiers. This system is unique for (a) being a no-code system, making NLP accessible to non-experts, (b) guiding users through the entire labeling process until they obtain a custom classifier, making the process efficient -- from cold start to classifier in a few hours, and (c) being open for configuration and extension by developers. By open sourcing Label Sleuth we hope to build a community of users and developers that will broaden the utilization of NLP models.
Fast Vocabulary Projection Method via Clustering for Multilingual Machine Translation on GPU
Aug 14, 2022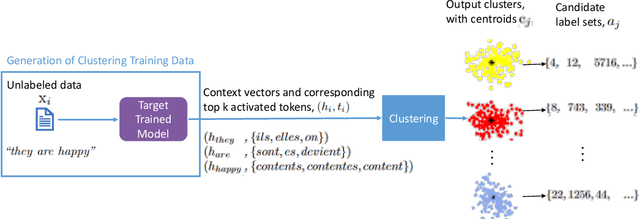
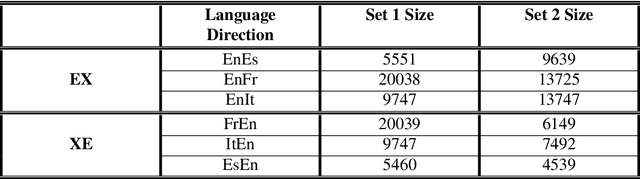
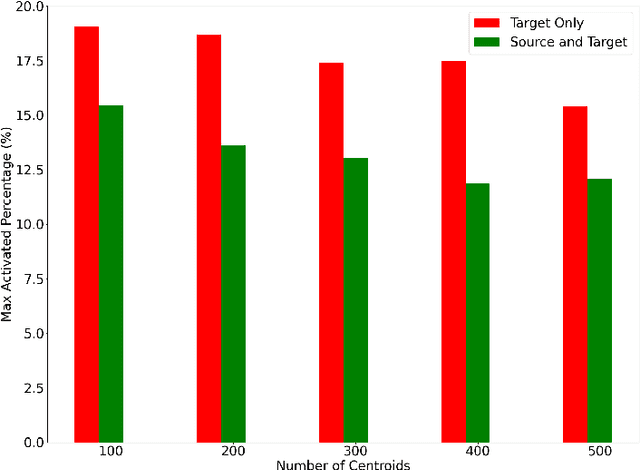
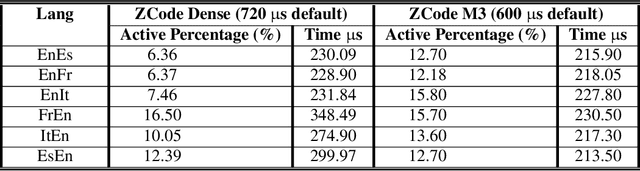
Multilingual Neural Machine Translation has been showing great success using transformer models. Deploying these models is challenging because they usually require large vocabulary (vocab) sizes for various languages. This limits the speed of predicting the output tokens in the last vocab projection layer. To alleviate these challenges, this paper proposes a fast vocabulary projection method via clustering which can be used for multilingual transformers on GPUs. First, we offline split the vocab search space into disjoint clusters given the hidden context vector of the decoder output, which results in much smaller vocab columns for vocab projection. Second, at inference time, the proposed method predicts the clusters and candidate active tokens for hidden context vectors at the vocab projection. This paper also includes analysis of different ways of building these clusters in multilingual settings. Our results show end-to-end speed gains in float16 GPU inference up to 25% while maintaining the BLEU score and slightly increasing memory cost. The proposed method speeds up the vocab projection step itself by up to 2.6x. We also conduct an extensive human evaluation to verify the proposed method preserves the quality of the translations from the original model.
