 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Dynamic Bayesian Learning and Calibration of Spatiotemporal Mechanistic System
Aug 12, 2022
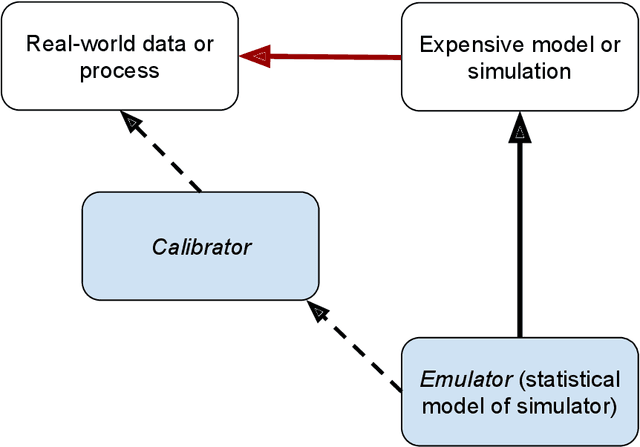
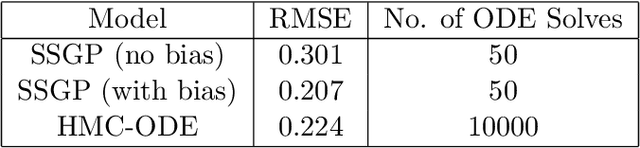
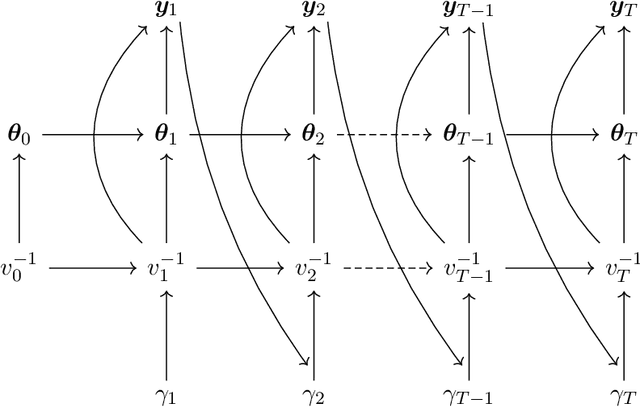

We develop an approach for fully Bayesian learning and calibration of spatiotemporal dynamical mechanistic models based on noisy observations. Calibration is achieved by melding information from observed data with simulated computer experiments from the mechanistic system. The joint melding makes use of both Gaussian and non-Gaussian state-space methods as well as Gaussian process regression. Assuming the dynamical system is controlled by a finite collection of inputs, Gaussian process regression learns the effect of these parameters through a number of training runs, driving the stochastic innovations of the spatiotemporal state-space component. This enables efficient modeling of the dynamics over space and time. Through reduced-rank Gaussian processes and a conjugate model specification, our methodology is applicable to large-scale calibration and inverse problems. Our method is general, extensible, and capable of learning a wide range of dynamical systems with potential model misspecification. We demonstrate this flexibility through solving inverse problems arising in the analysis of ordinary and partial nonlinear differential equations and, in addition, to a black-box computer model generating spatiotemporal dynamics across a network.
