 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Shielding Federated Learning Systems against Inference Attacks with ARM TrustZone
Aug 19, 2022

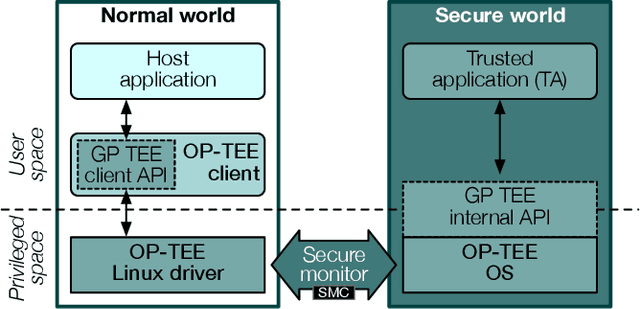
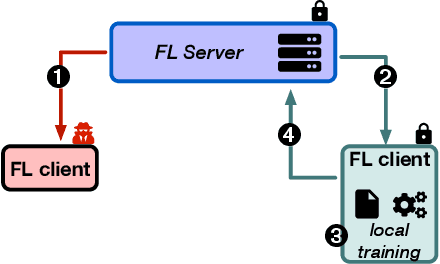
Federated Learning (FL) opens new perspectives for training machine learning models while keeping personal data on the users premises. Specifically, in FL, models are trained on the users devices and only model updates (i.e., gradients) are sent to a central server for aggregation purposes. However, the long list of inference attacks that leak private data from gradients, published in the recent years, have emphasized the need of devising effective protection mechanisms to incentivize the adoption of FL at scale. While there exist solutions to mitigate these attacks on the server side, little has been done to protect users from attacks performed on the client side. In this context, the use of Trusted Execution Environments (TEEs) on the client side are among the most proposing solutions. However, existing frameworks (e.g., DarkneTZ) require statically putting a large portion of the machine learning model into the TEE to effectively protect against complex attacks or a combination of attacks. We present GradSec, a solution that allows protecting in a TEE only sensitive layers of a machine learning model, either statically or dynamically, hence reducing both the TCB size and the overall training time by up to 30% and 56%, respectively compared to state-of-the-art competitors.
Transforming Autoregression: Interpretable and Expressive Time Series Forecast
Oct 15, 2021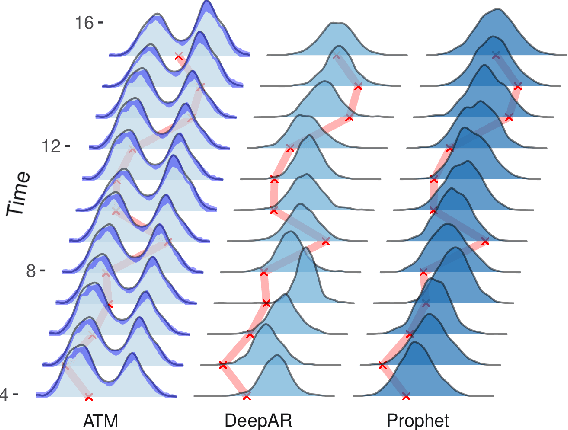

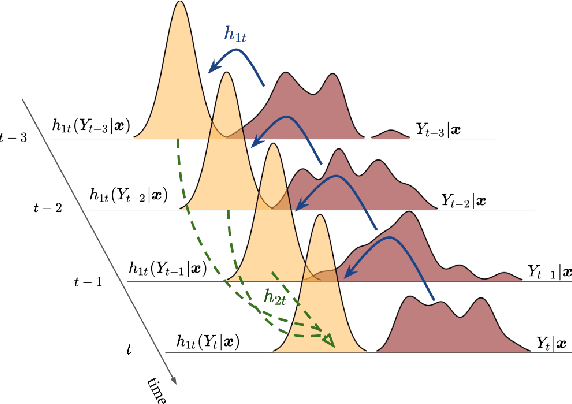

Probabilistic forecasting of time series is an important matter in many applications and research fields. In order to draw conclusions from a probabilistic forecast, we must ensure that the model class used to approximate the true forecasting distribution is expressive enough. Yet, characteristics of the model itself, such as its uncertainty or its general functioning are not of lesser importance. In this paper, we propose Autoregressive Transformation Models (ATMs), a model class inspired from various research directions such as normalizing flows and autoregressive models. ATMs unite expressive distributional forecasts using a semi-parametric distribution assumption with an interpretable model specification and allow for uncertainty quantification based on (asymptotic) Maximum Likelihood theory. We demonstrate the properties of ATMs both theoretically and through empirical evaluation on several simulated and real-world forecasting datasets.
