 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Highly dynamic locomotion control of biped robot enhanced by swing arms
Aug 17, 2022
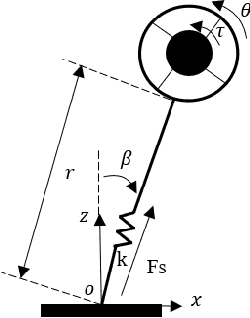
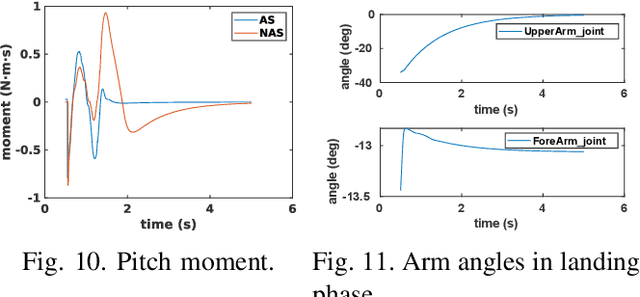
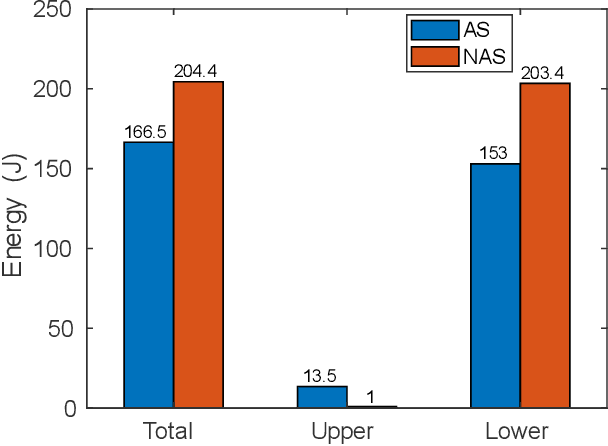
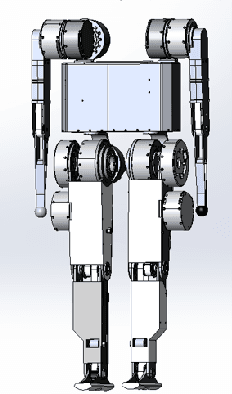
Swing arms have an irreplaceable role in promoting highly dynamic locomotion on bipedal robots by a larger angular momentum control space from the viewpoint of biomechanics. Few bipedal robots utilize swing arms and its redundancy characteristic of multiple degrees of freedom due to the lack of appropriate locomotion control strategies to perfectly integrate modeling and control. This paper presents a kind of control strategy by modeling the bipedal robot as a flywheel-spring loaded inverted pendulum (F-SLIP) to extract characteristics of swing arms and using the whole-body controller (WBC) to achieve these characteristics, and also proposes a evaluation system including three aspects of agility defined by us, stability and energy consumption for the highly dynamic locomotion of bipedal robots. We design several sets of simulation experiments and analyze the effects of swing arms according to the evaluation system during the jumping motion of Purple (Purple energy rises in the east)V1.0, a kind of bipedal robot designed to test high explosive locomotion. Results show that Purple's agility is increased by more than 10 percent, stabilization time is reduced by a factor of two, and energy consumption is reduced by more than 20 percent after introducing swing arms.
