 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Stream-based active learning with linear models
Jul 20, 2022
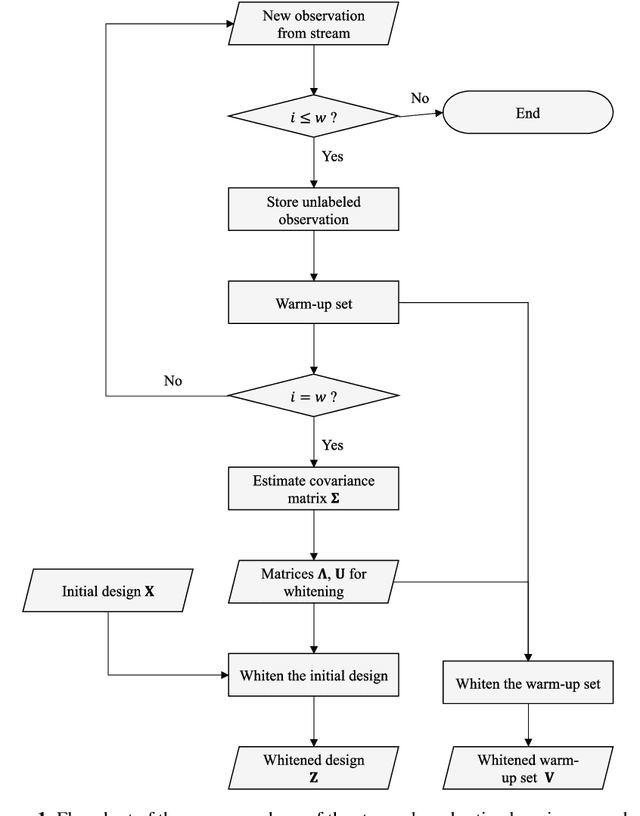

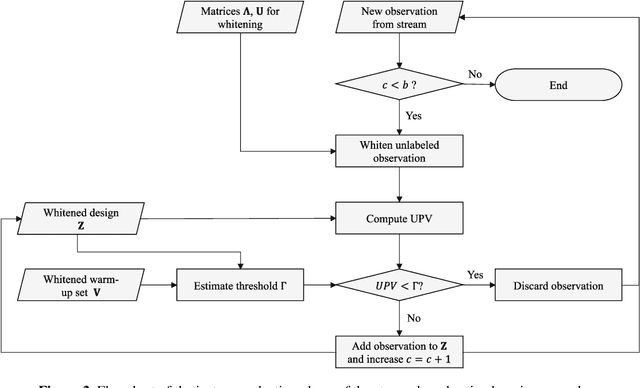
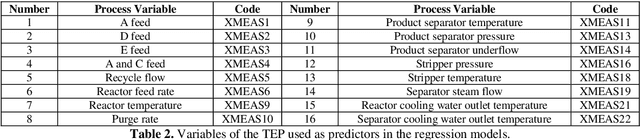
The proliferation of automated data collection schemes and the advances in sensorics are increasing the amount of data we are able to monitor in real-time. However, given the high annotation costs and the time required by quality inspections, data is often available in an unlabeled form. This is fostering the use of active learning for the development of soft sensors and predictive models. In production, instead of performing random inspections to obtain product information, labels are collected by evaluating the information content of the unlabeled data. Several query strategy frameworks for regression have been proposed in the literature but most of the focus has been dedicated to the static pool-based scenario. In this work, we propose a new strategy for the stream-based scenario, where instances are sequentially offered to the learner, which must instantaneously decide whether to perform the quality check to obtain the label or discard the instance. The approach is inspired by the optimal experimental design theory and the iterative aspect of the decision-making process is tackled by setting a threshold on the informativeness of the unlabeled data points. The proposed approach is evaluated using numerical simulations and the Tennessee Eastman Process simulator. The results confirm that selecting the examples suggested by the proposed algorithm allows for a faster reduction in the prediction error.