Blind-Spot Collision Detection System for Commercial Vehicles Using Multi Deep CNN Architecture
Aug 19, 2022



Buses and heavy vehicles have more blind spots compared to cars and other road vehicles due to their large sizes. Therefore, accidents caused by these heavy vehicles are more fatal and result in severe injuries to other road users. These possible blind-spot collisions can be identified early using vision-based object detection approaches. Yet, the existing state-of-the-art vision-based object detection models rely heavily on a single feature descriptor for making decisions. In this research, the design of two convolutional neural networks (CNNs) based on high-level feature descriptors and their integration with faster R-CNN is proposed to detect blind-spot collisions for heavy vehicles. Moreover, a fusion approach is proposed to integrate two pre-trained networks (i.e., Resnet 50 and Resnet 101) for extracting high level features for blind-spot vehicle detection. The fusion of features significantly improves the performance of faster R-CNN and outperformed the existing state-of-the-art methods. Both approaches are validated on a self-recorded blind-spot vehicle detection dataset for buses and an online LISA dataset for vehicle detection. For both proposed approaches, a false detection rate (FDR) of 3.05% and 3.49% are obtained for the self recorded dataset, making these approaches suitable for real time applications.
TCAM: Temporal Class Activation Maps for Object Localization in Weakly-Labeled Unconstrained Videos
Aug 30, 2022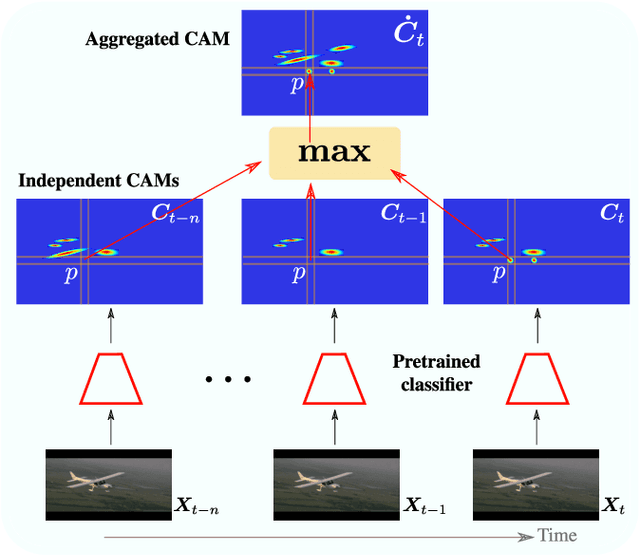
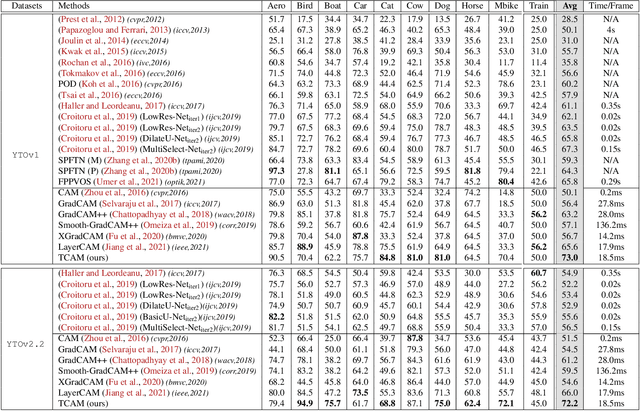
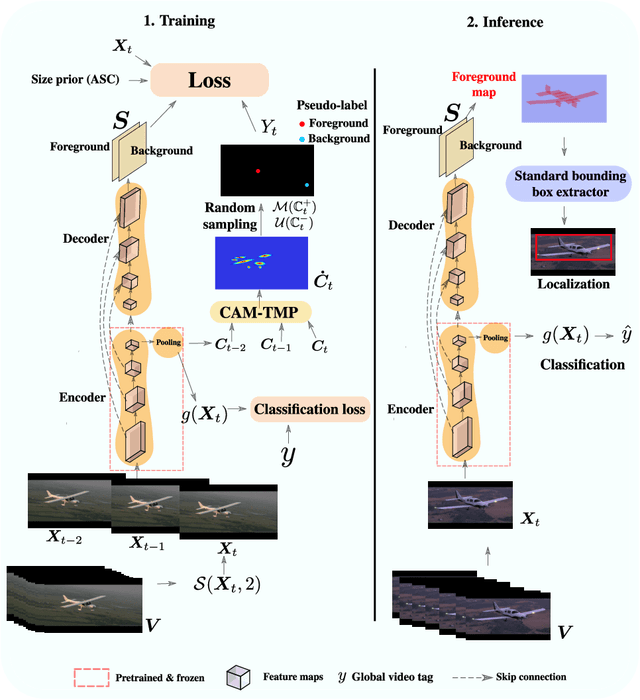
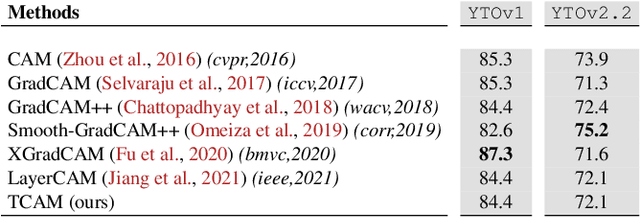