NeuralUQ: A comprehensive library for uncertainty quantification in neural differential equations and operators
Aug 25, 2022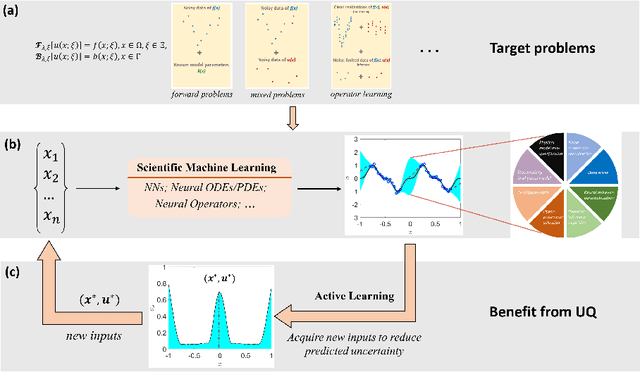

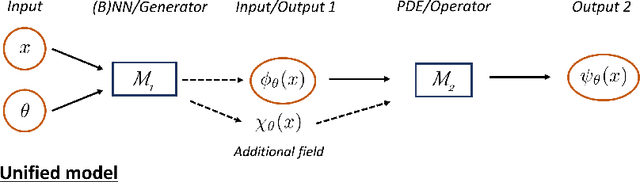
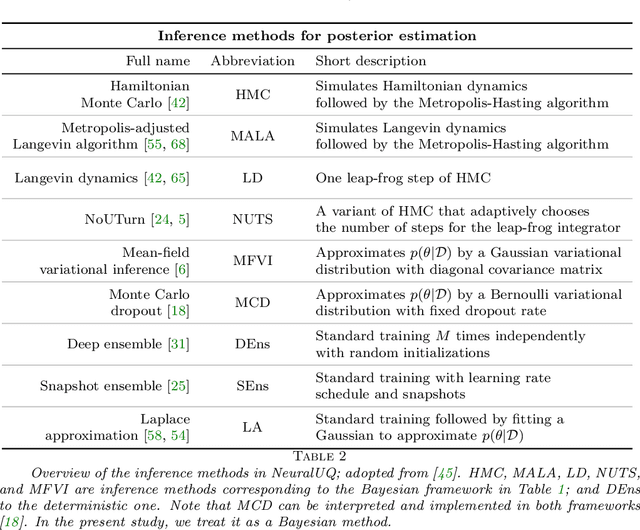
Uncertainty quantification (UQ) in machine learning is currently drawing increasing research interest, driven by the rapid deployment of deep neural networks across different fields, such as computer vision, natural language processing, and the need for reliable tools in risk-sensitive applications. Recently, various machine learning models have also been developed to tackle problems in the field of scientific computing with applications to computational science and engineering (CSE). Physics-informed neural networks and deep operator networks are two such models for solving partial differential equations and learning operator mappings, respectively. In this regard, a comprehensive study of UQ methods tailored specifically for scientific machine learning (SciML) models has been provided in [45]. Nevertheless, and despite their theoretical merit, implementations of these methods are not straightforward, especially in large-scale CSE applications, hindering their broad adoption in both research and industry settings. In this paper, we present an open-source Python library (https://github.com/Crunch-UQ4MI), termed NeuralUQ and accompanied by an educational tutorial, for employing UQ methods for SciML in a convenient and structured manner. The library, designed for both educational and research purposes, supports multiple modern UQ methods and SciML models. It is based on a succinct workflow and facilitates flexible employment and easy extensions by the users. We first present a tutorial of NeuralUQ and subsequently demonstrate its applicability and efficiency in four diverse examples, involving dynamical systems and high-dimensional parametric and time-dependent PDEs.
AdaRNN: Adaptive Learning and Forecasting of Time Series
Aug 11, 2021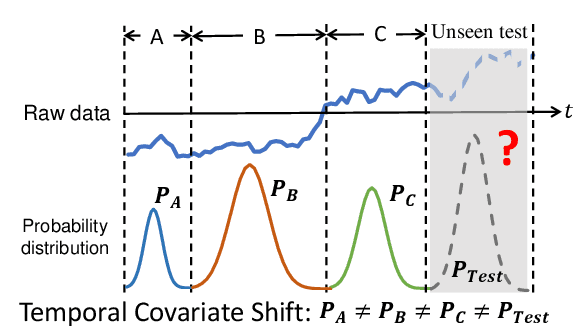
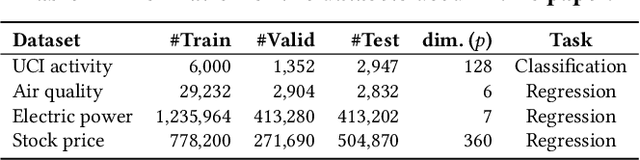
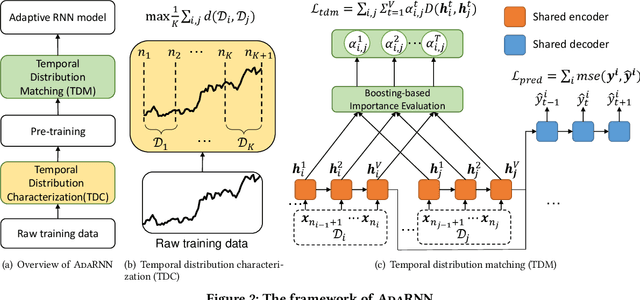
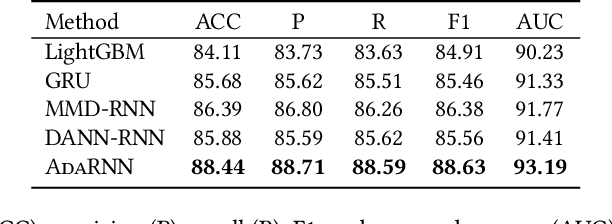
