 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Unsupervised Video Domain Adaptation: A Disentanglement Perspective
Aug 15, 2022
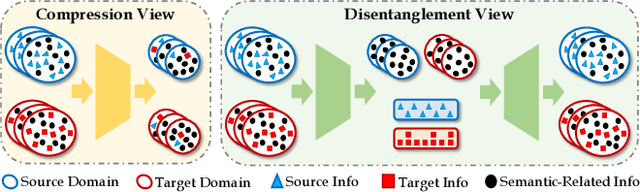
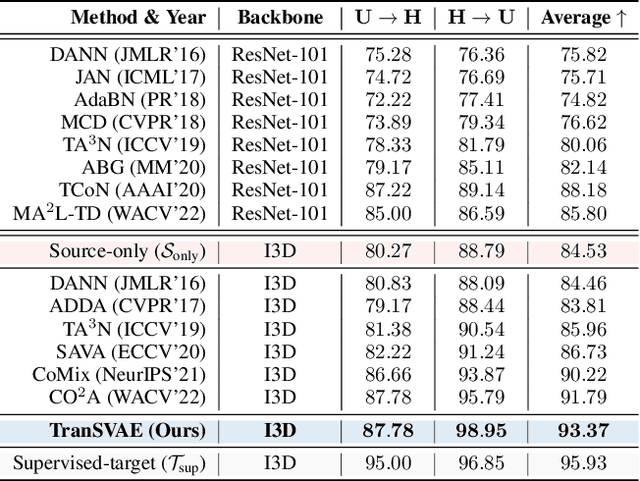
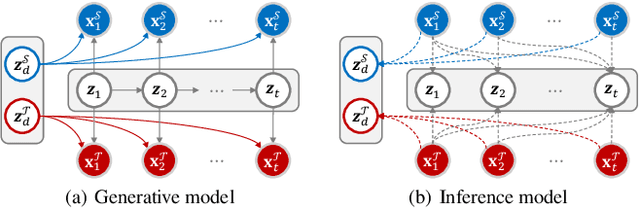
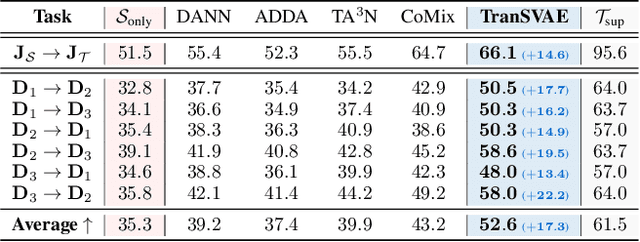
Unsupervised video domain adaptation is a practical yet challenging task. In this work, for the first time, we tackle it from a disentanglement view. Our key idea is to disentangle the domain-related information from the data during the adaptation process. Specifically, we consider the generation of cross-domain videos from two sets of latent factors, one encoding the static domain-related information and another encoding the temporal and semantic-related information. A Transfer Sequential VAE (TranSVAE) framework is then developed to model such generation. To better serve for adaptation, we further propose several objectives to constrain the latent factors in TranSVAE. Extensive experiments on the UCF-HMDB, Jester, and Epic-Kitchens datasets verify the effectiveness and superiority of TranSVAE compared with several state-of-the-art methods. Code is publicly available at https://github.com/ldkong1205/TranSVAE.
