 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Real-time Recognition of Yoga Poses using computer Vision for Smart Health Care
Jan 19, 2022
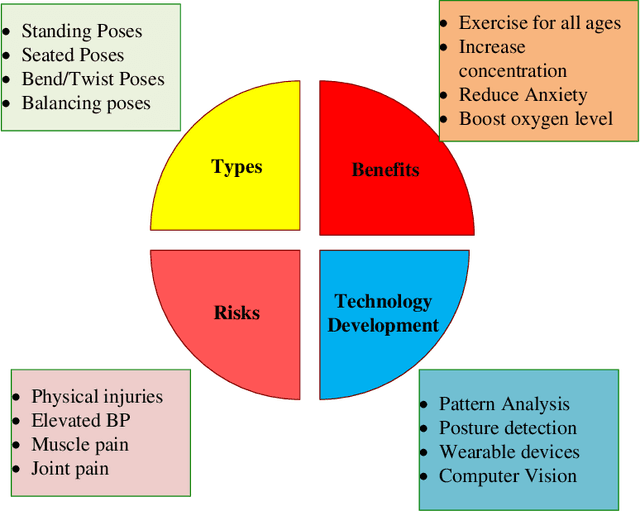
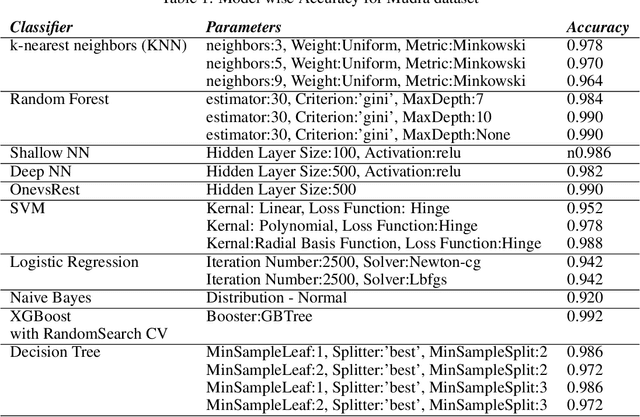
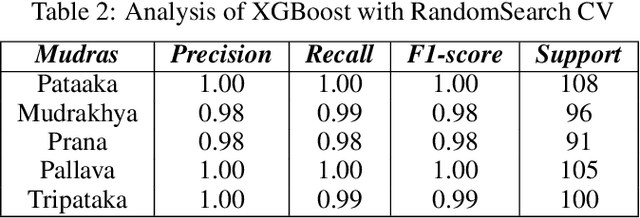
Nowadays, yoga has become a part of life for many people. Exercises and sports technological assistance is implemented in yoga pose identification. In this work, a self-assistance based yoga posture identification technique is developed, which helps users to perform Yoga with the correction feature in Real-time. The work also presents Yoga-hand mudra (hand gestures) identification. The YOGI dataset has been developed which include 10 Yoga postures with around 400-900 images of each pose and also contain 5 mudras for identification of mudras postures. It contains around 500 images of each mudra. The feature has been extracted by making a skeleton on the body for yoga poses and hand for mudra poses. Two different algorithms have been used for creating a skeleton one for yoga poses and the second for hand mudras. Angles of the joints have been extracted as a features for different machine learning and deep learning models. among all the models XGBoost with RandomSearch CV is most accurate and gives 99.2\% accuracy. The complete design framework is described in the present paper.