Time series has wide applications in the real world and is known to be difficult to forecast. Since its statistical properties change over time, its distribution also changes temporally, which will cause severe distribution shift problem to existing methods. However, it remains unexplored to model the time series in the distribution perspective. In this paper, we term this as Temporal Covariate Shift (TCS). This paper proposes Adaptive RNNs (AdaRNN) to tackle the TCS problem by building an adaptive model that generalizes well on the unseen test data. AdaRNN is sequentially composed of two novel algorithms. First, we propose Temporal Distribution Characterization to better characterize the distribution information in the TS. Second, we propose Temporal Distribution Matching to reduce the distribution mismatch in TS to learn the adaptive TS model. AdaRNN is a general framework with flexible distribution distances integrated. Experiments on human activity recognition, air quality prediction, and financial analysis show that AdaRNN outperforms the latest methods by a classification accuracy of 2.6% and significantly reduces the RMSE by 9.0%. We also show that the temporal distribution matching algorithm can be extended in Transformer structure to boost its performance.
Disentangling Identity and Pose for Facial Expression Recognition
Aug 17, 2022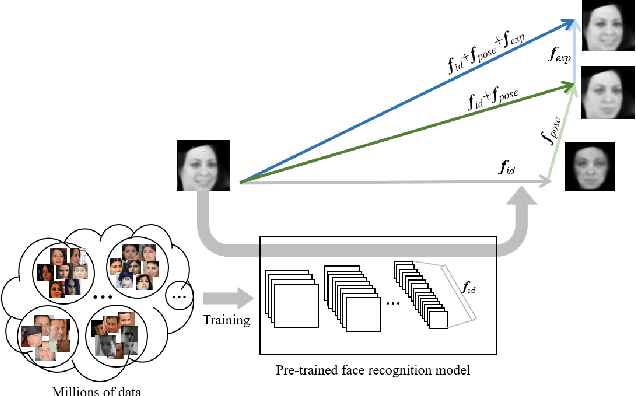

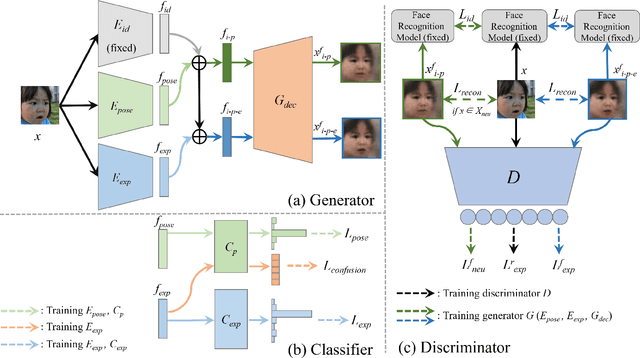
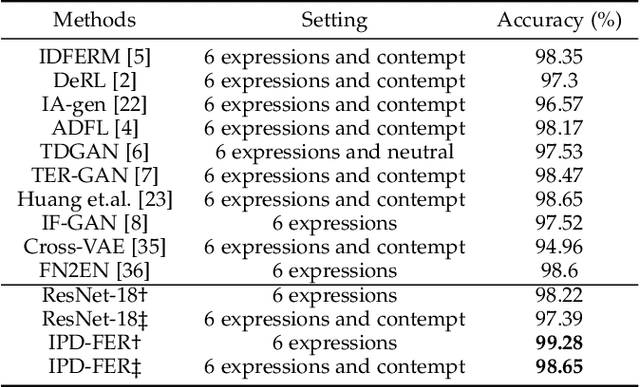
Facial expression recognition (FER) is a challenging problem because the expression component is always entangled with other irrelevant factors, such as identity and head pose. In this work, we propose an identity and pose disentangled facial expression recognition (IPD-FER) model to learn more discriminative feature representation. We regard the holistic facial representation as the combination of identity, pose and expression. These three components are encoded with different encoders. For identity encoder, a well pre-trained face recognition model is utilized and fixed during training, which alleviates the restriction on specific expression training data in previous works and makes the disentanglement practicable on in-the-wild datasets. At the same time, the pose and expression encoder are optimized with corresponding labels. Combining identity and pose feature, a neutral face of input individual should be generated by the decoder. When expression feature is added, the input image should be reconstructed. By comparing the difference between synthesized neutral and expressional images of the same individual, the expression component is further disentangled from identity and pose. Experimental results verify the effectiveness of our method on both lab-controlled and in-the-wild databases and we achieve state-of-the-art recognition performance.
