 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Non-stationarity Characteristics in Dynamic Vehicular ISAC Channels at 28 GHz
Mar 01, 2024
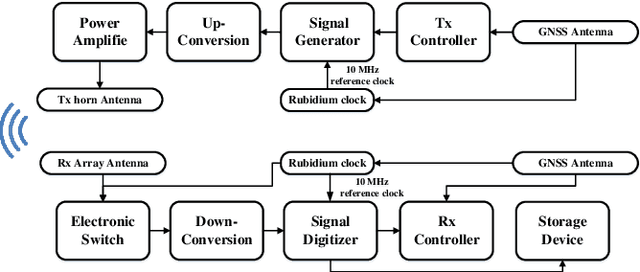

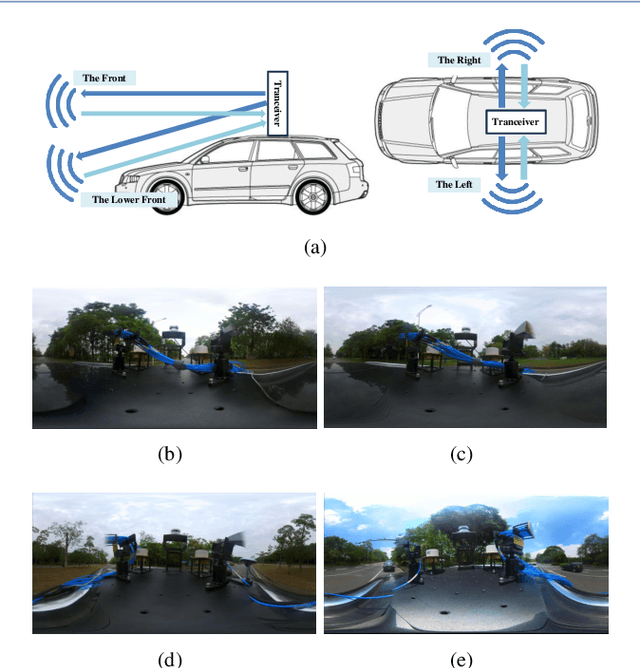
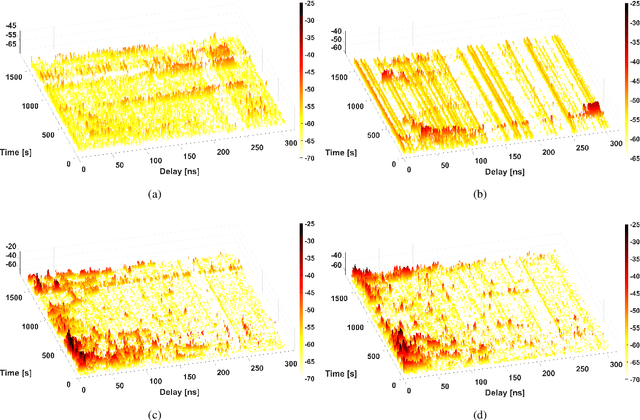
Integrated sensing and communications (ISAC) is a potential technology of 6G, aiming to enable end-to-end information processing ability and native perception capability for future communication systems. As an important part of the ISAC application scenarios, ISAC aided vehicle-to-everything (V2X) can improve the traffic efficiency and safety through intercommunication and synchronous perception. It is necessary to carry out measurement, characterization, and modeling for vehicular ISAC channels as the basic theoretical support for system design. In this paper, dynamic vehicular ISAC channel measurements at 28 GHz are carried out and provide data for the characterization of non-stationarity characteristics. Based on the actual measurements, this paper analyzes the time-varying PDPs, RMSDS and non-stationarity characteristics of front, lower front, left and right perception directions in a complicated V2X scenarios. The research in this paper can enrich the investigation of vehicular ISAC channels and enable the analysis and design of vehicular ISAC systems.