Collaborative Remote Control of Unmanned Ground Vehicles in Virtual Reality
Aug 24, 2022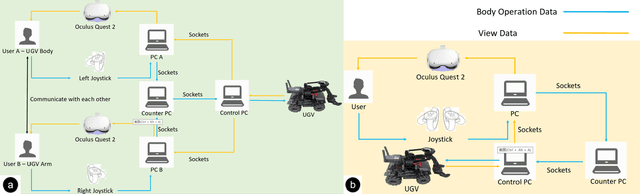
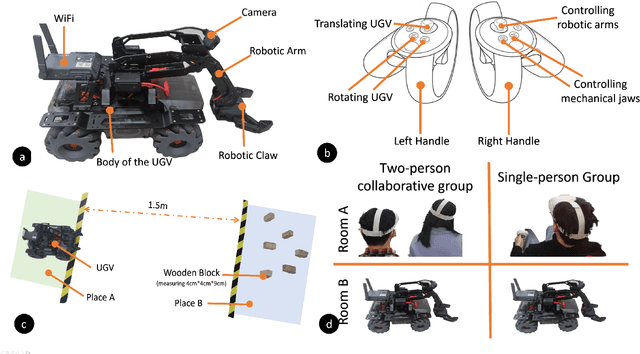
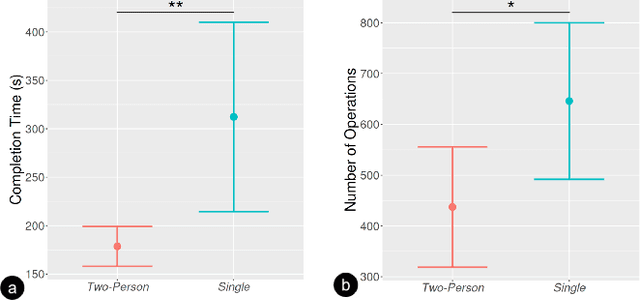
Virtual reality (VR) technology is commonly used in entertainment applications; however, it has also been deployed in practical applications in more serious aspects of our lives, such as safety. To support people working in dangerous industries, VR can ensure operators manipulate standardized tasks and work collaboratively to deal with potential risks. Surprisingly, little research has focused on how people can collaboratively work in VR environments. Few studies have paid attention to the cognitive load of operators in their collaborative tasks. Once task demands become complex, many researchers focus on optimizing the design of the interaction interfaces to reduce the cognitive load on the operator. That approach could be of merit; however, it can actually subject operators to a more significant cognitive load and potentially more errors and a failure of collaboration. In this paper, we propose a new collaborative VR system to support two teleoperators working in the VR environment to remote control an uncrewed ground vehicle. We use a compared experiment to evaluate the collaborative VR systems, focusing on the time spent on tasks and the total number of operations. Our results show that the total number of processes and the cognitive load during operations were significantly lower in the two-person group than in the single-person group. Our study sheds light on designing VR systems to support collaborative work with respect to the flow of work of teleoperators instead of simply optimizing the design outcomes.
The Correlated Arc Orienteering Problem
Aug 16, 2022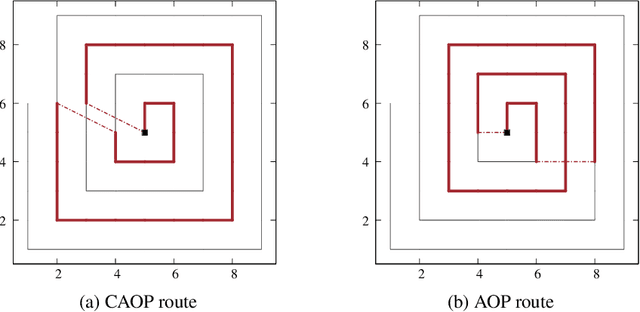
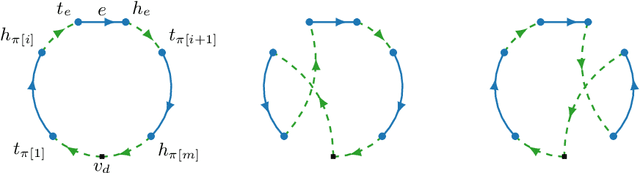
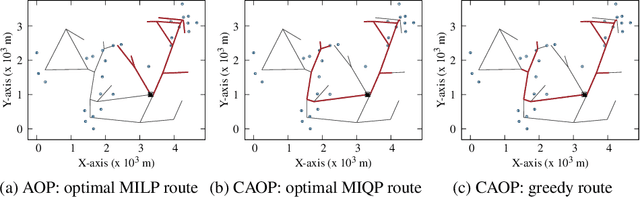
This paper introduces the correlated arc orienteering problem (CAOP), where the task is to find routes for a team of robots to maximize the collection of rewards associated with features in the environment. These features can be one-dimensional or points in the environment, and can have spatial correlation, i.e., visiting a feature in the environment may provide a portion of the reward associated with a correlated feature. A robot incurs costs as it traverses the environment, and the total cost for its route is limited by a resource constraint such as battery life or operation time. As environments are often large, we permit multiple depots where the robots must start and end their routes. The CAOP generalizes the correlated orienteering problem (COP), where the rewards are only associated with point features, and the arc orienteering problem (AOP), where the rewards are not spatially correlated. We formulate a mixed integer quadratic program (MIQP) that formalizes the problem and gives optimal solutions. However, the problem is NP-hard, and therefore we develop an efficient greedy constructive algorithm. We illustrate the problem with two different applications: informative path planning for methane gas leak detection and coverage of road networks.