Edge YOLO: Real-Time Intelligent Object Detection System Based on Edge-Cloud Cooperation in Autonomous Vehicles
May 30, 2022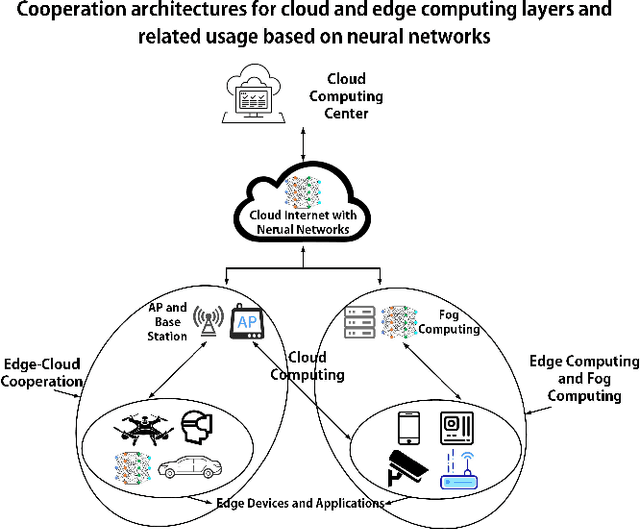

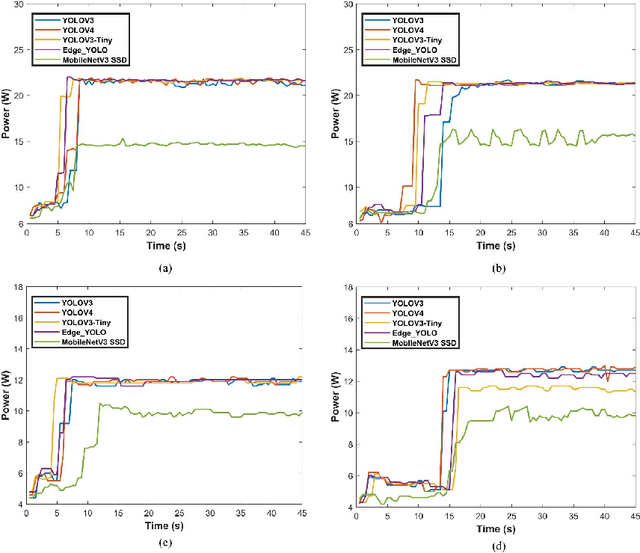

Driven by the ever-increasing requirements of autonomous vehicles, such as traffic monitoring and driving assistant, deep learning-based object detection (DL-OD) has been increasingly attractive in intelligent transportation systems. However, it is difficult for the existing DL-OD schemes to realize the responsible, cost-saving, and energy-efficient autonomous vehicle systems due to low their inherent defects of low timeliness and high energy consumption. In this paper, we propose an object detection (OD) system based on edge-cloud cooperation and reconstructive convolutional neural networks, which is called Edge YOLO. This system can effectively avoid the excessive dependence on computing power and uneven distribution of cloud computing resources. Specifically, it is a lightweight OD framework realized by combining pruning feature extraction network and compression feature fusion network to enhance the efficiency of multi-scale prediction to the largest extent. In addition, we developed an autonomous driving platform equipped with NVIDIA Jetson for system-level verification. We experimentally demonstrate the reliability and efficiency of Edge YOLO on COCO2017 and KITTI data sets, respectively. According to COCO2017 standard datasets with a speed of 26.6 frames per second (FPS), the results show that the number of parameters in the entire network is only 25.67 MB, while the accuracy (mAP) is up to 47.3%.