Towards Informed Design and Validation Assistance in Computer Games Using Imitation Learning
Aug 19, 2022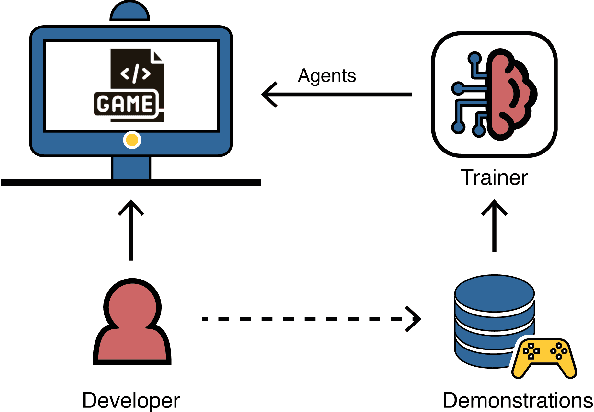

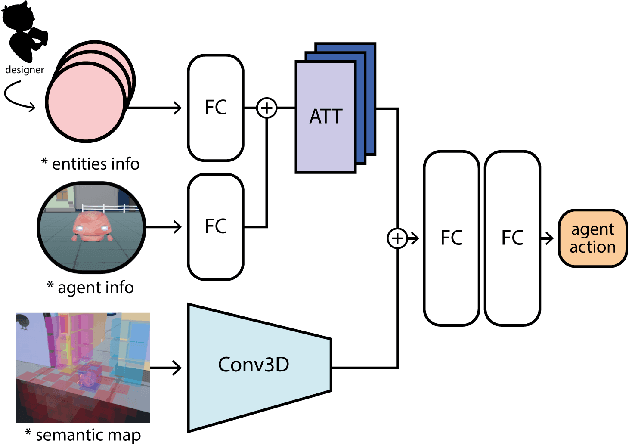
In games, as in and many other domains, design validation and testing is a huge challenge as systems are growing in size and manual testing is becoming infeasible. This paper proposes a new approach to automated game validation and testing. Our method leverages a data-driven imitation learning technique, which requires little effort and time and no knowledge of machine learning or programming, that designers can use to efficiently train game testing agents. We investigate the validity of our approach through a user study with industry experts. The survey results show that our method is indeed a valid approach to game validation and that data-driven programming would be a useful aid to reducing effort and increasing quality of modern playtesting. The survey also highlights several open challenges. With the help of the most recent literature, we analyze the identified challenges and propose future research directions suitable for supporting and maximizing the utility of our approach.
Synthetic Data in Human Analysis: A Survey
Aug 19, 2022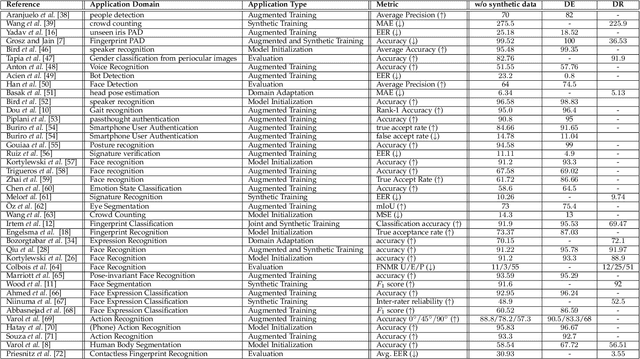



Deep neural networks have become prevalent in human analysis, boosting the performance of applications, such as biometric recognition, action recognition, as well as person re-identification. However, the performance of such networks scales with the available training data. In human analysis, the demand for large-scale datasets poses a severe challenge, as data collection is tedious, time-expensive, costly and must comply with data protection laws. Current research investigates the generation of \textit{synthetic data} as an efficient and privacy-ensuring alternative to collecting real data in the field. This survey introduces the basic definitions and methodologies, essential when generating and employing synthetic data for human analysis. We conduct a survey that summarises current state-of-the-art methods and the main benefits of using synthetic data. We also provide an overview of publicly available synthetic datasets and generation models. Finally, we discuss limitations, as well as open research problems in this field. This survey is intended for researchers and practitioners in the field of human analysis.