Energy-efficient Dynamic-subarray with Fixed True-time-delay Design for Terahertz Wideband Hybrid Beamforming
Feb 07, 2022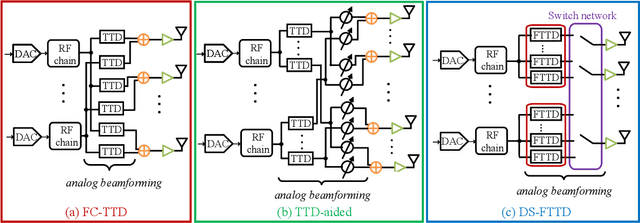
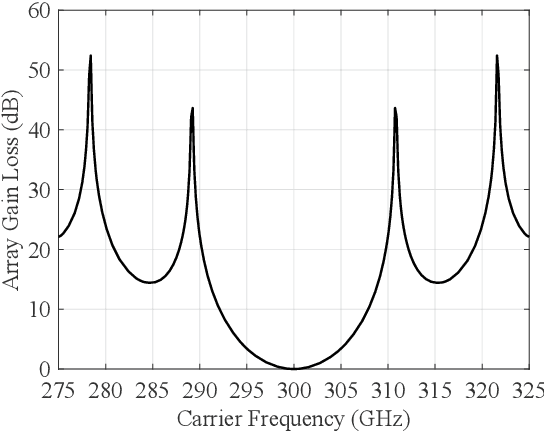
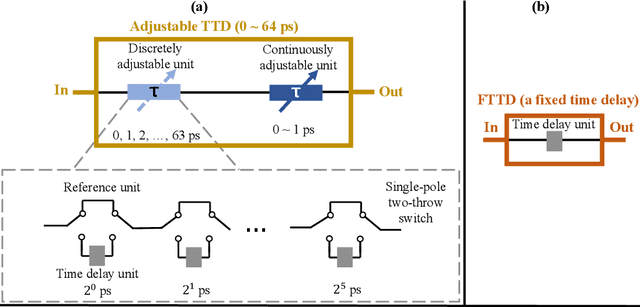
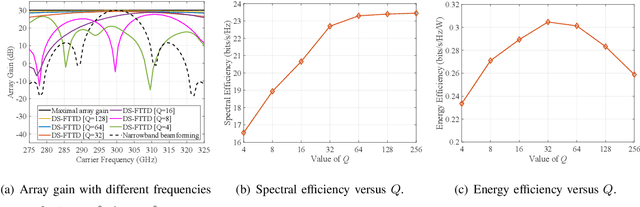
Hybrid beamforming for Terahertz (THz) ultra-massive multiple-input multiple-output (UM-MIMO) systems is a promising technology for 6G space-air-ground integrated networks, which can overcome huge propagation loss and offer unprecedented data rates. With ultra-wide bandwidth and ultra-large-scale antennas array in THz band, the beam squint becomes one of the critical problems which could reduce the array gain and degrade the data rate substantially. However, the traditional phase-shifters-based hybrid beamforming architectures cannot tackle this issue due to the frequency-flat property of the phase shifters. In this paper, to combat the beam squint while keeping high energy efficiency, a novel dynamic-subarray with fixed true-time-delay (DS-FTTD) architecture is proposed. Compared to the existing studies which use the complicated adjustable TTDs, the DS-FTTD architecture has lower power consumption and hardware complexity, thanks to the low-cost FTTDs. Furthermore, a low-complexity row-decomposition (RD) algorithm is proposed to design hybrid beamforming matrices for the DS-FTTD architecture. Extensive simulation results show that, by using the RD algorithm, the DS-FTTD architecture achieves near-optimal array gain and significantly higher energy efficiency than the existing architectures. Moreover, the spectral efficiency of DS-FTTD architecture with the RD algorithm is robust to the imperfect channel state information.