On Cyclical MCMC Sampling
Mar 01, 2024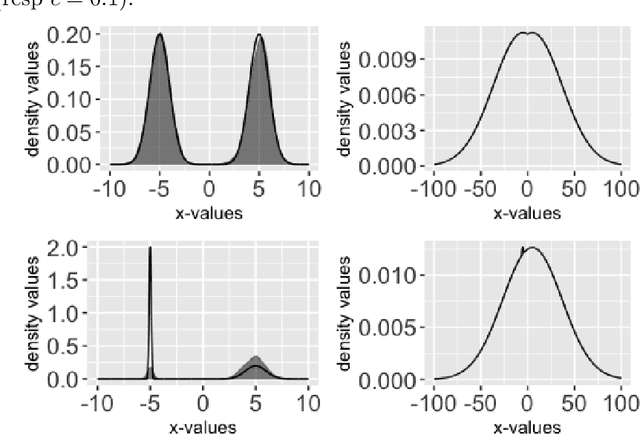
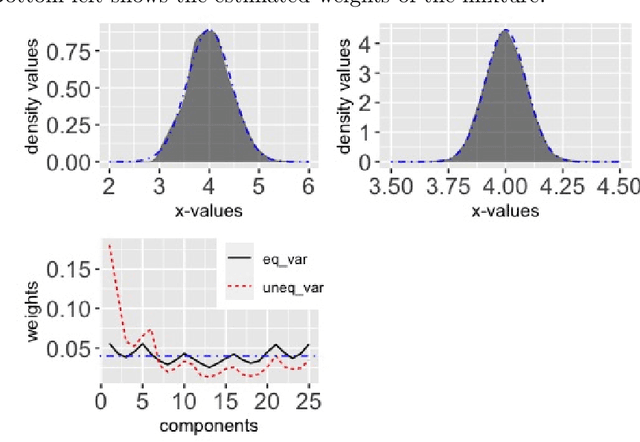
Cyclical MCMC is a novel MCMC framework recently proposed by Zhang et al. (2019) to address the challenge posed by high-dimensional multimodal posterior distributions like those arising in deep learning. The algorithm works by generating a nonhomogeneous Markov chain that tracks -- cyclically in time -- tempered versions of the target distribution. We show in this work that cyclical MCMC converges to the desired probability distribution in settings where the Markov kernels used are fast mixing, and sufficiently long cycles are employed. However in the far more common settings of slow mixing kernels, the algorithm may fail to produce samples from the desired distribution. In particular, in a simple mixture example with unequal variance, we show by simulation that cyclical MCMC fails to converge to the desired limit. Finally, we show that cyclical MCMC typically estimates well the local shape of the target distribution around each mode, even when we do not have convergence to the target.
Hierarchical Indexing for Retrieval-Augmented Opinion Summarization
Mar 01, 2024
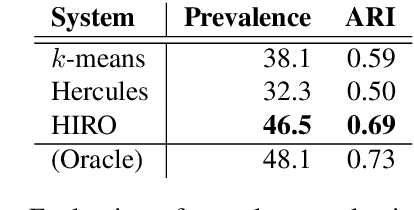
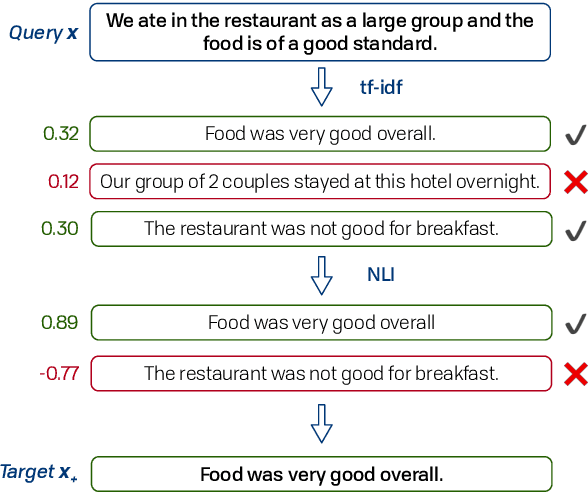
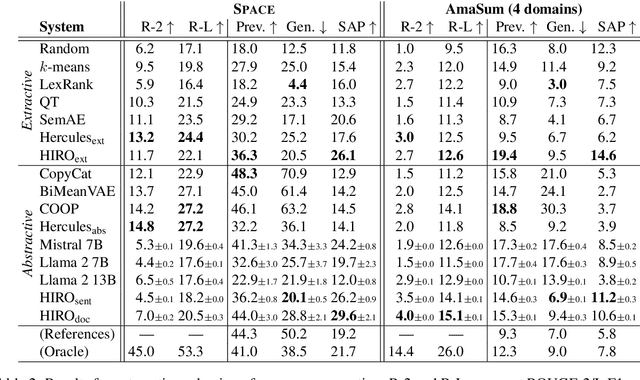
We propose a method for unsupervised abstractive opinion summarization, that combines the attributability and scalability of extractive approaches with the coherence and fluency of Large Language Models (LLMs). Our method, HIRO, learns an index structure that maps sentences to a path through a semantically organized discrete hierarchy. At inference time, we populate the index and use it to identify and retrieve clusters of sentences containing popular opinions from input reviews. Then, we use a pretrained LLM to generate a readable summary that