 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
TMGAN-PLC: Audio Packet Loss Concealment using Temporal Memory Generative Adversarial Network
Jul 04, 2022
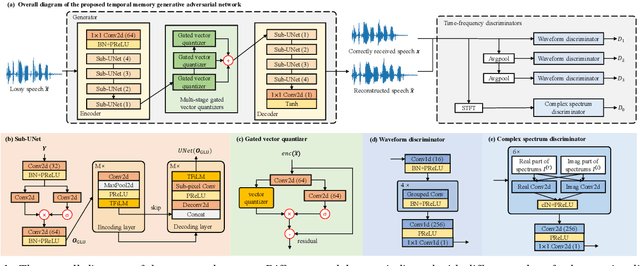
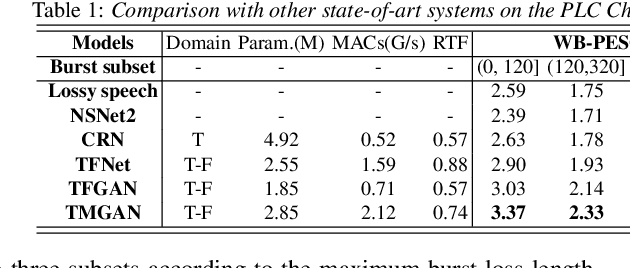
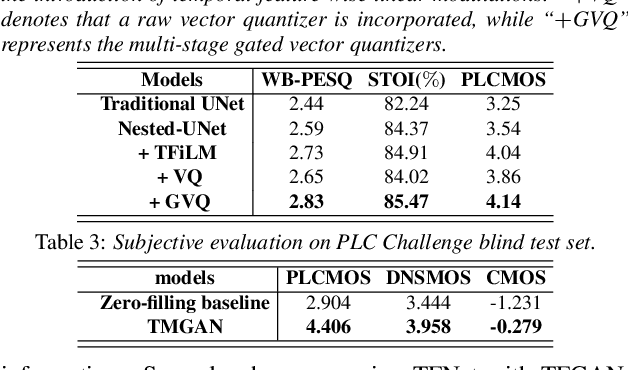
Real-time communications in packet-switched networks have become widely used in daily communication, while they inevitably suffer from network delays and data losses in constrained real-time conditions. To solve these problems, audio packet loss concealment (PLC) algorithms have been developed to mitigate voice transmission failures by reconstructing the lost information. Limited by the transmission latency and device memory, it is still intractable for PLC to accomplish high-quality voice reconstruction using a relatively small packet buffer. In this paper, we propose a temporal memory generative adversarial network for audio PLC, dubbed TMGAN-PLC, which is comprised of a novel nested-UNet generator and the time-domain/frequency-domain discriminators. Specifically, a combination of the nested-UNet and temporal feature-wise linear modulation is elaborately devised in the generator to finely adjust the intra-frame information and establish inter-frame temporal dependencies. To complement the missing speech content caused by longer loss bursts, we employ multi-stage gated vector quantizers to capture the correct content and reconstruct the near-real smooth audio. Extensive experiments on the PLC Challenge dataset demonstrate that the proposed method yields promising performance in terms of speech quality, intelligibility, and PLCMOS.