voxel2vec: A Natural Language Processing Approach to Learning Distributed Representations for Scientific Data
Jul 11, 2022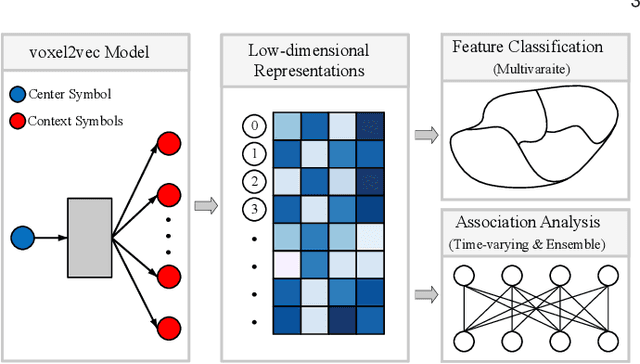


Relationships in scientific data, such as the numerical and spatial distribution relations of features in univariate data, the scalar-value combinations' relations in multivariate data, and the association of volumes in time-varying and ensemble data, are intricate and complex. This paper presents voxel2vec, a novel unsupervised representation learning model, which is used to learn distributed representations of scalar values/scalar-value combinations in a low-dimensional vector space. Its basic assumption is that if two scalar values/scalar-value combinations have similar contexts, they usually have high similarity in terms of features. By representing scalar values/scalar-value combinations as symbols, voxel2vec learns the similarity between them in the context of spatial distribution and then allows us to explore the overall association between volumes by transfer prediction. We demonstrate the usefulness and effectiveness of voxel2vec by comparing it with the isosurface similarity map of univariate data and applying the learned distributed representations to feature classification for multivariate data and to association analysis for time-varying and ensemble data.
Accelerating SGD for Highly Ill-Conditioned Huge-Scale Online Matrix Completion
Aug 24, 2022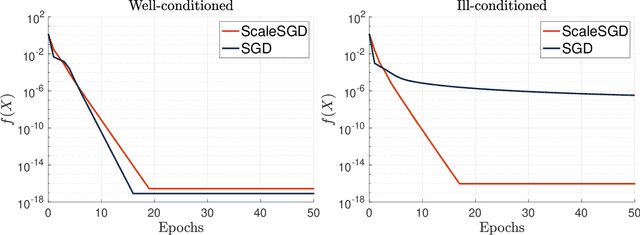
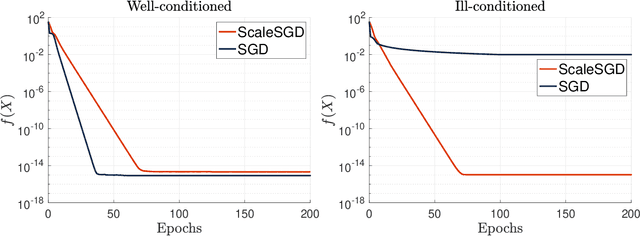
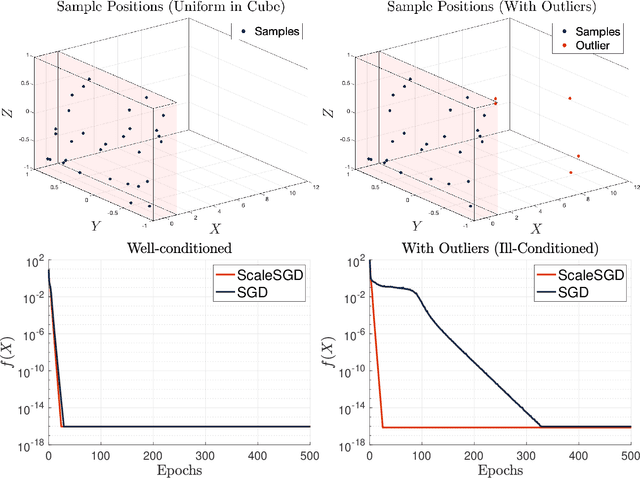
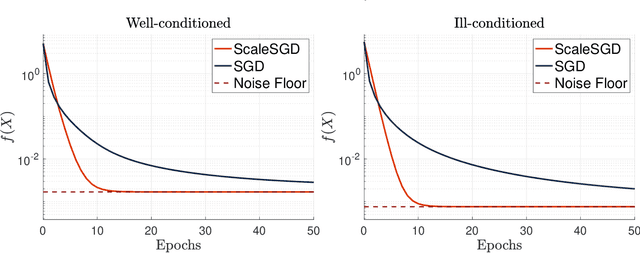
The matrix completion problem seeks to recover a $d\times d$ ground truth matrix of low rank $r\ll d$ from observations of its individual elements. Real-world matrix completion is often a huge-scale optimization problem, with $d$ so large that even the simplest full-dimension vector operations with $O(d)$ time complexity become prohibitively expensive. Stochastic gradient descent (SGD) is one of the few algorithms capable of solving matrix completion on a huge scale, and can also naturally handle streaming data over an evolving ground truth. Unfortunately, SGD experiences a dramatic slow-down when the underlying ground truth is ill-conditioned; it requires at least $O(\kappa\log(1/\epsilon))$ iterations to get $\epsilon$-close to ground truth matrix with condition number $\kappa$. In this paper, we propose a preconditioned version of SGD that preserves all the favorable practical qualities of SGD for huge-scale online optimization while also making it agnostic to $\kappa$. For a symmetric ground truth and the Root Mean Square Error (RMSE) loss, we prove that the preconditioned SGD converges to $\epsilon$-accuracy in $O(\log(1/\epsilon))$ iterations, with a rapid linear convergence rate as if the ground truth were perfectly conditioned with $\kappa=1$. In our numerical experiments, we observe a similar acceleration for ill-conditioned matrix completion under the 1-bit cross-entropy loss, as well as pairwise losses such as the Bayesian Personalized Ranking (BPR) loss.
GoodBye WaveNet -- A Language Model for Raw Audio with Context of 1/2 Million Samples
Jun 16, 2022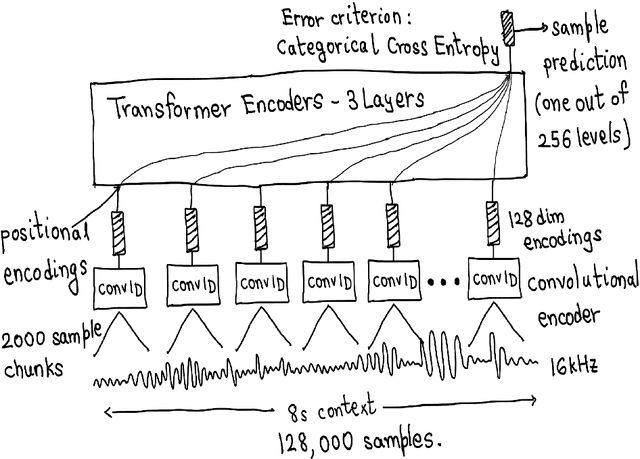
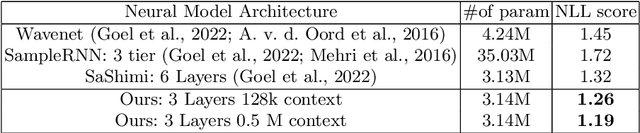
Modeling long-term dependencies for audio signals is a particularly challenging problem, as even small-time scales yield on the order of a hundred thousand samples. With the recent advent of Transformers, neural architectures became good at modeling dependencies over longer time scales, but they suffered from quadratic constraints to scale them. We propose a generative auto-regressive architecture that can model audio waveforms over quite a large context, greater than 500,000 samples. Our work is adapted to learn time dependencies by learning a latent representation by a CNN front-end, and then learning dependencies over these representations using Transformer encoders, fully trained end-to-end: thereby allowing to learn representations as it deems fit for the next sample. Unlike previous works that compared different time scales to show improvement, we use a standard dataset, with the same number of parameters/context to show improvements. We achieve a state-of-the-art performance as compared to other approaches such as Wavenet, SaSHMI, and Sample-RNN on a standard dataset for modeling long-term structure. This work gives very exciting direction for the field, given improvements in context modeling that can be scaled with more data, as well as potentially better results by using billions/trillions of parameters.