is grounded in these extracted evidential clusters. The modularity of our approach allows us to evaluate its efficacy at each stage. We show that HIRO learns an encoding space that is more semantically structured than prior work, and generates summaries that are more representative of the opinions in the input reviews. Human evaluation confirms that HIRO generates more coherent, detailed and accurate summaries that are significantly preferred by annotators compared to prior work.
Generalized User Representations for Transfer Learning
Mar 01, 2024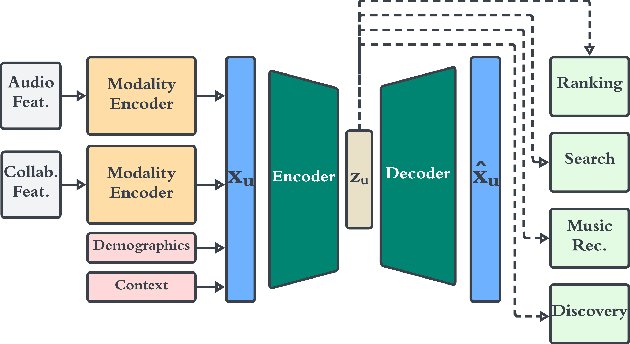

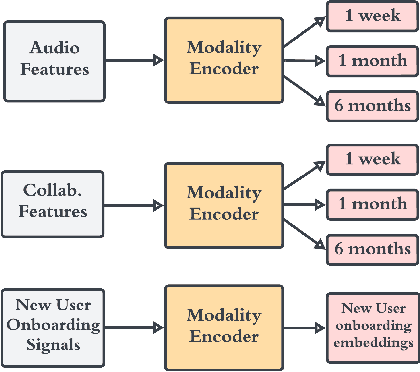
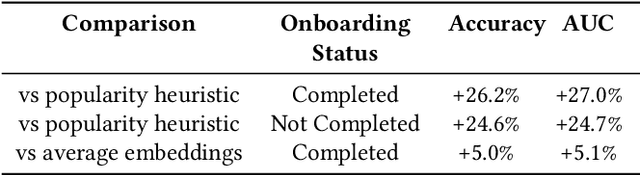
We present a novel framework for user representation in large-scale recommender systems, aiming at effectively representing diverse user taste in a generalized manner. Our approach employs a two-stage methodology combining representation learning and transfer learning. The representation learning model uses an autoencoder that compresses various user features into a representation space. In the second stage, downstream task-specific models leverage user representations via transfer learning instead of curating user features individually. We further augment this methodology on the representation's input features to increase flexibility and enable reaction to user events, including new user experiences, in Near-Real Time. Additionally, we propose a novel solution to manage deployment of this framework in production models, allowing downstream models to work independently. We validate the performance of our framework through rigorous offline and online experiments within a large-scale system, showcasing its remarkable efficacy across multiple evaluation tasks. Finally, we show how the proposed framework can significantly reduce infrastructure costs compared to alternative approaches.