Multiple Shooting Approach for Finding Approximately Shortest Paths for Autonomous Robots in Unknown Environments in 2D
Aug 22, 2022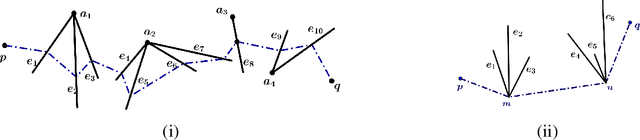
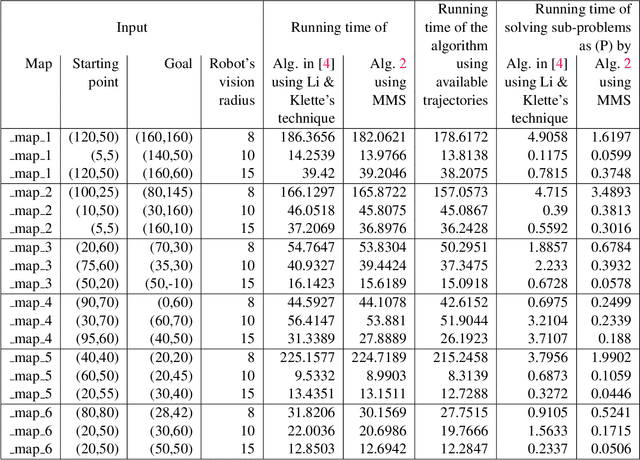
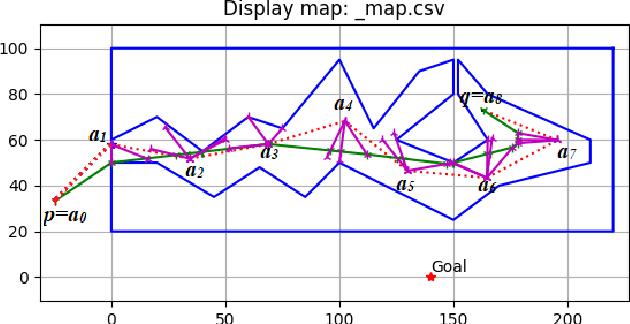
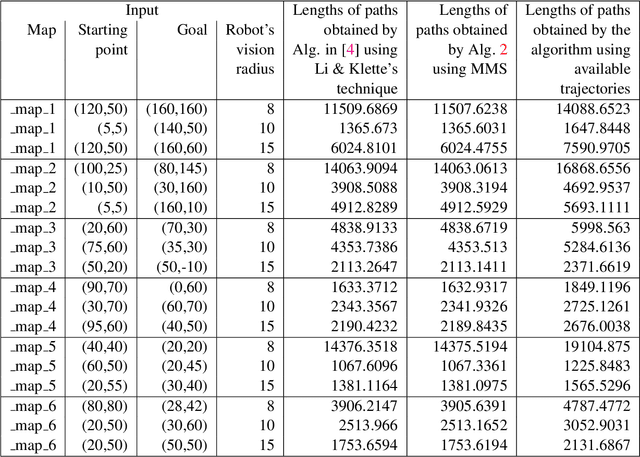
An autonomous robot with a limited vision range finds a path to the goal in an unknown environment in 2D avoiding polygonal obstacles. In the process of discovering the environmental map, the robot has to return to some positions marked previously, the regions where the robot traverses to return are defined as sequences of bundles of line segments. This paper presents a novel algorithm for finding approximately shortest paths along the sequences of bundles of line segments based on the method of multiple shooting. Three factors of the approach including bundle partition, collinear condition, and update of shooting points are presented. We then show that if the collinear condition holds, the exactly shortest paths of the problems are determined, otherwise, the sequence of paths obtained by the update of the method converges to the shortest path. The algorithm is implemented in Python and some numerical examples show that the running time of path-planning for autonomous robots using our method is faster than that using the rubber band technique of Li and Klette in Euclidean Shortest Paths, Springer, 53-89 (2011).