Learning with little mixing
Jun 16, 2022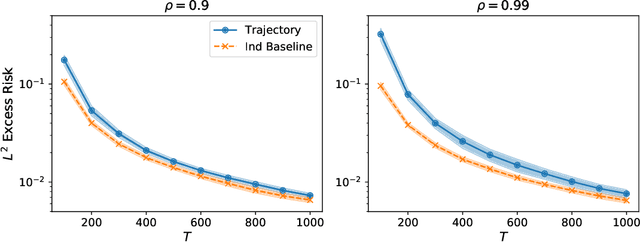
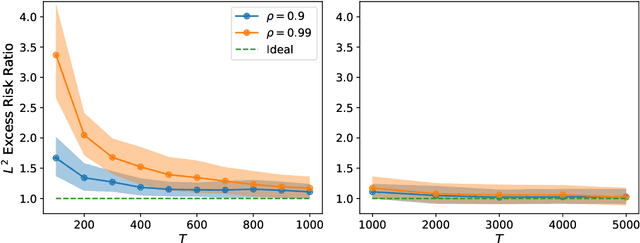
We study square loss in a realizable time-series framework with martingale difference noise. Our main result is a fast rate excess risk bound which shows that whenever a trajectory hypercontractivity condition holds, the risk of the least-squares estimator on dependent data matches the iid rate order-wise after a burn-in time. In comparison, many existing results in learning from dependent data have rates where the effective sample size is deflated by a factor of the mixing-time of the underlying process, even after the burn-in time. Furthermore, our results allow the covariate process to exhibit long range correlations which are substantially weaker than geometric ergodicity. We call this phenomenon learning with little mixing, and present several examples for when it occurs: bounded function classes for which the $L^2$ and $L^{2+\epsilon}$ norms are equivalent, ergodic finite state Markov chains, various parametric models, and a broad family of infinite dimensional $\ell^2(\mathbb{N})$ ellipsoids. By instantiating our main result to system identification of nonlinear dynamics with generalized linear model transitions, we obtain a nearly minimax optimal excess risk bound after only a polynomial burn-in time.
High-Quality Real Time Facial Capture Based on Single Camera
Nov 15, 2021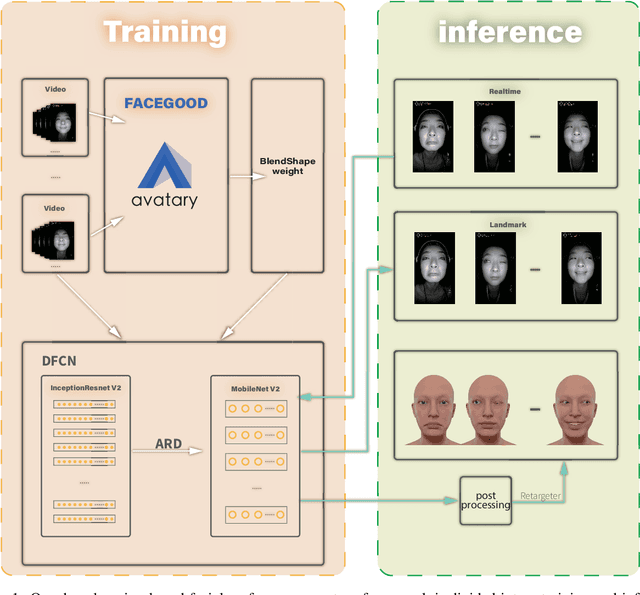


We propose a real time deep learning framework for video-based facial expression capture. Our process uses a high-end facial capture pipeline based on FACEGOOD to capture facial expression. We train a convolutional neural network to produce high-quality continuous blendshape weight output from video training. Since this facial capture is fully automated, our system can drastically reduce the amount of labor involved in the development of modern narrative-driven video games or films involving realistic digital doubles of actors and potentially hours of animated dialogue per character. We demonstrate compelling animation inference in challenging areas such as eyes and lips.