DISORF: A Distributed Online NeRF Training and Rendering Framework for Mobile Robots
Mar 01, 2024

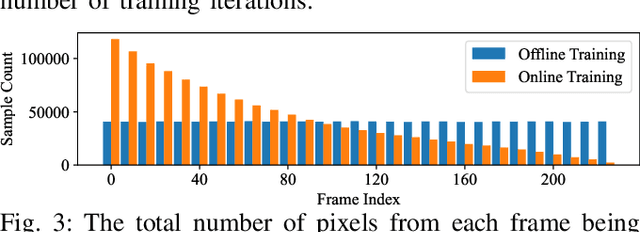
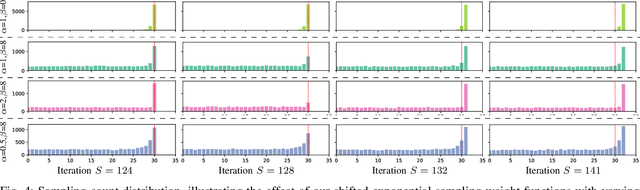
We present a framework, DISORF, to enable online 3D reconstruction and visualization of scenes captured by resource-constrained mobile robots and edge devices. To address the limited compute capabilities of edge devices and potentially limited network availability, we design a framework that efficiently distributes computation between the edge device and remote server. We leverage on-device SLAM systems to generate posed keyframes and transmit them to remote servers that can perform high quality 3D reconstruction and visualization at runtime by leveraging NeRF models. We identify a key challenge with online NeRF training where naive image sampling strategies can lead to significant degradation in rendering quality. We propose a novel shifted exponential frame sampling method that addresses this challenge for online NeRF training. We demonstrate the effectiveness of our framework in enabling high-quality real-time reconstruction and visualization of unknown scenes as they are captured and streamed from cameras in mobile robots and edge devices.
MuseGraph: Graph-oriented Instruction Tuning of Large Language Models for Generic Graph Mining
Mar 02, 2024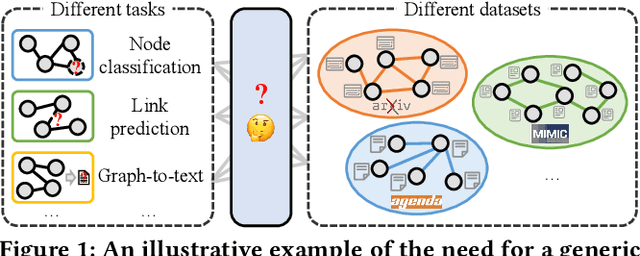
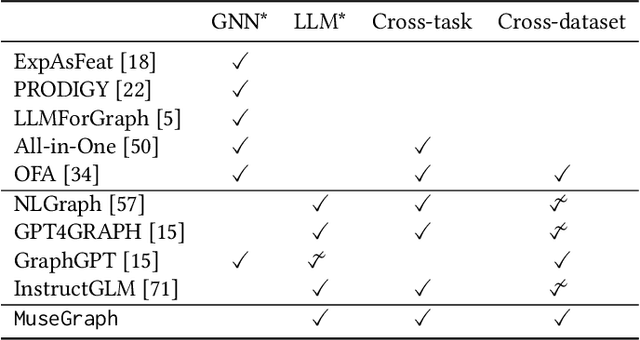
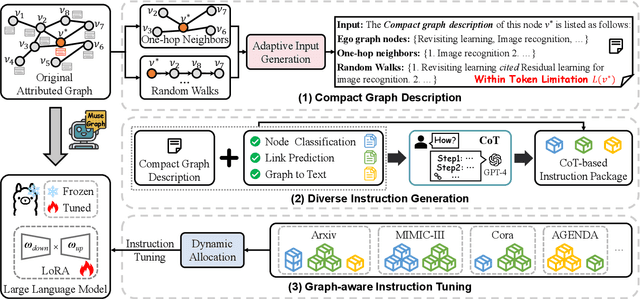
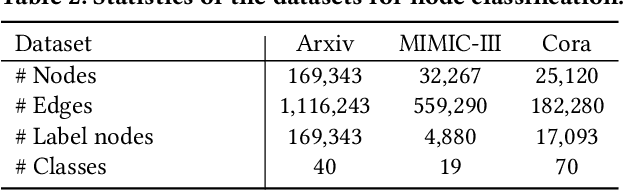
Graphs with abundant attributes are essential in modeling interconnected entities and improving predictions in various real-world applications. Traditional Graph Neural Networks (GNNs), which are commonly used for modeling attributed graphs, need to be re-trained every time when applied to different graph tasks and datasets. Although the emergence of Large Language Models (LLMs) has introduced a new paradigm in natural language processing, the generative potential of LLMs in graph mining remains largely under-explored. To this end, we propose a novel framework MuseGraph, which seamlessly integrates the strengths of GNNs and LLMs and facilitates a more effective and generic approach for graph mining across different tasks and datasets. Specifically, we first introduce a compact graph description via the proposed adaptive input generation to encapsulate key information from the graph under the constraints of language token limitations. Then, we propose a diverse instruction generation mechanism, which distills the reasoning capabilities from LLMs (e.g., GPT-4) to create task-specific Chain-of-Thought-based instruction packages for different graph tasks. Finally, we propose a graph-aware instruction tuning with a dynamic instruction package allocation strategy across tasks and datasets, ensuring the effectiveness and generalization of the training process. Our experimental results demonstrate significant improvements in different graph tasks, showcasing the potential of our MuseGraph in enhancing the accuracy of graph-oriented downstream tasks while keeping the generation powers of LLMs.