Physics-Informed Learning of Aerosol Microphysics
Jul 24, 2022Aerosol particles play an important role in the climate system by absorbing and scattering radiation and influencing cloud properties. They are also one of the biggest sources of uncertainty for climate modeling. Many climate models do not include aerosols in sufficient detail due to computational constraints. In order to represent key processes, aerosol microphysical properties and processes have to be accounted for. This is done in the ECHAM-HAM global climate aerosol model using the M7 microphysics, but high computational costs make it very expensive to run with finer resolution or for a longer time. We aim to use machine learning to emulate the microphysics model at sufficient accuracy and reduce the computational cost by being fast at inference time. The original M7 model is used to generate data of input-output pairs to train a neural network on it. We are able to learn the variables' tendencies achieving an average $R^2$ score of $77.1\% $. We further explore methods to inform and constrain the neural network with physical knowledge to reduce mass violation and enforce mass positivity. On a GPU we achieve a speed-up of up to over 64x compared to the original model.
Online Bilevel Optimization: Regret Analysis of Online Alternating Gradient Methods
Jul 14, 2022
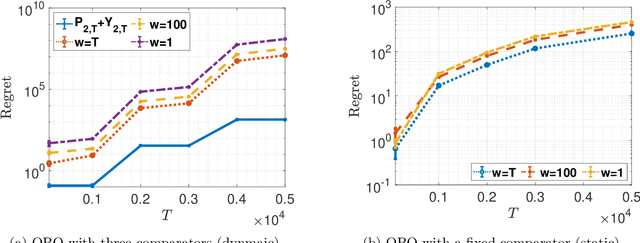
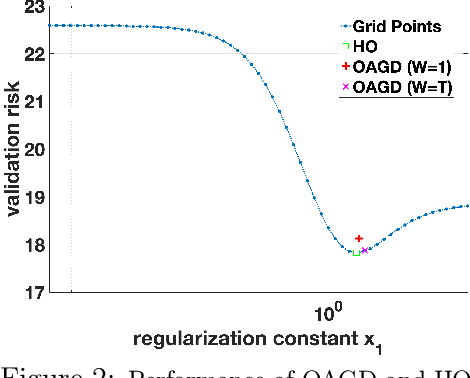
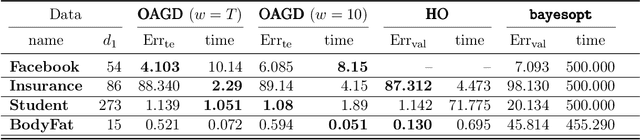
Online optimization is a well-established optimization paradigm that aims to make a sequence of correct decisions given knowledge of the correct answer to previous decision tasks. Bilevel programming involves a hierarchical optimization problem where the feasible region of the so-called outer problem is restricted by the graph of the solution set mapping of the inner problem. This paper brings these two ideas together and studies an online bilevel optimization setting in which a sequence of time-varying bilevel problems are revealed one after the other. We extend the known regret bounds for single-level online algorithms to the bilevel setting. Specifically, we introduce new notions of bilevel regret, develop an online alternating time-averaged gradient method that is capable of leveraging smoothness, and provide regret bounds in terms of the path-length of the inner and outer minimizer sequences.