Fraud Detection Using Optimized Machine Learning Tools Under Imbalance Classes
Sep 04, 2022
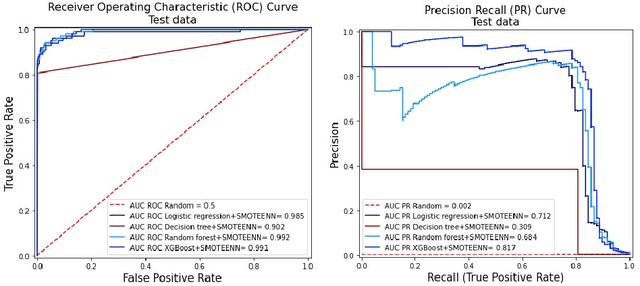
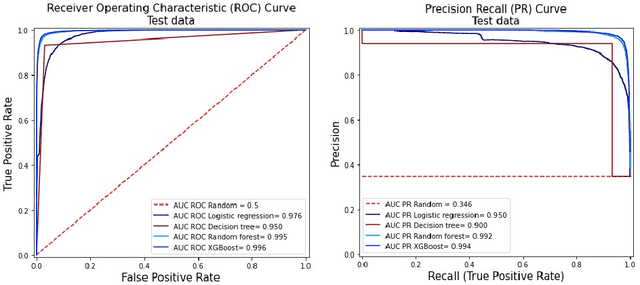
Fraud detection is a challenging task due to the changing nature of fraud patterns over time and the limited availability of fraud examples to learn such sophisticated patterns. Thus, fraud detection with the aid of smart versions of machine learning (ML) tools is essential to assure safety. Fraud detection is a primary ML classification task; however, the optimum performance of the corresponding ML tool relies on the usage of the best hyperparameter values. Moreover, classification under imbalanced classes is quite challenging as it causes poor performance in minority classes, which most ML classification techniques ignore. Thus, we investigate four state-of-the-art ML techniques, namely, logistic regression, decision trees, random forest, and extreme gradient boost, that are suitable for handling imbalance classes to maximize precision and simultaneously reduce false positives. First, these classifiers are trained on two original benchmark unbalanced fraud detection datasets, namely, phishing website URLs and fraudulent credit card transactions. Then, three synthetically balanced datasets are produced for each original data set by implementing the sampling frameworks, namely, RandomUnderSampler, SMOTE, and SMOTEENN. The optimum hyperparameters for all the 16 experiments are revealed using the method RandomzedSearchCV. The validity of the 16 approaches in the context of fraud detection is compared using two benchmark performance metrics, namely, area under the curve of receiver operating characteristics (AUC ROC) and area under the curve of precision and recall (AUC PR). For both phishing website URLs and credit card fraud transaction datasets, the results indicate that extreme gradient boost trained on the original data shows trustworthy performance in the imbalanced dataset and manages to outperform the other three methods in terms of both AUC ROC and AUC PR.
DropNet: Reducing Neural Network Complexity via Iterative Pruning
Jul 14, 2022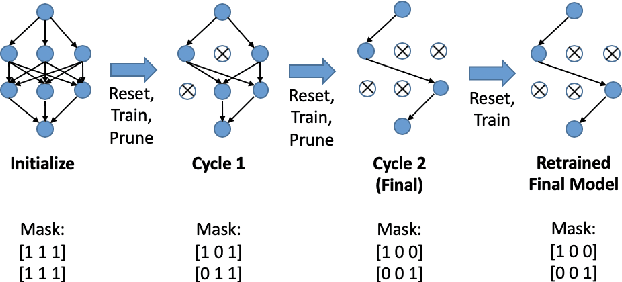

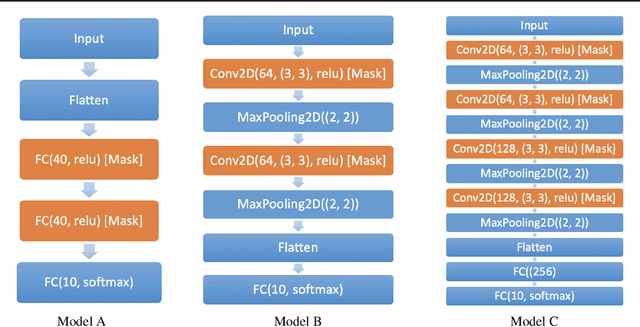
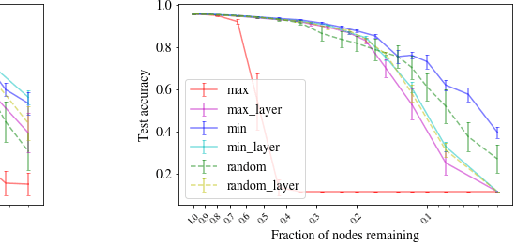
Modern deep neural networks require a significant amount of computing time and power to train and deploy, which limits their usage on edge devices. Inspired by the iterative weight pruning in the Lottery Ticket Hypothesis, we propose DropNet, an iterative pruning method which prunes nodes/filters to reduce network complexity. DropNet iteratively removes nodes/filters with the lowest average post-activation value across all training samples. Empirically, we show that DropNet is robust across diverse scenarios, including MLPs and CNNs using the MNIST, CIFAR-10 and Tiny ImageNet datasets. We show that up to 90% of the nodes/filters can be removed without any significant loss of accuracy. The final pruned network performs well even with reinitialization of the weights and biases. DropNet also has similar accuracy to an oracle which greedily removes nodes/filters one at a time to minimise training loss, highlighting its effectiveness.