Low Rank Approximation for General Tensor Networks
Jul 15, 2022

We study the problem of approximating a given tensor with $q$ modes $A \in \mathbb{R}^{n \times \ldots \times n}$ with an arbitrary tensor network of rank $k$ -- that is, a graph $G = (V, E)$, where $|V| = q$, together with a collection of tensors $\{U_v \mid v \in V\}$ which are contracted in the manner specified by $G$ to obtain a tensor $T$. For each mode of $U_v$ corresponding to an edge incident to $v$, the dimension is $k$, and we wish to find $U_v$ such that the Frobenius norm distance between $T$ and $A$ is minimized. This generalizes a number of well-known tensor network decompositions, such as the Tensor Train, Tensor Ring, Tucker, and PEPS decompositions. We approximate $A$ by a binary tree network $T'$ with $O(q)$ cores, such that the dimension on each edge of this network is at most $\widetilde{O}(k^{O(dt)} \cdot q/\varepsilon)$, where $d$ is the maximum degree of $G$ and $t$ is its treewidth, such that $\|A - T'\|_F^2 \leq (1 + \varepsilon) \|A - T\|_F^2$. The running time of our algorithm is $O(q \cdot \text{nnz}(A)) + n \cdot \text{poly}(k^{dt}q/\varepsilon)$, where $\text{nnz}(A)$ is the number of nonzero entries of $A$. Our algorithm is based on a new dimensionality reduction technique for tensor decomposition which may be of independent interest. We also develop fixed-parameter tractable $(1 + \varepsilon)$-approximation algorithms for Tensor Train and Tucker decompositions, improving the running time of Song, Woodruff and Zhong (SODA, 2019) and avoiding the use of generic polynomial system solvers. We show that our algorithms have a nearly optimal dependence on $1/\varepsilon$ assuming that there is no $O(1)$-approximation algorithm for the $2 \to 4$ norm with better running time than brute force. Finally, we give additional results for Tucker decomposition with robust loss functions, and fixed-parameter tractable CP decomposition.
Transforming Autoregression: Interpretable and Expressive Time Series Forecast
Oct 15, 2021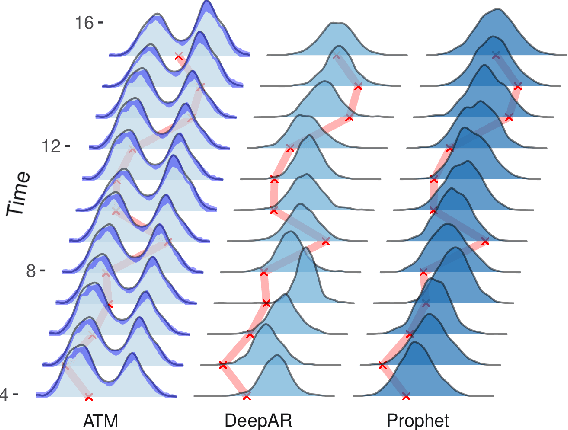

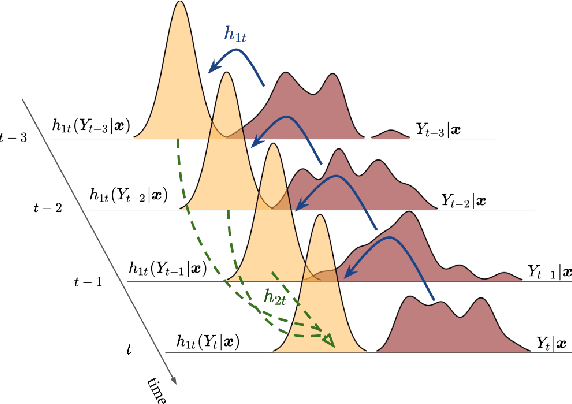

Probabilistic forecasting of time series is an important matter in many applications and research fields. In order to draw conclusions from a probabilistic forecast, we must ensure that the model class used to approximate the true forecasting distribution is expressive enough. Yet, characteristics of the model itself, such as its uncertainty or its general functioning are not of lesser importance. In this paper, we propose Autoregressive Transformation Models (ATMs), a model class inspired from various research directions such as normalizing flows and autoregressive models. ATMs unite expressive distributional forecasts using a semi-parametric distribution assumption with an interpretable model specification and allow for uncertainty quantification based on (asymptotic) Maximum Likelihood theory. We demonstrate the properties of ATMs both theoretically and through empirical evaluation on several simulated and real-world forecasting datasets.