Weakly supervised video object localization (WSVOL) allows locating object in videos using only global video tags such as object class. State-of-art methods rely on multiple independent stages, where initial spatio-temporal proposals are generated using visual and motion cues, then prominent objects are identified and refined. Localization is done by solving an optimization problem over one or more videos, and video tags are typically used for video clustering. This requires a model per-video or per-class making for costly inference. Moreover, localized regions are not necessary discriminant because of unsupervised motion methods like optical flow, or because video tags are discarded from optimization. In this paper, we leverage the successful class activation mapping (CAM) methods, designed for WSOL based on still images. A new Temporal CAM (TCAM) method is introduced to train a discriminant deep learning (DL) model to exploit spatio-temporal information in videos, using an aggregation mechanism, called CAM-Temporal Max Pooling (CAM-TMP), over consecutive CAMs. In particular, activations of regions of interest (ROIs) are collected from CAMs produced by a pretrained CNN classifier to build pixel-wise pseudo-labels for training the DL model. In addition, a global unsupervised size constraint, and local constraint such as CRF are used to yield more accurate CAMs. Inference over single independent frames allows parallel processing of a clip of frames, and real-time localization. Extensive experiments on two challenging YouTube-Objects datasets for unconstrained videos, indicate that CAM methods (trained on independent frames) can yield decent localization accuracy. Our proposed TCAM method achieves a new state-of-art in WSVOL accuracy, and visual results suggest that it can be adapted for subsequent tasks like visual object tracking and detection. Code is publicly available.