* Published at ICML 2020. Code can be found at https://github.com/tanchongmin/DropNet
Joint optimal beamforming and power control in cell-free massive MIMO
Aug 02, 2022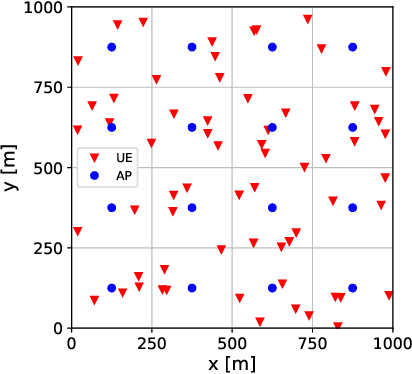
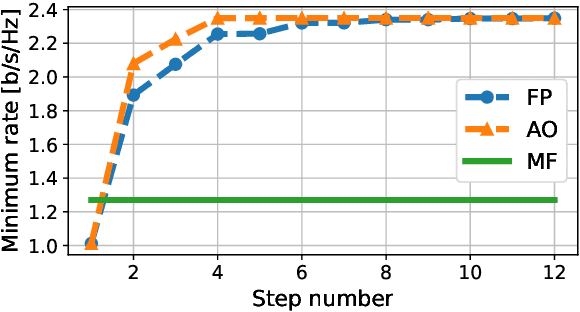
We derive a fast and optimal algorithm for solving practical weighted max-min SINR problems in cell-free massive MIMO networks. For the first time, the optimization problem jointly covers long-term power control and distributed beamforming design under imperfect cooperation. In particular, we consider user-centric clusters of access points cooperating on the basis of possibly limited channel state information sharing. Our optimal algorithm merges powerful power control tools based on interference calculus with the recently developed team theoretic framework for distributed beamforming design. In addition, we propose a variation that shows faster convergence in practice.
See Finer, See More: Implicit Modality Alignment for Text-based Person Retrieval
Aug 26, 2022
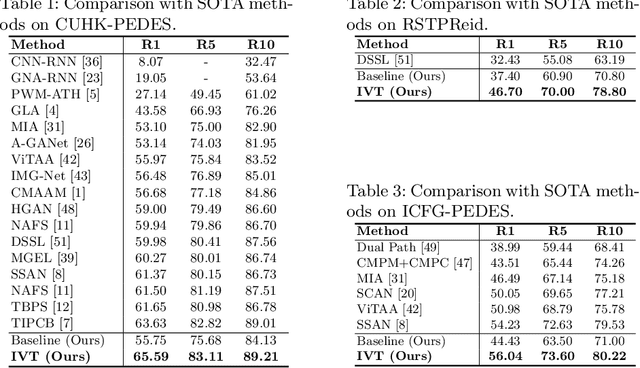
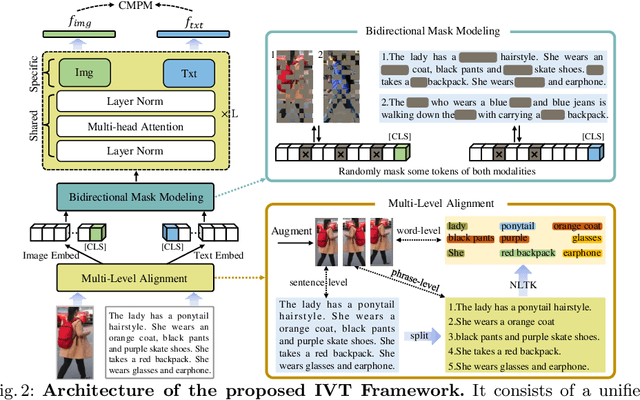

Text-based person retrieval aims to find the query person based on a textual description. The key is to learn a common latent space mapping between visual-textual modalities. To achieve this goal, existing works employ segmentation to obtain explicitly cross-modal alignments or utilize attention to explore salient alignments. These methods have two shortcomings: 1) Labeling cross-modal alignments are time-consuming. 2) Attention methods can explore salient cross-modal alignments but may ignore some subtle and valuable pairs. To relieve these issues, we introduce an Implicit Visual-Textual (IVT) framework for text-based person retrieval. Different from previous models, IVT utilizes a single network to learn representation for both modalities, which contributes to the visual-textual interaction. To explore the fine-grained alignment, we further propose two implicit semantic alignment paradigms: multi-level alignment (MLA) and bidirectional mask modeling (BMM). The MLA module explores finer matching at sentence, phrase, and word levels, while the BMM module aims to mine \textbf{more} semantic alignments between visual and textual modalities. Extensive experiments are carried out to evaluate the proposed IVT on public datasets, i.e., CUHK-PEDES, RSTPReID, and ICFG-PEDES. Even without explicit body part alignment, our approach still achieves state-of-the-art performance. Code is available at: https://github.com/TencentYoutuResearch/PersonRetrieval-IVT.