A Gentle Introduction and Survey on Computing with Words (CWW) Methodologies
Aug 12, 2022
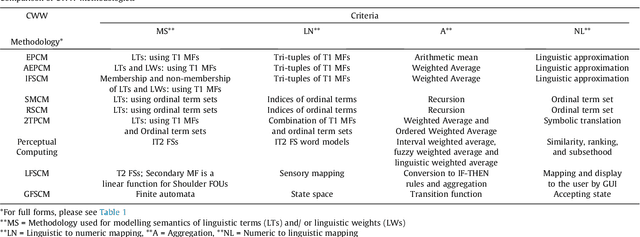
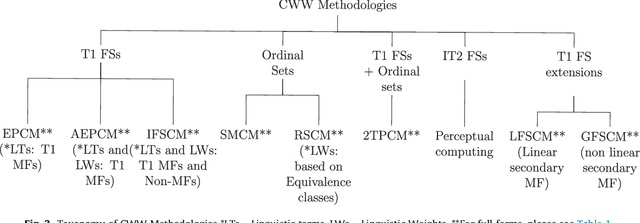
Human beings have an inherent capability to use linguistic information (LI) seamlessly even though it is vague and imprecise. Computing with Words (CWW) was proposed to impart computing systems with this capability of human beings. The interest in the field of CWW is evident from a number of publications on various CWW methodologies. These methodologies use different ways to model the semantics of the LI. However, to the best of our knowledge, the literature on these methodologies is mostly scattered and does not give an interested researcher a comprehensive but gentle guide about the notion and utility of these methodologies. Hence, to introduce the foundations and state-of-the-art CWW methodologies, we provide a concise but a wide-ranging coverage of them in a simple and easy to understand manner. We feel that the simplicity with which we give a high-quality review and introduction to the CWW methodologies is very useful for investigators, especially those embarking on the use of CWW for the first time. We also provide future research directions to build upon for the interested and motivated researchers.
Dynamic Bayesian Learning and Calibration of Spatiotemporal Mechanistic System
Aug 12, 2022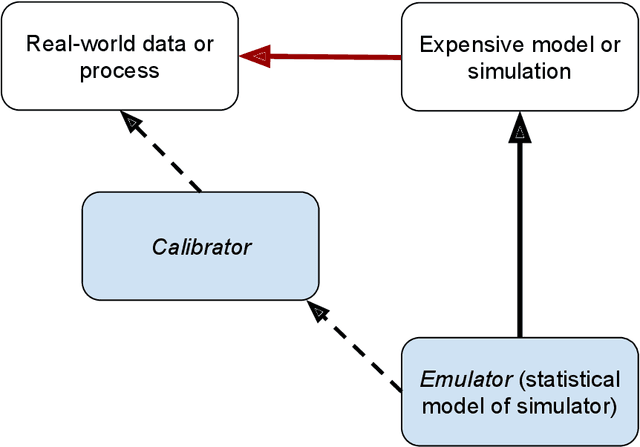
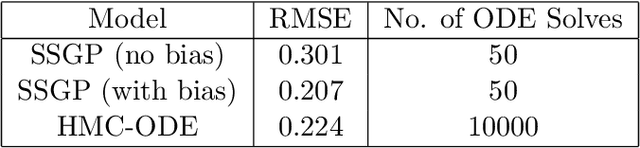
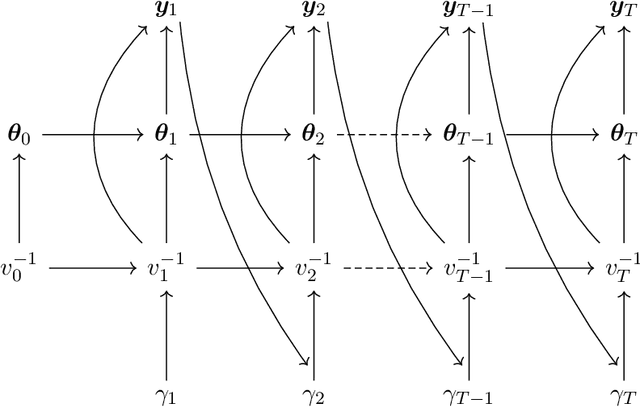

We develop an approach for fully Bayesian learning and calibration of spatiotemporal dynamical mechanistic models based on noisy observations. Calibration is achieved by melding information from observed data with simulated computer experiments from the mechanistic system. The joint melding makes use of both Gaussian and non-Gaussian state-space methods as well as Gaussian process regression. Assuming the dynamical system is controlled by a finite collection of inputs, Gaussian process regression learns the effect of these parameters through a number of training runs, driving the stochastic innovations of the spatiotemporal state-space component. This enables efficient modeling of the dynamics over space and time. Through reduced-rank Gaussian processes and a conjugate model specification, our methodology is applicable to large-scale calibration and inverse problems. Our method is general, extensible, and capable of learning a wide range of dynamical systems with potential model misspecification. We demonstrate this flexibility through solving inverse problems arising in the analysis of ordinary and partial nonlinear differential equations and, in addition, to a black-box computer model generating spatiotemporal dynamics across a network.