Multilayer deep feature extraction for visual texture recognition
Aug 22, 2022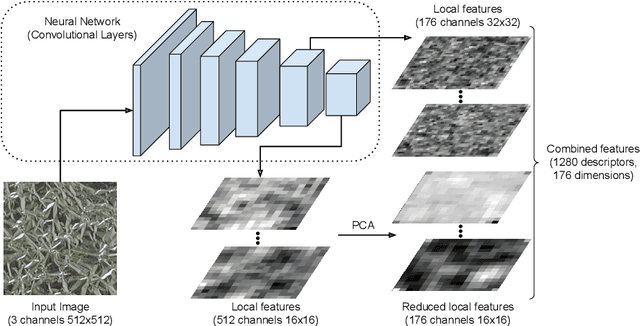
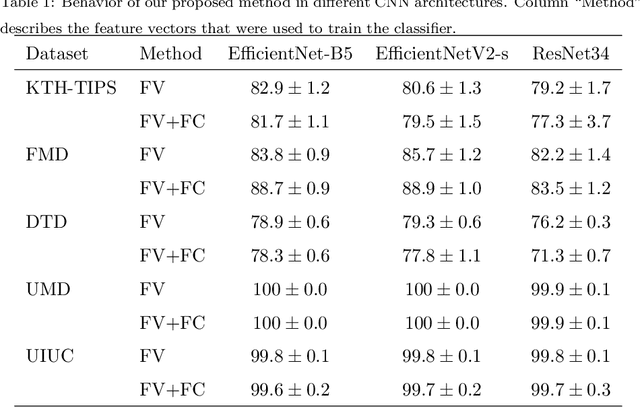
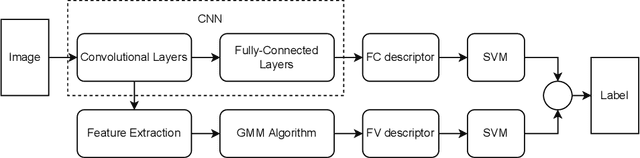
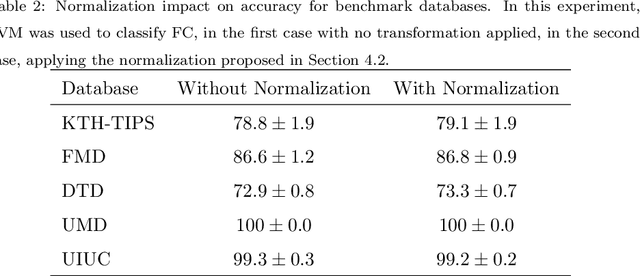
Convolutional neural networks have shown successful results in image classification achieving real-time results superior to the human level. However, texture images still pose some challenge to these models due, for example, to the limited availability of data for training in several problems where these images appear, high inter-class similarity, the absence of a global viewpoint of the object represented, and others. In this context, the present paper is focused on improving the accuracy of convolutional neural networks in texture classification. This is done by extracting features from multiple convolutional layers of a pretrained neural network and aggregating such features using Fisher vector. The reason for using features from earlier convolutional layers is obtaining information that is less domain specific. We verify the effectiveness of our method on texture classification of benchmark datasets, as well as on a practical task of Brazilian plant species identification. In both scenarios, Fisher vectors calculated on multiple layers outperform state-of-art methods, confirming that early convolutional layers provide important information about the texture image for classification.