MegaPortraits: One-shot Megapixel Neural Head Avatars
Jul 15, 2022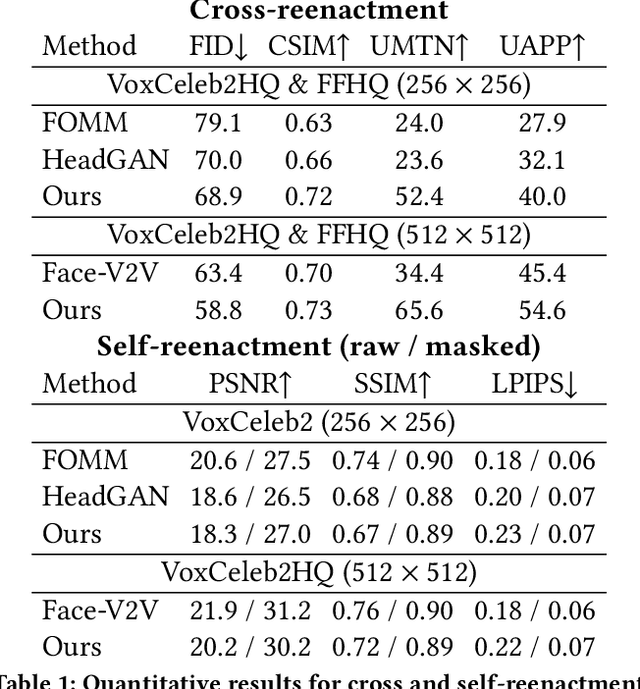
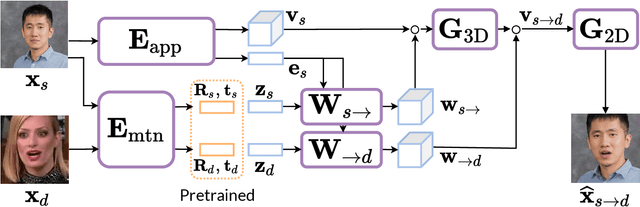
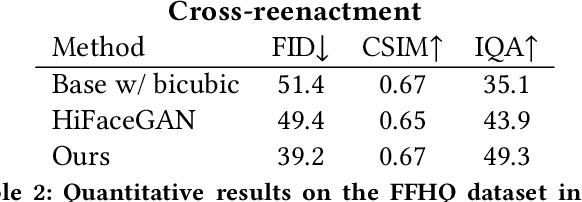

In this work, we advance the neural head avatar technology to the megapixel resolution while focusing on the particularly challenging task of cross-driving synthesis, i.e., when the appearance of the driving image is substantially different from the animated source image. We propose a set of new neural architectures and training methods that can leverage both medium-resolution video data and high-resolution image data to achieve the desired levels of rendered image quality and generalization to novel views and motion. We demonstrate that suggested architectures and methods produce convincing high-resolution neural avatars, outperforming the competitors in the cross-driving scenario. Lastly, we show how a trained high-resolution neural avatar model can be distilled into a lightweight student model which runs in real-time and locks the identities of neural avatars to several dozens of pre-defined source images. Real-time operation and identity lock are essential for many practical applications head avatar systems.