Accelerating SGD for Highly Ill-Conditioned Huge-Scale Online Matrix Completion
Aug 24, 2022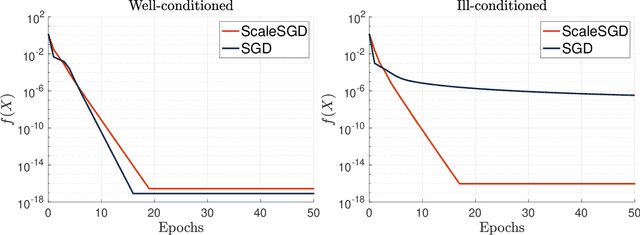
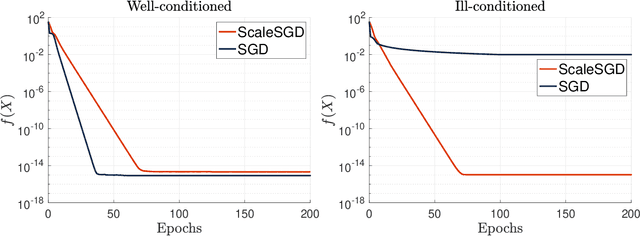
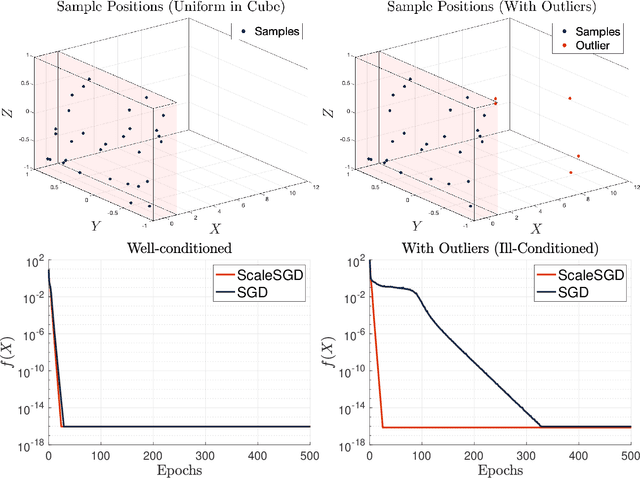
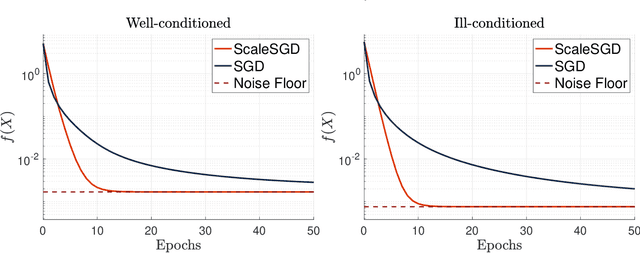
The matrix completion problem seeks to recover a $d\times d$ ground truth matrix of low rank $r\ll d$ from observations of its individual elements. Real-world matrix completion is often a huge-scale optimization problem, with $d$ so large that even the simplest full-dimension vector operations with $O(d)$ time complexity become prohibitively expensive. Stochastic gradient descent (SGD) is one of the few algorithms capable of solving matrix completion on a huge scale, and can also naturally handle streaming data over an evolving ground truth. Unfortunately, SGD experiences a dramatic slow-down when the underlying ground truth is ill-conditioned; it requires at least $O(\kappa\log(1/\epsilon))$ iterations to get $\epsilon$-close to ground truth matrix with condition number $\kappa$. In this paper, we propose a preconditioned version of SGD that preserves all the favorable practical qualities of SGD for huge-scale online optimization while also making it agnostic to $\kappa$. For a symmetric ground truth and the Root Mean Square Error (RMSE) loss, we prove that the preconditioned SGD converges to $\epsilon$-accuracy in $O(\log(1/\epsilon))$ iterations, with a rapid linear convergence rate as if the ground truth were perfectly conditioned with $\kappa=1$. In our numerical experiments, we observe a similar acceleration for ill-conditioned matrix completion under the 1-bit cross-entropy loss, as well as pairwise losses such as the Bayesian Personalized Ranking (BPR) loss.