TE-ESN: Time Encoding Echo State Network for Prediction Based on Irregularly Sampled Time Series Data
May 02, 2021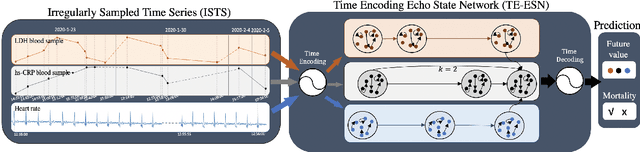

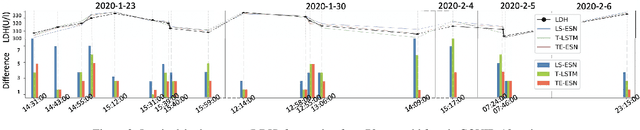
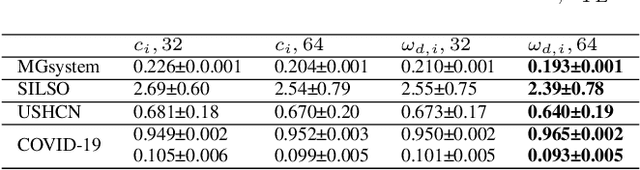
Prediction based on Irregularly Sampled Time Series (ISTS) is of wide concern in the real-world applications. For more accurate prediction, the methods had better grasp more data characteristics. Different from ordinary time series, ISTS is characterised with irregular time intervals of intra-series and different sampling rates of inter-series. However, existing methods have suboptimal predictions due to artificially introducing new dependencies in a time series and biasedly learning relations among time series when modeling these two characteristics. In this work, we propose a novel Time Encoding (TE) mechanism. TE can embed the time information as time vectors in the complex domain. It has the the properties of absolute distance and relative distance under different sampling rates, which helps to represent both two irregularities of ISTS. Meanwhile, we create a new model structure named Time Encoding Echo State Network (TE-ESN). It is the first ESNs-based model that can process ISTS data. Besides, TE-ESN can incorporate long short-term memories and series fusion to grasp horizontal and vertical relations. Experiments on one chaos system and three real-world datasets show that TE-ESN performs better than all baselines and has better reservoir property.
Learning to Solve Soft-Constrained Vehicle Routing Problems with Lagrangian Relaxation
Jul 21, 2022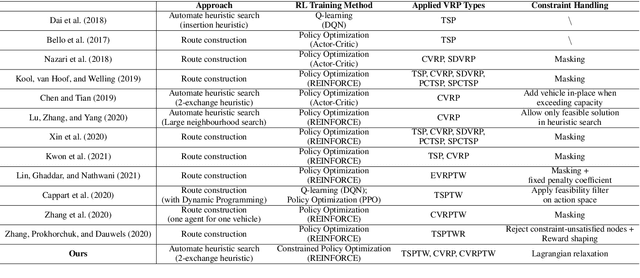

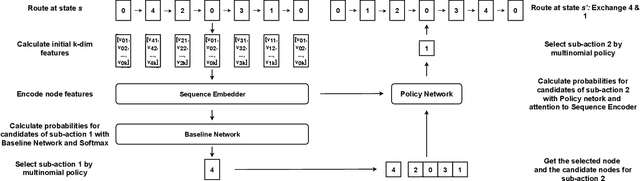
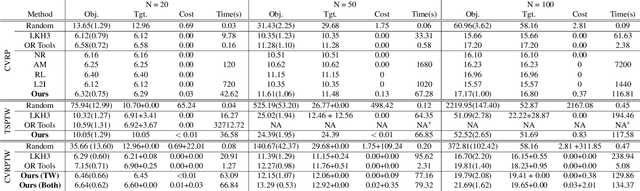
Vehicle Routing Problems (VRPs) in real-world applications often come with various constraints, therefore bring additional computational challenges to exact solution methods or heuristic search approaches. The recent idea to learn heuristic move patterns from sample data has become increasingly promising to reduce solution developing costs. However, using learning-based approaches to address more types of constrained VRP remains a challenge. The difficulty lies in controlling for constraint violations while searching for optimal solutions. To overcome this challenge, we propose a Reinforcement Learning based method to solve soft-constrained VRPs by incorporating the Lagrangian relaxation technique and using constrained policy optimization. We apply the method on three common types of VRPs, the Travelling Salesman Problem with Time Windows (TSPTW), the Capacitated VRP (CVRP) and the Capacitated VRP with Time Windows (CVRPTW), to show the generalizability of the proposed method. After comparing to existing RL-based methods and open-source heuristic solvers, we demonstrate its competitive performance in finding solutions with a good balance in travel distance, constraint violations and inference speed.