Automated Continuous Force-Torque Sensor Bias Estimation
Mar 02, 2024Six axis force-torque sensors are commonly attached to the wrist of serial robots to measure the external forces and torques acting on the robot's end-effector. These measurements are used for load identification, contact detection, and human-robot interaction amongst other applications. Typically, the measurements obtained from the force-torque sensor are more accurate than estimates computed from joint torque readings, as the former is independent of the robot's dynamic and kinematic models. However, the force-torque sensor measurements are affected by a bias that drifts over time, caused by the compounding effects of temperature changes, mechanical stresses, and other factors. In this work, we present a pipeline that continuously estimates the bias and the drift of the bias of a force-torque sensor attached to the wrist of a robot. The first component of the pipeline is a Kalman filter that estimates the kinematic state (position, velocity, and acceleration) of the robot's joints. The second component is a kinematic model that maps the joint-space kinematics to the task-space kinematics of the force-torque sensor. Finally, the third component is a Kalman filter that estimates the bias and the drift of the bias of the force-torque sensor assuming that the inertial parameters of the gripper attached to the distal end of the force-torque sensor are known with certainty.
Extreme Miscalibration and the Illusion of Adversarial Robustness
Feb 27, 2024Deep learning-based Natural Language Processing (NLP) models are vulnerable to adversarial attacks, where small perturbations can cause a model to misclassify. Adversarial Training (AT) is often used to increase model robustness. However, we have discovered an intriguing phenomenon: deliberately or accidentally miscalibrating models masks gradients in a way that interferes with adversarial attack search methods, giving rise to an apparent increase in robustness. We show that this observed gain in robustness is an illusion of robustness (IOR), and demonstrate how an adversary can perform various forms of test-time temperature calibration to nullify the aforementioned interference and allow the adversarial attack to find adversarial examples. Hence, we urge the NLP community to incorporate test-time temperature scaling into their robustness evaluations to ensure that any observed gains are genuine. Finally, we show how the temperature can be scaled during \textit{training} to improve genuine robustness.