Building for Tomorrow: Assessing the Temporal Persistence of Text Classifiers
May 19, 2022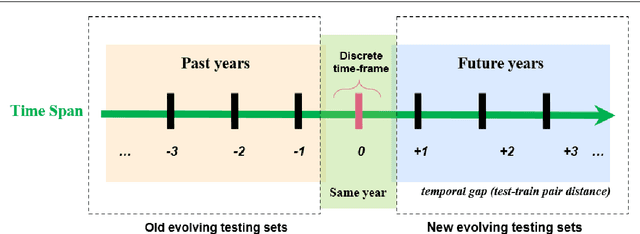
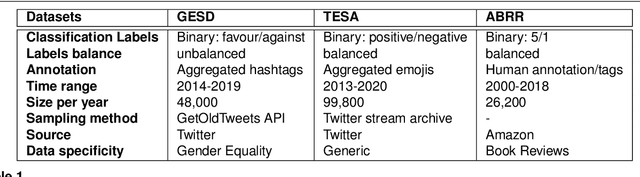
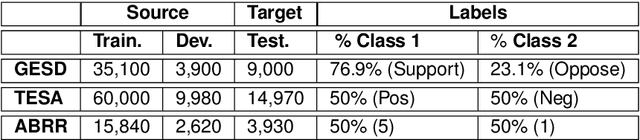
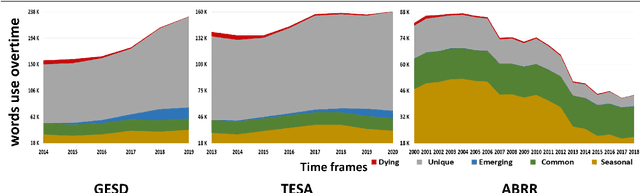
Where performance of text classification models drops over time due to changes in data, development of models whose performance persists over time is important. An ability to predict a model's ability to persist over time can help design models that can be effectively used over a longer period of time. In this paper, we look at this problem from a practical perspective by assessing the ability of a wide range of language models and classification algorithms to persist over time, as well as how dataset characteristics can help predict the temporal stability of different models. We perform longitudinal classification experiments on three datasets spanning between 6 and 19 years, and involving diverse tasks and types of data. We find that one can estimate how a model will retain its performance over time based on (i) how well the model performs over a restricted time period and its extrapolation to a longer time period, and (ii) the linguistic characteristics of the dataset, such as the familiarity score between subsets from different years. Findings from these experiments have important implications for the design of text classification models with the aim of preserving performance over time.