Model Blending for Text Classification
Aug 05, 2022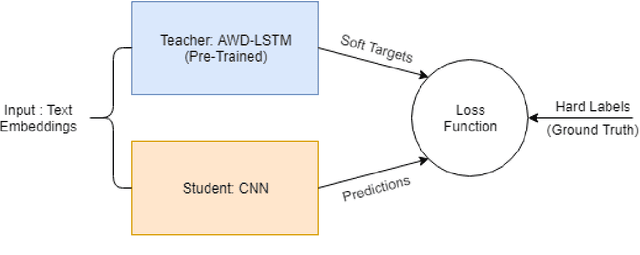
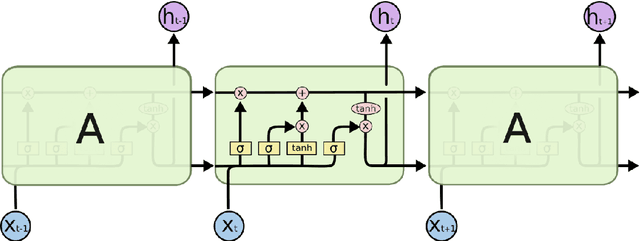
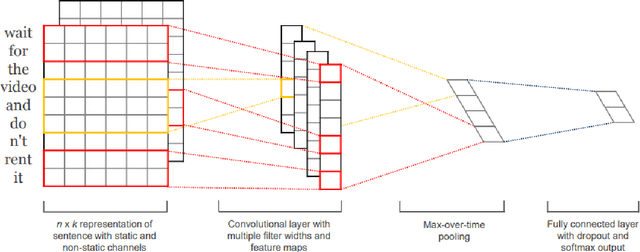
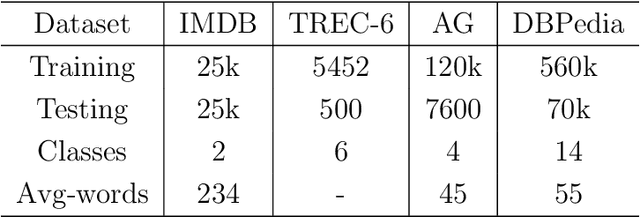
Deep neural networks (DNNs) have proven successful in a wide variety of applications such as speech recognition and synthesis, computer vision, machine translation, and game playing, to name but a few. However, existing deep neural network models are computationally expensive and memory intensive, hindering their deployment in devices with low memory resources or in applications with strict latency requirements. Therefore, a natural thought is to perform model compression and acceleration in deep networks without significantly decreasing the model performance, which is what we call reducing the complexity. In the following work, we try reducing the complexity of state of the art LSTM models for natural language tasks such as text classification, by distilling their knowledge to CNN based models, thus reducing the inference time(or latency) during testing.
Automated Noncontact Trapping of Moving Micro-particle with Ultrasonic Phased Array System and Microscopic Vision
Aug 22, 2022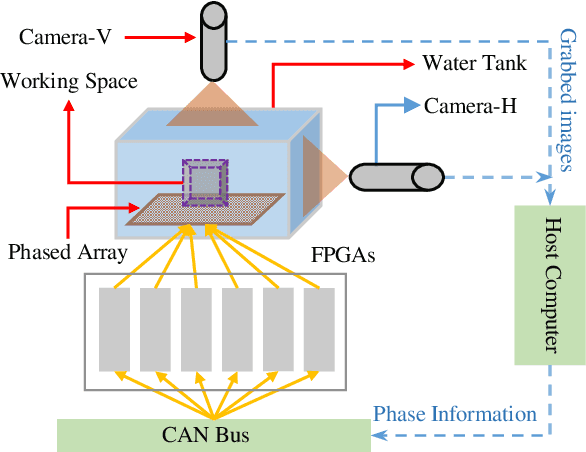
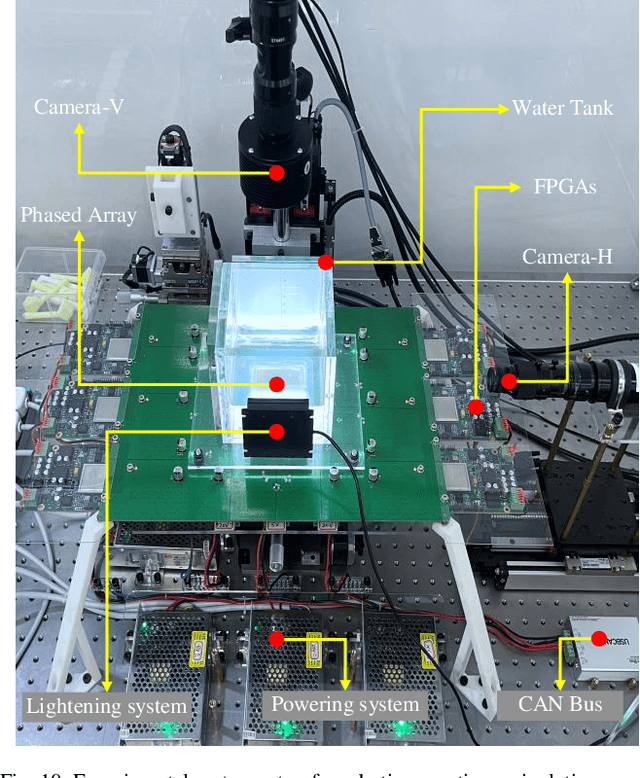
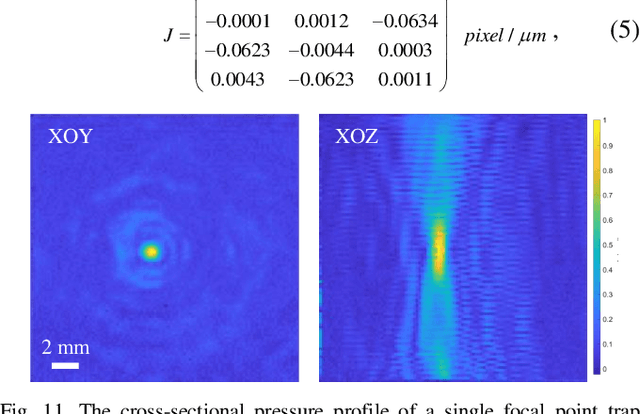

Noncontact particle manipulation (NPM) technology has significantly extended mankind's analysis capability into micro and nano scale, which in turn greatly promoted the development of material science and life science. Though NPM by means of electric, magnetic, and optical field has achieved great success, from the robotic perspective, it is still labor-intensive manipulation since professional human assistance is somehow mandatory in early preparation stage. Therefore, developing automated noncontact trapping of moving particles is worthwhile, particularly for applications where particle samples are rare, fragile or contact sensitive. Taking advantage of latest dynamic acoustic field modulating technology, and particularly by virtue of the great scalability of acoustic manipulation from micro-scale to sub-centimeter-scale, we propose an automated noncontact trapping of moving