PSA-GAN: Progressive Self Attention GANs for Synthetic Time Series
Aug 02, 2021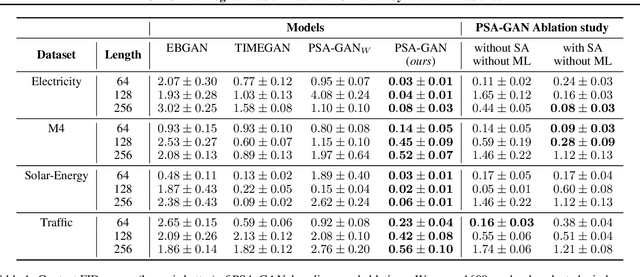

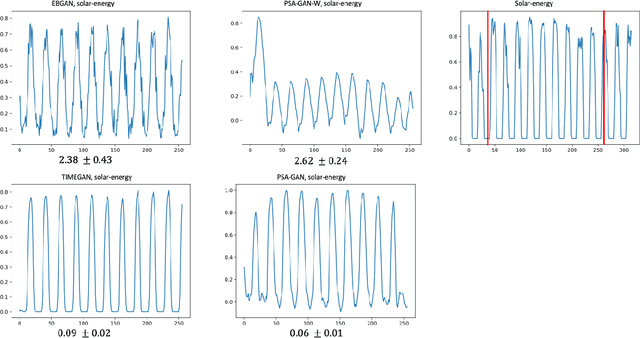
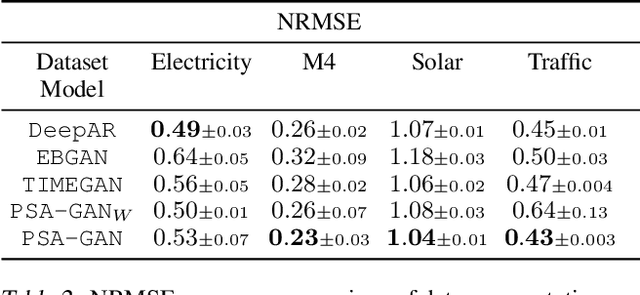
Realistic synthetic time series data of sufficient length enables practical applications in time series modeling tasks, such as forecasting, but remains a challenge. In this paper we present PSA-GAN, a generative adversarial network (GAN) that generates long time series samples of high quality using progressive growing of GANs and self-attention. We show that PSA-GAN can be used to reduce the error in two downstream forecasting tasks over baselines that only use real data. We also introduce a Frechet-Inception Distance-like score, Context-FID, assessing the quality of synthetic time series samples. In our downstream tasks, we find that the lowest scoring models correspond to the best-performing ones. Therefore, Context-FID could be a useful tool to develop time series GAN models.
Nonparametric Factor Trajectory Learning for Dynamic Tensor Decomposition
Jul 06, 2022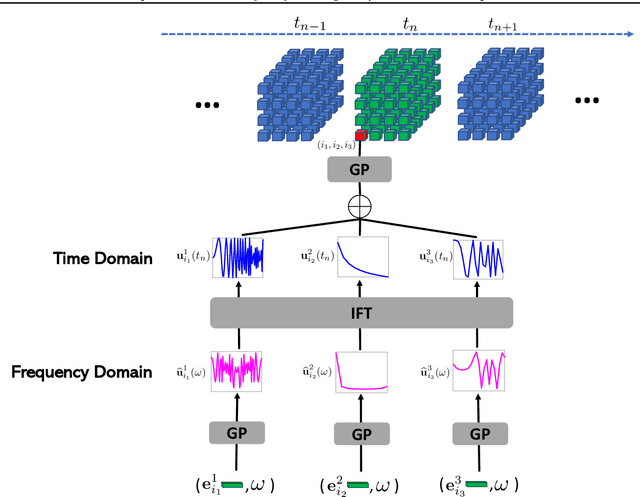
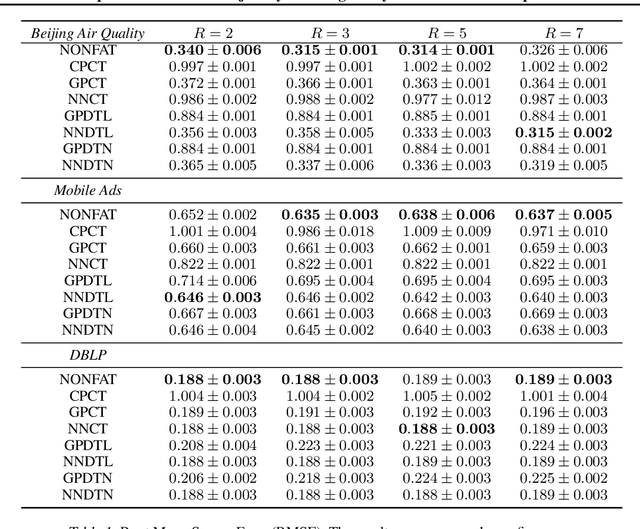
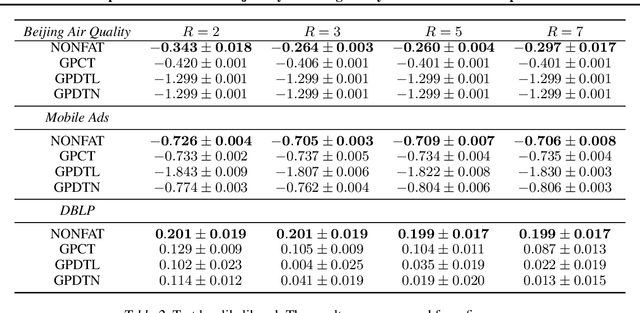
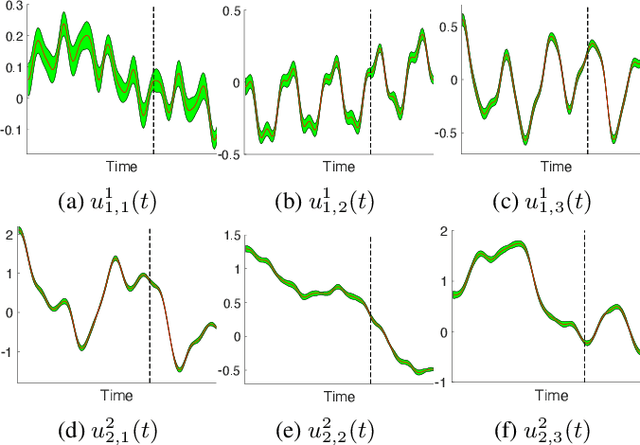
Tensor decomposition is a fundamental framework to analyze data that can be represented by multi-dimensional arrays. In practice, tensor data is often accompanied by temporal information, namely the time points when the entry values were generated. This information implies abundant, complex temporal variation patterns. However, current methods always assume the factor representations of the entities in each tensor mode are static, and never consider their temporal evolution. To fill this gap, we propose NONparametric FActor Trajectory learning for dynamic tensor decomposition (NONFAT). We place Gaussian process (GP) priors in the frequency domain and conduct inverse Fourier transform via Gauss-Laguerre quadrature to sample the trajectory functions. In this way, we can overcome data sparsity and obtain robust