Ultra Lite Convolutional Neural Network for Automatic Modulation Classification
Aug 09, 2022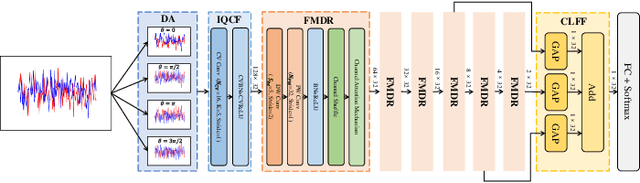
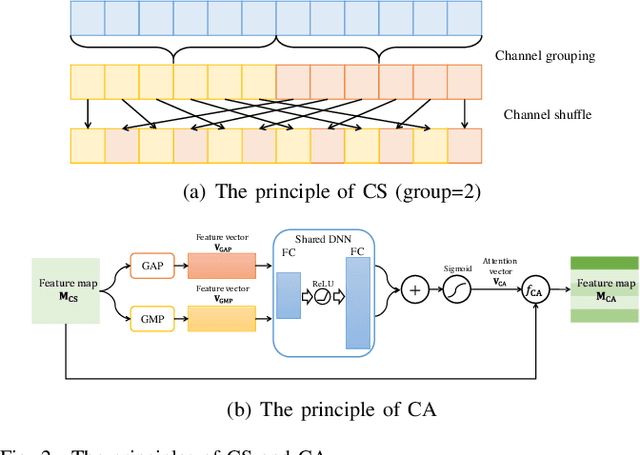
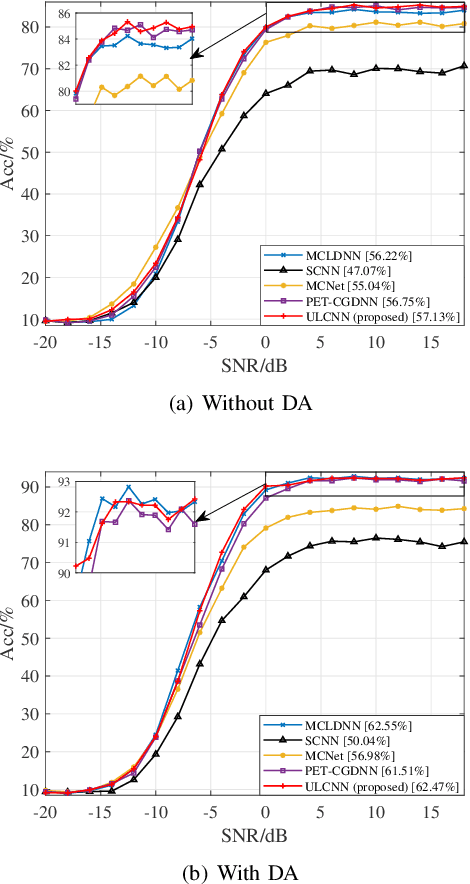
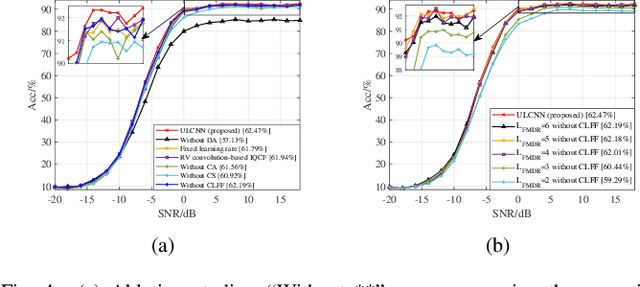
Automatic modulation classification (AMC) is a key technique for desiging non-cooperative communication systems, and deep learning (DL) is applied effectively into AMC for improving the classification accuracy.However, most of the DL-based AMC methods have a large number of parameters and high computational complexity, and they cannot be directly applied into scenarios with limited computing power and storage space.In this paper, we propose a lightweight and low-complexity AMC method using ultra lite convolutional neural network (ULCNN), which is based on multiple tricks, including data augmentation, complex-valued convolution, separable convolution, channel attention, channel shuffle. Simulation results demonstrate that our proposed ULCNN-based AMC method achieves the average accuracy of 62.47\% on RML2016.10a and only 9,751 parameters. Moreover, ULCNN is verified on a typical edge device (Raspberry Pi), where interference time per sample is about 0.775 ms. The reproducible code can be download from GitHub at https://github.com/BeechburgPieStar/Ultra-Lite-Convolutional-Neural-Network-for-Automatic-Modulation-Classification .