micro-particles with ultrasonic phased array system and microscopic vision in this paper. The main contribution of this work is for the first time, as far as we know, we achieved fully automated moving micro-particle trapping in acoustic NPM field by resorting to robotic approach. In short, the particle moving status is observed and predicted by binocular microscopic vision system, by referring to which the acoustic trapping zone is calculated and generated to capture and stably hold the particle. The problem of hand-eye relationship of noncontact robotic end-effector is also solved in this work. Experiments demonstrated the effectiveness of this work.
High-quality Task Division for Large-scale Entity Alignment
Aug 22, 2022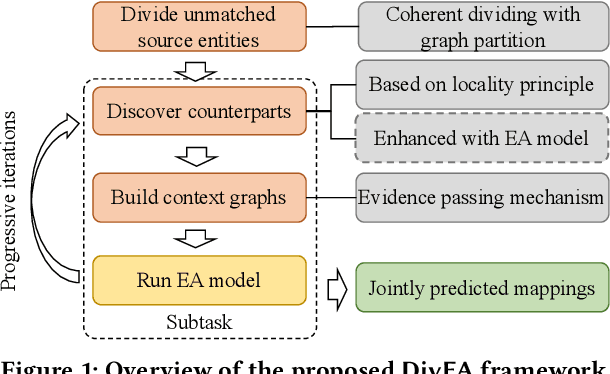

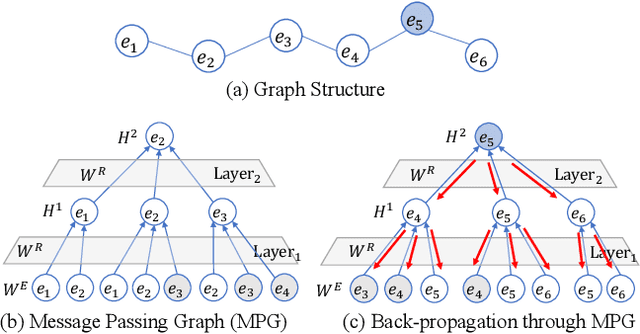

Entity Alignment (EA) aims to match equivalent entities that refer to the same real-world objects and is a key step for Knowledge Graph (KG) fusion. Most neural EA models cannot be applied to large-scale real-life KGs due to their excessive consumption of GPU memory and time. One promising solution is to divide a large EA task into several subtasks such that each subtask only needs to match two small subgraphs of the original KGs. However, it is challenging to divide the EA task without losing effectiveness. Existing methods display low coverage of potential mappings, insufficient evidence in context graphs, and largely differing subtask sizes. In this work, we design the DivEA framework for large-scale EA with high-quality task division. To include in the EA subtasks a high proportion of the potential mappings originally present in the large EA task, we devise a counterpart discovery method that exploits the locality principle of the EA task and the power of trained EA models. Unique to our counterpart discovery method is the explicit modelling of the chance of a potential mapping. We also introduce an evidence passing mechanism to quantify the informativeness of context entities and find the most informative context graphs with flexible control of the subtask size. Extensive experiments show that DivEA achieves higher EA performance than alternative state-of-the-art solutions.