Language Model Cascades
Jul 28, 2022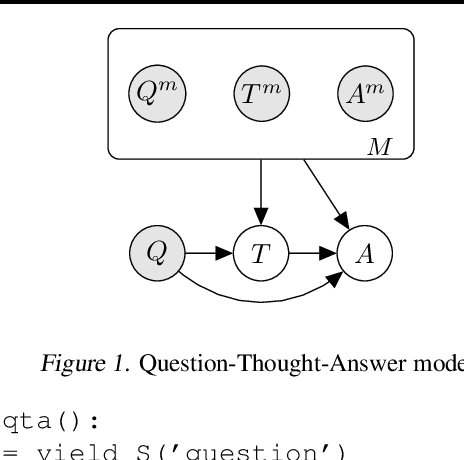
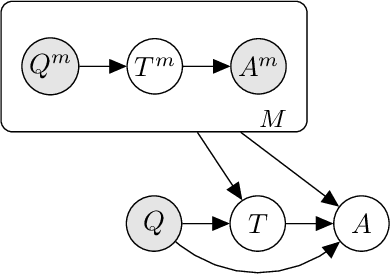
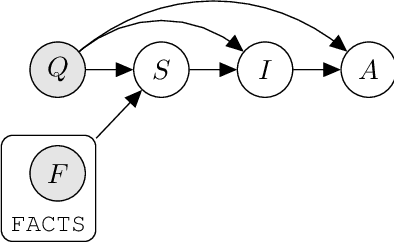
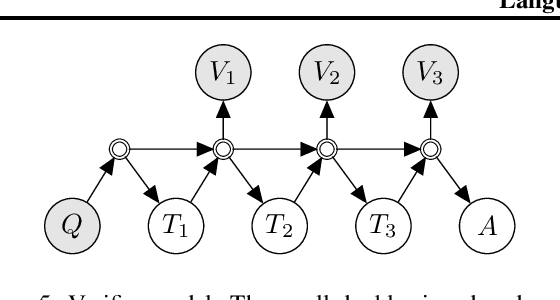
Prompted models have demonstrated impressive few-shot learning abilities. Repeated interactions at test-time with a single model, or the composition of multiple models together, further expands capabilities. These compositions are probabilistic models, and may be expressed in the language of graphical models with random variables whose values are complex data types such as strings. Cases with control flow and dynamic structure require techniques from probabilistic programming, which allow implementing disparate model structures and inference strategies in a unified language. We formalize several existing techniques from this perspective, including scratchpads / chain of thought, verifiers, STaR, selection-inference, and tool use. We refer to the resulting programs as language model cascades.
DRAGON: Decentralized Fault Tolerance in Edge Federations
Aug 16, 2022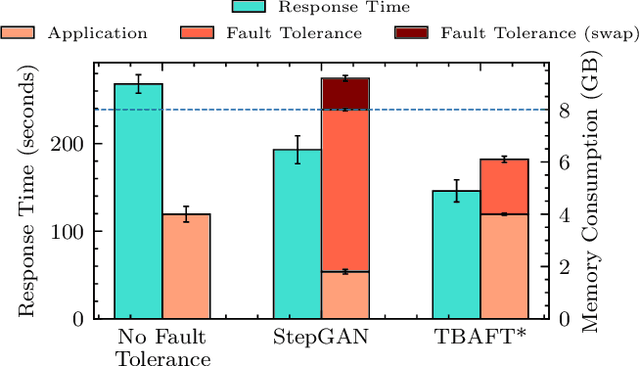
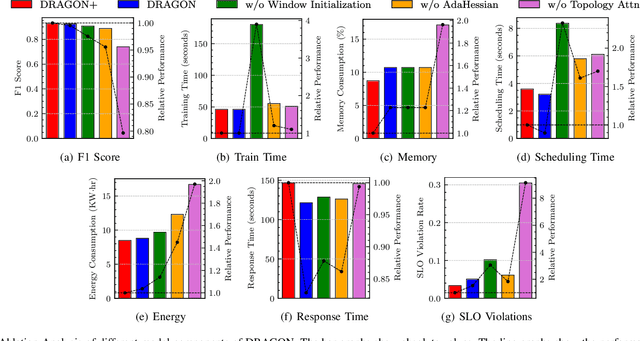
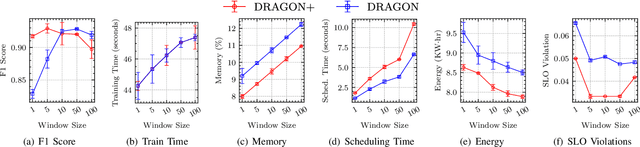
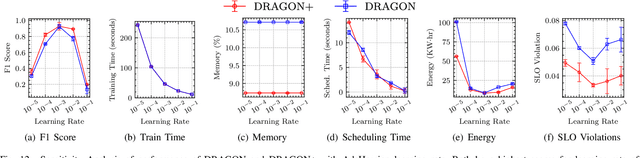
Edge Federation is a new computing paradigm that seamlessly interconnects the resources of multiple edge service providers. A key challenge in such systems is the deployment of latency-critical and AI based resource-intensive applications in constrained devices. To address this challenge, we propose a novel memory-efficient deep learning based model, namely generative optimization networks (GON). Unlike GANs, GONs use a single network to both discriminate input and generate samples, significantly reducing their memory footprint. Leveraging the low memory footprint of GONs, we propose a decentralized fault-tolerance method called DRAGON that runs simulations (as per a digital modeling twin) to quickly predict and optimize the performance of the edge federation. Extensive experiments with real-world edge computing benchmarks on multiple Raspberry-Pi based federated edge configurations show that DRAGON can outperform the baseline methods in fault-detection and Quality of Service (QoS) metrics. Specifically, the proposed method gives higher F1 scores for fault-detection than the best deep learning (DL) method, while consuming lower memory than the heuristic methods. This allows for improvement in energy consumption, response time and service level agreement violations by up to 74, 63 and 82 percent, respectively.