An Efficient Coarse-to-Fine Facet-Aware Unsupervised Summarization Framework based on Semantic Blocks
Aug 17, 2022
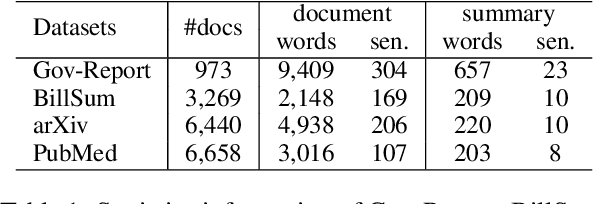
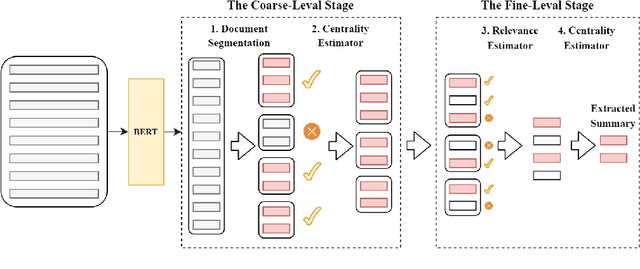
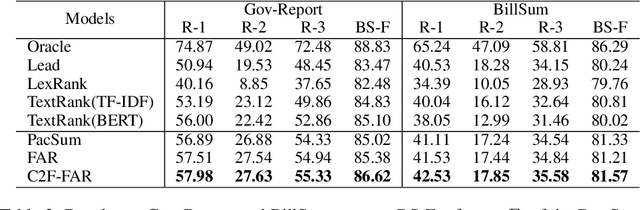
Unsupervised summarization methods have achieved remarkable results by incorporating representations from pre-trained language models. However, existing methods fail to consider efficiency and effectiveness at the same time when the input document is extremely long. To tackle this problem, in this paper, we proposed an efficient Coarse-to-Fine Facet-Aware Ranking (C2F-FAR) framework for unsupervised long document summarization, which is based on the semantic block. The semantic block refers to continuous sentences in the document that describe the same facet. Specifically, we address this problem by converting the one-step ranking method into the hierarchical multi-granularity two-stage ranking. In the coarse-level stage, we propose a new segment algorithm to split the document into facet-aware semantic blocks and then filter insignificant blocks. In the fine-level stage, we select salient sentences in each block and then extract the final summary from selected sentences. We evaluate our framework on four long document summarization datasets: Gov-Report, BillSum, arXiv, and PubMed. Our C2F-FAR can achieve new state-of-the-art unsupervised summarization results on Gov-Report and BillSum. In addition, our method speeds up 4-28 times more than previous methods.\footnote{\url{https://github.com/xnliang98/c2f-far}}
pyWATTS: Python Workflow Automation Tool for Time Series
Jun 18, 2021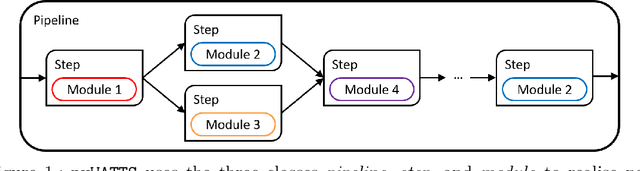
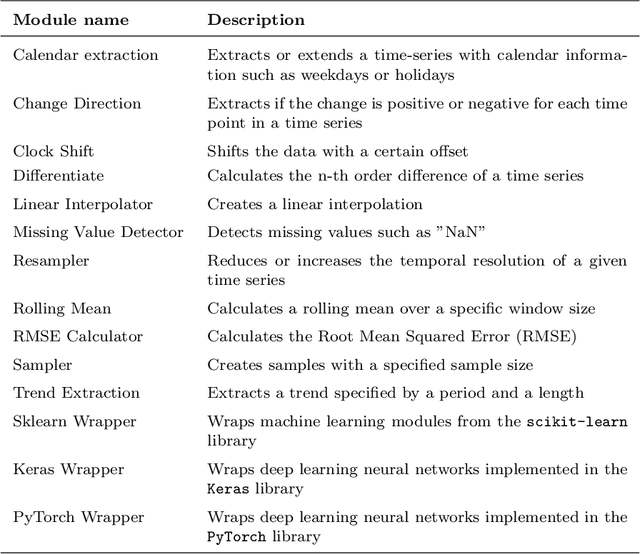
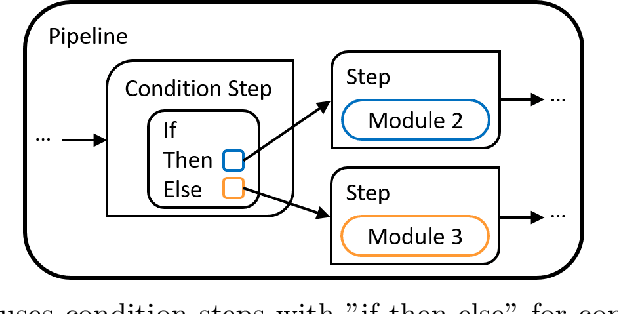
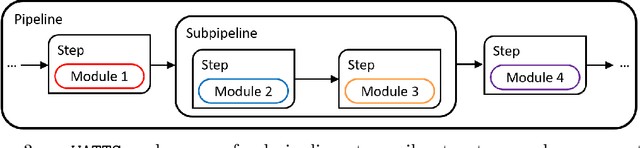
Time series data are fundamental for a variety of applications, ranging from financial markets to energy systems. Due to their importance, the number and complexity of tools and methods used for time series analysis is constantly increasing. However, due to unclear APIs and a lack of documentation, researchers struggle to integrate them into their research projects and replicate results. Additionally, in time series analysis there exist many repetitive tasks, which are often re-implemented for each project, unnecessarily costing time. To solve these problems we present \texttt{pyWATTS}, an open-source Python-based package that is a non-sequential workflow automation tool for the analysis of time series data. pyWATTS includes modules with clearly defined interfaces to enable seamless integration of new or existing methods, subpipelining to easily reproduce repetitive tasks, load and save functionality to simply replicate results, and native support for key Python machine learning libraries such as scikit-learn, PyTorch, and Keras.