Time Delay Estimation of Traffic Congestion Propagation based on Transfer Entropy
Aug 15, 2021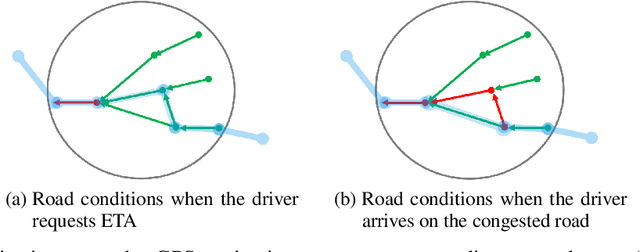
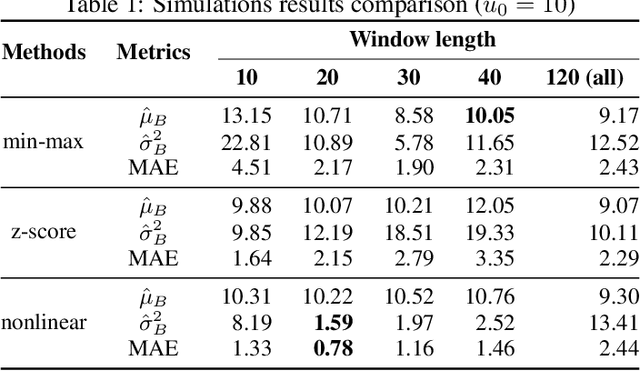
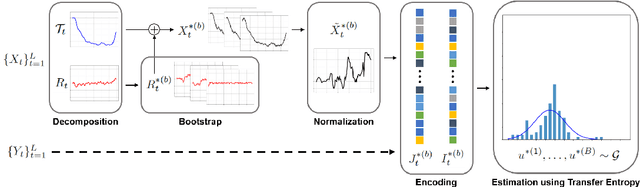
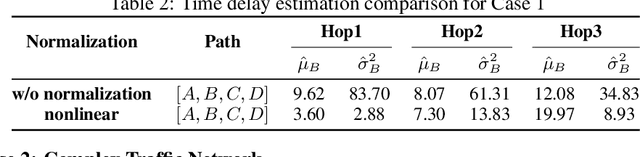
Considering how congestion will propagate in the near future, understanding traffic congestion propagation has become crucial in GPS navigation systems for providing users with a more accurate estimated time of arrival (ETA). However, providing the exact ETA during congestion is a challenge owing to the complex propagation process between roads and high uncertainty regarding the future behavior of the process. Recent studies have focused on finding frequent congestion propagation patterns and determining the propagation probabilities. By contrast, this study proposes a novel time delay estimation method for traffic congestion propagation between roads using lag-specific transfer entropy (TE). Nonlinear normalization with a sliding window is used to effectively reveal the causal relationship between the source and target time series in calculating the TE. Moreover, Markov bootstrap techniques were adopted to quantify the uncertainty in the time delay estimator. To the best of our knowledge, the time delay estimation method presented in this article is the first to determine the time delay between roads for any congestion propagation pattern. The proposed method was validated using simulated data as well as real user trajectory data obtained from a major GPS navigation system applied in South Korea.