Energy-efficient Dynamic-subarray with Fixed True-time-delay Design for Terahertz Wideband Hybrid Beamforming
Feb 07, 2022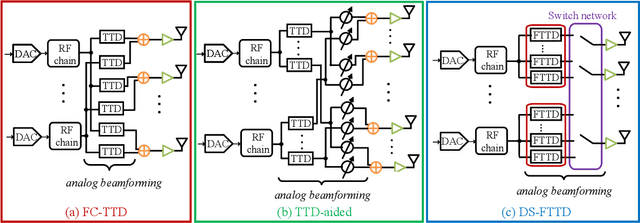
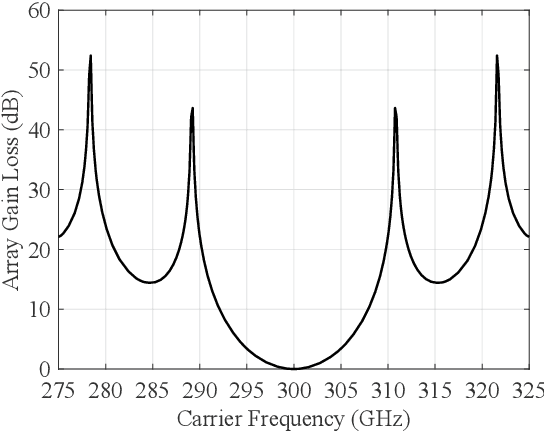
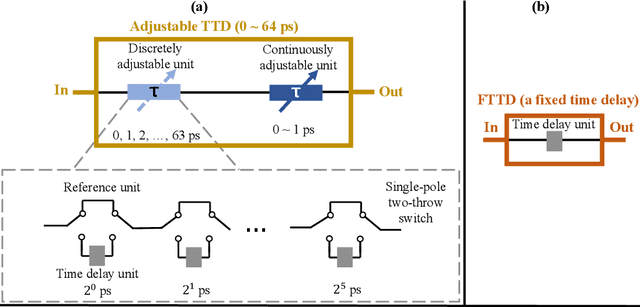
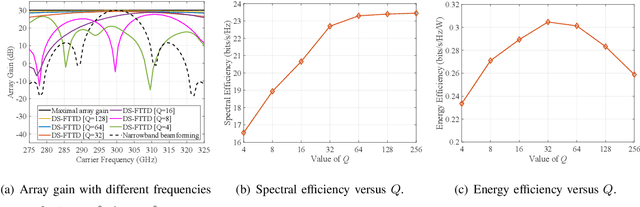
Hybrid beamforming for Terahertz (THz) ultra-massive multiple-input multiple-output (UM-MIMO) systems is a promising technology for 6G space-air-ground integrated networks, which can overcome huge propagation loss and offer unprecedented data rates. With ultra-wide bandwidth and ultra-large-scale antennas array in THz band, the beam squint becomes one of the critical problems which could reduce the array gain and degrade the data rate substantially. However, the traditional phase-shifters-based hybrid beamforming architectures cannot tackle this issue due to the frequency-flat property of the phase shifters. In this paper, to combat the beam squint while keeping high energy efficiency, a novel dynamic-subarray with fixed true-time-delay (DS-FTTD) architecture is proposed. Compared to the existing studies which use the complicated adjustable TTDs, the DS-FTTD architecture has lower power consumption and hardware complexity, thanks to the low-cost FTTDs. Furthermore, a low-complexity row-decomposition (RD) algorithm is proposed to design hybrid beamforming matrices for the DS-FTTD architecture. Extensive simulation results show that, by using the RD algorithm, the DS-FTTD architecture achieves near-optimal array gain and significantly higher energy efficiency than the existing architectures. Moreover, the spectral efficiency of DS-FTTD architecture with the RD algorithm is robust to the imperfect channel state information.