Towards Real-World Video Deblurring by Exploring Blur Formation Process
Aug 28, 2022

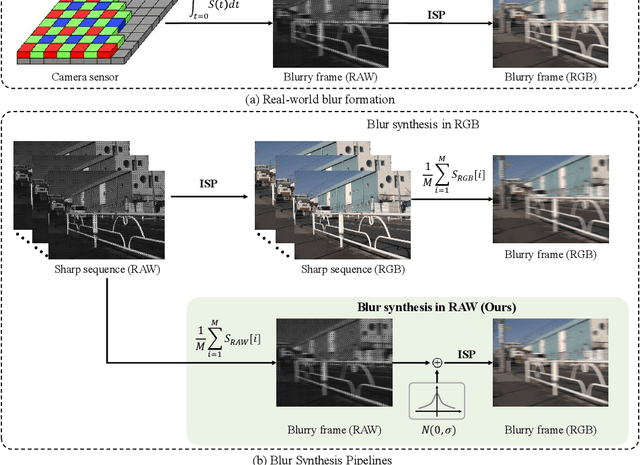
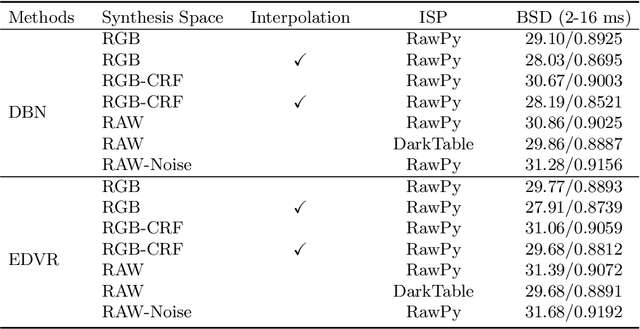
This paper aims at exploring how to synthesize close-to-real blurs that existing video deblurring models trained on them can generalize well to real-world blurry videos. In recent years, deep learning-based approaches have achieved promising success on video deblurring task. However, the models trained on existing synthetic datasets still suffer from generalization problems over real-world blurry scenarios with undesired artifacts. The factors accounting for the failure remain unknown. Therefore, we revisit the classical blur synthesis pipeline and figure out the possible reasons, including shooting parameters, blur formation space, and image signal processor~(ISP). To analyze the effects of these potential factors, we first collect an ultra-high frame-rate (940 FPS) RAW video dataset as the data basis to synthesize various kinds of blurs. Then we propose a novel realistic blur synthesis pipeline termed as RAW-Blur by leveraging blur formation cues. Through numerous experiments, we demonstrate that synthesizing blurs in the RAW space and adopting the same ISP as the real-world testing data can effectively eliminate the negative effects of synthetic data. Furthermore, the shooting parameters of the synthesized blurry video, e.g., exposure time and frame-rate play significant roles in improving the performance of deblurring models. Impressively, the models trained on the blurry data synthesized by the proposed RAW-Blur pipeline can obtain more than 5dB PSNR gain against those trained on the existing synthetic blur datasets. We believe the novel realistic synthesis pipeline and the corresponding RAW video dataset can help the community to easily construct customized blur datasets to improve real-world video deblurring performance largely, instead of laboriously collecting real data pairs.