Early and Revocable Time Series Classification
Sep 22, 2021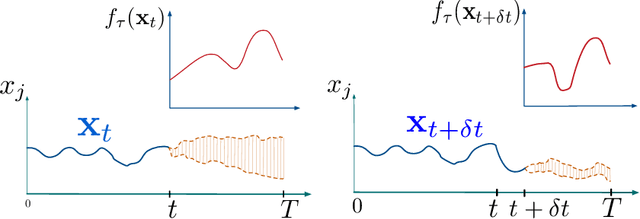
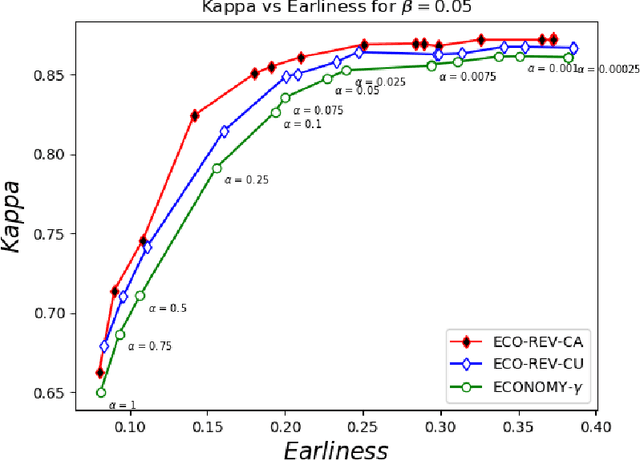
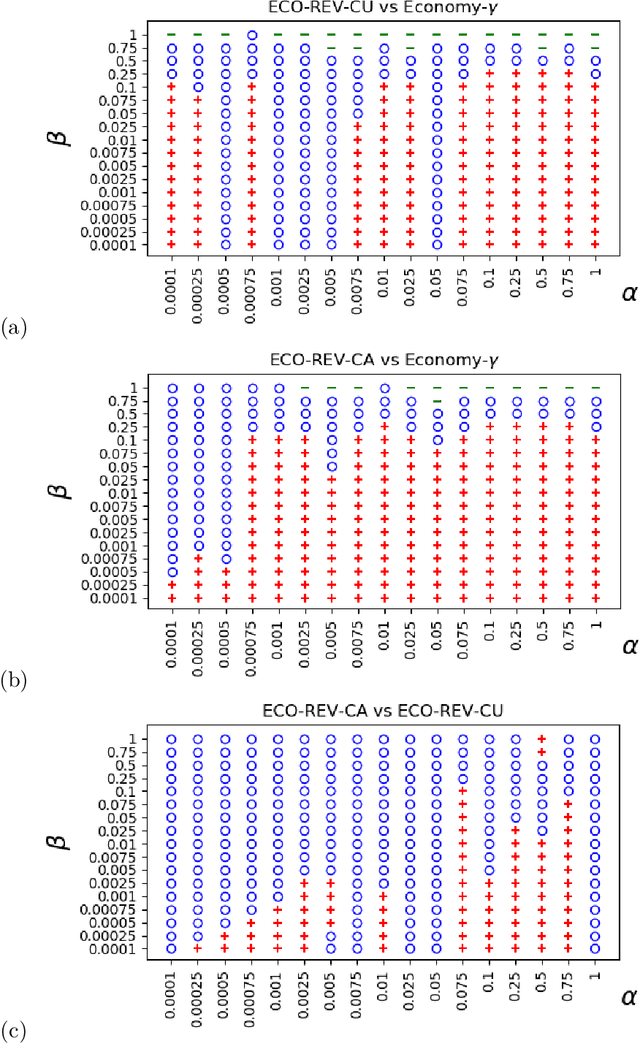
Many approaches have been proposed for early classification of time series in light of itssignificance in a wide range of applications including healthcare, transportation and fi-nance. Until now, the early classification problem has been dealt with by considering onlyirrevocable decisions. This paper introduces a new problem calledearly and revocabletimeseries classification, where the decision maker can revoke its earlier decisions based on thenew available measurements. In order to formalize and tackle this problem, we propose anew cost-based framework and derive two new approaches from it. The first approach doesnot consider explicitly the cost of changing decision, while the second one does. Exten-sive experiments are conducted to evaluate these approaches on a large benchmark of realdatasets. The empirical results obtained convincingly show (i) that the ability of revok-ing decisions significantly improves performance over the irrevocable regime, and (ii) thattaking into account the cost of changing decision brings even better results in general.Keywords:revocable decisions, cost estimation, online decision making