Prospect Theory-inspired Automated P2P Energy Trading with Q-learning-based Dynamic Pricing
Aug 26, 2022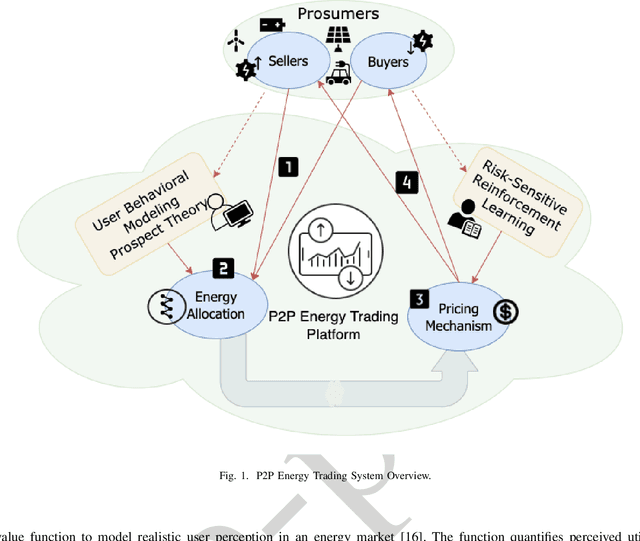
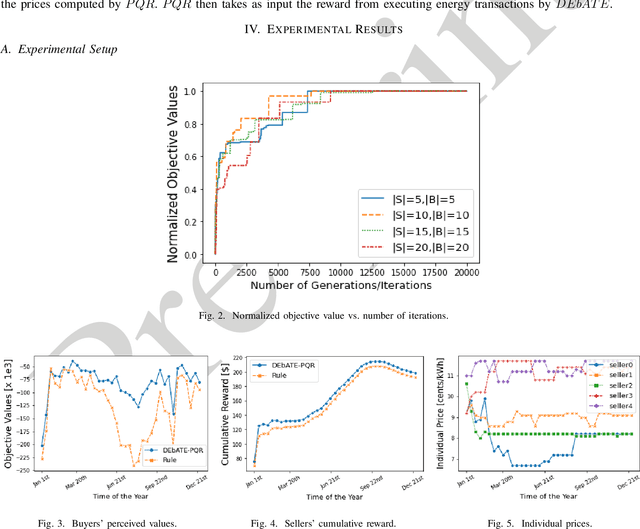
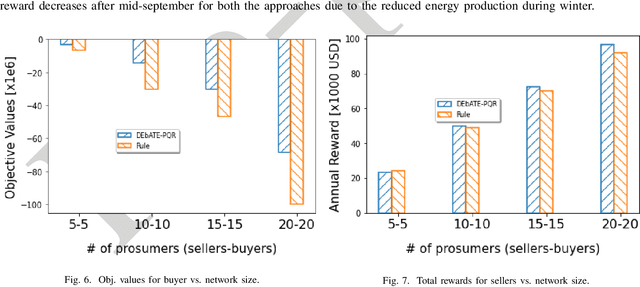
The widespread adoption of distributed energy resources, and the advent of smart grid technologies, have allowed traditionally passive power system users to become actively involved in energy trading. Recognizing the fact that the traditional centralized grid-driven energy markets offer minimal profitability to these users, recent research has shifted focus towards decentralized peer-to-peer (P2P) energy markets. In these markets, users trade energy with each other, with higher benefits than buying or selling to the grid. However, most researches in P2P energy trading largely overlook the user perception in the trading process, assuming constant availability, participation, and full compliance. As a result, these approaches may result in negative attitudes and reduced engagement over time. In this paper, we design an automated P2P energy market that takes user perception into account. We employ prospect theory to model the user perception and formulate an optimization framework to maximize the buyer's perception while matching demand and production. Given the non-linear and non-convex nature of the optimization problem, we propose Differential Evolution-based Algorithm for Trading Energy called DEbATE. Additionally, we introduce a risk-sensitive Q-learning algorithm, named Pricing mechanism with Q-learning and Risk-sensitivity (PQR), which learns the optimal price for sellers considering their perceived utility. Results based on real traces of energy consumption and production, as well as realistic prospect theory functions, show that our approach achieves a 26% higher perceived value for buyers and generates 7% more reward for sellers, compared to a recent state of the art approach.