Towards Real-World Video Deblurring by Exploring Blur Formation Process
Aug 28, 2022

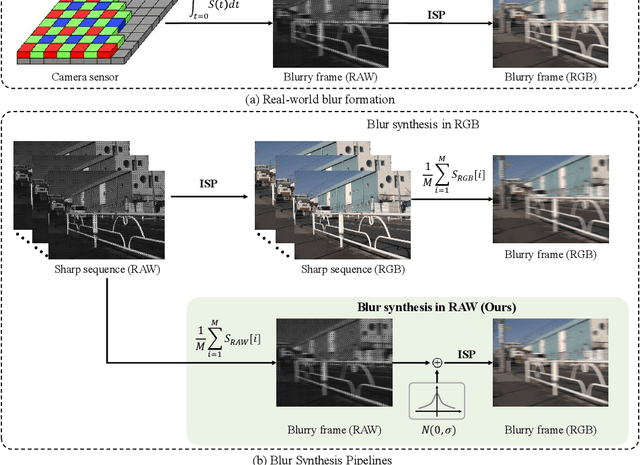
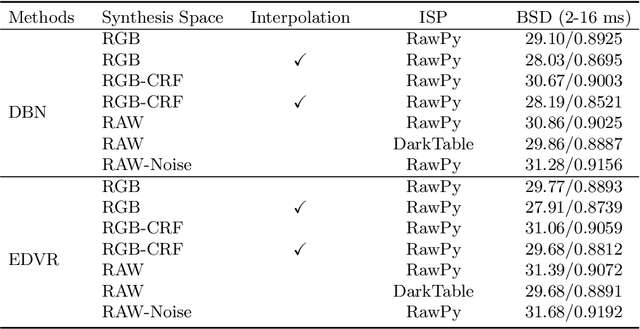
This paper aims at exploring how to synthesize close-to-real blurs that existing video deblurring models trained on them can generalize well to real-world blurry videos. In recent years, deep learning-based approaches have achieved promising success on video deblurring task. However, the models trained on existing synthetic datasets still suffer from generalization problems over real-world blurry scenarios with undesired artifacts. The factors accounting for the failure remain unknown. Therefore, we revisit the classical blur synthesis pipeline and figure out the possible reasons, including shooting parameters, blur formation space, and image signal processor~(ISP). To analyze the effects of these potential factors, we first collect an ultra-high frame-rate (940 FPS) RAW video dataset as the data basis to synthesize various kinds of blurs. Then we propose a novel realistic blur synthesis pipeline termed as RAW-Blur by leveraging blur formation cues. Through numerous experiments, we demonstrate that synthesizing blurs in the RAW space and adopting the same ISP as the real-world testing data can effectively eliminate the negative effects of synthetic data. Furthermore, the shooting parameters of the synthesized blurry video, e.g., exposure time and frame-rate play significant roles in improving the performance of deblurring models. Impressively, the models trained on the blurry data synthesized by the proposed RAW-Blur pipeline can obtain more than 5dB PSNR gain against those trained on the existing synthetic blur datasets. We believe the novel realistic synthesis pipeline and the corresponding RAW video dataset can help the community to easily construct customized blur datasets to improve real-world video deblurring performance largely, instead of laboriously collecting real data pairs.
Convolutional Neural Networks with A Topographic Representation Module for EEG-Based Brain-Computer Interfaces