trajectory estimates across long time horizons. Given the trajectory values at specific time points, we use a second-level GP to sample the entry values and to capture the temporal relationship between the entities. For efficient and scalable inference, we leverage the matrix Gaussian structure in the model, introduce a matrix Gaussian posterior, and develop a nested sparse variational learning algorithm. We have shown the advantage of our method in several real-world applications.
Revisiting Information Cascades in Online Social Networks
Aug 01, 2022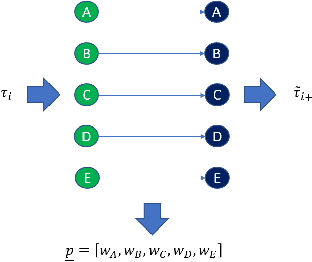

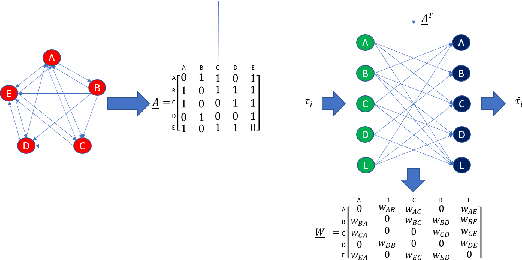
It's by now folklore that to understand the activity pattern of a user in an online social network (OSN) platform, one needs to look at his friends or the ones he follows. The common perception is that these friends exert influence on the user, effecting his decision whether to re-share content or not. Hinging upon this intuition, a variety of models were developed to predict how information propagates in OSN, similar to the way infection spreads in the population. In this paper, we revisit this world view and arrive at new conclusions. Given a set of users $V$, we study the task of predicting whether a user $u \in V$ will re-share content by some $v \in V$ at the following time window given the activity of all the users in $V$ in the previous time window. We design several algorithms for this task, ranging from a simple greedy algorithm that only learns $u$'s conditional probability distribution, ignoring the rest of $V$, to a convolutional neural network-based algorithm that receives the activity of all of $V$, but does not receive explicitly the social link structure. We tested our algorithms on four datasets that we collected from Twitter, each revolving around a different popular topic in 2020. The best performance, average F1-score of 0.86 over the four datasets, was achieved by the convolutional neural network. The simple, social-link ignorant, algorithm achieved an average F1-score of 0.78.