FedPerm: Private and Robust Federated Learning by Parameter Permutation
Aug 16, 2022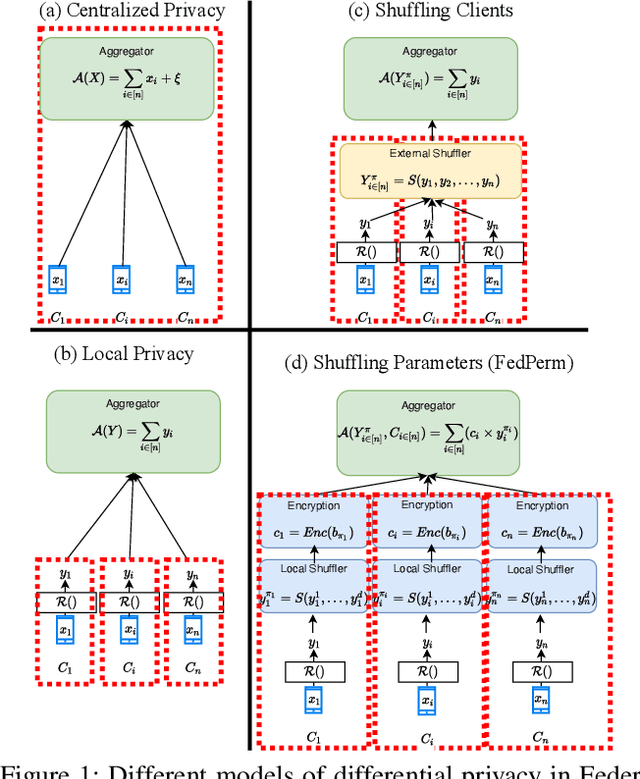

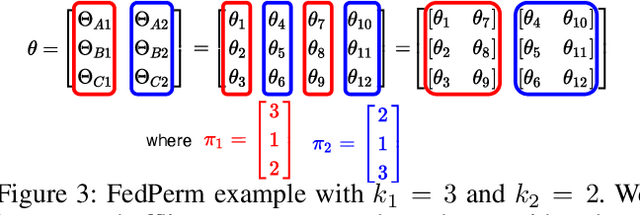
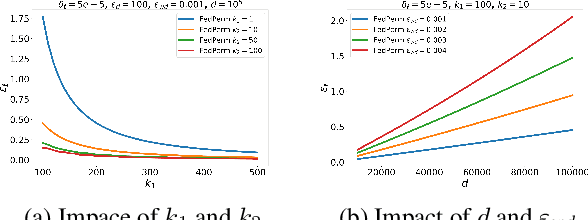
Federated Learning (FL) is a distributed learning paradigm that enables mutually untrusting clients to collaboratively train a common machine learning model. Client data privacy is paramount in FL. At the same time, the model must be protected from poisoning attacks from adversarial clients. Existing solutions address these two problems in isolation. We present FedPerm, a new FL algorithm that addresses both these problems by combining a novel intra-model parameter shuffling technique that amplifies data privacy, with Private Information Retrieval (PIR) based techniques that permit cryptographic aggregation of clients' model updates. The combination of these techniques further helps the federation server constrain parameter updates from clients so as to curtail effects of model poisoning attacks by adversarial clients. We further present FedPerm's unique hyperparameters that can be used effectively to trade off computation overheads with model utility. Our empirical evaluation on the MNIST dataset demonstrates FedPerm's effectiveness over existing Differential Privacy (DP) enforcement solutions in FL.