Aug 30, 2022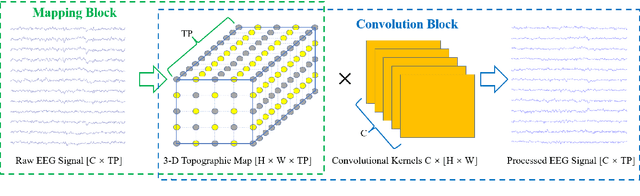
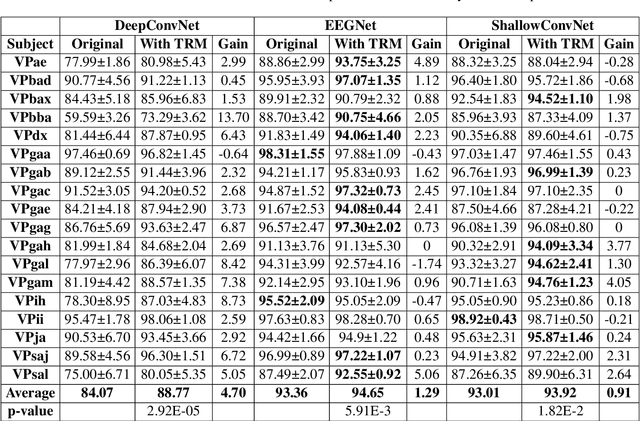
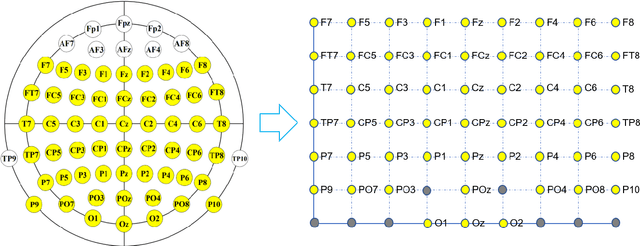
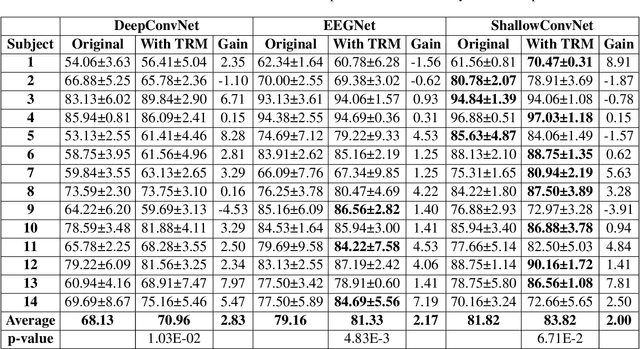
Objective: Convolutional Neural Networks (CNNs) have shown great potential in the field of Brain-Computer Interfaces (BCIs). The raw Electroencephalogram (EEG) signal is usually represented as 2-Dimensional (2-D) matrix composed of channels and time points, which ignores the spatial topological information. Our goal is to make the CNN with the raw EEG signal as input have the ability to learn EEG spatial topological features, and improve its performance while essentially maintaining its original structure. Methods:We propose an EEG Topographic Representation Module (TRM). This module consists of (1) a mapping block from the raw EEG signal to a 3-D topographic map and (2) a convolution block from the topographic map to an output of the same size as input. According to the size of the kernel used in the convolution block, we design 2 types of TRMs, namely TRM-(5,5) and TRM-(3,3). We embed the TRM into 3 widely used CNNs, and tested them on 2 publicly available datasets (Emergency Braking During Simulated Driving Dataset (EBDSDD), and High Gamma Dataset (HGD)). Results: The results show that the classification accuracies of all 3 CNNs are improved on both datasets after using the TRM. With TRM-(5,5), the average accuracies of DeepConvNet, EEGNet and ShallowConvNet are improved by 6.54%, 1.72% and 2.07% on EBDSDD, and by 6.05%, 3.02% and 5.14% on HGD, respectively; with TRM-(3,3), they are improved by 7.76%, 1.71% and 2.17% on EBDSDD, and by 7.61%, 5.06% and 6.28% on HGD, respectively. Significance: We improve the classification performance of 3 CNNs on 2 datasets by the use of TRM, indicating that it has the capability to mine the EEG spatial topological information. In addition, since the output of TRM has the same size as the input, CNNs with the raw EEG signal as input can use this module without changing their original structures.