Application of Convolutional Neural Networks with Quasi-Reversibility Method Results for Option Forecasting
Aug 25, 2022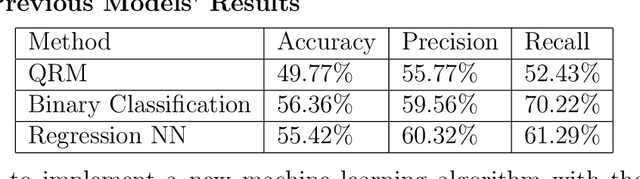
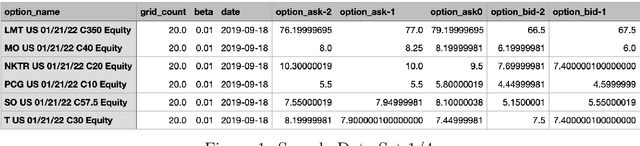
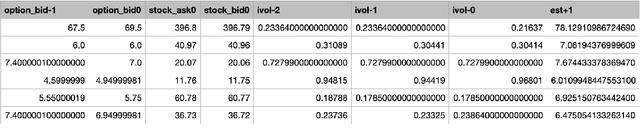
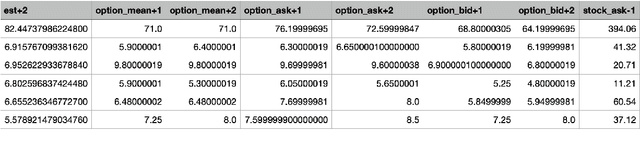
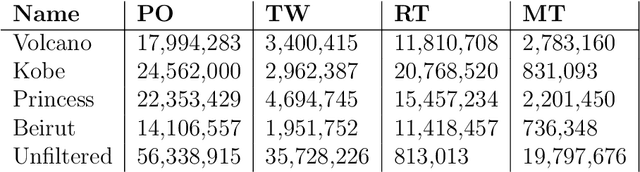
This paper presents a novel way to apply mathematical finance and machine learning (ML) to forecast stock options prices. Following results from the paper Quasi-Reversibility Method and Neural Network Machine Learning to Solution of Black-Scholes Equations (appeared on the AMS Contemporary Mathematics journal), we create and evaluate new empirical mathematical models for the Black-Scholes equation to analyze data for 92,846 companies. We solve the Black-Scholes (BS) equation forwards in time as an ill-posed inverse problem, using the Quasi-Reversibility Method (QRM), to predict option price for the future one day. For each company, we have 13 elements including stock and option daily prices, volatility, minimizer, etc. Because the market is so complicated that there exists no perfect model, we apply ML to train algorithms to make the best prediction. The current stage of research combines QRM with Convolutional Neural Networks (CNN), which learn information across a large number of data points simultaneously. We implement CNN to generate new results by validating and testing on sample market data. We test different ways of applying CNN and compare our CNN models with previous models to see if achieving a higher profit rate is possible.