One-class Recommendation Systems with the Hinge Pairwise Distance Loss and Orthogonal Representations
Aug 31, 2022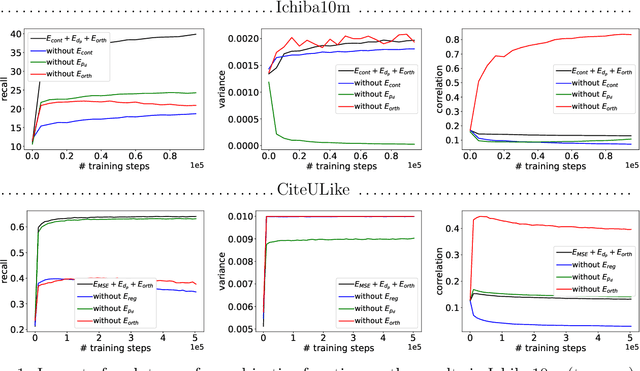
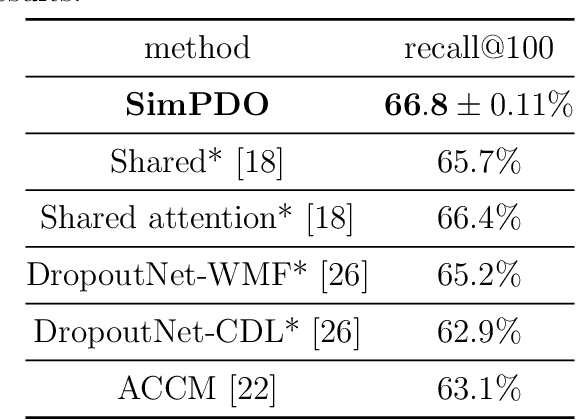
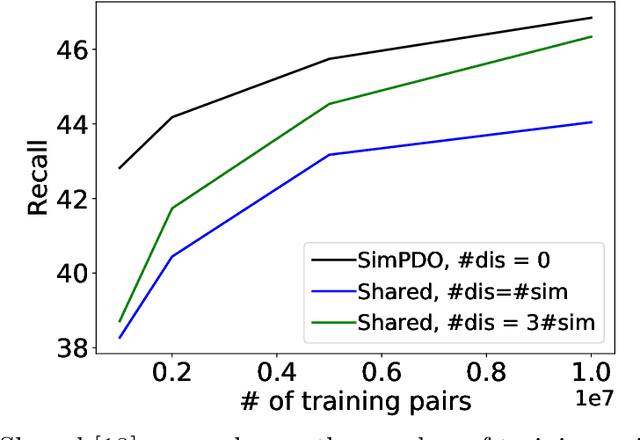
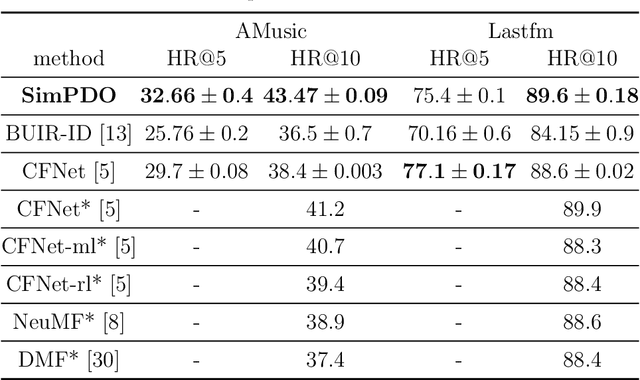
In one-class recommendation systems, the goal is to learn a model from a small set of interacted users and items and then identify the positively-related user-item pairs among a large number of pairs with unknown interactions. Most previous loss functions rely on dissimilar pairs of users and items, which are selected from the ones with unknown interactions, to obtain better prediction performance. This strategy introduces several challenges such as increasing training time and hurting the performance by picking "similar pairs with the unknown interactions" as dissimilar pairs. In this paper, the goal is to only use the similar set to train the models. We point out three trivial solutions that the models converge to when they are trained only on similar pairs: collapsed, partially collapsed, and shrinking solutions. We propose two terms that can be added to the objective functions in the literature to avoid these solutions. The first one is a hinge pairwise distance loss that avoids the shrinking and collapsed solutions by keeping the average pairwise distance of all the representations greater than a margin. The second one is an orthogonality term that minimizes the correlation between the dimensions of the representations and avoids the partially collapsed solution. We conduct experiments on a variety of tasks on public and real-world datasets. The results show that our approach using only similar pairs outperforms state-of-the-art methods using similar pairs and a large number of dissimilar pairs.