Recycling an anechoic pre-trained speech separation deep neural network for binaural dereverberation of a single source
Aug 09, 2022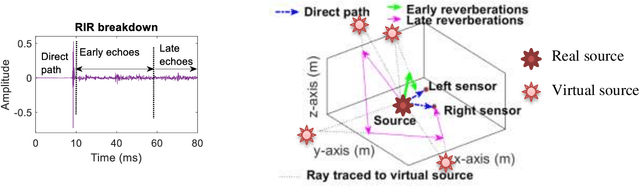

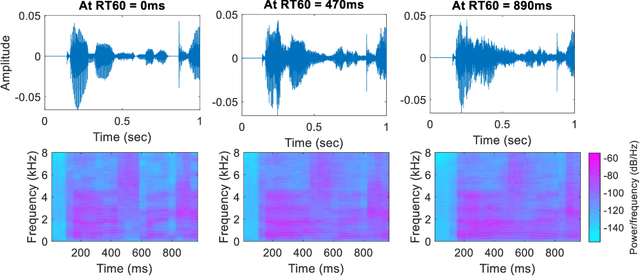

Reverberation results in reduced intelligibility for both normal and hearing-impaired listeners. This paper presents a novel psychoacoustic approach of dereverberation of a single speech source by recycling a pre-trained binaural anechoic speech separation neural network. As training the deep neural network (DNN) is a lengthy and computationally expensive process, the advantage of using a pre-trained separation network for dereverberation is that the network does not need to be retrained, saving both time and computational resources. The interaural cues of a reverberant source are given to this pretrained neural network to discriminate between the direct path signal and the reverberant speech. The results show an average improvement of 1.3% in signal intelligibility, 0.83 dB in SRMR (signal to reverberation energy ratio) and 0.16 points in perceptual evaluation of speech quality (PESQ) over other state-of-the-art signal processing dereverberation algorithms and 14% in intelligibility and 0.35 points in quality over orthogonal matching pursuit with spectral subtraction (OSS), a machine learning based dereverberation algorithm.
GraTO: Graph Neural Network Framework Tackling Over-smoothing with Neural Architecture Search
Aug 18, 2022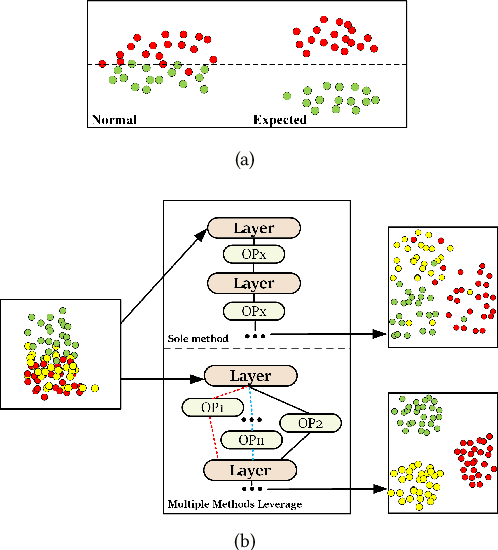

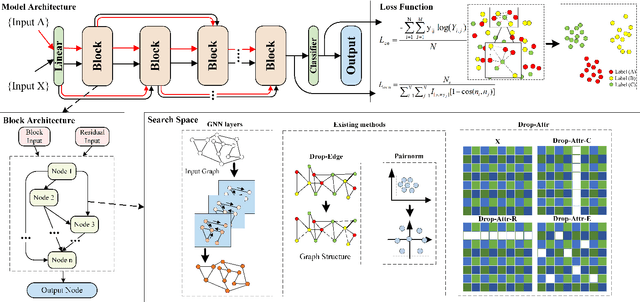

Current Graph Neural Networks (GNNs) suffer from the over-smoothing problem, which results in indistinguishable node representations and low model performance with more GNN layers. Many methods have been put forward to tackle this problem in recent years. However, existing tackling over-smoothing methods emphasize model performance and neglect the over-smoothness of node representations. Additional, different approaches are applied one at a time, while there lacks an overall framework to jointly leverage multiple solutions to the over-smoothing challenge. To solve these problems, we propose GraTO, a framework based on neural architecture search to automatically search for GNNs architecture. GraTO adopts a novel loss function to facilitate striking a balance between model performance and representation smoothness. In addition to existing methods, our search space also includes DropAttribute, a novel scheme for alleviating the over-smoothing challenge, to fully leverage diverse solutions. We conduct extensive experiments on six real-world datasets to evaluate GraTo, which demonstrates that GraTo outperforms baselines in the over-smoothing metrics and achieves competitive performance in accuracy. GraTO is especially effective and robust with increasing numbers of GNN layers. Further experiments bear out the quality of node representations learned with GraTO and the effectiveness of model architecture. We make cide of GraTo available at Github (\url{https://github.com/fxsxjtu/GraTO}).