Microstructure estimation from diffusion-MRI: Compartmentalized models in permeable cellular tissue
Sep 06, 2022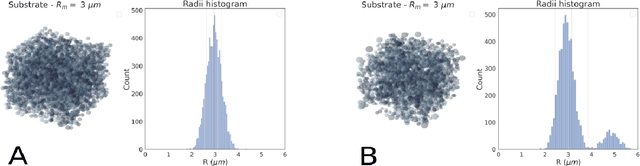

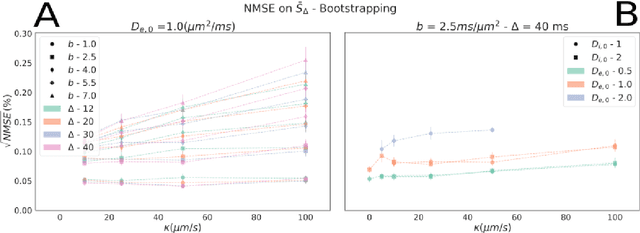

Diffusion-weighted magnetic resonance imaging (DW-MRI) is used to characterize brain tissue microstructure employing tissue-specific biophysical models. A current limitation, however, is that most of the proposed models are based on the assumption of negligible water exchange between the intra- and extracellular compartments, which might not be valid in various brain tissues, including unmyelinated axons, gray matter, and tumors. The purpose of this work is to quantify the effect of membrane permeability on the estimates of two popular models neglecting exchange, and compare their performance with a model including exchange. To this aim, DW-MRI experiments were performed in controlled environments with Monte-Carlo simulations. The DW-MRI signals were generated in numerical substrates mimicking biological tissue made of spherical cells with permeable membranes like cancerous tissue or the brain gray matter. From these signals, the substrates properties were estimated using SANDI and VERDICT, the two compartment-based models neglecting exchange, and CEXI, a new model which includes exchange. Our results show that, in cellular permeable tissue, the model with exchange outperformed models without exchange in the estimation of the tissue properties by providing more stable estimates of cell size, intracellular volume fraction and extracellular diffusion coefficient. Moreover, the model with exchange estimated accurately the exchange time in the range of permeability reported for cellular tissue. Finally, the simulations performed in this work showed that the exchange between the intracellular and the extracellular space cannot be neglected in permeable tissue with a conventional PGSE sequence, to obtain accurate estimates. Consequently, existing compartmentalized models of impermeable tissue cannot be used for microstructure estimation of cellular permeable tissue.
Explaining Time Series Predictions with Dynamic Masks
Jun 09, 2021

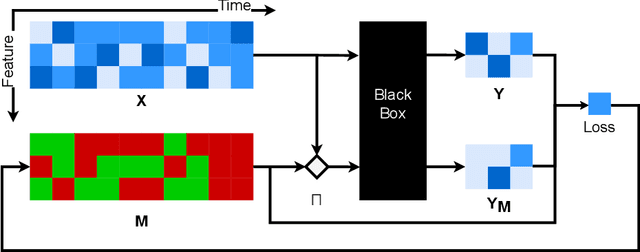
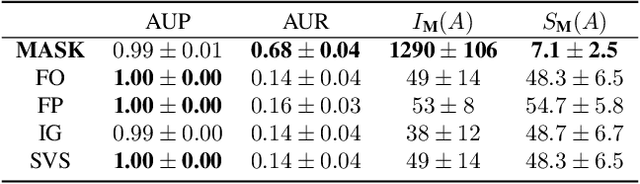
How can we explain the predictions of a machine learning model? When the data is structured as a multivariate time series, this question induces additional difficulties such as the necessity for the explanation to embody the time dependency and the large number of inputs. To address these challenges, we propose dynamic masks (Dynamask). This method produces instance-wise importance scores for each feature at each time step by fitting a perturbation mask to the input sequence. In order to incorporate the time dependency of the data, Dynamask studies the effects of dynamic perturbation operators. In order to tackle the large number of inputs, we propose a scheme to make the feature selection parsimonious (to select no more feature than necessary) and legible (a notion that we detail by making a parallel with information theory). With synthetic and real-world data, we demonstrate that the dynamic underpinning of Dynamask, together with its parsimony, offer a neat improvement in the identification of feature importance over time. The modularity of Dynamask makes it ideal as a plug-in to increase the transparency of a wide range of machine learning models in areas such as medicine and finance, where time series are abundant.