Analog Gated Recurrent Neural Network for Detecting Chewing Events
Aug 02, 2022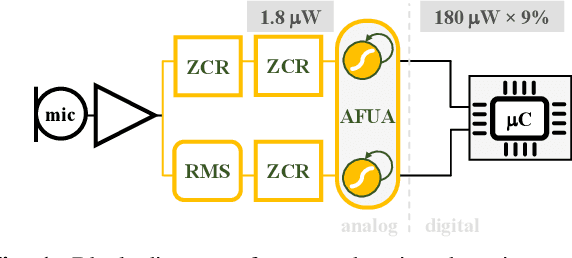
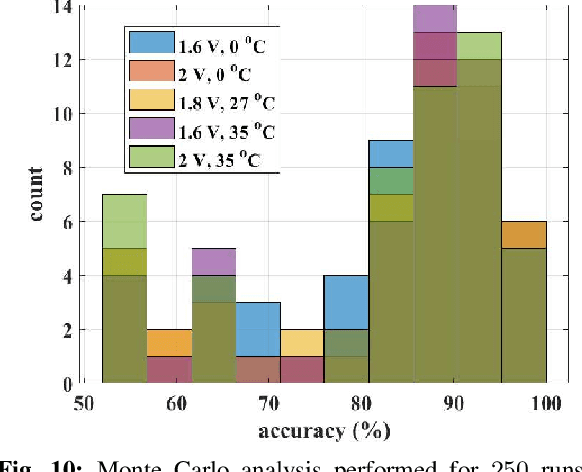
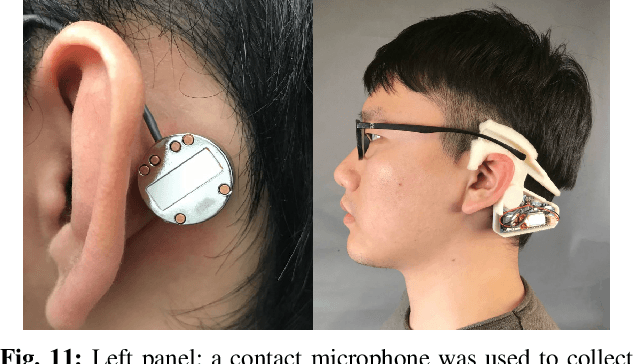
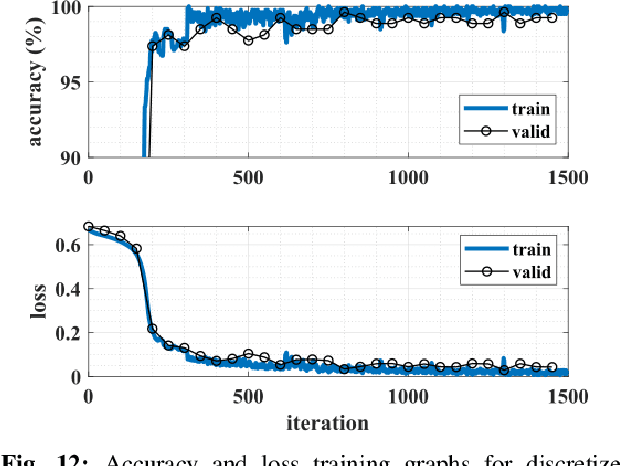
We present a novel gated recurrent neural network to detect when a person is chewing on food. We implemented the neural network as a custom analog integrated circuit in a 0.18 um CMOS technology. The neural network was trained on 6.4 hours of data collected from a contact microphone that was mounted on volunteers' mastoid bones. When tested on 1.6 hours of previously-unseen data, the neural network identified chewing events at a 24-second time resolution. It achieved a recall of 91% and an F1-score of 94% while consuming 1.1 uW of power. A system for detecting whole eating episodes -- like meals and snacks -- that is based on the novel analog neural network consumes an estimated 18.8uW of power.