Conformal Navigation Transformations with Application to Robot Navigation in Complex Workspaces
Aug 22, 2022
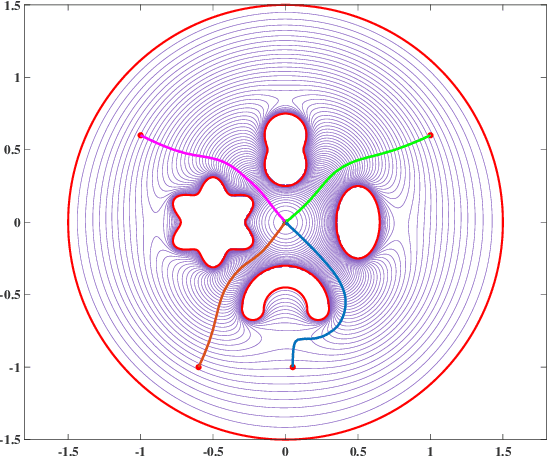
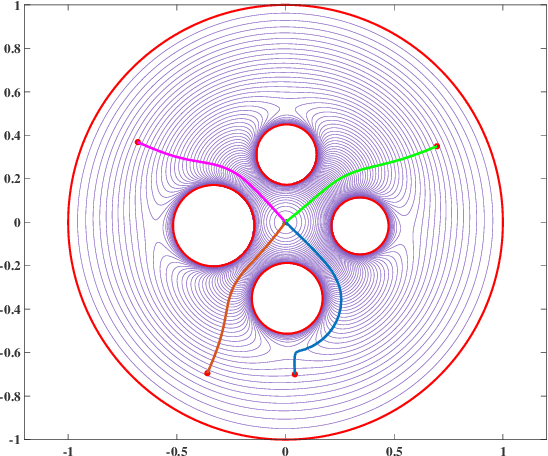
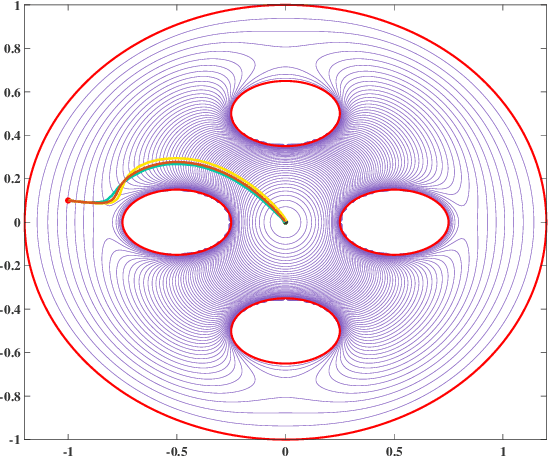
Navigation functions provide both path and motion planning, which can be used to ensure obstacle avoidance and convergence in the sphere world. When dealing with complex and realistic scenarios, constructing a transformation to the sphere world is essential and, at the same time, challenging. This work proposes a novel transformation termed the conformal navigation transformation to achieve collision-free navigation of a robot in a workspace populated with obstacles of arbitrary shapes. The properties of the conformal navigation transformation, including uniqueness, invariance of navigation properties, and no angular deformation, are investigated, which contribute to the solution of the robot navigation problem in complex environments. Based on navigation functions and the proposed transformation, feedback controllers are derived for the automatic guidance and motion control of kinematic and dynamic mobile robots. Moreover, an iterative method is proposed to construct the conformal navigation transformation in a multiply-connected workspace, which transforms the multiply-connected problem into multiple simply-connected problems to achieve fast convergence. In addition to the analytic guarantees, simulation studies verify the effectiveness of the proposed methodology in workspaces with non-trivial obstacles.
Patent Search Using Triplet Networks Based Fine-Tuned SciBERT
Jul 23, 2022
In this paper, we propose a novel method for the prior-art search task. We fine-tune SciBERT transformer model using Triplet Network approach, allowing us to represent each patent with a fixed-size vector. This also enables us to conduct efficient vector similarity computations to rank patents in query time. In our experiments, we show that our proposed method outperforms baseline methods.