Robust Key-Frame Stereo Visual SLAM with low-threshold Point and Line Features
Jul 12, 2022
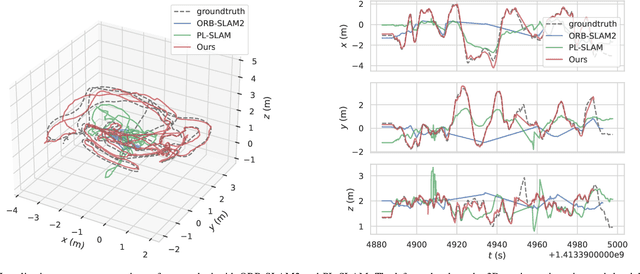
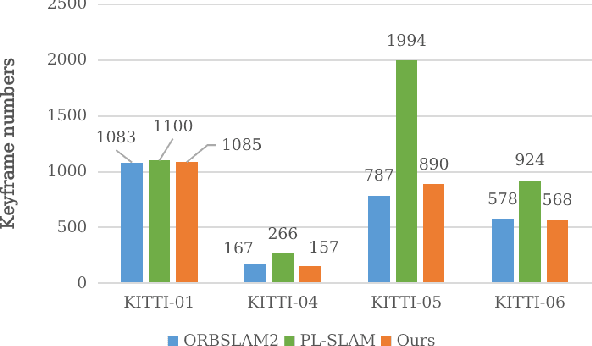
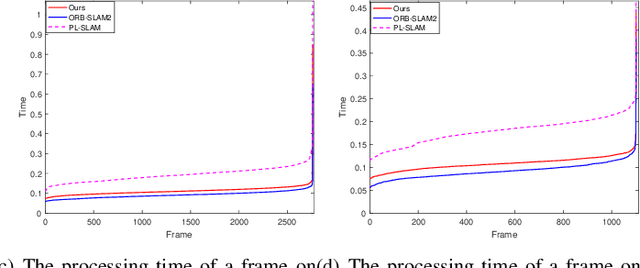
In this paper, we develop a robust, efficient visual SLAM system that utilizes spatial inhibition of low threshold, baseline lines, and closed-loop keyframe features. Using ORB-SLAM2, our methods include stereo matching, frame tracking, local bundle adjustment, and line and point global bundle adjustment. In particular, we contribute re-projection in line with the baseline. Fusing lines in the system consume colossal time, and we reduce the time from distributing points to utilizing spatial suppression of feature points. In addition, low threshold key points can be more effective in dealing with low textures. In order to overcome Tracking keyframe redundant problems, an efficient and robust closed-loop tracking key frame is proposed. The proposed SLAM has been extensively tested in KITTI and EuRoC datasets, demonstrating that the proposed system is superior to state-of-the-art methods in various scenarios.
OTB-morph: One-Time Biometrics via Morphing applied to Face Templates
Nov 25, 2021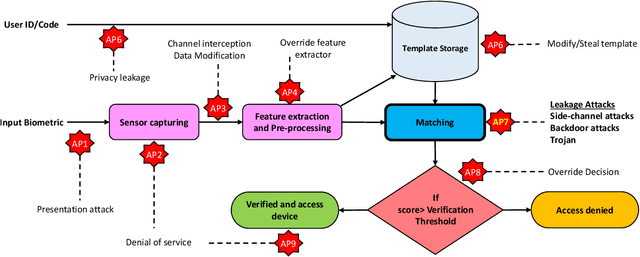

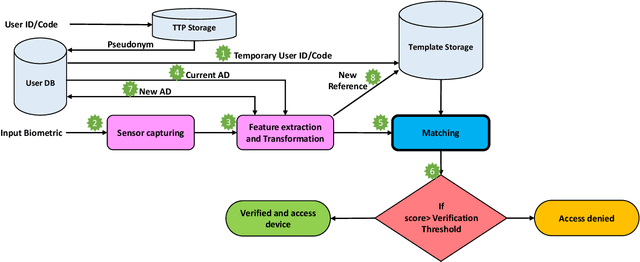
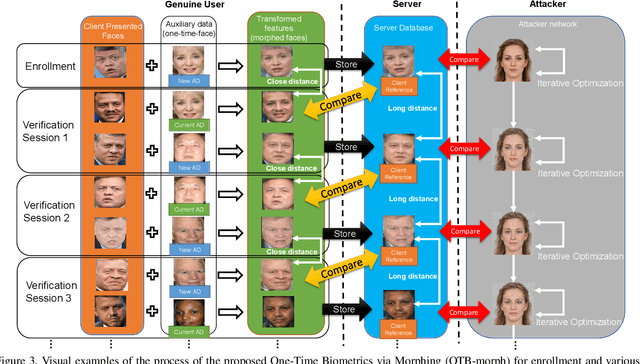
Cancelable biometrics refers to a group of techniques in which the biometric inputs are transformed intentionally using a key before processing or storage. This transformation is repeatable enabling subsequent biometric comparisons. This paper introduces a new scheme for cancelable biometrics aimed at protecting the templates against potential attacks, applicable to any biometric-based recognition system. Our proposed scheme is based on time-varying keys obtained from morphing random biometric information. An experimental implementation of the proposed scheme is given for face biometrics. The results confirm that the proposed approach is able to withstand against leakage attacks while improving the recognition performance.