Backpropagation-Based Analytical Derivatives of EKF Covariance for Active Sensing
Feb 29, 2024To enhance accuracy of robot state estimation, perception-aware (or active sensing) methods seek trajectories that minimize uncertainty. To this aim, one possibility is to seek trajectories that minimize the final covariance of an extended Kalman filter (EKF), w.r.t. its control inputs over a given horizon. However, this can be computationally demanding. In this article, we derive novel backpropagation analytical formulas for the derivatives of the final covariance of an EKF w.r.t. its inputs. We then leverage the obtained analytical gradients as an enabling technology to derive perception-aware optimal motion plans. Simulations validate the approach, showcasing improvements in both estimation accuracy and execution time. Experimental results on a real large ground vehicle also support the method.
Ensemble-Based Unsupervised Discontinuous Constituency Parsing by Tree Averaging
Feb 29, 2024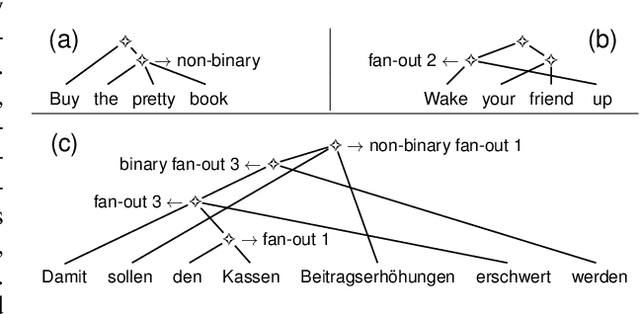
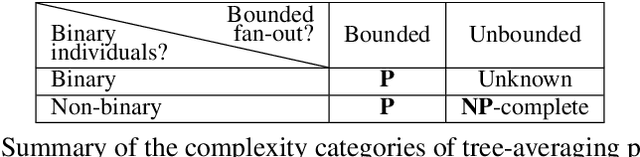
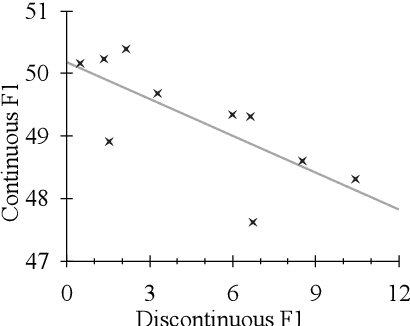
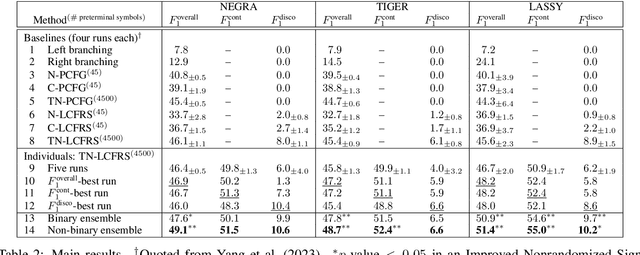
We address unsupervised discontinuous constituency parsing, where we observe a high variance in the performance of the only previous model. We propose to build an ensemble of different runs of the existing discontinuous parser by averaging the predicted trees, to stabilize and boost performance. To begin with, we provide comprehensive computational complexity analysis (in terms of P and NP-complete) for tree averaging under different setups of binarity and continuity. We then develop an efficient exact algorithm to tackle the task, which runs in a reasonable time for all samples in our experiments. Results on three datasets show our method outperforms all baselines in all metrics; we also provide in-depth analyses of our approach.