PiFeNet: Pillar-Feature Network for Real-Time 3D Pedestrian Detection from Point Cloud
Dec 31, 2021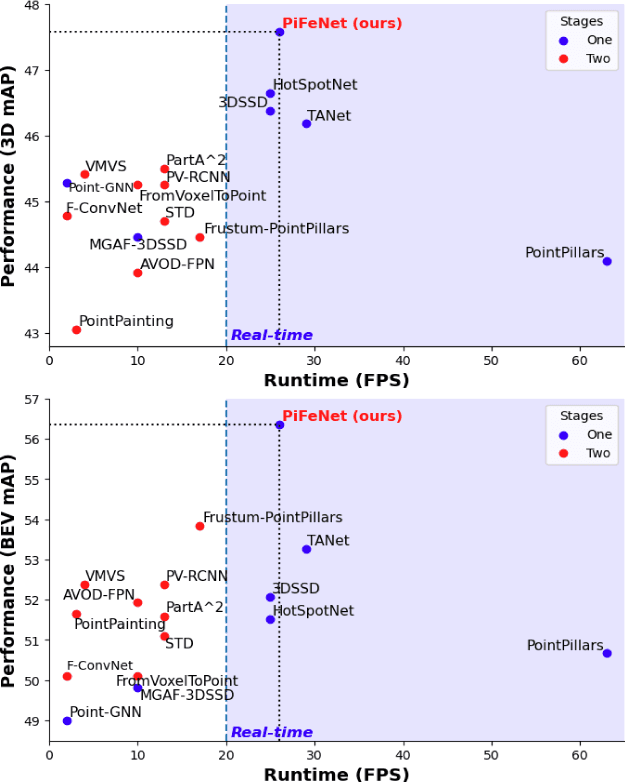
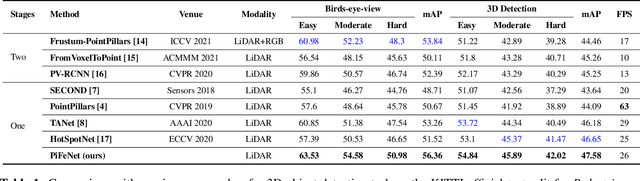
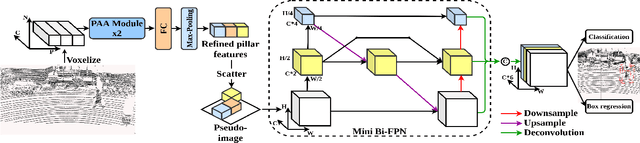

We present PiFeNet, an efficient and accurate real-time 3D detector for pedestrian detection from point clouds. We address two challenges that 3D object detection frameworks encounter when detecting pedestrians: low expressiveness of pillar features and small occupation areas of pedestrians in point clouds. Firstly, we introduce a stackable Pillar Aware Attention (PAA) module for enhanced pillar features extraction while suppressing noises in the point clouds. By integrating multi-point-aware-pooling, point-wise, channel-wise, and task-aware attention into a simple module, the representation capabilities are boosted while requiring little additional computing resources. We also present Mini-BiFPN, a small yet effective feature network that creates bidirectional information flow and multi-level cross-scale feature fusion to better integrate multi-resolution features. Our approach is ranked 1st in KITTI pedestrian BEV and 3D leaderboards while running at 26 frames per second (FPS), and achieves state-of-the-art performance on Nuscenes detection benchmark.